KV Cache 还能再砍一刀:SparK 在通道维度上做了一件被忽略多年的事
核心摘要
LLM 推理在长上下文场景下,KV 缓存几乎是命门。LLaMA3.1-8B 跑 100K token,光是 KV 就吃掉 50GB 显存,比模型权重本身还大。过去几年大家围着这个问题搞了一堆方案——按 token 驱逐、按 token 合并、按层共享、按头剪枝,结果有一条路一直没人认真走:通道维度(也就是每个 head 内部那 128 维特征)。AMD 联合中科院自动化所提出的 SparK 把这条路填上了——通道显著性会随 query 大幅波动,所以必须做查询感知的非结构化剪枝;而且剪掉的通道不能直接丢,得在算 attention 时把它"恢复"回来一个近似值,否则注意力打分会被打歪。最终结果挺漂亮:训练 free,正交于现有所有方法,叠加 SnapKV 后 KV 存储再降 30 个点以上,80% 通道剪枝下精度退化控制在 5 个点以内,而前作 ThinK 在同样设置下直接崩掉 47.6 个点。这是一篇值得长上下文推理工程师看的论文,不是噱头。
论文信息
- 标题:SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning
- 作者:Huanxuan Liao, Yixing Xu, Shizhu He, Guanchen Li, Xuanwu Yin, Dong Li, Emad Barsoum, Jun Zhao, Kang Liu
- 机构:中国科学院自动化研究所 + AMD AIG-AIMA
- 会议:AAAI 2026
- arXiv:2508.15212v3(2025-11-12)
- 代码:https://github.com/AMD-AIG-AIMA/AMD-Spark
一、为什么"通道维度"这条路一直被绕开
先说一下 KV cache 为什么这么烫手。一个标准 Transformer 推理里,KV cache 的总大小是 \(2 \times B \times S \times L \times N \times D\)——batch 数 \(B\)、序列长度 \(S\)、层数 \(L\)、头数 \(N\)、每个头的特征维度 \(D\)。这五个变量里,过去三年的论文几乎把每一个都拧过一遍:
- 砍 \(S\) 是主流:H2O、SnapKV、PyramidKV、StreamingLLM 全在做这个。看哪些 token 不重要就驱逐掉,或者合并相似 token。
