PEFT 不只是省钱的小补丁——它能撑起百万级人格模型
📌 核心摘要
如果你对 LoRA 的认识还停留在"全参微调用不起所以选它"这一层,这篇论文应该会让你重新思考一下。一个叫 Mind Lab 的团队(作者多达 65 人)放出了一篇 6 月初的硬核 position paper,arXiv ID 2606.02437,标题很直白——「On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters」。
这篇文章想说一件事:PEFT(特别是 LoRA)的价值不在于"便宜版的全参微调",而是让"一份共享的万亿基模 + 千万份小适配器"这种架构第一次变得可行。每个适配器是某个用户/Agent/角色的"持久人格状态"——记忆、技能、工具习惯、偏好——可以被命名、版本化、回滚、热部署。论文给出三条耦合的缩放轴:Scale Up 让基模越强适配器越值钱(Kimi K2 上跑 1T MoE 的 LoRA RL,算力压到全参 RL 的约 10%);Scale Down 把可训练单元压到极限(rank-1 仍能学,但需要 OLoRA-tail 这种 RL 友好的初始化才稳);Scale Out 把多模型当资源(同一个 30B 基模训出来的不同 LoRA,多数表决在 AIME24 上从 0.3644(k=1)涨到 0.4867(k=198))。配套的基础设施 MinT 给出策略身份、适配器版本、显存常驻三层抽象的工程范本。
我的判断:这是一篇"集大成式"的方向性论文,单独看每个子结论都有同期工作(OLoRA、PiSSA、MiLoRA、S-LoRA、LoRAHub 等),但把三条轴放在"持久人格模型"这个统一框架下重新讲,并用 1T 规模的实测撑起来,确实有它独特的位置。如果你在做 Agent、个性化、长期记忆方向,这篇值得花两小时啃。
📖 论文信息
| 字段 | 内容 |
|---|---|
| 标题 | On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters |
| 机构 | Mind Lab |
| arXiv | 2606.02437 |
| 提交 | 2026-06-01(v2: 2026-06-02) |
| 主题 | cs.LG / cs.CL |
🎯 从一个真实场景说起:你为什么需要"人格化"的小适配器
先抛一个我自己经常碰到的痛点。
我们之前给一个 Agent 系统接了一堆能力——长上下文、RAG、工具调用、用户画像。理论上"个性化"齐活了。但用了三个月就会发现一件很别扭的事:每开一次新会话,模型仍然像第一次见你。它知道你叫什么(profile 里写着)、知道你前几天问过什么(retrieval 翻得到),但它没有"记住你"——它只是每次重新读一遍你。
这个区别其实很关键。Profile 是 prompt 里的几行文字,retrieval 是检索出来再读一遍的笔记,这些都是"外挂的状态",不是"模型本体的一部分"。你昨天纠正过它一次的口味、上周教它的一套工作流、半年来反复出现的偏好——这些没有沉淀到模型本身的策略里去。它依然要在每次推理时把这些信息全部读一遍才能装作"懂你"。
论文给的处方是:让一份小小的 LoRA 适配器扛起这个"持久人格状态"。基模继续提供广义智能(推理、世界知识、语言、工具使用),适配器扛持续累积的行为后果——偏好、习惯、技能、长期记忆里"行为相关"的那一层。原始事实和文档继续放检索系统,适配器不当资料库。
