当 RAG 检索到的内容跟模型脑子里的"记忆"打起来——AAAI 2026 这篇用信息瓶颈给出了一个有理论支撑的解法
做过 RAG 的人,多多少少都碰到过这种尴尬场面。
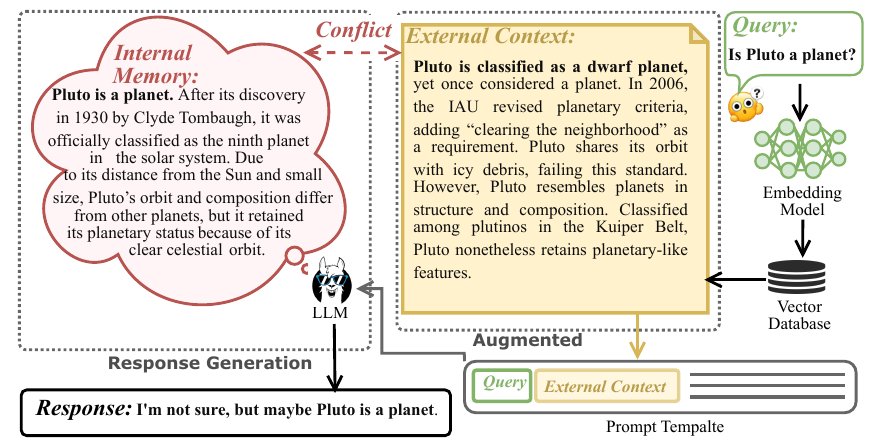
用户问"冥王星是行星吗?"。模型 closed-book 答得挺自信——"是行星,1930 年克莱德·汤博发现的"。然后接上检索增强,向量库返回一段更新后的资料——"2006 年 IAU 重新分类,冥王星已被移出行星行列"。两份信息一前一后塞进 prompt,模型沉默了一秒,最后吐出一句:"I'm not sure, but maybe Pluto is a planet."
不是它不会答,是两边的信息势均力敌的时候,它真的不知道该信谁。
这就是 RAG 在真实场景里最难处理的一类问题——知识冲突。AAAI 2026 上有一篇文章 Swin-VIB,从信息论角度把这个现象掰开讲了一遍,给出了一个观察直觉简单、但理论支撑挺扎实的方案。我读完之后觉得有几个点确实想跟大家聊聊。
核心一句话
这篇论文做了两件事。
第一,它用条件熵把"为什么 LLM 在冲突信息面前会犹豫"这件事写成了一组可分析的不等式,得到一个非常干净的结论——LLM 生成时的不确定性,单调依赖于"冲突信息"和"补充信息"在自信息上的差值 \(\Delta I = I_c - I_s\)。差值越大,越笃定;差值越接近 0,越混乱。
第二,它把这个洞见落到了一个工程上能用的模块。每个 transformer decoder 层挂一个变分信息瓶颈(VIB),用一个滑窗(Swin)把检索到的长上下文切成 7-token 的小窗口,逐窗预测"这个窗口里冲突 vs 补充信息的差异是不是足够大",差不大的窗口直接丢掉,只把差异够大的窗口拼回 prompt。这样 LLM 看到的上下文偏好就被显式地拉到了"自信区",而不是"困惑区"。
效果上——多选题任务上五个 LLM 全部跑赢 SOTA 基线,最高 +6.24 个点;开放问答 EM 提升 11.14 个点;额外延迟在 7B 模型上 0.39 秒,量级是可以接受的。
我个人对这篇的判断——这是少见的、把 RAG 的一个老问题真的拉到信息论框架里讨论清楚的工作。结论本身不算颠覆性,"差异大就笃定,差异小就犹豫"这种事情很多人凭直觉也能猜到。但作者把它形式化了,并给出一个能直接挂到 RAG pipeline 上的轻量模块——这才是它的价值所在。
论文信息
| 项 | 内容 |
|---|---|
| 标题 | Accommodate Knowledge Conflicts in Retrieval-augmented LLMs: Towards Robust Response Generation in the Wild |