- 砍 \(L\)、\(N\):跨层共享、剪头、CLA、xKV。
- 砍 \(D\) 的,几乎只有一篇 ThinK——它做的是结构化通道剪枝,所有 token 共用一套通道掩码。
一上来我看到 SparK 这个定位,第一反应是:通道维度真有那么大空间吗?\(D\) 在 LLaMA3 里是 128,撑死也就把 KV 砍到 1/2 量级;而 \(S\) 动不动就是几万,看上去显然砍 \(S\) 收益更大。
但作者的论证很巧。他们做了一个简单的可视化:把 LLaMA3.1-8B 第 18 层第 0 个 head 拿出来,画 Q·K 在通道维度上的分数。
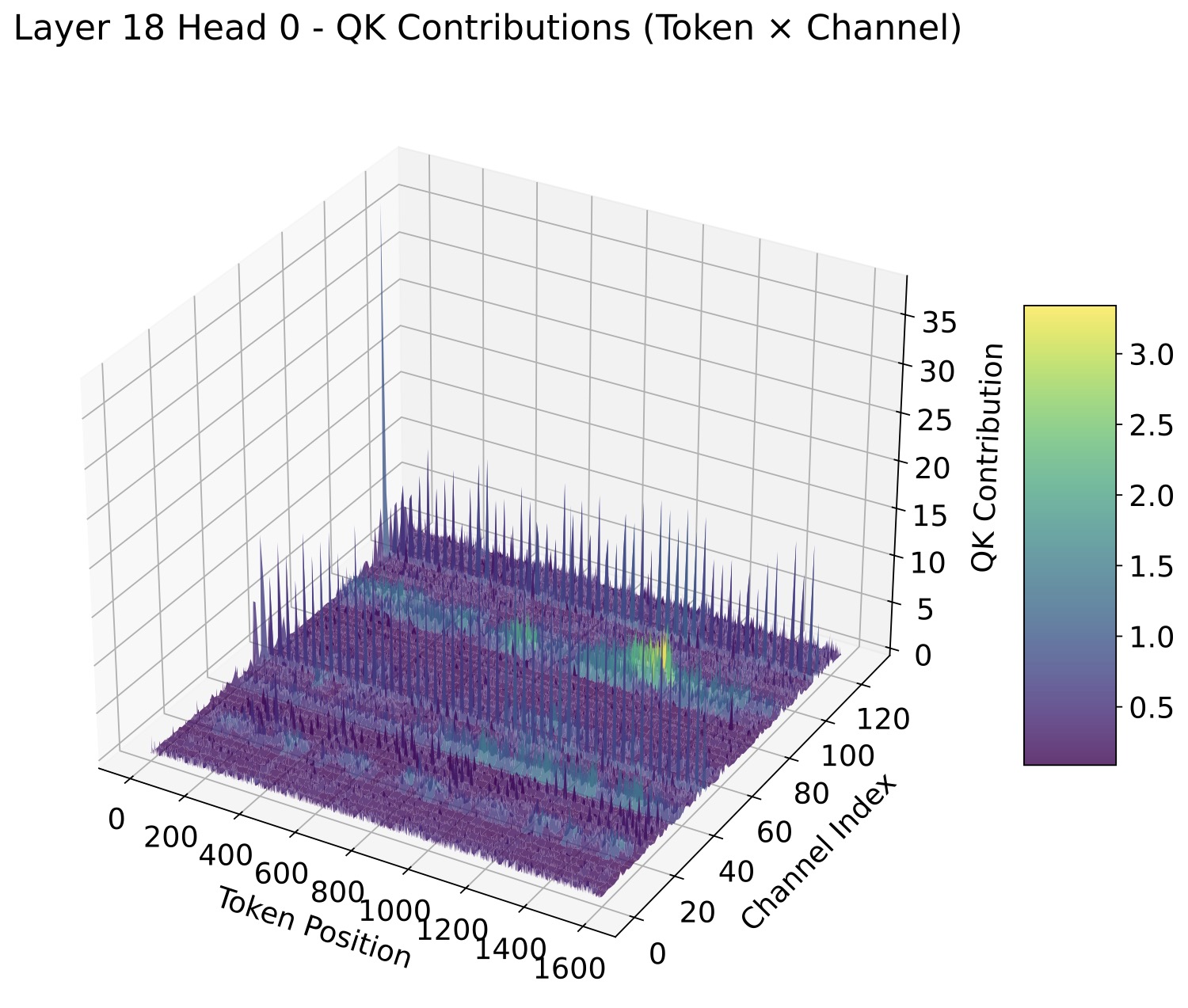
图 1:LLaMA3.1-8B 第 18 层 head 0 上的 Q·K 通道得分 3D 曲面。每个 token 真正"用得上"的通道集合不一样,整张曲面充满了尖峰和深谷,根本谈不上"哪些通道全局重要"。
这张图说明了一个挺关键的事——通道显著性不是全局静态的,而是随 token 剧烈波动。作者拿这个 head 算了一下变异系数(CV),平均超过 1.1,意思是绝大多数通道的标准差大于均值,token 之间的波动远比通道间的差异更主导。
于是 ThinK 那条路就被卡死了——结构化剪枝假设"哪些通道重要可以全局排个序",可实际上每个 token 的最佳通道子集都不一样。论文里给了个对比数据:50% 剪枝率下,结构化剪枝掉 4.2 个点,非结构化只掉 1.2 个点;80% 剪枝率下,差距直接拉到 27 个点。这就是 SparK 把"非结构化通道剪枝"当作核心命题的依据。
二、四种 KV 压缩思路放一起对比
作者在 intro 用了一张图把四种主流压缩思路并排放出来,看完就大致明白 SparK 在做什么了。
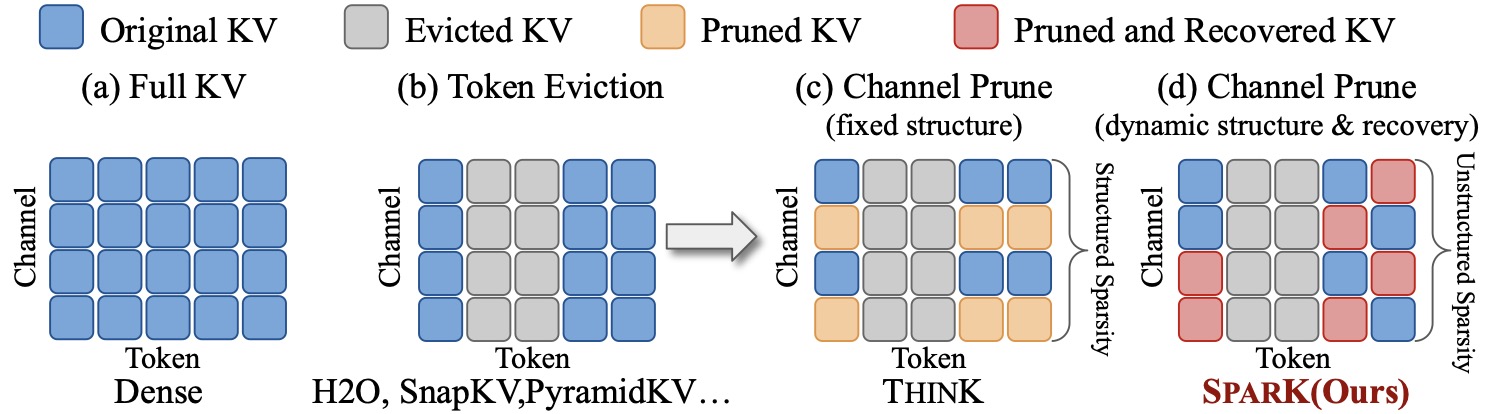
图 2:(a) 完整 KV cache;(b) 基于 token 驱逐的压缩,整行整行往外扔;(c) 结构化通道剪枝(ThinK),所有 token 共用一套通道掩码;(d) SparK 的非结构化通道剪枝 + 注意力计算时动态恢复。
把这张图盯一会儿就能看出几个关键差异:
| 维度 | Token 驱逐 | 结构化通道剪枝 | SparK |
|---|---|---|---|
| 砍的轴 | 序列轴 \(S\) | 通道轴 \(D\) | 通道轴 \(D\) |
