Reasoning-SAE 论文解读:用稀疏自编码器抓住 DeepSeek-R1 的"思考时刻"
摘要
这篇文章和 P14 那篇 CoT-SAE 同期出现,但走的是更激进的路线——不是研究"CoT prompt 让模型怎么想",而是直接拆 DeepSeek-R1 这种"内置 reasoning"的模型,问一个更尖锐的问题:模型在 chain-of-thought 里的"嗯"、"等等"、"也许"这些词,是不是真对应内部某些专属特征? 作者用 SAE 在 DeepSeek-R1-Llama-8B 的第 19 层做激活分解,提出 ReasonScore 自动指标筛出 200 个推理候选特征,再人工验证收敛到 46 个对应"不确定 / 探索 / 反思"三类思维模式的特征。最让我兴奋的是 model diffing 那部分——证明这些特征只在做完 reasoning fine-tuning 后才出现,单独喂 reasoning 数据或者只用 reasoning 模型都不够。
arXiv 编号:2503.18878v2,作者来自 AIRI(俄罗斯人工智能研究院)+ Skoltech + Sber + HSE 的联合团队,通讯作者 Andrey Galichin、Oleg Y. Rogov。代码:https://github.com/AIRI-Institute/SAE-Reasoning。AAAI 2026 接收。
一、问题背景:DeepSeek-R1 到底在想什么
让我从一个具体观察开始。如果你让 DeepSeek-R1 解一道数学题,它不会直接给答案,而是先生成几千 token 的"思考"。这些思考里反复出现一组特定词汇:maybe(也许)、but(但是)、wait(等等)、alternatively(或者)、however(然而)、actually(实际上)。
这些词在普通模型的输出里也存在,但在 reasoning model 里频率明显高得多。作者用 OpenThoughts-114k 数据集做了一个频率对比:把同一道题的"标准解答"和"DeepSeek-R1 的思考链"放进两个语料库,统计每个词在两边的频率差。下图是 top-40 频率差最大的词。
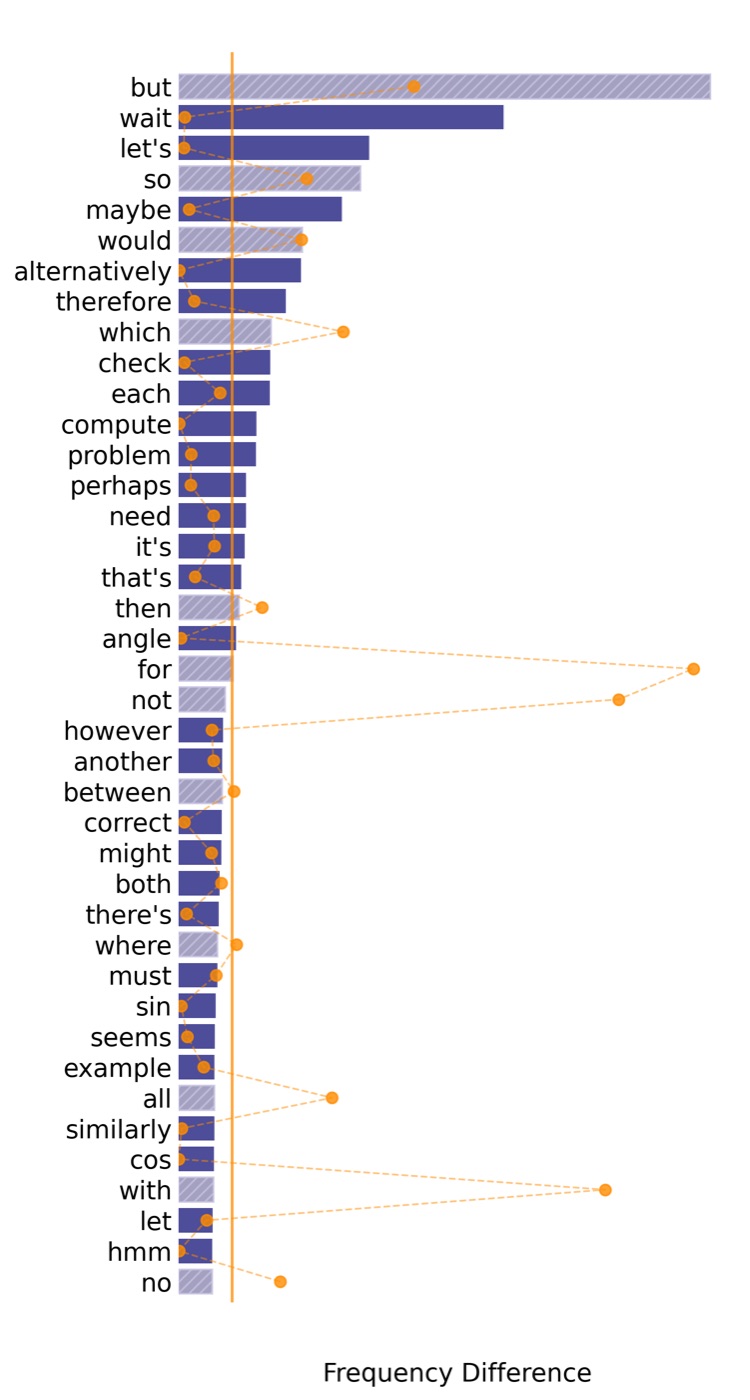
橙色点是这些词在 Google Books Ngram 里的"通用频率"。作者把通用频率高的词(橙线以上)过滤掉——因为这些词在哪都常见,不是 reasoning 特有的。剩下的就是"reasoning 信号词":maybe, but, wait, alternatively, actually, perhaps, however, indeed, hmm, okay 这 10 个词被选成 reasoning vocabulary \(\mathcal{R}\)。
这一步设计我觉得很取巧。它用语言学的"reasoning 信号词"作为锚点,假设这些词出现的位置就是模型内部"reasoning 时刻"的位置。这个假设强不强?我个人觉得偏强但合理——人类思考时也确实在这些转折点上做语言切换,模型 RL 出来的语言习惯应该也会朝这个方向收敛。
