TransMamba:把 Transformer 和 Mamba 塞进同一套参数里,按 token 长度自由切换
核心摘要
混合 Transformer 和 Mamba 这件事,过去做法都很笨——要么固定每层用谁,要么按比例硬叠,结构一旦定死就再也动不了。TransMamba 这篇 AAAI 2026 的工作换了个角度:让 QKV 和 CBx 共享同一套参数矩阵,通过一个无参 Memory Converter 在序列中间某个位置(叫 TransPoint)从 Attention 模式无缝切到 SSM 模式。同一组权重,前半段当 Transformer 用,后半段当 Mamba 用,按层、按 token 长度灵活调度。在 1.5B 规模上 LongBench-v2 涨到 38.76、训练时间降到 Transformer 的 0.75,PhoneBook 这种精确检索任务还能保住接近纯 Transformer 的水平。这在我看来是这篇论文最值钱的地方——它用一个偏数学的对偶视角,把两种架构在同一组权重里捏合到一起,而不是工程上拼一拼。
论文信息
- 标题:TransMamba: A Sequence-Level Hybrid Transformer-Mamba Language Model
- 作者:Yixing Li, Ruobing Xie, Zhen Yang, Xingwu Sun, Shuaipeng Li, Weidong Han, Zhanhui Kang, Yu Cheng, Chengzhong Xu, Di Wang, Jie Jiang
- 机构:Tencent Hunyuan、香港中文大学、澳门大学
- 会议:AAAI 2026
- arXiv:https://arxiv.org/abs/2503.24067
- 代码:https://github.com/Yixing-Li/TransMamba
一、为什么还要再做一篇 Trans-Mamba 混合
说实话我看到这个题目第一反应是:这种缝合工作不是已经做烂了吗?Jamba、Zamba、各种 Hybrid 出了一堆,按比例叠层、按位置插 Mamba,还能玩出什么花。
但仔细看下去发现作者切的角度确实不太一样。
现有 Hybrid 模型的根本问题在于它是层级(layer-level)混合——这层 Attention,下层 SSM,再下层 Attention,每层是哪种结构在训练之前就定死了,比例和顺序都不能动。Jamba 那种 1:7 的搭配一改就掉点,结构上的灵活性近乎为零。
更糟的是,这种层级缝合根本没回答一个更本质的问题:Transformer 在短序列上训练快,Mamba 在长序列上训练快——那一条序列从短到长的过程中,模型有没有可能在不同位置用不同机制?现有 Hybrid 没办法做这件事,因为它不知道某一层在某一个 token 位置应该用哪个机制,除非你训两套参数,但那就不是一个模型了。
我之前在做长上下文训练的时候碰到过类似的纠结。如果用纯 Attention,长序列上 KV Cache 内存压力顶不住,训练吞吐也掉得厉害;切成 Mamba 之后吞吐上来了,但短序列上的精确建模能力又不如 Attention,做一些 Needle-in-Haystack 风格的检索任务直接拉胯。当时唯一能做的就是按层级混合,1:1 或者 1:7 拼一拼,但效果上限始终被这个固定比例钉死。
TransMamba 的切入点就是这里——在序列内部按 token 位置切换机制,而不是在层之间切换。
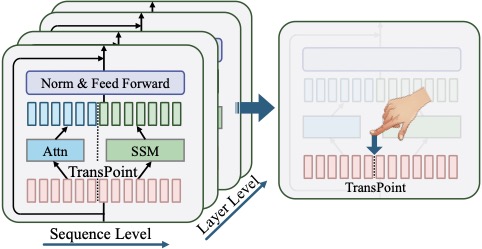
图1:TransMamba 的核心思路。Sequence Level 维度上,前 N 个 token 走 Attention 路径,TransPoint 之后走 SSM 路径;Layer Level 维度上,不同层的 TransPoint 位置不同,形成跨层的渐进式切换。
这张图其实把整个 idea 讲清楚了——序列方向有一根分界线,分界线之前是 Transformer,之后是 Mamba;不同层的分界线位置还不一样,从浅层到深层逐渐迁移。这就是关键。
二、为什么这件事能做成——Attention 和 SSM 的对偶
