Agent的"空闲时间"被浪费了——ProAct想用它干点正事
核心摘要
你有没有发现,现在的所谓"智能体"其实挺懒的——你不戳它,它就在那儿待机。用户敲一句话,它转一圈、答一句,然后就进入"什么也不做"的等待状态。直到你下一次开口,循环才重新开始。
ProAct 这篇论文盯上了这段被浪费的"空闲时段"。它的核心命题就一句话:让 Agent 在两次交互之间,预测你接下来可能要问什么,并提前把材料备好。作者来自上海交通大学和 Tencent,构造了一个叫 ProActEval 的基准(40 个领域、200 个场景),把 Agent 拉进一个"必须主动"的考场。
效果数字也挺能打:任务完成所需的轮次降了 14.8%、用户操作成本降了 11.7%、幻觉率掉了 28.1%。在另一个记忆基准 MemBench 上也拿到了 SOTA。
但我读到一半的时候眉毛就抬起来了——收益不是来自"空闲时间多花了 token"这件事本身,而是来自一个更具体的子事实:单纯放开搜索预算其实没用,必须把算力精准导向预测出来的需求。这个区分非常关键,下面会展开。
论文信息
- 标题:Anticipate and Learn: Unleashing Idle-Time Compute in Proactive Agents
- 作者:Haoyi Hu, Qirong Lyu, Xianghan Kong, Weiwen Liu, Jianghao Lin, Zixuan Guo, Yan Xu, Yasheng Wang, Weinan Zhang, Yong Yu
- 机构:上海交通大学 / Tencent
- arXiv:2605.25971
- 代码:github.com/AgentACE-AI/ProAct
一、为什么"被动 Agent"是个问题
回想一下你最近用 ChatGPT 或者类似工具做一个稍微复杂点的事——比如让它帮你准备一个项目评审会。
你先问它:"明天 10 点开个项目评审,把会议安排上。"它说:好的,安排上了。然后呢?什么也没发生。第二天你想起来了,又过去问:"能不能给我准备 10 页 executive 风格的幻灯片,要包括项目进展、风险、下一步、图表、演讲备注……"它说:好的,我现在去搜资料整理。
整个流程里有一段巨长的空白——从"安排好会议"到"用户回来要 PPT",可能是几个小时甚至一晚上。这段时间里 Agent 完全闲着,但其实它已经掌握了足够多的信息(项目名、评审目的、用户身份),可以推测出来"这个人接下来八成要 PPT、要议程、要风险清单"。
ProAct 的图1 把这个对比画得特别清楚:
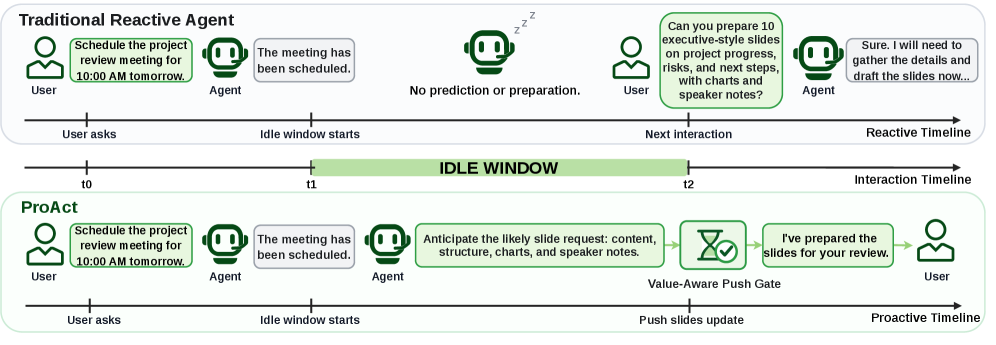
图1:被动 vs 主动两种范式的时间线对比。中间那段绿色的 IDLE WINDOW 是这篇论文真正想抢回来的资源。
我看到这张图的第一反应是:这个问题在工程里其实并不新鲜。很多产品团队都做过"提前预取"——浏览器预渲染、IDE 后台 build、推荐系统的离线召回——说到底都是在用空闲资源换交互延迟。但是把这个思路系统化地塞到 LLM Agent 里,并且认真定义"什么算预测正确、什么算干扰用户、什么算白干一场",这个论文倒是头一份做得比较系统的。