这是 PEFT 的第二种姿态。它不是"全参微调省不起,所以将就用一下 LoRA",而是 "PEFT 是个性化的天然单位"——99% 的能力共享,0.5% 的差异写进每个人自己的小适配器里。论文用了一个挺漂亮的生物学类比:人类基因组之间相差不到 1%,那 1% 已经足够区分出每一个个体。
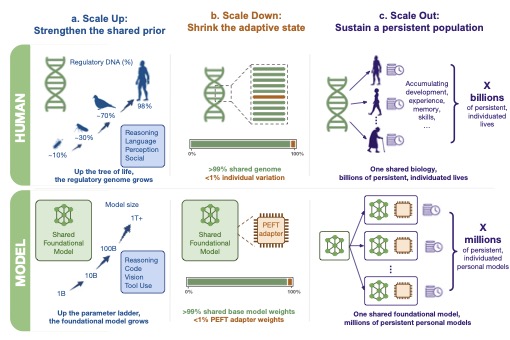
图1:论文开篇的核心隐喻——一份共享基模 + 海量个性化小适配器,类比为「一份共享生物学 + 数十亿持久人格」。
🧭 三轴框架:不是三个独立维度,而是耦合的依赖链
论文最值得记的一张表,不是任何实验主表,而是它怎么把"PEFT 缩放"这个含糊的题目结构化。它把问题拆成三条轴:
| 轴 | 在问什么 | 关键技术证据 |
|---|---|---|
| Scale Up | 共享基模强到什么程度,小更新才有杠杆? | 万亿规模 LoRA RL(Kimi K2,1T MoE)、TIM 失效、Router Replay R3 |
| Scale Down | 局部适应状态可以多小、多稳、多便宜? | Rank 扫到 1,OLoRA-tail RL 友好初始化,超参跨 rank 迁移 |
| Scale Out | 海量持久适配器同时存在会发生什么? | LoRA 记忆容量律、Context Learning、OASIS 社会模拟、多模型多数表决 |
但作者强调一句很重要的话——三条轴不是松散的分类,而是依赖链:
- 只有 Scale Up,没有 Scale Down——基模再强,每次微调都贵到不能频繁做,个性化沦为偶尔事件;
- 只有 Scale Down,没有 Scale Up——适配器是便宜了,但下面没强先验,调出来的东西没什么杠杆;
- 没有 Up 和 Down 就直接 Scale Out——你只是堆了一堆同质化、低质量、随时可丢的小变体,不是真正的持久人格。
这才是这篇论文的"骨架",比任何单点的实验数字都重要。后面所有章节都是为这条依赖链补证据。
🚀 Scale Up:先把"基模强到值得反复改写"这件事做扎实
这一轴的核心命题是 "RL is prior-limited"——RL 只能强化 base policy 已经能采样到的轨迹。基模如果根本采不到正确的推理路径,PPO/GRPO 就只能在噪声里挣扎。基模越强,潜在能被强化的"半成品技能"越多,每一步小更新的杠杆就越大。
LoRA 在这件事里扮演的不是"省内存的小补丁",而是让强先验进入持续优化循环的经济票根。比较点不是"全参 vs LoRA",而是 "在固定预算下你能让多大的先验进 RL loop"。一个小但全参可训的模型,可训参数比例高,但底子薄;一个大但 LoRA 的模型,可训参数少,但站在巨人肩上——后者只需要"把强先验掰一掰"。
万亿规模 LoRA RL:不是不可能,但要协同设计
论文的硬证据是 Kimi K2 上的实测:1.04T 参数 MoE、激活 32.6B 的推理模型,用 LoRA + GRPO-style 在线策略 RL,算力和通信开销压缩到全参 RL 的约 10%。
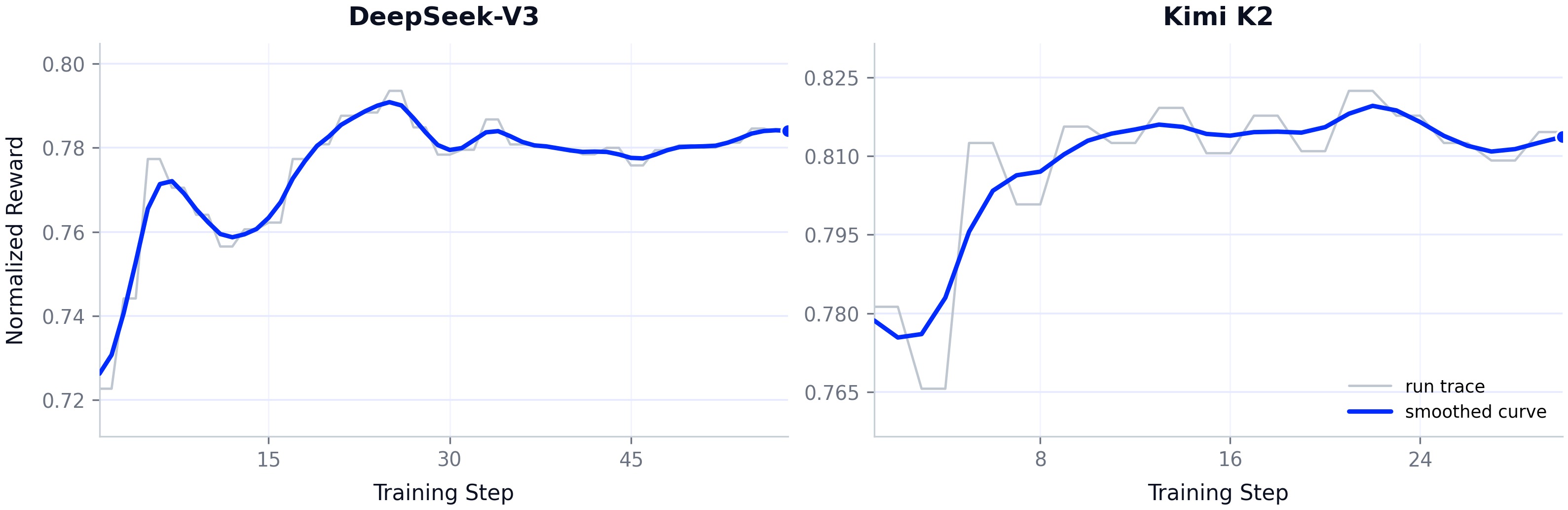