| 作者 | Jiatai Wang, Zhiwei Xu, Di Jin, Xuewen Yang, Tao Li |
| 收录 | AAAI 2026 |
| arXiv | 2504.12982v2 |
| 代码 | github.com/JiataiWang/Swin-VIB |
为什么这件事值得花力气
先说一个我个人觉得现有工作没做好的地方。
针对 RAG 的知识冲突,社区里目前主要有两条路。
一条是调整 LLM 偏向外部上下文——通过 fine-tune 或 model editing,强行让模型相信检索到的内容。代表工作像 CD²、TruthX 等。这条路的麻烦在于,它默认了一个隐含假设:检索到的就是对的。但真实场景里,向量库里有时候装的是过期内容、有偏见的来源、甚至是错的。把模型调成无脑相信外部,就是在赌检索质量永远在线。
另一条是外挂校验模块——TruthRAG 这一系,先验证检索到的内容靠不靠谱,靠谱就用、不靠谱就丢。问题是它只是在做"二选一",没解释 LLM 内部到底怎么处理冲突的。当外部内容部分可信、部分可疑(这才是真实场景的常态),这种 hard gate 就力不从心了。
还有第三条——解码时重新平衡,比如 PIP-KAG 之类的工作,在每个 token 上重新加权 internal/external。这条思路挺优雅,但 token 级重加权扩展到长上下文上开销就比较吃紧了。
作者的判断是——这些方法都有效果,但都缺一个东西:LLM 在冲突场景下究竟为什么会形成某种偏好,之前没人从原理层面说清楚过。没有原理,所有调整都是经验性的,换个数据集、换个领域,参数就得重调。
这是为什么这篇要回去做信息论分析。
核心理论:把"犹豫"写成一个不等式
理论部分作者写得挺克制,4 步推下来核心思路就出来了。我用工程的话翻译一遍。
第一步:把不确定性形式化
给定 query \(Q\)、检索结果 \(R\)、生成响应 \(O\),LLM 生成的不确定性就是条件熵:
这个量越大,模型越没主见。要做的是把它压低。
第二步:把生成概率拆到 latent space
用 LLM 的高维隐状态 \(X\) 做引子,把 \(p(o \mid r, q)\) 重新表达。一通推导(贝叶斯展开 + 引入"对齐到检索内容"的隐状态 \(x_\gamma\))之后,作者得到一个挺漂亮的形式:
这里两个量需要解释——
- \(I_s = -\log p(r \mid x)\):自信息,描述的是检索到的 \(r\) 与 LLM 内部记忆 \(x\) 一致的程度,作者称为补充信息(supplementary information);