要让一组参数同时服务 Attention 和 SSM,前提是这两种机制的数学结构本身要能对齐。这块的洞察不是 TransMamba 原创,而是从 Mamba2 那篇工作继承过来的。
Mamba2 当时给出了一个非常震动人的结论:SSM 在合适的简化下可以写成 dual form,跟 Attention 的矩阵运算几乎完全对称。论文里给了一张表把这件事说得很直白:
| Attention | SSM |
|---|---|
| \(\mathbf{Q} = \delta(\mathbf{H} \mathcal{W}_{\mathbf{Q}})\) | \(\mathbf{C} = \delta(\mathbf{H} \mathcal{W}_{\mathbf{C}})\) |
| \(\mathbf{K} = \delta(\mathbf{H} \mathcal{W}_{\mathbf{K}})\) | \(\mathbf{B} = \delta(\mathbf{H} \mathcal{W}_{\mathbf{B}})\) |
| \(\mathbf{V} = \delta(\mathbf{H} \mathcal{W}_{\mathbf{V}})\) | \(\mathbf{X} = \delta(\mathbf{H} \mathcal{W}_{\mathbf{x}}) \circ \Delta\) |
| \(\mathbf{y} = (\mathbf{L} \circ \mathbf{Q}\mathbf{K}^T) \mathbf{V}\) | \(\mathbf{y} = (\mathbf{A}^{\times} \circ \mathbf{C}\mathbf{B}^T) \mathbf{X}\) |
Q ↔ C,K ↔ B,V ↔ x,唯一不同是掩码矩阵:Attention 用因果掩码 L,SSM 用累乘衰减矩阵 \(A^\times\)。
把这件事再往前推一步——既然两套机制的参数矩阵一一对应,那能不能干脆让它们共享同一组 W?这就是 TransMamba 的胆子。Q 和 C 用同一个 \(\mathcal{W}_{QC}\),K 和 B 用同一个 \(\mathcal{W}_{KB}\),V 和 x 用同一个 \(\mathcal{W}_{Vx}\)。整个模型只有一套权重,但前向时可以选择走 Attention 路径还是 SSM 路径。
后续还有篇蒸馏工作 MOHAWK 做过验证:把 Llama 的 QKV 权重对齐到 Mamba 的 CBx 上做蒸馏,居然能蒸出来——这间接说明这两种参数确实是可以互通的。这不是数值巧合,是数学结构的同源性。
我自己第一次看到 Mamba2 那张对偶表的时候是有点震动的。在那之前我对 SSM 和 Attention 的理解一直停留在"两种独立的序列建模机制",是 Mamba2 让我意识到它们更像是同一个东西的两个面——一个把序列依赖写成显式的 \(QK^T\) 矩阵,另一个把它压缩到一个递推的隐状态里。两者之间的差别在表达形式而不在底层语义。这套对偶视角是 TransMamba 能成立的根本理由。
三、训练效率上为什么有空间
这块得花点篇幅讲清楚,不然你不会理解 TransPoint 为什么非这么设。
Transformer 和 Mamba 在训练 FLOPs 上各有优势:
| 模型 | 单层训练 FLOPs |
|---|---|
| Transformer | \(O(T^2 N)\) |
| Mamba | \(O(T N^2)\) |
| TransMamba | \(O(P^2 N + (T-P) N^2)\) |
T 是序列长度,N 是 state 维度,P 是 TransPoint 位置。
注意看:当 T \lt N 时 Transformer 占优(\(T^2 N \lt TN^2\)),这就是为什么大家觉得 Attention 在短序列上训练快;当 T \gt N 时 Mamba 占优。临界点就在 T 和 N 相等的位置。
但实际训练里 T 通常远大于 N(比如 T 是 8k、N 是 1.5k),所以序列整体来看 Mamba 是占优的。然而序列前面那一小段,Attention 仍然比 SSM 快——因为前 N 个 token 内 \(T^2 N \lt TN^2\) 还成立。
