观测掩码不是免费午餐:搜索智能体的 Regime Map 与机制拆解
核心摘要
聊一篇视角很特别的论文,主题是 long-horizon 搜索智能体的"观测掩码"(Observation Masking, 下文简称 CM, Context Management)到底什么时候有用、什么时候反而会伤害模型。
过去半年很多团队都在做 deep research / browse 类 agent,跑长任务的时候有一个共同痛点:context 越积越长,旧的网页正文挤占预算,模型注意力被稀释,rollout 还经常超 token 限制。社区流行的应对手段就是 CM——把不再需要的旧 observation 替换成 placeholder(比如 [OMITTED]),保留 reasoning 和 tool call 结构。这种做法在 multi-turn benchmark 上经常能看到 +10 个点级别的提升,似乎是一个"白送"的优化。
但这篇论文(arXiv ID 2606.00408)做了一件更冷静的事——它把 CM 放在不同模型 × 不同 retriever 的 17 个组合里系统对照,然后画出了一张倒 U 型的 Regime Map:
- Regime 1(Retriever bottleneck plateau):弱 retriever 配中等模型,CM 稳定 +6~7 个点;
- Regime 2(CM sweet spot):中等模型配强 retriever,CM 最大收益 +11.7 pts(Qwen3.5-35B-A3B + AgentIR);
- Regime 3(Model-saturated collapse):强模型配强 retriever,CM 收益跌到 ≤ 0,比如 Tongyi-DeepResearch-30B-A3B 直接 −1.1 pts。
更进一步,作者用 attention map、open-cursor 行为分布、ablation 把"为什么会塌"讲清楚了:当模型已经掌握了 anchor & verify 这种不依赖 observation 全文的工作模式时,把 observation 抹掉省不下什么注意力,反而会伤害那些罕见但关键的 long-tail 步骤。
我的判断:这是过去一段时间我读到的少数几篇真正具有"工程指导意义"的 agent 评测论文,它告诉你 CM 不是要不要做的问题,而是判断你的"模型 × retriever"组合落在哪个 regime 上的问题。
论文信息
- 标题:Masking Stale Observations Helps Search Agents — Until It Doesn't: A Regime Map and Its Mechanism
- 作者:Haoxiang Zhang、Qixin Xu、Zhuofeng Li、Lei Zhang、Pengcheng Jiang、Yu Zhang、Julian McAuley
- arXiv:2606.00408(2026 年 5 月 29 日提交)
一、为什么要研究"观测掩码到底什么时候有用"
先讲讲我读到这篇论文时的第一反应。
CM 这件事在社区里其实是默认正确的。OpenManus、AgentLab、Browser Gym 这些框架默认都会做某种形式的 truncation 或 masking,理由也很直观:
- 网页正文太长,tokens 会爆。
- 旧 observation 大多数是噪声——比如你为了找一个人名,先打开了 Wikipedia 的目录页,最后只用了一个搜索片段,目录页就成了死代码。
- Attention 是 quadratic 的,越短越快。
所以"把旧 observation 抹掉、保留 reasoning"看起来是免费的、单调向好的。
但 long-horizon 搜索任务里,这种直觉会被一个矛盾打破——很多时候 agent 是要在第 30 步回头查第 5 步的 observation 的,比如要做表格交叉对照、要 verify 一个事实。如果你早早把那个观测 mask 掉,agent 只能依赖自己 reasoning 中残留的"记忆",而 reasoning 本身往往是高度概括的、丢失了细节的。
这篇论文的提问就是:究竟在什么条件下 CM 是净收益的?什么时候它在偷偷扣分?
