RALM 真的"知道自己不知道"吗?AAAI 2026 揭开检索增强模型的过度拒答陷阱
一段先讲清楚
做 RAG 的人多少都碰到过这个怪现象——你给模型挂上知识库,本来想着能多答对一些题,结果它反而开始装糊涂:明明这个事实它自己脑子里就有,喂进去几篇不相关的检索片段后,它居然回了一句"抱歉,我无法回答这个问题"。
这就是这篇 AAAI 2026 论文盯上的事。来自北京理工大学等机构的作者们系统地评估了 RALM(Retrieval Augmented Language Model,检索增强语言模型)的拒答行为,得到了一个挺刺耳的结论:当前的 RALM 普遍存在严重的过度拒答问题,而且更糟糕的是——拒答能力变好不等于校准变好,更不等于准确率变好。这三个东西在主流 refusal 后训练方法上是会打架的。作者最后给出一个简单但很能打的方案:把"基于知识状态的不确定性弃答"和"refusal-aware 微调"拼起来用,在 0p10n 这种全是噪声的硬场景下把 OAcc 从 0.437 抬到了 0.729,over-refusal 从 0.770 压到 0.176。值不值得读?我觉得做检索增强的人都该认真看一遍。
论文信息
- 标题:Do Retrieval Augmented Language Models Know When They Don't Know?
- 作者:Youchao Zhou, Heyan Huang, Yicheng Liu, Rui Dai, Xinglin Wang, Xingchen Zhang, Shumin Shi, Yang Deng
- arXiv:2509.01476v3
- 会议:AAAI 2026
- 代码/数据:基于 RGB、CRUD、NQ 三个公开数据集
为什么这个问题值得追
先把背景顺一遍。当前缓解大模型幻觉,工业界基本上是两条路线在跑:
第一条是 RAG,给模型挂外挂知识库,让它在生成时引用真实文档。第二条是 refusal post-training,专门训模型学会在不确定的时候说"我不知道",而不是硬编造。R-tuning、Dynamic R-tuning 这一类工作走的就是后一条路。
听起来这两条路是互补的——一个补外部知识、一个补自我认知,组合起来岂不美哉?
但作者敏锐地抓到了一个被忽视的交叉地带。把 refusal-trained 模型直接挂到 RAG 系统里,它的拒答行为还靠谱吗?检索回来的文档质量是参差不齐的,有的相关有的不相关,模型面对噪声文档时的不确定性怎么变?会不会被噪声"带偏",把本来答得对的题也拒掉?
这个问题听起来像个边角料,但它其实戳中了 RAG 系统落地的一个真实痛点。说实话我之前在搭 RAG 的时候就碰到过类似的情况——召回质量稍微一波动,系统的拒答率就跟着抖,用户体验非常不稳定。当时我们的归因是"召回的问题",但作者这篇论文给了一个更深层的解释:模型本身的知识边界感知能力在外部噪声面前是脆弱的。
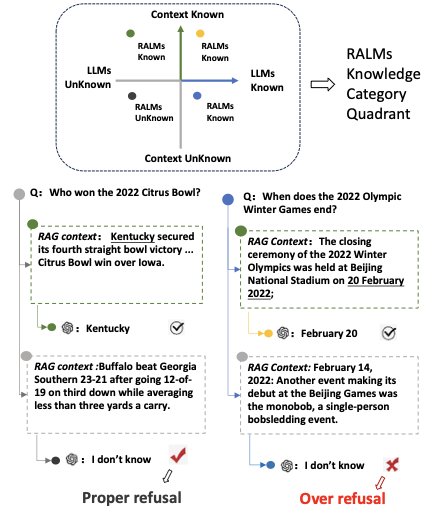
图1:RALM 知识边界四象限示意——左边是 proper refusal(不知道就说不知道),右边是 over-refusal(明明知道却装不知道)。论文整篇都在围绕这个图展开。
核心贡献概览
把作者的工作浓缩一下,主要三件事:
第一件事:第一次系统性地评估了 RALM 的拒答行为与校准质量。把不确定性估计 UE 与拒答行为放在一个统一框架下分析,引入了"知识状态四象限"作为切片维度。
