8K 条合成任务,把开源深度研究 Agent 拉到闭源水平 —— QUEST 论文细读
最近开源圈的"深度研究 Agent(Deep Research Agent)"卷得相当凶。Tongyi-DR、OpenResearcher、DR Tulu、RedSearcher……一茬接一茬。但坦率讲,每次拿到一个新的开源 deep research 模型,我心里都在打鼓——这玩意儿在自家擅长的那个 benchmark 上能跑出花来,换一个任务类型立马拉胯。
要会找事实(fact seeking,比如 BrowseComp 那种"哪个建筑师设计了《麦田守望者》作者住了几十年的房子"),要会做引用核查(citation grounding,Mind2Web 2 那种带 URL 的硬约束),还要会写综述报告(report synthesis,DeepResearch Bench 那种开放式长报告)。这三件事在现有开源方案里基本是分裂的——擅长 A 的不擅长 B,没有谁能在所有任务上都顶住闭源的压力。
这就是 QUEST 这篇论文要解决的问题。
OSU NLP Group 的这篇工作,提了一套完整的"通用型深度研究 Agent"训练配方,从数据合成、上下文管理到 mid-training+SFT+RL 三阶段训练,最后只用 8K 条全合成任务就把 Qwen3.5-35B-A3B 拉到了一个让我有点意外的位置——在 8 个 deep research benchmark 上,在 Mind2Web 2(30.7%)和 DeepResearch Bench(48.2%)上反超 OpenAI DeepResearch,在 GAIA(80.8%)上反超 GPT-5。模型、数据、训练脚本全开源。
我读完最大的感觉是:deep research agent 训练里那个"任务类型间不可调和"的矛盾,他们用一个叫 rubric tree 的东西给统一了。这个东西不是新发明(Mind2Web 2 的工作里就有了),但 QUEST 把它从"评测协议"用成了"数据合成的统一接口 + RL 奖励信号源",让一套训练框架同时能产出三种能力的训练数据。这一步走得挺漂亮。
下面我们细聊。
论文信息
- 标题:QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
- 作者:Jian Xie, Tianhe Lin, Zilu Wang, Yuting Ning, Yuekun Yao, Tianci Xue, Zhehao Zhang, Zhongyang Li, Kai Zhang, Yufan Wu, Shijie Chen, Boyu Gou, Mingzhe Han, Yifei Wang, Vint Lee, Xinpeng Wei, Xiangjun Wang, Yu Su, Huan Sun
- 机构:The Ohio State University (OSU NLP Group) 等
- arXiv:2605.24218
- 提交日期:2026 年 5 月 22 日

论文给的核心战绩图:QUEST-35B 在 BrowseComp、Mind2Web 2、DeepResearch Bench 等 8 个 deep research benchmark 上全面对标闭源系统,并在 30B 同规模开源 Agent 中拿下整体最优。
一、问题在哪儿:为什么"通用 deep research agent"这么难
先把背景捋清楚。
Deep research agent 到底要会什么
论文给了一个我觉得挺干净的能力划分。Deep research 任务可以分成两类:
| 任务类型 | 核心特征 | 评测方式 | 代表 benchmark |
|---|---|---|---|
| Objective tasks(客观题) | 答案有外部可验证证据 | 二元正确性 + 约束满足 | BrowseComp / Mind2Web 2 / HLE / GAIA |
