ToolACE-R:让模型自己决定训练吃什么、推理时改几遍
一句话核心
工具调用模型不该用同一份数据反复硬灌,也不该在每个 query 上都死磕 N 轮自我修正。ToolACE-R 把这两件事都改成了"模型自己说了算"——训练数据要和当前模型的能力相匹配,推理时模型自己判断这一题改到位了没有,到位了就停。最终在 BFCL 上 LLaMA3.1-8B-Instruct 从 76.83 拉到 86.83,已经压过 GPT-4o 和 DeepSeek-V3。
开篇:为什么"工具学习"这件事一直没那么顺
先从一个真实的工程困境说起。
你训过工具调用模型应该知道这种感觉:明明合成了一大批高质量数据,模型在简单 case 上分数蹭蹭往上涨,但一到 Live 类(真实用户 query)就趴窝。再仔细看,更让人头疼的是:你新加进来的"困难样本"——那些 GPT-4o 才能勉强答对的——非但没让小模型变强,反而把它本来稳的 case 也搞乱了。
这其实不是数据质量的问题,是数据和模型能力错配的问题。
之前业界主流的工具学习路径,比如 ToolACE、APIGen、Gorilla,几乎都把火力对准了"怎么造更多更好的数据"。这思路当然对,但有个被普遍忽视的副作用:先进模型造出来的样本,对一个待训练的小模型来说,常常超出了它的认知边界。文献里管这个叫 unfamiliar finetuning——用学不会的东西硬训,反而催生幻觉、破坏原有能力。
另一个被冷落的方向是 test-time scaling。推理时多做几次、自己改一改,这套在数学推理上已经很有效了(OpenAI o1、DeepSeek-R1 都是吃这一波红利)。但工具调用场景里,这思路用得不多,而且一旦用上又有个新问题:query 难度差异极大,简单 case 一次就对、再改就错,复杂 case 可能改 3 次还不够。统一改 N 次是浪费,关键是模型怎么知道自己什么时候该停。
ToolACE-R 这篇被 AAAI 2026 收录的工作,对这两个问题给了一套彼此咬合的答案。读下来你会发现,它的精彩不在某个孤立的 trick,而在"训练-推理"两端的设计在同一根逻辑链上。
论文信息
- 标题:ToolACE-R: Model-aware Iterative Training and Adaptive Refinement for Tool Learning
- 作者:Xingshan Zeng、Weiwen Liu、Xu Huang、Zezhong Wang、Lingzhi Wang、Liangyou Li、Yasheng Wang、Lifeng Shang、Xin Jiang、Ruiming Tang、Qun Liu(共 11 位作者,主要来自华为诺亚方舟实验室)
- arXiv:2504.01400v3(2026 年 1 月更新)
- 收录:AAAI 2026
- 链接:https://arxiv.org/abs/2504.01400
核心贡献先讲清楚
ToolACE-R 的贡献其实就两条主线,但每一条都是"训练-推理"两端联动的:
第一条线,模型感知的迭代训练。 不是预先选好一份数据集训到底,而是定义了一个叫 model-aware difficulty 的指标,让训练样本的去留取决于当前这个模型自己的表现——既不能太简单(学不到东西),也不能太难(学不动)。每训一轮,模型变了,数据集就重新筛一次。
第二条线,自适应自精修推理。 训练时刻意加入"答案已经对了,再问一遍仍然给出同样答案"的样本,让模型学会"识别自己已经答对了"。推理时模型反复自我精修,直到连续两轮答案完全一致,自动停。
这两条线在论文图 1 里一眼能看明白:
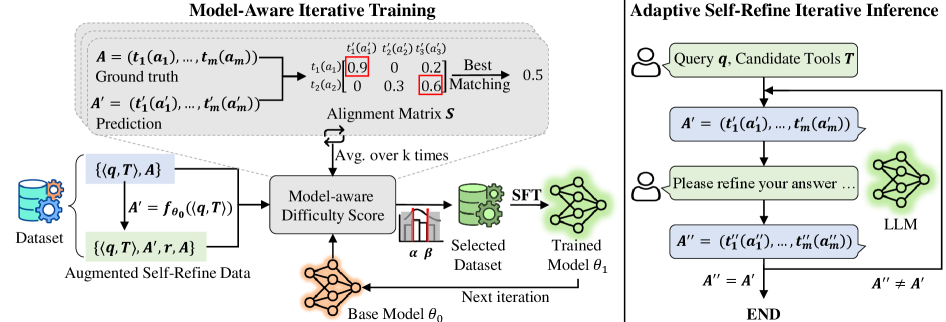
图 1:左半部分展示了 model-aware difficulty 的计算方式(基于 ground truth 和模型预测的对齐矩阵),以及如何用难度阈值 \(\alpha, \beta\) 筛出"恰好合适"的训练样本进行 SFT;右半部分展示了推理时反复自精修,直到 \(A'' = A'\) 才终止
下面把每一块拆开讲。
第一块:什么是"模型感知难度",为什么重要
直觉先行
你想想看,给一个完全不会做高考压轴题的初中生塞一摞清北自招题,他能学会的概率有多大?大概率是抄答案、记套路、考试一变形就崩。但如果给他刚好高出一档的题,正好踩在他够得着但要使劲的位置,效果就完全不一样。
这是教育学里的"最近发展区",被这篇论文搬到工具学习里,叫 model-aware difficulty。
怎么量化
定义其实挺漂亮,分三步。
第一步,单次预测的对齐分数。 给定 ground truth 工具调用序列 \(A = [t_1(a_1), \dots, t_m(a_m)]\) 和模型预测 \(A' = [t'_1(a'_1), \dots, t'_{m'}(a'_{m'})]\),对每对 tool call 算一个 Jaccard 风格的参数级对齐分数:
工具名不一样直接给 0;工具名一样,再看参数名和值的交并比。注意这里有个细节——参数名相同但值不同的会被分开计入分母,不会"猜对一半就给一半分"。
第二步,序列级最优匹配。 把所有 \(S_{ij}\) 拼成矩阵 \(S \in \mathbb{R}^{m \times m'}\),用匈牙利算法找最优二分匹配,得到序列级对齐分:
分母用 \(\max(m, m')\) 是为了惩罚"漏调用工具"或"多调用工具"的情况——这个细节看起来朴素,但工程上很关键,否则一个只调一个工具的预测可能会被误判为"完美"。
第三步,多次采样取均值降方差。 让模型跑 \(k\) 次(论文里 \(k=8\),温度 1.0),定义难度为:
\(D \in [0, 1]\),0 是模型每次都能完美答对(太简单),1 是每次都答得一塌糊涂(太难)。
训练样本怎么筛
设两个阈值 \(\alpha=0\) 和 \(\beta=0.9\),只保留 \(\alpha < D < \beta\) 的样本。
翻译一下:模型已经能稳稳答对的丢掉(学不到东西),模型基本一次都答不对的也丢掉(强行学反而带歪)。剩下的中间区间,是模型"踮一踮脚就够得着"的部分,这才是真正能让它进步的训练材料。
这思路是不是似曾相识?是的,DeepSeek 的 GRPO、QwQ 这些 reasoning model 训练里都用过类似的"难度筛选"思路。但 ToolACE-R 做得更彻底的一点是:它是迭代的。每训一轮,模型变强,原本难的样本变简单了,就被踢出去;原本太难的样本现在变成"踮脚够得着"的,就被纳入。这就是图 1 左侧那个"Next iteration"循环箭头的意思。
第二块:自精修语料怎么造,怎么让模型学会"自己停"
一个细节决定成败
这块设计有个非常容易被忽略但至关重要的点。我看论文的时候差点漏掉,回头看 ablation 表格才意识到它的分量。
构造方式很直白:每一条原始样本 \(\{\langle q, T\rangle, A\}\),都被扩展成一个两轮对话——
User: <q, T>
Model: A_1 ← 待训模型基于当前能力先输出一版
User: r ← 一句通用 refine prompt,比如 "Please refine your answer..."