第二件事:识别并刻画了 over-refusal 这个新现象。在纯负样本上下文(0p10n)的场景下,RALM 即使对自己原本能答对的"highlyknown"问题也会大量拒答。R-tuning 这种主流 refusal 后训练方法非但没缓解、反而加剧了这个问题。
第三件事:提出一个简单到有点出乎意料但很能打的方案——基于双阈值的两阶段拒答机制。一个阈值看 LLM 自身的不确定性 \(U_{\text{LLM}}\),另一个阈值看 RALM 引入上下文后的不确定性变化 \(\Delta U=U_{\text{RALM}} - U_{\text{LLM}}\),先判断知识状态再决定要不要拒答。
下面挨个展开。
概念铺垫:什么叫 over-refusal、什么叫四象限知识状态
直接看公式之前,先把两个核心概念用人话讲清楚。
proper refusal vs over-refusal
作者沿用了 [Feng et al. 2024 ACL Don't Hallucinate, Abstain] 的定义,把所有问题划成两类:should answer(模型本来就能答对的)和 should refuse(模型答不对的)。然后根据模型实际响应又分三种:答对、拒答、答错。
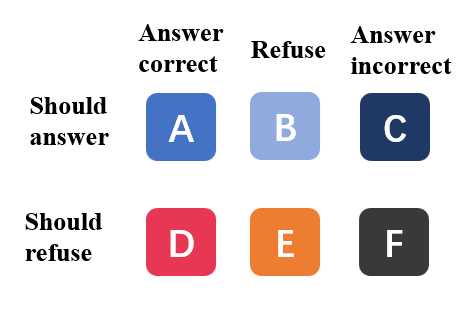
图2:拒答行为的混淆矩阵。over-refusal rate = B/(A+B+C),专指那些"本来能答对却被拒掉"的比例;proper refusal rate = E/(D+E+F),是真正应该拒的题里被拒掉的比例。
工程直觉是这样的:理想状态下,模型应该精准地把 should-refuse 的题拒掉、把 should-answer 的题答出来。over-refusal 就是把好牌打烂——明明知识在那儿,却被外部噪声搞得自我怀疑。
四象限知识状态
把"模型自己是否知道"和"上下文是否包含正确信息"这两个维度交叉一下,就得到四个象限。作者进一步把模型自身的知识细分成 highlyknown(任何 prompt 下都能答对)、maybeknown(贪心解码能答对但温度采样会偏)、weaklyknown(只在某些采样下能答对)、unknown(怎么采样都答不对)四类。
前两类被定义为 should-answer,后两类被定义为 should-refuse。这个细分非常关键——它让作者可以分层分析,不同知识层级的题在不同上下文设置下的行为差异。
实验设置先快速过一下
| 维度 | 选型 |
|---|---|
| 模型 | Qwen-2.5-7B(中文)+ LLaMA-3.1-8B(英文) |
| 数据集 | RGB(中英)、CRUD(中文)、NQ(英文) |
| 不确定性方法 UE | 三类共 9 种:Verbalization、Consistency、Similarity Matrix |
| 上下文设置 | no context、0p10n、1p9n、5p5n、1p19n |
| 采样数 | 16 次,温度 0.5 |
注意这个 ApBn 的命名,A 个正向相关文档 + B 个无关文档,是论文的核心实验切片。0p10n 表示全是噪声、1p9n 表示只有 1 个正向相关文档藏在 9 个无关文档里,5p5n 是正负各半。
为什么要做这种切片?因为真实 RAG 系统检索回来的文档质量本来就分布广、负样本一大堆,作者想看的就是模型在不同质量分布下的稳健性。
RQ1:RALM 的校准在不同知识状态下到底什么样
先选一个最稳的 UE 方法
不同 UE 方法的校准误差差异很大,作者在 RGB 中英文上都跑了一圈,结论是 consistency-based 方法整体最稳,所以后续分析都用这一类。这个结论跟 [Su et al. 2025 ACL] 在 adaptive RAG 上的发现是一致的。
