多奖励 RL 训练崩了?阿里云这篇 DVAO 给了 GRPO 一个真正干净的多目标解
一句话先把判断撂这儿:这是 GRPO 多奖励工程化里我最近读到最舒服的一篇。没有引入新超参、没有再叠一层网络、没有靠 reward shaping 调魔法常数,就一个 6 行公式的修改,把 RC(Reward Combination)和 AC(Advantage Combination)那两个常年被工程同学吐槽的毛病一次解决了。
核心摘要
如果你做过多奖励的 RLHF/RLVR 训练,下面这场景应该不陌生:你想让模型既答得对又答得短,于是 reward 加个长度项 r_acc + r_length,结果跑着跑着——acc reward 在涨,但 loss 抖得厉害,输出长度反而越来越奇怪;换成把两路 advantage 各自归一化再加权(也就是 AC),稳是稳了,但权重得调到天荒地老,不同任务还得重调一遍。
这篇来自阿里云的 DVAO(Dynamic Variance-adaptive Advantage Optimization)干的事很简单:让 advantage 的组合权重随着每个 rollout group 内各 reward 的经验方差动态变化。方差大的目标(说明这个方向还有学习信号)权重上去,方差小的目标(已经学得差不多了)权重退下来。整套机制零超参、纯数据驱动,作者还顺手给了三个数学命题,证明它的 advantage 幅度有界、隐式带跨目标正则。
效果上,Qwen3-4B-Base 在 5 个数学 benchmark 平均 acc 从 RC 的 38.99 拉到 42.19 个点,更关键的是长度合规率从 96.39 怼到 99.91 个点——基本就是"全部 rollout 都没超长"。工具调用任务在 BFCL-v4 上 Qwen2.5-7B-Instruct 平均 acc 拉到 63.00,多轮(Multi-Turn)从 RC 的 14.75 涨到 22.25 个点。
它不是一个"颠覆性"的工作。但对于在做多奖励 RL 的工程同学来说,它很可能是你下次实验默认要换上去的那一行代码。
论文信息
- 标题:DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
- 作者:Guochao Jiang, Jingyi Song, Guofeng Quan, Chuzhan Hao, Guohua Liu, Yuewei Zhang
- 机构:Alibaba Cloud Computing(阿里云)
- 发布日期:2026-05-25
- arXiv:2605.25604
一、为什么多奖励 RL 一直没个干净的方案
先把场景放具体。GRPO 之所以这两年成了标配,是因为它把 PPO 那套 critic 给省了——一个 prompt 出 G 条 rollout,把每条的 reward 在组内做 z-score,得到 advantage 直接拿去做 policy gradient。流程极简,训练也稳。
但单 reward 走天下的好日子早就过去了。真实业务里你至少要兼顾这几路信号:
- 答对没(accuracy)
- 输出有没有超长(length penalty)
- 工具调用格式合不合法(format compliance)
- 有没有幻觉(faithfulness)
- 有没有触发安全策略(safety)
到了多奖励,工程同学最常用的两条路其实就两个流派:
路线 A:Reward Combination(RC)
把多路 reward 先加权求和成一个标量,再走标准 GRPO 的归一化:
简单粗暴,一行代码改完。但问题在哪?
路线 B:Advantage Combination(AC)
每路 reward 先各自做 z-score,得到独立的 \(A_k\),再加权合并:
各路 advantage 量纲对齐了,看起来更稳。但它有个隐藏代价。
命题 1:RC 比 AC 更"暴躁"
作者上来就摆了个不太被注意的数学事实:RC 的 advantage 平方平均一定不小于 AC——
等号当且仅当所有 reward 在 rollout 组内完全正相关(\(\hat\rho_{kl}=1\))才成立。
什么意思?AC 因为利用了不同 reward 的相关性,advantage 幅度天然被压住,所以训练比 RC 平稳。但这也是 AC 的另一个问题——它把不同 reward 当成"完全独立"来归一化,等于把跨目标的协同/冲突信号一起扔了。
我自己之前调多目标 GRPO 的时候碰到过这个:用 AC 把权重调对了某一组任务,换一组任务(reward 之间相关性变了)之后就得重调。这不是你写代码不细,是静态权重 × 独立归一化这个组合本身就没法适应数据分布。
对,这就是 DVAO 想攻击的两个问题:RC 不稳、AC 静态。
二、DVAO 怎么解:让方差去说话
DVAO 的核心改动其实就一个等式。把 AC 的权重改成"方差自适应"的:
其中 \(\sigma_k^i = \text{std}(\{r_k^{(i,j)}\}_{j=1}^G)\) 是第 \(i\) 个 prompt 的 G 条 rollout 上第 \(k\) 路 reward 的经验标准差。
然后 advantage 长这样:
读到这儿你可能会问:就这?
