ThoughtFold:让推理模型把"想得太多"的废话自己折叠掉
一个反直觉的事实:现在的推理大模型(LRM)越是被 RLVR 训练得"会推理",它就越会"过度思考"——并不是因为它笨,而是 RLVR 这套范式本身在主动鼓励它记住那些没必要的探索。
核心摘要
调过 R1、Qwen3 这类大推理模型的人多半都有这种感觉:模型推理是对了,但生成的 CoT 里充满了"我再确认一遍"、"等等,我换个思路想想"、"或者也可以这样"——明明已经走到答案了,还要绕回去自我重复一圈。这篇来自上海人工智能实验室的 ThoughtFold(arXiv 2606.03503)把这个现象的病灶扒开来给你看:问题不在模型,而在 RLVR——它只看最终答案对不对,于是把一条"碰巧蒙对"的 trial-and-error 轨迹整条记下来,包括那些其实是浪费的探索。作者的方案有意思:用模型自己的注意力把每条正确轨迹里的"冗余步"挖出来,构造出一个从"精炼成功"到"过度简化失败"的偏好谱,再用一个带 Fold Anchor 的动态 mask DPO 在 step 级别做精确监督,配合 GRPO 联合训练。结果是 DeepSeek-R1-Distill-Qwen-7B 的平均 token 砍掉 56.1 个百分点(10234 → 4496),同时准确率不降反升 2.82 个点。这是我最近看到的"高效推理"方向里少有的、技术细节让人觉得"对,就该这么做"的工作。
论文信息
- 标题:ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
- 作者:Ziyan Liu, Xueda Shen, Yuzhe Gu, Songyang Gao, Kuikun Liu, Guangran Cheng, Chengqi Lyu, Dahua Lin, Wenwei Zhang, Kai Chen
- 机构:上海人工智能实验室、中国科学技术大学、香港中文大学 MMLab
- arXiv:https://arxiv.org/abs/2606.03503
- 代码:https://github.com/ziyanliux/ThoughtFold
- 提交日期:2026 年 6 月 2 日
一、问题动机:RLVR 在悄悄教模型"过度思考"
先聊一个我自己跑模型时经常碰到的现象。让 Qwen3-8B 解一道 GSM8K 的小学数学题——一道五句话能讲完的题——它能给你扯出 2000+ 个 token 的 CoT。点开看,前 800 token 把答案都已经算出来了,后面剩下的全是"嗯让我再核对一下"、"另一种角度看"、"等等如果换种方法呢"——结论从头到尾都没变,只是模型在那儿自我对话不肯停下来。
这种"想得太多",专业一点叫 overthinking。但很少有人深究它的根因——其实它根本不是模型的"性格问题",是 RLVR 这套训练范式的算法层 artifact。
来看看 RLVR 怎么干活的。它给一道题采样 G 条轨迹,验证最终答案对不对,然后把"对的那条"整条 reinforce 回去。GRPO 里这个 advantage 是这样算的:
注意这个公式的关键点:对于一条正确轨迹 \(i\),advantage \(A_t^{(i)}\) 被均匀地分配到 CoT 中的每一个 token 上。
问题就在这里。一条"正确的"长 CoT 里,必然包含 trial-and-error——这是推理的本质,不是它的 bug。但 RLVR 不区分哪些 step 是必要推导(信号),哪些 step 是自我重复或岔路尝试(噪声),它把它们一视同仁地强化。
