25% 的 Agent 技能其实在帮倒忙:一篇把"技能生命周期"拆到底的系统研究
核心摘要
最近一两年,"让 Agent 自己抽自己的技能(skill)"几乎成了刚需——Claude Skills、Codex 的 AGENT.md、各种 Trace2Skill 类工作,都在围绕同一件事打转:把跑过的 trajectory 蒸成一段可复用的程序性知识,下次遇到同领域任务直接挂上当系统提示用。听起来挺美。问题是,这些自动抽出来的技能到底有没有用?什么时候有用?为什么有时候反而把模型带歪?
这篇 5 月底放出来的微软 + 复旦合作论文 From Raw Experience to Skill Consumption(arXiv 2605.23899),把这个问题拉到了我看过最系统的程度。它把整个生命周期切成三段——经验生成 → 技能抽取 → 技能消费,在 5 个领域、6 个 target 模型、5 个 extractor 模型的全交叉矩阵上跑了一遍,得出了几个反直觉的发现:整体平均涨点不假,但 25% 的格子里技能在帮倒忙;强模型不一定是强抽取器(Gemini-3.1-Flash-Lite 在 Spreadsheet 上当 extractor 比 GPT-5.4 还稳);写得越漂亮的技能越有可能效果更差——LLM judge 在 δ ≥ 5pp 的高差距对里只挑对 15.8% 的次数,是反向预测。最后他们把诊断结论翻译成一个 3 维 rubric 喂回 extractor 当 meta-skill,9 个 cell 全部正向、平均 +1.55pp。这是一篇不告诉你"我提了个新方法 SOTA 了",而是告诉你"这个领域大家可能搞错了什么"的论文,对真在做 Agent 系统的人非常值。
论文信息
- 标题:From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills
- 作者:Zisu Huang, Jingwen Xu, Yifan Yang, Ziyang Gong, Qihao Yang, Muzhao Tian, Xiaohua Wang, Changze Lv, Xuemei Gao, Qi Dai, Bei Liu, Kai Qiu, Xue Yang, Dongdong Chen, Xiaoqing Zheng, Chong Luo(共 16 位)
- 机构:微软 / 微软亚洲研究院(MSRA)+ 复旦大学(一作在 MSRA 实习期间完成)
- arXiv:https://arxiv.org/abs/2605.23899
- 代码与资料:https://aka.ms/SkillLens
- 日期:2026 年 5 月 22 日
为什么要做这件事——一个被工程吃掉的研究空白
先聊聊我自己最近一段时间的感受。
业界这两年对"skill"这个东西的态度,从一开始的"也就是个长 prompt"到现在已经变成"deploy 必备组件"了。Claude Agent Skills、商用 RPA 平台几乎都在卖"我们能从你的执行日志里抽出来一份可复用的工作手册"。学术界这边节奏更快,从 Trace2Skill、CoEvoSkills 到各种 Agentic Memory、Skill Library,方法源源不断。
但有个事其实一直没人系统地回答:这些自动抽出来的技能,真的稳定有效吗?