TransMamba 的思路就是把这个分界线显式表达出来:让前 P 个 token 走 Attention,后面 T-P 个 token 走 SSM。FLOPs 是 P 的二次函数,对 P 求导可以得到最优点 \(P_{\text{optimal}} = N/2\)。论文里设置 N=1536、T=8192,理论最优 P 大概在 768,实际实验跑出来在 2048 附近——和理论有偏差是正常的,因为 Attention 和 Mamba 的工程实现优化系数不一样。
我特别喜欢这个分析,因为它把"为什么要混合"从直觉层面落到了 FLOPs 公式上。这不是一个工程拼接,而是有数学动机的。
四、Memory Converter——把 Attention 的状态喂给 SSM
这是 TransMamba 真正巧妙的地方。
序列前 P 个 token 走完 Attention 之后,得到的是一堆 Q、K、V 中间结果。但 SSM 需要的是一个隐状态 \(h_0\),作为递推的起点:
那个起始状态 \(h_0\) 从哪儿来?如果直接用零向量 SSM 显然丢了前 P 个 token 的所有信息。这就是 TransPoint 处的核心难题——信息怎么在两种机制之间无损传递。
作者的做法挺漂亮:直接用 K 和 V 算出一个等效的 SSM 隐状态。
把 SSM 的隐状态展开:
由于 K↔B、V↔x 在共享参数下是同一组数,前 P 个 token 算出来的 K 和 V 直接就是 SSM 视角下的 B 和 X。所以等效隐状态可以写成:
然后取 \(h_0 = h_s[-1]\),作为后半段 SSM 的初始状态。
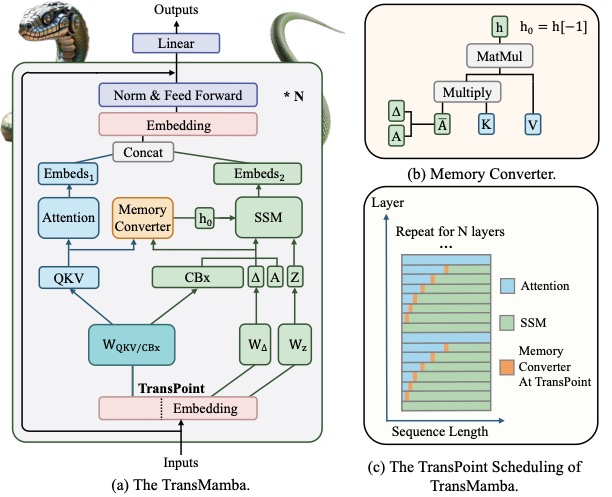
图2:(a) 主架构。\(W_{QKV/CBx}\) 是共享的核心参数,输入沿 TransPoint 切成两段,前段走 Attention 输出 Embeds1,后段走 SSM 输出 Embeds2,两段 concat 后做后续 FFN。Memory Converter 负责在 TransPoint 处把 KV 转成 SSM 的初始 h0。(b) Memory Converter 内部展开。(c) TransPoint 调度示意:每层有不同的 TransPoint,蓝色是 Attention 区域,绿色是 SSM 区域。
关键是这一步不需要任何额外参数。不是再训一个 adapter,不是加一层 MLP,就是用现有 K、V 直接代数推导。这在工程上意味着零额外开销。
我看到这个设计的时候真的挺被打动的。很多人做 Hybrid 都会加一个 transition module 来对齐两种特征空间,但 TransMamba 直接说:因为参数共享,K 就是 B、V 就是 x,所以 SSM 的隐状态本来就能从 KV 算出来,只是平时大家没这么用而已。这是一个"重新发现"的设计,不是堆叠出来的设计。
再深一层想,Memory Converter 的存在本身也澄清了一件事:TransPoint 处的信息是真的连续的。前段 Attention 处理过的 token 信息,全都被压缩进 \(h_s[-1]\) 这个隐状态里传给后段 SSM。这跟"硬切两段、各自处理"完全不是一回事——后者会丢失跨 TransPoint 的依赖,而 TransMamba 不会。这一点在长上下文 benchmark 上的领先(后面 LongBench-v2 那张表)就是直接证据。
顺便说一句,Memory Converter 这个机制虽然简洁,但实现的时候有个隐藏细节:\(A^\times\) 这个累乘衰减矩阵在 \(h_s\) 计算里需要被显式构造出来。在前段 Attention 走 \(QK^T\) 路径的时候并不会用到 A,但在 TransPoint 处如果你想算等效隐状态,A 就必须算出来。这意味着 TransPoint 那一步本身有额外的 FLOPs 开销,虽然相对整段序列来说占比很小,但在工程实现上是个细节。
五、TransPoint 怎么调度——三个经验法则
设计完结构,剩下的问题是:每一层的 TransPoint 应该放在哪儿?