| Open-ended tasks(开放题) | 答案是长报告,质量需主观判断 | rubric 评判 + 主观分维度 | DeepResearch Bench / LiveResearchBench |
横跨这两类任务,Agent 需要的能力可以收敛到三个:
- Fact seeking:多跳搜索找到具体的、冷门的事实(BrowseComp 是典型)
- Citation grounding:每个论断都要配可验证的 URL(Mind2Web 2 是典型)
- Report synthesis:综合多源信息写成结构化报告(DeepResearch Bench 是典型)
现有开源方案的根本问题
我之前调过几个开源 deep research agent,最直接的体感就是——它们的"擅长面"完全跟着训练数据走。
- Tongyi-DR 用的是 BrowseComp 风格的"复杂问题→单一可验证答案"的合成数据,所以它在 BrowseComp、HLE、GAIA 这种 fact seeking 任务上表现强,但在写报告的 DeepResearch Bench 上明显掉档。
- OpenResearcher 的合成 pipeline 是离线检索导向的,所以它在 BrowseComp-Plus(一个完全离线的 benchmark)上特别能打,换到在线任务就吃亏。
- DR Tulu 偏开放式报告,objective 任务直接拉胯(Mind2Web 2 上只有 1.6%)。
核心矛盾:现有开源方案大多用"复杂问题 + 单一答案"的格式合成数据。这种格式天然对 fact seeking 友好,但对 report synthesis 来说几乎没用——长报告没有"单一正确答案",二元 reward 也没法做有效的 credit assignment。
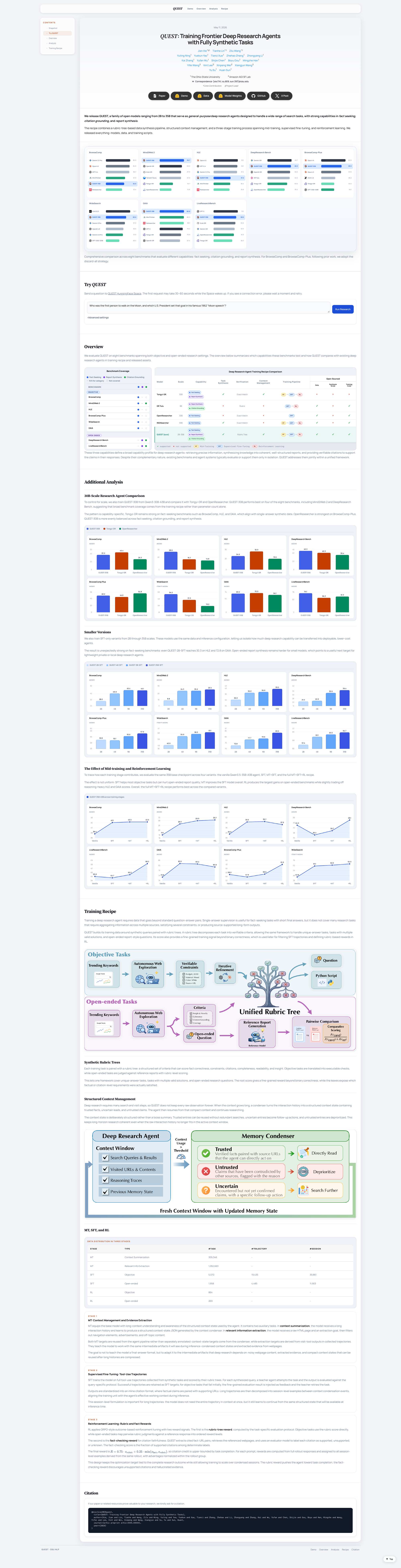
论文 Figure 2:横向对比已有的 deep research agent 训练 recipe(OpenResearcher、Tongyi-DR、DR Tulu 等)的能力覆盖。多数现有 recipe 只覆盖 fact seeking / citation grounding / report synthesis 中的 1-2 项,QUEST 是首个三项全覆盖的开源 recipe。
QUEST 的核心思路就是:别再合成"问题-答案"对了,合成"问题-rubric tree"对。
二、核心设计:rubric tree 当作统一接口
这是这篇论文最关键的一步。我读到这里有点拍大腿——这个设计本身不复杂,但它把数据合成、SFT 监督信号、RL 奖励信号三件事用同一个表示串了起来。
Rubric tree 是什么
Rubric tree 是一棵层次化的"约束树":
- 根节点:整体得分
- 中间节点:高层约束(比如"价格符合预算"、"材料正确")
- 叶子节点:可直接验证的细粒度约束(每个叶子返回 0/1)
每个叶子节点都能被自动验证(事实正确性、来源归属等),上层节点通过加权聚合得到分数。整棵树的得分就是这条 trajectory 的训练信号。
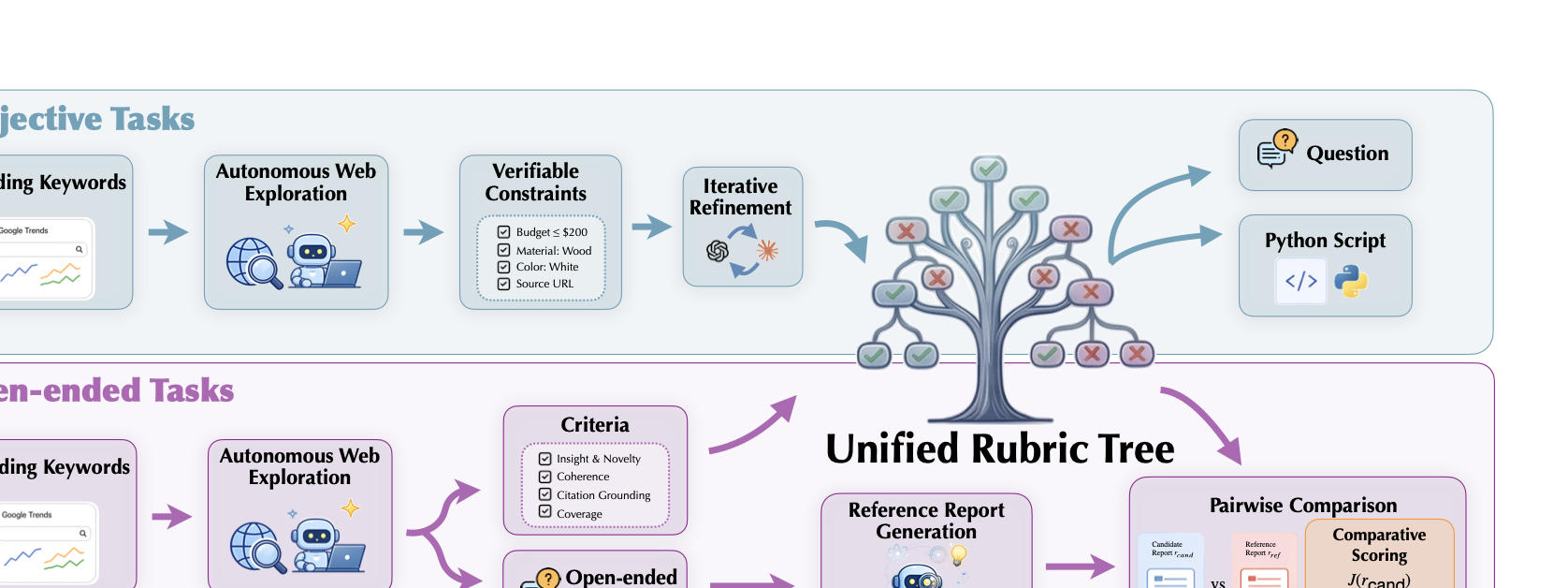
数据合成 pipeline 的核心结构:左上 objective tasks 和左下 open-ended tasks 共用同一棵 rubric tree(中间),但产出的最终监督信号不同——客观任务输出 question + Python 评测脚本,开放任务输出 question + criteria + 参考报告 + pairwise 评判。
为什么 rubric tree 解决了通用性问题
这套表示有一个隐性的好处:它同时容纳了三种任务——单一答案任务、多解任务、无标准答案的开放任务。
- 单一答案:rubric tree 只有一个叶子,叶子要求"答案 == ground truth"
- 多约束任务:每个约束一个叶子,全部满足 = 满分