你去翻现有 benchmark:SkillsBench 用人写的技能,SWE-Skills-Bench 和 Skills-in-the-Wild 直接拿现成 skill 库——这三个都把抽取阶段排除在外了。SkillCraft 倒是做了抽取,但只在 SWE 一个域上看了一下。也就是说,在这篇论文之前,整个研究社区没有一篇工作真的把"经验池怎么影响抽取""不同抽取器抽出来的差别在哪""不同 target 用同一份技能是不是同样受益"这条完整链路一起跑过。
这就是论文要补的洞。它做的不是"我又提了一个新的 skill 抽取算法",而是"我搭了个评测框架,把这个领域里大家凭直觉做的决策,全部用数据测一遍"。从工程视角,我觉得这种工作其实比又一个 SOTA 方法更有价值——它告诉你哪些常识是错的。
评测框架:把生命周期拆成三段
整个研究最关键的设计是这张图:
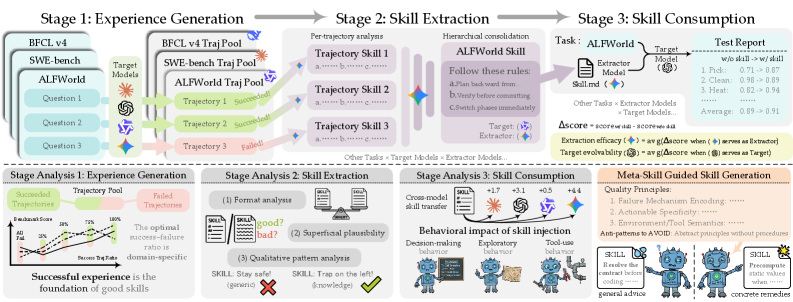
图 1:上半部分定义生命周期——target 模型先生成经验池(Stage 1),再由 extractor 抽成技能(Stage 2),同一个 target 在测试集上消费这份技能(Stage 3);下半部分是论文给每个阶段做的具体分析,最后落到一个"元技能引导生成"的可操作干预上。
三个阶段的形式化(一句话版)
- Stage 1:经验生成。给定领域 \(\mathcal{D}\),target 模型 \(M\) 跑训练划分的任务,留下 trajectory 池 \(\mathcal{T}_{M,\mathcal{D}}\),里面成功和失败的轨迹都有。
- Stage 2:技能抽取。extractor 模型 \(E\)(可以和 \(M\) 不同)把 \(\mathcal{T}_{M,\mathcal{D}}\) 蒸成一份技能 \(\mathcal{S}_{E,M,\mathcal{D}} = E(\mathcal{T}_{M,\mathcal{D}})\)。
- Stage 3:技能消费。同一个 target \(M\) 拿着这份 \(\mathcal{S}\) 去做留出测试集,跟没有技能的 baseline 比 \(\Delta\)。
注意 Stage 3 的关键约束——抽出来的技能只回给原 target 用,这是个 deployment-realistic 的设定:你部署的就是这个模型,技能是你自己跑出来的经验淬炼出来的,又喂给自己。这样把"模型能不能从自己的经验里学到东西"这个问题独立出来,抽取器 \(E\) 是变量,target \(M\) 是常量。
抽取框架:故意做得很简陋
这块我得专门夸一下作者的处理方式。
他们的抽取流水线只有两步:每条 trajectory 单独抽 pattern → 层次合并成最终 skill。没有 sub-agent fleet、没有冲突解决、没有 skill deepening。他们自己说这是从 Trace2Skill 借来高层结构后主动剥掉的。
为什么这么做?因为只有把 pipeline 工程做薄,性能差异才能干净地归因到"extractor 模型本身的能力"上。如果你流水线里塞了一堆启发式过滤、重写、二次校验,那最后涨点是 pipeline 工程的功劳还是模型选型的功劳就分不清了。这个判断是对的。
两个评测指标
- 抽取效能 EE(Extraction Efficacy):固定 target,平均所有 extractor 带来的 \(\Delta\),衡量"这个抽取器有多通用"。
- 目标可演化性 TE(Target Evolvability):固定 extractor 集合,平均某个 target 收到的 \(\Delta\),衡量"这个 target 有多吃技能"。
简单但好用。后面所有的反直觉发现,本质都是这两个指标解耦出来的——当你不再笼统地说"技能有用",而是问"对谁有用、谁抽出来的有用"时,故事就完全不一样了。
主实验:5 个领域 × 6 target × 5 extractor 的大矩阵
评测设置
- 5 个领域:ALFWorld(具身)、SpreadsheetBench(表格生产力)、SWE-bench-Verified(软工)、SEAL-0(Web 搜索 QA)、BFCL-v4 多轮子集(工具调用)。这个域选择很到位——动作空间形态都不一样。
- 6 个 target:GPT-5.4 / GPT-5.4-mini、Gemini-3.1-Pro / 3.1-Flash-Lite、Qwen3.5-35B / 9B。
- 5 个 extractor:上面除了 Qwen3.5-9B(因为它跟不上结构化抽取协议)之外都用。
- 每个 cell 跑 3 次取平均,单位是百分点(pp)。