为了讲清楚,作者跑了一个我个人觉得相当扎实的实验矩阵——5 个开源/闭源模型族 × 3 个 retriever × 4 个 benchmark,覆盖 BrowseComp-Plus(offline,可控语料)+ GAIA / xBench-DeepSearch / BrowseComp-ZH(live web,真实网页)。
二、方法核心:可控的 Page Pool + 一行公式的 CM
先把术语对齐。论文里的 CM 不是大刀阔斧的 context compression(如 summarization),而是非常克制的——只把 stale 的 tool observation 替换成占位符,reasoning 和 tool-call 结构一字不动。这就让你能干净地比较"masking 这一个 intervention 本身"的影响。
2.1 一行掩码公式
论文给的形式化定义大致是这样的(我用中文复述):
设第 \(i\) 步的 trajectory 元素为 (reasoning \(r_i\), tool call \(a_i\), observation \(o_i\)),CM 用一个 mask 函数 \(m_i\) 把 \(o_i\) 替换为占位符 \(\tilde{o}\):
其中 \(T\) 是当前步数,\(K\) 是 retention window(实验默认 5)。也就是只保留最近 5 个 observation 的原文,更早的全部替换成 [OMITTED]。
这看起来太简单了——但关键在于实验设计的对照感:reasoning 不动、tool call 不动、\(K\) 固定,就是为了把"observation 抹掉"这个变量隔离出来。
2.2 与 context 解耦的 page pool
如果只是 mask 旧 observation,agent 怎么回头查?论文给了一个我觉得设计得挺巧妙的工具集:
search(query)→ 返回 hit list(标题 + 短摘要)open(cursor, page_id)→ 把整页正文塞进 contextfind(cursor, pattern)→ 在指定页里 grep 关键词
cursor 是这套设计的核心——它是一个与 context 解耦的、agent 可见的页面池索引。哪怕第 5 步的 observation 在 context 里被 mask 掉了,agent 仍然可以通过 open(5) 重新把那一页加载回来。
