把"40000层迭代"写成吸引子收敛:CMU 团队让 5M 小模型在 Sudoku-Extreme 上从 2.6% 干到 99.8%
这论文有意思在哪
先抛一个反直觉的事实。
一个只有 5.03M 参数、训练时最多展开 16 步的小模型,在推理时被一路展开到 1024 步——按等价层数算下来是40000 层左右——做出来的事是把 Sudoku-Extreme(极难数独)的精确率从 64 层前馈大模型的 2.6% 干到了 99.8%。同样是堆算力,前馈那条路 OOM 了都没用,weight-tied 迭代这条路反而越堆越准。
更让我愣了一下的是:训练只见过 16 次迭代的模型,测试时跑 1024 次居然不崩,反而 residual 一路降、准确率一路涨。线性外推 64 倍。
这不是常见的 test-time scaling 故事——堆 chain-of-thought、堆 search、堆 verifier,那些都需要外部信号。这篇论文(ICML 2026,CMU Zico Kolter 组)想问的是更底层的问题:当一个权重共享的迭代模型反复更新自己的潜状态时,它内部到底在干什么?为什么深度堆得越多越好?什么时候又会失效?
作者给的答案是:模型在学一个任务条件化的吸引子(task-conditioned attractor)。把这件事当成一个潜空间里的动力学系统来看,迭代推理的 scaling law 就有了机制解释。
我读完的第一感觉是——这篇论文的概念非常 DEQ(Deep Equilibrium Model)。Zico Kolter 本人就是 DEQ 那篇 NeurIPS 2019 的资深作者之一,所以这套吸引子语言对他来说就是回家。但有趣的是,他们这次没有走"严格不动点"的老路,而是松弛到了"吸引子"的弱版本——这一手放得很关键,下面会聊到。
论文信息
- 标题:Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
- 作者:Benhao Huang、Zhengyang Geng、Zico Kolter
- 机构:CMU(论文标注 "Machine Learning, ICML CMU")
- arXiv:https://arxiv.org/abs/2605.21488