图2:1T MoE 模型上的 LoRA RL 训练曲线,奖励和任务成功率保持单调上升,验证了「rollout、训练、混合并行联合设计」的可行性。
但坦率讲,做到这个规模,LoRA 已经不只是一个低秩参数化了——它变成一个分布式系统对象。论文识别出四类 scale-induced failure modes,我觉得是这一节最有工程价值的内容:
- 算法不一致失效(TIM, Training-Inference Mismatch):rollout 用推理引擎、训练用训练引擎,两边数值精度差一点点,在稠密模型里只是噪声;在 MoE 里会改变路由决策——token 走到不同专家,整个计算图都不一样了。这时 importance sampling 修正已经不够用,因为它假设的是"分布在同一个计算图上偏移",而你这里计算图本身在变。
- 稀疏架构失效:路由、稀疏注意力的 top-k、MTP 头的处理,每一处的细微差别都会让 adapter 训练到的"有效计算"和服务时的不一致。
- 适配器语义失效:LoRA 包装器在 MLA、DSA、专家层这些"非标准 Linear 层"上加,看似 load 成功,实际语义已经跑偏。
- 生命周期/服务失效:训练好的 adapter 经过保存→合并→量化→服务,每一步都可能让"被部署的策略"不再是"被训练的策略"。
针对 TIM,作者给的办法是 Router Replay R3——rollout 时把路由信息记录下来,训练时回放。听起来很简单,但我觉得这个想法的精髓在于它承认了一件事:在 MoE + RL 这种规模上,"算法"已经不能脱离"执行路径"独立定义。这是一个挺反直觉但很硬核的认识。
实测上,R3 让 PPO KL divergence 从飙升到接近 0(step 46 时 0.000026),梯度范数也稳定下来,下游 DAPO 数学任务的验证准确率单调上升。
我的判断
Scale Up 这一节最值得借鉴的不是"我们能在 1T 上跑 LoRA RL"这个结论本身(同期工业界其实也在做类似事情),而是它第一次把"规模上的 RL 失效模式"做了系统性梳理。如果你正在尝试在 MoE 模型上做 RL 微调,TIM 和 R3 这两个概念至少能让你少走半年的弯路。
⚙️ Scale Down:rank 不是越大越好,秩为 1 也能用——但前提是初始化对了
这一节是我个人最喜欢的部分,因为它给出了"rank 该选多少"这个常被拍脑袋的问题一个相对扎实的答案。
Rank 扫描:三段操作区,不是单调曲线
作者在 Qwen3-8B 上做了 216 次 PPO 跑(9 个 rank × 4 个 batch × 6 个 seed),数学验证奖励,500 步固定预算。结果不是单调的容量曲线,而是三段:
![]()
图3:Rank-batch 增益热图。三段操作区一眼能看出来——中段(16-32)是当前部署默认值;低段(1-4)有可达的高点但跨种子均值塌陷;高段(64-256)已经在浪费可训练参数预算。
| 区段 | rank 范围 | 现象 | 解读 |
|---|---|---|---|
| 低秩研究区 | 1-4 | 最优 seed 接近中秩,但跨 seed 均值塌陷、方差大 | 不是容量不够,是优化不稳 |
| 中秩部署默认 | 16-32 | 最高均值增益、风险可控、token 效率好 | 当前推荐操作点 |
| 高秩警示区 | 64-256 | footprint 暴涨,最优 frontier 不再扩展 | 性价比差,挤占其他预算 |