下次模型生成时,它就同时学会了"该怎么推"和"该怎么绕"。模型在学推理能力的同时,也在学过度思考。
之前主流的解法是给短轨迹更高的奖励(Short-RL、RL+Length Penalty 这类),但作者一针见血地指出:这种 trajectory-level 的长度惩罚做不了 step-level 的信用分配。换句话说,你能告诉模型"短的更好",但你没法告诉它"短在哪一步"。结果常常是模型为了追求短,把必要的推理也砍掉了,准确率掉得很厉害。
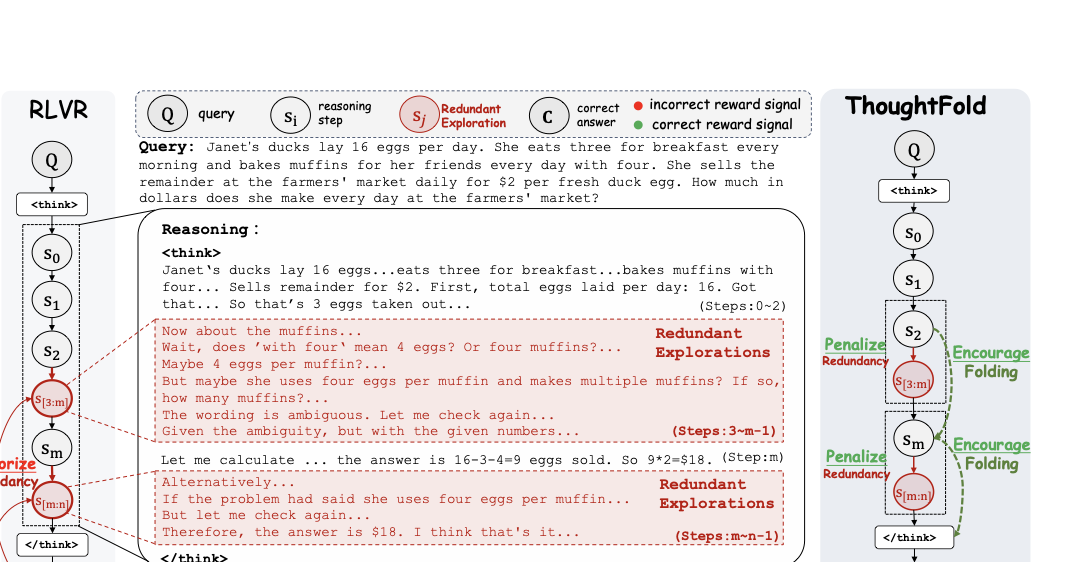
图1:RLVR 把整条正确轨迹无差别地"记下来",于是把冗余探索也一并记住了;ThoughtFold 则把冗余识别出来、精确惩罚,让推理链"折叠"成一条直达答案的路径。
这张图是这篇论文的灵魂。中间那条 CoT 标了 redundant exploration(冗余探索)和 essential reasoning(必要推理)两种颜色——RLVR 视角下它们都是"正确轨迹的一部分",而 ThoughtFold 把它们当成两类截然不同的信号来处理。这才是问题的根本。
二、方法:用模型的注意力,把冗余"内省"出来
ThoughtFold 的核心设计可以用一个词概括:introspective——"内省"。它不引入外部裁判,也不依赖人工标注,而是让模型用自己的注意力分布告诉你"哪些 step 其实是可以省的"。
整个框架由两部分组成:(a)细粒度偏好学习;(b)外层的 GRPO。两者通过一个系数 \(\lambda\) 联合优化:
GRPO 那部分大家都很熟,重点说说细粒度偏好学习这块。
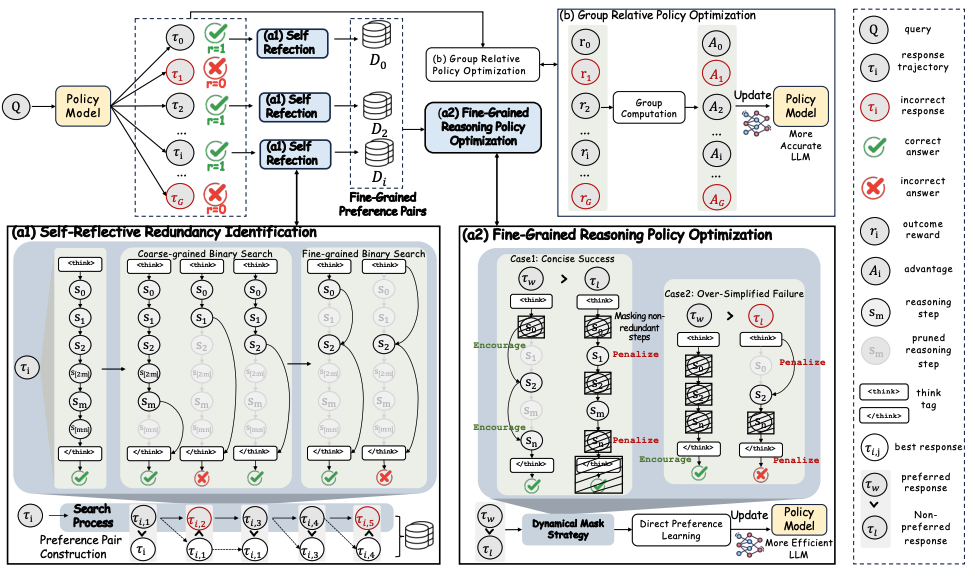
图2:框架总览。橙色色块是被识别出的冗余步,蓝色是必要推理段,Fold Anchor(折叠锚点)是冗余被去掉之后承接逻辑的那一步——动态 mask 就是围绕这个锚点设计的。
2.1 内省式冗余识别:剪枝–验证两阶段
给一条已经通过验证的正确轨迹 \(\tau_{ref} = (z_{ref}, y^*)\),先把 CoT 拆成 step 序列 \(z_{ref} = \{s_1, s_2, \dots, s_N\}\)(按 \n\n 切分)。然后用一种"剪枝–验证"的迭代搜索来挖冗余。
Phase 1:尾部截断(Tail Truncation)
模型经常推到答案了还在那儿"再想一遍"——这是 self-repetition。所以第一阶段做一个前缀长度的二分搜索:取 \(z_{cand,j} = z_{ref}[:m_j]\),截断到第 \(m_j\) 步后强制塞个 </think> token,让模型立刻给答案。如果还能答对,说明 \(m_j\) 之后的部分都是没必要的尾巴。
二分搜索能很快定位到"最短的、还能保持正确"的截断点 \(z_{trunc}\)。
Phase 2:内部折叠(Internal Folding)
光砍尾巴还不够。CoT 中段可能也夹着 off-target attempts——那种"我换个思路试试……不对,回到原来的"的小岔路。这种内部冗余怎么识别?
作者用了一个挺漂亮的 trick——用注意力打分。step \(s_t\) 的重要性定义为:
通俗讲就是:最终答案 token 在生成时,平均"回头看"了这一步多少次? 看得多的步骤说明对最终答案重要,看得少的说明就是溜达了一圈没用。
按这个分数排序,做 retention ratio \(k_j\) 的二分搜索:保留 top-\(k_j\%\) 的高重要性步骤,把低分的折叠掉,看模型还能不能答对。