- 开放任务:根节点的子节点固定为 4 个(指令遵循、全面性、可读性、insight,沿用 DeepResearch Bench),下面是任务相关的细粒度叶子
而且训练信号天然变成连续值——根节点聚合分数 ∈ [0,1],比传统二元奖励能给出更精细的 credit assignment。这一点对 RL 阶段很关键。
数据合成 pipeline 怎么跑
合成流程大致是:
- 从 Google Trends 爬取 trending keywords 当种子(保证话题时新性 + 用户真实需求覆盖)
- 让 Claude Sonnet 4.5 自主浏览网页,把检索到的内容总结成可验证约束,组织成 rubric tree
- 强约束的迭代精炼和验证——结构有问题、节点定义不清晰的 rubric tree 直接丢弃
- 用 GPT-5 把 rubric tree 翻译成可执行的 Python 评测脚本(客观任务)
- 开放任务则生成参考报告 + pairwise 评判规则
最终产出:8K 条任务(5070 客观 + 1958 开放),每条都带一棵任务专属的 rubric tree。
我觉得最妙的一点是 rubric tree 替代了人工标注。Mind2Web 2 是人工写约束树的,工作量极大。QUEST 把这一步全自动化了——只要 Claude 4.5 能跑稳,rubric tree 的生产就是规模化的。
三、Open-ended 任务的 reward 设计:作者踩过的两个坑
这块是我读论文时最有共鸣的一段——他们写了一节叫 "Unsuccessful Attempts" 的章节,把试过但没 work 的方案诚实地列出来。
坑 1:Pointwise 评分的 score inflation
最直觉的做法是给每个 rubric 标准打"满足/部分满足/不满足"(0 / 0.5 / 1)。结果:约 50% 的回答得分接近 1——judge model 在缺少参考的情况下,有强烈的"高分讨好用户"倾向。
这个现象我自己跑 LLM-as-judge 的时候也碰到过。没有对照,judge 几乎不愿意打低分。
坑 2:Pairwise win/tie/lose 的 score collapse
那加个 reference response 做 pairwise 比较呢?三档:lose=0,tie=0.5,win=1。
结果出现反向问题:早期模型水平远低于 teacher,judge 几乎全打 lose 标签,分数 collapse 到 0,SFT 过滤和 RL 训练都没法用。
最终方案:连续 pairwise 分数 + 离散化 reward
QUEST 最后用的是这样一套:
- 对每个 rubric 节点,judge 同时看 candidate 和 reference 报告,分别打 0-10 的连续分(同时看两个比独立打分能给出更细的差异)
- 节点分按 rubric tree 加权聚合得到 J(r_cand) 和 J(r_ref) ∈ [0,1]
- 最终 score = J(r_cand) / (J(r_cand) + J(r_ref)),>0.5 表示超过 reference 报告
- RL 阶段把这个连续分离散化为 reward levels:
- score > 0.5 → reward = 1.0
- [0.475, 0.5) → 0.75
- [0.45, 0.475) → 0.5
- [0.425, 0.45) → 0.25
- < 0.425 → 0
这个离散化设计很有工程感——保留相对排序,又让 reward 信号对小波动不敏感。我觉得这种"基于 ratio 的归一化分数"思路在 RLHF 里其实可以广泛借鉴。
四、Context Management:跑长 horizon 不能靠"大窗口硬扛"
Deep research agent 一次任务动辄几十轮搜索 + 网页阅读,原始 context 很容易爆。现有开源方案两个套路:
- 限制 turn 数:直接卡死,Agent 想做长程推理也没机会
- 塞超大窗口:100K+ context,但 attention 实际上 degrade 严重,钱花了效果不一定好