最反直觉的一点:rank-1 的 best-seed 表现已经接近 rank-32,问题不是容量,是稳定性。这就把 rank 从"容量旋钮"重新定义成了"操作区参数"——你需要的不是更多 rank,而是让你那一两个方向稳下来。
OLoRA-tail:用预训练权重的"次要奇异方向"做初始化
那怎么让 rank-1 稳下来?作者提了一个挺漂亮的小 trick——OLoRA-tail。
直觉是这样的:
- LoRA 默认随机初始化,rank=1 的时候你只有一根方向向量,随机选一根太碰运气;
- PiSSA / MiLoRA 用 SVD 分解的奇异向量做初始化(PiSSA 用主奇异方向,MiLoRA 用次要方向),SFT 上效果不错——但搬到 RL 上会崩,KL 直接爆炸;
- 论文复现了这个崩溃现象,并提出原因:PiSSA/MiLoRA 把奇异值的幅度也注入进去了,让初始 update 太激进,撞破 RL 的 KL 信任域。
OLoRA-tail 的修改非常小,但很关键:
注意——只取最小奇异值对应的左/右奇异向量,不带奇异值缩放。换句话说,"用预训练权重里那些'最不重要的方向'做正交初始化"。
为什么这是 RL 友好的?两个原因:
- 次要子空间是预训练模型里的"惰性方向"——在这些方向上做更新不会大幅扰动主流策略,KL 漂移自然小;
- 不带奇异值缩放——避免初始 update 在 KL 预算耗光之前就把策略推得太远。
公式上有一段我觉得讲得很到位。RL 的有效梯度近似依赖一阶 Taylor 展开:
只在 rollout 策略和当前策略接近时才成立。一旦初始化推得太猛,这个近似就破了,整个 PPO/DAPO 链路全部失效。所以"初始化"在 RL 里不只是起点选择,它在塑造整个轨迹能不能停留在可信区里。
Rank-1 实测:OLoRA-tail 把不能用变成能用
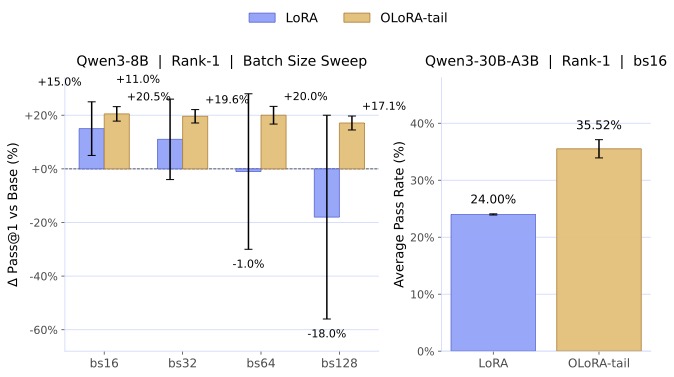
图4:Rank-1 极限压缩下,OLoRA-tail 与标准 LoRA 的对比。Qwen3-8B 上 LoRA 在 bs=128 时直接负增益(-18%)、崩溃率 67%,OLoRA-tail 全程稳定 +20%。Qwen3-30B 上 +11.5 个点的绝对差距(相对 +48%)。
我看到这个数的时候第一反应是有点不敢相信——rank-1 LoRA,每个权重矩阵只有一个外积更新方向,居然在 30B 模型上能跑出 35.5% pass rate?这意味着 LoRA 的"最小可用单元"远比我们以为的要小。
实务上的启示也很直接:如果你在做 RL 微调,且对 KL 漂移敏感,把 LoRA 的初始化换成 OLoRA-tail 几乎是无成本的改动——可训练参数、optimizer state、checkpoint 大小、服务时间内存全都不变,只换初始化权重。
一个小提醒:OLoRA-tail 的论文叙述是把它定位成"RL 友好"的初始化,SFT 场景下它和 PiSSA/MiLoRA 的相对优势可能会变。这点作者也承认——RL 的稳定性约束(KL leash)才是它优势的来源。
🌐 Scale Out:从一个模型,到多个适配器构成的"群体"
Scale Down 把单个适配器压到极小且稳定。Scale Out 接着问:当成千上万个这样的小适配器同时存在,会发生什么?