接着自然的问题是:SAE 字典里有没有特征专门在这些词的位置激活? 如果有,那就找到了 reasoning 的内部表征。
二、ReasonScore:自动定位推理特征的指标
SAE 的训练在 DeepSeek-R1-Llama-8B 的第 19 层(约 60% 模型深度)做。字典大小 \(m = 65{,}536\)(隐藏维度 4096 的 16 倍)。训练数据 1B tokens,一半来自 LMSys-Chat-1M(base data),一半来自 OpenThoughts-114k(reasoning data)。在 L0 = 86 的稀疏度下能解释 68.5% 的方差,标准 SAE 训练。
关键贡献是 ReasonScore 的设计。我把它的几个版本依次拆开讲。
2.1 朴素版:reasoning 词激活集中度
最朴素的想法是:一个 reasoning 特征应该在 \(\mathcal{R}\) 里的词上激活强、在其他词上激活弱。把数据集分成 \(\mathcal{D}_{\mathcal{R}}\)(reasoning 词的 token 激活)和 \(\mathcal{D}_{\neg \mathcal{R}}\)(其他 token 激活),定义:
\(\mu(i, \mathcal{D})\) 是第 i 个特征在数据集 \(\mathcal{D}\) 上的平均激活值。这个 score 测的是"激活质量在 reasoning 词上的相对集中度"。
2.2 上下文窗口版:捕捉过渡时刻
朴素版有个问题:reasoning 特征不一定只在那个词本身激活,可能在词的前后几个 token 都激活,因为模型是"在思考过程中"逐渐转换状态。作者把激活集合扩展为带上下文窗口的版本——每个 reasoning 词周围取 [-2, +3] 的 token 窗口。新数据集 \(\mathcal{D}_{\mathcal{R}}^{\text{W}}\) 就是所有这些窗口里的激活并集。
2.3 加熵惩罚:避免特征只覆盖一小部分词汇
还有一个隐患:某个特征可能只在 wait 这一个词上激活强烈,对其他 9 个 reasoning 词无反应。这种特征显然不算"通用 reasoning 特征",应该被过滤掉。
作者引入 entropy penalty。对第 i 个特征,先算它在每个 reasoning 词 \(r_j\) 上的激活分布 \(p_i(r_j)\),然后归一化的熵:
\(\mathrm{H}_i \in [0, 1]\),1 表示在 10 个 reasoning 词上均匀激活。最终 ReasonScore:
\(\alpha\) 控制 specificity / generalization tradeoff。\(\alpha \to 0\) 时熵无影响(鼓励 specific),\(\alpha\) 大时熵权重大(鼓励 general)。论文设 \(\alpha = 0.7\)。