我得说一句,这个用注意力做 step-level 重要性的设计,比我预期的要巧。它完全不需要训练任何打分器,模型自己的注意力就是天然的"哪一步有用"的指示器。而且因为是基于已经训好的 reasoning model 的 attention,这种判断带着模型自己的"主观体验"——某种意义上是模型在"反省自己刚才哪句话其实是废话"。
2.2 偏好对构造:成功更短 vs 失败过短
这两阶段搜索会生成一系列候选轨迹 \(\{z_{cand,j}\}\),按结果分成两类:
- 精炼成功(\(z_{cand,j} \succ z_{best}\)):剪短了还答对,那它就是当前最好的精简路径,加入 \(\mathcal{D}\) 作正例,更新 \(z_{best}\)
- 过度简化失败(\(z_{best} \succ z_{cand,j}\)):剪过头了答错,记录为负例,告诉模型"这种砍法不行"
这就是"偏好谱"的来源——不是单点的 win/loss,而是整个搜索过程中沿着"长度递减、准确率松动"这条轴自然生成的对比对。
2.3 动态 Mask 策略:Fold Anchor 是关键
光有偏好对还不够,标准 DPO 会犯一个错——它把整条 rejected 轨迹一视同仁地惩罚。但 rejected 里那些"必要的推理步"是不该被惩罚的,preferred 里那些"碰巧也走的步"也不该被强化。
作者引入了一个挺漂亮的概念叫 Fold Anchor(折叠锚点):在精简后的轨迹 \(z_{cand,j}\) 里,紧跟在被剪掉的冗余段之后那一步——这一步起到的作用是"在删掉冗余之后,重新把逻辑接起来"的桥梁。
举例:原序列 \(\{s_0, s_1, s_2\}\),如果 \(s_1\) 被识别为冗余折叠掉,那 \(z_{cand,j}\) 中保留下来的 \(s_2\) 就是 Fold Anchor——它需要直接从 \(s_0\) 接上来,这一步才是"高效连接"的精髓。
针对两类偏好对,mask 设计如下(保留 \(M_t=1\) 的部分参与 loss):
| 场景 | \(M_w\)(winner mask) | \(M_l\)(loser mask) |
|---|---|---|
| 精炼成功 | 激活 Fold Anchor,鼓励模型学会"跳过冗余直接连" | 屏蔽共同步骤和最终答案,只对冗余步施加惩罚 |
| 过度简化失败 | 只激活正确答案 token | 激活 Fold Anchor 和错误答案,惩罚"接得太硬"导致逻辑断裂 |
把这套 mask 套进 DPO 的隐式奖励里:
最终的 MDPO 目标就是:
这套 mask 设计的精妙在于:同样的 step 在不同样本里出现时不会接收冲突的梯度。后面消融实验会证明,这个 mask 是整个方法的灵魂——去掉它,性能崩盘到比 GRPO baseline 还差。
三、实验:56% 的 token 砍掉,准确率反而涨了
3.1 主实验:四个模型、五个 benchmark 全面碾压
实验设置很扎实:四个主流推理模型(DeepSeek-R1-Distill-Qwen-7B/14B、Qwen3-8B/14B),五个 benchmark(GSM8K、AIME 2024、AIME 2025、MATH-500、GPQA Diamond),训练用 DeepMath-103K,对比 5 个基线(Vanilla、GRPO、RL+Length Penalty、Short-RL、S-GRPO)。AIME 跑 16 trials、MATH/GPQA 跑 8 trials、GSM8K 跑 4 trials——抗噪做得挺充分。
主结果先看 R1-Distill-Qwen-7B 这一组(数据来自论文 Table 1):
