该不该把这条会话存进 Agent 记忆?这篇论文说:先看是哪个用户
论文标题:Personalize-then-Store: Benchmarking and Learning Personalized Memory for Long-horizon Agents 作者:Yeonjun In, Wonjoong Kim, Sangwu Park, Kanghoon Yoon, Chanyoung Park(KAIST) arXiv:2605.25535 代码与数据:github.com/yeonjun-in/PerMemBench
如果你做过任何带"长程记忆"的 Agent 产品,大概都会撞到一个相同的痛点——
记忆预算总是不够用。
不管你用的是 Mem0、Memory-R1、还是 RMM 这种最新的工业级记忆系统,最终都要回答同一个问题:这次会话要不要写进长期记忆? 现在主流的回答方式很粗暴——按一套统一的启发式规则(事实抽取、重要度打分、时间衰减驱逐)一刀切处理所有用户。
这篇 KAIST 五月底刚挂出来的论文,把这件事拆开看了一下,给出一个我觉得挺有意思的判断:这套"通用记忆策略"的设计哲学本身就是有问题的,因为同一条会话对不同用户的价值完全不一样。
更重要的是,他们没停在"提个观点",而是真的搭了一套基准(PerMemBench)、做了对照实验,最后得出一个让人挺意外的结论——个性化的潜力很大(Oracle 上界比通用策略高出一大截),但当前所有现成的门控方法都还没法把这个潜力兑现。
这就有点像那种"问题被诚实地提出来了,但解法还没收敛"的论文。但恰恰是这种论文,对工程团队最有参考价值——它告诉你这个坑在哪,深度多少,目前哪条路是死胡同,剩下的就看你怎么挖。
来仔细聊聊。
一、问题:为什么"统一记忆策略"是个伪命题?
先看作者画的这张图,它把核心矛盾讲得非常直白:
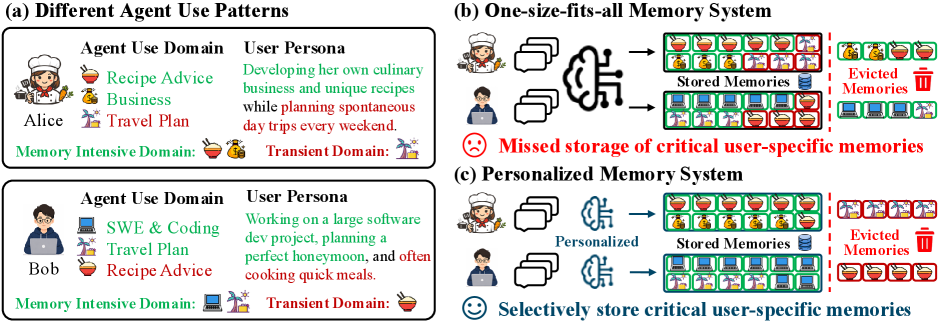
图 1:(a) Alice 把"食谱建议"当作长程项目(自己创业、研发独家菜谱),"旅行计划"是周末说走就走的临时查询;Bob 完全相反——"旅行计划"是认真规划蜜月的长程项目,"食谱建议"反而是赶时间糊弄一顿的临时使用。(b) 一刀切的记忆系统按统一规则处理,导致每个用户真正需要保留的关键上下文反而被驱逐。(c) 个性化记忆系统按用户使用模式选择性保留。
这个例子的精妙之处在于——两个用户完全相同的"领域偏好",对应着完全相反的记忆价值。
我第一反应是:这个观察其实很多做 Agent 的团队都有模糊的感觉,但很少有人把它拎出来当作一个独立问题在做。大家更习惯往"事实抽取更准"、"语义检索更好"、"摘要更紧凑"这些方向使劲。
但你想想看,再准的事实抽取,前提也是这条会话应该被写进记忆。如果一开始就把 Alice 周末的随机旅游问询当成长程偏好存了下来——后面她真正需要的"独家菜谱研发进度"反而被预算上限挤掉,那再好的检索都救不回来。
写入决策才是上游。这是这篇论文的第一个判断,我觉得是对的。
二、核心摘要:一句话讲清这篇论文做了什么
如果只能讲一段,是这样:
作者指出主流 LLM 记忆系统都用"通用静态策略"——对所有用户用同一套写入/驱逐规则——这浪费了大量记忆预算在临时性会话上,挤掉了真正长程的上下文。他们构建了 PerMemBench(首个个性化记忆评估基准,跨 20 个领域、20 个用户、最长 28 个月的交互历史),并提出 会话级存储门控(session-level storage gating)——在会话写入记忆前先判断"对这个用户是不是值得存"。Oracle(用真实用户画像门控)下记忆留存率(RR)显著高于通用策略,证明个性化潜力巨大;但他们设计的三种实际门控方法(Greedy、Context-aware、Structure-aware)几乎都跑不赢通用策略——Structure-aware 虽然 F1 最高,但遇到用户兴趣转变就立刻崩盘。结论很坦诚:个性化是对的方向,但门控本身仍然是一个开放难题。
这种"立靶子—证明靶子值钱—承认还没射中"的诚实结构,在 LLM 记忆这个被各种 SOTA paper 刷得很热的赛道里,其实挺难得。
三、PerMemBench:一个把"行为异质性"做进数据的基准
要研究"个性化",第一道坎是数据。
现有的长程对话基准——LoCoMo、PersonaMem、LongMemEval、AmemGym、DialSim——大多聚焦"长上下文检索"或"persona 一致性",但没有一个明确把用户使用模式的差异性作为核心变量。你想想看,它们的数据里 Alice 和 Bob 在"旅行规划"领域的会话价值是同质的,没有那种"对你是长程对他是临时"的对照样本。
作者花了大力气把这件事补上了。
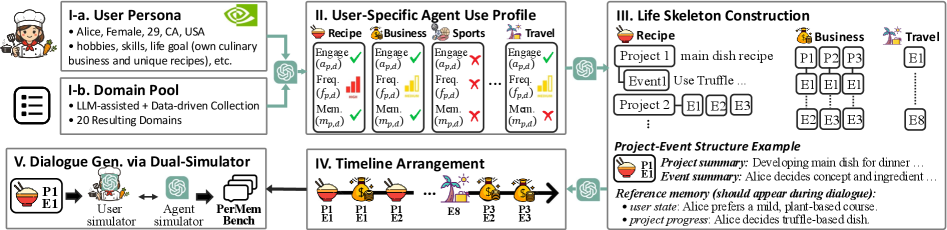
图 2:PerMemBench 的构建流程。(I) 从 Nemotron-Personas-USA 抽取真实人物 persona + 构建 20 个领域池;(II) 为每个用户在每个领域上推断"使用画像"(Engagement、Frequency、Memory Intensity 三维标签);(III) 在 Memory-Intensive 领域里搭"项目-事件"结构(Life Skeleton),在 Transient 领域只生成孤立事件;(IV) 把 Project 和 Event 在时间轴上铺开;(V) 用 User Simulator 与 Agent Simulator 对话,生成最终对话数据。
我特别想聊聊第二阶段——用户特定的领域使用画像(User-Specific Profile Assignment)。
每个 (用户, 领域) 二元组会被标注三个维度:
- Engagement:用户在这个领域到底有没有兴趣(不是兴趣的领域可能根本不会触发对话)
- Frequency:使用频率
- Memory Intensity:使用模式是"长程项目导向"还是"临时一次性"
第三个维度就是这篇论文想抓住的核心区分。Alice 在"食谱"上是 Memory-Intensive(长程),在"旅行"上是 Transient(临时);Bob 反过来。这种结构上的差异才是数据集独有的信号。
而且他们做了一件挺重要的事——验证了不同用户的画像确实不一样:
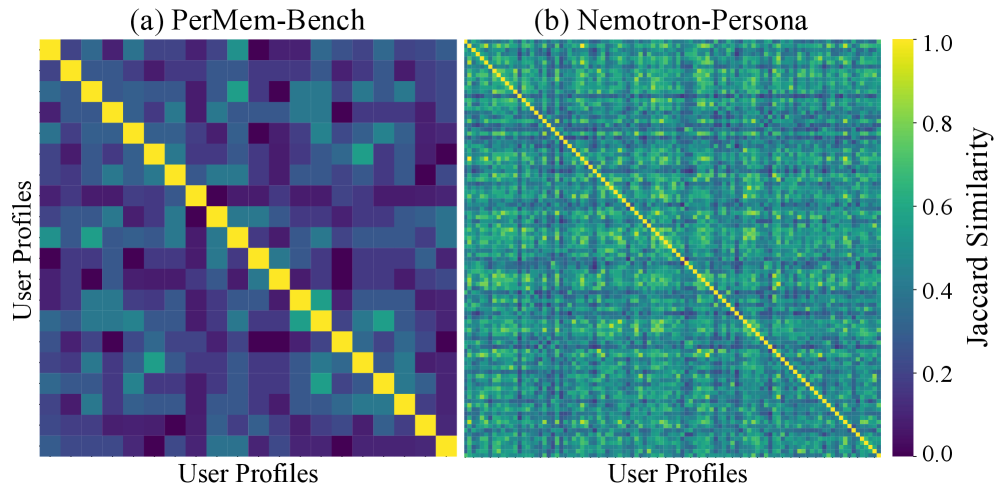
图 3:(a) PerMemBench 20 个用户两两之间的画像 Jaccard 相似度,对角线是自己和自己(=1),其他大部分都很低,证明数据集里的用户画像彼此差异显著;(b) 来自 Nemotron-Persona 的 100 个随机用户,相似度普遍偏高一些(绿色更多),但仍没有完全相同的对。
说实话,这张图其实在替整个论文背书——如果用户之间画像高度相似,那"个性化"就是个伪问题,研究通用策略就够了。结果显示用户画像确实结构性不同,所以"个性化记忆"的研究前提是成立的。这一步很扎实。
数据集规模
| 指标 | PerMemBenchs(短版) | PerMemBenchd(长版) |