- \(I_c = -\log p(r \mid x_\gamma)\):与内部记忆相左的部分,对应的是冲突信息(conflicting information)。
工程上的直觉很简单——\(I_s\) 大表示"检索到的东西模型认得",\(I_c\) 大表示"检索到的东西跟模型自己的记忆对不上"。
第三步:泰勒展开拿到一阶代理
利用 \(\exp(\cdot)\) 的单调性、加上对 \(o\) 归一化能消掉常数项,作者做一个一阶泰勒展开,得到了核心代理:
第四步:连接到不确定性
把第三步代回 instance-level 不确定性 \(\psi(p) = -p\log p\),作者得到一个非常干净的单调关系:
也就是说——冲突信息和补充信息的差异越大,模型生成的不确定性越低;两者差异接近 0 时,不确定性达到峰值。
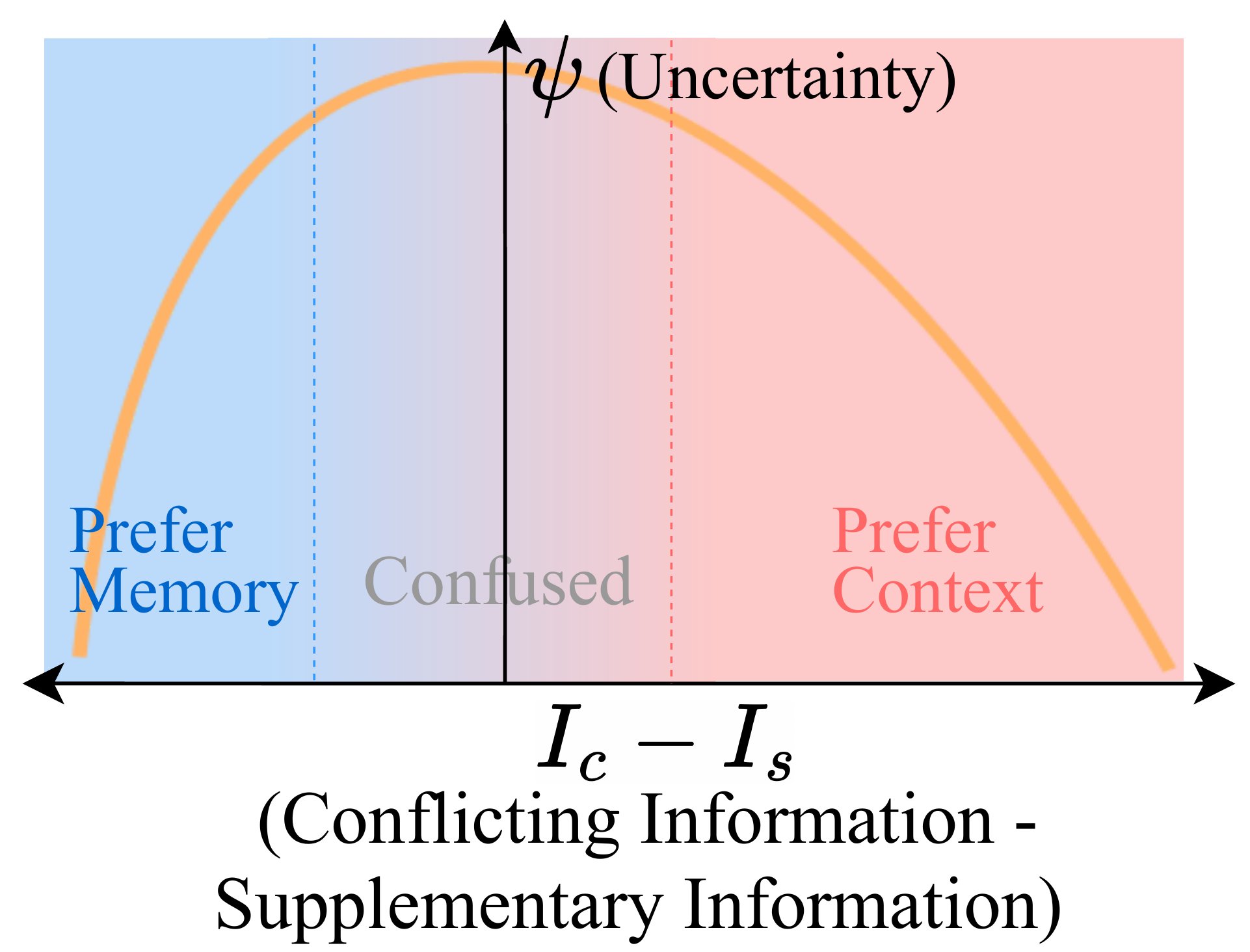
这张图是整篇文章的灵魂图——一个倒 U 形曲线。横轴是 \(I_c - I_s\),纵轴是不确定性 \(\psi\)。中间是 Confused 区,左边是 Prefer Memory,右边是 Prefer Context。这个图传达的就一件事——模型在两端都是笃定的,只在中间犯怵。
一段实证验证
光有理论不够。作者跑了一个挺简洁的验证实验——在 ConflictQA 数据集上,把外部 context 里冲突 vs 补充内容的比例从 2:0 拉到 0:2,看 LLM 的偏好和 UAR(不确定回答率)怎么变。
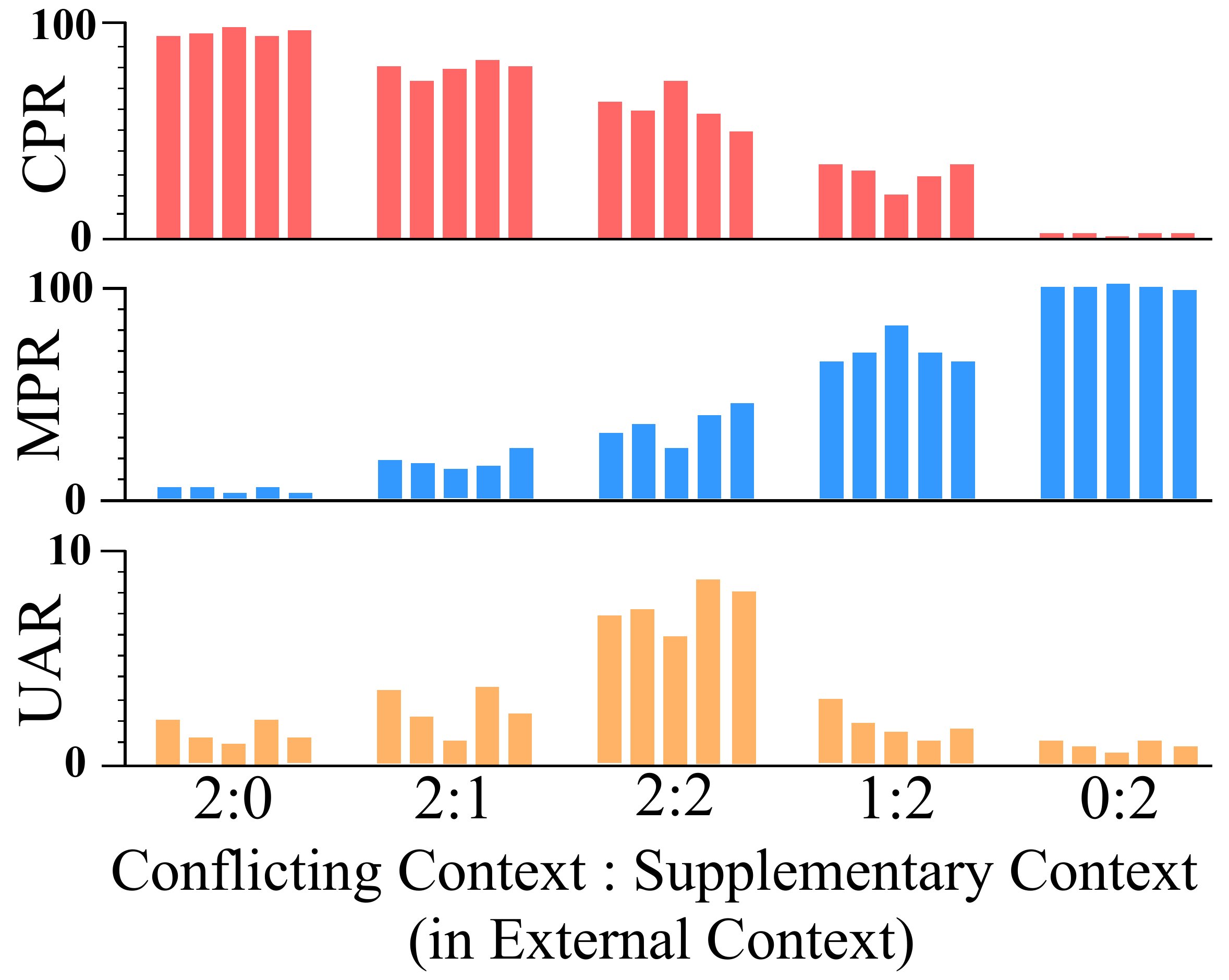
这张图把三个比例的趋势画在一起——CPR 从 90+ 一路跌到接近 0,MPR 从接近 0 涨到 100,UAR 在 2:2 处呈现明显的尖峰,往两边递减。
UAR 在 2:2 处冲到顶——这就是理论预测的"差异接近 0 时不确定性最大",五个模型(Llama2-7B、13B、70B、DeepSeek-7B、Qwen3-8B)行为完全一致。这种跨模型一致性其实挺有说服力的,不是某一个模型的特殊行为,是这一类 transformer 模型都遵循的某种基础规律。
Swin-VIB:把理论变成一个能挂的模块
理论说完,工程实现的思路就出来了——既然差异大的窗口才能让 LLM 笃定,那就把检索回来的长上下文切成小窗口,每个窗口预测它的"信息差"够不够大,差够大就保留,差不够就丢。
整体流程
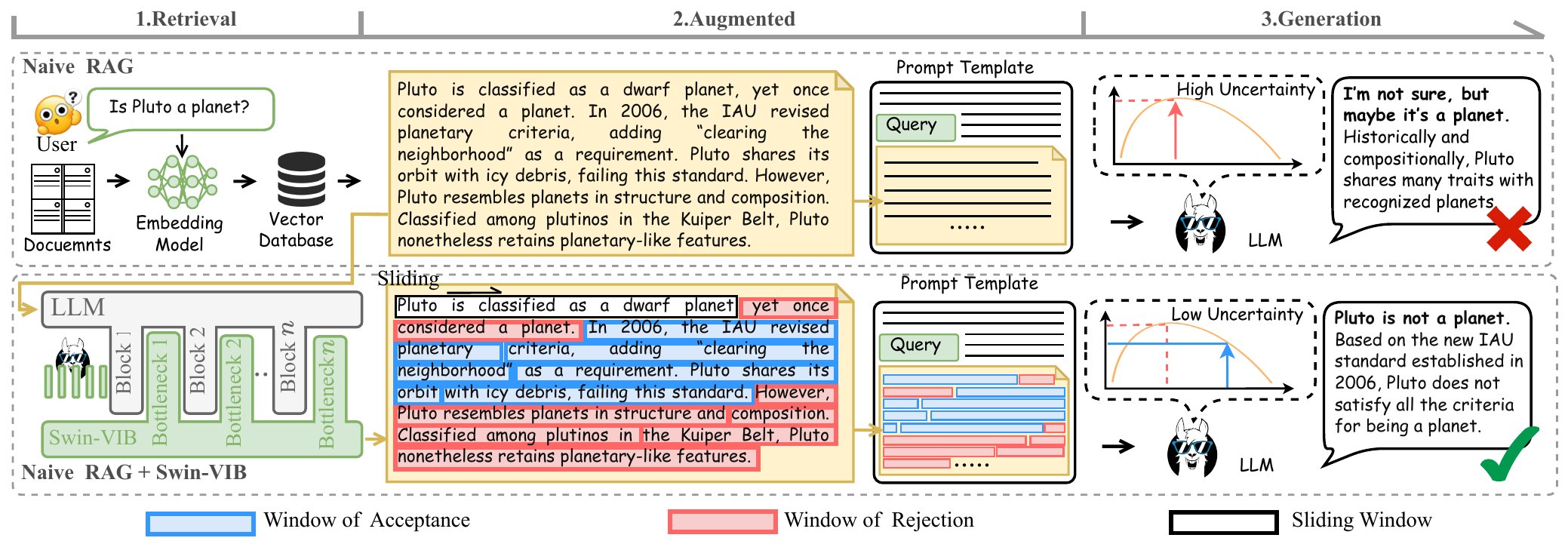
整张图分成两条流——