| 粒度 | 整 token | 整列通道 | 单个 token 的单个通道 |
| 是否 query 感知 | 半感知(按 attention score) | 不感知 | 完全感知 |
| 恢复机制 | 无(信息直接丢) | 无 | 有(用分布统计采样) |
| 与前者正交 | / | 是 | 是 |
SparK 真正的差异点在最后一行——剪掉的通道在算 attention 时要把它"补"回来。这不是把数据存回去,而是用一个轻量的恢复函数 \(\boldsymbol{\mathcal{F}}\) 在算分时填一个近似值。这是论文里我觉得最巧的设计。
三、方法核心:把通道剪枝重新表述成"关键通道集"选择问题
3.1 一个干净的优化目标
作者把通道剪枝从直觉描述拉到了优化框架里。设 \(\mathcal{S}_{i,t} \in \{0,1\}^D\) 是 head \(i\)、token \(t\) 上的二值通道掩码,目标是选出 \(T\) 个通道(\(T \ll D\)),让剪枝后注意力得分的偏差最小:
这个问题本身是 cardinality-constrained low-rank approximation,NP-hard。但作者做了一步漂亮的展开和近似:把 \(\mathcal{E}^2\) 展开后会得到两项,一项是被剪通道自身的贡献和,一项是通道间的交叉相关项 \(\langle \mathbf{q}^j, \mathbf{q}^r \rangle \langle \mathbf{k}^j, \mathbf{k}^r \rangle\)。在实际模型里通道间几乎不相关(这点作者在附录里有验证),第二项可以扔掉。
于是问题坍缩成一个非常干净的形式:
其中 \(w_{i,t}^j = \|\mathbf{q}_{i,t}^j\|_2 \cdot \|\mathbf{k}_{i,t}^j\|_2\) 是该通道的代理显著性分数。这是一个标准的 top-\(T\) 选择问题,用贪心就能 \(O(D \log D)\) 解。
我读到这里其实挺欣赏的——大多数 KV 压缩的论文是先有 trick、再凑解释,SparK 是从一个干净的优化问题里推出贪心规则。论证链条短,假设也写得很明白:通道间近似不相关。这个假设在 attention 训练目标里是成立的,但作者没回避它,附录里专门验了一下。
3.2 prefill 阶段:用观察窗口算显著性
到了实现层面,问题来了——你在 prefill 阶段做剪枝,怎么知道未来 query 会用哪些通道?