QUEST 的做法是 Context Condenser + 结构化 Memory State。

Memory State 把累积知识划分成三类:Trusted(已核验、附带源 URL,可直接复用)、Untrusted(被其他来源证伪,附带证伪原因)、Uncertain(部分支持的待跟进项,附带"该访问的 URL"或"该重新搜索的 query")。
这块的设计我特别喜欢的两点:
1. Memory State 不是单纯的"摘要",而是 epistemic state
它不光记"我知道什么",还记"我对它有多确信、为什么不确信、下一步该怎么验证"。这跟人类做研究时的笔记结构很像——好的研究笔记不是流水账,是知识 + 元知识。
2. Trusted/Untrusted 的区分让 Agent 不会反复掉同一个坑
如果一个网页声称的事实被另一个权威源证伪了,Untrusted 标签 + 证伪原因会保留下来。新窗口续跑的 Agent 就不会再去引用那个被证伪的源。这一点对 citation grounding 任务尤其重要。
具体实现上,condenser 用的是 GPT-5-mini(轻量、便宜),触发条件是 context 使用率超过阈值。压缩后 Agent 在全新的 context 窗口里续跑,初始化为最新的 Memory State。
五、训练配方:MT + SFT + RL,每一步都有讲究
QUEST 的训练流程分三段:
Vanilla (Qwen3.5-35B-A3B base)
↓ Mid-training (MT): Context Summarization + Relevant Info Extraction
MT
↓ SFT: 教师轨迹模仿(teacher = Tongyi-DR + GPT-5.2 抛光)
MT + SFT
↓ RL: GRPO + rubric reward + fact-checking reward
MT + SFT + RL = QUEST-35B
Mid-training:教模型理解 Memory State 这个"协议"
MT 阶段做两个辅助任务:
- Context Summarization:给一段长历史,输出结构化的 Memory State JSON。监督目标直接复用合成 pipeline 里 GPT-5-mini 产出的 Memory State,不需要额外标注。
- Relevant Information Extraction:给一个原始 HTML 页 + 提取目标,输出与目标相关的内容(过滤掉导航栏、广告、跑题段落)。
这两个任务的特点是不需要新数据——目标本身是合成 pipeline 的副产物。MT 自然嵌入进整个流水线,不是额外的标注负担。
数据规模:Context Summarization 30.9 万条,Relevant Info Extraction 105.3 万条。
SFT:Session-level training
SFT 用的是 teacher model(Tongyi-DR)跑出来的轨迹,过滤掉评分不达标的(客观任务阈值 ε=1,开放任务 ε=0.475)。客观任务还有一个 reflection-based retry:第一次没过线,把细粒度评测结果作为 hint 再让 teacher 跑一次。
关键设计:session-level training。一条完整 trajectory 因为有多次 context condensation,被切成多个 session(两次 condensation 之间的 working context)。每个 session 是一个独立训练样本。这样训练单元和推理时的 effective working context 对齐,相比把整条 trajectory 当一条样本,对长程任务的训练更高效。
数据规模:
| Stage | Type | #Tasks | #Trajectories | #Sessions |
|---|---|---|---|---|
