HINT-SD:长程 Agent 训练里,"在哪里反馈"比"反馈多稠密"更值钱
核心摘要
训长程 LLM Agent 这件事,最折磨人的不是奖励太稀疏,而是你好不容易拿到一份反馈,不知道往哪一步贴。把反馈贴到第一步看着稳,但很多失败发生在 Turn 7、Turn 10;把反馈贴到每一步又费算力——大部分中间步骤其实是对的,监督它们等于注入噪声。
KAIST 和 DeepAuto.ai 的这篇 HINT-SD 把这个问题挑明了:长程轨迹的核心痛点不是"feedback 不够多",而是"relevance 太稀疏"——一条失败轨迹里,真正需要纠正的动作可能只有那么一两个。所以他们把"自蒸馏"这件事改造成了一个目标选择 + 局部蒸馏问题:先用 hindsight 分析整条失败轨迹挑出关键失误的 turn,再只在这几个 turn 上做 feedback-conditioned 蒸馏。
效果是真的能打:BFCL v3 上 Avg@4 从最强基线 31.56 干到 41.88,AppWorld 从 9.74 干到 18.46,最大提升 18.80 个百分点;同时 step time 从 84.76s 降到 37.45s(降至 1/2.26),峰值显存从 126GB 降到 85GB。这个结果给了我一个挺重要的判断:Agent post-training 这一步,"在哪里反馈"已经成了核心设计变量,跟"反馈用什么形式"同样重要,甚至更重要。
论文信息
- 标题:HINT-SD: Targeted Hindsight Self-Distillation for Long-Horizon Agents
- 作者:Woongyeng Yeo, Yumin Choi, Taekyung Ki, Sung Ju Hwang(*共同一作)
- 机构:KAIST、DeepAuto.ai
- 日期:2026 年 5 月 18 日
- arXiv:https://arxiv.org/abs/2605.17873
一、为什么"在每一步都给反馈"是个伪密集
先聊一个真实的工程感受。我之前在调一个多轮工具调用 Agent 的时候踩过这么个坑:rollout 跑完发现失败了,模型在第 8 个 turn 把参数填错了。但拿到 GPT 当 critic 一分析,问题根源是 turn 3 那次工具调用——那次调用从语法上看完全没问题,输出也合理,但里面藏着一个错误假设,导致后面所有动作都在错的轨道上滑。
这就是长程 Agent 训练的真正难点。你看到的"明显错",往往是几步前一个"看起来没错"的决策的连锁反应。
现在主流的几条解决路线,各有各的别扭:
第一条路:Outcome Reward + 信用分配。GRPO 这类基于终端奖励的方法没办法精确知道是哪一步导致了失败。AgentEvolver 这类做 LLM self-attribution 的方法能给每一步打分,但它给的还是个标量,学正确的替代动作还得靠稀疏的成功 rollout 撑着。
第二条路:Process Reward / 每步反馈。OpenClaw-RL 把 next-state 信号转成每个 turn 的 reward 或文本 hint。直觉上这条路更密,但论文这次给的实验数据让我皱了一下眉:OpenClaw-RL 在 BFCL v3 上 Best@4 反而是基线最高的(45.00),但 Avg@4 只有 28.28——比 GRPO 还低。说明每步反馈并不稳,有时候一个"稠密但不对路"的信号还不如一个"稀疏但对的"信号。
第三条路:Feedback-Conditioned Self-Distillation。SDPO、RLTF 这类把反馈当作"特权上下文"喂给 teacher,再把 teacher 蒸馏到一个不依赖反馈的 student。这条路 token-level 监督非常密,但有个隐形 bug——如果反馈是针对 turn 3 的,但你拿整条轨迹做蒸馏,turn 4 之后的 student 行为可能已经被 turn 3 的反馈牵着走偏了,后面这些 token 监督其实在学一个被反馈拖累的版本。