SparK 沿用了 SnapKV 的做法:用最后一段观察窗口(observation window)的平均 query \(\overline{\mathbf{q}}_i\) 作为代理。具体来说:
然后用这个平均 query 算每个 (token, channel) 的显著性 \(w_{j,t} = \|\overline{\mathbf{q}}_i^j\|_2 \cdot \|\mathbf{k}_{i,t}^j\|_2\),按 token 内排序,每个 token 保留 top-\(T\) 个通道。这个做法挺务实的——既避免了对每个未来 query 单独剪枝(那等于不剪),又保留了 token 级的差异性。
3.3 decode 阶段的恢复函数:被忽略的细节
接下来是最容易被一笔带过、但其实最关键的一步——已经剪掉的通道,在算 attention 时要补什么值。
最朴素的做法是补 0。但补 0 会让 softmax 输出严重失真:因为 attention 分母里少了一项贡献,整个分布都被拉偏。补一个固定的小值(比如 0.01)会好一点,作者在 motivation 里验证过这个 trick 能大幅缓解掉点(80% 剪枝下从掉 55.7 个点降到掉 12.2 个点)。
但 SparK 想做得更精细。它的核心思路是:用 query 把 score 倒推回 key。
具体步骤是这样的:
- 在 prefill 阶段,除了存裁后的 key 和 mask,还存每个 head 上 saliency 分数的分布统计(均值 \(\mu_i\)、标准差 \(\sigma_i\),或者被剪通道的均值 \(\mu_{i,\text{pruned}}\))。
- decode 时,对每个被剪通道 \(j\),先从分布里采一个 score \(\tilde{w}_{i,t}^j\);
- 再用 \(\tilde{\mathbf{k}}_{i,t}^j = \tilde{w}_{i,t}^j / \|\overline{\mathbf{q}}_i^j\|_2\) 倒推一个 key 值;
- 这样 \(\langle \overline{\mathbf{q}}_i^j, \tilde{\mathbf{k}}_{i,t}^j \rangle \approx \tilde{w}_{i,t}^j\),与采样的 score 一致。
为什么不直接用 \(\mu_{\text{key}}\) 给 key 补一个常数?作者在论文里给了一句话解释,挺关键的——"我们要选的是 attention score 小的通道,而不是 key 本身值小的通道",因为 small key 不保证 small score(取决于 query)。所以恢复目标应该锚在 score 上,不是锚在 key 上。
恢复函数 \(\boldsymbol{\mathcal{F}}\) 给了三种选择:
| 分布 | 形式 | 直觉 |
|---|---|---|
| Degenerate | \(\tilde{w} = \mu_{\text{pruned}}\) | 直接填均值,最简单 |