我自己在做不确定性估计的时候也试过 verbalized 方法(直接让模型口头给个置信度),效果非常不稳定——模型经常给出 "0.95 confidence" 然后答错,这跟论文里的观察对得上。一致性方法把多次采样的答案聚合起来看分布,相当于把"自我陈述置信度"这种不靠谱的信号绕过去了。
关键发现 1:正向上下文是校准的"开关"
把 0p10n(全噪声)和 1p9n(夹一个正向)这两个场景放一起对比,作者发现了一个挺干净的现象:
- 加 1 个正向就足够好:1p9n 下 Brier Score 从 0p10n 的 0.162(FSD 方法在 RGB-en)骤降到 0.041,校准质量飞跃式提升。
- 再加更多正向收益不明显:5p5n、1p19n 跟 1p9n 的差距不大。
- 加更多负样本也没把校准搞得更糟:1p19n 跟 1p9n 接近,说明只要有 1 个正向锚点,模型就能稳得住。
这个发现的工程意义其实挺直接的——不要纠结 top-k 该是 5 还是 10,关键看能不能把那 1 个真正相关的文档稳稳地召回到上下文里。
关键发现 2:负样本上下文让模型集体过自信,但同时拒答率飙升
这是论文最反直觉的一段。直觉上你会想,模型如果遇到一堆噪声,应该是"不确定"才对——置信度该降、不该升。
但实际数据是反的。看 0p10n 场景下的可靠性图:
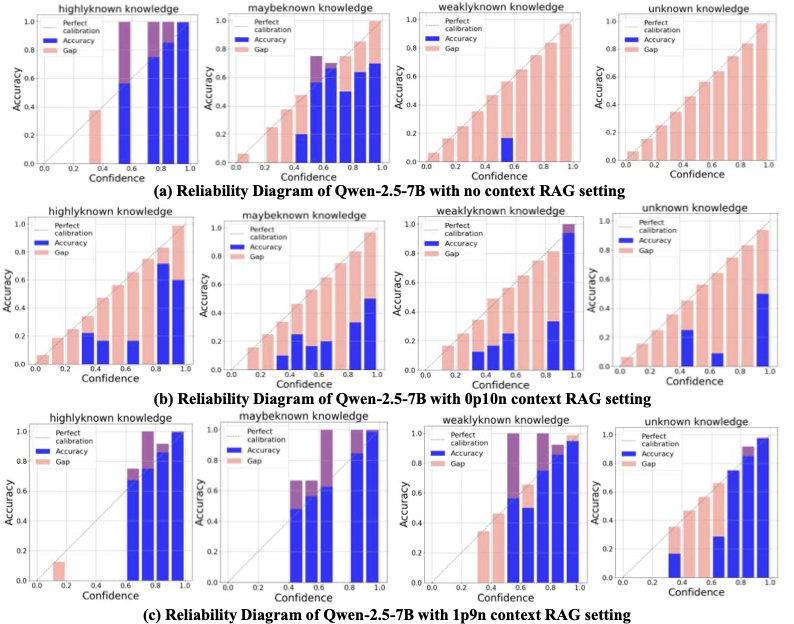
图3:分知识状态的可靠性图。第一行(无上下文)highlyknown 上模型基本校准良好,weaklyknown/unknown 上模型过自信。第二行(0p10n 全噪声)所有知识状态下都出现严重过自信——粉色 Gap 全面变大。第三行(1p9n)模型回到欠自信状态,校准重新接近对角线。
也就是说,纯噪声上下文同时让模型变得更过自信、又让它更倾向拒答。这听起来矛盾,但其实合得上——置信度的分布变得更分散(很多答案都拿到了高置信、但精度跌了),同时模型对自己输出的整体可信度感知变差,于是触发了更多拒答。over-confident 和 over-refusal 在 0p10n 下是同时发生的。
关键发现 3:over-refusal 普遍且严重
把视角切到精度和拒答率:
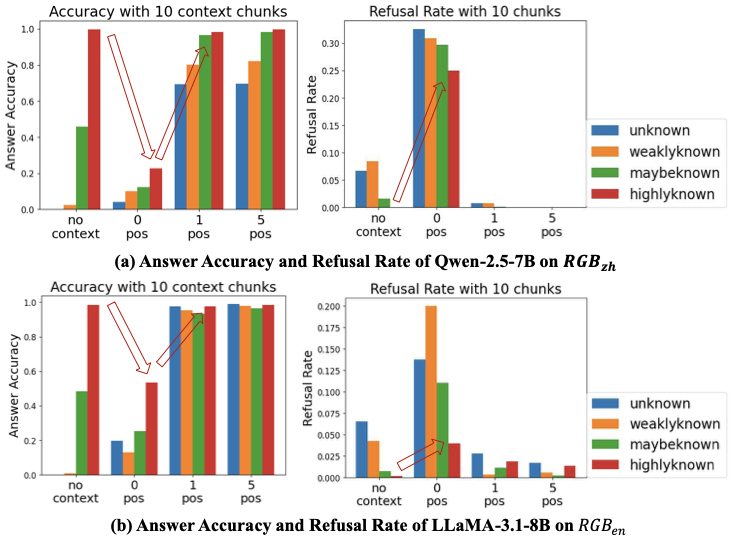
图4:Qwen-2.5-7B(中文 RGB)和 LLaMA-3.1-8B(英文 RGB)的精度和拒答率随上下文变化。左列上行:highlyknown(红柱)从 no context 的近 1.0 跌到 0 pos 下的 0.2 多,肉眼可见的精度悬崖。右列上行:highlyknown 拒答率从近 0 飙到 0.25 左右——明明能答对的题被拒掉了。
红色箭头标的就是 over-refusal 现象的视觉证据:highlyknown 这类"模型应该轻松答对"的题,在 0p10n 上拒答率显著上升、精度显著下降。Qwen 上更明显,LLaMA 上稍弱但同样存在。
我看到这个数据的第一反应是——这个 baseline 的 0p10n 设置是不是太人为了?真实 RAG 不至于完全没有相关文档吧?但仔细想想,召回完全失败这件事在生产环境是一个高频事件,尤其是冷启动场景、长尾 query、多语言场景下。0p10n 不是 corner case,是经常发生的 case。
RQ2:refusal 后训练能不能修好 over-refusal?答案出乎意料
这一节是全文我觉得最有信息量的部分。作者把两类主流的 refusal 后训练方法放在一起对比:
- R-tuning:在训练数据里把模型答错的题改成"I don't know",让模型学会拒答。这是 NAACL 2024 的方法,工业界用得挺多。
- In-Context Fine-Tuning(ICFT):在训练时把检索上下文一起塞进 prompt 里再做 SFT。作者把它扩展成四个变体:
- ICFT(n):只用负样本上下文,根据模型内部知识决定答案是 ground truth 还是拒答。
- ICFT(p):只用正样本上下文,所有答案都是 ground truth。
- ICFT(pn):正负都用,所有答案都是 ground truth。
- ICFT(w):把 ICFT(n) 和 ICFT(pn) 的训练样本都用上。
主表数据:R-tuning 反而把 over-refusal 搞得更严重
把 RQ1 那张大表压缩成关键对比:
| 测试场景 | 方法 | OAcc ↑ | OR ↓(过度拒答率) | RF1 ↑ |
|---|---|---|---|---|
| no context | Vanilla | 0.427 | 0.000 | 0.085 |
| no context | R-tuning | 0.457 | 0.105 | 0.335 |
| no context | ICFT(n) | 0.487 | 0.039 | 0.245 |
| 0p10n | Vanilla | 0.290 | 0.355 | 0.341 |
| 0p10n | R-tuning | 0.457 | 0.678 | 0.579 |
| 0p10n | ICFT(n) | 0.620 | 0.270 | 0.601 |
| 1p9n | Vanilla | 0.863 | 0.000 | 0.000 |
| 1p9n | R-tuning | 0.830 | 0.066 | 0.301 |
| 1p9n | ICFT(n) | 0.787 | 0.171 | 0.573 |
注意看 0p10n 这一行——R-tuning 的 OR(over-refusal rate)冲到 0.678,意思是接近七成原本能答对的题被它拒掉了。这个数高得离谱。R-tuning 的初衷是让模型更有自知之明、该拒就拒,但实际效果是把模型训得"草木皆兵"——遇到点噪声就直接放弃作答。
ICFT(n) 在 0p10n 下表现明显更好,OAcc 从 R-tuning 的 0.457 抬到 0.620,OR 从 0.678 压到 0.270。这个差异挺大的。
为什么会这样?作者给的解释是 R-tuning 训练分布和测试分布对不上。R-tuning 训练时不带检索上下文,模型学到的是"我自己不知道就拒答"。但部署到 RAG 里之后,模型遇到的是带噪声上下文的输入,这种分布移位让模型把"上下文有问题"误判成"我自己不知道",结果就是过度拒答。ICFT 训练时本身就在带噪声的上下文里学,分布对得上,所以拒答行为更稳。
关键发现:拒答好 ≠ 校准好 ≠ 准确率好
这是论文最值钱的一个观察。作者用 OaBs(Overall Brier Score,把拒答也纳入校准计算)这个指标度量整体校准质量,发现:
- ICFT(p) 和 ICFT(pn) 校准最好:在 0p10n 下 OaBs 分别是 0.204 和 0.189,明显优于 ICFT(n)(0.216)和 R-tuning(0.408)。
- 但它们的拒答性能(RF1)很差:ICFT(p) 在 0p10n 下 RF1 是 0,ICFT(pn) 也是 0——它们几乎不拒答。
- 拒答最强的 ICFT(n),校准没有最好:RF1 在 0p10n 下 0.601 是最高,但 OaBs 0.216 只是中等。