不过我也得提一个怀疑:用户真的需要 Agent 在背地里偷偷干活吗?这个动机其实有点工程化美学的味道——"算力闲着就是浪费",听起来很对,但实际部署里很多用户会反感"还没问就给我推一堆"的体验。论文后面也确实承认了这点(精确率-召回率解耦的部分),不过我们先把它的方法看完再说。
二、ProAct 是怎么设计的
整个系统拆成 4 个模块,论文图2 把架构画清楚了:
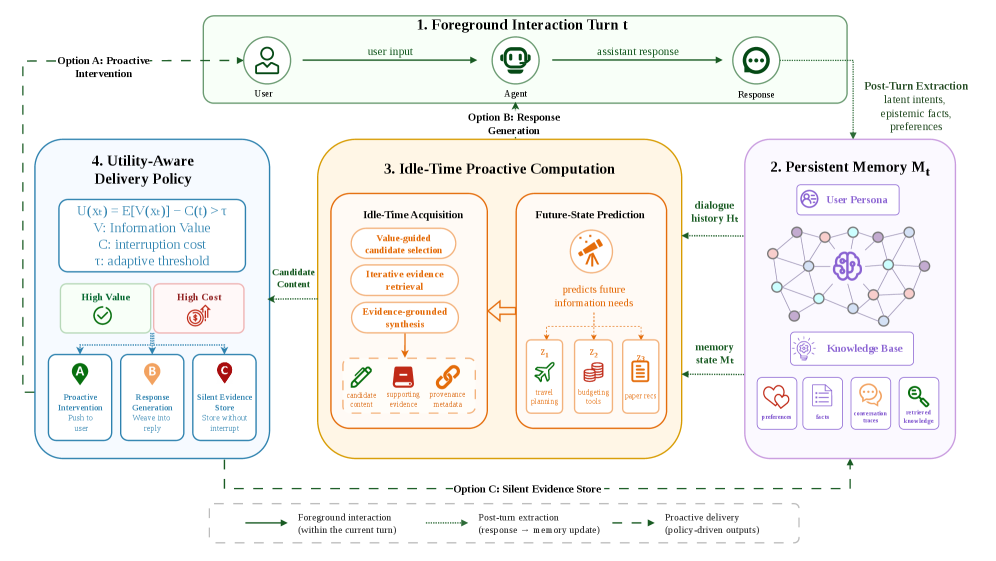
图2:ProAct 的 4 个模块。重点不是"主动搜索",而是橙色那块——Future-State Prediction 在指挥 Idle-Time Acquisition 该搜什么。
我把这 4 个模块用更直觉的话翻译一下:
| 模块 | 一句话讲它在干嘛 |
|---|---|
| 1. 前台交互(Foreground Interaction) | Agent 跟你正常对话,跟普通 Agent 没区别 |
| 2. 持久记忆 \(M_t\) | 把每轮的潜在意图、事实、偏好抽出来沉淀下来 |
| 3. 空闲时段主动计算 | 用户不在时,先预测你接下来想问什么,再去搜对应资料 |
| 4. 效用感知交付 | 准备好了,到底要不要主动推给你?还是默默存着 |
模块 3 是这篇论文真正的核心,里面又分成两个子模块——预测什么 和 怎么获取。
2.1 Future-State Prediction:预测你接下来要问啥
候选需求的来源有两种:
局部场景预测:从当前对话历史 \(H_t\) 推断短期需求。比如你刚说"安排明天 10 点项目评审",模型就猜你接下来可能要 PPT、议程、参会人列表。
关联扩展:从持久记忆 \(M_t\)(用户画像、对话摘要、过往事实)推断长期需求。比如你的 profile 里写着"在做 X 项目",那么和 X 相关的领域动态、新闻、技术更新都可能是候选。
还有一个细节比较巧——Memory-gap 增强。系统会主动检查记忆里哪些信息已经过时或缺失,把这些缺口也变成候选需求。比如它知道你三个月前在用某个工具的某个版本,那它就会去查"现在这个工具的最新版本变了什么"。
候选生成完之后过两道关:置信度阈值 \(\theta_{\text{conf}}=0.6\) 砍掉低置信的,去重并按主题分组。
2.2 Idle-Time Acquisition:怎么去搜
光预测出"用户可能要问 PPT"还不够,还得去搜实际的资料。这里作者设计了一个价值打分函数:
四个分量分别是:
- \(r_z\):和用户的相关性
- \(g_z\):知识缺口(记忆里有没有,有没有过时)
- \(v_z\):增量价值(搜到了能多带来多少东西)
- \(\tau_z\):时效性(信息会不会很快过期)
默认权重都是 0.25,价值阈值 \(\theta_{\text{val}}=60\)(0-100 量表)。说实话这种线性加权打分在工程里太常见了——简单粗暴,可解释,能调。我个人觉得这部分没什么"创新"可言,但作为一个 baseline 实现是很合理的。
搜索完会生成一个带溯源的紧凑工件 \(A_z\)——这点在我看来是工程上最值得抄的地方,因为它直接决定了后面"幻觉率下降 28.1%"那个数字。提前搜出来的内容自带 provenance(来源标记),用的时候模型有据可依,幻觉自然就少。
2.3 Utility-Aware Delivery:到底要不要打扰用户
准备好了之后,三种处理方式:
- Push(主动推送):直接打断用户当前流程,告诉他"我提前帮你准备了 X"
- Queue(响应时使用):用户下次来问时直接调出来用
- Store(静默存储):只存到记忆里,下次用得到时再说
打分公式叫 PushScore:
V 是信息价值,C 是打断成本。推送阈值 40,高优先级阈值 70。
这个设计我挺欣赏的——它承认了"主动"是有成本的。你不能一有发现就 push,那比 reactive 还烦。论文后面也确实观察到,太激进的 push 会带来"主动内容挤占响应"的回退现象。
2.4 整体优化目标
把上面这些拼起来,整篇论文的优化目标可以写成:
未来效用要最大化,但同时要扣掉打断成本、算力预算和幻觉风险。形式化看着挺漂亮,但实操中这几个 \(\lambda\) 怎么定?论文里我没看到很系统的论证,主要靠默认值和阈值扫一扫。这个我后面会再吐槽。
三、ProActEval:一个让 Agent 必须"主动"的考场
光有方法不行,得有评估基准——而且现成的基准都没法考"主动能力",因为传统基准都是"用户问什么,Agent 答什么"。
所以作者自己造了一个:ProActEval,40 个领域 × 5 个场景 = 200 个完整场景。
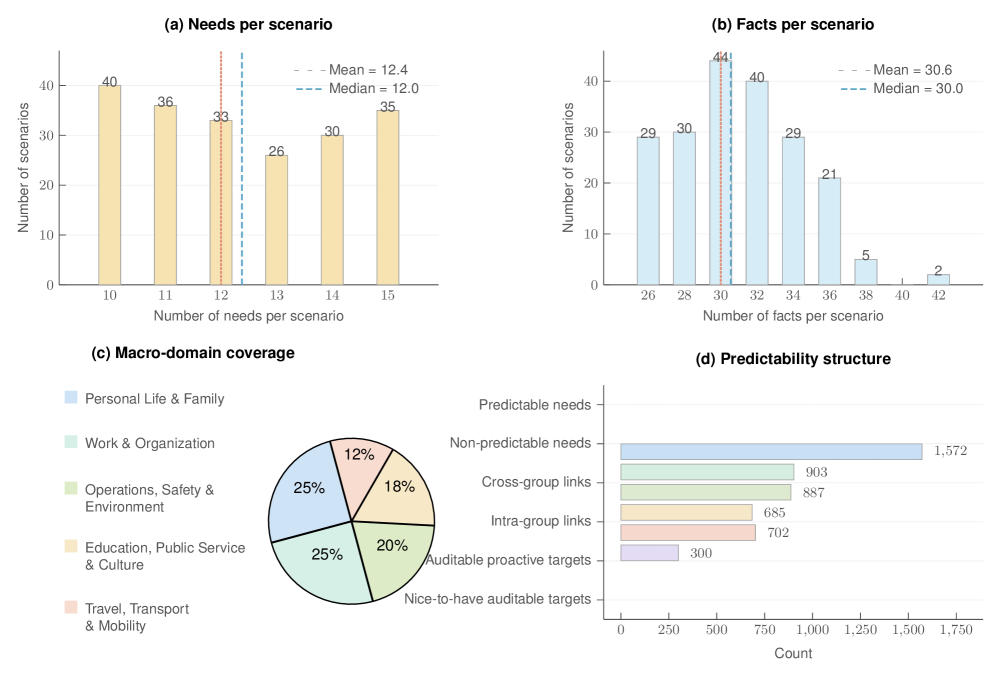
图4:ProActEval 的统计画像。重点看 (d) 那张图——1572 个非预测需求 vs 300 个 must-have 主动目标,比例接近 5:1,意思是大部分 turn 还是 reactive 的,proactive 其实是个"少数事件"。这个比例设计得挺克制的。
每个场景由几个东西构成:
- Fact Sheet:原子事实+稳定标识符
- User Needs:每个需求有重要性标签、所依赖的 fact ID、轮次顺序、
predictable_after字段(标注从哪一轮起这个需求就可以被预测了) - Reveal Groups:建模主题切换和局部主题结构
还设计了 5 种用户认知原型:基础记忆、转换与缺口解决、追踪与依赖推理、交接与一致性控制、准备与跟进。这个分类我觉得挺有意思——它在试图把"什么样的认知任务最适合主动 Agent"也分类清楚。后面消融实验里也确实发现:Trace and Dependency Reasoning 收益最大(\(T_{100}\) 减少 1.48 轮),因为这种任务有明确的因果/时间链作为预测锚点。
评估指标 7 个,分三组:
- 效率:\(T_{80}\)、\(T_{100}\)(达到 80%/100% 覆盖所需的轮次)、User Effort
- 事实完整性:Fact Accuracy、Hallucination Rate
- 覆盖:Total Coverage、Must-Have Coverage、Anticipation Recall
Anticipation Recall 是这里最关键的指标——它直接衡量"模型预测了多少个真正出现的需求",是用来区分"真主动"和"瞎搜"的。
四、实验:哪些数字真有说服力
4.1 主表:ProAct vs Reactive
200 个场景的完整结果如下:
| 指标 | Reactive | Undirected Idle | ProAct(Directed) | vs.Reactive | vs.Undirected |