HINT-SD 看到的洞察其实很朴素:一条失败轨迹里,绝大多数 turn 是对的、是中性的、或者是早期错误的连锁后果,监督这些 turn 既浪费预算又引入噪声。所以他们把问题重新定义了——这不是 feedback 稠密度问题,是 relevance-sparsity 问题。
想清楚这一点之后,问题的次序就反过来了:先回答"在哪里反馈",再回答"反馈什么"。
二、HINT-SD 怎么做:把"自蒸馏"改造成"目标选择 + 局部蒸馏"
整个方法分两步:hindsight 反馈生成和目标性自蒸馏。
2.1 用整条轨迹的"事后视角"挑失误点
给一条失败轨迹 \(\tau = (s_1, a_1, \ldots, s_T, a_T)\),HINT-SD 把当前策略 \(\pi_\theta\) 实例化成一个 hindsight analyzer \(\mathcal{H}_\theta\),喂给它任务描述 + 完整 rollout + 一段指令,让它产出一组稀疏的失败相关步骤和对应反馈:
这里 \(\mathcal{I}\) 是被挑出来的失败相关 turn 集合,\(f_i\) 是自然语言的纠正反馈,描述 turn \(i\) 为什么导致失败、应该怎么改。
这里有个我觉得挺漂亮的小细节:反馈生成这一步同时干了两件事——它既给出了纠正建议,又圈定了应该把这个纠正应用到哪个动作 span 上。不需要再搞一个独立的 attribution 模块。
而且因为是基于完整轨迹做选择的,它能避开"局部看起来很糟但其实是早期错误的连锁结果"的那些 turn,直接定位真正的根因。论文限制每条失败轨迹最多挑 3 个 failure-relevant 步骤——这个数字其实挺关键的,等会儿在实验分布里能看到为什么。
2.2 只在选中的 span 上做反向 KL 蒸馏
挑出 \(\mathcal{I}\) 之后,怎么把每个反馈准确贴到对应的动作 span 上?HINT-SD 用的是自蒸馏 + 信息不对称的玩法:
对每个选中的 step \(i \in \mathcal{I}\),把原始交互历史 \(h_i\) 拼上反馈 \(f_i\),让当前策略在这个增强 context 下产出一个"局部专家"分布——
而 student 还是只看原始 history \(h_i\)。然后在选中的 action span 上最小化 reverse KL:
sg 是 stop-gradient,teacher 不回传梯度。这个写法的精髓在于:teacher 和 student 用同一个模型,teacher 唯一的"特权"是看到了 hindsight 反馈——所以 teacher 在那个 turn 上知道"应该怎么做才对",student 通过反向 KL 学会在没有反馈的情况下也产出同样的动作分布。
为什么是 reverse KL 不是 forward KL?这是 SDPO/RLTF 这条线一直用的设定——reverse KL 会让 student 产出 mode-seeking 的行为,更倾向于学到一个"明确的纠正"而不是"混合的多模态分布"。在 Agent 场景里你确实想要一个明确的纠正,因为下一步要做工具调用,分布太扁平等于推理不稳。
2.3 一个直观的对比
把 HINT-SD 跟前面三条路做个对比,问题就清楚了:
| 方法 | 反馈位置 | 监督形式 | 问题 |
|---|---|---|---|
| GRPO | 全轨迹(终端奖励) | 标量 | 信用分配模糊 |
| SDPO | 全轨迹 | token-level 蒸馏 | 不相关 turn 引入噪声 |
| OpenClaw-RL | 每个 turn | 标量 reward + 文本 hint | 局部信号易被早期错误污染 |
| HINT-SD | 选定的失败相关 turn | token-level 蒸馏 | 需要 model 有基本的反思能力 |