对,就这。但你得理解为什么"方差"是对的信号。
直觉:方差就是"还有多少能学的"
GRPO 是组内归一化,如果某路 reward 在 G 条 rollout 上方差为 0(比如所有回答的 format 都已经全对了),那这路其实已经没有学习信号了——再让它在 advantage 里占大权重,纯粹是在给梯度添乱。反过来,方差大的那一路,说明模型在这个目标上还在分化、还有提升空间,应该让它多说话。
DVAO 就是把这个工程经验直接写进了权重的更新规则,每一步、每一组都重新算一次,不需要人手调度表。
命题 2:DVAO 的 advantage 永远比 RC "温柔"
证明的关键恒等式是 \(\sigma_{\text{sum}}^i\, A_{\text{sum}}^{(i,j)} = \sum_k w_k\, \sigma_k^i\, A_k^{(i,j)}\),再用 Cauchy-Schwarz 推出 \(\sigma_{\text{sum}}^i \leq \sum_k w_k\, \sigma_k^i\)。所以 DVAO 在分母上比 RC 大,advantage 自然就有界了。
这就是 DVAO 同时拿到 RC 的"利用相关性"和 AC 的"幅度可控"两个好处的根本原因——它不是把两个方案折中,是用方差作为一个干净的中间媒介把两边连起来。
命题 3:DVAO 是隐式跨目标正则
这条最有意思。AC 的偏导数只依赖单目标自己:
DVAO 的偏导数则跑出了跨目标耦合项:
注意最后那个 \(A_{\text{DVAO}}\cdot A_k\)。当某条 rollout 在第 \(k\) 路上很好(\(A_k\) 很大),但综合 advantage \(A_{\text{DVAO}}\) 也很大(说明其它目标也好),这个二阶项就会主动抑制 \(r_k\) 的边际收益——避免单目标"独大"挤压其它目标的梯度。
我对这条特别买账。多目标 RL 里"奖励博弈"是个老问题——某个 reward 容易刷分,模型就死磕它、其它目标全摆烂。AC 的偏导跟其它目标完全没关系,所以它对这种"独大"是没免疫力的;DVAO 的耦合项把这事压住了,而且不需要写一行 explicit regularizer。
三、实验:训练动态先过一遍
光看公式不过瘾,我们先看训练动态——这一节其实比主表更能看出 DVAO 在干什么。
3.1 数学任务(Qwen3-4B-Base)的训练曲线
数学任务用的两路 reward:\(r_{\text{acc}}\)(答案对错,0/1)+ \(r_{\text{length}}\)(输出 ≤ 4000 tokens 给 1,否则给 0)。训练数据 DAPO-MATH-17K,rollout group \(G=16\),500 步。
Accuracy reward 的均值
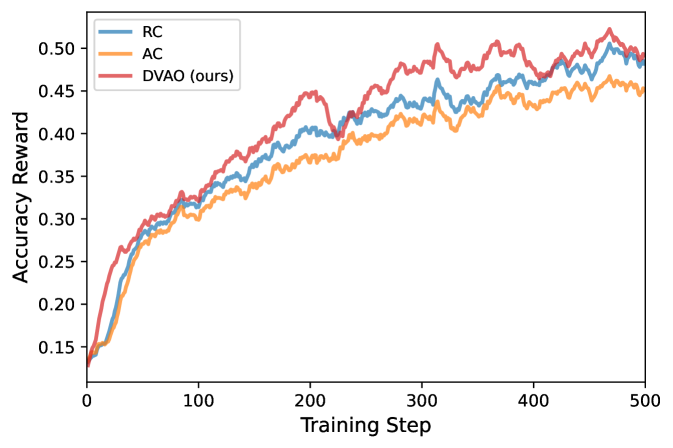
图 1:Accuracy reward 均值。RC(蓝)、AC(橙)、DVAO(红)。DVAO 全程领先,第 200 步左右突破 0.45,最终接近 0.50;AC 一直拖在最下面,最终只到 0.45 出头。