|---|---|---|---|---|---|
| \(T_{80}\)↓ | 6.615 | 6.600 | 5.530 | -16.4% | -16.2% |
| \(T_{100}\)↓ | 8.110 | 8.040 | 6.910 | -14.8% | -14.1% |
| User Effort↓ | 9.140 | 9.040 | 8.075 | -11.7% | -10.7% |
| Total Coverage↑ | 0.892 | 0.905 | 0.956 | +7.2% | +5.6% |
| Must-Have Coverage↑ | 0.938 | 0.950 | 0.977 | +4.2% | +2.9% |
| Anticipation Recall↑ | 0.000 | 0.000 | 0.428 | +0.428 | +0.428 |
| Fact Accuracy↑ | 0.972 | 0.972 | 0.985 | +1.3% | +1.3% |
| Hallucination Rate↓ | 0.132 | 0.124 | 降至 0.095 | 降 28.1 个点 | -23.1% |
| Active Tokens | 0 | 69.8k | 111.8k | +111.8k | +42.0k |
第一眼看主表会觉得"哦,全面提升"。但我建议你重点盯第三列和第四列的对比——那才是这篇论文真正在论证的事。
4.2 关键消融:单纯"花更多算力"几乎无效
这是这篇论文里我觉得最值钱的发现。看 Reactive vs Undirected Idle 这一行:
- Undirected Idle 多花了 69.8k 个 token,但 \(T_{100}\) 只降了 0.9%、User Effort 只降了 1.1%
- Anticipation Recall 是 0——也就是说它瞎搜了一堆,一个真实需求都没命中
而加上预测引导之后(Directed Idle):
- 又多花了 42k 个 token
- \(T_{100}\) 直接降了 14.1%、User Effort 降了 10.7%
- Anticipation Recall 从 0 跳到 0.428
这说明什么?——空闲时段算力本身没有价值,价值来自"把算力精准导向预测出来的需求"。
这个对比让我想到推荐系统里的一个老问题:召回扩到 1 万和召回扩到 10 万,差别可能远没有"召回质量提升 30%"来得大。盲目扩规模和精准制导,是两件事。
4.3 搜索预算:不是越多越好
作者在 50 场景子集上扫了 \(k \in \{4, 8, 12, 16\}\):
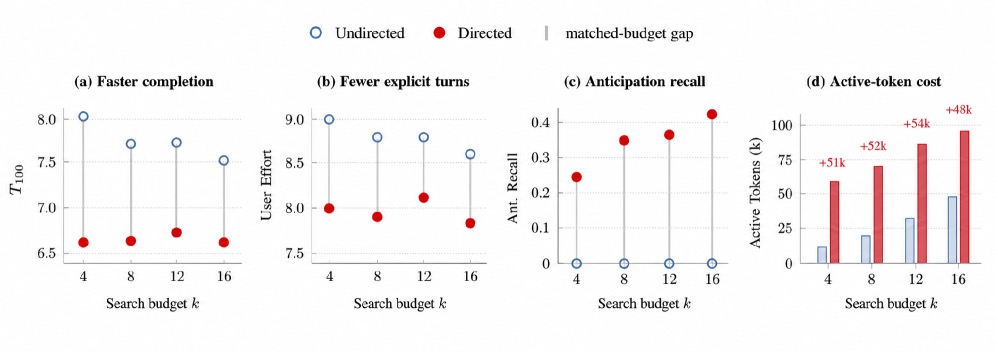
图3:扩搜索预算的代价收益曲线。Anticipation Recall(c)在涨,但 \(T_{100}\) 和 User Effort(a, b)在 k=8 之后就基本平稳了。
作者得出的结论是:搜索预算应该当作一个 trade-off 操作点,而不是最大化目标。Recall 涨不代表用户真的少打字了——很多被命中的需求,用户其实自己也很快能搞定。
这个观察相当克制,也是我对这篇论文好感最大的地方之一。它没有用"k 越大越好"的方式来吹自己,反而坦白说"差不多到 k=8 就别再加了"。