这就是把"拒答能力"和"校准质量"做了一次正交分解。一个模型可以拒答得很激进(高 RF1),但代价是把很多本该答的题也拒了(差校准);也可以校准很好(低 OaBs)但根本就不学拒答。这两件事不是同一回事,主流的 refusal 微调把它们混为一谈了。
再追一层:去噪能力和上下文利用率
作者用两个新指标来诊断 RIFT 模型的内部行为:
| 方法 | DR (no context) | DR (0p10n) | CU (10p0n) | CU (1p9n) |
|---|---|---|---|---|
| Vanilla | 0.579 | 0.191 | 0.759 | 0.738 |
| R-tuning | 0.444 | 0.138 | 0.750 | 0.682 |
| ICFT(n) | 0.734 | 0.632 | 0.750 | 0.591 |
| ICFT(p) | 0.750 | 0.658 | 0.824 | 0.723 |
| ICFT(pn) | 0.757 | 0.691 | 0.777 | 0.696 |
DR 是去噪率(denoising rate),衡量模型在噪声里坚持自己内部知识的能力。CU 是上下文利用率(context utilization),衡量模型用好正向上下文的能力。
读出来的故事是这样的:R-tuning 的 DR 比 vanilla 还低——它本来要教模型"知道自己不知道",结果反而把模型自身的知识能力削弱了。我看到这个数的时候愣了一下。R-tuning 训练流程里,"标错为不知道"的样本会让模型在 SFT 时把一些原本能答对的知识也覆盖掉,相当于一种"学拒答 = 忘知识"的副作用。
更刺眼的是 CU 这一栏。所有 refusal 微调方法的 CU 都比 vanilla 差。ICFT(p) 在 10p0n(全是正向)下 CU 0.824 看起来不错,但跟 vanilla 的 0.759 比也只是稍好;其他变体在 1p9n 下都比 vanilla 差。这说明 refusal 微调的副作用是双向的——既损伤了内部知识、又损伤了上下文利用。模型变得"更倾向拒答",但代价是"答的时候答得更差"。
这个观察对工程落地的启发是直接的:别简单地往生产模型上叠 R-tuning。如果你的 RAG 已经在跑了,加一层 R-tuning 很可能让整体质量下降,尤其在 happy path(召回质量高的场景)下。
RQ3:把不确定性弃答和 refusal 微调拼起来
到这儿前两个 RQ 都把问题暴露透了——RIFT 单独用有副作用,那怎么办?作者的方案是不依赖模型自己的"主动拒答",而是在推理阶段挂一个基于不确定性的后置拒答机制,跟 refusal 微调互补。
核心思路:双阈值两阶段判断
作者用两个不确定性信号来推断知识状态:
第一阶段:用 \(U_{\text{LLM}}\)(基础 LLM 不引入上下文时的不确定性)判断答案是否能被内部知识支撑。再用 \(\Delta U=U_{\text{RALM}} - U_{\text{LLM}}\) 判断引入上下文后不确定性的变化方向——如果 \(\Delta U\) 显著为负(上下文降低了不确定性),说明上下文是有用的;如果 \(\Delta U\) 接近 0 甚至为正,说明上下文是噪声。
第二阶段:根据第一阶段判出的知识状态决定是否触发拒答阈值。只在被判为"unknown"的时候启用阈值拒答,避免在内部知识充足的时候被噪声干扰。
阈值通过开发集上的 grid search 选出。这套方案的工程实现很轻——不需要改训练流程,只需要在推理时多采样一次(不带上下文)算 \(U_{\text{LLM}}\)。