这条曲线是最朴素的"谁学得快"。DVAO 在前 50 步就跟另两条拉开差距,并且没有出现 RC 那种第 200 步附近的小震荡——说明跨目标耦合项确实把"过度上调单目标"那部分梯度噪声压住了。
Accuracy reward 的标准差
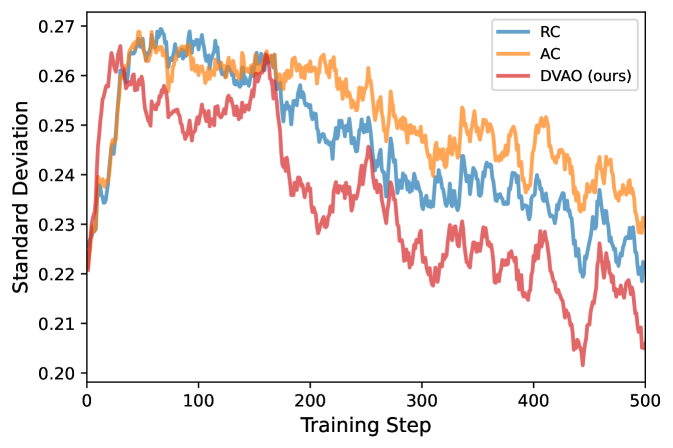
图 2:Accuracy reward 的组内标准差。DVAO(红)从第 200 步开始持续下降,最终跌到 0.20-0.21;AC(橙)反而是三条里方差最高的,全程在 0.23-0.26 区间徘徊。
这张图我盯着看了挺久。组内 std 在下降说明什么?说明同一个 prompt 的 16 条 rollout 越来越"一致地答对",策略在这个分布上收敛得更紧。DVAO 把 std 压到 0.20 以下而 AC 还在 0.23 上方晃,这就是命题 2 在工程上的可视化体现:advantage 幅度有界、梯度更干净,所以策略更新更聚焦。
Length reward 的均值
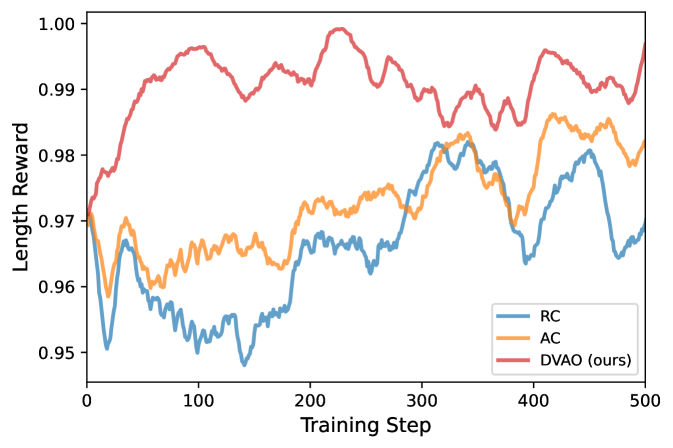
图 3:Length reward 均值(≤4000 tokens 比例)。DVAO(红)从第 50 步起就贴着 0.99-1.00,RC(蓝)和 AC(橙)反复在 0.96-0.98 拉锯。
这是 DVAO 在多目标上"两全"的最直接证据——长度约束基本被打满,而且不是靠牺牲 acc 换来的(图 1 同时在涨)。RC 和 AC 都还在为长度纠结,DVAO 已经把这个目标"交差"了,腾出来的优化预算就全压在 acc 上。
3.2 Qwen3-8B-Base:放大模型规模后的结论
放大模型规模到 8B 后,结论一致。我直接把数据贴出来——
| 方法 | AIME-2024 | AIME-2025 | MATH500 | OlympiadBench | AMC23 | Avg Acc | Avg Len |
|---|---|---|---|---|---|---|---|
| Base Model | 11.87 | 8.96 | 69.20 | 34.95 | 41.56 | 33.31 | 94.28 |
| GRPO(单 reward) | 29.58 | 24.58 | 87.93 | 55.57 | 65.21 | 52.57 | 63.47 |
| RC | 21.04 | 16.25 | 84.97 | 49.73 | 59.33 | 46.26 | 98.71 |
| AC | 20.41 | 15.62 | 84.42 | 48.52 | 58.13 | 45.42 | 98.84 |
| GDPO | 1.67 | 0.00 | 35.07 | 9.15 | 27.56 | 14.69 | 99.99 |
| DVAO | 21.87 | 18.33 | 86.10 | 50.62 | 60.54 | 47.49 | 99.92 |
3.3 一个绕不过去的发现:单 reward 的 GRPO 在 acc 上反而最强?