|---|---|---|
| 平均会话数 | 54 个 | 104 个 |
| 时间跨度 | 17 个月 | 28 个月 |
| 总 Token 量 | 平均 314K | 平均 634K |
| 单会话 Token | ~5.8K | ~6.1K |
| 参考记忆条目 | 53 条 | 97 条 |
| 用户数 | 20 | 20 |
| 领域数 | 20 | 20 |
最长跨度的用户超过两年、上百万 tokens——对于评估"长程记忆"来说,这个时间维度是真的有意义。LoCoMo 之类的基准最多到 35 轮对话,跟这里完全不在一个量级。
数据生成质量
人工标注三阶段验证:
| 阶段 | 质量得分 | Gwet's AC1 一致性 |
|---|---|---|
| 1. Profile 合理性 | 99.5% | 99.0% |
| 2. Life Skeleton & Timeline 真实性 | 100% | 100% |
| 3. 对话质量 | 98.4% | 96.9% |
数字漂亮归漂亮——但我得提一句,用 Claude-Haiku-4.5 / GPT-5.4 / GPT-5.1 这套合成的对话数据,跟真实生产环境的会话分布之间还是有 gap 的。这个数据集最适合做的是受控对照实验,但要拿这上面的结论直接外推到真实业务,还是要小心。作者自己在 Limitation 里也提到了这点。
附录里他们还放了三张人工标注界面截图(profile、life skeleton、dialogue),从我读的感觉看,整个流程做得挺认真的,不是甩个 prompt 让 GPT 跑一通就完事。
四、核心方法:会话级存储门控(Session-Level Storage Gating)
数据有了,问题就清晰了:给定一条新会话,能不能在它进入记忆系统之前先判断"对这个用户值不值得存"?
这个想法本身不新——早在传统对话系统时代就有人做过 turn-level 的 importance scoring。但作者把它放到当代 LLM 记忆系统的语境下重新提了一遍,并且明确说:门控应该作用在 session 级别,而不是 turn 级别。理由是:
- 单个 turn 信息量太碎,难以判断"是否长程"
- 主流记忆系统(Mem0、RMM)的写入接口本来就是 session 粒度的
- session 级别能让门控复用 LLM 自身的推理能力(in-context 判断)
然后他们设计了三种由弱到强的门控方法:
方法一:Greedy(最简单)
只看当前会话本身,截断到 max_chars,输入 LLM 问一句:
prompt = f"""Given the dialogue session, decide if it requires long-term memory.
Dialogue: {session_text}
Output: {{"memory_required": <true|false>}}"""
无历史、无画像、纯靠 LLM 当下的判断。
方法二:Context-aware
每个会话存一份 1-2 句的摘要到缓冲区。判断时把最近 K 个会话的摘要拼进上下文:
[Past sessions summary]
- Session_t-3: 用户在帮孩子做作业,问数学题
- Session_t-2: 用户提到要给孩子换学校
- Session_t-1: 又问了一道几何题
[Current session]
{当前对话}
Memory required?