这就形成了一种很有意思的张力:CM 不是"删除"信息,而是把信息从短期记忆里搬到外部存储。模型如果记得自己开过哪几页、记得 cursor,就还能找回来。
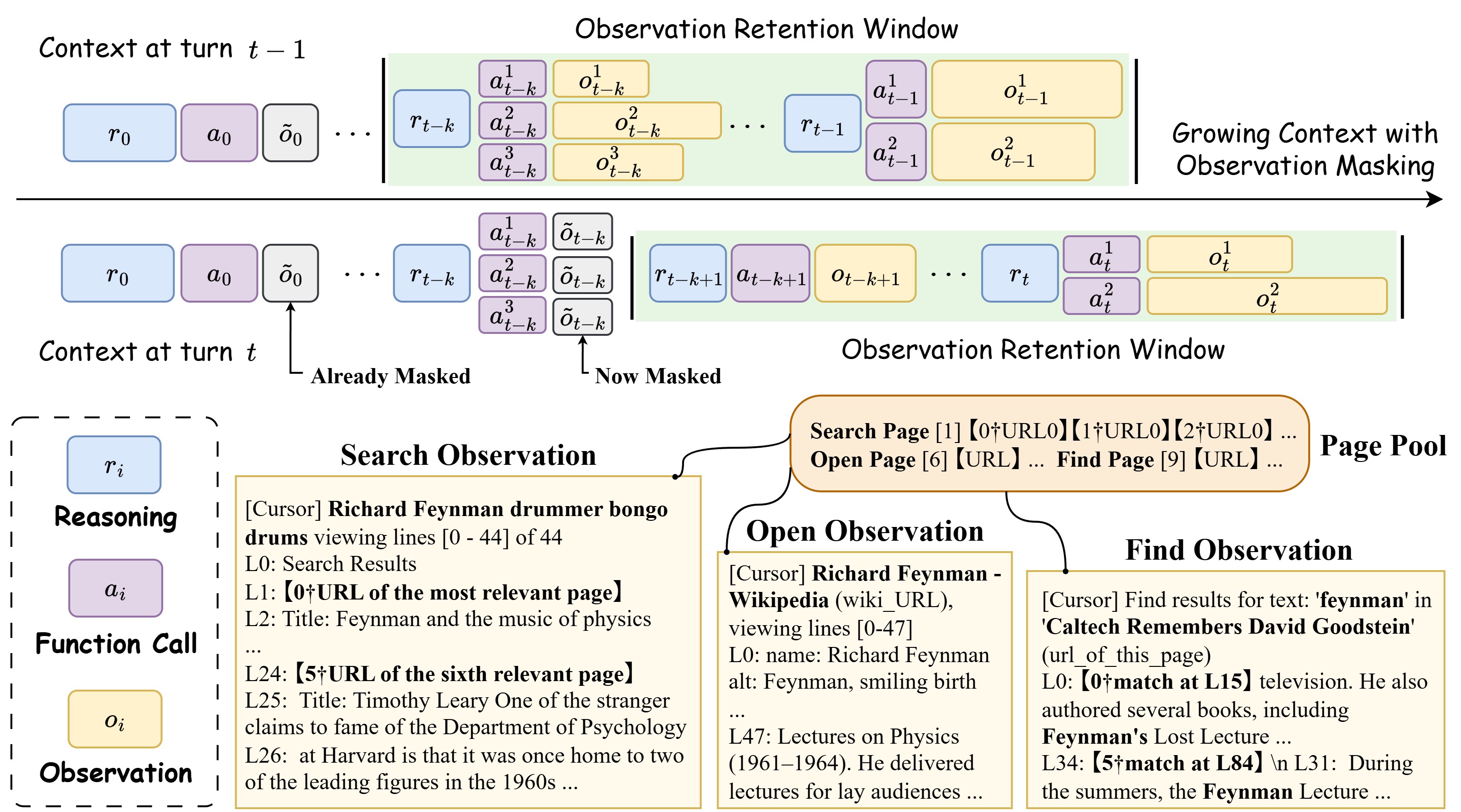
图 1:CM 的工作方式——左侧是普通 trajectory,所有 observation 累积;右侧是开启 CM 后,旧 observation 被替换成 placeholder \(\tilde{o}\),但底层的 page pool 不动,cursor 还在。
三、三段式 Regime Map:CM 收益的非对称倒 U
论文最有价值的一张图,就是下面这张 teaser。横轴是 "no-CM 准确率"(也就是模型 × retriever 组合的内在能力),纵轴是 "CM 带来的相对收益"。
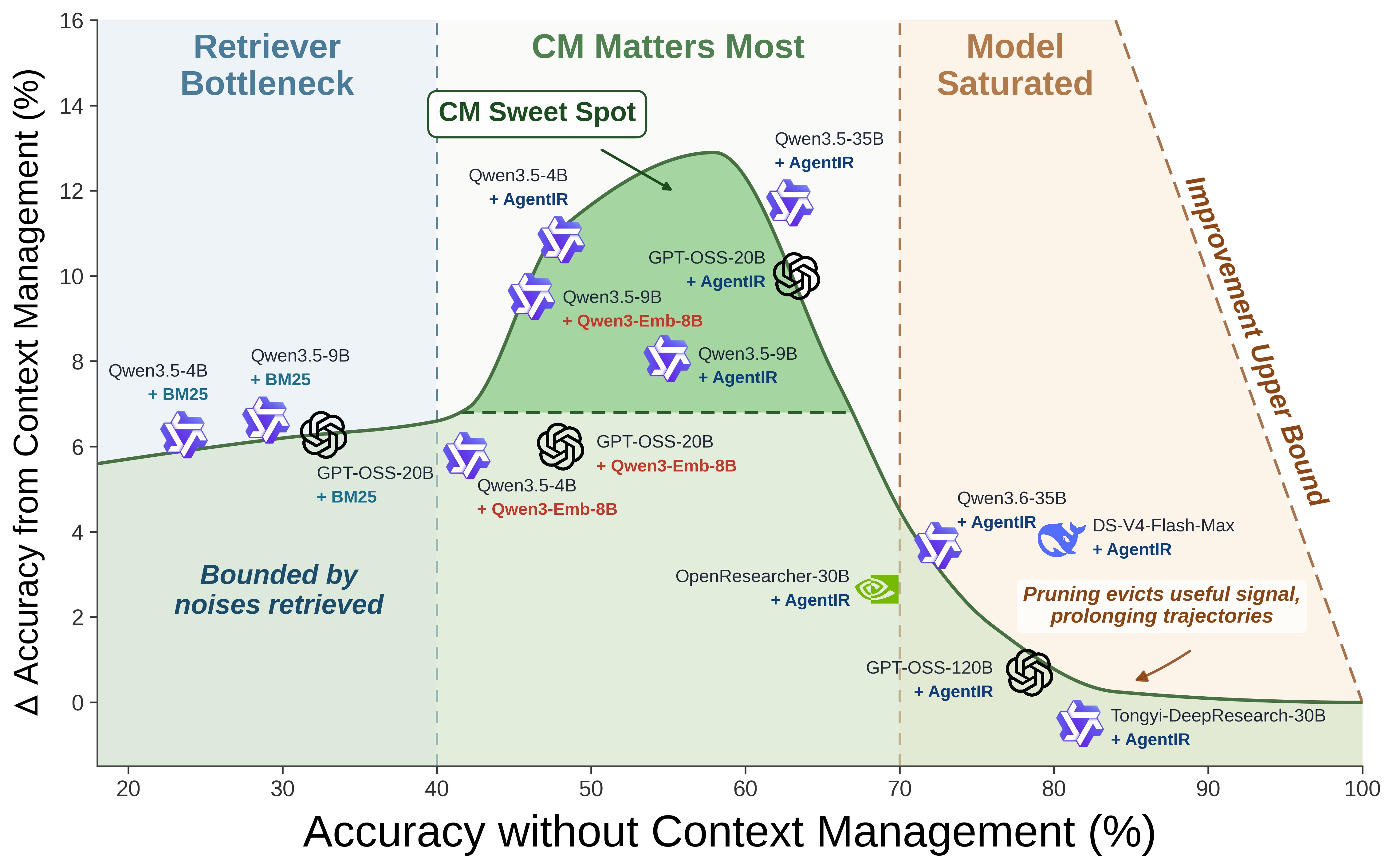
图 2:把 17 个 (model, retriever) 组合在 BrowseComp-Plus 上的成绩点出来,得到的非对称倒 U 曲线。
我把三个 regime 分开讲一下——
3.1 Regime 1:Retriever bottleneck plateau(+6~7 pts)
最左端是配 BM25 这种弱 retriever 的组合。这时候 agent 的能力被 retriever 卡死,no-CM 准确率天花板就在那里。CM 在这里有一个稳定的 +6~7 pts 收益,原因相对单纯——reasoning 长度变短了,token 预算更够,retry / refine 的 turn 数变多了。
注意,这里的 +6 不是"模型变聪明了",而是 CM 让 agent 用 token-for-turn 的方式换到了更多次重试机会。论文后面的 trade-off 分析会明确指出这一点。
3.2 Regime 2:CM sweet spot(+11.7 pts)
中间这一段是 CM 真正发光的地方。代表是 Qwen3.5-35B-A3B + AgentIR-4B,从 18.6% 涨到 30.3%,+11.7 pts。