等等。我盯着这表愣了一会儿——8B 上 GRPO(单 reward)的 acc 平均是 52.57,比 DVAO 的 47.49 高了 5 个点。4B 上也是同样情况:GRPO 39.91 vs DVAO 42.19,这次 DVAO 反过来了,但差距没大到夸张。
这是不是说明多 reward 反而拖累了 acc?不完全是。看 Length 那一列你就明白了:
- GRPO(单 reward):4B 长度合规率 77.84%,8B 只有 63.47 个点——意思是 8B 模型在 AIME 题目上有 超过三分之一的回答超过了 4000 tokens。
- DVAO:长度合规率 99.91% / 99.92%。
所以这个对比根本不公平——GRPO 是在"不管长度爆不爆"的前提下刷 acc 的,相当于人家裸跑你穿铅鞋。真实部署里输出超长是会被截断或者直接拒绝服务的,63% 的合规率意味着每三次请求一次出问题,工程上没法上线。
DVAO 是在 99.9% 长度合规率的硬约束下,还能保住 47.49 的 acc——这个对比才是公平的。
而且看 RC 和 AC:长度合规度都做到了 98%+,但 acc 比 DVAO 低 1-2 个点,说明 DVAO 不是在"acc 和 length 之间做了更好的权衡",是在 length 已经几乎打满的前提下,还能挤出来 acc 的额外增益。这才是这篇论文真正硬的地方。
老实说,这种"看起来 GRPO 单 reward 最强"的表,如果作者不主动指出长度合规率,是很容易被一些读者误读成"DVAO 不如 GRPO"的。这也是为什么"长度合规率"必须作为一等公民进表格——单看 acc 等于刻意放水。
四、工具调用任务:DVAO 的优势更明显
数学任务的 length reward 比较"软"(多写一点也能答对),但工具调用就不一样——format 错了,整个调用直接挂掉。
BFCL-v4 划分三档:Live(真实场景的简单调用)、Non-Live(虚构场景的复杂调用)、Multi-Turn(多轮对话+工具)。这是 Qwen2.5-7B-Instruct 的结果:
| 方法 | Live Acc | Live Fmt | Non-Live Acc | Non-Live Fmt | Multi-Turn Acc | Multi-Turn Fmt | Avg Acc | Avg Fmt |
|---|---|---|---|---|---|---|---|---|
| Base Model | 62.92 | 0.0 | 69.56 | 0.0 | 11.00 | 0.0 | 47.83 | 0.00 |
| GRPO | 68.76 | 0.0 | 81.65 | 0.0 | 6.38 | 0.0 | 52.26 | 0.00 |
| RC | 75.06 | 87.58 | 85.33 | 96.11 | 14.75 | 45.56 | 58.38 | 76.42 |
| AC | 63.80 | 67.39 | 56.21 | 85.40 | 12.75 | 51.33 | 44.25 | 68.04 |
| GDPO | 76.17 | 68.90 | 86.73 | 85.83 | 17.50 | 49.63 | 60.13 | 68.12 |
| DVAO | 79.68 | 77.93 | 87.06 | 95.11 | 22.25 | 64.58 | 63.00 | 79.21 |
几个值得注意的点:
- GRPO 单 reward 的 Format 全是 0——它根本没把 format 当目标,碰巧偶尔对一次但合规率几乎为 0,等于训练完了基本不能用。
- AC 这次掉链子了:7B 上 Avg Acc 只有 44.25,比 base model 还低。我猜是 AC 的静态权重在工具调用场景下选得不对,加上独立归一化丢了"format 错了 acc 必然为 0"这个强相关性,模型在权重上跑偏了。
- DVAO 在 Multi-Turn 上提升最猛:22.25 vs RC 的 14.75,绝对涨了 7.5 个点。多轮工具调用最考验"format + acc"的协同——错一步全错——而 DVAO 的跨目标耦合项天然契合这种场景。
3B 模型上 DVAO 的优势同样存在:Multi-Turn Acc 12.50 vs RC 5.62,翻了一倍多。
五、Pareto 前沿:DVAO 对权重不敏感
到这儿你可能会想:DVAO 表现好是不是因为作者把 \(w_k\) 调得正好?