主结果(Table 1 节选)
为了让你直观感受这个矩阵的丰富度,我挑几行关键数字:
| 领域 | Target | Base | 收益最高的 extractor | TE(平均收益) |
|---|---|---|---|---|
| ALFWorld | GPT-5.4 | 68.66 | Gem-3.1-Pro +7.46 | TE 等于 +4.93 pp |
| ALFWorld | Gem-3.1-Pro | 87.56 | Gem-3.1-Pro 0.00 | -0.15 |
| ALFWorld | Gem-3.1-FL | 51.99 | 5.4-mini -1.24 | TE 等于 -1.59 pp |
| SpreadsheetBench | GPT-5.4 | 37.17 | Gem-3.1-FL +14.66 | TE 等于 +9.66 pp |
| SpreadsheetBench | Qwen3.5-35B | 23.83 | 5.4-mini +5.50 | +1.50 |
| SWE-bench-V | 5.4-mini | 59.73 | Gem-3.1-FL +3.60 | +2.91 |
| SEAL-0 | Gem-3.1-FL | 14.93 | GPT-5.4 +9.45 | TE 等于 +5.32 pp |
| SEAL-0 | 5.4-mini | 45.27 | Gem-3.1-FL +3.98 | -0.50 |
| BFCL-v4 | 5.4-mini | 53.50 | Gem-3.1-Pro +7.56 | TE 等于 +5.15 pp |
三个核心发现(先看结论)
发现一:技能整体有用,但远非"装上就涨"。
整张矩阵 75% 的格子是正的,平均也是正向。但有 25% 的格子是负的——也就是说每四次部署里有一次,技能反而把模型带得更差。而且这个风险强烈跟领域相关:SpreadsheetBench 和 SWE-bench-Verified 各自只有 13% 的负迁移率,ALFWorld 高达 47 个百分点。
为什么 ALFWorld 这么脆弱?我后面会讲,作者在 5.3 节给出的解释是 ALFWorld 的动作词表非常具体(open / take / heat / put 这种),技能写得稍微抽象一点,target 就映射不到实际动作上去,反而被引导跑偏。
发现二:强 executor ≠ 强 extractor。
这是我看到最大的反直觉。在 SpreadsheetBench 这一栏:
- Gemini-3.1-Flash-Lite 当 extractor 时 EE = +5.86(最高)
- GPT-5.4 当 extractor 时 EE = +1.67(垫底)
但 GPT-5.4 自己作为 target 时 baseline 是 37.17,是 6 个 target 里最强的;Flash-Lite 作为 target 时 baseline 才 25.00,是后段。最强的执行者,反而是最差的抽取者。
我第一反应是想去查 Flash-Lite 是不是因为输出更"枯燥"所以 token 密度高、抽出来的技能更可执行。但作者后面用 5.2 节的 format 实验把"格式效应"基本排除了——这事真的是模型层面的能力差别。抽取本身是一个独立于执行的能力维度,跟模型大小、benchmark 强弱、推理能力都不直接挂钩。这条规律对工程选型非常有用:你下次再做 skill pipeline,不要默认拿你最强的模型当 extractor,应该单独 ablate 一遍。
发现三:技能效用是 target 依赖的。
同样一个 ALFWorld 域,GPT-5.4 当 target 时被任何 extractor 抽出来的技能喂都涨(TE = +4.93),但 Gemini-3.1-FL(TE = -1.59)、Qwen3.5-35B(-1.34)、Qwen3.5-9B(-1.69)三个 target 全是负的。同一份技能、同一个领域,不同的消费者得到的价值是反的。
这就解释了为什么"我这套 skill 在客户 A 那里跑得很好,到客户 B 那里就崩了"——不是你 pipeline 的问题,是消费者本身的问题。
RQ1 的发现一句话:模型生成的领域级技能整体平均有用,但 1/4 概率出现负迁移;extractor 的任务能力不预测它的抽取能力;同领域不同 target 的 TE 差距巨大。抽取器和消费者共同决定了技能的真实效用,光看其中一个会得出错误结论。
深挖每一阶段:到底是什么决定了技能的价值
主实验告诉你"差异很大",深入分析告诉你"差异从哪来"。这部分是论文最值钱的地方。
阶段一:经验池里成功多还是失败多更教得动技能?