论文把这个问题拆成三层:
- 个体层——LoRA 作为持久记忆和技能容器,能装多少?该装什么?怎么写入?
- 环境层——一群带着不同适配器的 Agent,能不能构成一个比 prompt-based 模拟更真实的"用户群体"?
- 群体层——不同适配器之间的差异,能不能聚合成系统级的能力增益?
LoRA 作为记忆:容量律
第一个反直觉的发现:LoRA 记忆是有硬上限的,且这个上限可以测量。作者构造了一个叫 DishNameBenchmark 的受控基准("报菜名"——一个菜名是一个记忆槽,连写、查、改都能测),扫了 263 次跑:
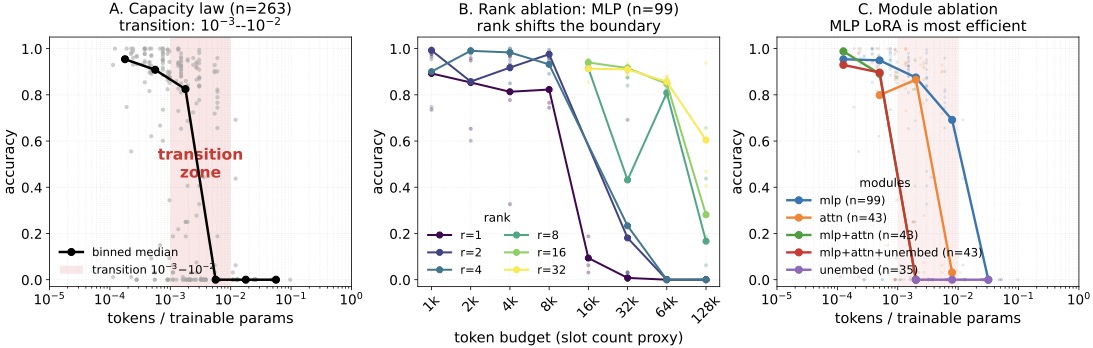
图5:LoRA 作为记忆的容量律。可用容量大约在 每个可训参数 0.001 到 0.01 个 token 之间,超过就饱和崩溃。MLP-only 训练的参数效率最好。
三个核心结论:
| 结论 | 实测 | 工程含义 |
|---|---|---|
| 容量上限存在 | 约 \(10^{-3}\) 到 \(10^{-2}\) tokens / 可训参数 | 你不能把所有事都塞 LoRA 里 |
| 超过容量后线性下滑 | 不是软退化,是较硬的边界 | 容量规划要在 onboarding 阶段就设好 |
| MLP > Attention ≈ All ≫ Unembed | MLP-only LoRA 参数效率最好 | 个人记忆首选 MLP 层 |
这个结果其实挺重要——它把"LoRA 能不能当长期记忆"从玄学问题变成了一个有边界的工程问题。容量算得清楚,你就能算出"一个用户的历史上限是多少 token / 多少 turn"。
该写什么进 LoRA:行为状态,不是原始事实
容量有限,所以"什么该被写进 LoRA"就成了关键问题。论文给了一个层次表:
| 记忆层 | 例子 | 适合存什么 |
|---|---|---|
| Context | 当前对话 | 短期推理、本地任务状态 |
| Retrieval | 笔记、文档、用户事实 | 可编辑的事实,大量证据 |
| Tool state | 日历、文件、数据库 | 必须可外部审视的实体状态 |
| LoRA memory | 技能、习惯、策略、人格 | 持久的行为状态 |
这个分层的精髓是——LoRA 写"行为后果",不写"原始事实"。一份会议纪要应该留在 retrieval;一个反复用的工作流("先用 X 工具拿数据,再用 Y 工具分析,最后写报告")应该写进 LoRA。前者编辑频繁、内容易变,适合外部存储;后者本身就是稳定的行为模式。
技能侧的实测:基于 Qwen3-235B,用 rank-32 LoRA 训 ALFWorld 任务,平均成功率从 0.646 提到 0.845——证明 LoRA 确实能装"可复用的程序性技能",不只是参数级的"记住一个名字"。
Context Learning:把"上下文里的临时改进"内化进参数
记忆有了容量律,那写入策略呢?作者提了 Context Learning 这个概念,定位是 personal model 的 write policy——决定哪些临时的上下文级改进应该被沉淀成持久参数。
机制叫 Context Distillation,伪代码很简单:
def context_distill(model, query, build_context, rl_update):
out = model.sample(query) # 1. 仅 query 出 rollout
ctx = build_context(query) # 2. query+context 给奖励