为什么是这里?我的理解是这样的—— - retriever 已经够强(AgentIR 是专为 agentic search 训的),能把相关页面捞出来; - 模型本身能力中等,注意力还会被冗长的 stale observation 稀释——你一个 35B 但 active 3B 的 MoE,每步只用 3B 参数算 attention,长 context 的代价是看得见的; - CM 把噪声压下去,关键 reasoning step 的 attention 反而集中了,下游决策更准。
这是教科书级别的"信噪比改善"。
3.3 Regime 3:Model-saturated collapse(≤ 0 pts)
最右端是被强模型 + 强 retriever "饱和"的组合。代表案例:
- Tongyi-DeepResearch-30B-A3B:CM −1.1 pts
- DeepSeek-V4-Flash-Max(284B-A13B):CM 收益接近 0
- GPT-OSS-120B 在 GAIA live web:CM −4.8 pts
这是论文最有意思的发现——强到一定程度的模型,反而会被 CM 伤害。
为什么?作者给出的解释我个人很认可:这些模型已经形成了一种 "anchor & verify" 的工作模式——在 reasoning 里就把关键事实 anchor 下来("OK 这个人 1972 年出生"),后面再用 tool 去 verify 而不是依赖原始 observation 全文。换句话说,对它们来说 stale observation 本来就不是主要的认知负担,但偶尔它们仍然需要回头去原文查证一个细节,而 CM 恰好把这个 fallback 切断了。
最有说服力的一个对照是 同尺寸不同模型在不同 regime: - Qwen3.5-35B-A3B:sweet spot,+11.7 - Qwen3.6-35B-A3B:collapse 边缘,几乎打平
这就把"模型大小决定 regime"这个 naive 假设直接证伪了——是模型工作模式(mismatch not size)决定的。
3.4 一组主表数据感受一下
| 模型 | retriever | no-CM | +CM | Δ |
|---|---|---|---|---|
| Qwen3.5-35B-A3B | AgentIR-4B | 18.6 | 30.3 | +11.7 |
| GPT-OSS-20B | AgentIR-4B | 21.0 | 32.2 | +11.2 |
| GPT-OSS-120B | AgentIR-4B | 22.4 | 34.8 | +12.4 |