直觉上这事不应该有悬念吧——成功轨迹是金子,失败是噪音。但作者把成功/失败比例从 0% 拉到 100%,跑了三个域:
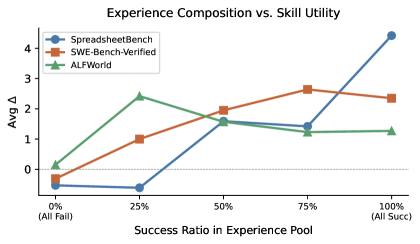
图 2:横轴是经验池里的成功率(0% 全失败 → 100% 全成功),纵轴是抽出来的技能在下游的平均 \(\Delta\)。三条曲线形态完全不一样。
读这张图你会发现:
- SpreadsheetBench:单调上升,越多成功越好,100% 时拿到峰值(约 +4.4pp)。
- SWE-bench-Verified:基本也是涨的,75% 处达到约 +2.6pp,100% 时小幅回落。
- ALFWorld:反过来——25% 处就达到了 +2.4pp 左右的峰值,全是成功反而掉到 +1.3 左右。
最优的成功-失败配比是领域特定的。但有一条共性结论很硬:全失败池在三个域上都最差。失败池能告诉你"哪些路是死的",但你光有边界不知道路在哪——程序性信号(怎么做)比约束性信号(不要做什么)更基础。
ALFWorld 那条曲线我盯了一会,作者的解释挺有说服力:在那种动作离散、很多状态有死角的环境里,失败轨迹会暴露"open 后什么都没拿到"这类无效转换信息,对技能抽取反而比成功轨迹更稀有。这事跟我之前在做模仿学习的时候碰到的情况是相符的——某些领域的失败数据 informational density 是高于成功的。
阶段二:好技能到底"长什么样"?
这一节是论文最反直觉的部分,也是后面 meta-skill 干预的逻辑起点。
子问题 1:格式重要吗?
作者把同一份技能用 4 种格式(有序列表 / 无序列表 / checklist / 散文)重写后再评测。Friedman 检验结果:6 个 target 里 6 个的 p 值都大于 0.34,格式影响不显著。但同样的检验换成 extractor 维度,5/6 的 p 值小于 0.01。也就是说变化来自技能说了什么这件事,跟它长什么样无关。
这个结论挺干净的——后面所有讨论都建立在这个基础上:format 不重要,content 重要。
子问题 2:人(或 LLM judge)能从文本本身判断技能好坏吗?
直觉上肯定可以吧?给两份技能让 GPT-5.4 选哪个更好用,应该至少比随机强吧?
实验:从主实验里挑出 151 对(同 extractor、同领域、同 target),对效用差距 \(\delta = |\Delta_A - \Delta_B|\) 做分析。
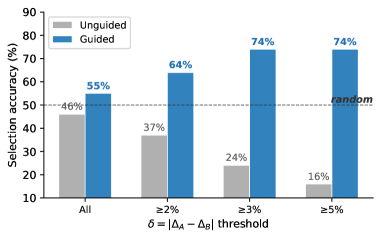
图 3:灰色是无引导 judge,蓝色是用了 validated rubric 引导。横轴从 All(所有对)到 \(\delta \ge 5\%\) (高差距对)。
灰色那一列的数字让我看完愣了一下:
- 所有对:accuracy 是 46 个百分点(不如随机)
- \(\delta \ge 2\%\):37%
- \(\delta \ge 3\%\):24%
- \(\delta \ge 5\%\):只有 16 个百分点
差距越大,LLM 越倾向于选错的那个。 在 \(\delta \ge 5\%\) 的高差距对上,挑中真正高效用技能的概率只有 15.8%——这已经不是"判断不出来"了,是反向预测。
我第一反应是怀疑评测协议是不是有问题。但作者把这个现象讲清楚了:高差距对的"差距"往往体现在一个写得文气漂亮、抽象层级高、读起来很顺的技能 vs 一个充满细节、看起来啰嗦但贴着具体 failure mode 写的技能。LLM judge(也包括人类直觉)会被前者吸引。这是 plausibility 和 utility 的脱钩——好读 ≠ 好用。
子问题 3:哪种文本特征跟效用真的相关?