0p10n 硬场景下的提升数字
| 拒答方法 | 模型 | OAcc ↑ | MA ↓ | AF1 ↑ | OR ↓ | RF1 ↑ |
|---|---|---|---|---|---|---|
| Post refusal | Vanilla | 0.437 | 0.145 | 0.167 | 0.770 | 0.570 |
| Post refusal | ICFT(n) | 0.673 | 0.098 | 0.655 | 0.462 | 0.690 |
| Post refusal | ICFT(p) | 0.683 | 0.240 | 0.672 | 0.243 | 0.682 |
| Ours | Vanilla | 0.523 | 0.104 | 0.240 | 0.282 | 0.590 |
| Ours | ICFT(n) | 0.729 | 0.059 | 0.707 | 0.176 | 0.731 |
| Ours | ICFT(p) | 0.697 | 0.178 | 0.691 | 0.106 | 0.698 |
最强组合是 Ours 叠加 ICFT-n:OAcc 0.729、OR 0.176、RF1 0.731。三个指标同时打到所在列的最优或接近最优。
跟单纯的后置阈值(Post refusal)比,作者方法在 ICFT(n) 上把 OAcc 从 0.673 抬到 0.729,OR 从 0.462 压到 0.176——over-refusal 的相对降幅接近 62%。这个数我觉得是真的能打。
跟 RQ2 主表 ICFT(n) 在 0p10n 下的 0.620 比,又涨了大约 11 个点。
这个方法为什么有效
我自己琢磨了一下作者的思路,核心其实是把"是否拒答"这个决策从模型内部抽出来、放到外面用一个轻量决策器统一管。模型负责生成 + 给置信度,决策器负责根据"内部置信度 + 上下文增益"两个信号合成一个最终拒答判断。
这种解耦方式的好处是显著的——它把 RAG 系统里"拒答"和"作答"两条决策路径用统一的不确定性语言来描述,避免了 R-tuning 那种"为了学拒答把知识也忘掉"的副作用。\(\Delta U\) 这个信号尤其聪明:它直接刻画了"上下文对模型有没有帮助",而不是依赖模型自己事后说"我用了"或"没用"。
类似的思路 [Yu et al. 2025 EMNLP info-gain] 也提过,作者在论文里也承认了这一点,说自己的工作是更显式地把"知识状态"作为决策维度。我觉得这个承认挺坦荡的,没有强行包装成完全原创。
我的判断
先说亮点。这篇论文在做一件挺扎实的"现象观察 + 机理分析 + 简单方案"的事。over-refusal 这个现象作为新的视角被刻画出来,论文的论证链条非常完整:
- 先证明现象普遍存在(RQ1 的 highlyknown 在 0p10n 下精度悬崖 + 拒答率上扬);
- 再分析现有方法的失效模式(RQ2 R-tuning 加剧 over-refusal、ICFT 部分缓解但有 CU 下降副作用);
- 最后给出一个解耦式的简单方案(RQ3 双阈值两阶段拒答)。
每一步都有数据支撑,没有跳跃。表格的 OAcc / OR / RF1 / OaBs 几个指标互相印证,不是单点优化。
我觉得最值得带回工程的洞察有这么几个:
- 0p10n 不是 corner case。生产环境的召回质量经常会出现"全错"的情况,作者用这个切片是合理的,结果有现实意义。