期待 LLM 能"看上下文趋势"做更准的判断——比如发现用户在"孩子教育"上其实是有连续脉络的,单个数学题不是孤立的。
方法三:Structure-aware(最强)
这是论文里最有意思的设计。它不是简单地堆历史摘要,而是主动维护一份结构化的用户使用笔记:
{
"projects": [
{
"project_id": "P1",
"topic": "孩子教育与学校选择",
"session_ids": [12, 15, 18, 22],
"status": "ongoing"
},
{
"project_id": "P2",
"topic": "家庭旅行规划",
"session_ids": [9, 14],
"status": "completed"
}
],
"isolated_sessions": [
{"session_id": 17, "topic": "查菜谱"},
{"session_id": 21, "topic": "天气查询"}
]
}
每 K 个会话更新一次这份笔记。判断当前会话时: - 如果当前会话能 attach 到某个 project → 值得存储 - 如果只能进 isolated_sessions → 临时性,不存
而且这里有个我觉得挺漂亮的细节——追溯重新分配(retroactive reassignment):之前以为是孤立的会话,发现后续有相关项目时,可以重新归到 project 里。这个机制让笔记本身能"反思"。
整个流程不需要训练,全部靠 prompt 工程 + LLM 推理(温度 0)。这一点在工程上算是个减分项也算是个加分项——好处是部署门槛低、可以热更新;坏处是性能上限被 LLM 自身的 instruction following 能力卡死。
两个参考点
- Universal:完全不门控,所有会话都按记忆系统的默认策略处理(这就是 Mem0/RMM 等系统现在的部署方式)
- Oracle:用真实的用户使用画像门控(性能上界,模拟"如果我们能完美判断该不该存"的效果)
五、实验:有意思的地方在于"反直觉"
实验主表先看:
5.1 门控本身的分类能力(Table 2)
PerMemBenchs(短版)
| LLM | 方法 | F1 ↑ | FNR(漏存)↓ | FPR(误存)↓ |
|---|---|---|---|---|
| Qwen3-14B | Greedy | 0.660 | 0.457 | 0.117 |
| Qwen3-14B | Context | 0.434 | 0.715 | 0.008 |
| Qwen3-14B | Structure | 0.844 | 0.115 | 0.280 |
| gpt-5-mini | Greedy | 0.733 | 0.301 | 0.259 |
| gpt-5-mini | Context | 0.751 | 0.287 | 0.211 |
| gpt-5-mini | Structure | 0.795 | 0.018 | 0.652 |
PerMemBenchd(长版)
| LLM | 方法 | F1 ↑ | FNR ↓ | FPR ↓ |
|---|---|---|---|---|