上面 Naive RAG 那条:query + 检索回的全部上下文 → prompt → LLM。结果是模型不确定,给出"I'm not sure, but maybe..."这种含糊回答。
下面 Naive RAG + Swin-VIB 那条:检索回的内容被 7-token 的滑窗切片,每个窗口送进每一层 decoder 旁的 bottleneck 模型,输出一个"这窗口的信息差够不够大"的概率。蓝色窗口(Window of Acceptance)保留、红色窗口(Window of Rejection)丢弃。最后只把蓝色窗口拼回 prompt 喂给 LLM。
最终模型答出:"Pluto is not a planet. Based on the new IAU standard established in 2006..." 给了个明确、有依据的答复。
训练数据怎么构造
这部分是整个方法最让我觉得"诶这个想法挺巧"的地方。
bottleneck 模型要预测的目标是"窗口内信息差大不大",但信息差本身是不可观测的——你怎么标 ground truth?
作者的处理是——用窗口的来源单一性当成信息差大小的代理。
具体规则是这样:
- 给 query \(q\) 配两类 context:纯冲突 \(r_c\)、纯补充 \(r_s\),再把这俩按每 4 个 token 交错混合得到 \(r_m\);
- 从 \(r\) 中随机抽一个 7-token 的窗口 \(\omega^*\);
- 标签 \(\mathbf{Y}\):来自 \(r_c\) 或 \(r_s\) → 1(信息差大),来自 \(r_m\) → 0(信息差小)。
这个标注的合理性在于——纯冲突或纯补充的窗口,信息单一来源,\(|\Delta I|\) 自然大;混合窗口里冲突与补充各占一半,\(|\Delta I|\) 自然小。这个映射本身就是一个隐式假设,但作者后面用人工标注验证了一下——丢弃的窗口里 76% 被人工判定为"undecidable"(无明显冲突或补充倾向),证明这个 proxy 确实抓到了重点。
每层一个 bottleneck
第二个有意思的设计是 bottleneck 不是单个,是每个 transformer decoder 层都挂一个。
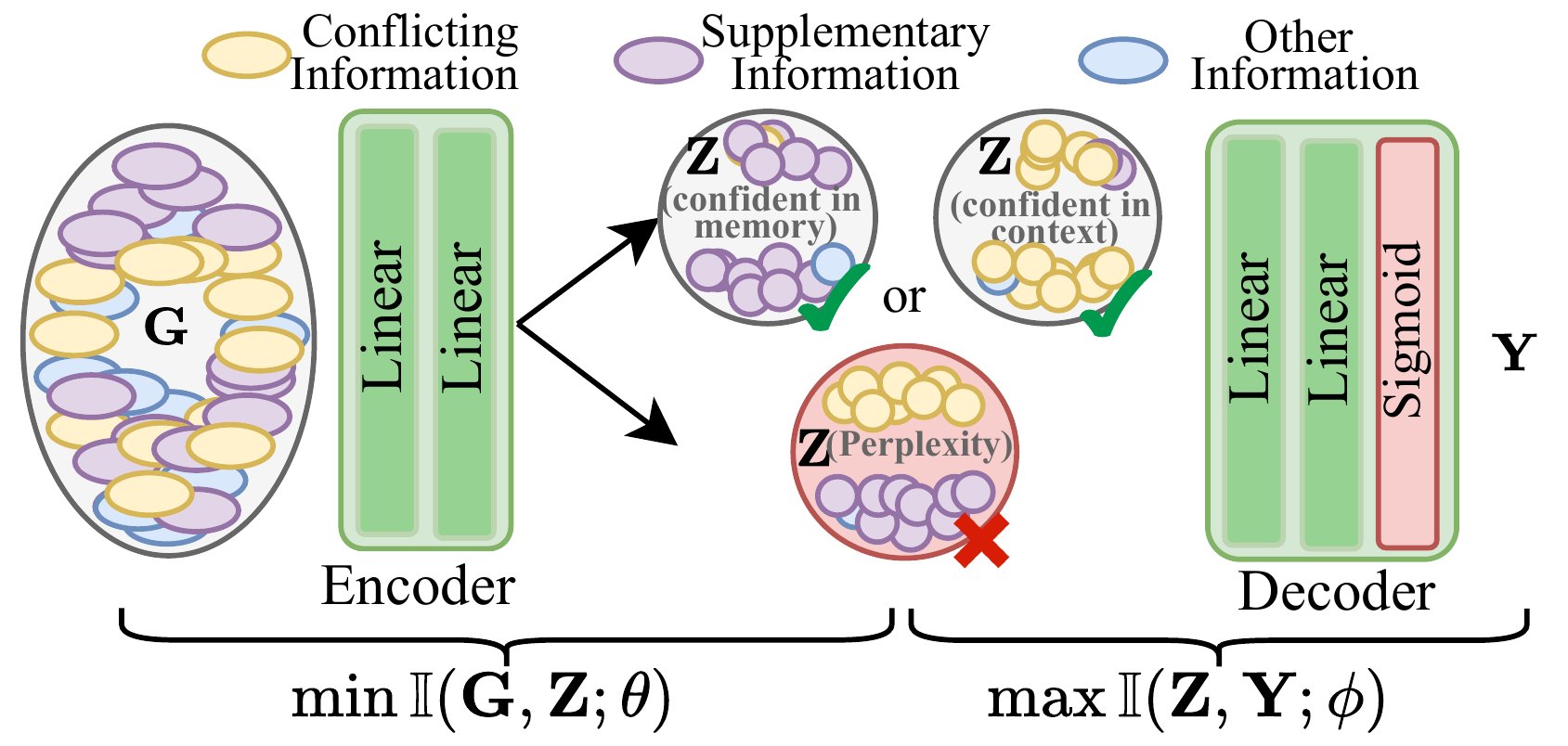
输入是某一层的注意力矩阵 \(\mathbf{G}_n\)(取 head 平均后的结果)。
Encoder 输出高斯潜变量 \(\mathbf{Z}_n\) 的均值和对数方差: $\(q_\theta(\mathbf{Z}_n \mid \mathbf{G}_n) = \mathcal{N}(\mu_n, \mathrm{diag}(\sigma_n^2))\)$