| Tongyi-DR-30B-A3B | AgentIR-4B | 41.2 | 40.1 | −1.1 |
| DS-V4-Flash-Max-284B | AgentIR-4B | 39.8 | 39.9 | +0.1 |
中等模型挤进 +11/+12 的甜区,最强的两个 native deep research 模型直接转负或贴 0。
四、机制解读:注意力分布与 cursor 双峰行为
论文不只是停在统计现象,作者花了一整章去拆"为什么",这部分是我觉得最值得读的。
4.1 注意力上的 U 型分布
作者对几条典型 trajectory 抽 attention map,统计每一类 token 占总注意力的比例:
- reasoning:53.7%
- tool call:13.2%
- observation:25.6%
- 其他:7.5%
这本身就不太直觉——大家普遍以为长 trajectory 里 observation 占大头,因为它确实占 token 数最多。但 attention 是反过来的:reasoning 和 tool call 加起来吃掉了 67% 的注意力,observation 只有 25%。
更细看,attention 在 trajectory 上的位置分布是典型 U 型——开头(任务说明)和结尾(最近几步)很高,中间塌陷。这就解释了为什么 K=5 的 retention window 看起来够用:模型本来就主要看头和尾,中间被 mask 掉损失不大。
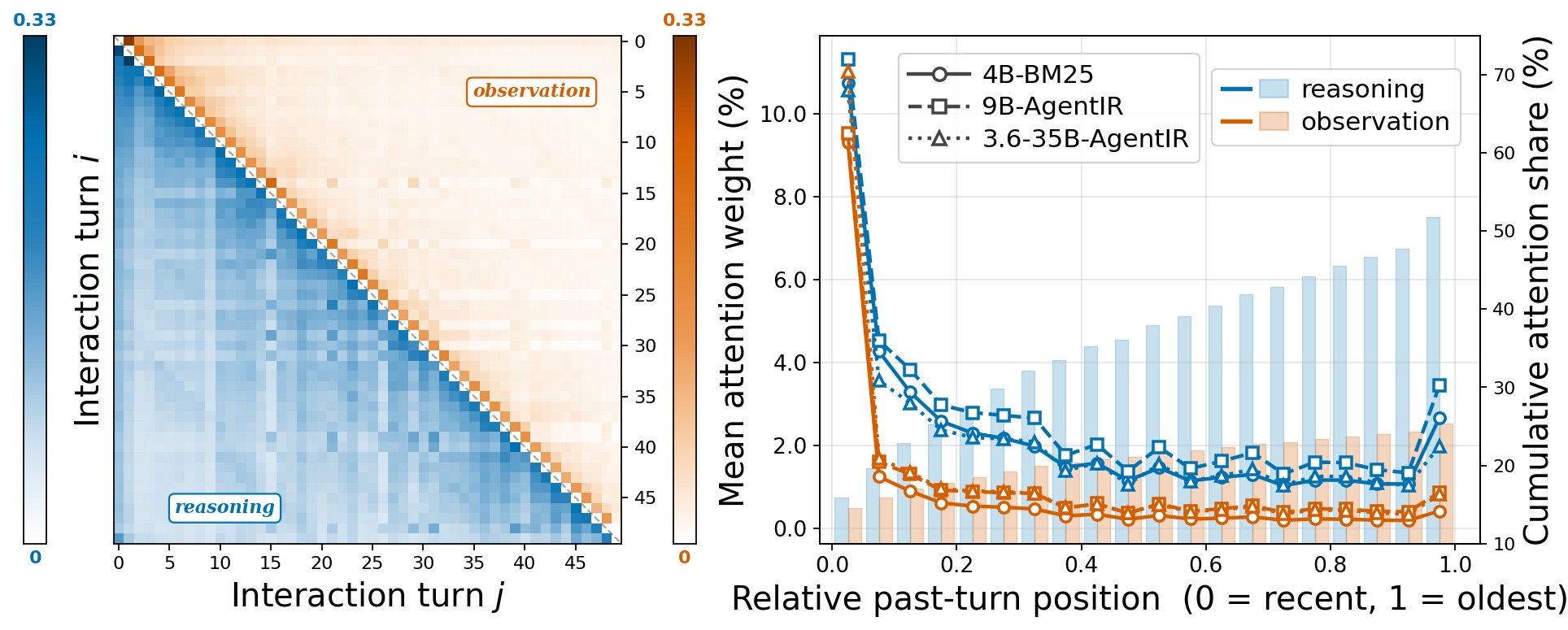
图 3:注意力的 U 型分布。reasoning > observation 是常态,中间步骤的 observation 被 mask 掉对决策几乎无损。
但这也恰好解释了 collapse——当模型已经把注意力打得很集中(reasoning 53.7%),CM 抹掉的 observation 那 25.6% 里有一小部分是真正需要的细节锚点,把它们一刀切掉就成了净损失。
4.2 Open-cursor 的双峰行为
如果 agent 真的需要回头查 observation,它应该会通过 open(cursor) 把页面 reload 回来。作者统计了所有 reopen 操作的 cursor 分布——