- 代码:https://github.com/locuslab/EqR
- 会议:ICML 2026
先把"奇观"放出来——一张能打的图
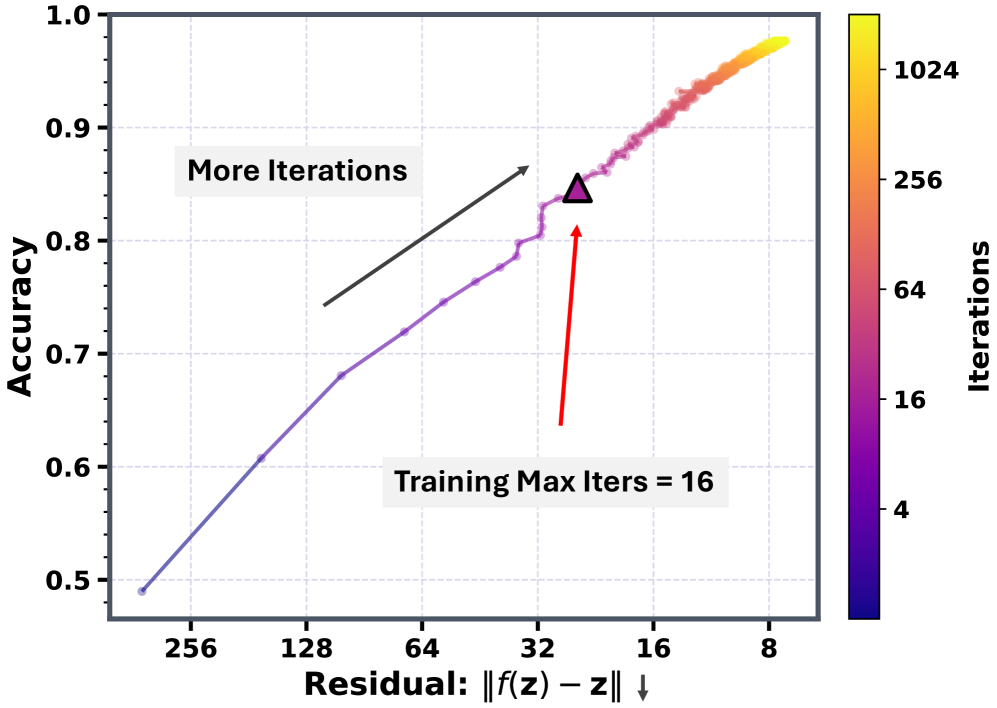
图1:一条几乎线性的对数曲线。横轴是潜状态的不动点残差 \(\|f_\theta(\mathbf{z};\mathbf{x})-\mathbf{z}\|\),纵轴是精确率,颜色编码迭代次数(log 尺度)。三角形标注的是训练时见过的最大 16 次迭代——但测试时一路推到 1024 次,residual 还在降,准确率还在涨。
这张图我看了挺久。它说的是一个非常清爽的事实:模型有多收敛(残差有多小),就有多准。这不是"堆算力总会有点用"的渐近曲线,而是几乎成线性正比的强耦合。
更关键的是右侧那一大片黄色高密度点——它们都是训练时根本没出现过的迭代深度。模型却能稳定外推。这意味着学到的不是"我背了 16 步该输出什么",而是一个可以无限迭代下去的稳定动力学。
这就是论文标题"Equilibrium Reasoners"的实证基础。
核心故事:把推理当成在景观上找凹坑
一句话直觉
如果你做过梯度下降,你脑子里有一个景观(loss landscape)的图像:参数从初始点出发,沿着某个动力学下降到一个最优点。
EqR 把推理也想成这件事,但下降发生在潜状态空间,而不是参数空间。模型参数 \(\theta\) 是固定的,每一步迭代 \(\mathbf{z}_{k+1} = f_\theta(\mathbf{z}_k; \mathbf{x})\) 是把当前潜状态往一个吸引子方向拉。这个吸引子如果和"任务正确解"对齐,那模型只要收敛过去,就解对了题。
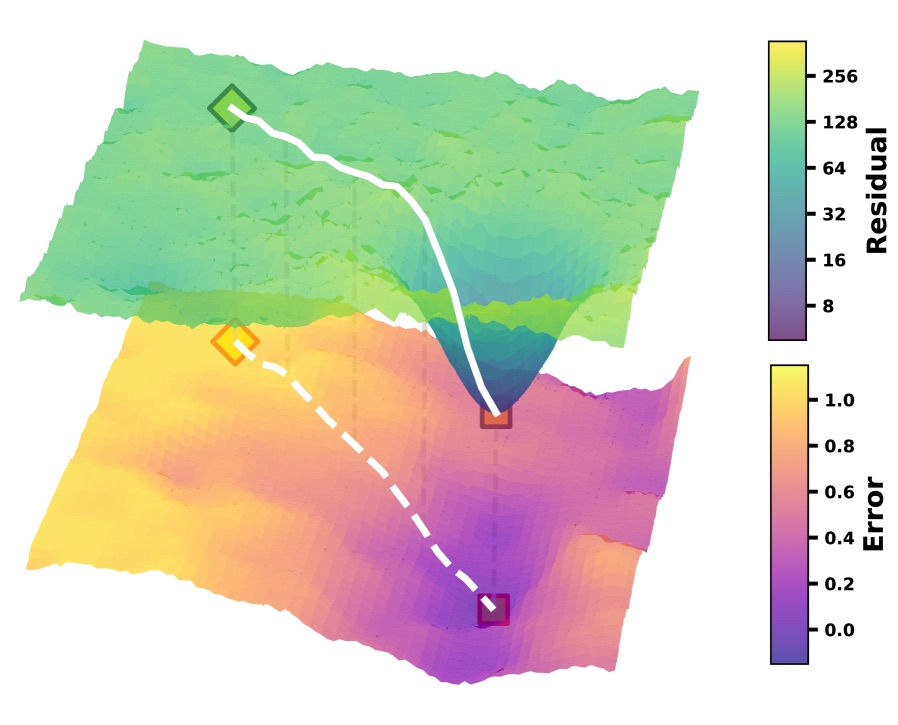
图2:作者用一张3D景观示意图把核心 idea 讲清楚了。上面那一层是模型自己的不动点景观——哪些潜状态会被反复迭代吸过去;下面这一层是任务的正确解景观——哪些位置对应低错误率。EqR 的训练目标可以理解为:把上面这层的凹坑往下面那层的凹坑上叠。一旦对齐,潜状态滑向自己的吸引子也就同时滑向了任务的正确解。
这个比喻不是为了好看。它直接给了两个可以验证的预言:
- 模型有多收敛 ↔ 任务有多准(图1已验证)
- 景观结构决定了 scaling 怎么生效(下面图6会展示)
比 DEQ 弱一档的"吸引子"假设——为什么这步关键
DEQ 严格要求 \(\mathbf{z}^* = f_\theta(\mathbf{z}^*; \mathbf{x})\) 收敛到唯一不动点。HRM、TRM 这一系列工作在实践中都吐槽过:损失里 residual 永远不会真正降到 0,但模型确实在学东西。
EqR 的做法是把"严格不动点"松弛成"吸引子"——一个轨迹只要被一个稳定区域吸引(哪怕是一个有限循环或一个低残差小邻域),就足够了。
我们使用"吸引子"这个术语来描述学到的动力学的稳定长程结果,推广了 DEQ 的均衡视角。一个有利的盆地就够了。
我觉得这一手放得很巧。严格不动点是一个数学上漂亮但实践中难达成的目标;吸引子则给了"近似不动点也算数"的合法性,同时保留了"收敛性可以作为质量指标"这条线索。论文后面所有 diagnostics(用 residual 选 best-of-N)都是建立在这个松弛之上的。
两轴 scaling:深度(D)× 广度(B)
EqR 把测试时算力分到两个维度:
- Depth \(D\):单条轨迹跑多少次迭代——给一个轨迹更多机会在它进入的盆地里打磨
- Breadth \(B\):从多少个不同初始化各跑一条独立轨迹——增加进入正确盆地的覆盖率
总算力 \(\text{NFE} = D \cdot B\)。
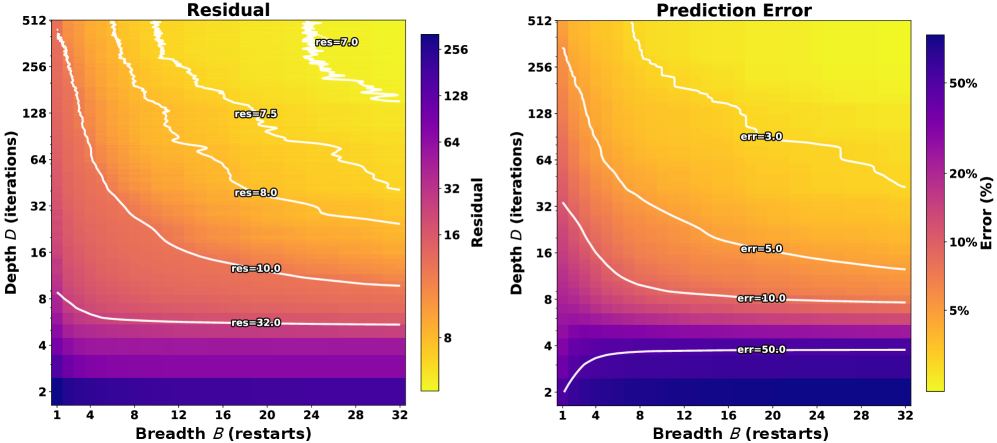
图3:横轴是广度 B(restart 次数),纵轴是深度 D(迭代步数)。左右两张图的等高线几乎完全同构——这意味着"残差降下来"和"准确率升上去"是同一件事。还有一个细节值得注意:广度 scaling 必须在 D ≳ 4(即等价 168 层展开)之后才开始起效。深度太浅的时候,restart 多少次都没用,因为没有任何一条轨迹真的走进了某个盆地。
这个 D-B 互补关系不是凑出来的,作者把它解释成了四种景观模式:

图4:把前馈模型一步步改造成可 scale 的迭代推理器,要加这五件东西:(1) 跨步骤共享权重;(2) 层次化迭代(高低两层潜状态以不同频率更新);(3) 梯度截断(detached carry,砍掉跨段反传以稳定优化);(4) 分段在线训练(SOT,沿轨迹分段做 supervision 和参数更新);(5) 自适应计算(ACT halting,按难度分配算力)。