定性观察一对 SpreadsheetBench 上 \(\Delta\) 差 10.3pp 的技能:
- 高效用那份说,对宿主引擎不评估公式字符串的情况,先把静态值预计算出来——指名了一个具体失败机制 + 给出可执行修复。
- 低效用那份说:"写代码前先理清合约"——空洞的程序性建议。
这就是 5.2 节的定性结论:concrete remedies, not generic advice。具体的失败机制 + 可执行修复 > 通用指导原则。
阶段三:同样的技能,为什么有的 target 涨有的 target 掉?
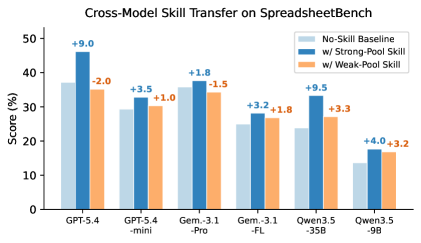
图 4:在 SpreadsheetBench 上,固定 extractor 是 GPT-5.4-mini,分别拿"从最强 target(GPT-5.4)经验池抽出来的强池技能"(蓝)和"从最弱 target(Qwen3.5-9B)经验池抽出来的弱池技能"(橙),注入给 6 个不同 target。
两条结论:
- 同一份技能,per-target 收益差异巨大。强池技能在 Gemini-3.1-Pro 上只涨 +1.8,到 Qwen3.5-35B 上涨 +9.5——同一段文字,效果差 5 倍。
- 强池技能稳定向上,弱池技能选择性害人。弱池技能在 GPT-5.4 上是 -2.0、在 Gem-3.1-Pro 上 +1.0,给最强的模型反而扣分——这跟 5.1 节"经验池质量是关键"完美对接。
作者还做了个行为分析(Appendix D),发现一个挺有意思的事:技能消费不是触发显式的 skill 调用,而是把 target 的默认策略给重塑了。GPT-5.4 被推向"对齐评估器的计算 + 验证",Qwen3.5-9B 被推向"复杂的 workbook 原生工作流"——后者结构上更对,但执行鲁棒性变差,所以反而掉点。
这个观察我个人觉得对工程很关键:技能不是工具,是先验。你给一个不具备执行该先验所需基础能力的 target 喂高级先验,它会被带偏。
从诊断到干预:3 维 rubric 当 meta-skill
走到这里,论文已经诊断完了:技能效用其实来自三个独立维度的乘积——经验池质量 × 抽取器选择 × 消费者匹配度。但诊断只是诊断,作者最后还做了件挺漂亮的事:把这些诊断结果翻译成一个可操作的干预。
怎么找出"真正预测效用"的文本维度?
思路很直接:用对比 pipeline 自动发现。给定一对效用差距大的技能,提取它们在多维度上的差异,看哪些维度的差异方向跟效用方向对齐。作者最后筛出 3 个维度(与 GPT-5.4 不经验证就生成的 7 维 plausibility rubric 形成对比):
- Failure Mechanism Encoding:是否明确编码了具体的失败机制?
- Actionable Specificity:建议是否可执行、是否带具体步骤?
- High-Risk Action Blacklist:是否把高风险操作明确列入禁止清单?