| Qwen3-14B | Greedy | 0.657 | 0.444 | 0.178 |
| Qwen3-14B | Context | 0.477 | 0.665 | 0.071 |
| Qwen3-14B | Structure | 0.805 | 0.110 | 0.461 |
| gpt-5-mini | Greedy | 0.715 | 0.287 | 0.378 |
| gpt-5-mini | Context | 0.733 | 0.261 | 0.375 |
| gpt-5-mini | Structure | 0.784 | 0.010 | 0.782 |
光看 F1,Structure-aware 完全压制——0.84 vs 0.66/0.43,差距不小。
但仔细看 FPR 你会愣一下:Structure-aware 在 gpt-5-mini 上的 FPR 高达 0.65~0.78——意思是 65~78% 的临时会话被误判为"值得存"。它的高 F1 是靠把所有东西都倾向于"存"换来的(FNR 极低,0.018 / 0.010)。
这是 prompt 工程做出来的方法的典型 failure mode——LLM 在 prompt 里被告知要识别项目,它就会倾向于把更多东西归到 project 里来完成任务。
Qwen3-14B 反而 FPR 控制得好一些(0.28 / 0.46),但代价是 F1 略低。
这其实是个很值得记下来的工程教训:用 LLM 做二分类,看 F1 容易被骗,必须把 confusion matrix 完整看一遍。
5.2 门控对最终记忆留存的影响(Figure 5)
这才是真正决定胜负的指标——把门控接到 Mem0、Memory-R1、RMM 三套真实记忆系统上,看 Memory Retention Rate(RR):
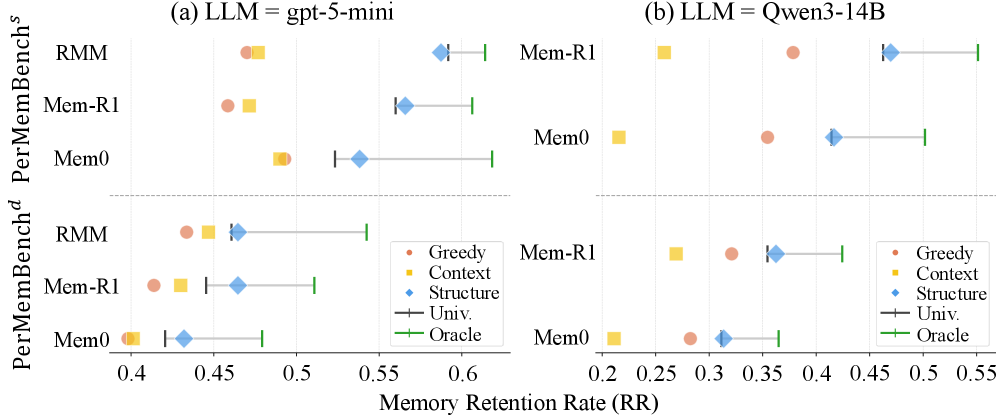
图 5:每行是一个 (基准, 记忆系统) 组合。圆点 = Greedy,方块 = Context,菱形 = Structure,左侧黑短杠 = Universal(无门控基线),右侧绿短杠 = Oracle(上界)。关键观察:Universal 和 Oracle 之间存在显著 gap,但三个门控方法(彩色点)大多数都没把 Universal 推过去。
直观结论:
- Oracle 显著高于 Universal——平均 6~10 个百分点的留存率提升空间。这证明个性化的潜力是真实存在的。
- 三种门控方法基本都打不过 Universal——Greedy 和 Context 在大多数 setting 下甚至比 Universal 还差。Structure-aware 在 gpt-5-mini 上勉强追平或略超 Universal,在 Qwen3-14B 上倒是稳定超出一些。
- Oracle 和最佳门控方法之间还有显著差距——说明潜力远没被吃掉。
我看到这个结果的第一反应是:"等等,这数据其实挺尴尬的——你证明了存在性问题,但没证明你的方法 work。"
但作者写论文的姿态我反而觉得挺让人尊敬——他们没去硬包装"我们方法 SOTA",而是直接把这个 gap 摆出来作为论文的核心 finding:
"Personalized memory is a promising direction, but accurate gating remains an open and critical challenge."
这种态度在 ML paper 里其实越来越少见了。
5.3 Profile Shift 才是真正的杀手(Figure 4)
这张图是我最喜欢的一张:
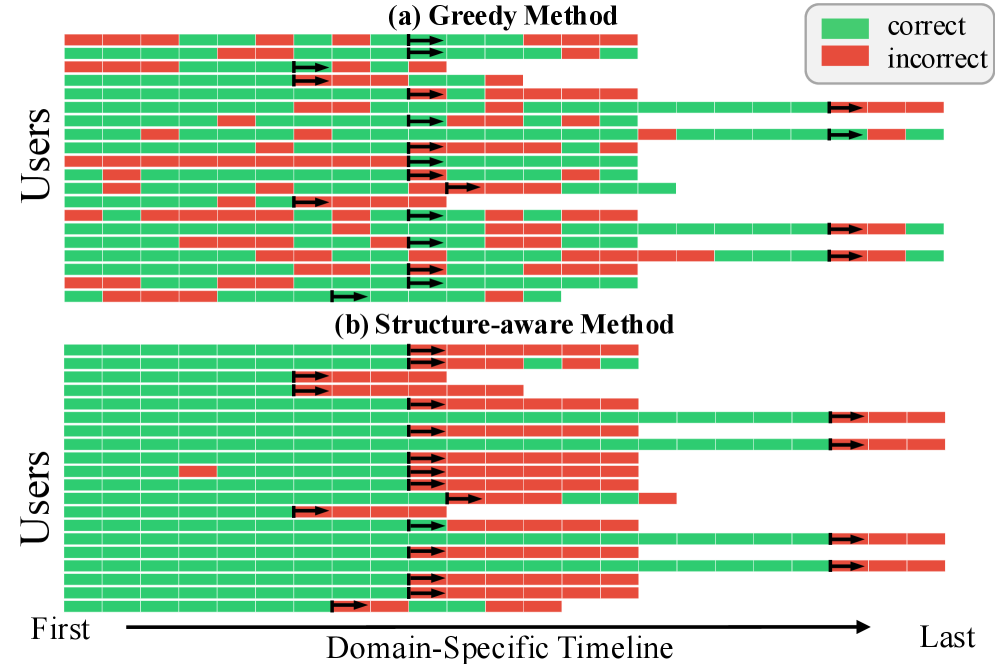
图 4:每一行是一个用户在某个领域上的时间序列,绿色 = 门控正确,红色 = 错误。黑色箭头标记"用户使用模式发生转变"的时间点(比如某个领域从长程项目变成只是偶尔用一下,或反过来)。(a) Greedy 方法在转变前后表现相对一致;(b) Structure-aware 在转变前一片绿(很准),转变后立刻一片红(崩了)。
我看完这张图的判断是:Structure-aware 不是真的"理解"了用户,它只是"记住"了用户当前的项目结构。
一旦用户换了兴趣方向(比如完成一个项目转向新项目,或者从长程使用切换成临时查询),它建立的那份"用户笔记"瞬间就不准了,但 LLM 并不会主动去推翻这份笔记,反而会继续按笔记内容判断——结果就是大面积错判。
这是个非常深刻的工程问题。用 LLM in-context 维护的所谓"状态",说到底就是 prompt 里的 frozen knowledge,对环境变化几乎没有自纠正能力。
相比之下 Greedy 没有"历史包袱",反而在转变点表现稳定——但代价是它从头到尾就不太准。
5.4 预算敏感性:个性化在紧预算下增益最大(Figure 6)
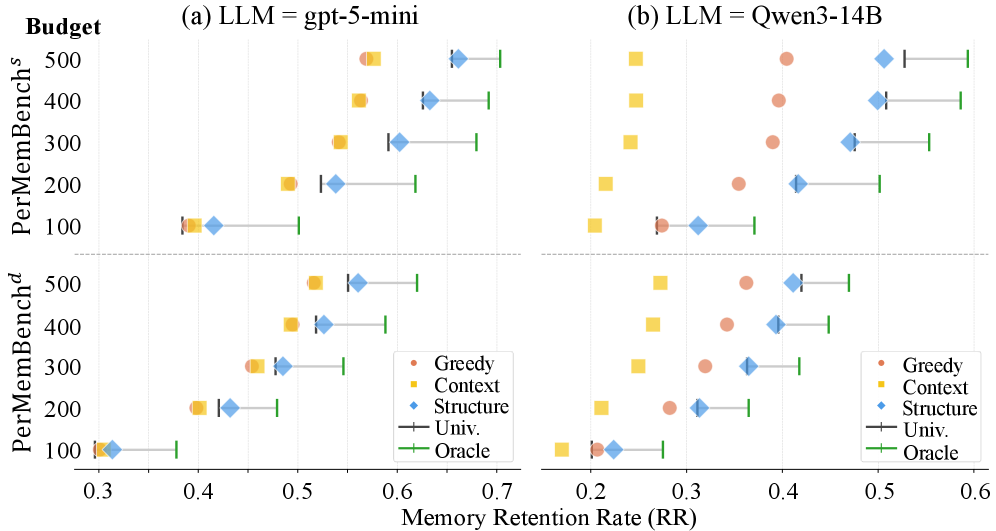
图 6:横轴是 Memory Retention Rate,纵轴是不同的记忆预算(100 / 200 / 300 / 400 / 500)。Oracle(绿)和 Universal(黑)之间的距离表示"个性化的潜在收益"。预算 100 / 200 时差距最大,500 时仍有改进。
这个发现挺合理的——预算越紧,"该存什么"的决策权重越大。预算无限的时候你随便存,反正都装得下;预算紧到 100 条记忆要管 28 个月对话时,每一条都得精挑细选。
工程上的意义:部署在端侧/手机/紧约束环境下的 Agent 记忆系统,更值得做个性化。云上无限存储的场景,个性化的收益要小一些。
六、几个值得记下来的细节
1. 为什么不用分类器训练?
我刚开始读的时候一直在想——这种二分类问题不是 BERT-class fine-tune 一下就能搞定吗?为什么非要用 prompt?
作者的隐含理由我猜是这样:
- 冷启动:每个新用户没有标注数据,传统分类器要重训一遍才能上线
- 领域泛化:用 prompt 至少能借 LLM 的世界知识跨领域迁移
- 可解释:Structure-aware 的"项目笔记"是人能读懂的中间产物,分类器是黑箱
但反过来——LLM-based 门控的成本确实高(每条会话都要跑一次 LLM 推理),延迟也大。这块我觉得后续工作有空间:能不能用一个小模型(如 0.5B)做基础门控,只在不确定时才 fallback 到大模型?