r_tok = model.token_reward(query, ctx, out)
return rl_update(model, query, out, r_tok) # 3. 用奖励更新 query-only 策略
关键在于:rollout 是从"无上下文"的策略采的,但奖励是用"加了上下文"的更强系统给的。这样训完之后,模型在没有 context 的时候也能表现得好——上下文里"临时学会"的东西被内化进参数了。
我觉得这个设计很巧。它和传统的 context distillation(用 teacher 模型在有 context 下生成数据,再 SFT 学生模型)有本质区别——这里是 on-policy 的,避开了 SFT 的分布偏移问题。RAG2LoRA 就是一个具体例子:当某些事实反复在 retrieval 中被用到、并反复改善行为,就把它从 retrieval 层"上提"到 LoRA 层,retrieval 仍然保留可编辑副本。
用户模拟:per-user LoRA vs prompt-based persona
prompt-based 的多人格模拟(OASIS、Generative Agents 这一类)有个老问题——persona prompt 改变的是描述,不是策略。所有 Agent 共享同一个 base policy,重复交互几轮之后,行为会向 base model 的平均态漂移,"个性"消失。
作者在 OASIS 平台跑了一个对照实验:c8 游戏开发社区,N ∈ {128, 256, 512},每个用户分一个 rank-4 LoRA(用历史 80 条推文训)vs 共享一个 Qwen3-4B-Instruct base。结果:
| 指标 | 含义 | LoRA / Base 比值 |
|---|---|---|
| Effective interaction communities | 有效交互社区数 | 1.47-2.19× |
| Within-side stance std | 同阵营立场分散度 | 1.32-2.45× |
| Comments in DB | 评论总数差 | +70 / +247 / +493 |
| Original posts in DB | 原创帖差 | +139 / +153 / +306 |
LoRA 群体的身份持久性(极化距离稳定)、话题多样性(立场分散度高)、社区拓扑(有效社区数随 N 单调上升)全面优于共享 base。最关键的是——这些差异不是数量级别的,而是质性的。共享 base 群体几乎没人发原创帖,LoRA 群体里有上百条;共享 base 把"赞"挤到长尾头部,LoRA 群体的 attention 分布更平。
一句话总结:prompt-based 模拟是"一个模型在演不同的人",LoRA-based 是"很多人在自己活着"。
群体智能:模型数量 = 计算资源
最后一个实验是我觉得这篇论文里最让我"愣一下"的:同样的 30B base、同样的 RL 配方,只改训练数据排列和 mask,得到一群 LoRA 变体,多数表决合作。
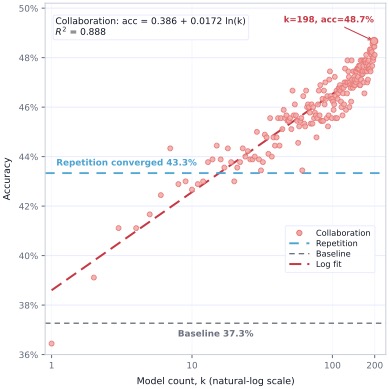
图6:AIME24 上的多数表决曲线。k=1 时 0.3644,k=10 时 0.4267,k=100 时 0.4633,k=198 时 0.4867。Collaboration 比 Repetition 在大 k 下高出约 +5.3 个点。拟合:accuracy ≈ 0.386 + 0.0172·ln(k),R²≈0.888。
这个结果重要在哪儿?