直觉上你会觉得每层都放最优 P=2048 不就完了?作者一开始也这么试,结果训练损失很糟。论文做了一组对比实验把这件事说清楚:
| 设置 | TransPoint 调度 | Val Loss | Val PPL |
|---|---|---|---|
| Transformer 基线 | [8192] | 3.098 | 2.194 |
| Layer-shared V1 | [2048] | 3.356 | 2.401 |
| Layer-shared V2 | [4096] | 3.297 | 2.346 |
| Layer-shared V3 | [6144] | 3.308 | 2.339 |
| Layer-specific V4 | [3072, 4096, 5120] | 3.125 | 2.287 |
| Layer-specific V5 | [2048, 3072, 4096] | 3.100 | 2.219 |
| Layer-specific V6 | [512, 1024, 2048] | 3.135 | 2.299 |
| Broad-range V7 | [2048, 4096, 6144] | 3.084 | 2.185 |
| Broad-range V8 | [0, 1024, 2048, 6144, 8192] | 3.022 | 2.053 |
| Fine-grained V9 | [0, 128, 256, 512, 1024, 2048, 4096, 8192] | 2.898 | 1.813 |
这张表透露的信息非常密。
第一个规律是 Layer-specific:所有层都用同一个 TransPoint(V1-V3)效果最差,PPL 比纯 Transformer 还高一截。直觉上是因为同一个位置所有层同时做"Attention→Mamba"的相变,模型被这个突变搞得很难收敛。每层错开来切(V4-V6)就好很多。
第二个规律是 Broad-range:TransPoint 要尽可能覆盖整个序列长度。V4-V6 都集中在 2k-5k 之间窄范围,效果不如 V7-V8 这种从 0 到 8192 全范围铺开的设置。
第三个规律是 Fine-grained:TransPoint 要细粒度密集分布。V9 把 TransPoint 放在对数刻度上的 8 个位置 [0, 128, 256, 512, 1024, 2048, 4096, 8192],按 8 层一个循环铺开,PPL 直接降到 1.813,比纯 Transformer 低了将近 0.4 个点。
最终方案就是 V9。8 层一循环,对数尺度铺开 TransPoint,平均值刻意压在最优 P 偏小的位置(这样能多利用 Mamba 的长序列效率),同时保证不同层之间的 TransPoint 充分错开。
这套调度有意思的地方在于,把它画到 Layer-Sequence 的二维空间上看,整个模型其实是一个"渐进式从 Transformer 过渡到 Mamba"的连续体——浅层 TransPoint 靠后(更多 Attention),深层 TransPoint 靠前(更多 SSM)。这种渐进式设计可能对应了模型在浅层做局部精确建模、在深层做全局压缩抽象的归纳偏好。当然这只是我的猜测,论文没明确这么解释。
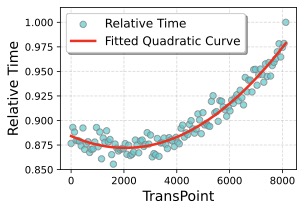
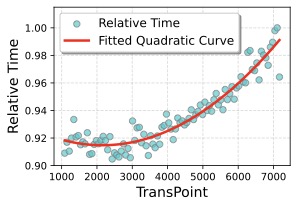
图3:左图 Layer-Shared 调度,相对训练时间是 TransPoint 的二次函数,最优点在 2k 附近;右图 Layer-Specific 调度(即 V9 这类设置),同样呈二次趋势但整体更快。这两张图最大的价值是验证了第三节那个 FLOPs 公式真的成立——不是理论推导拍脑袋。
六、主实验——通用任务上确实涨点
400M 和 1.5B 两个规模,纯 Transformer、纯 Mamba2、Jamba 风格 Hybrid、TransMamba 四个模型同样训 83B token,跑 7 个英文任务。
| Model | ARC-E | ARC-C | CoQA | OBQA | PIQA | PhoneBook | BoolQ |
|---|---|---|---|---|---|---|---|
| Transformer-400M | 60.57 | 58.72 | 5.07 | 42.4 | 52.75 | 38.70 | 60.72 |
| Mamba2-400M | 56.15 | 52.27 | 4.68 | 40.8 | 51.10 | 13.07 | 57.51 |
| Hybrid-400M | 62.33 | 55.78 | 5.52 | 43.6 | 53.89 | 17.60 | 61.66 |
| TransMamba-400M | 62.50 | 59.33 | 6.23 | 44.8 | 55.76 | 39.69 | 64.15 |
| Transformer-1.5B | 60.87 | 59.43 | 5.93 | 48.6 | 56.66 | 41.04 | 61.42 |
| Mamba2-1.5B | 63.64 | 56.00 | 5.30 | 44.0 | 58.97 | 19.08 | 59.20 |
| Hybrid-1.5B | 63.92 | 57.97 | 6.21 | 51.0 | 59.25 | 26.63 | 65.48 |
| TransMamba-1.5B | 64.75 | 63.33 | 6.97 | 50.6 | 59.61 | 40.92 | 66.73 |
几个观察值得盯一下。
PhoneBook 这一列特别有意思。 这是一个精确检索任务——给一堆人的电话号码,问某个人的号码。Mamba2 在这种任务上是出名的灾难(13.07/19.08),因为 SSM 的有限状态压缩天然不擅长精确匹配。Hybrid 模型也好不到哪去(17.60/26.63),因为 Mamba 层把信息压缩了再传给 Attention 层就找不回来了。
但 TransMamba 在 PhoneBook 上拿到了 39.69 和 40.92,几乎追平纯 Transformer。这是为什么?
