Harness-1:把"思考过程"写到外面去——一个 20B 搜索智能体如何打过 Opus 和 GPT-5
arXiv: 2606.02373 | 作者:UIUC、UC Berkeley 与 Chroma 团队
关键词:Search Agent、State-Externalizing Harness、Cognitive Offloading、CISPO RL、Importance-Tagged Curated Set
一句话总结
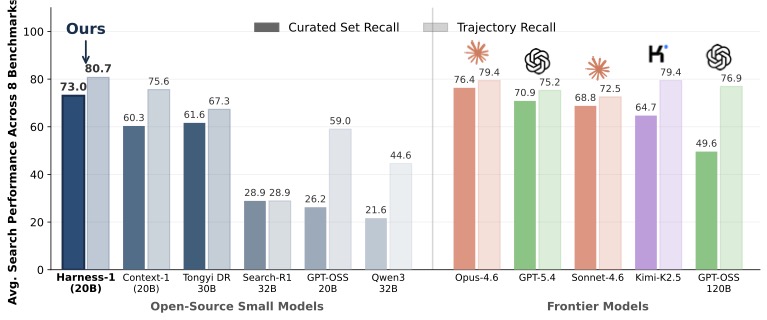
这篇论文做了一件听起来不太"AI"、但效果惊人的事:让一个 20B 的开源模型,把它的工作记忆、证据、搜索意图全都写到 prompt 之外的"外部状态"里去——配上一套精心设计的 RL 训练,最终在 8 个搜索基准上的平均 Curated Recall 拿到 0.730,比次强的开源模型 Tongyi DeepResearch 30B 高 11.4 个点,甚至越过了 Claude Opus-4.6 与 GPT-5.4。
更让人心情复杂的一点是:训练只用了 SEC 这一个领域的 3,453 条 RL query,在没见过的领域(专利、网页、长文档 QA)上的提升幅度是源域的 2.2 倍。
为什么值得读
最近搜索智能体(Search Agent)的研究路线大致分两派:
- 加大模型 + 加大上下文:靠 100B+ 的模型把整段网页塞进 context,硬扛复杂查询。
- 加好工具 + 加好提示:靠 prompt engineering 让小模型多步搜索。
Harness-1 走了一条少有人走的第三条路:承认 LLM 的工作记忆是有限的,与其让它在 context 里反复读自己以前写的东西,不如把状态搬到外部数据结构里,让模型每一步只看"当前最该看的"那点信息。这件事说起来朴素,但做对它需要的工程量和训练设计远比想象中多。本文值得读的地方就在于:它把"认知卸载(cognitive offloading)"这件事真的做成了一个可训练、可复现的 harness,并把每个组件的贡献用消融拆得很清楚。
论文要解决的真问题
搜索类智能体在长任务上几乎都会遇到三个老问题:
- Context 越塞越长,越长越糊。多轮搜索后,prompt 里堆满了过期的搜索结果、重复的中间想法和已经被否决的假设,模型很容易在自己的"上文垃圾"里迷路。
- 证据散落,无法回看。模型早期看到的关键句子,到了第 30 轮可能已经被挤出 context window,再也用不上。
- 训练目标和实际行为脱节。RL 直接拿"最终答对/答错"做奖励,会让模型学会"赌一把",而不是真的在搜集证据。
Harness-1 的做法是让模型 每一步都在维护一个外部 state:包括分层的工作记忆、一张证据图、一份带"重要性标签"的策划集合,以及一些专门用来精炼这堆状态的工具调用。模型每次只看自己当下需要的那一小块,剩下的全部由 harness 帮它管。
方法:状态外部化的 Harness 长什么样
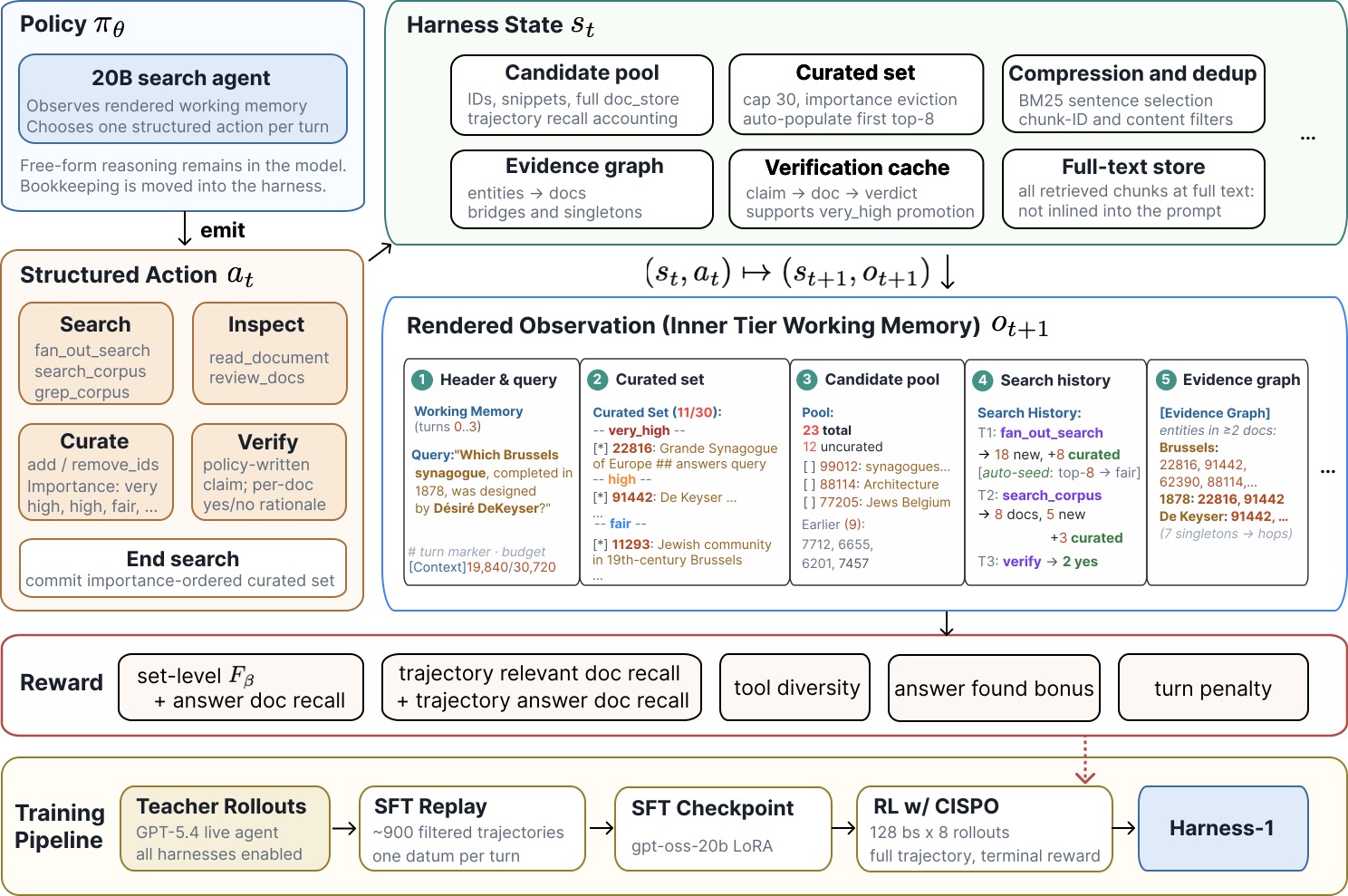
三个外部数据结构
整个 harness 的核心是三类外部状态,每一类都对应"人在做研究时会做的某件事":
| 外部状态 | 作用 | 直观类比 |
|---|---|---|
| Working Memory(两层工作记忆) | 顶层放当前研究目标和已确认结论,下层放当前最相关的几条工作笔记 | 桌面上的那张 A4 纸 |
| Evidence Graph(证据图) | 节点是 claim/document/snippet,边记录"支持/否定/补充" | 你画的那张证据关系图 |
| Importance-Tagged Curated Set | 一个带 very_high / high / fair / low 四档标签的策划集合,上限 M=30 条 | 你手边按重要性排序的那一摞资料 |