- 不是采样噪声——重复采样(Repetition)很早就饱和了,Collaboration 还能继续涨;
- 不是预训练差异——所有 LoRA 都长在同一个 base 上,只在数据扰动 + mask 上有别;
- 是真实的策略互补性——不同 LoRA 走了不同的优化轨迹,犯不同的错,互相能纠错;
- 而且能拟合成 ln(k) 的对数律——可以当一个研究对象去优化。
这把 PEFT 的价值带到了一个新层面:不仅是"训出一个更好的模型",而是"训出一群有用的不同模型"。同一个 base 上长出 200 个不同的 LoRA,比训 200 个 full checkpoint 便宜两个数量级,但能拿到的群体智能增益是真实的。
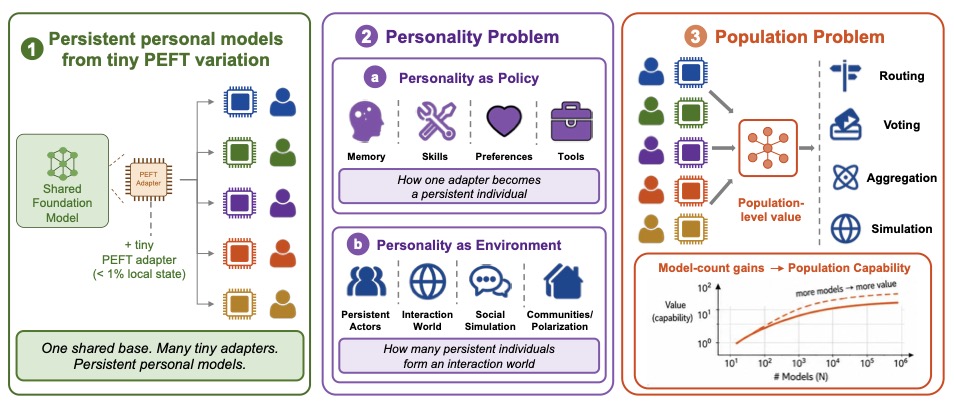
图7:Scale Out 范式总览。差异不是噪声,差异是资源。
🏗️ MinT 基础设施:让"持久人格"成为系统对象
光有算法层证据还不够。一个适配器要真的成为持久人格,它得有:身份(policy record)、版本(adapter revision)、移动(adapter-only handoff)、驻留控制(catalog → CPU cache → GPU batch 三层)。论文给了一套叫 MinT 的基础设施作为示范实现。
我把核心的几个数字列一下,让你感觉一下"工程上这玩意儿能跑多大":
| 指标 | 实测 |
|---|---|
| Catalog 规模 | 10⁶ 条适配器版本 |
| GPU 批同时活跃适配器 | 64 个不同 adapter / 一个 30B rank-1 服务 actor |
| CPU cache 容量 | 数百 adapters |
| Adapter 大小(Qwen3-30B, rank-16) | 1.692 GB(合并后 full ckpt 是 61.084 GB) |
| Cold-load 时间(packed) | 中位数 < 0.2s |
| Two-phase readiness | 老用户 TTFT p95 9.63s(无 readiness 时 24.03s) |
最关键的设计是把"adapter handoff"从"全量 checkpoint 复制"换成"adapter-only 传递"——训练侧把 LoRA tensor + 路由元信息 + 张量布局打包成一个 revision,推理侧已经常驻 base、只 load adapter。这是 Scale Down 在系统层的延伸:减小可训练状态只在配套的传递与服务也是 adapter-only 时才有意义,否则你训练时省了 60GB,部署时还是要复制 60GB 的 base model。
Two-phase readiness 这个细节我觉得也挺工业级的——新 adapter 注册后先预热再对用户可见,避免冷启动把已经在用的老用户卡住。在大规模多租户 LoRA 服务场景下,没有这层控制,每次扩容都会搅乱已有流量。
🤔 我的判断
这篇论文最打动我的地方,是它把零散的 PEFT 研究第一次拧成了一条主线。
LoRA 出来好几年了,相关工作很多但很碎——有人专攻 rank 选择,有人做奇异值分解初始化,有人做 multi-LoRA 服务,有人做 LoRA 当记忆,有人做投票聚合。每个方向单独看都有价值,但都没把"PEFT 应该是什么"讲清楚。
Mind Lab 这篇 paper 的贡献是给出了一个叙事:PEFT 不是省钱的微调,PEFT 是"持久人格的物质基础"。然后用三轴框架把所有相关工作收编进来,每条轴上配上自己实测的硬证据(1T 规模 LoRA RL、OLoRA-tail、容量律、200-model 投票、MinT),形成一个相对完整的论证。
会让我皱眉的地方也有几个:
- "million personal models of trillion parameters"这个口号有点过载。论文最后一句也承认了——这不是说每个用户拥有自己的 1T checkpoint,而是说千万 adapter 共享一个 1T base。但标题这么写,第一眼真的会让人误解。
- OASIS 实验只跑了一个社区、一种推荐器、每个 cell 一个 seed——这个证据强度对"per-user LoRA 改变社会模拟拓扑"这种大结论是不够的。论文也明确写了"this should be read as evidence for a scale-out regime rather than a universal social-simulation law",这点诚实,但放在论文里给读者的印象还是会偏强。
- OLoRA-tail 和 MiLoRA 的本质区别只是"去掉奇异值缩放"——这个改动的智识贡献是有限的,但实测效果确实好。我会更倾向于把它当成一个工程经验而不是理论突破。
- Context Learning 和 Context Distillation 在自蒸馏文献里有先例(论文也引了),这部分的新意主要在"把它定位成 personal model 的 write policy"这个框架,而不是技术本身。
但抛开这些细节,论文的整体方向我是认的——未来一两年,"个性化 + 持久状态 + 群体智能"会成为 Agent/Assistant 类产品的核心赛道,而 PEFT 是这个赛道最自然的实现物质基础。如果你在做这个方向的工程或研究,这篇 position paper 至少能帮你把认知拉到一个相对统一的框架里。
工程落地的几个直接启发
如果你在做相关方向,下面几条可以直接拿去试:
- LoRA RL 微调:把初始化换成 OLoRA-tail(用最小奇异向量、不带奇异值缩放)。低成本,低 KL 漂移,rank-1 都能稳。
- Rank 选择:默认 16-32,预算紧 R\&D 阶段可以扫到 1-4 但要做 6+ seed 的可靠性测试,不要无脑往 64+ 走。
- MoE + RL:警惕 TIM。把 rollout 时的路由信息存下来,训练时回放(R3 思路)。否则 KL 会无解地飘。
- LoRA 记忆设计:MLP-only 训,容量按 \(10^{-3}\) tokens / 可训参数 估上限。超过容量就分多个 adapter,不要硬塞。
- 多模型聚合:同一个 base 训不同 data 排列的 LoRA,多数表决比单模型多采样划算得多。
accuracy ≈ a + b·ln(k)是个能拟合的对数律。 - LoRA 服务:catalog → CPU cache → GPU batch 三层分离,readiness 必须做 two-phase 否则老用户会被冷启动卡死。
最后一句感想:LoRA 这件事可能比我们以为的更像生物学。一份基因组(base model)+ 0.5% 的差异(adapter)+ 几十亿持久个体(population)——这个类比在论文开头看起来像营销话术,看完之后我觉得它至少有一半是真的。
📚 参考文献
- 论文原文:arXiv:2606.02437 — On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
- 相关前置工作:LoRA (Hu et al., 2021)、PiSSA (Meng et al., 2025)、MiLoRA (Wang et al., 2025)、DeepSeek-R1 (DeepSeek, 2025)、S-LoRA (Sheng et al., 2023)、OASIS (2024)、Generative Agents (Park et al., 2023)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我