别再只看准确率了:用认知负荷理论给工具智能体画一张"能力边界图"
写在前面
你有没有遇到过这种诡异情况:同一个 Agent,在 BFCL 榜单上跑 70 多分,挂到自己业务上一用就翻车——多调几次工具就漏参数,query 写得稍微歧义一点就直接调错 API。但你看官方排行榜,它明明在头部。
问题出在哪?我之前调 Agent 的时候有过一段挺挫败的时期,明明每个测试集都在涨点,真实任务就是不稳。后来我意识到一件事:几乎所有工具调用 benchmark,最后都把任务难度压成了一个标量——成功率。任务到底"难在哪",这一层信息全被丢掉了。
这篇被 AAAI 2026 收的论文《Beyond Accuracy: A Cognitive Load Framework for Mapping the Capability Boundaries of Tool-use Agents》就是想解决这个问题,作者来自中科院信工所和国科大网络空间安全学院。他们做了一件挺有意思的事:把心理学里的认知负荷理论搬过来,把任务难度拆成两块——结构性的"内在负荷"和呈现性的"外在负荷",分别量化、可参数化调节,最后画出每个模型的"能力衰减曲线"。
不是给模型打个分,而是给每个模型画一张"能力地图"。
核心摘要
- 痛点:现有 benchmark 把任务难度当成一个整体,只能告诉你模型"行不行",告诉不了你"在什么复杂度下崩盘、为什么崩盘"。
- 核心方案:引入认知负荷理论(CLT),把任务复杂度拆成两块——Intrinsic Load(内在负荷,用工具调用依赖图 TIG 量化)和 Extraneous Load(外在负荷,由 query 歧义性 + 干扰工具诱发)。然后假设单步成功率是 \(\exp(-(k\cdot CL+b))\),整条任务成功率就是各步乘积,从而得到任务总负荷与精度的指数衰减关系。
- 关键效果:构建 ToolLoad-Bench(500 个实例,10 个域,106 个工具),9 个主流模型上跑下来,实测精度和理论曲线高度吻合,Hosmer-Lemeshow 拟合优度检验所有模型 p 值都远高于 0.05。专门微调过的 xLAM2-32B 拿了 78.8 分,反超 GPT-4o 的 68 分。
- 真实定位:这不是一个堆数据冲榜的工作,而是一个评估方法论的工作。理论部分(指数 + 累加)确实有点像物理里的"自由能模型"那种简化假设,但对于工程团队来说,用 k 和 b 两个参数刻画一个模型的能力剖面这件事本身就很值钱——它直接对应到生产系统里的"任务路由"决策。
为什么需要这样一个框架
先说一个我自己感受比较深的事。BFCL、API-Bank、ToolBench 这些主流 benchmark 都很有用,但用多了你会觉得不够——它们告诉你模型 A 比模型 B 强 5 个点,但说不清楚:
- 是 A 在简单任务上更稳,还是在复杂任务上更稳?
- 同样是失败,A 是因为 query 没看懂,还是因为工具依赖搞错了?
- 给一个具体业务场景,我应该选 A 还是 B?