| Gaussian | \(\tilde{w} \sim \mathcal{N}(\mu, \sigma^2)\) | 假设 score 高斯分布 |
| Exponential | \(\tilde{w} \sim \text{Exp}(1/\mu)\) | 重尾,给采样多样性 |
后面消融会看到一个挺反直觉的结果——Degenerate 这个最简单的"填均值"方案表现反而最好。
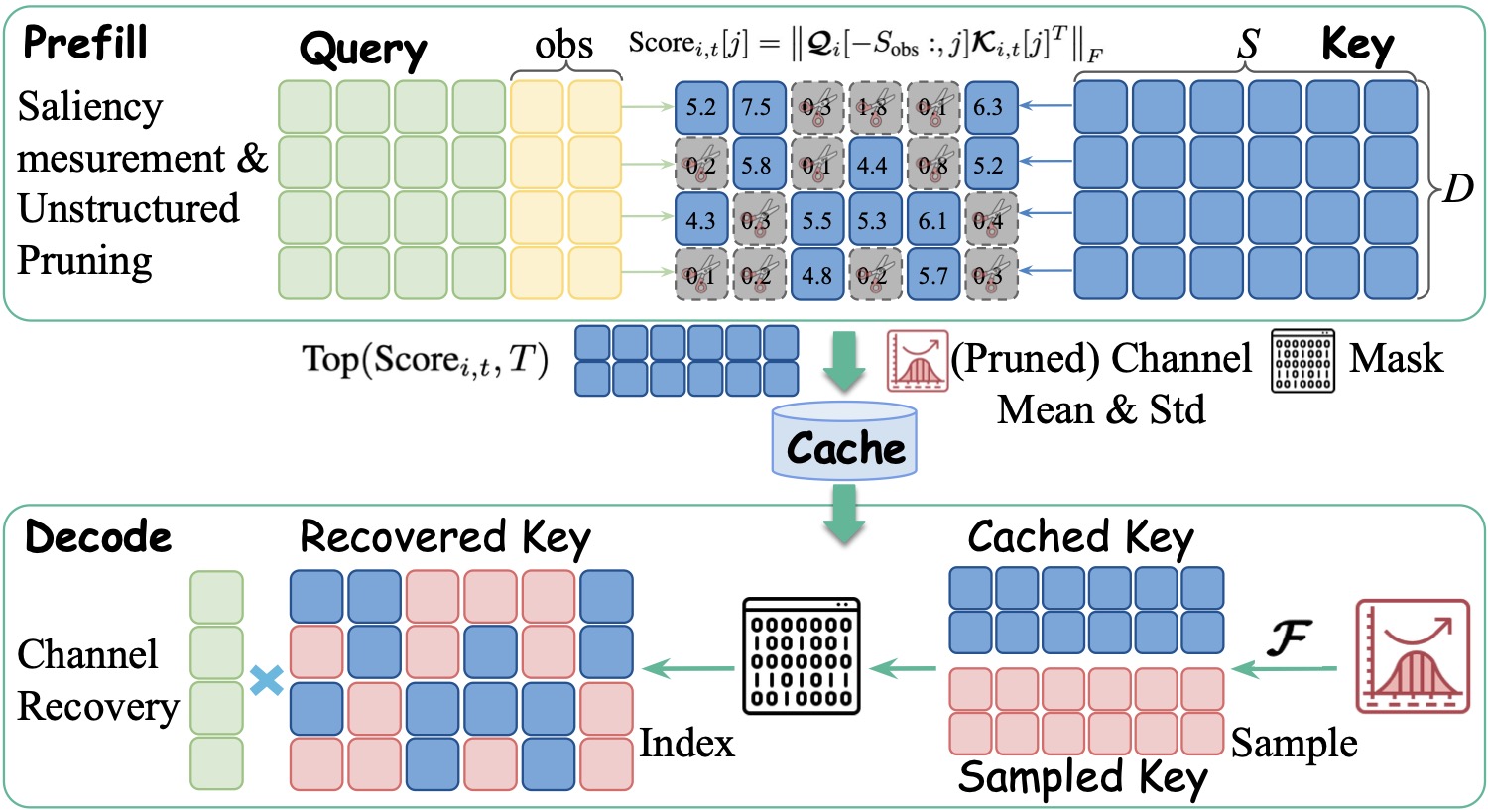
图 3:SparK 在 prefill 阶段计算通道级显著性并做非结构化剪枝,缓存中存裁后的 key、通道 mask 和分布统计;decode 阶段用 \(\boldsymbol{\mathcal{F}}\) 从分布里采样恢复被剪通道,再做标准全 attention。
四、实验:硬数据说话
4.1 LongBench 主实验
作者在 LLaMA3-8B-Instruct 上跑 LongBench,对比基线包括 StreamingLLM、ExpectedAttention、TOVA、SnapKV、PyramidKV,以及把 ThinK 和 SparK 分别叠加到 SnapKV/PyramidKV 上。一些关键数据:
KV-size 128,PyramidKV 作为底座(最严苛设置):
| 方法 | 平均分 | 相对完整 KV 退化 |
|---|---|---|
| Vanilla(完整 KV) | 44.27 | / |
| PyramidKV | 43.80 | 掉 0.47 |
| +ThinK (0.5) | 40.38 | 掉 3.89 |
| +ThinK (0.8) | 12.34 | 掉 31.93 |
| +SparK (0.5) | 43.81 | 掉 0.46 |
| +SparK (0.8) | 41.87 | 掉 2.40 |
注意看 ThinK(0.8) 那一行——12.34 分,比随机猜还惨,模型基本垮了。同样配置下 SparK(0.8) 还能保住 41.87,相对 vanilla 只掉 2.4 个点。这就是恢复机制的价值。如果只看 ThinK 这种结构化方案,你可能会得出"通道剪枝不能压太狠"的结论;但 SparK 告诉你不是通道剪枝不行,是结构化剪枝 + 没有恢复机制不行。
正交叠加效果:单独 PyramidKV 是 43.80,叠 SparK(0.5) 后是 43.81——精度几乎不掉,但 KV 存储再降 50%(key cache 的 50%,整体大约 25%)。叠 SparK(0.8) 时整体 KV 存储再降 40%,精度只掉 1.93 个点。这是一笔挺划算的交易。
4.2 RULER:长上下文真功夫
LongBench 现在大家觉得有点偏简单了,RULER 才是检验长上下文能力的硬骨头。SparK 在 LLaMA3.1-8B、20% KV budget、16K 输入下的结果:
| 方法 | RULER 平均 |
|---|---|
| Vanilla | 93.36 |
| SnapKV | 80.18 |
| +ThinK (0.5) | 76.03 |
| +ThinK (0.8) | 3.03(崩了) |
| +SparK (0.5) | 80.07 |