四种吸引子景观——把 scaling 何时有效讲透了
这是我个人觉得这篇论文最有概念价值的部分。
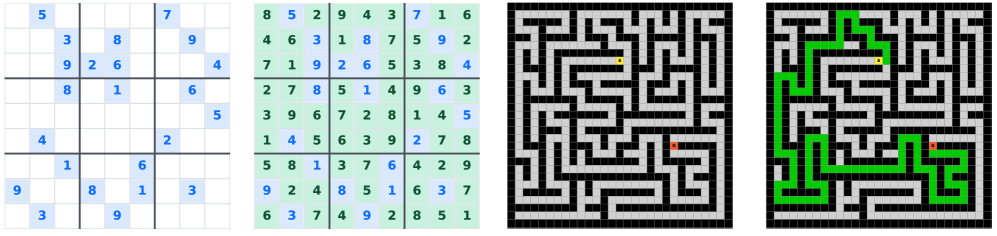
图5:评测的是两个结构化推理任务。Sudoku-Extreme 是 9×9 的极难数独,Maze-Unique 是 30×30 唯一最短路径迷宫。这两个任务都满足"可控、能区分记忆与泛化"的设计——光背训练集是答不对的。
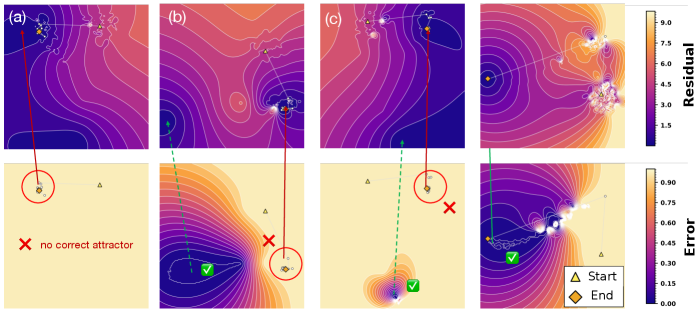
图6:把 512 个随机初始化在 256 道数独题上跑出的轨迹用 PCA 投到 2D,再按错误率上色。上半部分是 residual 景观,下半部分是 task-error 景观。四种典型模式把"什么时候 scaling 有用"讲得很清楚。
逐个说一下我对这四种模式的理解:
模式 a:没有正确吸引子——模型学错了,所有能到的稳定区域都解码不出正确答案。这种情况下 residual 降到 0 也没用——降的是错误吸引子的残差。深度和广度都救不了,要重训。
模式 b:正确与错误吸引子并存——正确的盆地有,但还有别的诱人的(低残差但高错误率)伪吸引子在抢轨迹。这是广度 scaling 的主战场——多 restart 几次,提高进入正确盆地的概率。深度只有在已经进入正确盆地之后才能继续打磨。
模式 c:正确吸引子很窄——唯一正确的盆地存在,但盆地小、引力弱,大多数轨迹根本进不去。广度增加 hit 率,深度让进入了的轨迹稳下来。但天花板被盆地大小限制。
模式 d:景观对齐良好——正确吸引子又宽又稳,残差下降几乎等价于错误率下降。深度可靠地继续 refine,广度起到锦上添花的作用。
这套分类的实用价值在于:它告诉你 scaling 失效时该往哪查。如果加深度不涨,去查景观是不是 (a);如果加广度无效,去查 D 够不够大、是不是 (a) 或 (c)。这比"加更多算力"这种摸鱼式建议有用得多。
训练侧两个干预:RI + NI
景观分析说了"我们想要 (d) 模式"。那怎么训出来?