2. Memory Retention Rate 这个指标怎么算
公式是:
含义说人话就是:对每条"参考记忆" \(r\),从它第一次出现到目标会话之间所有时间步上,记忆库 \(\mathcal{M}_t\) 里到底有没有它,把这个命中率算出来再平均。
实际实现用 K=20 个等距检查点近似(首尾会话强制包含),不是真的每个 t 都查一遍——这是个工程优化,但也意味着如果一条记忆只在很短时间窗口被驱逐又重写入,可能漏掉。
3. RMM 只支持 session 粒度
实验里一个细节:Mem0 和 Memory-R1 都同时支持 turn-level 和 session-level 写入,但 RMM 只支持 session-level。所以表里 RMM 那些行就只有 session 粒度结果。这说明当前的记忆系统在写入接口上还没收敛,做横向对比要小心。
4. 评估用 gpt-5-nano 当 LLM Judge
"判断某条参考记忆是否还在记忆库中"用 gpt-5-nano 做 judge。这是个标准做法,但仍要警惕——judge 自己也会出错,特别是当记忆条目语义相近时。论文里没看到 judge 错误率的数据,这是个可以追问的点。
七、我的判断:这篇论文好在哪、不够在哪
真正的贡献
-
把"用户画像"明确引入记忆系统的写入决策——之前业界都聚焦"事实抽取更准"或"检索更好",写入门控基本是被忽略的。这篇正面提出"写入应该个性化",是有原创价值的。
-
PerMemBench 的设计——20 用户 × 20 领域、最长 28 个月、明确标注每个 (用户, 领域) 的使用模式——这种结构化的异质性数据,业界确实缺。即便方法部分还没收敛,光数据集就值得后续工作用。
-
诚实承认门控难题没解决——这点我是真的服。在一个 SOTA 满天飞的 RAG/记忆赛道,敢把"我的方法跑不赢 baseline"明明白白写在 abstract 里的论文不多。
不够的地方
-
门控方法本身没有实质创新——三种方法都是 prompt 工程,没有引入新的归纳偏置。Structure-aware 的设计虽然比另两个精巧,但仍然是 LLM in-context 操作,吃的还是大模型的能力红利。
-
Profile shift 这个真正的难题没给出解法——作者只是诊断出"Structure-aware 在 shift 后崩盘",但没设计 shift 检测/适应机制。这其实是后续工作的明显方向。
-
数据是合成的——尽管标注质量很高,但跨多月、多领域的真实用户对话数据分布,与 GPT 生成的 simulator 数据之间一定存在 gap。如果能补一个真实数据子集做 sanity check 会更有说服力。
-
没有和"基于 embedding 检索"的写入决策对比——其实工业界还有一种朴素思路:先看新会话的 embedding 是否能匹配已存的某个 cluster,如果不能匹配也不靠近任何 cluster 中心,就当作 transient。这种"无 LLM 门控"的方法没出现在 baseline 里,挺可惜。
工程启发
如果你正在做 Agent 记忆系统,这篇文章能直接拿走的几条:
-
写入决策值得单独设计一个模块,不要直接接死到记忆系统的内置规则里——给后续替换/迭代留接口。
-
预算紧的部署场景(端侧/小内存)优先做个性化门控——增益最大。
-
小心 LLM-based 门控的 FPR——别光看 F1,混淆矩阵每一格都得盯。
-
维护"用户使用画像"作为 Agent 系统的一等公民——不止用于记忆,还可以反哺检索权重、提示词调优、tool 选择等等。
-
要么不做用户结构感知,要做就必须考虑兴趣转变检测——否则你建立的所有用户画像在 shift 时都会变成误导信号。
八、一个开放问题
这篇论文最后留下的核心问题是:如何在没有训练数据、用户画像随时变化的前提下,做出准确的会话级门控?