| MT | C.S. | — | — | 309,346 |
| MT | R.I.E. | — | — | 1,052,663 |
| SFT | Objective | 5,070 | 19,435 | 39,861 |
| SFT | Open-ended | 1,958 | 4,485 | 11,903 |
| RL | Objective | 864 | — | — |
| RL | Open-ended | 269 | — | — |
注意 RL 阶段只用了 1,133 条任务——RL 在这个 setting 里非常贵(每条要采样 rollout group),只挑了最值得训的子集。
RL:rubric reward + fact-checking reward 的联合
RL 用 GRPO(group relative policy optimization),reward 是两部分加权:
- \(s_{\mathrm{rubric}}\):来自 rubric tree 的评测分数(前面讨论的连续→离散映射)
- \(s_{\mathrm{fact}}\):fact-checking reward。把回答里所有 inline citation 抽出来,retrieve 引用的网页,让 GPT-5-mini 判断每个引用是 supported / unsupported / unknown,然后计算 supported 比例
这里的 min 操作是个亮点:如果回答虽然引用很扎实但任务做得稀烂,s_rubric 就低,min 把 fact-checking 的贡献也一起压住——避免"引用对了但题答错了"反而拿高分。这种 reward shaping 我觉得在 RLHF 里也很有借鉴意义。
advantage 用 group 内 z-score 标准化,从同一 rollout 切出的多 session 共享一个 advantage(避免重复影响)。
六、实验结果:跟闭源系统真的能掰手腕了
主表:8 个 benchmark 横评
下面是论文 Table 1 的核心数据(仅列 30B 量级的开源 Agent + 主流闭源系统):
| 模型 | BC | BC-Plus | M2W2 | WideSearch | HLE | GAIA | DRB | LRB |
|---|---|---|---|---|---|---|---|---|
| GPT-5 | 59.9 | 71.7 | — | 54.0 | 35.2 | 76.4 | — | 73.1 |
| Claude Opus 4.5 | 67.8 | 83.0 | — | 76.2 | 43.2 | — | 50.6 | — |
| Gemini 3 Pro | 59.2 | — | — | 57.0 | 45.8 | — | 49.6 | — |
| OpenAI-DR | 51.5 | — | 28.0 | — | 26.6 | 67.4 | 47.0 | — |
| Tongyi-DR | 43.4 | 44.5 | 16.7 | 37.3 | 32.9 | 70.9 | 40.5 | 56.3 |
| OpenResearcher | 26.3 | 54.8 | 14.8 | 19.2 | 19.6 | 64.1 | 35.4 | 61.3 |
| QUEST-30B(同基座对比) | 37.0 | 48.2 | 28.6 | 54.2 | 24.6 | 69.0 | 45.3 | 74.1 |
| QUEST-35B | 45.5 / 64.6* | 61.0 / 69.5* | 30.7 | 60.6 | 37.2 | 80.8 | 48.2 | 68.2 |
* 标记的是用 discard-all 上下文管理策略(与 Claude/Kimi/RedSearcher 对齐)跑全集的结果。
几个关键判断:
1. QUEST-35B 在 Mind2Web 2、DeepResearch Bench、GAIA 上反超 OpenAI DeepResearch——M2W2 30.7 vs 28.0,DRB 48.2 vs 47.0,GAIA 80.8 vs 67.4。这三个 benchmark 分别考察 citation grounding、report synthesis、复杂问题求解,说明 QUEST 在三种能力上都顶得住。
2. GAIA 80.8 反超 GPT-5 的 76.4——这个数我看到的时候有点愣。GAIA 是个综合的复杂工具使用 benchmark,不是只考察 fact seeking。35B 的开源模型在 GAIA 上压过 GPT-5,是真挺难得的。
3. 同 30B 量级横评,QUEST-30B 是最均衡的——8 个 benchmark 里拿了 4 个第一。Tongyi-DR 在 BrowseComp/HLE/GAIA 三个 fact-seeking 重的 benchmark 上更强(这跟它单答案合成数据吻合),OpenResearcher 在 BC-Plus 上更强(跟它离线检索的合成 recipe 吻合)。QUEST 的优势在于它没有明显短板,而对手都有。
不过我得在这里说点公道话:
- BrowseComp 上 QUEST-35B 用 discard-all 策略才到 64.6 分,正常跑只有 45.5 分。这跟 Claude Opus 4.5 的 67.8 还有差距。fact-seeking 这块他们承认 Tongyi-DR 更强。
- WideSearch 上 Claude Opus 4.5 的 76.2% 仍然是天花板,QUEST-35B 的 60.6% 是开源里最高,但跟闭源差 16 个点。
- HLE 上 Gemini 3 Pro 的 45.8% 仍然遥遥领先——这个 benchmark 重 reasoning,QUEST 的 RL recipe 反而轻微伤害了 HLE(后面消融能看到)。
所以这不是开源彻底追平闭源的故事,而是开源在 deep research 这个垂直能力组上把差距拉得很近了。这个定位我觉得说得过去。
训练阶段消融:MT、SFT、RL 谁的贡献最大
逐个 benchmark 看(数字是 Vanilla → SFT → +MT → +RL):
| Benchmark | Vanilla | SFT | +MT | +RL | RL 贡献 |
|---|---|---|---|---|---|
| BrowseComp | 38.4 | 45.1 | 45.5 | 45.5 | 持平 |
| Mind2Web 2 | 15.1 | 26.5 | 29.9 | 30.7 | 微涨 |
| HLE | 32.3 | 39.5 | 39.7 | 37.9 | 掉点 |
| DeepResearch Bench | 44.1 | 36.4 | 39.7 | 48.2 | 大涨 |
| BrowseComp Plus | 58.5 | 57.9 | 58.6 | 61.0 | 微涨 |
| WideSearch | 43.8 | 61.1 | 62.5 | 64.5 | 微涨 |
| GAIA | 72.8 | 83.5 | 83.2 | 80.8 | 掉点 |
| LiveResearchBench | 65.0 | 64.7 | 65.5 | 68.2 | 涨 |
几个观察:
1. SFT 在 open-ended 任务上反而伤害性能:DRB 从 44.1 掉到 36.4——单纯的轨迹模仿对长报告任务有过拟合风险,因为模仿 teacher 等于把 teacher 风格固化下来了。这一点其实很反直觉,论文给的解释也合理。
2. MT 在 SFT 之上几乎全面正向:长上下文理解 + Memory State 格式适配的辅助任务,对所有 benchmark 都有小幅或中幅提升。
3. RL 在 open-ended 上爆发:DRB 从 39.7 涨到 48.2(+8.5 个点),LRB 从 65.5 涨到 68.2。这说明 rubric-tree reward 这个连续可比较的信号是 RL 在长报告任务上 work 的关键——比传统二元 reward 强太多。