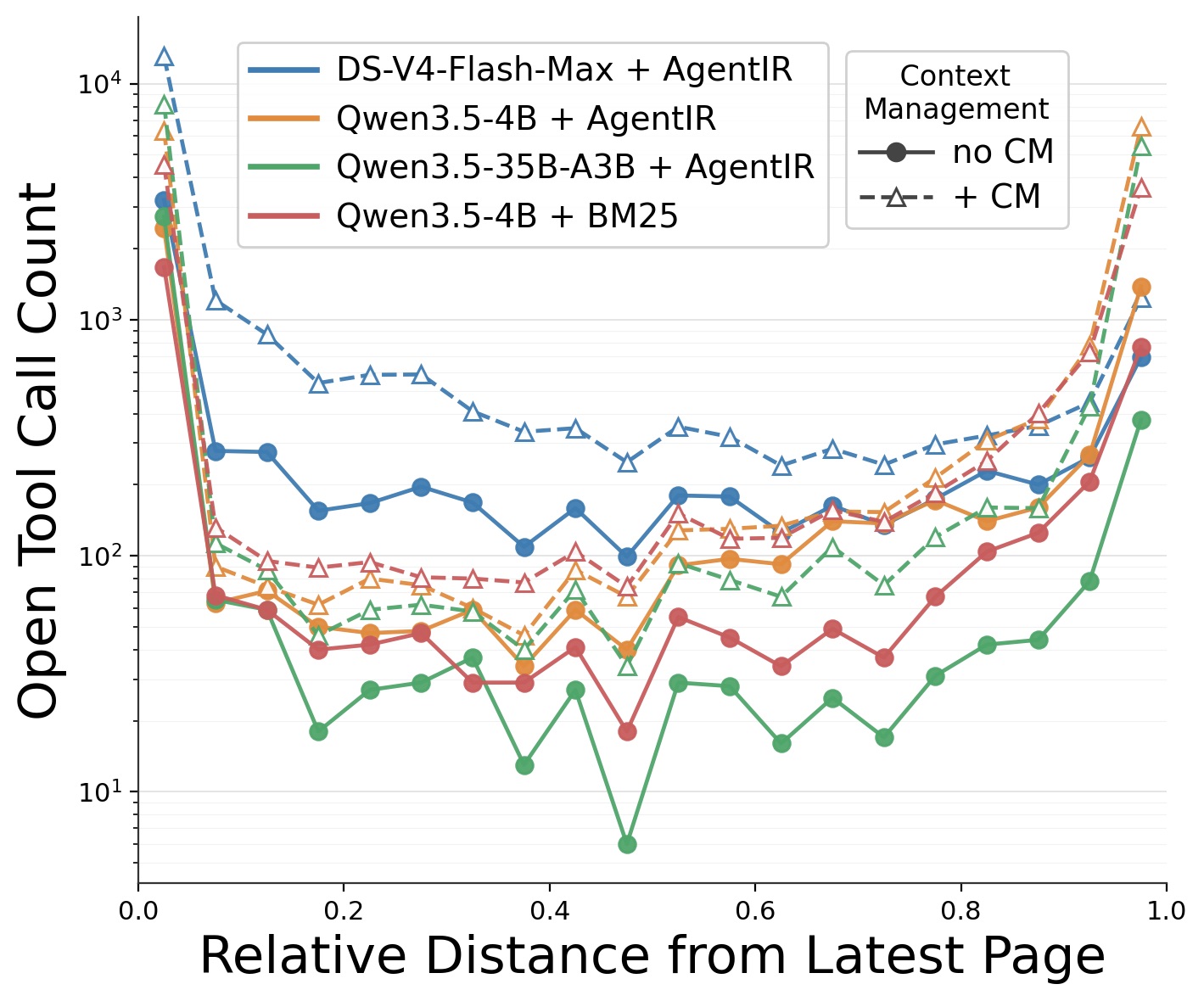
图 4:Open-cursor 双峰——agent 要么 reopen 第一页(任务起点的关键页),要么 reopen 最近几页。中间页几乎不被回访。
这是又一个支撑 K=5 合理性的证据:中间页 mask 掉影响极小,因为 agent 本来就不会回头去查。
4.3 trade-off:CM 在 fix 什么、break 什么
我个人觉得最 honest 的一段分析。作者把每个 (model, retriever) 组合下 CM 的影响分成两类:
- fixes:no-CM 错、+CM 对
- breaks:no-CM 对、+CM 错
然后看 fixes : breaks 比例。
- Qwen3.5-35B-A3B + AgentIR:3 : 1(每修 3 个错,伤 1 个)→ 净正
- GPT-OSS-120B + AgentIR:1 : 1 → 净 0
- Tongyi-DeepResearch + AgentIR:约 1 : 1.3 → 净负
这个比例最直观地说明了 collapse 的本质——CM 的 break 集合在强模型上不容忽视。
4.4 用 no-CM 前缀预测 CM 是否 rescue
这个实验很 nerd 但很漂亮。作者训了一个 Trace-SNR regression probe——用 no-CM 前缀(前 N 个 token)的特征预测 CM 是否能 rescue 这条 trajectory。
结果:
- GPT-OSS-120B + AgentIR:AUC 0.74
- DS-V4-Flash-Max + AgentIR:AUC 0.80
也就是说,只看 trajectory 前缀的 SNR(reasoning vs observation 的注意力比)就能 70~80% 准确率预测 CM 会不会有用。这个发现有很强的工程含义——你可以做 dynamic CM,让 agent 在 trajectory 早期就决策"这次要不要 mask"。
五、Live web 上 collapse 被放大
如果说 BCP-Plus(offline,固定语料)上 collapse 还不算夸张,那 live web 上就触目惊心了。
| 模型 | benchmark | no-CM | +CM | Δ |
|---|---|---|---|---|