作者做了权重扫描:\(w_1 \in \{0.1, 0.3, 0.5, 0.7, 0.9\}\),\(w_2 = 1 - w_1\),看每种方法在不同初始权重下的 Pareto 前沿。
数学任务(Qwen3-4B-Base)
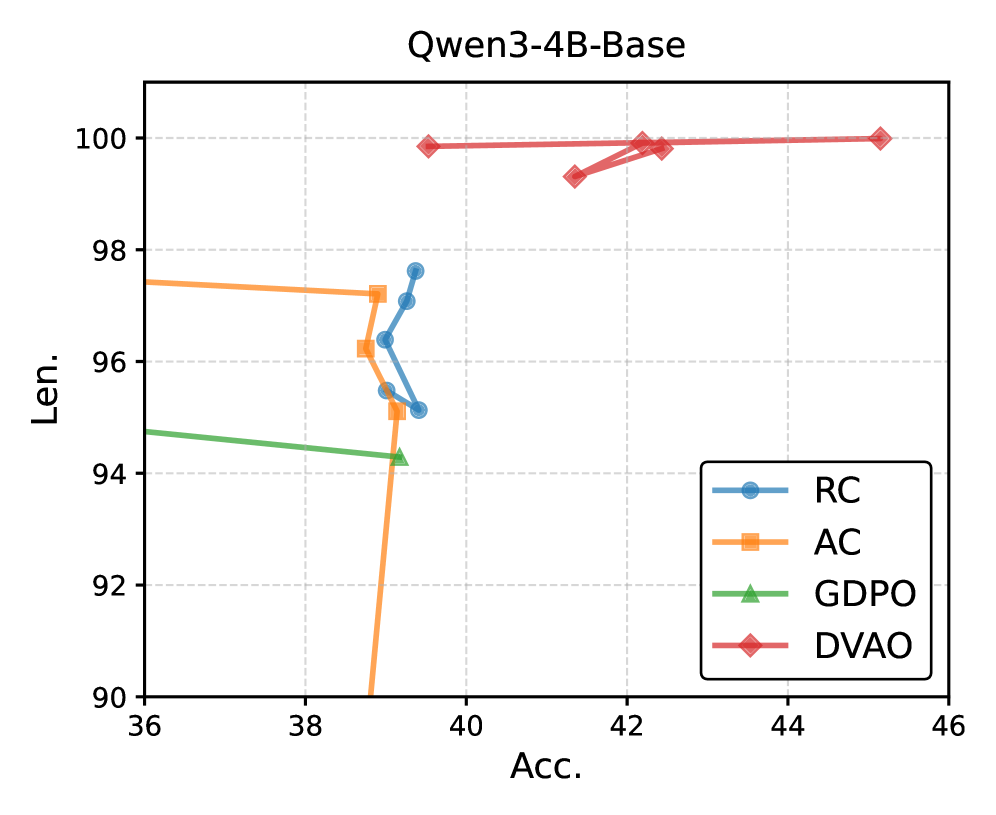
图 4:横轴 Acc,纵轴 Length 合规率。DVAO(红色钻石)整体在右上角形成一个紧凑的簇,最佳点 (Acc, Len) ≈ (45.2, 100);RC/AC 全部挤在 Acc≈39 附近的窄带;GDPO 拉成一条 Acc 36-40 之间的横线,没法跟 DVAO 比。
工具调用任务(Qwen2.5-3B-Instruct)
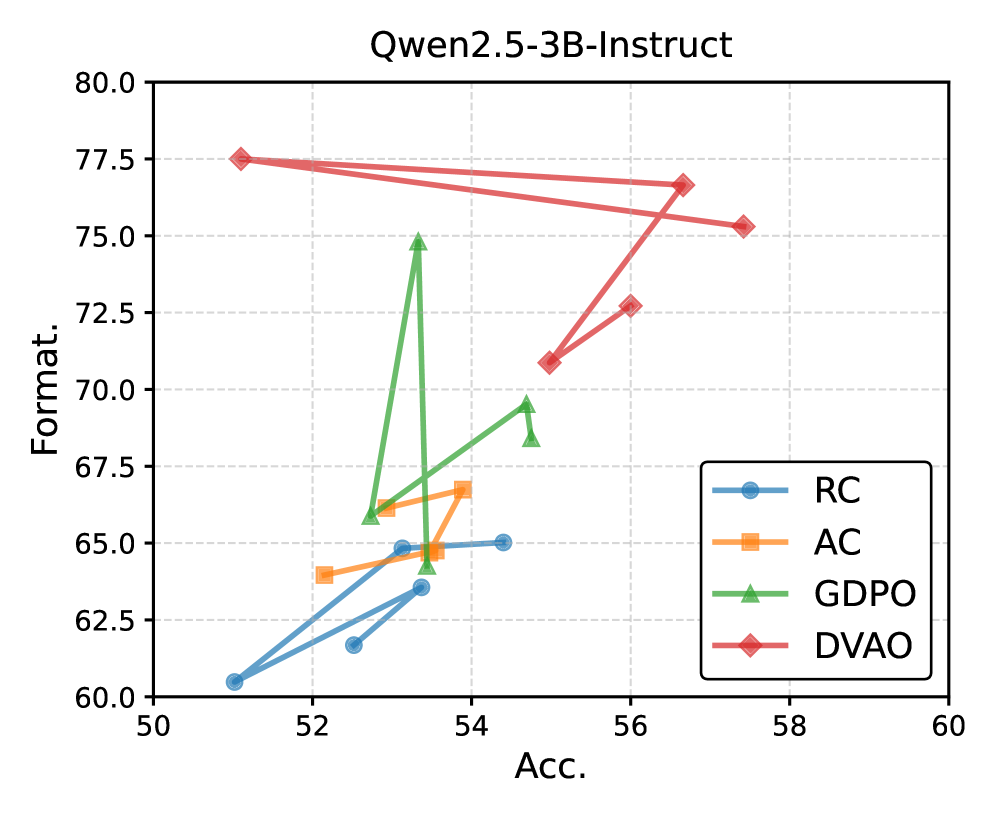
图 5:横轴 Acc,纵轴 Format 合规率。DVAO(红色钻石)形成一个"右上保护伞",覆盖 Acc 51-57.5、Format 71-78 的最佳区域;RC(蓝圆)困在 Acc 51-54 / Format 60-65 的左下;AC(橙方)严重不稳定,大幅跨越 Acc 52-54;GDPO(绿三角)走出一个奇怪的 Z 字。
这张图我觉得是 DVAO 最有说服力的论据。对工程来说真正重要的不是单组权重调得多准,而是调出来的多组权重普遍都能用。DVAO 的 5 个点几乎都在 Pareto 前沿上而且彼此靠得近,说明初始权重选择对最终性能不敏感——这才是能在生产上替换 RC/AC 的前提。
RC 那种挤成一坨的形态,反过来是它的另一个隐藏问题:它对 reward 的尺度敏感,权重一变就被某一路 reward 主导,几乎不能调出有差异的 trade-off。
六、几个我的判断
6.1 这篇值得读的核心点是什么?