通过 reparameterization trick 采样: $\(\mathbf{Z}_n = \mu_n + \sigma_n \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I})\)$
Decoder 把 \(\mathbf{Z}_n\) 映射到二分类 logit。每层 bottleneck 的损失是经典 VIB 形式:
第一项让 Z 保留预测 Y 所需的信息,第二项把 Z 压向标准正态先验、强制丢掉冗余。\(\beta\) 控制这两者的权衡。
为什么要每层都挂?因为不同层捕捉的信息不同——浅层关注 token 级语法,深层才开始处理语义和事实冲突。把每层信号都拿来加权,鲁棒性会高一些。论文实测发现,深层 decoder 提供的鲁棒性更强,这跟"浅层处理表面、深层处理事实"的直觉一致。
推理时怎么决定
推理时就简单了——多层概率取平均:
只要 \(\hat{p} \geq \xi\)(论文取 \(\xi = 0.68\)),这个窗口就被接受。最后所有接受窗口拼到 query 后面送给 LLM。
整个过程——LLM 参数完全冻结、bottleneck 是个轻量小网络,挂上去几乎不增加显存压力。
实验:5 个 LLM × 3 个数据集
主实验是多选题任务,五个 LLM、两个冲突数据集(ConflictQA + DRUID),跟 5 个 SOTA 基线(Closed-book、In-context、CD²、Rowen-CL、CK-PLUG)比。
我把 Llama2-13B 在两个数据集上的关键结果列出来——
| 方法 | ConflictQA ACC | ConflictQA UAR | DRUID ACC | DRUID UAR |
|---|---|---|---|---|
| In-context | 79.83 | 1.98 | 51.73 | 7.16 |
| CD² | 80.20 | 4.85 | 60.72 | 4.04 |
| Rowen-CL | 80.36 | 1.10 | 52.61 | 4.36 |
| CK-PLUG | 81.44 | 1.78 | 61.07 | 5.47 |
| Swin-VIB | 85.68 | 0.18 | 63.43 | 1.96 |
几个观察:
ACC 全面碾压——Swin-VIB 在 ConflictQA 上比最强基线 CK-PLUG 高出 4.24 个点,在 DRUID 上高 2.36 个点。论文里说最高有 6.24 个点的提升,这是在某些 LLM × 数据集组合上的极值。