EqR 给了两个非常 cheap 的干预:
RI (Randomized State Initialization)
HRM、TRM 这些工作训练时用的是同一个固定的 \(\mathbf{z}_0\)。EqR 改成每条轨迹独立采样 \(\mathbf{z}_0 \sim \mathcal{N}(0, \sigma_0 I)\)。
为什么?因为测试时如果要做广度 scaling,一定是从多个不同初始点出发;训练时如果只见过一个初始点,那训练-测试分布就不一致。RI 让模型在训练时就习惯"从各种地方出发",这样:
- 探索的状态空间区域更广,更多正确吸引子在训练中被塑造
- 同一道题在不同 \(\mathbf{z}_0\) 下被反复训练,预测分歧会被惩罚——这鼓励了路径独立性(path independence)
NI (Noise Injection / Path Stochasticity)
加 RI 还不够。RI 管"起点",但每条轨迹中间的演化还是确定性的——容易过早卡进某个伪吸引子。
NI 在每一步迭代里注入高斯噪声,公式长这样:
其中 \(\varepsilon_k \sim \mathcal{N}(0, I)\),\(\lambda\) 是阻尼,\(\beta\) 是噪声强度。作者实测最佳是 \(\lambda=0.05\)、\(\beta=0.01\)——非常小的扰动。
测试时还可以调大 \(\beta\) 做"温度采样式"的探索。
伪代码作者也给得很简洁:
def iter_step(z, cond):
eps = noise() # NI: 路径随机性
return z + (1 - lam) * (f_theta(z, cond) - z) + beta * eps
def latent_loop(z_H, z_L): # 两层潜状态嵌套
for _ in range(n):
z_L = iter_step(z_L, x + z_H)
z_H = iter_step(z_H, z_L)
return z_H, z_L
def truncated_unroll(z_H, z_L):
with torch.no_grad(): # detached carry
for _ in range(T - 1):
z_H, z_L = latent_loop(z_H, z_L)
z_H, z_L = latent_loop(z_H, z_L) # 只有最后一步反传
y_hat, q_hat = lm_head(z_H), q_head(z_H)
return y_hat, q_hat, z_H, z_L
# RI: 每条轨迹随机初始化
z_H ~ N(0, sigma_H * I); z_L ~ N(0, sigma_L * I)
for k in range(N_sup): # 分段在线训练
y_hat, q_hat, z_H, z_L = truncated_unroll(z_H, z_L)
L = CE(y_hat, gt) + BCE(q_hat, [y_hat == gt])
backprop(L); opt.step()
if q_hat > 0: break # 难度感知早停
整个训练 pipeline 干净到我有点意外——没有外部 verifier、没有专门的搜索、没有 task-specific 先验,只是把"起点随机化 + 步长加噪 + 分段反传"这些都拧到位。
实验:从前馈→迭代→EqR 的逐级证据
第一段:前馈到底有多不行
| 方法 | Sudoku 精确率 | Maze 精确率 |
|---|---|---|
| 前馈 4 层 | 1.8% | 0.0% |
| 前馈 16 层 | 2.1% | 0.0% |
| 前馈 64 层 | 2.6% | 0.0% |
| 前馈 256 层 | OOM | OOM |
| HRM (Wang et al., 2025) | 55.0% | 0.3% |
| TRM (Jolicoeur-Martineau, 2025) | 84.8% | 44.9% |
| URM (Gao et al., 2025) | 77.6% | 51.4% |