| +SparK (0.8) | 77.51 |
| PyramidKV | 76.59 |
| +ThinK (0.8) | 2.65(崩了) |
| +SparK (0.8) | 73.99 |
ThinK(0.8) 在 RULER 上的 3.03 是真的让我有点震惊——意味着模型彻底失去长程检索能力。SparK(0.8) 维持在 77 左右,距离 SnapKV 基线掉 3 个点以内。这不是修修补补的提升,是一个能不能用的差别。
4.3 三维 trade-off 分析
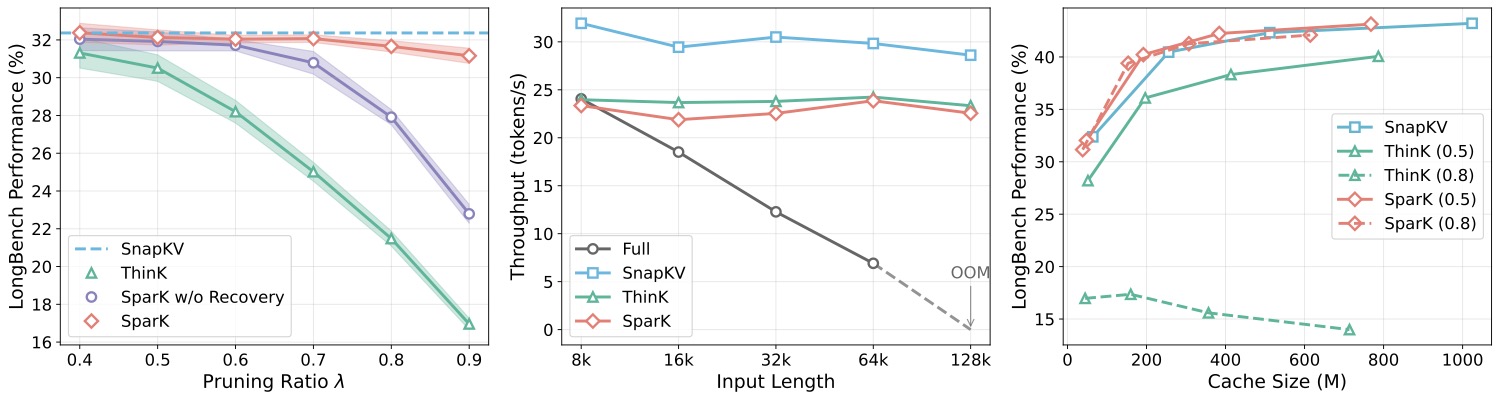
图 4:(a) 不同剪枝率 \(\lambda\) 下的 LongBench 平均精度——SparK 在 \(\lambda=0.8\) 仍稳定,ThinK 跌至 35 个点以下;(b) 不同输入长度下的 decode 吞吐——SparK 一直能跑到 128K,full KV 在 64K 之后 OOM;(c) cache 大小 vs. 精度——SparK 在同等 cache 下精度高于 ThinK,且全面优于 SnapKV。
(b) 那张图我盯了一会儿——按理说 SparK 多了个恢复步骤,吞吐应该比 ThinK 慢,但实际跟 ThinK 几乎重合。原因是恢复就是一次轻量的采样 + 元素级乘法,相比 attention 本身的开销可以忽略。这种"加了功能但不加成本"的设计,才是工程上真正能落地的方案。
4.4 同时剪 K 和 V 通道
作者还顺手把 V cache 也加进剪枝(用 norm-based 启发式)。SnapKV + SparK(0.5+0.5)(即 K 剪 50%、V 剪 50%)相比 SparK(0.5) 单剪 K,平均分从 32.04 → 32.03,几乎不掉。(0.5+0.3) 和 (0.5+0.5) 甚至比单剪 (0.5) 更好——这点意外。作者的解释是 V 通道的冗余确实存在,但剪太狠(0.8+0.8)才会掉点。
五、消融:恢复分布选哪个?变体怎么选?
5.1 三种恢复分布对比
| 分布 | \(\lambda=0.5\) 平均 | \(\lambda=0.8\) 平均 |
|---|---|---|
| Normal | 38.99 | 38.21 |
| Exponential | 39.49 | 38.39 |
| Degenerate | 39.41 | 38.48 |
(数值是 KV-size 128/512/1024/2048 的平均,论文表里更详细)
最简单的"填均值"反而胜出。这其实挺有意思的——加更复杂的分布采样(高斯、指数)会引入噪声,在 cache budget 有限时反而是坏事。退化分布提供了一个稳定的锚点。
我的判断:这条结论对工程落地是好事——不用调分布超参,直接 degenerate 就行。但有个待解的问题论文没展开——如果 prefill 阶段统计样本不够(短输入),degenerate 的 \(\mu\) 估计会失真,这种情况下 Gaussian 可能更鲁棒。作者没在短输入场景下做对比,是个小遗憾。
5.2 自适应变体:SparK-p 和 SparK-g