UAR 降到几乎归零——这个比 ACC 提升更值得说。Llama2-70B 上 Swin-VIB 的 UAR 只有 0.03(ConflictQA)和 0.16(DRUID),意味着模型几乎不会再说"I don't know"了。实际产品里这个其实更重要——用户最讨厌的不是答错,是问了半天得到个含糊回答。
Mean-\(\psi\) 也降下来——instance-level 不确定性从 0.27-0.34 区间降到 0.22-0.28 区间。Pearson 相关性测出来 Mean-\(\psi\) 跟 TRE 的相关系数 0.81,证明微观和宏观两个层级的不确定性同步下降,理论预测和实验结果对得上。
集成到 RAG pipeline 上的效果
更接近真实场景的实验是开放问答——把 Swin-VIB 挂到 Naive RAG / Self-RAG / Astute RAG 上。
| RAG 方法 | EM | METEOR | Faithfulness |
|---|---|---|---|
| Naive RAG | 46.50 | 42.85 | 73.03 |
| Naive RAG + Swin-VIB | 60.14 | 50.95 | 66.58 |
| Self-RAG | 39.39 | 43.38 | 70.10 |
| Self-RAG + Swin-VIB | 58.32 | 55.29 | 64.32 |
| Astute RAG | 53.02 | 44.69 | 65.23 |
| Astute RAG + Swin-VIB | 64.16 | 53.70 | 64.09 |
EM 从 46.5 涨到 60.14、从 39.39 涨到 58.32、从 53.02 涨到 64.16,三个 baseline 上都有十几个点的提升,最猛的是 Self-RAG +18.93 个点。
Faithfulness 下降挺有意思——作者解释是滑窗策略丢掉了一些"低信息差"的窗口,模型不再无脑复述检索结果,所以 Faithfulness 反而降了。这个 trade-off 我觉得是合理的——RAG 不应该只追求 faithfulness,否则就退化成检索结果的复读机。
延迟开销
| LLM | Naive RAG 延迟 | Swin-VIB 增加延迟 |
|---|---|---|
| Llama2-7B | 0.49 s | +0.39 s |
| Llama2-13B | 0.88 s | +0.52 s |
| Llama2-70B | 4.60 s | +2.78 s |
| Qwen3-8B | 0.39 s | +0.27 s |
| DeepSeek-7B | 0.38 s | +0.43 s |