| EqR(本文) | 99.8 | 93.0 |
Table 1:在结构化推理任务上,前馈模型几乎是 0 分。这不是"差一点",是范式级别的失败——256 层都直接 OOM 了。Maze 上前馈 0%,到 EqR 一路打到 93.0%。
我看到这张表的第一反应是有点替前馈感到抱歉——但仔细想,这其实是这套实验设置的关键设计:他们故意挑了结构化、需要长程一致性的任务,让"靠记忆刷分"这条路走不通。Sudoku-Extreme 的难度就是有意调到对前馈不友好。所以这张表更准确的解读是:"在需要真正多步约束传播的任务上,迭代结构是必需品,不是 nice-to-have。"
第二段:从 vanilla 前馈到迭代基线,每加一件东西涨多少
| 方法 | Blocks | 参数(M) | NLE | 训练 Acc | 测试 Acc |
|---|---|---|---|---|---|
| vanilla 前馈 | 42 | 105.6 | 42 | 93.8 | 2.6 |
| + 权重共享 | 2 | 5.03 | 42 | 94.5 | 32.6 |
| + SOT + 深度×16 | 2 | 5.03 | 672 | 94.9 | 74.7 |
| + 层次化迭代 | 2 | 5.03 | 672 | 99.3 | 76.5 |
| + ACT 训练 | 2 | 5.03 | 672 | 82.2 | 84.8 |
Table 2:Sudoku-Extreme 上的逐级构造路径。最戏剧性的一步是从 vanilla 前馈到权重共享——参数量从 105.6M 砍到 5.03M(缩小 21 倍),测试准确率反而从 2.6 涨到 32.6。这说明问题不在于"参数不够",而在于"算力组织方式不对"。
我觉得这张表里最值得停一停的是最后一行:加 ACT 之后训练准确率从 99.3 降到了 82.2,但测试准确率反而从 76.5 升到 84.8。作者的解释是 ACT 让模型学会在简单题上早停以避免过拟合,把更多算力留给难题。这个 train-eval gap 缩窄是难得的——通常我们看到的是反向的过拟合,这里是有意识的"训练时少做点"换来"测试时泛化更好"。
第三段:景观塑造干预的增量
| 方法(景观塑造) | Sudoku | Maze |
|---|---|---|
| baseline | 84.8 | 44.9 |
| + train w/ RI | 86.0 | 68.6 |
| + train w/ RI + NI (EqR) | 86.4 | 82.2 |
Table 3:在不增加测试时算力的前提下(D=16, B=1),仅靠训练干预。Sudoku 上提升不大(84.8→86.4),但 Maze 上从 44.9 一路涨到 82.2——RI 一项就贡献了 23.7 个点的提升。
Maze 上 RI 带来的 +23.7 个点,我觉得是这篇论文最值得回味的数据之一。Maze 任务的特点是路径选择空间巨大、容易出现多个低 residual 但路径错误的伪吸引子——也就是图6里的 (b) 模式。RI 通过让训练时就见到多种起点,等价于在训练阶段就做了"广度覆盖",把模型推到了 (d) 模式。
第四段:测试时 scaling 的真正威力
| 测试时策略 | D | B | Sudoku | Maze |
|---|---|---|---|---|
| EqR baseline | 16 | 1 | 86.4 | 82.2 |
| + 深度 scaling | 64 | 1 | 93.0 | 88.9 |
| + 广度 scaling | 64 | 128 | 99.8 | 93.0 |
Table 4:D=16 到 D=64 这一步深度 scaling,Sudoku 涨 6.6 个点,Maze 涨 6.7 个点。再加上 B=128 的广度 scaling,Sudoku 一路冲到 99.8——基本只剩极少数题不会做。
总 NFE = 64 × 128 = 8192。这就是开头那个"展开 40000 等价层"故事的来源(深度方向单独展到 1024 时是 40000+ 等价层)。