HINT-SD 的 trade-off 也很清楚——它依赖 model 自己当 hindsight analyzer,所以模型本身得有基本的指令理解和反思能力。论文用 Qwen3-4B-Instruct-2507 跑通了,证明 4B 这个量级已经够用了。
三、实验结果:18.80 个点的提升 + 步骤耗时减半
3.1 主表
测了两个 benchmark:
- BFCL v3:可执行的多轮工具调用,主要看 Base 和 Long Context 子集
- AppWorld:有状态的 App 工作流,按最终环境状态的单元测试打分
每个任务 4 次 rollout,报 Avg@4 和 Best@4。
| 方法 | BFCL v3 Avg@4 | BFCL v3 Best@4 | AppWorld Avg@4 | AppWorld Best@4 |
|---|---|---|---|---|
| Initial(zero-shot) | 25.94 | 36.25 | 5.98 | 13.85 |
| SFT(GPT-5.4-mini 高奖励轨迹) | 28.44 | 38.13 | 6.82 | 13.16 |
| GRPO | 31.56 | 41.25 | 7.49 | 15.21 |
| SDPO | 30.78 | 40.00 | 9.74 | 19.32 |
| OpenClaw-RL | 28.28 | 45.00 | 7.65 | 12.31 |
| HINT-SD-Single | 36.25 | 43.13 | 16.54 | 29.40 |
| HINT-SD-Multi | 41.88 | 48.75 | 18.46 | 31.11 |
几个值得品的点:
HINT-SD-Single 已经把基线全面拉爆。Single 版本只蒸馏第一个 failure-relevant step,已经在 BFCL v3 Avg@4 上从 31.56 拉到 36.25,AppWorld Avg@4 从 9.74 拉到 16.54。这个数据其实把"目标选择"这件事的价值说得很清楚——就算只挑一个 turn,挑得准比每一步都监督要值钱。
Multi 版本在 Single 基础上还能再涨。说明在同一份 rollout 预算下,多挑几个 failure-relevant turn 可以挖出更多的纠正信号。但论文限制最多 3 个,这个上限我觉得是工程性的——挑太多就回到 SDPO 那种"全轨迹蒸馏"的老问题了。
OpenClaw-RL 的 Best@4 高但 Avg@4 低。这个对比挺有意思——OpenClaw-RL 在 BFCL Best@4 上拿到 45.00,比 GRPO 还高,但 Avg@4 只有 28.28。说明它在某些样本上能爆出很高的成绩,但整体方差大。这背后的原因论文没明说,但我猜跟它的 dense 局部 hint 有关——hint 对了就一飞冲天,hint 错了就把模型带歪。
SFT 提升相当有限。从 25.94 到 28.44,只涨 2.5 个点。这其实暴露了一个常被忽略的事实:纯靠 GPT-5.4-mini 生成的高奖励轨迹做 SFT,对长程 Agent 涨点很有限——长程任务里"看着对的轨迹"和"真正学会决策"是两回事,模仿表面行为很容易学了个壳。
3.2 训练动态和效率
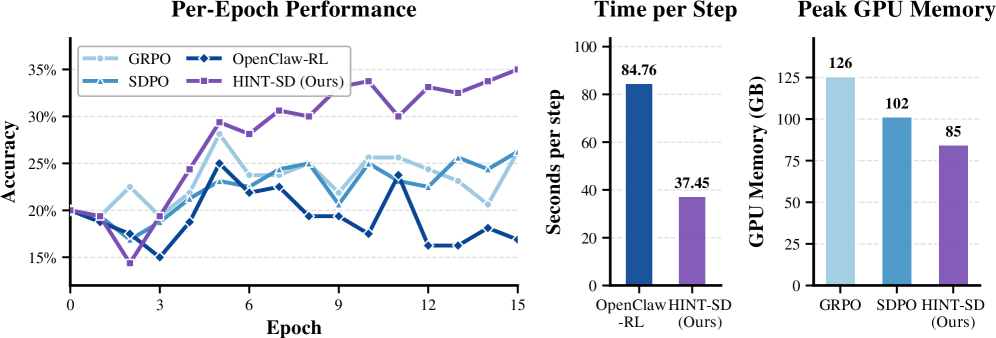
图 1:左——BFCL v3 验证集上每个 epoch 的准确率曲线;中——单步训练耗时;右——首个 epoch 的峰值 GPU 显存。HINT-SD(紫色)在三个维度上都占优。
左图最直观的信息是收敛速度。GRPO 和 SDPO 在前 6 个 epoch 还能跟住,但很快就在 25% 左右饱和了;OpenClaw-RL 走得最不稳,一会儿涨一会儿跌;HINT-SD 从 epoch 5 开始就拉开身位,到 epoch 15 稳定在 35% 上方。