这个 metric 的设计我打 8 分。"激活集中度 + 上下文扩展 + 熵惩罚"三个组件每一个都对应一个明确的 failure mode,组合起来很完整。如果让我自己设计,我可能会再加一项"对照模型激活差异"——让 reasoning model 和 base model 在同一批 token 上激活差异大的特征更优先。但作者把这一步放到了 model diffing 里独立做,思路也清晰。
最后取 ReasonScore 在 q=0.997 分位以上的特征,得到 \(|\mathcal{F}_{\mathcal{R}}| = 200\) 个候选。
三、人工验证:46 个特征对应三类推理模式
200 个候选里有多少是真"reasoning 特征"?作者老老实实做了人工解释。每个特征用 OpenThoughts-114k 上 top-activating examples 构造一个 interface,看激活模式、logit 影响、统计规律,按三个标准筛选:
- 特征激活时,相关概念在上下文中可靠出现
- 特征在多种 reasoning 任务中都触发
- 特征对 logit 的影响和 reasoning 过程一致
经过人工筛选,46 个特征通过验证(标记为 \(\mathcal{F}_{\mathcal{R}}^{\text{manual}}\)),可以归到三类行为模式:
- Uncertainty:模型表达犹豫、怀疑、暂时性思考的时刻(典型特征 #61104)
- Exploration:模型考虑多种可能、连接想法、检查不同视角(典型 #25953)
- Reflection:模型回顾并重新评估之前步骤(典型 #4395、#46691)
下图是这些特征的 manual interface 示例,可以看到激活模式确实对应这三种语义场景。

为了进一步验证,作者把这 46 个特征用自动化 pipeline 也跑了一遍——steering 不同强度(\(\gamma \in [-4, 4]\))下的输出喂给 GPT-4o,让 GPT 给出语义功能描述,再聚类。结果如下图。
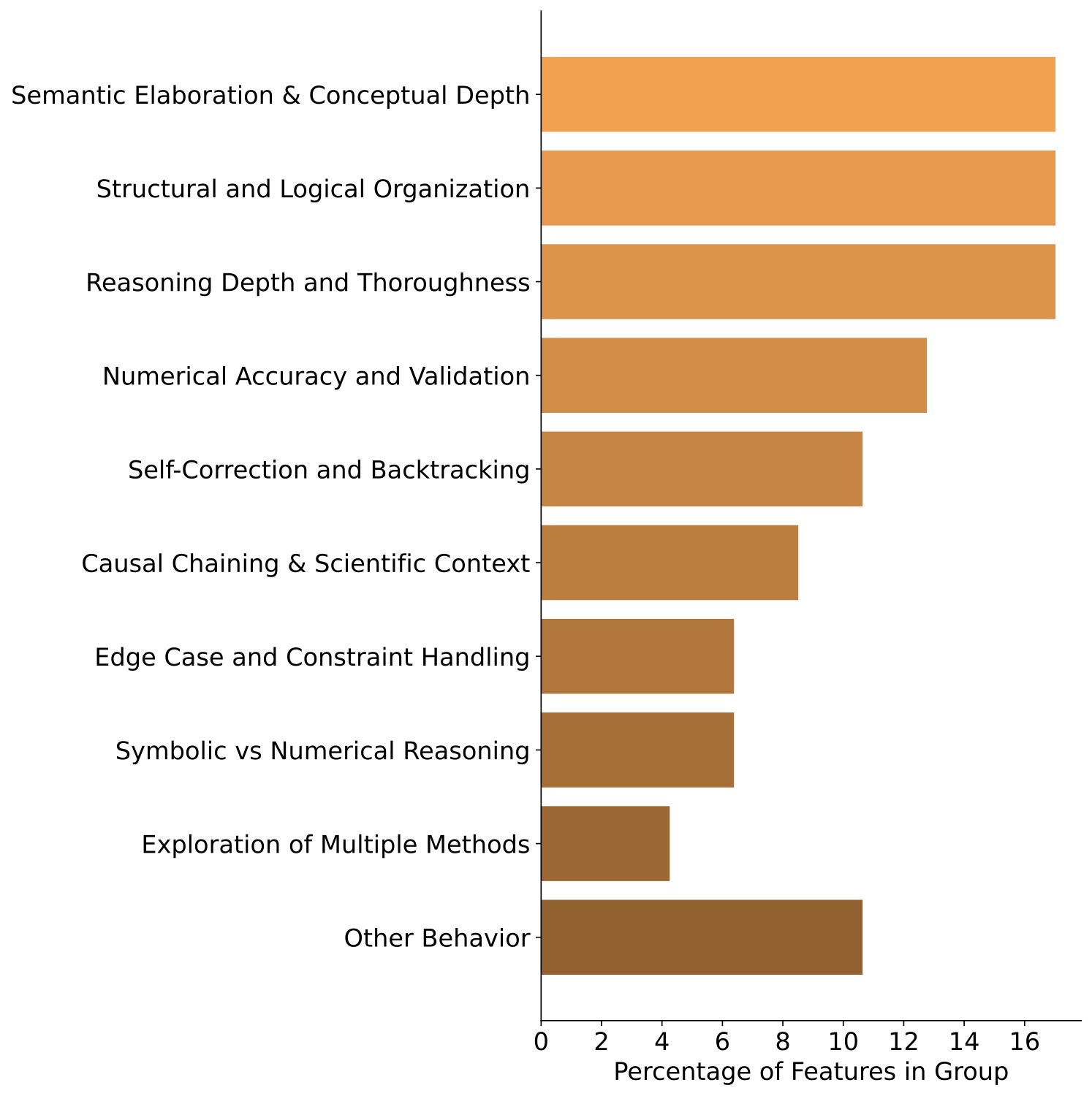
聚类后的功能组和人工分类高度一致——uncertainty / exploration / reflection 三组是主体,只有 5 个特征落到"Other Behavior"混合类。
这种"人工 + 自动"双重解释是 SAE 论文里比较扎实的做法。光人工容易主观,光自动容易被 GPT 的偏好带偏。两边一致才能下结论。
四、Steering 实验:放大特征真的能改变行为
光找到特征还不够,作者要证明这些特征对 reasoning 行为有因果影响。用的是 feature steering——在生成时把第 i 个特征的解码方向直接加到激活上:
\(\gamma\) 是 steering 强度,\(f_i^{\max}\) 是特征在 OpenThoughts-114k 上的最大激活值。预实验确定 \(\gamma = 2\) 是最佳——既能改变行为又不破坏整体能力。
从 46 个 manual 特征里挑 9 个最有潜力(在 MATH-500 上 pass@1 提升 ≥ 0.5%)+ 1 个特殊特征 #3942(响应明显变短但性能不掉)。在 AIME 2024、MATH-500、GPQA Diamond 三个 benchmark 上跑 maj@4。