| 方法 | GSM8K Acc/Tokens | AIME 2024 | AIME 2025 | MATH-500 | GPQA | Overall Acc / Tokens |
|---|---|---|---|---|---|---|
| Vanilla | 92.4 / 1,833 | 55.4 / 13,232 | 39.1 / 15,131 | 85.8 / 5,590 | 50.1 / 15,385 | 64.56 / 10,234 |
| GRPO | 93.2 / 1,767 | 55.0 / 13,451 | 39.0 / 14,926 | 93.6 / 5,317 | 50.7 / 15,817 | 66.30 / 10,256 |
| RL + Length Penalty | 92.4 / 1,062 | 51.9 / 7,464 | 35.5 / 9,976 | 92.2 / 2,451 | 49.1 / 3,984 | 64.22 / 4,987 |
| Short-RL | 93.1 / 1,102 | 53.7 / 7,239 | 35.2 / 9,779 | 91.7 / 2,234 | 49.3 / 3,897 | 64.60 / 4,850 |
| S-GRPO | 93.8 / 906 | 56.0 / 7,377 | -- | 92.4 / 2,252 | 50.8 / 3,751 | -- |
| ThoughtFold | 94.3 / 842 | 57.2 / 7,013 | 39.1 / 9,102 | 94.4 / 2,089 | 51.9 / 3,433 | 67.38 / 4,496 |
总体看下来,几个关键现象:
第一,Length Penalty 类方法掉准确率掉得很明显。 Short-RL 和 RL+Length Penalty 把 token 压下去了,但 AIME 2024 上从 55+ 掉到 51-53,AIME 2025 从 39 掉到 35。这印证了开头那段判断——trajectory-level 的长度惩罚没办法做 step-level 信用分配,砍长度的时候必要推理也被砍掉了。
第二,GRPO 不仅没省 token,还涨了 0.2%。 这就是 RLVR 在主动鼓励冗余探索的直接证据——它优化准确率的副产物就是把 CoT 拉得更长。在 R1-Distill-Qwen-14B 上更夸张,GRPO 把 token 从 7305 干到 8194,多写了 12.2%,这数据看得我有点想笑。
第三,ThoughtFold 是唯一一个"既短又准"的方法。 在 7B 模型上准确率 +2.82 个点、token -56.1 个点。在 GPQA 这种纯 OOD 的科学推理任务上还能涨 1.8 个点(50.1 → 51.9),说明它学到的不是"这道数学题该怎么压缩",而是更通用的"如何不绕弯子"的推理结构。
四个模型 overall 看一下 token 压缩比:7B 砍 56.1%、14B 砍 42.6%、Qwen3-8B 砍 41.9%、Qwen3-14B 砍 39.4%。模型越小、原本越啰嗦,ThoughtFold 的增益越明显——这其实挺合理,越啰嗦的模型,可压缩空间越大。
说实话看到 R1-Distill-7B 这一栏 +2.82 acc / -56.1 tokens 这两个数同时出现的时候,我愣了一下。一般这类工作 trade-off 都是"我用 X% 的准确率换 Y% 的速度",能两边同时占便宜的不多。
3.2 消融实验:mask 一拆全盘崩
来到我最关心的部分——这套方法的几个组件,到底哪个最重要?