4. RL 对 HLE 和 GAIA 有 alignment tax:HLE 掉 1.6 个点,GAIA 掉 2.4。论文承认这是因为 RL 优化目标偏 report synthesis 风格的可读性,对纯 reasoning 类任务有微小损伤。这个诚实度我喜欢——很多论文会把这种掉点藏起来。
模型规模 scaling:2B 模型也能打
QUEST 还做了 2B / 4B / 9B / 35B 的 SFT 对比(同样的 8K 训练数据):
| Benchmark | 2B-SFT | 4B-SFT | 9B-SFT | 35B-SFT |
|---|---|---|---|---|
| BrowseComp | 28.0 | 40.0 | 45.4 | 45.1 |
| Mind2Web 2 | 8.8 | 24.3 | 24.4 | 26.5 |
| HLE | 30.3 | 36.2 | 36.9 | 39.5 |
| DRB | 21.0 | 22.0 | 32.6 | 36.4 |
| BC-Plus | 52.6 | 52.1 | 55.6 | 57.9 |
| WideSearch | 40.9 | 55.0 | 58.5 | 61.1 |
| GAIA | 72.8 | 77.7 | 78.6 | 83.5 |
| LRB | 57.4 | 62.1 | 63.5 | 64.7 |
最让我惊讶的是 2B 模型的 HLE 30.3% 和 GAIA 72.8%——比 OpenAI o3 的 24.9% 和 70.5% 还高。一个 2B 的开源模型,靠 8K 条合成数据 + SFT(连 RL 都没做),在 HLE 上能压过 o3。
但这个故事也有限制:2B/4B 在 DeepResearch Bench 上掉得很厉害(只有 21-22%,35B 是 36.4%)。说明 fact seeking 类任务对模型规模敏感度低,但 report synthesis 类任务对模型规模强烈依赖——长报告需要的 reasoning 深度和 coherence,小模型确实跟不上。
这个 scaling 模式对工程落地很有意义:fact-seeking-heavy 的应用(医疗检索、法律检索)可以用 2B-4B 模型本地部署,处理隐私敏感场景;写报告的应用必须上更大模型。
七、几个让我皱眉的地方
读完整篇,我觉得有几个点值得提醒:
1. 数据合成对超强 LLM 的依赖
整个 pipeline 高度依赖 Claude Sonnet 4.5(合成 rubric tree)+ GPT-5(生成 Python 评测脚本)+ GPT-5-mini(context condenser、citation 评判)。整个"开源"的故事,是建立在一系列闭源前沿模型之上的。如果这些模型的 API 政策变化或价格上涨,复现成本会很高。论文没有讨论用全开源模型替代会损失多少质量。
2. RL 数据规模其实很小
只有 1,133 条任务上 RL(864 客观 + 269 开放)。这个规模撑起的 reward signal 稳定性我有点担心——尤其是 269 条开放任务要驱动 DRB 上 8.5 个点的提升,听起来有点"魔法"。论文没给 RL 的 group size、rollout 次数等细节(推测在附录),希望开源代码能让社区验证。
3. teacher 的污染问题
SFT 的 teacher 是 Tongyi-DR,open-ended report 用 GPT-5.2 抛光。这意味着 QUEST 的"风格"实际上继承自 Tongyi 和 GPT-5.2。在 LRB 等 benchmark 上的优势,有可能部分来自 teacher 风格本身,跟训练 recipe 的关系反而是次要的。这个混淆变量论文里没充分剥离。
4. discard-all 策略的 caveat