这些问题对工程落地特别关键。一个 Agent 系统在生产环境里,不同任务的复杂度差异很大——大量是简单任务,少量是复杂任务。如果有办法把"复杂度"量化出来,就能做精细化的任务路由:简单的喂便宜模型,复杂的喂强模型。这就能省一大笔钱。
但前提是,你得先有办法度量任务的复杂度。
作者从心理学借了一个现成的工具——认知负荷理论(Cognitive Load Theory,Sweller 1988)。这套理论原本是研究人类工作记忆的,核心观点是:人的工作记忆容量有限,当任务的认知需求超过容量,学习和问题解决就会失败。CLT 进一步把负荷拆成几类,其中两类最相关:
- Intrinsic Load:任务本身固有的复杂度,比如同时要处理的概念之间的交互。
- Extraneous Load:信息呈现方式带来的额外负担,比如说明书写得晦涩、上下文里有干扰信息。
作者的一个聪明操作是:把 LLM 的上下文窗口和推理能力类比为人的工作记忆。然后这套 CLT 就能搬过来用。
之前也有人把 CLT 用到 LLM 研究里,但要么是把它当成"算力成本"的隐喻(比如 Sparse Attention 减少 KV Cache 像减负),要么是研究 LLM 怎么帮人类降低认知负担(比如自动简化文本)。这篇论文是头一次把 CLT 当正经的、可量化的、用来诊断 AI 能力边界的形式化框架。
这是这篇论文最值钱的地方——把一个被泛泛比喻使用的概念,第一次做成了可以拿来跑数据、跑显著性检验的工具。
方法核心:把工具调用任务拆成一张图
整个方法的入口是一个新的形式化对象:Tool Interaction Graph(TIG,工具交互图)。
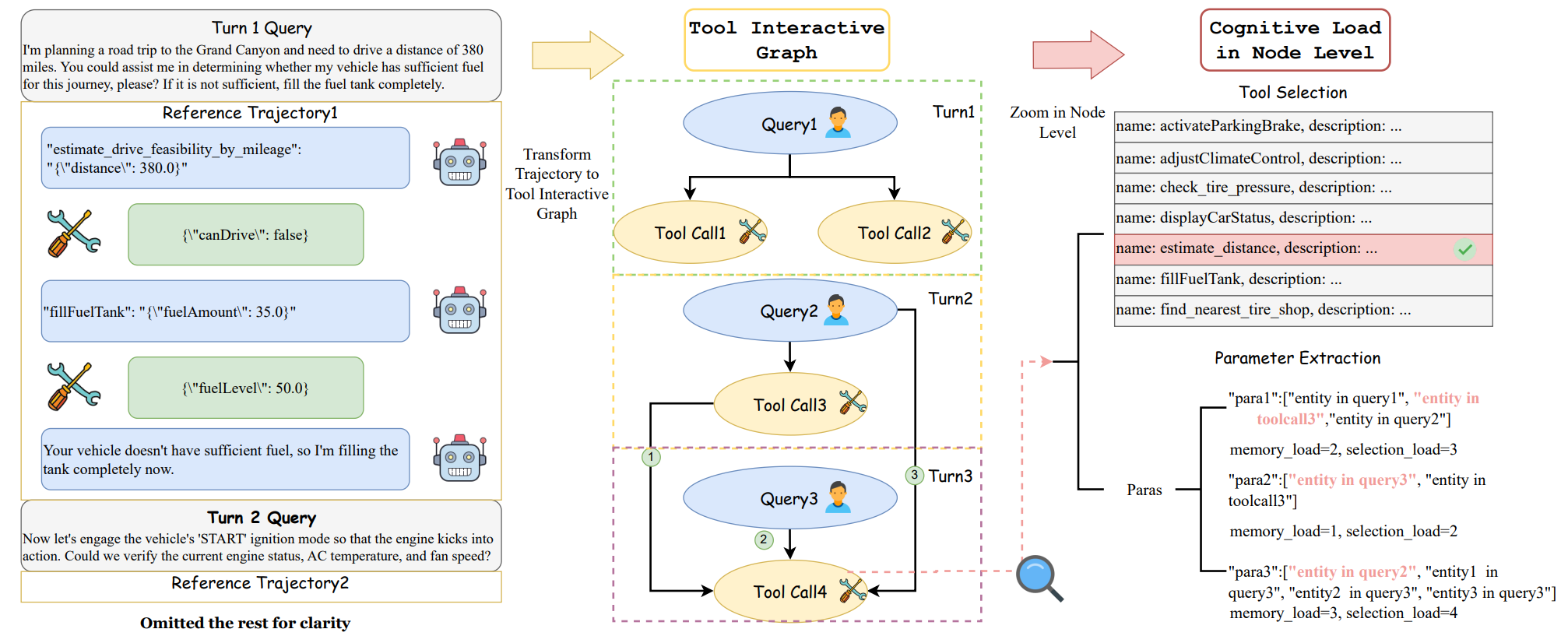
图1:左边是真实的多轮工具使用任务(Turn 1:开车去大峡谷判断油是否够,调 estimate_drive_feasibility 和 fillFuelTank;Turn 2:启动引擎、查胎压等)。中间把它转成 TIG,每个节点是一次 Tool Call 或 Query,边表示数据/执行依赖。右边放大到一个节点内部,认知负荷分两块:选对工具的负荷(Tool Selection)和填对参数的负荷(Parameter Extraction)
TIG 是什么
TIG 是一个有向无环图(DAG)\(G=(V, E)\)。
- 节点 \(V\):包括用户 query 节点 \(\{v_{q_1}, ..., v_{q_m}\}\) 和工具调用节点 \(\{v_{f_1}, ..., v_{f_n}\}\)。
- 边 \(E\):表示依赖关系,分两种——
- Data Dependency:节点 \(v_j\) 的调用需要 \(v_i\) 产出的数据。比如查询用户 ID 后才能用这个 ID 调下一个接口。
- Execution Dependency:纯逻辑顺序,不传数据但有先后约束。比如必须先 startEngine 才能 setTemperature。
TIG 是任务"标准答案"的形式化表达。给定一个多轮工具任务 \((Q, T)\),它的 TIG 就完整地描述了"理论上该怎么解"。