中间和右边的两张图是论文主张"高效"的核心证据:
- Step time:从 OpenClaw-RL 的 84.76 秒/步降到 HINT-SD 的 37.45 秒/步——2.26 倍提速
- Peak GPU memory:从 GRPO 的 126GB 降到 HINT-SD 的 85GB,比最强 dense baseline 低 1.48 倍
这套数字背后的逻辑很直白:HINT-SD 只在选中的几个 turn 上算 distillation loss,而 OpenClaw-RL 要对每个 turn 都做反馈生成 + 计算 loss,SDPO 要对整条轨迹做蒸馏。计算量不省,省的是不必要的监督。
3.3 反馈位置消融——这是我觉得最有说服力的实验
论文做了一个特别干净的对照实验:固定 hindsight analyzer 给出的反馈内容,只改变反馈插入的位置——是放在 rollout 开头(Start-FB),还是放在选中 target turn 之前(Target-FB)。每种条件都跟"无反馈 rollout"对比,看 success rate 提升多少。
| Benchmark | Start-FB Gain | Target-FB Gain | Target − Start |
|---|---|---|---|
| BFCL v3 | +2.68 | +8.67 | +5.99 |
| AppWorld | +0.44 | +2.16 | +1.72 |
涨了 5.99 个百分点。 同样的反馈,只是换了贴的位置,效果差出这么多。
这个数据是论文整篇里最直击核心的——它直接证明了"在哪里反馈"不是个细枝末节,而是核心设计变量。把反馈放在开头当 global hint,效果只有放在 target turn 上的 1/3 左右。
我读这个实验的时候真的有种"对,就该这么验证"的感觉。很多论文会做主表对比说自己更好,但很难证明"涨点是因为我的核心 idea 而不是其他工程细节"。这个对照设计把变量精确隔离到了"反馈位置"这一个维度上,剩下的所有东西都不变——这种实验是真的能立住论点的。
3.4 Target Turn 分布——动态揭示了模型在学什么
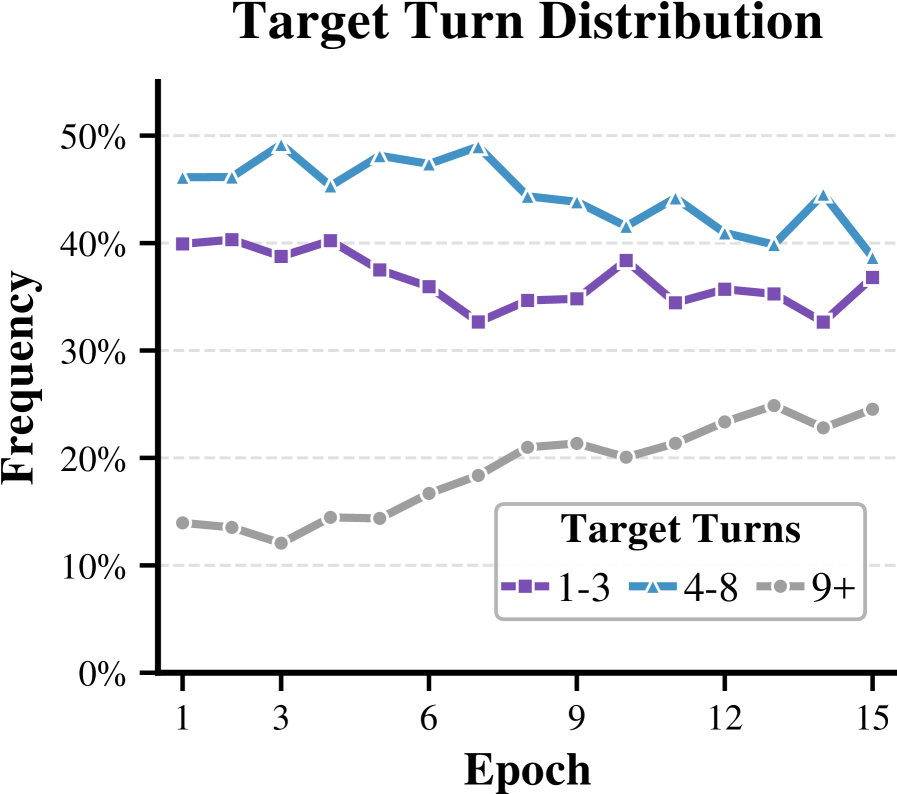
图 2:BFCL 训练过程中,被选作 feedback target 的 turn 分布。横轴是 epoch(1-15),三条曲线分别是 turn 1-3、4-8、9+ 的频率。
这张图我看了一会儿才品出味道。前 15 个 epoch:
- turn 1-3:从 39.9% 缓慢降到 36.7%
- turn 4-8:稳定在 45% 左右
- turn 9 及之后:从 14.0% 涨到 24.5%
随着训练进行,反馈目标在向后迁移。这个现象其实非常符合直觉——训练初期,模型在前几个 turn 就经常犯错(解析任务、选 API),所以反馈集中在前面;训练后期,前面几步搞定了,瓶颈才出现在更后面的 turn 上。
你也可以这么理解,HINT-SD 不是在挑一个固定的"难点位置",而是跟着模型能力的进化,动态把火力打到当前最薄弱的环节。这个性质对长程任务训练特别重要——它不会让模型反复在已经解决的问题上做无用功。
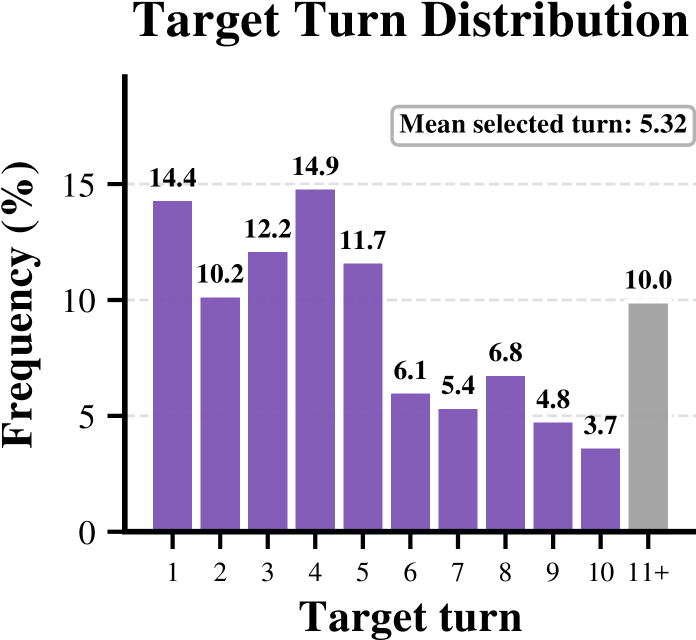
图 3:前 15 个 epoch 累计的 target turn 分布。平均选 5.32 个 turn,1-5 turn 占 60% 以上,但 11+ 仍有 10% 的占比。
这张图(附录里的 Figure 3)补了一个有意思的视角:累计来看,超过 turn 10 的反馈仍占 10%。这说明长程任务里确实存在那些晚期才暴露的根因——你没法用"前面几步对了就稳"的启发式去糊弄过去。这一点也是 HINT-SD 区别于 OpenClaw-RL 这类"per-turn dense feedback"方法的关键:HINT-SD 不假设错误一定发生在哪里,而是 case-by-case 用 hindsight 去找。