| GPT-OSS-120B | GAIA | 36.4 | 31.6 | −4.8 |
| Tongyi-DR | xBench-DeepSearch | 51.5 | 48.0 | −3.5 |
| OpenResearcher-30B | BrowseComp-ZH | 34.8 | 33.7 | −1.1 |
为什么 live web 把 collapse 放大?我的解读:live web 上单页噪声比 offline 高很多(广告、导航、cookie 提示),强模型本来就在做 "噪声中提炼信号" 的工作,而 CM 把这种"在长 observation 里慢慢沉淀"的过程一刀切了。
图 5:Scaffold 的可靠性曲线。Reliability 不是恒正——它随模型规模和环境(offline vs live web)抖动。
六、Ablation:error retention 和 blurred title
作者还做了两个我觉得设计很贴心的 ablation:
- Error retention:如果只 mask 成功的 observation、保留报错的 observation,CM 收益会从 18.6 → 22.6(+4 pts),说明错误信号对 self-correction 有用。
- Blurred title:把页面标题 mask 掉但保留正文,CM 收益从 26.2 → 20.8(−5.4 pts),说明标题是非常 cheap 但高 ROI 的 anchor,别 mask 标题。
这两个 ablation 翻译成工程语言就是:做 CM 的时候保留 error trace、保留 page title,单独 mask 正文。这是一条相当落地的 rule of thumb。
七、我的几点判断
读完通篇我有几个挺直接的 takeaway:
1. 别再把 CM 当 "always-on" 的优化。 它是 regime-dependent 的。判断你落在哪个 regime 的方法很简单——跑一下 no-CM 基线,看准确率落在哪个区间,再决定要不要开 CM。如果你是在用 Tongyi-DR 这种 native deep research 模型,CM 默认应该关。
2. K=5 retention window 的合理性是被注意力 U 型 + open-cursor 双峰共同支撑的。 你 fork 这套设计的时候不需要试 K=10、K=20,K=5 已经够。