如果不想手动定剪枝率 \(\lambda\),作者给了两个变体:
- SparK-p:top-\(p\) 阈值,每个 token 选累计显著性达到 99% 的最少通道。平均剪枝率 0.58。
- SparK-g:把通道按重要性分组,每组用不同剪枝率。\(g=4\) 时分配 \((0.25, 0.5, 0.75, 1.0)\),平均剪枝率 0.44。
| 变体 | 2048 平均 | 平均剪枝率 |
|---|---|---|
| SparK (\(\lambda=0.5\)) | 43.13 | 0.50 |
| SparK-p (99%) | 42.95 | 0.58 |
| SparK-g (\(g=5\)) | 42.76 | 0.55 |
| SparK-g(\(g=4\),最优) | 43.27 | 0.44 |
SparK-g(\(g=4\)) 是最优解——更低的平均剪枝率(0.44)和更高的精度(43.27)。这说明分组渐进剪枝可能比一刀切更合理:低重要性的通道大胆剪、高重要性的通道少剪。我个人感觉这条是论文里的一个隐藏宝藏,没被作者放在主结果里大书特书。
六、内存效率
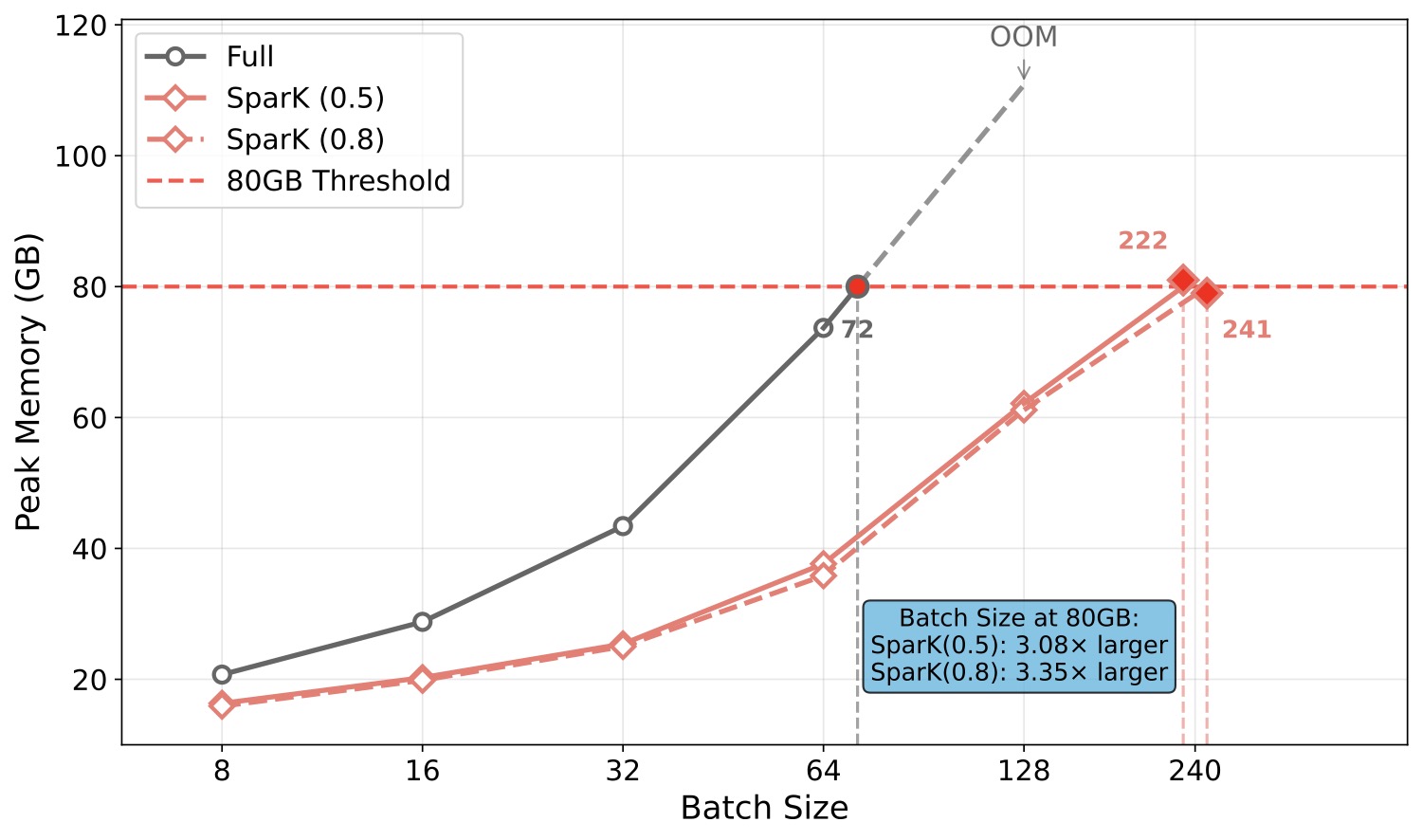
图 5:不同方法在不同输入长度下的峰值显存。SparK 叠加在 SnapKV 之上后能稳定支撑到 128K 输入,full KV 在 64K 就 OOM。
这张图直观说明了 SparK 的工程价值:在固定显存预算下能处理的最长上下文有大幅扩展。具体数字论文给了:在等长序列下,相比 eviction-based 方法,KV 存储再降 30 个点以上。
七、批判性看:哪些地方不是无懈可击
我对这篇论文的整体观感是正面的——问题定义清晰、推导干净、实验扎实。但有几个值得追问的地方:
第一,通道间不相关这条假设。 作者在附录里验了,但 cosine similarity 接近 0 不等于完全无关。在某些 attention head 里(比如做位置编码主导任务的头),通道间可能有结构化关联,这时丢掉交叉项可能引入系统性偏差。论文没有按 head 类型做分层分析,这是一个待补的洞。
第二,观察窗口的代表性。 用最后 \(W\) 个 query 的均值作代理,其实是在赌"未来 query 跟最近 query 分布一致"。这在多轮对话或者主题切换的场景下可能站不住——上一轮 query 关心的通道未必是下一轮关心的通道。SparK 在这种场景下的表现,论文没做。
第三,"30% 存储压缩"的口径。 这个数字是相对 eviction-based 方法说的,意思是在 SnapKV 之上再压缩 30%。但和完整 KV 相比是先 eviction 再 channel pruning 的级联效果。读这种数字时要看清楚 baseline,不然容易过高估计单一技术的贡献。
第四,恢复机制的稳定性。 80% 剪枝下掉 5 个点以内,确实漂亮。但 90% 呢?95% 呢?论文止步在 80%,没做更激进的尝试。直觉上恢复函数的有效性会随剪枝率非线性下降,找到那个崩塌点也有研究价值。