3.5 反馈来源的消融
| Feedback Source | BFCL v3 Avg@4 | BFCL v3 Best@4 | AppWorld Avg@4 | AppWorld Best@4 |
|---|---|---|---|---|
| Teacher(EMA 更新) | 41.88 | 48.75 | 18.46 | 31.11 |
| 环境直接反馈 | 36.25 | 42.50 | 15.90 | 27.86 |
| Initial Teacher(不更新) | 37.50 | 45.63 | 14.40 | 28.89 |
| Larger Teacher(GPT-5.4-mini) | 48.59 | 52.50 | 20.81 | 35.04 |
几个观察:
- EMA-updated teacher 比 initial fixed teacher 好——说明反馈生成器需要跟着策略一起进化,否则会越用越脱节
- 环境反馈不如 LLM 生成的反馈——直接拿环境 stderr / API 错误码当反馈是不够的,需要 LLM 把这些信号"翻译"成可执行的纠正建议
- 更强的 teacher(GPT-5.4-mini)能再涨 6-7 个点——说明 HINT-SD 的天花板还没到,feedback 质量直接决定上限。但 HINT-SD 用 4B 自蒸馏的版本已经能跟 OpenClaw-RL/SDPO 拉开差距,这个 self-contained 的特性其实挺重要——不依赖外部大模型,单卡训练就能跑
四、我的判断:HINT-SD 是一个范式上的小突破,不是工程整合
4.1 核心贡献该怎么看
读完一遍我的判断是:HINT-SD 的核心价值不在算法新颖度——self-distillation 是 SDPO 那条线已经成熟的做法,反向 KL 也是 RL post-training 里通用配方,hindsight 在 RL 领域更是老熟人(HER 那一脉)。
它真正值钱的地方在于问题重定义:把 "feedback-conditioned distillation" 这件事从"反馈用什么形式"重新指向了"反馈打在哪里"。这个视角转换在长程 Agent 这个具体场景里非常合理——relevance-sparsity 的洞察是真切扎实的,不是为了写论文凑出来的痛点。
4.2 几个值得追问的地方
hindsight analyzer 的可靠性。整个方法链条上最脆的一环就是"模型自己挑出来的失败相关 turn 真的对吗?"。论文用 Qwen3-4B 做 analyzer 跑通了,但小模型在反思自己的轨迹时存在一个潜在风险——它对自己的错误有盲区。如果 4B 模型挑错了 turn,HINT-SD 就会在错误的位置做蒸馏,反而引入噪声。论文用 EMA + GPT-5.4-mini 的对比间接证明了 analyzer 质量很重要,但没做"挑错 turn 会怎样"的失败案例分析——这个我觉得是个比较明显的 gap。
最多挑 3 个 turn 这个上限的鲁棒性。论文限制每条失败轨迹最多 3 个 failure-relevant 步骤,但没消融过这个数字。如果一条轨迹有 5 个真正的失误,限制到 3 个会丢掉信息;如果只有 1 个,挑 3 个会引入噪声。这个超参的敏感性应该值一个表。
只在两个 benchmark 上验证。BFCL v3 偏工具调用、AppWorld 偏 App 工作流,覆盖范围还行但不算全。在更长的轨迹(比如 SWE-Bench 这种几十轮交互的)上是不是仍然成立?我猜会,但需要验证。