这 3 个维度的 better-rate 都在 64–66% 之间,明显高于随机。三个加起来就是 validated rubric。
把它喂回去做 LLM judge 引导,就是 Figure 3 里那条蓝色柱:整体准确率从 46.4 个点拉到 73.8 个点,在 \(\delta \ge 5\%\) 高差距对上从 15.8% 拉到 74%。同一个 LLM judge,加一个 3 维评分模板,从反向预测变成了可靠预测器。
把 rubric 做成 meta-skill
这才是真正的工程意义所在——把 validated rubric 直接塞进 extractor 的 system prompt,让抽取器在生成技能时就按这 3 个维度自查。
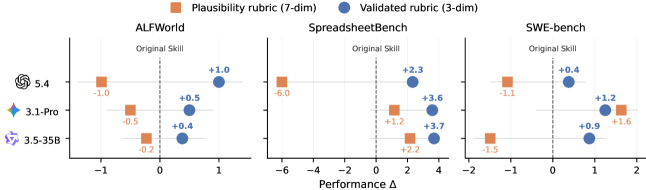
图 5:在 ALFWorld、SpreadsheetBench、SWE-bench 三个域 × 三个 target 共 9 个 cell 上的对比。橙色方块是 7 维 plausibility rubric(GPT-5.4 不经实证直接生成的版本),蓝色圆是 3 维 validated rubric。
结果非常有意思:
- 7 维 plausibility rubric 平均 -0.59pp,9 个 cell 里 6 个掉点。这呼应了 5.2 节那个核心洞察——写得"看起来全面"的指导反而把抽取带跑偏。
- 3 维 validated rubric 9 个 cell 全部正向,平均 +1.55pp,SpreadsheetBench 上 +2.3 到 +3.7pp。
这是个标准的"诊断—干预闭环"故事,从 Section 5 的"我发现 plausibility 不预测 utility",到 Section 6 的"那我去找真正预测 utility 的维度",再到"把这些维度做成 meta-skill 验证可以提升下游"。在论文里把整个分析链条 closed-loop 跑通,是这篇工作最让我服气的地方。
一个工程上的注意点:这个 meta-skill 是 plug-in 的,不需要改 pipeline,只需要在 extractor 的系统提示里拼上一段额外的 Extraction Quality Guidance 块。任何一套现有的 skill 抽取流水线都能直接挂。
我的判断:这篇论文值不值得花时间细读
先说结论:值得,特别是如果你在做 Agent 平台、Skill 库、AGENT.md 这类工程的话。
亮点
1. 评测维度的完整性是这个领域里最高的之一。5 域 × 6 target × 5 extractor,三阶段全覆盖。在我读过的同类工作里,要么只测 consumption 阶段(SkillsBench),要么只测一个域(SkillCraft),这篇是第一篇真正把 lifecycle 跑全的。
2. 几个反直觉发现都有可重复实验支撑。"强 executor ≠ 强 extractor"、"plausibility 反预测 utility"、"ALFWorld 失败池更有用"——这三个我之前在工程上多多少少都隐约感觉过,但从没看到有人正经做实验定量证伪/证实。这种工作的 value 不在 SOTA,在于把模糊的工程直觉结晶成可引用的发现。
3. 闭环到了一个 drop-in 的工程改进。不是发现完问题就甩论文,最后给了 validated rubric meta-skill 这个落地物,9 个 cell 全部正向。审稿人爱看这种"诊断 + 治疗"的完整故事,工程师也爱用。
我有保留的地方
1. 经验池的成功率扫描只覆盖了 3 个域,还差俩没测。SEAL-0 和 BFCL 上成功-失败比例的最优点是不是也跟领域强相关?没说。如果作者补这部分就更完整了。
2. validated rubric 的 3 个维度全是"failure-mode 导向"的——Failure Mechanism Encoding、High-Risk Action Blacklist。我猜在某些任务(比如开放探索类)上这套 rubric 反而会偏严,把"有用的高层抽象"过滤掉。论文里覆盖的 3 个域(ALFWorld、Spreadsheet、SWE-bench)都偏向"有明确正确答案"的任务,这个 rubric 在更开放的任务(创意写作辅助、研究 Agent)上是不是 still hold,得看后续工作。