| 配置 | Phase 1 | Phase 2 | Mask | GSM8K | AIME 2024 | AIME 2025 | MATH-500 | GPQA | Overall Acc / Tokens |
|---|---|---|---|---|---|---|---|---|---|
| GRPO baseline | N | N | N | 95.8 / 2,355 | 74.0 / 15,061 | 65.4 / 17,987 | 94.4 / 5,440 | 55.8 / 8,819 | 77.08 / 9,932 |
| ThoughtFold 完整版 | Y | Y | Y | 96.2 / 1,097 | 78.1 / 9,099 | 65.4 / 11,670 | 97.4 / 2,933 | 57.9 / 4,571 | 79.00 / 5,874 |
| w/o attention(随机选) | random | Y | Y | 95.5 / 1,398 | 77.1 / 9,978 | 63.9 / 13,114 | 96.1 / 3,194 | 56.9 / 4,873 | 77.90 / 6,511 |
| w/o Phase 2 | N | Y | Y | 96.3 / 1,457 | 77.9 / 10,449 | 64.6 / 13,081 | 96.9 / 3,367 | 57.7 / 4,786 | 78.68 / 6,628 |
| w/o mask | Y | Y | N | 94.8 / 1,134 | 73.2 / 11,079 | 62.3 / 13,371 | 94.1 / 3,542 | 54.6 / 5,099 | 75.80 / 6,845 |
几个观察:
注意力打分确实比随机选好——但好得没那么夸张。 w/o attention 那一行准确率从 79.00 降到 77.90(-1.1),token 从 5,874 涨到 6,511。说明 attention-based importance 是有用的,但 Phase 1 的尾部截断 + 动态 mask 已经把大部分空间吃掉了,attention 只是锦上添花。
Phase 2 单独贡献也不大。 w/o Phase 2 是 78.68,比 full 只低 0.32。这其实有点出人意料——按论文的逻辑,内部折叠应该是核心,但消融数据告诉你 Phase 1 的尾部截断已经能解决大部分冗余了。
真正的灵魂是 mask。 w/o mask 那一栏直接崩了——overall acc 75.80,比 GRPO baseline(77.08)还低 1.28 个点。论文的解释也很到位:credit assignment ambiguity——同一个 reasoning step 在 preferred 和 rejected 轨迹里都出现时,不做 mask 的 DPO 会给它互相冲突的梯度,模型就被搞混了。
这个消融让我对方法的本质有了更清晰的判断:ThoughtFold 真正值钱的不是用注意力挖冗余这一招,而是用动态 mask 解决 step 共享导致的信用分配冲突。前者是数据构造层面的优化,后者是 loss 设计层面的根基。如果有人想复现或迁移这个方法,mask 那块是核心,attention scoring 可以先用启发式替代。
3.3 超参分析:\(\lambda\) 给了一个干净的 trade-off 旋钮
\(\lambda\) 控制 GRPO 和 fine-grained preference 的权重。Qwen3-8B 上的实验数据:
| \(\lambda\) | 0 (GRPO) | 0.001 | 0.01 | 0.1 | 1.0 | \(\infty\) (MDPO) |
|---|---|---|---|---|---|---|
| Acc (%) ↑ | 77.08 | 78.14 | 79.21 | 79.00 | 77.23 | 73.57 |
| Tokens ↓ | 9,932 | 7,512 | 6,431 | 5,874 | 5,249 | 4,787 |
这个 trade-off 曲线挺漂亮的。\(\lambda\) 在 0.01 ~ 0.1 之间是甜蜜点,再大准确率开始掉。\(\lambda \to \infty\)(纯 MDPO 没 GRPO)时 token 最少(4,787)但准确率掉到 73.57——印证了作者的判断:MDPO 只惩罚冗余,不能给"必要推理步"提供正向信号,所以必须配上 GRPO 兜底正确性。
工程视角看,这个旋钮给得很大方——业务方可以根据延迟敏感度和精度要求自己调,不用动模型架构。
3.4 ML@k 与拓扑分析:不是简单地"剪短",是真的"重塑"
作者还引入了一个有意思的指标 Minimum Average Length@k(ML@k),类比 pass@k——给定 k 次 rollout 预算,期望的最小输出长度。
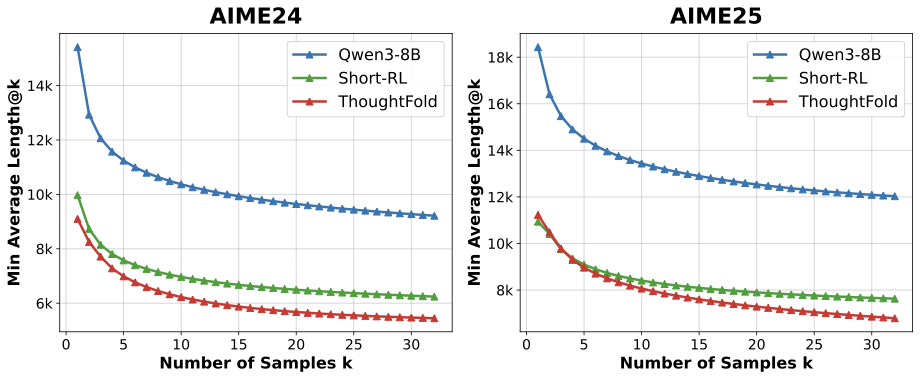
图3:ThoughtFold 不仅 ML@1 短,关键是 ML@k 曲线斜率更陡——这意味着它的"最短可能输出"分布被实质性地压低了,不是靠平均拉低均值。
这张图传递的信息很值得品。Short-RL 和 ThoughtFold 在 ML@1 上其实差距不大——也就是说"平均长度"接近。但 ThoughtFold 的 ML@k 曲线随 k 增大降得更快、最终下界更低。说明它真的能产出更短的轨迹,而不是把长尾压平——前者是结构性优化,后者只是分布塑形。
更直观的是拓扑可视化:
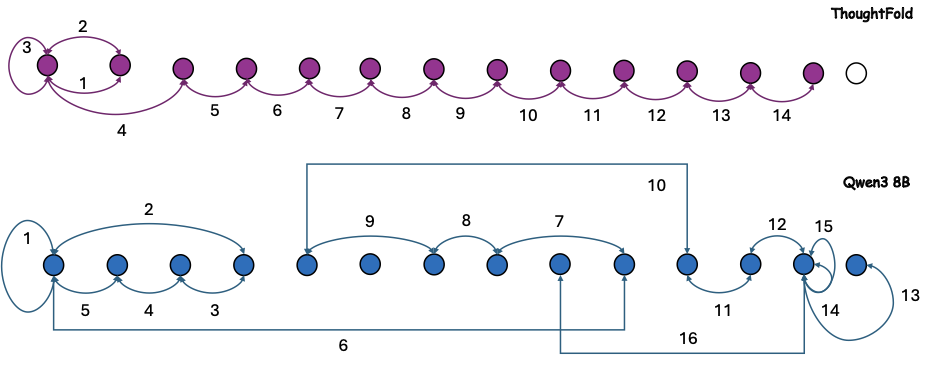
图4:把推理 step 投影到概念图后,ThoughtFold 的轨迹是一条直线,vanilla Qwen3-8B 有明显的环路和长程回跳。冗余探索不是 token 数的问题,是结构的问题。
这张图我觉得是这篇论文里最直观的"why it works"证据。Vanilla 模型那种"想一下、回头确认、再想一下、又回头"的螺旋式推理,在拓扑图上就是真的会出现环。ThoughtFold 训完之后这些环消失了,轨迹直接从问题走到解。
3.5 Case Study:Short-RL 的"为短而错"病

图5:Short-RL 的失败案例很有代表性——为了短而短的方法,常常会在压缩过程中丢掉关键步骤、走向幻觉。
这种失败模式我自己之前调 Length Penalty 的时候也遇到过——模型把"短"当成目标后,会主动在中间过程偷懒,包括把数值估算、保留必要的代数步骤都跳过。最终答案对错不可控。
ThoughtFold 通过 over-simplified failure 这一类负样本明确告诉模型:"这种砍法是不行的",从机制上避免了 Short-RL 这条路。
四、我的判断:这是一篇我会想自己复现的工作
聊聊我对这篇论文的整体看法。
最大的亮点:把 overthinking 的根因归到 RLVR 的 credit assignment 上,然后用一套自洽的方法链(introspective 挖冗余 → 偏好谱构造 → 动态 mask DPO)把这个问题精确解决。对问题的诊断和对方案的设计是对得上的——这种感觉在很多论文里其实并不常见,很多工作是"先有方法再编故事",这篇是"先看清问题再设计方法"。