- R-tuning 慎用。如果你的 RAG 系统对 happy path 的回答质量要求高,R-tuning 可能反而是负优化。论文的 DR、CU 数据是直接证据。
- 拒答策略应该和 refusal 微调解耦。作者的两阶段方案非常轻,不需要改训练流程,可以在现有 RAG 系统上加一层补丁。\(U_{\text{LLM}}\) 和 \(\Delta U\) 都是可以在线计算的,工程成本不高。
- 不确定性估计该选 consistency-based。verbalized 那种让模型自己说置信度的方式不靠谱,多次采样的一致性才是更稳的信号。
但也有一些地方我觉得可以挑刺:
第一,评估的模型规模偏小。论文主表都是 7B-8B 模型,更大的模型(70B 量级)在 over-refusal 上表现如何?作者在附录提了,但正文没展开。我直觉上觉得大模型在噪声面前会更稳一点,但不知道 over-refusal 是不是规模能解决的问题。
第二,评测任务集中在 short-form factoid QA。CRUD、RGB、NQ 都是短答案事实题。在长答案、多跳推理、对话式场景下 over-refusal 是不是同样严重?这块论文没覆盖。
第三,\(\Delta U\) 这个信号本身的稳定性没有充分讨论。它依赖采样次数(论文用了 16 次),如果在线服务为了延迟把采样次数砍掉,这个信号还能多稳?这是个工程化的关键问题。
第四,baseline 的覆盖度。论文对比了 R-tuning 和 ICFT 系列,但 RL-based refusal 方法(如 DPO 路线)只在脚注一带而过。同期的 refusal 微调工作其实不少,正文应该再展开一些对比。
工程落地的几条建议
如果你正在搭 RAG 系统,看完这篇论文我会建议:
-
召回质量是 1,其他都是 0 后面的位数。论文很硬地证明了——只要能稳定召回 1 个相关文档,模型校准就能从灾难变到极佳。砸资源在召回上比砸资源在 refusal 微调上 ROI 高得多。
-
想加 refusal 能力,优先选 ICFT(n) 风格而不是 R-tuning。把检索上下文带进训练样本,让训练分布和部署分布对齐,副作用小很多。
-
用 consistency-based UE 做拒答阈值。多次采样的一致性比 verbalized confidence 稳。生产环境如果延迟敏感,可以采样 4-8 次而不是 16 次,作者的发现仍然适用。
-
把"判断是否拒答"做成一个独立的决策模块。模型只输出"答案 + 不确定性",由外层决策器根据 \(U_{\text{LLM}}\) 和 \(\Delta U\) 决定是返回答案还是返回拒答。这种解耦让系统更可调可控。
-
做 A/B 实验时盯着 OR 这个指标。很多团队只看 accuracy 和 refusal rate 各自的数,但 over-refusal rate(被拒掉的本来能答对的题占比)才是真正反映用户体验恶化的指标。
最后一句
RAG 这个领域已经卷得够久了,大家都在比召回 recall、比 reranker、比 chunk 策略。这篇论文把视角拉到"模型自己怎么想"——它知不知道自己知不知道?面对噪声它会不会自我怀疑?refusal 微调有没有副作用?这些问题没那么显学,但它们是 RAG 系统从能跑到好用之间的关键一公里。
over-refusal 不是个孤立的 bug,它是 LLM 在外部信息和内部知识之间没找到平衡的症状。怎么让模型学会"在嘈杂中坚持自我"、又"在有用的时候善用外部",这个命题我觉得后面还会出更多有意思的工作。这篇论文给出了一个不错的起点。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我。