| Feature | AIME 2024 maj@4 | MATH-500 maj@4 | GPQA Diamond maj@4 | 平均 token 数 |
|---|---|---|---|---|
| No steering | 53.3 | 93.2 | 50.0 | 12.4 / 3.9 / 7.9 K |
| #3942 | 56.7 | 93.0 | 46.5 | 11.1 / 3.4 / 6.7 K(最短) |
| #4395 | 56.7 | 95.4 | 52.0 | 14.7 / 4.1 / 8.5 K |
| #16441 | 60.0 | 95.0 | 54.0 | 14.0 / 4.1 / 8.3 K |
| #16778 | 56.7 | 94.0 | 51.0 | 14.1 / 4.7 / 9.0 K(最长) |
| #61104 | 66.7 | 95.0 | 53.0 | 12.0 / 3.6 / 7.5 K |
读这张表的几个 take:
第一,没有一个特征单独把所有 benchmark 都拉到最高,但 7/10 个特征在 3 个 benchmark 上都有提升。这是分布式特征的典型特征——单点干预只能调一个面。
第二,#61104(uncertainty)在 AIME 上从 53.3 涨到 66.7,提升 13.4 个百分点。这是一个相当夸张的数字。它说明放大"模型对自己输出的不确定性"在难题上反而是好事——模型更倾向于多检查、多反思。
第三,#16778(reasoning trace 最长)在三个 benchmark 上 token 数分别提升 13.7、20.5、13.9 个百分点。"思考更长" → "答案更准"这条因果链被直接验证。
第四,#3942 让响应变短但性能基本不掉,token 数减 7.7%。这个特征的存在挺有意思——它可能对应的是"自信地下结论、不啰嗦"这种行为模式。
这套 steering 实验是这篇文章最有说服力的部分。如果只是"找到一些和 reasoning 词相关的特征",那只能算相关性。但放大这些特征确实让模型在 AIME 这种最难的数学题上涨了 13 个百分点,因果链就站住了。
论文给了一个具体生成例子,问"把直角坐标 (0, 3) 转成极坐标"。无 steering 的版本输出 1500 token 的 reasoning,最后给答案 \((3, \pi/2)\)。Steering 后的版本输出 2000 token,多了一段反思:"I think I've covered all the bases here. Calculated r, determined θ, checked using different methods, and even considered the quadrant placement." 然后才给答案。论文标题"I Have Covered All the Bases Here"就来自这个具体例子。
五、Model Diffing:这些特征是不是 reasoning 微调专属