我个人觉得这个抽象做得挺干净的。之前看过一些工具任务的形式化,要么把整个 trajectory 拍平成线性序列(丢失并行结构),要么搞得太复杂(把每个参数也拆成节点)。TIG 这种"工具调用为节点、依赖为边"的粒度,刚好够用,又不冗余。
从 TIG 到认知负荷的两个公设
光有图还不够,要把它和"模型成功率"挂钩,作者提了两个公设:
公设 1:负荷-成功率关系。 单步认知操作的成功率是负荷的指数衰减函数:
其中 \(k > 0\) 是模型对负荷的敏感度,\(b \ge 0\) 是基线难度,两个都是模型特异的参数。
公设 2:TIG 上的概率独立性。 整个任务成功的概率是各个工具调用节点成功概率的乘积:
把公设 1 代入公设 2,因为指数函数的乘积等于指数的和,所以——
这就是论文的核心命题:任务的总认知负荷等于各节点认知负荷之和。
说实话我看到这两个公设的时候有点皱眉。公设 2(独立性)其实挺勉强的——工具调用之间显然不是独立的,前一步出错了后一步极可能跟着错。但作者要的不是"分子层面"的精确,而是一个能拿来做工程预测的近似。后面的实验用 H-L 检验证明这个近似确实够用。
这也是这类工作的常见套路:先用强假设把问题简化到可计算,再用实证检验来圆回来。能不能 work,看的是最终的拟合优度。
Intrinsic Load 怎么算
内在负荷来自 TIG 的结构。作者把它定义为所有依赖边的权重之和:
每条边的权重 \(w(e)\) 由两部分构成:
- Memory Load(注意力距离) \(\delta(v_i, v_j)\):从 \(v_i\) 产出信息到 \(v_j\) 使用信息,中间隔了多少轮对话或工具调用。隔得越远越难记。
- Selection Load(干扰) \(I(v_i, v_j)\):上下文里有多少同类型但错误的实体在干扰。比如要选对一个 user_id,但上下文里飘着 5 个其他 user_id,干扰就大。
\(\lambda\) 是平衡超参。这个建模其实有点类似工作记忆研究里的"信息检索成本"——距离 + 干扰,是经典的两个维度。
Extraneous Load 怎么算
外在负荷来自任务呈现方式,独立于 TIG 结构。作者定义为:
每个 query 的外在负荷由两个 [0,1] 区间的归一化分数加和:
- Query 的歧义性——这句话有多少种合理解读。
- 干扰工具的可能性——可用工具集 \(T\) 里有多少看起来"也合理"但其实错的工具。
这两个分数怎么打?作者用 Gemini-2.5-pro 当裁判。
我对这块持保留态度。LLM 当裁判这件事在 2024-2025 年成了普遍做法,但它本身也是个黑盒——Gemini 觉得"歧义"的 query,跟 Qwen 觉得"歧义"的 query 是一回事吗?作者自己在 Limitation 里也承认了这一点:"developing more objective, feature-based metrics would strengthen the framework"。这是这个框架最薄弱的一环,未来肯定还要打补丁。
总负荷与精度预测
把内在和外在合一起:
注意这里有个权重 \(\omega_E\),它不是拍脑袋拍的,而是从实测数据里反推出来的——观察 \(CL_I\) 和 \(CL_E\) 各自变化一个单位时对精度的影响比,从而把两类负荷"换算到同一个尺度"。
最终,任务精度的预测公式:
每个模型只需要拟合两个参数 \(k\) 和 \(b\),就能用一条曲线刻画它在任意复杂度任务上的预期精度。
ToolLoad-Bench:一个"难度可调"的基准
光有理论没用,得有数据集来跑。作者基于 BFCL v3 的 multi-turn base 拆分(200 个实例)做了扩展:
| 基准 | 实例数 | 域数 | 工具数 | 平均调用数 |
|---|---|---|---|---|
| BFCL(原始) | 200 | 8 | 84 | 4.1 |
| ToolLoad-Bench | 500 | 10 | 106 | 4.9 |
扩展的两个关键策略:
- Graph Generation:合成全新的复杂任务图(不是简单改写)。
- Edge Insertion:在现有图里系统地添加新的依赖边,提高结构复杂度。
外加两个新增工具领域,专门补强"高复杂依赖场景"。
数据集的关键特点是参数化可调——每个实例都标了 \(CL_I\) 和 \(CL_E\) 的数值,研究者可以按负荷区间筛样本,做受控实验。这和那种"把 1000 个例子混在一起算个总分"的传统 benchmark 不是一回事。
我觉得这是这篇论文实操价值最高的部分。理论可以争议,但这套基准做完之后,后面的工作可以直接拿来用——比如想验证某个新方法是不是真的提升了"对复杂度的鲁棒性",而不只是在简单任务上多刷了几分,ToolLoad-Bench 是现成的工具。
实验:性能悬崖真实存在
主表:xLAM2-32B 反超所有大模型
ToolLoad-Bench 上 9 个模型的总体精度:
| 模型类别 | 模型 | 总精度(%) |
|---|---|---|
| 闭源 | GPT-4o | 68.0 |
| 闭源 | Claude 3.7 Sonnet | 64.8 |
| 闭源 | GPT-4o-mini | 62.2 |
| 闭源 | Gemini 2.5 Pro | 60.0 |
| 开源 | Qwen3-235B | 58.0 |
| 开源 | Qwen3-32B | 55.2 |
| 开源 | Qwen3-8B | 38.6 |
| 开源 | Llama3.3-70B | 17.0 |
| 微调 | xLAM2-32B | 78.8 |
第一眼最让我意外的是两件事:
第一,Llama3.3-70B 才 17 分。 这个数有点离谱。Llama3.3-70B 在通用基准上明明很能打,怎么到了 multi-turn 工具调用场景就崩成这样?我猜跟它的工具调用模板/格式适配有关——这个家族在 function calling 上一直不太"原生"。但 17 分这个数字还是让我对这个模型在 Agent 场景下的实用性彻底打了问号。