我的直觉是这个问题的答案不会出在 prompt 工程里。可能的方向:
- 把"门控"从单步决策改成"延迟决策 + 后悔机制"——先全存,过 N 个会话后回看,把不必要的剔除
- 用"双时间尺度":fast loop 做 cheap heuristic 入口,slow loop 用大模型周期性 reorganize 记忆
- 把 user profile 显式参数化为可在线更新的小向量,用对比学习从用户行为序列里学
但这些都已经在论文之外了。从 PerMembench 出发,应该还会有不少后续工作冒出来。
附:标注界面三连图
论文附录里还展示了人工标注流程的三个 UI,做研究做得相当工整。如果你也在做需要密集标注的合成数据集,这套流程可以抄作业:
 Profile 合理性标注 UI——人工判断 LLM 推断的用户画像是否与 persona 描述吻合。
Profile 合理性标注 UI——人工判断 LLM 推断的用户画像是否与 persona 描述吻合。
 Life Skeleton 与时间线真实性标注 UI——验证生成的项目-事件结构是否符合真实生活节奏。
Life Skeleton 与时间线真实性标注 UI——验证生成的项目-事件结构是否符合真实生活节奏。
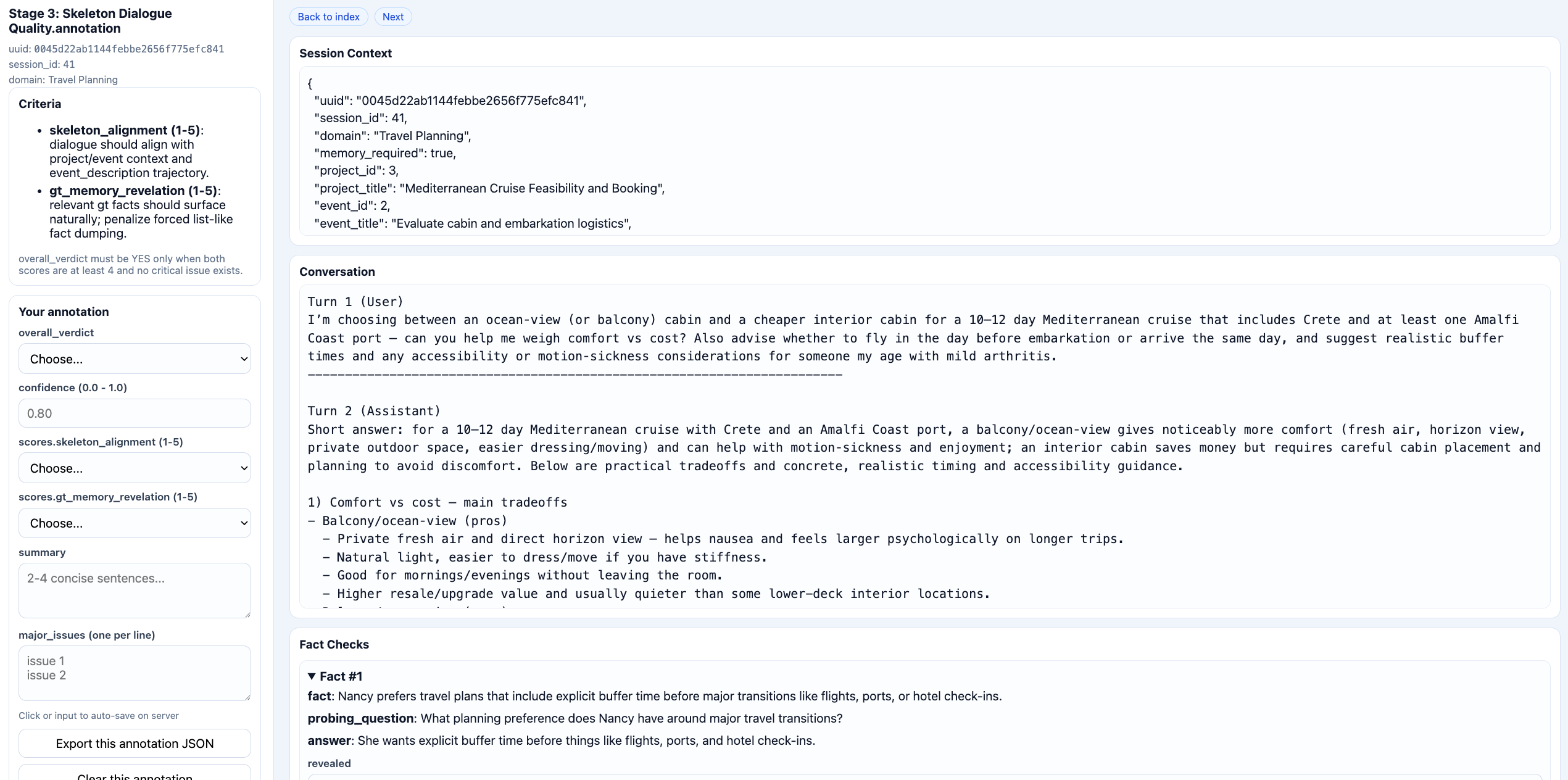 对话质量标注 UI——评估最终生成的多轮对话是否自然、是否承载了 reference memory。
对话质量标注 UI——评估最终生成的多轮对话是否自然、是否承载了 reference memory。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我