3. Trade-off 不在 token 预算,在 turn 预算。 CM 是用更短的 context 换更多的 turns。所以如果你的任务本身 turn 上限被 cap 死了(比如 20 步内必须出答案),CM 的收益会大打折扣。
4. 最有工程价值的两条具体规则:mask observation 时保留 page title;保留 error/exception observation 不要 mask。这两条只需要十几行代码就能落地,能在 sweet spot regime 上多榨 5~10 个点。
5. Trace-SNR probe 是一个被低估的研究方向。 用前缀预测 CM 是否 rescue 当前 trajectory,AUC 0.74~0.80。这意味着 dynamic CM(让 agent 自己决定每条 trajectory 要不要 mask)是可行的。下一篇做 deep research agent 的同行,可以认真考虑把这个 probe 接进 rollout pipeline。
6. 最被忽视的一句话:mismatch not size。 同样是 35B-A3B,Qwen3.5 在 sweet spot、Qwen3.6 在边缘塌陷。别用模型大小判断 regime,用 model × retriever 的具体行为判断。
收尾
这篇 Masking Stale Observations Helps Search Agents — Until It Doesn't(arXiv 2606.00408)我会推荐给两类人:
- 正在搭 deep research / browse agent 的工程师——它能帮你避免把 CM 误当成默认 ON 的优化,以及给出 K=5、保留 title、保留 error 这些极具落地价值的规则;
- 关注 long-horizon agent evaluation 的研究者——它示范了一种很难得的"系统化对照实验 + 机制层面证据 + ablation"的写作组织方式,模型 × retriever × benchmark 矩阵跑得相当扎实。
最大的一个启发是:很多看起来"应该总是有用"的 agent 优化技巧,可能只是落在某个 regime 里有用。下次再看到 "+10 pts via X" 的 paper,第一个反应应该是"在哪个 regime 上 +10?",而不是"这个技巧很厉害"。
完。