因为在 TransMamba 里,序列开头那段所有层都是走 Attention 的——只有 token 位置超过 TransPoint 之后才切到 SSM。所以电话号码这种关键信息如果出现在序列前段,就是被 Attention 处理的,精度不会被 Mamba 的状态压缩拉走。这其实是序列级混合相对层级混合的一个本质优势:层级混合无法保证某段 token 在所有层都用同一种机制处理,序列级混合可以。
LongBench-v2 上的表现也值得看:
| Model | Overall | Easy | Hard |
|---|---|---|---|
| Transformer | 31.61 | 34.38 | 29.90 |
| Mamba | 30.62 | 32.81 | 29.26 |
| Hybrid | 35.79 | 38.02 | 34.41 |
| TransMamba | 38.76 | 40.10 | 37.94 |
长文本基准上 TransMamba 全面领先,这一定程度上印证了 Memory Converter 真的把前段信息无损传给了后段——不然在长序列上一定会掉点。
七、效率——节省 25% 训练时间
| Model | 相对训练时间 | 单层 FLOPs(×10^10) |
|---|---|---|
| Transformer | 1.00 | 10.51 |
| Mamba | 0.77 | 2.01 |
| Hybrid | 0.78 | 6.26 |
| TransMamba | 0.75 | 1.91 |
相对训练时间 0.75,节省 25%。FLOPs 上是 Transformer 的 0.18 倍、Mamba 的 0.95 倍——理论上 TransMamba 比纯 Mamba 还要省,因为它把前段短序列让给了 Attention,避免了 Mamba 在 T \lt N 段的浪费。
不过作者也很坦诚地指出:实际加速没有完全达到理论上限。原因是 Attention 和 Mamba 各自有大量工程优化(FlashAttention、Mamba 的 selective scan kernel),TransMamba 这种切换模式还没充分享受到这些优化的好处。这块是后续的工程空间。
论文附录里有一个我觉得挺重要的数字:作者实测下来 Transformer 的训练优化系数是 Mamba 的 2.67 倍——也就是说同样 FLOPs 下 Transformer 的实际训练速度反而更快 2.67 倍。这是因为 Attention 的 kernel 优化(FlashAttention 系列)成熟度远超 Mamba 的 selective scan。这个比例反过来又会影响 TransPoint 的最优位置——理论最优 P=N/2 是基于 FLOPs 算的,如果加上工程优化系数修正,最优 P 会进一步左移。论文里实际跑出来 P_optimal 在 2048 附近,明显比理论 N/2=768 大,这个偏移其实就是工程系数贡献的。这种"理论+工程"的最优点偏移分析,在我看来是这篇论文很扎实的一个证据——作者真的把每一步的偏差都解释清楚了,不是只贴个数据。
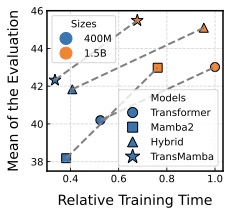
图4:横轴训练时间越往左越省,纵轴评估分越往上越好。两种模型尺寸下 TransMamba(五角星)都被推到了帕累托前沿的最优角落。
八、训练和推理可以用不同的 TransPoint
这是论文里我觉得最"有想象力"但也最玄学的一节。
由于 TransMamba 的结构灵活性来自参数共享,理论上你可以用一种 TransPoint 训完,再用另一种 TransPoint 推理。比如训练用 V9 那种细粒度调度,推理时强行设置 TransPoint=8192(也就是全 Attention 模式);或者反过来,推理时设置 TransPoint=0(全 Mamba 模式)。
作者说这种"不一致训练-推理"在某些任务上居然能拿到更好的结果,但又承认结果"非常扰动",规律不稳定。我的理解是,这块的潜力可能远大于它现在能稳定兑现的——因为这种 train-once、inference-many 的范式如果能稳定下来,相当于一个模型可以根据任务负载切换计算 profile,这是非常有想象空间的方向。
但说实话,目前作者也只是观察到现象,没给出可解释、可重现的方法。这块可能是后续工作的金矿。
九、几点保留意见
聊到现在,必须挑点刺。