第二,xLAM2-32B 78.8 分,反超 GPT-4o 整整 10 个点。 这个数据其实很重要,它说明针对工具调用的专门微调,比堆通用模型规模更有效。32B 的专精模型打过 GPT-4o,这放在 2024 年是很难想象的,但放在 2025 年的 Agent 工具调用领域,已经成了一种新的常态——APIGen-MT 那条线的工作(xLAM 系列正是 Salesforce 那批人做的)证明了一件事:工具使用是个可以靠数据合成 + 监督微调来高效压榨的能力维度。
内在负荷下的"性能悬崖"
把数据集按 \(CL_I\) 分成 easy/middle/difficult 三档,每档约 167 个实例。
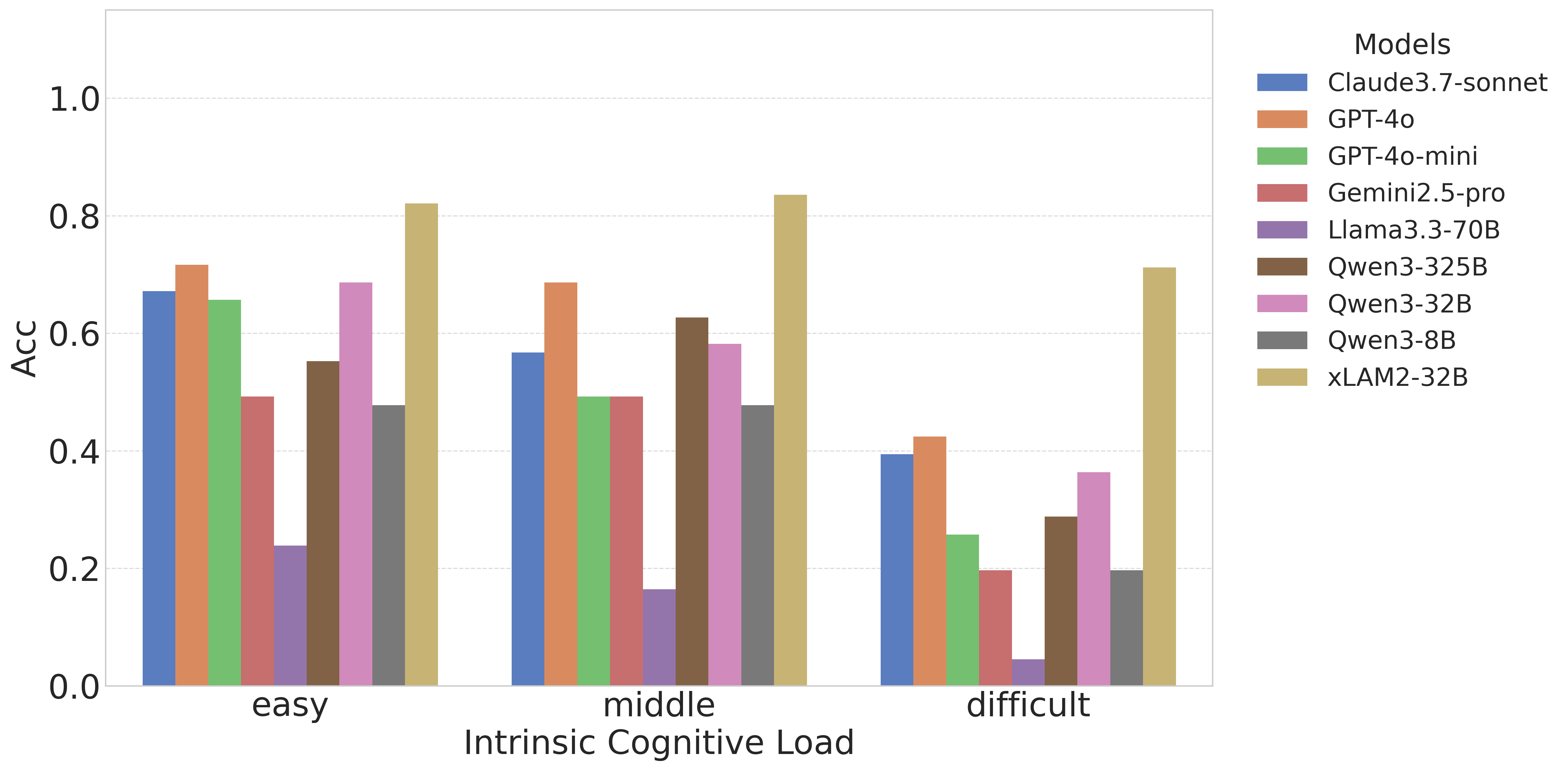
图2:横轴是内在负荷(easy → middle → difficult),纵轴是精度。所有模型都呈下降趋势,但下降幅度差异巨大
几个观察:
- 在 easy 档,大部分模型都能跑到 0.5-0.8 之间,看起来差距不大,平台期。
- 到了 difficult 档,断崖式下跌——GPT-4o-mini、Claude 3.7、Qwen3 系列都跌到 0.2-0.4。
- xLAM2-32B 在 difficult 档还能维持 0.71,是唯一守住 60% 以上精度的模型。
- Llama3.3-70B 在 easy 档就只有 0.24,到 difficult 档几乎归零。
"性能悬崖"是个很形象的描述。模型不是线性变差的,是在某个负荷阈值之后突然崩盘。这个阈值就是模型的能力边界。
外在负荷下的相似规律
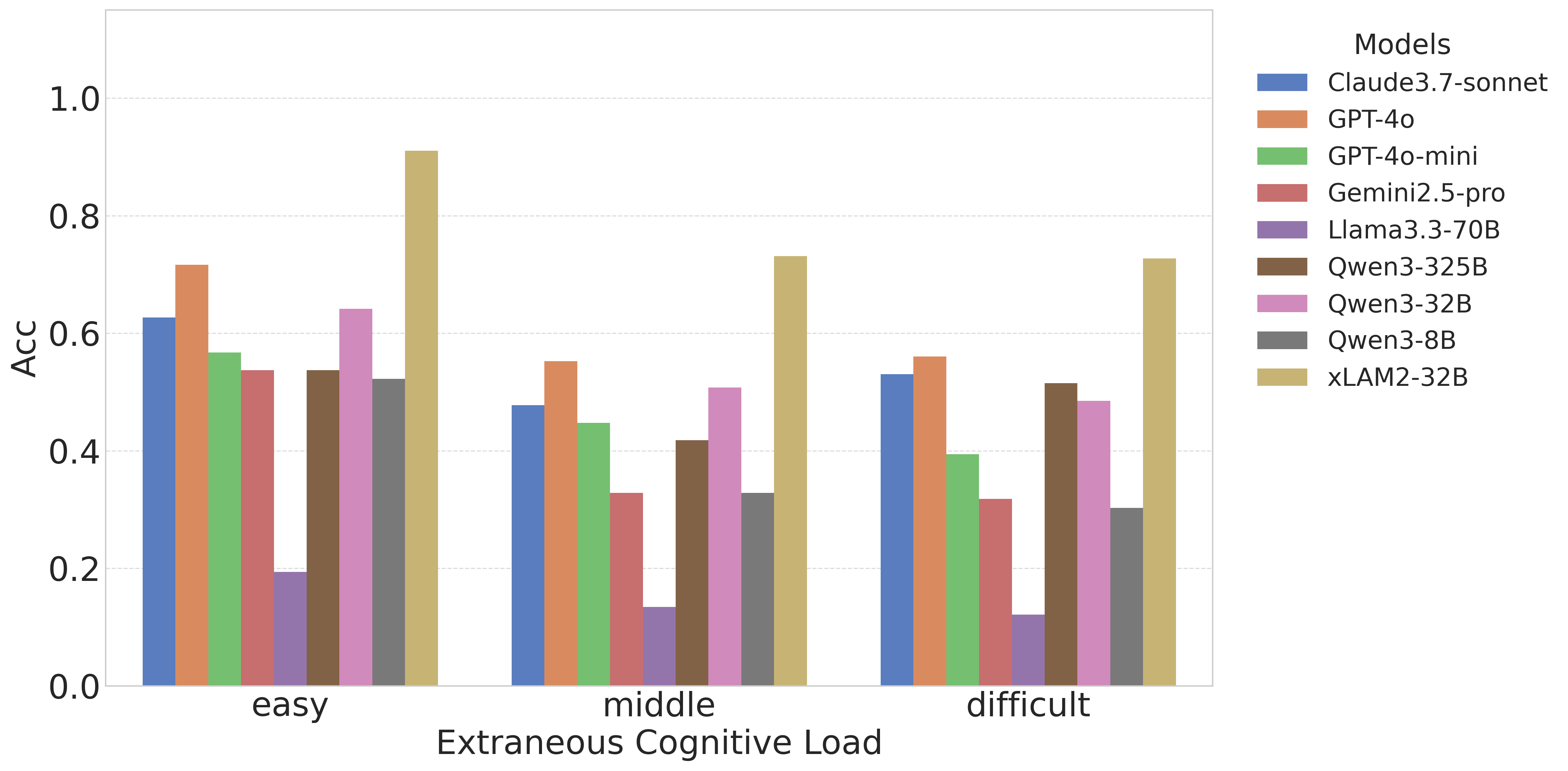
图3:把 CL_I 换成 CL_E(query 歧义 + 干扰工具),下降趋势几乎复刻图 2
值得注意的是,外在负荷的影响和内在负荷几乎一样大。这意味着:把 query 写歧义,跟把工具依赖搞复杂,对模型的杀伤力是同量级的。
工程上这个结论挺有用的。如果你的业务里 user query 写得比较随便(用户都这样),即使工具链再简单,你也得选 \(CL_E\) 鲁棒性强的模型。反过来如果你能在前端做 query 改写/澄清,就能给后端模型省很多复杂度预算。
拟合曲线:理论模型站得住
这是论文最关键的一张图——验证那个 \(\exp(-(k \cdot CL + b))\) 的指数衰减假设到底成不成立。
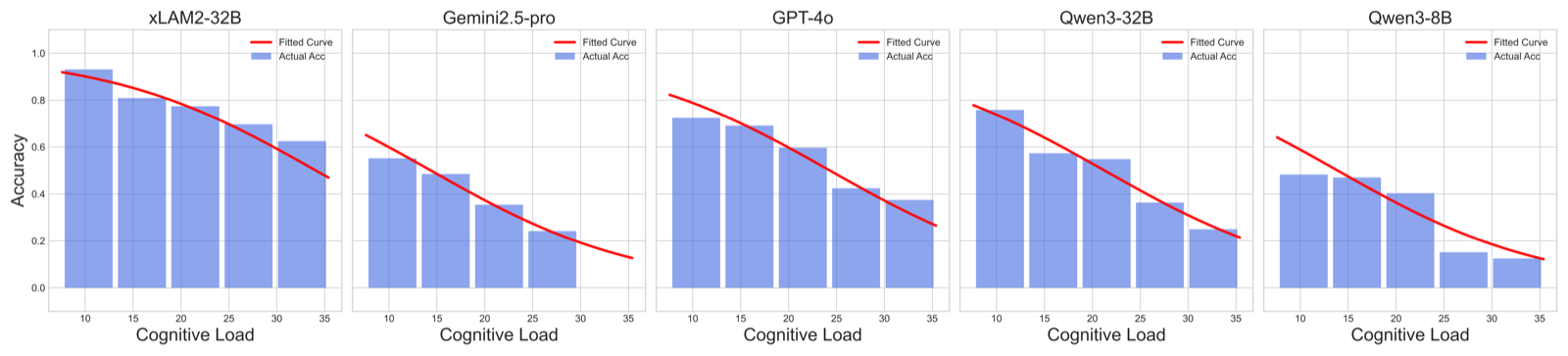
图4:5 个代表模型的拟合结果。横轴是总认知负荷(10-35 区间),纵轴是精度。每个模型的红线和蓝色柱状图基本对齐
5 个模型的拟合效果都不错。说实话我看到这张图的时候是有点惊讶的——那么强的简化假设(独立性 + 指数)竟然真的拟合得这么干净。这背后可能有两个原因:
- CLT 在心理学里本身就是个 well-tested 的框架,"工作记忆容量有限 → 任务失败概率随负荷指数增长"在人类身上验证过很多次。LLM 的注意力机制其实有相似的"容量瓶颈",这种类比可能比想象的更深。
- 分桶之后每个 bin 里有几十个样本,平均化掉了独立性假设违反带来的偏差。
不管怎样,能拟合就是硬证据。
用箱线图刻画"能力地图"
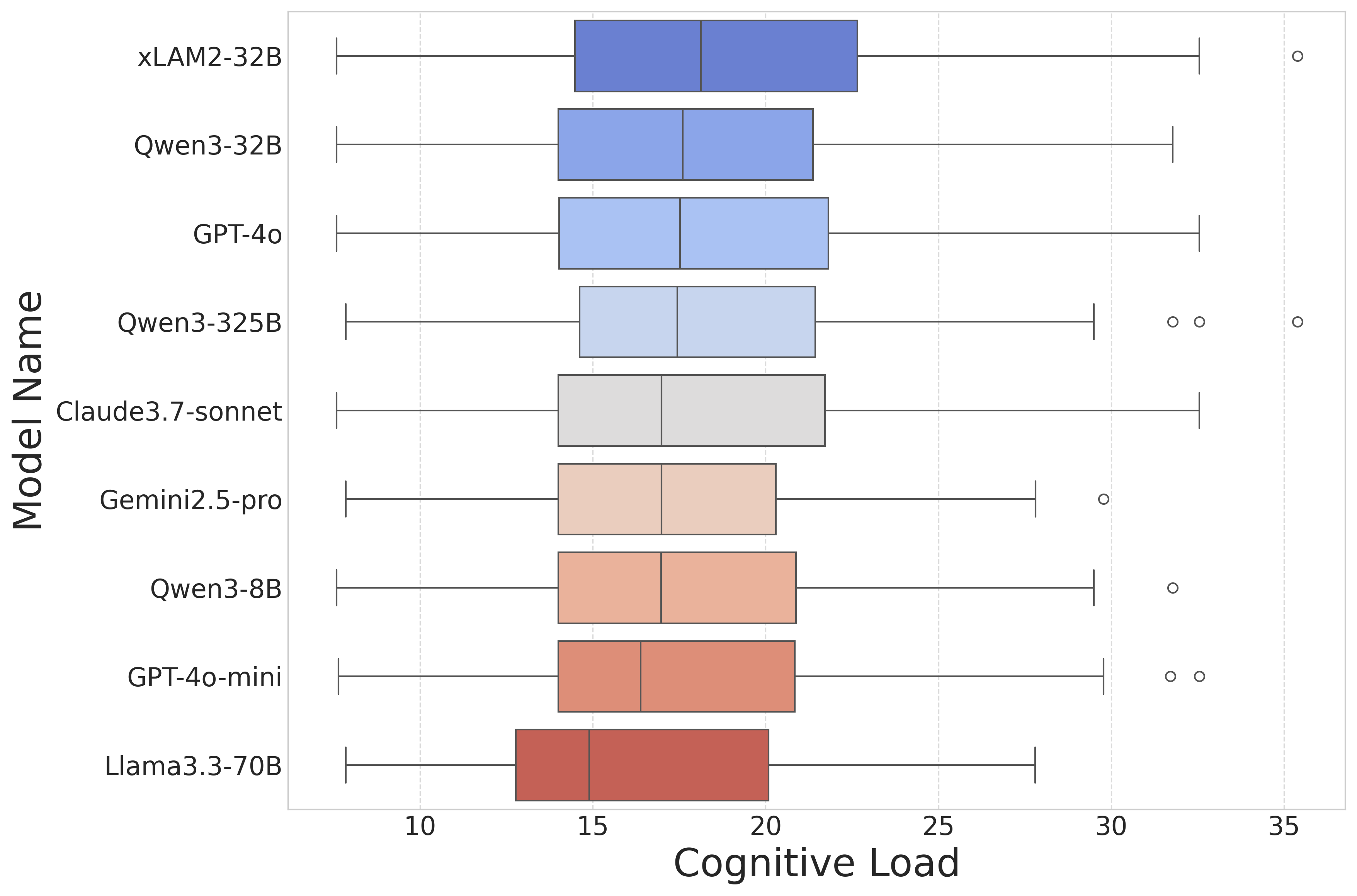