4.4 vs ProactiveAgent:不是同一个层次的"主动"
| 方法 | \(T_{80}\)↓ | \(T_{100}\)↓ | User Effort↓ | Judge Ant.R↑ | 命中需求 |
|---|---|---|---|---|---|
| ProactiveAgent (Lu et al. 2024) | 5.600 | 7.145 | 8.425 | 0.020 | 32/1572 |
| ProAct | 5.530 | 6.910 | 8.075 | 0.447 | 703/1572 |
这里值得注意的细节:ProactiveAgent 在 1173 轮(69.6%)里都生成了非空的 Proactive_Task,但只命中了 32 个真实可预测需求。也就是说它一直在"主动",但绝大部分主动是无效的。
ProAct 命中了 703 个,差了一个数量级。这说明真正起作用的不是"是否生成主动行为",而是"生成的主动行为是否锚定了未来真实需求"。这个对比挺漂亮的。
4.5 MemBench:顺手在记忆评测上拿了个 SOTA
作为额外验证,作者在 MemBench 上测了一下记忆能力:
| 方法 | 10k tokens | 100k tokens |
|---|---|---|
| FullMemory | 0.733 | 0.533 |
| RecentMemory | 0.700 | 0.333 |
| RetrievalMemory | 0.692 | 0.833 |
| GenerativeAgent | 0.742 | 0.333 |
| MemoryBank | 0.692 | 0.400 |
| MemGPT | 0.733 | 0.367 |
| SCMemory | 0.542 | 0.267 |
| ProAct | 0.843 | 0.863 |
10k 上从 0.742 拉到 0.843(+10 个点),100k 上从 0.833 拉到 0.863(+3 个点)。最有意思的是 100k 这一档——很多 baseline 在长上下文下急速退化(0.5+ 跌到 0.3),但 ProAct 几乎没退化,说明它的记忆机制对上下文长度的敏感性比较低。
不过这里我得插一句——MemBench 的提升其实更可能来自 ProAct 的 Memory 模块设计(持久记忆 + memory-gap 增强),不一定是 idle-time compute 起的作用。论文没有把这两个因素彻底解耦开来跑 MemBench,这是一个可以挑刺的点。
五、我的几点判断
5.1 真正的贡献是什么
这篇论文的"创新"如果用一句话概括:它把"主动"这个概念从模糊的产品愿景,落地成了一套可衡量、可消融、可对比的系统。具体来说:
- 设计了一个能区分"真主动"和"瞎主动"的指标:Anticipation Recall + Coverage 的组合,比单纯看 Hallucination 或者 Coverage 更全面
- 构造了一个强迫 Agent 做主动行为的基准:ProActEval 的
predictable_after字段是核心设计,没有这个字段就没法严格评估"提前预测" - 用消融实验证明了一个反直觉的事实:空闲时段算力本身没价值,必须有预测制导