Model: A ← 给出 ground truth
这里的"模型"就是要被训练的那个模型自己跑出的初版预测 \(A_1\)。
但是!会有一部分样本, \(A_1 = A\)——也就是说,模型第一次就已经答对了,这种"自精修"其实没改什么。
普通做法会把这种样本扔掉,觉得没价值。但 ToolACE-R 偏偏把这部分留下来。
为什么?因为这才是教模型"识别自己已经答对了"的关键信号。模型在 SFT 阶段学到的是:当输入是"query + 上一轮答案 + refine prompt"且上一轮答案确实正确时,正确的输出就是再来一遍同样的答案。
这个能力到推理阶段就变成了"adaptive stopping"——模型之所以能在推理时知道"我这一轮和上一轮答案一样了,可以停了",根子就在这。
工程上的小心思
构造的 refine 样本里,第一轮 assistant 输出 \(A_1\) 是被 loss mask 掉的,因为它本身可能就是错的,硬学这部分会污染模型。loss 只在最终的 \(A\) 上算。
这个细节论文里就是一句话带过,但实际上线时是个坑——很多 RLHF 团队栽过类似的跟头:训练数据里夹杂了"模型自己产出的错误版本"而没 mask,模型学着学着就把错误模式也学进去了。
第三块:推理时怎么"自适应停"
训练里埋下的"答对了就别动"的能力,到推理时就长这样:
1. 给定 query q 和工具集 T,模型生成 A'
2. 拼上 refine prompt,让模型再生成 A''
3. 如果 A'' == A',停,输出 A''
4. 否则 A' ← A'',回到步骤 2
5. 最多迭代 n 次(论文中 n=5)兜底
简单到不像是"创新",但它能 work 的前提是训练阶段那个被很多人会扔掉的 \(A_1 = A\) 样本被保留了。
来看实际效果——这是论文里最有说服力的一张图:

图 2:横轴是迭代轮数,纵轴是 BFCL 整体准确率。蓝色 Vanilla Self-Refine 始终在 86.10 到 86.65 之间剧烈来回,根本不收敛;绿色 Adaptive Self-Refine 在第 4 轮稳定后保持在 86.80 上下;红色虚线是 Self-Consistency at Itr 10 的天花板,三者在第 10 轮汇合
这张图能讲明白几件事。
第一,无脑改是不行的。 Vanilla Self-Refine 每一轮强制取最新答案,结果模型有时把对的改错、有时把错的改对,整体就是布朗运动。这印证了一个直觉——模型并不是每次精修都能改得更好,它需要一个机制来判断什么时候该停手。
第二,Adaptive 的稳定性来自训练阶段的设计。 模型已经学会了"答对了就重复输出同一个答案",所以连续两轮答案一致这个信号非常可靠。论文统计 BFCL 上平均迭代轮数只有 2.4 轮(最大允许 5 轮),意味着大多数 query 在 2 到 3 轮就终止了,没有把算力浪费在已经答对的题上。
第三,自适应 vs Self-Consistency。 红色虚线那个 Self-Consistency at Itr 10——意思是跑 10 轮然后取多数答案——是公认的强 baseline,但代价是 10 倍推理开销。Adaptive Self-Refine 在大约 1/4 的开销下就追平了,这才是论文真正的工程价值。
实验结果:BFCL 上压过 GPT-4o 是怎么做到的
主表搬过来,重点看最后一行 ToolACE-R:
| 模型 | Non-live | Live | Overall |
|---|---|---|---|
| GPT-4o-2024-11-20 | 87.67 | 80.24 | 83.96 |
| GPT-4.1-2025-04-14 | 88.75 | 78.46 | 83.60 |
| Gemini-2.5-Pro-Exp | 78.75 | 68.17 | 73.46 |
| DeepSeek-V3 | 89.17 | 82.09 | 85.63 |