这套方法到底贵不贵?——ACT 的算力账
99.8% 听起来很美,但 NFE = 8192 是真实的算力开销。论文也意识到了这个问题,于是接到 ACT(Adaptive Computation Time):让每个样本根据自己的难度自己决定什么时候停。
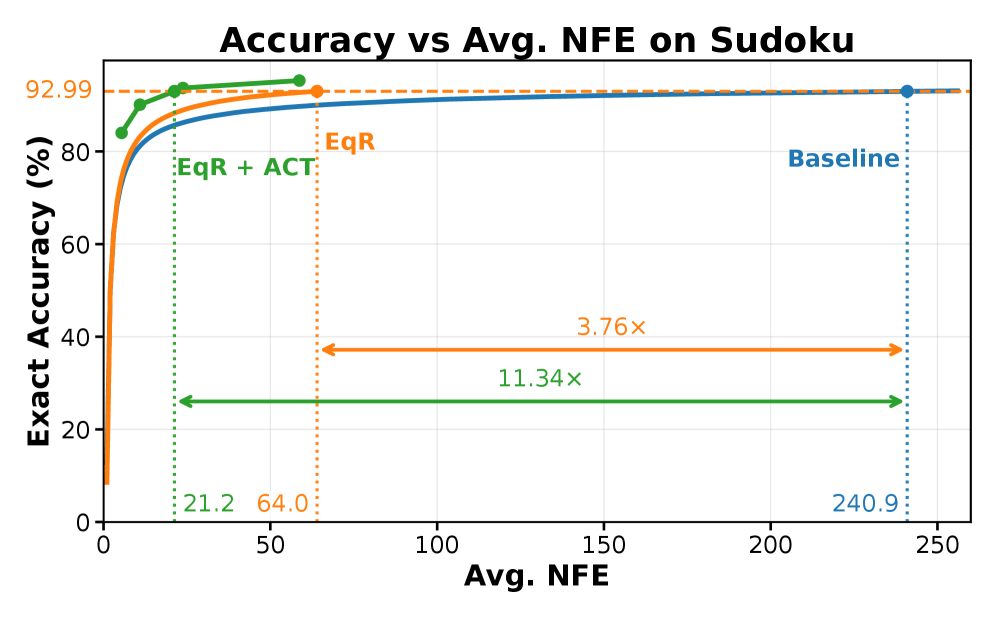
图7:要达到 92.99% 这个精度水平,baseline 要 240.9 NFE,EqR 只要 64.0(节省 3.76 倍),EqR+ACT 只要 21.2(节省 11.34 倍)。绿色曲线在低 NFE 段直接吊打另外两条——这意味着大部分题模型早就解出来了,根本不需要那么多迭代。
| 预算 (D, B) | ACT | 测试 Acc | 平均 NFE |
|---|---|---|---|
| (16, 1) | ✗ | 84.3 | 16.0 |
| (16, 1) | ✓ | 84.0 | 5.4 |
| (1024, 1) | ✗ | 96.1 | 1024.0 |
| (1024, 1) | ✓ | 95.3 | 58.7 |
| (64, 128) | ✗ | 97.9 | 8192.0 |
| (64, 128) | ✓ | 97.4 | 1400.6 |
Table 5:ACT 把平均 NFE 砍掉一个数量级,准确率只掉 0.5 个点左右。最戏剧的是 (1024, 1) 这一行:1024.0 → 58.7,17.4 倍算力节省。
这个数我看了挺久。它说的是一个挺反直觉的事:模型对绝大多数题是几步就收敛的,只有少数硬骨头需要 1024 步。但如果不上 ACT,你就要为每一道简单题也分配 1024 步——浪费的是非常恐怖的算力。也就是说,massive depth scaling 必须配自适应停止才能成立,不然成本曲线根本没法看。
收敛信号能不能直接当 best-of-N 选择器?
这是论文 6.2 节里我觉得最微妙的一个观察:只有在景观塑造做好之后,"挑残差最小的那条轨迹"才是个靠谱策略。
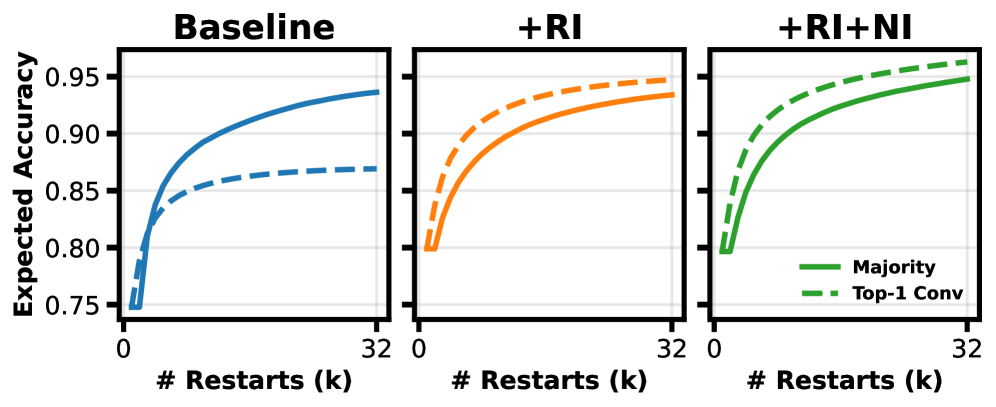
图8:三个面板分别是 baseline、+RI、+RI+NI(即 EqR)。实线是 majority vote(多数投票),虚线是 Top-1 Converged(选残差最小的那条)。最有意思的对比在最左面板:baseline 上虚线低于实线,说明"挑收敛最好的"反而不如"投票"。但在右面板,虚线高于实线——景观塑造之后,残差才真正成了正确性的代理信号。
这个细节捕捉到一个挺深的事:收敛性不是天然就和正确性绑定的。在一个景观结构混乱的模型里,"最收敛的轨迹"很可能是收敛到了一个伪吸引子——它残差是低,但答案是错的。这就是为什么 baseline 上 Top-1 Converged 不如 majority vote。只有当 RI+NI 把景观塑造到 (d) 模式之后,残差才成了一个可信的内部 verifier。
我之前在做强化学习时也碰到过类似的事:reward 模型有时候会给一些"看起来很对但其实有问题"的输出打高分。这里的 residual 也是一回事——它是个学出来的代理,不是天然真理。
几句我自己的判断
聊聊这篇论文我觉得真正值钱的地方,和我觉得需要打个问号的地方。
值钱的地方:
第一,机制视角。把迭代推理放到吸引子动力学的语言里,给"为什么 test-time scaling 有时候有用、有时候没用"这件事提供了一个可证伪的解释。图6 那四种景观模式是我看完论文最想留下来的概念工具——它直接告诉你,下次 scaling 失效时该往哪个方向 debug。
第二,residual 作为通用 diagnostic。这条线索其实非常 DEQ。但 EqR 给出的实证耦合(图1的线性关系、图3左右等高线同构)非常硬。这意味着以后训迭代模型,可以不用任务标签就监控收敛性,知道模型跑到哪一步够了。
第三,RI + NI 这两个干预的便宜程度。代码改动可能就十几行——但 Maze 上从 44.9 涨到 82.2、加深加宽后到 93.0,这个 ROI 太香了。
需要打问号的地方:
第一,任务的局限性。Sudoku、Maze 这类约束满足问题有非常清晰的"对/错"结构,是不是吸引子框架天然适配的场景?换到开放式生成任务(比如 LLM 文本生成)上,"任务景观"本身就模糊得多——你怎么定义"正确解的盆地"?论文 Appendix A.5 提到 Mini-ARC 有效,也提到能迁到 Transformer backbone,但主战场还是结构化推理。这套吸引子语言能不能搬到 LLM 的 chain-of-thought 上去,我自己持谨慎乐观——可能需要一些非平凡的改造。
第二,收敛只是一个学到的代理。论文自己也强调了这一点:"convergence is useful here not as a task-agnostic certificate, but as a learned proxy whose reliability depends on the attractor landscape." 也就是说,把 residual 当 reward signal 这件事在景观还没塑造好时是会反咬你一口的(图8最左面板)。这给后续工作留了个口子——在还没达到 (d) 模式时,怎么知道自己在 (d)?
第三,和 baseline 的同台条件。EqR 用的 backbone 跟 TRM "block-level matched",但参数量比前馈基线小一个数量级(5.03M vs 105.6M)。在 Table 1 把 EqR 和 256 层前馈直接比有点不公平——256 层前馈 OOM 了,公平的对比可能是给迭代模型一个相同 FLOP 预算的前馈对手。当然这种对比大概率还是迭代赢,但把数据放成 99.8 vs OOM 的视觉冲击,我觉得有点过头了。
工程启发
如果你也在做迭代式潜空间推理(包括 latent reasoning、recurrent depth、weight-tied transformer 这些方向),这篇论文有几个我觉得能直接搬走的点:
-
训练时随机化初始状态。如果你打算测试时做 best-of-N,训练时就要让模型见过多种 \(\mathbf{z}_0\),否则训练-测试分布会不一致。代码改动就一行
z_0 = randn(...)。 -
小幅度路径噪声。\(\beta=0.01\) 这种级别的扰动,几乎不影响单条轨迹的质量,但能显著改善景观结构、提升路径独立性。
-
用 residual 做 best-of-N 选择——但前提是先验证收敛-正确性耦合。在你的任务上画一张图1那样的散点图,看 residual 和准确率是不是真的强相关。如果不是,先回去做 RI+NI,别急着做 best-of-N。
-
ACT 不是可选项,是必需品。如果你打算把深度推到 100+,没有自适应停止,平均成本会爆炸。Sudoku-Lite 上 17.4 倍算力节省这种数,对生产部署是决定性的。
-
debug scaling 失效用四象限框架。深度加了不涨?看是 (a) 还是 (c)。广度加了不涨?看是不是 D 还不够大、或者是不是 (a)。这个心智模型比"加更多算力"的摸鱼版方法论有用得多。
最后一句
这篇论文对我来说最大的价值不在于刷出了 99.8% 这种数字——结构化推理任务的 SOTA 一直在变。真正值钱的是它把"为什么迭代模型能 scale"这件事写成了一套可以验证、可以失效、可以诊断的机制。Zico Kolter 组延续了 DEQ 那条吸引子的脉络,但这次松弛得更接地气、更能落地。
下一步我会去看的事是:这套吸引子框架能不能搬到 LLM 的潜思考上去——比如 latent CoT、Coconut 那一系列工作。如果可以,"测试时给模型多想几秒"这件事就有了机制解释,而不是凭手感堆 token。
如果你也在做相关方向,强烈推荐去把 EqR 的代码 clone 下来跑一下:https://github.com/locuslab/EqR。Sudoku-Extreme 这个 benchmark 我觉得未来一段时间会成为迭代推理方向的"开发机"——它够难、可控、能区分记忆与泛化,跑起来还不至于太贵。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我