到这里已经证明了:1)找到了和 reasoning 词强相关的特征;2)这些特征在三类语义模式上可解释;3)放大它们能改变行为。但还有一个最关键的反事实问题:这些特征是预训练就有的,还是 reasoning fine-tuning 才长出来的?
作者用 stage-wise model diffing 回答。设计四个阶段:
- Stage S:base model(Llama-3.1-8B 原版)+ base data(SlimPajama)→ 训一个 SAE,作起点
- Stage D:base model + reasoning data(OpenThoughts-114k)→ 把 SAE 微调到 reasoning 数据上
- Stage M:reasoning model(DeepSeek-R1-Llama-8B)+ base data → 把 SAE 微调到 reasoning model 上
- Stage F:reasoning model + reasoning data → 完全 reasoning 设定
通过两条路径走到 F:S → D → F,以及 S → M → F。每个阶段把当前 SAE 的特征字典和原始 \(\mathcal{F}_{\mathcal{R}}\) 做余弦相似度匹配(阈值 0.7),算 reasoning 特征"出现率"。
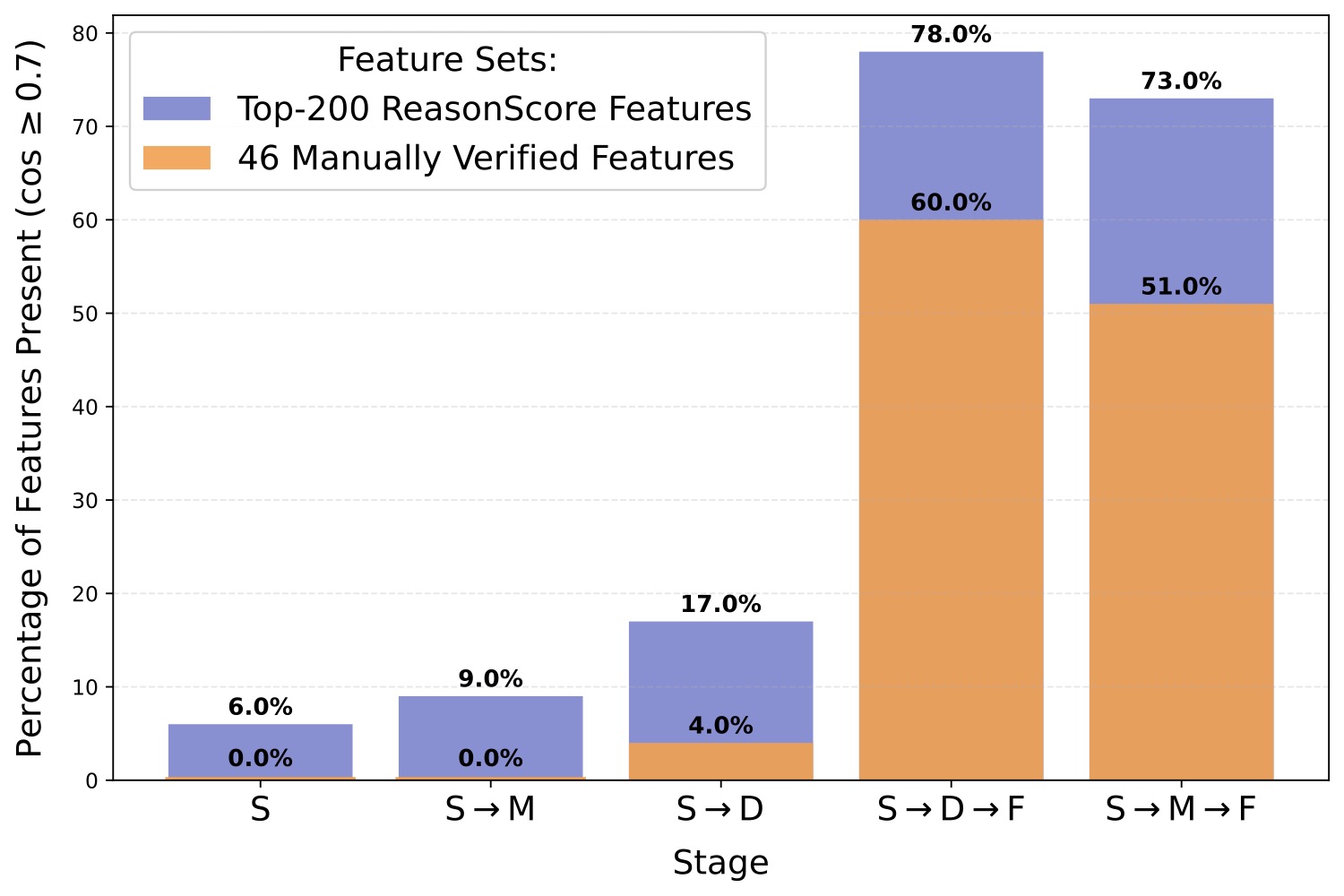
结果非常清楚:
- Stage S(base model + base data):0% 验证特征存在
- Stage S→D(base model + reasoning data):4% 验证特征出现
- Stage S→M(reasoning model + base data):0% 验证特征出现
- Stage S→D/M→F(reasoning model + reasoning data 全配齐):60% / 51% 验证特征出现
这一步的结论我读了三遍才意识到它的力量。不是只换数据有用,也不是只换模型有用,是两个一起换才能让 reasoning 特征长出来。这意味着 reasoning 能力既不是数据简单"传染",也不是模型架构本身的属性,而是 RL fine-tuning 这个特定过程产生的内部组织。
为什么是 60% 而不是 100%?作者诚实地解释:cosine similarity 阈值 0.7 是经验值,可能漏掉一些方向被旋转过的同质特征。另外 SAE 是从 Stage S 微调过来的,不是从头训练,可能丢失一部分新特征。这些都是已知 limitation。
六、和 P14 CoT-SAE 那篇的对比
正好我刚解读完 P14 那篇 CoT-SAE,把两篇放一起对比是有意思的。
| 维度 | P14 CoT-SAE | P15 Reasoning-SAE(本文) |
|---|---|---|
| 研究对象 | CoT prompting 的内部机制 | DeepSeek-R1 这种内置 reasoning 模型的内部机制 |
| 模型规模 | Pythia-70M / 2.8B | DeepSeek-R1-Llama-8B |