图5:箱线图——只统计"成功完成"的任务,看它们的认知负荷分布。中位数和上四分位数越高,说明模型能 hold 住的负荷越高
这张图我特别喜欢。它把"模型能力"从一个标量变成了一个区间。
- xLAM2-32B:中位数最高(约 18),上四分位数接近 22,最高异常值能跑到 35。
- Qwen3-32B、GPT-4o:中位数 17 左右,比 xLAM 略低但分布也很宽。
- Llama3.3-70B:中位数最低,约 15,上四分位数也在 20 以下,整个分布严重左偏——只能在低负荷区间生存。
如果你做生产系统的任务路由,这张图直接告诉你:给 Llama3.3-70B 派 CL>20 的任务基本是浪费算力。
k 和 b:两个数搞定模型剖面
把每个模型的拟合曲线参数化,得到 \(k\)(负荷敏感度,越小越鲁棒)和 \(b\)(基线难度,越小起点精度越高):
| 模型 | Load Sensitivity(k) | Baseline Load(b) |
|---|---|---|
| xLAM2-32B | 0.034 | 1.22 |
| GPT-4o | 0.067 | 1.71 |
| Claude 3.7 | 0.073 | 1.57 |
| Gemini 2.5 Pro | 0.088 | 1.22 |
| Qwen3-32B | 0.075 | 1.60 |
| Qwen3-8B | 0.085 | 1.12 |
这张表比总精度榜单信息量大得多。
注意一个有意思的发现:Qwen3-8B 的 b 值最低(1.12),意味着在零负荷的最简单任务上,它的起步精度最高。但它的 \(k\) 值偏大(0.085),说明随负荷增加衰减得很快。所以在简单任务上 Qwen3-8B 性价比可能极高,但复杂任务别指望它。
xLAM2-32B 的 \(k\) 值(0.034)几乎只有其他模型的一半——这是它在 difficult 档维持高精度的根本原因。它的 \(b\) 也很低(1.22),所以两头都强。这种"双优"的剖面才是真正的能力代差。
校准检验:Hosmer-Lemeshow + 校准图
最后一步,作者要证明这套预测不是"看图说话",而是统计上站得住的。
用 Hosmer-Lemeshow 拟合优度检验,零假设是"模型校准良好",所以希望 p 值高(>0.05):
| 模型 | H-L \(\chi^2\) | p-value |
|---|---|---|
| GPT-4o | 4.87 | 0.77 |
| Claude 3.7 Sonnet | 10.47 | 0.23 |
| Gemini 2.5 Pro | 13.15 | 0.11 |
| GPT-4o-mini | 8.91 | 0.35 |
| Qwen3-235B | 5.19 | 0.74 |
| Llama3.3-70B | 13.21 | 0.10 |
| Qwen3-32B | 7.50 | 0.48 |
| Qwen3-8B | 7.90 | 0.44 |
| xLAM2-32B | 3.59 | 0.89 |