第3点是这篇论文最有传播价值的洞察。我之前自己也想过"是不是该让 Agent 在背地里多搜点东西",看完这篇之后我会重新思考——单纯放开搜索,可能就是在浪费 token。
5.2 哪些地方让我皱眉
第一,痛点的真实性还有疑问。论文反复强调"被动 Agent 浪费了空闲算力",但说实话——大部分用户可能并不希望 Agent 在背地里偷偷调 LLM 推理。每一次主动搜索都是真金白银的 token 消耗。论文的实验里平均每场景多花了 111.8k token——把这个成本平摊到几亿用户上,账单不一定能 cover 11.7% 的"用户操作降幅"。
第二,PushScore 这套阈值像是手调的。\(\theta_{\text{conf}}=0.6\)、\(\theta_{\text{val}}=60\)、推送阈值 40、高优先级 70——这些数字看着规整,但论文没有给出系统的敏感性分析。换一个 LLM 当 backbone,这些阈值还能不能用,是个未知数。
第三,评估闭环是合成的。ProActEval 完全用虚构实体构造,user simulator 也是 LLM。这种设置好处是干净可复现,坏处是真实部署里用户行为的不确定性、上下文切换、隐私敏感度、多模态干扰,全都没考虑进来。论文也在 limitations 里坦白了这一点,我不算苛求,但读者得心里有数。
第四,那个"精确率-召回率解耦"现象。192/200 场景有非零的 Anticipation Recall,但其中 82 个 User Effort 没下降——也就是说你预测对了,但用户没省事。这个比例不算小(41%!),其实暴露了一个更本质的问题:预测对≠对用户有用。论文给出的解释是"高主题碎片化场景收益较小"和"Reactive 兼容性回退",但我觉得这个现象本身就值得作为下一篇论文的核心问题。
5.3 工程上能抄什么
如果你也在做 Agent 系统,我觉得有 3 个点值得直接借鉴:
- 空闲时段做带溯源的资料预备——这是幻觉率下降 28 个点的关键。不是预测多准,而是预先给后续生成钉了证据钩子
- 打分函数 + 阈值门控的交付策略——别让所有"主动行为"都直接 push 给用户,分 push/queue/store 三级是最低限度的产品克制
- 拒绝盲目扩搜索——论文已经替你试过了,从 k=8 之后再扩,token 涨一倍但用户没什么感知
5.4 这篇放在 Agent 领域的位置
我个人觉得这篇论文的贡献定位是把一个工程直觉系统化,不是底层突破。LLM Agent 的"主动"想法早就有人提过(论文里也引了 Lu et al. 的 ProactiveAgent),但前人的工作要么没有像样的评估基准(ProactiveAgent 命中率才 0.02),要么没有把"预测制导"这件事拎出来单独做消融。
它的位置类似于 RAG 领域的某些早期工作——idea 不算新,但把它做得严谨、可衡量、能复现,本身就是有价值的研究。
六、一句话总结
如果你的 Agent 系统每天有大段时间在空转,但你又懒得改架构去做"主动预备",这篇论文给了你一个具体的施工蓝图:预测 → 价值打分 → 带溯源采集 → 分层交付。
但如果你只是想让 Agent 在闲着的时候多搜点东西、多花点算力——别费劲了,那样做几乎没有收益。
主动的关键是制导,不是用力。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我