最关键的是,模型不会一次性看到所有这些。每一步它能看到的只有:当前 working memory + 最近一次搜索的 top-k + curated set 里被标为 very_high / high 的若干条。其他全部隐藏在 harness 内部,需要时再调工具去取。
八个工具,分工很细
工具集本身并不花哨,但分工足够细:
fan_out_search:发散查询,一次发出多条互补 querysearch_corpus/grep_corpus:在已下载语料里做语义检索 / 字面 grep(这两步是 retrieval 的双轨)read_document:把整篇文档调进来精读curate:把刚读到的内容写进 curated set,并打very_high / high / fair / low标签verify:触发对某条 claim 的反向核验review_docs:周期性回看 curated set 做去重和重排序
值得一提的是 curate 的标签不是 cosmetic:Sentence-BM25 压缩会按这些标签做差异化的截断(very_high 几乎全保留,low 只留一句话摘要),保证后续轮次进 context 的就是真正高价值的内容。
Auto-seed:第一步永远是先撒网
模型每个新任务的第一动作都被强制设为 auto-seed:在不依赖任何模型推理的情况下,由 harness 自动用问题本身生成 k=8 条 fan-out 查询,把语料先粗扫一遍。这一步看起来"不智能",但消融显示它单独贡献了约 1.6 点 recall——好的探索起点比好的推理还重要。
训练:CISPO RL 加四份奖励
训练分两段:
- SFT:用 899 条由更强模型生成、再人工筛过的高质量轨迹做 LoRA(rank=32, 3 epochs),到 step-550 切换 RL。
- CISPO RL(on-policy + within-group advantage normalization):只用 SEC 一个领域的 3,453 条 query,跑在 Tinker 训练框架上。
奖励函数同时管四件事:
- \(F_\beta\) 取 \(\beta=2\),偏向 recall 而不是 precision——这是搜索任务的核心 inductive bias。
trajectory recall单独评估"过程中是否真的看见过黄金证据",避免模型靠运气押对答案。answer evidence要求最终答案必须能从 curated set 中索引出来,断了"凭印象答题"的路。diversity bonus鼓励 fan_out 的多条 query 互不冗余。turn penalty防止无意义地多调工具刷奖励。
整个训练规模其实很克制:899 SFT + 3,453 RL = 4,352 项,硬件预算并不可怕。
实验:8 基准、跨域转移、消融
主结果:20B 打过 Opus 和 GPT-5
8 个基准覆盖了搜索智能体最常被刁难的几种场景:
- 同源:BrowseComp+ (BC+)、Web、Patents、SEC
- 跨源:LongSealQA、Seal0QA、FRAMES、HotpotQA
| 模型 | 平均 Curated Recall | 平均 FA Recall | 备注 |
|---|---|---|---|
| Harness-1(20B) | 0.730 | 0.612 | 本工作 |
| Tongyi DeepResearch(30B) | 0.616 | 0.527 | 次强开源 |
| Search-R1 | 0.512 | 0.433 | 同期 RL baseline |
| Qwen3-235B | 0.587 | 0.488 | 大模型 baseline |