| 数据集 | GSM8K | AIME 2024 / MATH-500 / GPQA Diamond |
| 特征筛选 | 按 \(\lvert h_{\text{CoT}} - h_{\text{NoCoT}} \rvert\) | ReasonScore(reasoning 词为锚) |
| 因果验证 | activation patching | feature steering |
| 关键发现 | 规模阈值(小模型上 CoT 无效) | reasoning 特征只在 RL fine-tuning 后涌现 |
| 性能提升 | log-prob +3.2(patching) | AIME 准确率 +13.4%、MATH-500 token +20.5% |
两篇互补得很。P14 关心的是"prompt 让模型发生什么",P15 关心的是"训练让模型发生什么"。P14 在小模型上发现规模阈值,P15 直接用 8B 大模型确认 reasoning 特征的存在。如果把 P14 的发现往前推:CoT prompt 能不能也让小模型长出 reasoning 特征?P15 的 model diffing 给了答案——光靠 prompt 不够,需要正经的 RL fine-tuning。
把这两篇连起来读,CoT 这件事的全景图就清楚了。CoT 在大模型上让内部计算更稀疏更模块化(P14 视角),而 reasoning fine-tuning 进一步在大模型里催生出专门的 uncertainty / exploration / reflection 特征(P15 视角)。两者是同一条线索的不同切面。
七、几个我会追问的点
读完后我留下几个未解的问题。
第一,10 个 reasoning 词的选择有没有偏见? 作者说从频率差异 + 语言学文献 + 人工分析三步选出 10 个。但这本身是一个有 bias 的过程。如果换一组语言学家,选出的词可能不同;进而 ReasonScore 选出的特征也可能不同。论文 limitation 里承认了"可能没覆盖所有 reasoning 模式",但没给出 vocabulary sensitivity analysis。
第二,第 19 层是不是最佳层? 作者只在 layer 19(约 60% 深度)做。论文 appendix 提到了其他层的实验,但主结果都基于这一层。reasoning 特征是不是只集中在中段?早期层和后期层是不是有不同的 reasoning 特征?这是个很自然的下一步。
第三,能否把这套方法扩到非数学 reasoning? GPQA Diamond 是物理生物题,已经算稍微泛化。但代码 reasoning、常识 reasoning、agent 决策 reasoning 用的"语言信号词"可能完全不同。reasoning vocabulary 是任务相关还是通用的?这点也没回答。
第四,feature steering 有没有破坏其他能力? 论文报了 reasoning benchmark 的提升,但没报通用 capability 的回归(比如 MMLU、HellaSwag)。如果 steering 让模型在 AIME 涨了 13 个点,但在常识题上掉了 5 个点,整体收益要重新算。这是一个很容易补的 ablation,论文没做让人略感意外。