BrowseComp 全集 64.6% 这个数字是用 discard-all 策略跑的——也就是上下文管理策略选择"丢弃一切,只保留必要的"。这跟 Claude Opus 4.5 用的策略一致。但用户实际部署 deep research agent 时不一定能这样配,正常 context 管理下 QUEST-35B 在 BrowseComp 只有 45.5 分——这个数才是日常使用的真实体感。这一点我希望论文更直白一点。
八、对工程实践的几点启发
如果你也在做 deep research agent,这篇论文里我觉得最值得借鉴的几点:
1. 用 rubric tree 替代"问题-答案对"做数据合成
哪怕你不做 RL,光是用 rubric tree 合成 SFT 数据就比传统 QA 对格式有优势——它强迫你显式列出所有约束,能合成更丰富的任务类型。配合 LLM-as-judge,几乎可以零标注成本。
2. Memory State 的 Trusted/Untrusted/Uncertain 三分
这个设计的精髓不在于"压缩历史",而在于保留 epistemic state。如果你做的是带 citation 的 RAG/Agent 系统,引入这种"信任度标签 + 待核查项"的 memory 结构,Agent 行为会稳定很多。
3. RL reward 用 min 操作上界 fact-checking 贡献
\(R = 0.75 \cdot s_{\mathrm{rubric}} + 0.25 \cdot \min(s_{\mathrm{fact}}, s_{\mathrm{rubric}})\)
这种"次要 reward 不能超过主 reward"的设计避免了 reward hacking。我觉得在多目标 RL 里是个通用技巧。
4. Session-level training
把 trajectory 切成 session 训练,本质是让训练单元和推理单元对齐。如果你的 Agent 在推理时会触发 context compression,训练时按完整 trajectory 做反而是错的。
5. 别迷信单一答案合成数据
这是论文最大的工程教训——单答案合成数据训出来的 Agent,在 BrowseComp 类任务上打榜很猛,但泛化性差。如果你想做"通用 deep research agent",从一开始就该规划多种任务类型的合成 recipe。
九、收尾
QUEST 给我的整体感觉是——它不是某一个组件的突破,是一套完整、自洽、可复现的工程配方。从数据合成到 context 管理到三阶段训练,每一步都有明确的设计动机,也都有相应的消融数据支持。
它的最大价值,不是把开源 deep research agent 的某个 benchmark 数字推到了新高,而是给社区提供了第一个"通用型"开源配方——你不再需要为 fact seeking 和 report synthesis 各训一个模型了。
它的最大限制,是这个配方的复现成本不低——8K 数据合成需要海量 Claude 4.5 调用,RL 阶段需要 GPT-5-mini 做 fact-checking 评判。开源模型,闭源数据生产链。
未来一年我比较期待看到的方向:
- 用全开源模型(比如 Qwen3.5-235B 自己)替代 Claude/GPT 做合成,看质量损失多少
- 把 rubric tree 合成扩到 100K 量级,看 scaling law
- 把 QUEST 配方放到代码 / 数学 / 科研助手等更垂直的 deep research 场景
如果你也在做 search agent / RAG / deep research 方向,这篇论文非常值得花两小时细读,尤其是 "Unsuccessful Attempts" 那一节——失败案例往往比成功案例更有信息量。
参考链接: - 论文:https://arxiv.org/abs/2605.24218 - 模型/数据/代码:论文声称全开源(具体 GitHub 地址见论文)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我