第五,prefill 时算 saliency 也是有开销的。 计算每个 (token, channel) 的 \(\|\mathbf{q}^j\|_2 \cdot \|\mathbf{k}^j\|_2\)、排序、构建 mask、存分布统计——这些操作叠加起来在 prefill 阶段不是 0 开销。论文里没有给完整的 prefill latency breakdown,只在 decode 阶段对吞吐做了对比。这对工程落地评估是个缺失。
这些问题不影响 SparK 的价值,但读论文时不能只盯着"训练 free"、"plug-and-play"、"30%"、"80%"这几个亮眼标签。
八、对工程落地的启发
如果你正在做长上下文推理优化,SparK 给出的几个工程启示我觉得值得记下来:
第一,KV 压缩的几个轴并不是非此即彼,而是可以叠加。 SparK 不是要替换 SnapKV,而是和 SnapKV 一起用。如果你已经用了 SnapKV/PyramidKV,加上 SparK 是一笔几乎纯赚的交易:精度几乎不掉、显存再降一截。
第二,对"压缩后还得能用"的细节要更敏感。 大部分压缩方法只关心"哪些信息能丢",SparK 的精彩之处在于关心"丢掉的信息怎么补回去"。这个视角挺值得借鉴——不止 KV cache,模型量化、token pruning 这些场景里都能想想"恢复机制"能不能加。
第三,不要被结构化的工程便利绑架。 结构化剪枝写起来简单、kernel 好写、显存对齐好做,但精度天花板是实打实的。非结构化剪枝写 kernel 痛苦,但精度收益是数量级差异(80% 下从掉 47 个点变成掉 5 个点)。SparK 也面临这个工程痛点——它需要每个 token 维护自己的通道 mask,写高效 attention kernel 不容易。但既然精度收益这么大,工程上的复杂度是值得啃的。
第四,先把问题写成优化目标,再找贪心解。 这是 SparK 推导链条的范式——从 Frobenius 范数最小化出发,做合理近似(通道无关),坍缩成 top-\(T\) 问题。很多工程 trick 论文是反过来:先有 trick、后凑解释。从优化目标出发能避免事后归因,也更容易找到"该剪什么"的精确表述。
九、收尾
SparK 这篇论文我读完之后的感觉是——它没有发明新概念、没有训练新模型,但它把"通道维度剪枝"这条被绕了很多年的路,认真走了一遍。优化目标的推导干净,恢复机制的设计精巧,实验数据 stand on its own。
放在 2026 年的长上下文推理生态里,SparK 这种"正交叠加、训练 free、工程友好"的方案我觉得会被快速吸收。短期内它会成为 SnapKV/PyramidKV 之上的一个标准插件;长期看,"通道维度也能剪、剪了也能恢复"的认知会重塑下一代 KV 压缩方法的设计空间。
如果你手上有长上下文推理任务、用的是 SnapKV/PyramidKV 这类 token eviction 方案,SparK 是值得直接接入试一下的。代码已经在 https://github.com/AMD-AIG-AIMA/AMD-Spark 开源了,AMD 自家也在推。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我