| Llama3.1-70B-Inst | 89.98 | 76.53 | 83.26 |
| Llama3.1-8B-Inst(base) | 84.37 | 69.28 | 76.83 |
| ToolACE-8B(FC) | 87.54 | 76.02 | 81.78 |
| Hammer2.1-7B(FC) | 88.65 | 77.20 | 82.92 |
| xLAM-2-8b-fc-r(FC) | 84.40 | 67.51 | 75.95 |
| ToolACE-R(FC) | 90.94 | 81.72 | 86.33 |
几个判断:
8B 模型干翻 70B 这件事不再稀奇,但能把 GPT-4o 和 GPT-4.1 都按下去就比较有看头。 在 Non-live(合成测试)上,ToolACE-R 的 90.94 比 Llama3.1-70B 的 89.98 还高一截,比 8B base 涨了 6.57 个点。Live(真实场景)上,81.72 距离 DeepSeek-V3 的 82.09 只差 0.37,几乎打平,但人家是 671B MoE。
ToolACE-R 比 ToolACE-8B 涨了 4.55 个点。 这点比"打 GPT-4o"更有意义,因为两者用的是同一份原始数据集(论文明确说用的是 ToolACE 训练数据的子集),区别只在训练流程。也就是说,4.55 个点是 model-aware iterative training 这套方法本身的纯收益。
再看推理时扩展加上之后的版本——
| 方法 | Non-live | Live | Overall |
|---|---|---|---|
| ToolACE-R | 90.94 | 81.72 | 86.33 |
| ToolACE-R + Adaptive SR | 91.32 | 82.34 | 86.83 |
Adaptive Self-Refine 再涨 0.5 个点。乍看不大,但配上"平均只多 1.4 轮推理"这个开销,性价比是相当能打的。
消融:到底是哪一块在贡献
| 设置 | Non-live | Live | Overall | 相对 base 提升 |
|---|---|---|---|---|
| Llama3.1-8B-Inst(base) | 84.37 | 69.28 | 76.83 | — |
| 全量 SFT(无 SR data,无 data selection) | 88.75 | 80.09 | 84.42 | +7.59 |
| + SR data | 88.96 | 81.13 | 85.04 | +8.21 |
| + Data Selection(即 ToolACE-R) | 90.94 | 81.72 | 86.33 | +9.50 |
| + Adaptive SR | 91.32 | 82.34 | 86.83 | +10.00 |
这张表读下来挺有意思的:
- 单纯做 SFT 就能从 76.83 涨到 84.42,证明 ToolACE 原始数据集本身够强
- 加上 self-refine data:+0.62,贡献中等
- 加上 model-aware data selection:+1.29,是单一模块里贡献最大的
- 加上推理时 Adaptive SR:+0.50
model-aware difficulty + iterative selection 才是这篇论文最值钱的部分。 Adaptive Self-Refine 是锦上添花的工程优化,但真正的"原创性贡献"在于训练侧那套难度建模。
一个值得专门讲的实验:模型感知到底是不是真的"模型感知"
论文有个实验我觉得设计得相当聪明,专门拿来回答一个反直觉的问题:
既然你说要"模型感知",那我用一个别的模型(比如 Qwen2.5-7B)来评估 Llama3.1-8B 训练样本的难度,会差多少?
按理说工具调用难度不就是数据本身的属性吗?应该和评估模型无关才对。