每个窗口 bottleneck 处理时间是亚毫秒级(0.08-0.55 ms),整体延迟主要来自窗口数量。在 7B/8B 模型上额外开销大约是原 RAG 的 1 倍——绝对值还是 sub-second,对很多产品场景能接受。70B 上加 2.78 秒就比较吃紧了。
几个我觉得需要泼冷水的地方
写完以上这些,我得说几个让我有点不放心的点。
第一:训练标签的 proxy 是否足够准
作者用"窗口来源单一 vs 混合"作为信息差大小的标签。这个映射在 ConflictQA、DRUID 这种结构化数据集上能工作,因为 \(r_c\) 和 \(r_s\) 是清晰可分的。但真实 RAG 场景里——检索回的 top-5 内容很少有"完全冲突"或"完全补充"的,更多是"部分重合 + 部分矛盾 + 部分无关"。这种细粒度混合下,proxy 是不是还能保持一致性?文章没正面回答。
人工标注那个 76% undecidable 的实验结果,其实只能说明 reject 的窗口里大部分确实是"难判断"的,但反过来——accepted 的窗口里有多少是真正的高信息差?没有给出。
第二:每层 bottleneck 平均加权
推理时 N 层 bottleneck 输出做了一个简单的算术平均。但论文自己也提到"深层 decoder 提供的鲁棒性更强"——既然如此,为什么不用加权平均、按层重要性给不同权重?这看起来是个明显能做的优化但没做。我猜可能是简单平均已经够好了所以没动,但这个设计选择没有充分讨论。
第三:跟 token-level 重加权方法的比较
CD²、CK-PLUG 这类 token 级重加权方法跟 Swin-VIB 在思路上是有冲突的——前者是"在生成时动态调权",后者是"在 prompt 构造时硬筛"。论文里的对比主要看 ACC,但缺一个更细的分析——在哪些样本上 Swin-VIB 赢、哪些样本上 token-level 方法赢?这种 per-sample 的 breakdown 才能告诉我们这两类方法是替代关系还是互补关系。
第四:阈值 \(\xi\) 的设定有点经验
\(\xi = 0.68\) 是论文的默认值,并且声称在 0.6-0.8 范围都稳定。但这个参数对不同领域、不同检索质量的数据,是不是真的不敏感?没有跨领域的鲁棒性测试。如果在医疗、法律这种高 stakes 的领域要部署,这个阈值可能需要重新校准,而 calibration 本身的成本论文没讨论。
我的判断
抛开这些挑刺,我觉得这篇文章的真正价值在三个地方。
第一,它把 RAG 知识冲突的研究从"经验调参"拉到了"理论建模"层面。条件熵 → 信息差 → 不确定性这条链条虽然不复杂,但它是第一次有人把这套话语建立起来。后续做 RAG 鲁棒性的工作,都可以在这个框架上往前推。