所有 p 值都远高于 0.05,统计上无法拒绝"校准良好"。xLAM2-32B 的 p=0.89,校准度最高——这意味着它的精度衰减最"光滑",最符合理论模型的预测。
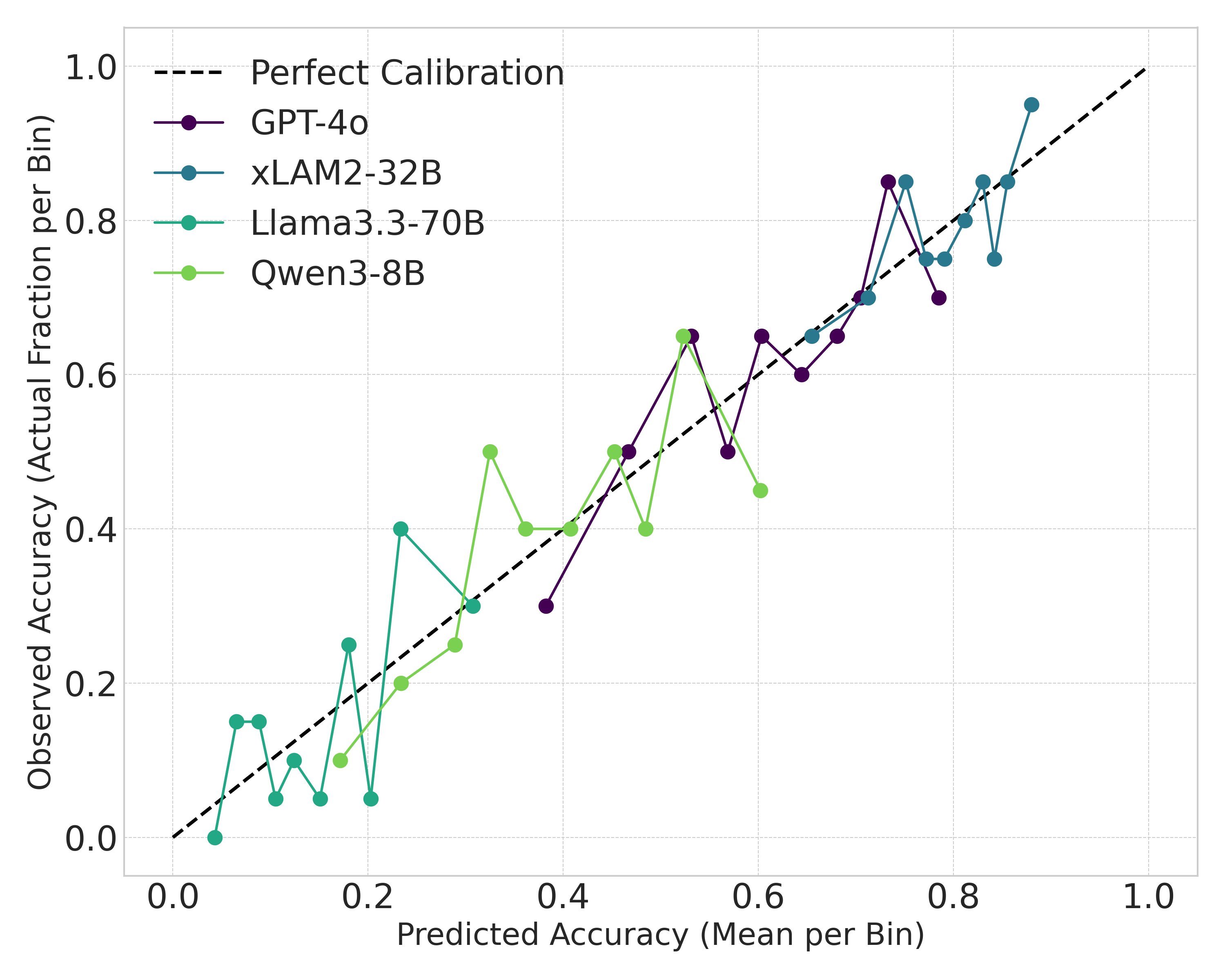
图6:横轴是按预测精度分桶的均值,纵轴是该桶里实测的成功比例。虚线是完美校准(y=x)。GPT-4o、xLAM2-32B、Llama3.3-70B、Qwen3-8B 四条曲线都基本贴着对角线
校准图直观看也确实没问题。
我的判断:好在哪、什么地方还要打补丁
我觉得这篇论文最值钱的三件事
第一,TIG 这个抽象。把工具任务变成 DAG,把"复杂度"变成"图上的边权和",这是个干净、通用、可计算的抽象。后面要做工具规划、工具组合检索、工具能力建模,TIG 都是个好的脚手架。我觉得这个抽象本身的价值可能比认知负荷这个外壳更长久。
第二,把"能力"变成 (k, b) 二维剖面。一个模型有多强,本来是个模糊的事情。现在用两个数刻画——一个管基线起点,一个管复杂度衰减率,对工程团队特别友好。生产系统做任务路由,要的就是这种剖面,而不是一个总分。
第三,可参数化的 ToolLoad-Bench。500 个实例,每个都标了 \(CL_I\) 和 \(CL_E\),可以做受控实验。这件事的工程价值很大——以后做新方法的对比实验,不用再争"是不是测试集太简单了",可以直接按负荷区间划档对比。
我皱眉的几个地方
第一,公设 2 的独立性假设有点理论上的硬伤。工具调用之间显然不独立——前一步输出错了,后一步在错误数据上跑,几乎必错。但作者用分桶 + 大样本平滑掉了这个问题。从工程结果看是 work 的,但从理论严谨性看不算完美。如果要做更深的工作,可能需要把"链式失败"显式建模到图上。
第二,外在负荷依赖 LLM 当裁判。Gemini-2.5-pro 给 query 打歧义分,给工具集打干扰分,这个"裁判一致性"是没经过验证的。换个 LLM 当裁判,分数会变成什么样?这块作者自己也承认是局限性。
第三,benchmark 仍然以 BFCL 为基础。BFCL 本身的工具任务偏静态、偏函数式,跟真实生产场景里那种"长程多轮 + 状态机"的 Agent 任务还是有距离。10 个域、106 个工具是个不错的覆盖,但离 ToolBench 那种 16000+ API 的规模还差得远。
第四,评估对象局限于工具调用准确性。但生产系统里 Agent 还有别的失败模式——幻觉调用不存在的工具、调用顺序对了但参数语义不对、token/延迟超预算。这些没纳入框架。
xLAM2-32B 的反超说明了什么
我觉得这是这篇论文除了方法论外最有信息量的实证发现。
专精微调 + 32B 反超 GPT-4o 这种通用大模型,这件事在 2025 年的 Agent 工具调用领域已经不是孤例了。它背后是一个更深的趋势:
工具调用能力是一个任务边界相对清晰、数据可以大量合成、奖励信号容易构造的能力维度。这种能力维度,监督微调 + 强化学习能把模型压榨到很高的水平,规模带来的边际收益反而不那么大。
如果这个判断成立,对工程选型有几个直接的启发:
- 生产系统优先考虑专精微调模型,不要默认上最大的通用模型。
- 如果业务能容忍数据闭环,自己用线上数据做一轮 SFT,效果可能比换更贵的 API 更划算。
- 任务路由变得很重要——简单任务给 8B 级别专精模型,复杂任务给 32B 级别专精模型,超复杂兜底给 GPT-4o/Claude,整体性价比能比"全用 GPT-4o"高一个数量级。
而要做这种任务路由,先得有一套像 ToolLoad-Bench 这样的、按复杂度分层的评估基准,外加每个模型的 \((k, b)\) 剖面参数。这就是作者提的"应用价值:智能任务路由"。
一些工程落地的思考
如果我现在要在生产系统里用这套思路,会怎么做?
第一步:把自己业务里的工具调用任务录下来,按 TIG 的方式建图。这一步需要标注,但只需要标依赖关系,比标完整 trajectory 简单。
第二步:算每个任务的 \(CL_I\)(结构负荷)。\(\delta\)(注意力距离)和 \(I\)(干扰)都可以从 trajectory 里直接抽出来,不需要 LLM 介入。
第三步:用一组离线评测样本,跑 2-3 个候选模型,拟合每个模型的 \((k, b)\)。可能不需要那么多样本——按论文的实验,50-100 个分桶样本就能拟出比较稳定的曲线。
第四步:上线时,每个新任务实时算 \(CL_I\)(外在负荷可以暂时用启发式特征近似,先不依赖 LLM 裁判),根据负荷区间选模型。
整个流程不需要复刻论文的全部,但核心思想——用 TIG 量化结构负荷,用指数模型预测精度——是直接可迁移的。
收尾
这篇论文最让我有共鸣的一点是它的姿态——不是在卷 SOTA,而是在卷方法论。
工具调用领域过去两年涨点的速度很快,但很多涨点其实是"在简单任务上多刷了几分",能力边界其实没怎么往外推。这种时候,跳出来反思"我们到底在测什么、怎么知道一个模型变强了",比再卷 5 个百分点更有意义。
认知负荷理论从心理学借来当评估框架,本身有点像一种"理论降维打击"——把"模型能力"这个一直被当成黑盒的东西,强行拆成可量化、可拟合、可预测的形式。能不能完美?不能,论文里那些假设和 LLM 裁判的依赖都是软肋。但能不能用?能,H-L 检验的 p 值放在那里,工程上完全够用。
我对这类工作的偏好是明显的——宁可看一篇只涨 0 个点但提出新工具/新方法论的论文,也不想再看一篇靠数据合成涨 3 个点的论文。前者打开了一扇门,后者只是在房间里多走了几步。
这篇是前者。
参考文献
- 论文 PDF:https://arxiv.org/pdf/2601.20412
- 论文 HTML:https://arxiv.org/html/2601.20412v1
- 论文 arXiv 页面:https://arxiv.org/abs/2601.20412
- 相关基准 BFCL:https://gorilla.cs.berkeley.edu/leaderboard.html
- 相关工作 xLAM/APIGen-MT:Prabhakar et al., 2025
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我