| GPT-OSS-120B | 0.601 | 0.502 | 6× 参数量 |
| Claude Opus-4.6 | 0.681 | 0.571 | 闭源大模型 |
| GPT-5.4 | 0.708 | 0.595 | 闭源旗舰 |
| Sonnet-4.6 | 0.652 | 0.541 | 闭源中端 |
| Kimi-K2.5 | 0.643 | 0.530 | 闭源 |
11.4 点的开源差距、超过 GPT-5.4 的 2.2 点——这两个数字基本说明了 harness 设计 + 任务定向 RL 的组合拳能把 20B 打出多远。
跨域泛化:训练在 SEC,提升却落在专利和长文档上
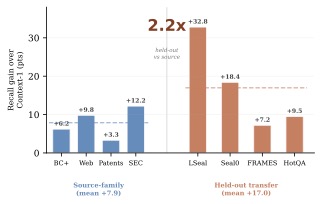
这张图是论文最有意思的发现之一:
- Source-family(与 SEC 同源的金融类):相对 SFT baseline 提升 +7.9 点
- Held-out(专利、Web、LongSealQA、Seal0QA、FRAMES):提升 +17.0 点
转移收益是源域的 2.2 倍。作者的解释是:在源域上模型已经接近上限,进一步的提升空间小;而 RL 真正学到的是"如何使用 harness"这一通用 skill,因此对没见过的领域帮助更大。这与目前主流"为每个领域单独 RL"的做法形成鲜明对比——只要训练任务足够 harness-intensive,单域训练就能学到跨域的检索习惯。
消融:每个组件值多少分
七项关键消融(数字为相对于完整 Harness-1 的 Curated Recall / FA Recall 下降):
| 移除组件 | Δ Curated Recall | Δ FA Recall | 解读 |
|---|---|---|---|
| Importance tags | -3.8 | -2.1 | 没有重要性分级,压缩就开始误伤 |
| Sentence-BM25 压缩 | -2.4 | -1.5 | curated set 直接全文进 context,长上下文淹没关键信息 |
| Auto-seed | -1.6 | -0.9 | 起步靠模型自己想 query,覆盖面骤降 |
| Evidence graph | -1.1 | -0.8 | claim 之间的关系丢了,verify 找不到回路 |
| Verify 工具 | -1.4 | -1.1 | 没有反向核验,幻觉答案变多 |
| Review_docs | -0.9 | -0.7 | curated set 内部冗余累积 |
| Content dedup(两级去重) | -1.0 | -0.6 | 同一段事实在多文档间被重复 curated |
| 全部移除 | -12.2 | -6.4 | 基本回到一个普通工具调用 baseline |
最有"人味"的两个发现:
importance tags是单点贡献最大的设计,远超花哨的 evidence graph。这说明:把"重要性"的判断从"谁压缩谁"前置到"谁 curate 谁",才是真正影响信息密度的关键。- 去掉所有结构后,模型整体掉 12.2 点,但 final answer recall 只掉 6.4 点——也就是说,harness 的一半功劳是在帮模型搜得更准、而不是答得更准,这恰好是搜索智能体最容易被忽略的那一半。
训练动态:先学走路再学跑步
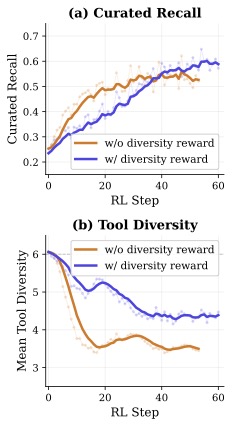
训练曲线展示了几个值得注意的现象:
- SFT 阶段在 step-550 被切走,并不是越多越好——再练下去 RL 反而被 SFT 的 mode 锁住,泛化掉点。
- CISPO 的 within-group advantage normalization 让奖励信号稳定得多,turn 数曲线在 RL 中后期开始下降而 recall 还在涨——模型学会了"用更少轮次干同样的事"。