这四个问题里第一是最值得做的 follow-up(vocabulary 是不是 reasoning 特征发现的瓶颈),第三是把这套框架推广到更广领域的关键。第二和第四是论文严谨性可以再提的地方。
八、对从业者的启示
如果我是研究 reasoning model interpretability 的同行,从这篇文章我会拿走几条具体经验。
经验一:用"语言表面信号"作为锚点定位内部特征是可行的。reasoning 词、emotion 词、persona 词都可以套进 ReasonScore 这个框架。这是一种比"训分类器找特征"更轻量的方法。
经验二:SAE 训练成本可以摊销。一个在 LMSys + OpenThoughts 上训好的 SAE 字典可以用来研究多种现象(不只 reasoning),只要换 vocabulary 和 ReasonScore 公式就能复用。
经验三:steering 是低门槛因果实验。不需要重训模型,不需要 LoRA,只要在生成时改激活就能验证特征的因果作用。这个工具应该被更广泛使用。
经验四:model diffing 这种"分阶段对比"实验设计应该成为 reasoning 研究的标配。不做这一步,"特征是预训练就有的还是 fine-tuning 长出来的"这种关键问题就回答不了。
九、写在最后:把"思考"看见
我读完这篇文章最强烈的感受是:第一次有研究把 LLM 的"思考"看见了。
之前所有关于 CoT、reasoning model 的讨论都停留在"输出更长"、"准确率更高"、"看起来在思考"这种现象层面。这篇文章实打实地指出 DeepSeek-R1 的第 19 层、字典里第 4395、61104、25953 等具体特征,分别对应 reflection、uncertainty、exploration 这三种思考模式。这些特征不是预训练就有的,是 RL 阶段长出来的,且只有 8B 这种规模才足够支持它们出现。
这种"具体到 feature index"的可解释性,让 reasoning model 从一个黑箱产物变成了可以拆开、调整、增强的对象。如果未来的工作能找到更多这样的特征,并设计自动 steering pipeline,那么"按需调用 reasoning 强度"就成了一个可工程化的能力——你可以在 latency 敏感场景下抑制 reasoning 特征,在 hard problem 场景下放大它们。
我个人会把这篇推荐给三类读者。第一类是做 reasoning model 训练的工程师——这套方法可以诊断你 RL 阶段是不是真的长出了 reasoning 特征。第二类是 mechanistic interpretability 研究者——这是 SAE 应用到 reasoning 这个高价值场景的早期工作之一,框架值得借鉴。第三类是关心"AI safety"的人——理解 reasoning 特征是哪些、它们怎么涌现,对于检测和控制模型的"自我反思"行为是关键基础。AAAI 2026 录这篇是合适的。