第二,VIB 在 NLP 里其实用得不多。原始 Deep VIB 论文是 2017 年的事情,主要应用场景在 vision 和 representation learning。把它搬到 LLM 的 decoder 层做窗口筛选,这个嫁接挺巧妙的——VIB 的"压缩 + 预测"双目标天然适合做"提取关键信号 + 丢弃冗余"这种场景,跟 RAG 窗口筛选的需求高度契合。
第三,工程上的 plug-and-play 属性确实漂亮。LLM 不动、bottleneck 是轻量小模块、推理时延的增量在可控范围内——这种工程亲和度让它更容易被采纳。比起那些需要重新 fine-tune LLM 的方法,门槛低很多。
工程上能借鉴的几个点
如果你正在做 RAG 系统、并且也碰到了类似的"检索回来的内容跟模型内部知识打架"的问题,这篇至少给了三个可借鉴的思路:
-
信号来源选 attention 而不是 hidden state——作者用的是每层注意力矩阵的 head-mean,这个比 hidden state 更轻量,且 attention 本身就编码了 token 间相互依赖,做窗口级判断更合适。
-
用 VIB 而不是直接分类器——KL 项作为信息上界,逼着 encoder 丢冗余、保关键,比一个简单的 MLP 二分类器更鲁棒,对 OOD 数据的退化也更轻。
-
滑窗 + 接受/拒绝二分——这个比 token 级权重重新分配的实现成本低非常多,且 latency 可控(窗口数量是常数)。如果你的 RAG 系统现在用的是 token-level 调权且开销吃紧,可以考虑切到 window-level。
最后
这种把"信息论框架 + 一个轻量工程模块"组合起来的工作,在我看来是 RAG 这个方向下一个阶段比较有前景的形态——不是堆模型、不是堆数据、不是 fine-tune,是用更精细的理论工具去解释和干预 LLM 已经表现出的行为。
我自己之前在做检索增强相关项目时,最头疼的就是 reranker 之后的内容塞给 LLM 后还是会"思考过度"——明明已经检索到了正确答案,模型还要纠结一会儿。Swin-VIB 这种思路,等于是在 LLM 之前再加一层"语义级 dedup"——把那些会把模型往困惑区拉的窗口提前剔掉。
至于这套方案能不能直接抄过去用?最大的问题在训练数据——论文用 ConflictQA、DRUID 这种结构化冲突数据集训出来的 bottleneck,迁移到自己业务的检索数据上效果是否还在,需要做一轮验证。但作为一个值得跟进的方向,我觉得是 OK 的。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我