最有借鉴价值的设计:动态 mask 配合 Fold Anchor 的概念。这套思路其实可以泛化到其他"step 级偏好学习"的场景——任何时候你有"长 vs 短"、"详细 vs 简洁"的偏好对,且共享 step 较多,都可以借鉴这个 mask 设计来避免冲突梯度。
有点疑虑的地方:
第一,Phase 2 的注意力打分依赖于"middle Transformer layer"——这个具体哪一层、为什么是中层、不同模型是否需要不同选择,论文里说得不够细。从消融看 attention 不是核心,但如果想推广到 GPT-OSS、Llama 这类不同架构,这块可能需要重新调。
第二,introspective 搜索的成本。论文说"only a single computation per correct sample, incurring negligible training overhead"——但 Phase 1+2 都是二分搜索,每个候选都要一次 forward 拿到答案。如果一道题的 G 条 rollout 里有 5 条对的,每条做 log(N) 次二分,单 step 的训练成本至少是普通 GRPO 的几倍。论文没给具体的训练时间对比,希望开源代码能补充这块的 profiling。
第三,"crucial 假设"——模型自己的注意力分布能客观反映 step 重要性。这个假设其实挺勉强。注意力从来都不是因果性指示器,attention is not explanation 这事社区吵了好多年了。这里之所以 work,可能是 attention + 二分搜索 + 准确率验证这三个机制叠加起来形成的鲁棒性。如果只用 attention 不做剪枝–验证,单点判断的可靠性应该会差很多。
对工程的启发:
如果你正在做需要长思维链的 Agent 或推理服务,且推理成本是瓶颈,ThoughtFold 这套方法值得直接试——它不需要外部裁判模型、不依赖人工标注、可以从你已经训好的 GRPO checkpoint 接着 finetune。用 R1-Distill-7B 那个 56% 的 token 压缩比直接对应推理 latency 的 50%+ 下降,这对在线服务的价值非常实在。
更深一层,RLVR 这个范式本身可能需要重新审视。这篇论文把"信用分配"这个老问题在长 CoT 场景下重新点出来了——RLVR 看似已经成熟,但只要它依赖 outcome-only 奖励,它就在持续地把噪声当信号训进模型。下一波"高效推理"工作可能都会朝这个方向发力——细粒度信用分配、step-level 信号挖掘、structure-aware 的 RL。ThoughtFold 算是这个方向上一个比较清晰的起点。
最后,标题取得也很聪明。"Folding"这个动词比"compressing"或者"pruning"都准确——它不是把推理删短,是把绕来绕去的路径"折叠"成直线。这个差别看图 4 那个拓扑可视化体会最深。
参考链接
- 论文:https://arxiv.org/abs/2606.03503
- 代码:https://github.com/ziyanliux/ThoughtFold
- 相关工作:DeepSeek-R1(GRPO)、Mask-DPO、S-GRPO、Short-RL
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我