和同期方法的对比留了空白。论文 Related Work 提到了 HCAPO(hindsight credit assignment)、PivotRL(pivot 选择)、GiGPO(group-based 细粒度信用分配)这几个 2026 年的同期工作,但主表里没跟它们对比。只跟 SDPO、OpenClaw-RL、GRPO 比有点选择性了——HCAPO 同样是用 hindsight 做 credit refinement,跟 HINT-SD 在思路上很接近,没对上是个不太干净的地方。
4.3 对工程实践的启发
如果你也在做 long-horizon Agent 训练,下面几个点值得直接借鉴:
- 重新审视你的反馈位置。如果你现在的 pipeline 是"把 feedback 拼到 prompt 开头"或者"每步都生成反馈",可以试试在选定的 failure turn 上做 targeted supervision,这接近 6 个点的差距是真实存在的
- self-attribution 当 selector 是可行的。不一定非得训一个独立的 critic,用当前策略 + hindsight prompt 就能做出像样的 turn 选择——前提是 backbone 模型有基本的反思能力(4B 已经够)
- 反向 KL + stop-gradient 的自蒸馏配方在长程任务上是 work 的。比纯 GRPO 那种基于标量奖励的优化稳定得多
- EMA teacher 比 initial fixed teacher 好——这个细节经常被忽略,但实测涨 4 个点不是小数
4.4 一个更大的判断
这一年半来,Agent post-training 这条线我的总体感觉是:reward 设计这块的红利已经吃得差不多了——做更密的 reward、做更细的 PRM、做更好的 critic,每条路都有人在走,但增量越来越小。
HINT-SD 给我的启发是,下一波涨点的空间可能在信号利用效率——在已经拿到的 reward / feedback 基础上,如何更准确地把它定位到该被监督的位置。这是个跟 reward 形式正交的问题,跟数据采样、curriculum、attribution 都相关。
可以预期接下来会有一波"在哪里监督"的工作冒出来——target span selection、credit assignment 的精细化、轨迹级别的 importance sampling 重新被翻出来用。HINT-SD 是这条路上比较干净的一个起点。
五、收尾
读完最大的感受是:这篇论文最值钱的不是 HINT-SD 这个具体方法,而是它把"反馈位置"这个变量从隐性变成了显性。Start-FB vs Target-FB 那 +5.99 个点的对照实验给我的冲击挺大的——同样的反馈、同样的训练流程、只换了一个位置参数,差出 6 个点。这种实验出来之后,再做 long-horizon Agent 训练就很难再忽略"反馈贴在哪"这个问题了。
如果你在做 Agent post-training,强烈推荐把这篇论文跟 SDPO、OpenClaw-RL 三篇放一起读——能看清楚同一条技术路线上"反馈形式 → 反馈位置"的演进逻辑。
参考资料
- HINT-SD 论文:https://arxiv.org/abs/2605.17873
- SDPO(Hübotter et al., 2026):Reinforcement learning via self-distillation
- OpenClaw-RL(Wang et al., 2026):Train any agent simply by talking
- BFCL v3(Patil et al., 2025):Berkeley Function Calling Leaderboard
- AppWorld(Trivedi et al., 2024):A controllable world of apps and people for benchmarking interactive coding agents
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我