| 数据筛选模型 | Live | Overall | 数据量 |
|---|---|---|---|
| ToolACE-R(用 Llama3.1-8B 自己筛) | 81.72 | 86.33 | 120K |
| Select w/ Qwen2.5-3B-Inst | 80.83 | 85.50 | 125K |
| Select w/ Qwen2.5-7B-Inst | 81.27 | 85.97 | 134K |
| Intersection(三个模型都同意保留) | 81.37 | 86.08 | 108K |
注意几个细节:
- 用 Qwen2.5-7B 筛出 134K 样本,比 Llama3.1-8B 自己筛的 120K 还多——但训出来的 Llama 反而差 0.36
- 取三家交集只剩 108K 样本,结果反而比单用 Qwen2.5 系列好
这说明什么?说明难度并不是数据的固有属性,而是模型与数据之间的关系。Qwen 觉得简单的样本,对 Llama 可能就是踮脚才够得着;反过来也成立。这给"用强模型筛数据训弱模型"这个广为流传的做法泼了一盆冷水——强模型筛出来的中等难度样本对小模型来说很可能已经是天花板。
训练动态:迭代到底跑几轮才合适
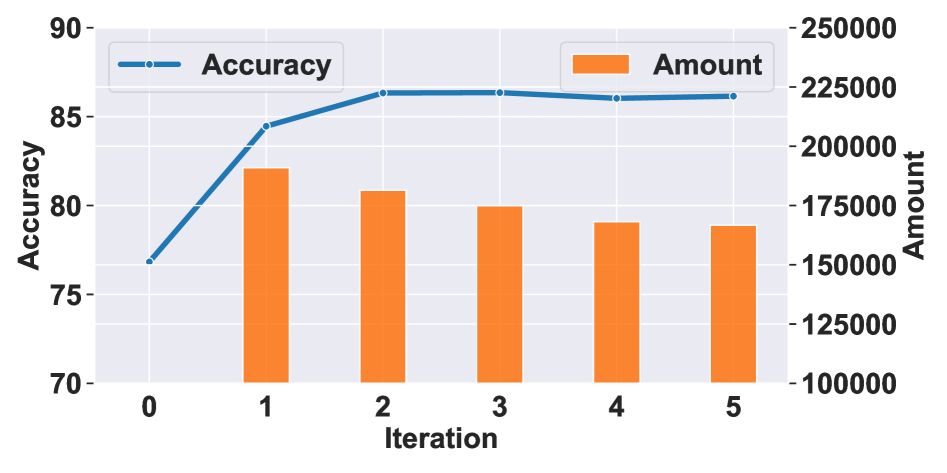
图 3:精度从迭代 0 的 76.83 涨到迭代 2 的 86.33 后基本饱和;训练数据量从约 19 万持续下降到 17 万左右——因为越来越多样本被模型答对,难度变 0 被踢出
两个观察:
精度在第 2-3 轮饱和,再继续迭代既不涨分还可能让模型在筛剩下的小数据集上过拟合。论文给的工程建议是最多迭代 3 次,这个经验值对工业落地很实用——不需要无限循环,跑 2 轮看是否还有提升,没有就停。
数据量单调下降而不是上下波动,说明迭代过程是收敛的——模型不会"忘记"之前学到的东西然后让某些样本难度回升。
跨模型尺寸的扩展性
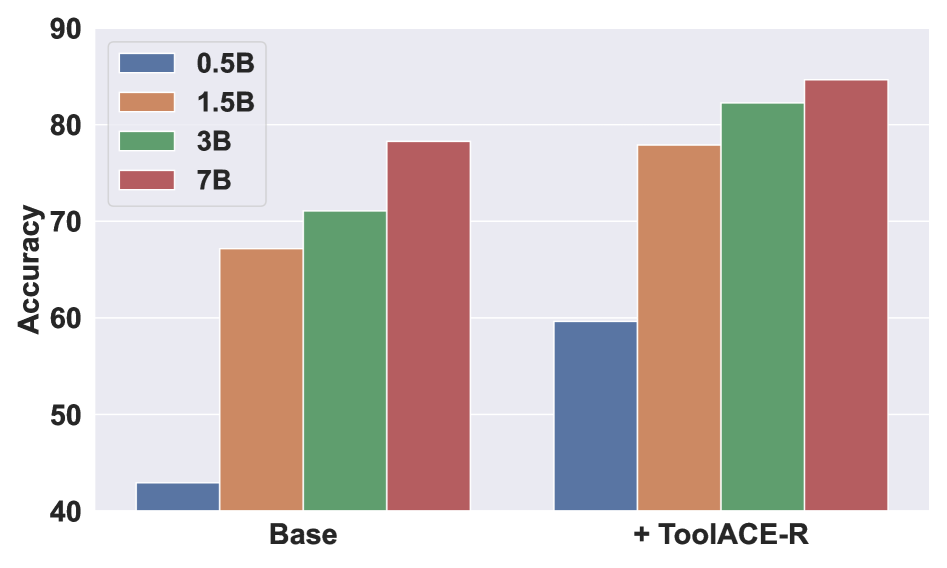
图 4:左侧蓝条是 Qwen2.5 base 模型,右侧是 + ToolACE-R 之后。0.5B 从约 43 涨到约 60,提升 17 个点;7B 从 78.28 涨到 85.21,提升约 7 个点
小模型涨得更猛这件事其实不太意外——base 越弱,model-aware 难度筛选筛出来的"恰好合适的训练样本"对它的边际收益就越大。但能让 0.5B 这种"半残"模型涨 17 个点,工程上是相当能打的——这意味着边缘部署场景(端侧、低算力 agent)有了一条新的路径。
跨 backbone 也试了,Qwen2.5-7B-Inst 从 78.28 涨到 85.21,Mistral-7B-Inst-v0.2 从惊人的 55.16 涨到 84.00(基线弱意味着工具调用能力差),都说明这套训练流程对底座的要求并不挑剔。
几个需要泼冷水的地方
吹了这么多,按 paper analysis 的传统,得讲讲哪些地方我觉得没那么完美。
第一,多轮对话场景没覆盖。 论文明确说只用了 ToolACE 数据集里的 single-turn samples,BFCL 也只评了 single-turn 的子集。但真实 agent 应用里,多轮对话才是主战场——用户说"刚才那个查询改成下周的",模型要理解上下文调正确的工具。这个场景下 model-aware difficulty 怎么定义、自精修要不要把历史轮次都重新判断一遍,论文都没碰。这是后续工作必须解决的问题。
第二,Adaptive Self-Refine 在 ACEBench 上几乎没收益。 主表里 ACEBench 涨了 0.12(83.88 → 84.00),论文承认是"presence of particularly challenging cases where the model struggles to correctly refine its answers"。说人话就是:遇到模型本身就不会的题,怎么改也改不对。 自精修的边界很清楚——它放大了模型已有的能力,但变不出来本来不存在的能力。