第一,规模和数据。 实验最大只到 1.5B,训练 token 量 83B。在 LLM 这个尺度下,1.5B 还属于"玩具规模",83B 也算少。论文也承认了这个 limitation。混合架构在小规模有效不一定意味着 scale 起来还有效——历史上有大量小规模 work、放大就崩的例子。
第二,PhoneBook 的对比基准其实有点投巧。 因为 TransMamba 的 TransPoint 调度天然让前段全走 Attention,PhoneBook 这种关键信息在前段的任务有结构性优势。如果换一个关键信息在序列尾部的检索任务,TransMamba 的优势可能就反转了。这个评估维度没在论文里展开。
第三,对 V9 这个调度的解释偏经验。 三条规律(layer-specific、broad-range、fine-grained)是从消融里反推出来的,但没有给出更深的理论解释——为什么是 8 层一个循环、为什么是对数尺度、能不能根据数据特征自适应?换一种数据集这套调度还成不成立?这些都没回答。这种"我们调出来一个最好"的 schedule 在工程上能用,但理论锚点不够。
第四,Memory Converter 真的"无损"吗? 论文一直强调 lossless,意思是数学上 SSM 的等效隐状态可以从 KV 算出来。但这里有个隐含假设:训练时 SSM 路径的梯度流经过 Memory Converter 时是否保持稳定?如果 Memory Converter 在训练动态里实际上让前段 Attention 的梯度被后段 SSM 拉偏了,所谓的"无损"就只是 inference 时无损、training 时不一定。这块论文没有详细分析梯度行为。
十、对工程的启发
抛开论文本身,我觉得这套思路有几点值得借鉴。
参数共享是一个被低估的设计维度。 很多时候我们倾向于"加更多模块"来提升性能,但 TransMamba 这种"让一组参数同时服务两种机制"的做法反而推动了模型对参数的更高效利用——同样规模、同时拥有 Attention 和 SSM 的能力。这比单独加层更省。
序列级混合 vs 层级混合是一个真问题。 之前我也没意识到这个区分有多本质,看完 PhoneBook 的对比才反应过来——层级混合下,关键信息只要经过任一 Mamba 层就被压缩了;序列级混合可以保证某段 token 在所有层都用 Attention,从根本上保留了精确检索能力。如果你的应用场景里精确检索很重要,这个区分非常关键。
TransPoint 这种"机制切换点"的概念可能能推广。 不只是 Attention/SSM,未来 Linear Attention、Sliding Window Attention、Local Attention 等等不同复杂度的机制都可以用类似的方式按 token 位置切换。说到底就是在序列内部做计算 profile 的动态调度。
十一、收尾的判断
老实讲我对这篇 paper 的评价是正向但有保留。
正向的地方在于它的核心 insight 是真的扎实——不是工程拼接,是基于 Attention/SSM 数学对偶推到底之后的一个优雅设计。Memory Converter 不需要新参数这一点尤其漂亮。从架构创新的角度看,这是近两年 Hybrid 方向少有的"在数学层面真的做了点东西"的工作,不是又一篇按比例改一改 layer 配比的。
保留的地方在于规模偏小、调度策略偏经验、对训练动态的分析不够深入。这种工作要真正进入"下一代序列建模"的位置,还得在 7B/30B 规模上跑通,还得证明它在 SFT、RLHF 之后的稳定性。混合架构在小尺寸上 work、放大就崩的案例历史上太多了,TransMamba 现在还没回答这个问题。
另一个我会持续关注的方向是 train-inference 不一致那一节。如果作者后续能找到稳定的"训练用混合、推理用纯 Attention"或反之的范式,TransMamba 的价值会再上一个台阶——它就不只是一个混合架构,而是一个计算 profile 可调的统一架构。这跟 MoE 用稀疏激活控制计算量是不同的方向,但目标都是把"参数固定、计算可变"这件事做好。
但作为一个方向性的探索,TransMamba 给出的"用一组参数做混合架构"这个范式值得被记住。如果你在做长上下文模型,或者纠结 Hybrid 的层级比例,这篇论文应该认真读一遍——它至少告诉你,结构灵活性的天花板比你以为的要高。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我