3. behavioral analysis 部分(5.3 后半 / Appendix D)做的是"重塑默认策略"这种相对软的定性结论。我想知道更硬的东西——比如能不能用 attention 或 token-level entropy 显式量化"技能改变了 target 的多少行为",把"为什么 Qwen3.5-9B 被技能害"这件事说得更机制化。
4. 跟同期工业方案的对比。Claude Skills、Codex 的 AGENT.md、Anthropic 的 Skill Marketplace 这些产品级方案各自带不少启发式(review、可执行性约束、版本控制),论文的"故意做得很简陋"的抽取 pipeline 跟它们的工程加持版本相比效果如何,没做正面对比。我能理解为啥不做(变量爆炸),但这层留给读者去自己 evaluate 还是有点遗憾。
跟同期工作的相对位置
最近半年在 Agent skill / Agent memory 这个方向上密集出了一批工作:HASP(把技能从 prompt 升级成可执行 guard)、SLIM(技能生命周期管理)、Skill1(技能库协同进化)、SkillsVote(证据门控的技能治理)、MOCHA(多目标技能优化)等等。这些工作大多在做"我提了一种新的抽取/治理/优化方法"。
而 SkillLens 这篇是反向定位的——它做的是"在所有这些方法之前,你应该先理解的基础规律"。它跟其他工作的关系不是替代,是底层。其他工作的方法在加各种启发式之前,先得知道哪些维度才是需要被启发式管控的真正变量——而这篇告诉你:经验池质量、抽取器选型、消费者匹配,以及 rubric 三维。这就是 evaluation paper 的价值,它会被广泛引用,但很少被替代。
工程启发:如果你在做 skill pipeline,至少做这几件事
读完这篇,我想了一下,对真在做 Agent 系统的人,至少有 4 件事可以马上动手:
-
不要默认用最强模型当 extractor。专门 ablate 一遍——大概率你能找到一个更小、更便宜、抽出来的技能效用更稳的模型。Spreadsheet 上 Flash-Lite 干翻 GPT-5.4 这事不是巧合,背后是抽取能力跟执行能力解耦这条规律。
-
经验池配比要做领域调参。不要默认"全成功 = 最好"。在动作离散、状态空间复杂的领域(具身、UI 操作、某些游戏)上故意保留一些失败轨迹,让技能里同时编码 do-list 和 don't-list。论文 ALFWorld 25% 成功率最优这事提供了一个量化锚。
-
不要让评审 LLM 在没有 rubric 的情况下挑技能。直接挑会得到反向预测。把 validated rubric(Failure Mechanism Encoding、Actionable Specificity、High-Risk Action Blacklist)拼进 judge prompt,准确率从 46% 拉到 73%——这个是几乎零成本的改造。
-
抽取器的系统提示里加一段 meta-skill guidance。3 维 rubric 当生成时的先验,9 个 cell 全部正向、平均 +1.55pp。改一行 prompt,比改整个 pipeline 收益高。
收尾
把整篇论文压缩成一句话:模型自己抽自己的技能这件事不是简单的"装上就涨",它是一个三阶段乘三方匹配的复杂系统问题,当你用足够细的颗粒度去测量时,会看到 25% 的部署其实在帮倒忙——而真正能稳定把这个系统校准的方法,是用 utility-grounded 的 rubric 去引导抽取器,而不是依赖更强的模型或更复杂的 pipeline。
如果你接下来要部署任何一种 skill 自动化系统,这篇 paper 至少帮你节省一遍踩坑的成本。
代码在 https://aka.ms/SkillLens ,作者也明确这个 meta-skill 是 drop-in 的,没改你现有 pipeline 的成本。我自己最近在弄类似的事,已经准备把 validated rubric 塞进我们抽取器的 system prompt 里跑一组 ablation 看看。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我