第三,难度估计的成本被低估了。 \(k=8\) 次推理 × 几十万个样本 × 每次迭代重算一遍——这个开销在论文里没有详细汇报。对于资源受限的团队,这其实是个不小的工程负担。\(k=1\) 的对比实验(85.96 vs 86.33)显示降到 1 次也只掉 0.37 个点,这其实给了一个工程妥协方案:先粗筛、再精算。
第四,和 RL 路径的对比缺失。 同期工业界(包括 Qwen-Agent、xLAM-2)已经在用 RL(GRPO、DPO)训工具调用了。SFT + 难度筛选是不是真的比 RL 更有效?或者说能不能叠加?论文没回答。这一块如果能补上,影响力会大很多。
工程启发:哪些做法可以直接搬
如果你正在做工具调用类的 fine-tune 项目,以下几条建议是这篇论文给的真东西:
第一,别再用一份固定数据集训到底。 训完一轮拿模型自己跑一次全量数据,把全对的样本扔掉再训,光这一步就有可观收益。
第二,构造自精修样本时,留下"答对也不改"的那部分。 这是教模型识别"答案已经够好了"的唯一信号源,扔掉就废了 adaptive stopping 这个能力。
第三,推理时优先做 adaptive 而不是 majority voting。 平均 2.4 轮 vs 强制 10 轮,性能持平但开销 1/4,这账谁都会算。
第四,难度评估别迷信"借助强模型筛数据"。 论文实验已经证明,强模型筛出来给弱模型用,效果反而比弱模型自己筛差。"模型感知"的 model 必须就是被训练的那个。
第五,迭代训练 2-3 轮就够。 别贪。
我的整体判断
这篇论文我读完最深的感受是:它没有发明任何全新的技术原语,但把几个看起来朴素的想法拼成了一条很顺的链路。
model-aware difficulty 不新——本质是 curriculum learning 的变种;自精修不新——OpenAI、DeepMind 早就玩过;refine-until-stable 这种停止条件也不新——RAG 里的 self-consistency 就是类似思路。但把这三件事用"模型自我评估"的同一个底层信号串起来——训练时模型的当前能力决定吃什么数据,推理时模型的当前判断决定改不改下去——这个统一性是这篇论文真正的贡献。
读到最后我有个挺强的感觉:工具学习这个赛道正在从"造数据"阶段进入"造能力"阶段。光把数据堆得更大、更精致,已经不是边际收益最高的方向了;如何让模型在训练和推理两端都自我感知、自我调度,才是后面几年的主旋律。ToolACE-R 在这个意义上是个相当及时的工作。
如果你也在做 agent / tool calling / function calling 类项目,这篇值得啃一遍原文。它的核心思路实现门槛不高,半天能搭一个 prototype,一周能跑完一轮迭代——和那些动辄需要重写训练框架的方法比起来,已经非常工程友好了。
参考资料
- 论文:https://arxiv.org/abs/2504.01400
- ToolACE 原始工作:Liu et al., ToolACE: Winning the Points of LLM Function Calling, 2024
- Berkeley Function Call Leaderboard:https://gorilla.cs.berkeley.edu/leaderboard.html
- ACEBench:Chen et al., ACEBench: Who Wins the Match Point in Tool Learning, 2025
- API-Bank:Li et al., API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs, 2023
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我