- diversity bonus 是 RL 早期的主要驱动力:前 200 步的提升大多来自 fan_out 多样性的提升,后期才轮到 curated recall。
数据规模:4,352 项就够了
作者扫描了 SFT 与 RL 数据规模的影响:
- SFT 在 ~600 条以后边际收益几乎消失——超出会过拟合 harness 的 surface form。
- RL 在 ~3,000 条以后收益放缓,但还在继续涨;论文取 3,453 是带预算约束的折中。
- 这意味着复现门槛比人们想象的低很多:只要 harness 设计正确,数据可以非常少。
一些值得多停留两秒的细节
- β=2 的 F-score:这是把 recall 偏置写进奖励函数的最直接方式,比"调权重"清楚得多。任何把 LLM 当 retriever 用的人都该考虑。
- 40-turn cap:长任务里硬截到 40 轮,强迫模型在每轮都要"为后面的回合留余地"。
- curate 后再压缩:很多工作顺序反过来——先压缩再 curate,结果重要内容已经在压缩里被截断了。Harness-1 的顺序意味着重要性判断永远在最长的上文窗口里完成。
- on-policy CISPO:相比 off-policy 的 PPO 变体,CISPO 在多工具长轨迹场景下方差更小。
局限与可能的下一步
作者自己点了几条:
- 闭源 baseline 的工具集不完全可控,对比可能略有不公(比如 Claude 的 web tool 与本工作的语料不在一个口径)。
- harness 本身仍是手工设计,多个数据结构、阈值、压缩规则需要调优。一个自然的延伸是让 harness 自己也变成可学习对象。
- 奖励函数的 4 个权重靠 grid search 定出来,对新领域可能要重调。
- Auto-seed 的 k=8 是经验值,对小语料可能浪费 budget。
我会再补一个:本文使用的语料 indexer 是论文假设的"理想 retriever",真实搜索引擎的噪声、payment、cloak 等问题还没在 harness 内部被建模。这是搜索智能体走向生产的最后一公里,但本文显然没有在这一英里内多走。
复现要点(如果你想动手)
- 基础模型:gpt-oss-20b,LoRA rank=32
- SFT 数据:899 条经过筛选的多步搜索轨迹(论文附带)
- RL 数据:SEC 3,453 条 query
- 训练框架:Tinker(CISPO + within-group advantage)
- 关键超参:F_β with β=2、40-turn cap、auto-seed k=8、curated 上限 M=30
- 建议起跑顺序:SFT 跑到 step-550 的 checkpoint → 切 RL,不要等 SFT 完全收敛
- 算力门槛:作者团队规模并不大,4,352 项的训练规模意味着这是一个学术实验室能复现的体量
我的判断
这是 2026 年到目前为止读到最"工程美感"的一篇搜索智能体论文。它没有发明新的 RL 算法,也没有用更大的模型,但把"如何让 LLM 不在自己写的字里溺水"这个老问题做了非常结构化的回答。
如果未来有谁在做长任务智能体(搜索、研究、代码),Harness-1 提出的"重要性标签 + 外部状态 + 任务导向 RL"组合值得当作起手式。它的最大启示不是任何一个具体的工具,而是这句话:
给 LLM 配一个真正像人一样会做笔记、整理、回看的"外部记忆",比把它的 context window 拉得更长,要划算得多。
论文信息:arXiv: 2606.02373,UIUC + UC Berkeley + Chroma;模型 weights 与训练代码作者承诺开源。