不是"提了一个新的多奖励 RL 算法"——多奖励 RL 的方法学术界已经太多了。它的真正价值是:用一个最简洁的方差自适应权重,把 RC 和 AC 这两个工业界默认方案的明显毛病一起治了,而且没有引入任何新超参。
对工程同学来说这个性价比是无敌的。换上 DVAO 你不会失去 GRPO 的简洁性,但你拿到了 RC 没有的"幅度有界"和 AC 没有的"跨目标耦合"。
6.2 但我也不完全买账的几个点
第一,GDPO 这个 baseline 太弱了。表 1 里 GDPO 在 4B 上 Avg Acc 只有 13.41,8B 上 14.69,比 base model 还差很多——这不是一个有竞争力的 baseline 表现。要么 GDPO 这个方法本身有问题(不太可能,文献上不是这样),要么作者的复现有问题。我希望作者能在附录里给出 GDPO 的完整训练曲线,看看是不是某些超参没调对,或者收敛模式有特别。否则把它放进表里有点虚张声势的味道。
第二,理论部分对方差估计的稳健性讨论不够。DVAO 把所有信任都押在 \(\sigma_k^i\) 这个组内经验标准差上,但 G=16 的样本算 std 是有相当噪声的。作者在附录 E 里也承认 G≤4 时方差估计可能噪声过大,但 G=16 是不是就足够稳健?没有给出敏感性分析。我自己的工程经验是:组内 std 在某些"全队都答对了"或"全队都答错了"的退化场景下会变成 0 或极小,这时候 DVAO 的权重会怎么动?分母会不会爆?论文没写明数值稳定性的处理(比如加 \(\epsilon\) smoothing)。
第三,跨目标个数到 3 个以上呢? 论文实验全是双目标(acc + length 或 acc + format)。三目标以上的情形,DVAO 的"方差自适应"在不同方差量级的 reward 上会不会失衡?比如一路 reward 是 0/1 离散(std 上限 0.5),一路是连续 reward(std 量级可能完全不同),DVAO 的归一化会偏向方差天然就大的那一路。这个在附录 E 里也只是一笔带过,工程上要落地需要自己再做实验。
6.3 工程落地建议
如果你正在做多奖励 GRPO 训练,我会建议:
- 第一时间换上 DVAO。代码改动不到 10 行(在你算 advantage 的地方加一段方差归一化),收益看起来非常确定。
- 保留 reward 权重 \(w_k\) 作为 prior。DVAO 不是把 \(w_k\) 给省了,而是让它"在方差自适应的基础上再发挥作用"——你仍然可以表达"acc 比 format 重要",但不需要再为不同任务精调具体数值。
- 加 \(\epsilon\) smoothing 防退化。论文没明说但我强烈推荐:\(\sigma_k^i \leftarrow \max(\sigma_k^i, \epsilon)\),避免组内 reward 全相同时分母爆炸。
- 多目标场景下监控每路 \(\tilde w_k\) 的曲线。这是 DVAO 最有诊断价值的副产物——你能看到训练的每一步模型"在哪个目标上还有学习信号"。如果某一路的 \(\tilde w_k\) 长期为 0,说明这个 reward 已经饱和或者没设计好,可以考虑换 reward 函数或调整 prior 权重。
七、总结
DVAO 不是一篇会让你"哇好惊艳"的论文。它解决的是一个工程同学每天都在头疼的具体问题——多奖励 GRPO 训练为什么调不稳——并给出了一个数学上干净、实现上简单、效果上明显的方案。
我读完最大的感受是:"这种问题,本来就该是这种解法"。它没有引入复杂机制,没有依赖外部模型,甚至没有改 GRPO 的主体框架,只是把一个我们工程上靠人肉调的"权重感觉",变成了一个由组内方差自动算出来的公式。这种"把直觉数学化"的论文我特别喜欢——因为它不是制造问题来炫技,是把已有的问题做得更对。
如果你正在 RL 阶段做多目标对齐,不管是 reasoning 还是 tool-use,强烈建议下次实验默认就跑 DVAO。
参考链接
- 论文:arXiv:2605.25604
- HTML 版:https://arxiv.org/html/2605.25604
- 训练框架:verl
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我