RAG-R1:让模型自己决定要搜几次,把 RAG 从串行链改成自适应多查询并行
核心摘要
做过 RAG-Agent 的同学应该都有这种体验:让模型一边思考一边检索,听起来很优雅,但跑起来一旦命中多跳问答,模型就开始在 search 标签里来回拉扯,一查、再查、再查,串行排队等检索结果,整体延迟一下就被拖到秒级。更糟的是,第一个 query 写得不好就会把整条推理链带歪,模型在后续轮次里疯狂打转却走不出来。RAG-R1 这篇论文(AAAI 2026)把矛头对准这件事:放弃"一次只发一个 query"的单查询模式,让 LLM 在每个 search 节点自适应决定生成几条并行 query,并在两阶段训练(格式学习 SFT + 检索增强 RL)里把这种新范式硬训进模型。在 7 个 QA 基准上,多查询版相比最强 RL 基线 R1-Searcher 平均涨 13.7 个百分点,同时推理时间还能再降 11.1 个百分点。这不是在 prompt 上加几个花活,而是顺着 Search-R1、R1-Searcher 那条 RL+RAG 路线再往前推了一步——把检索的并行性当成一等公民。
论文信息
- 标题:RAG-R1: Incentivizing the Search and Reasoning Capabilities of LLMs through Multi-query Parallelism
- 作者:Zhiwen Tan, Jiaming Huang, Qintong Wu, Hongxuan Zhang, Chenyi Zhuang, Jinjie Gu
- arXiv:2507.02962v6
- 收录:AAAI 2026
- 代码:github.com/inclusionAI/AWorld-RL/tree/main/RAG-R1
一、动机:单查询 RAG 的两个老毛病
先说点工程上的体感。
去年下半年开始,RL+RAG 这条线突然密集起来:Search-R1、R1-Searcher、ReSearch、ZeroSearch 一个接一个。共同范式都很像,模型按 think → search → information → think → ... → answer 的格式跑,遇到信息缺口就发出一条 <search>...</search> 调用检索器,把结果包在 <information> 里灌回上下文,再继续推理。强化学习负责让模型自己学会什么时候该搜、搜什么、搜到了怎么用。这套范式优雅是真优雅,能 work 也是真能 work。
但实际部署起来你会发现两个特别难受的地方。
第一个是延迟非常炸裂。检索是串行执行的,每发一次 search 就要等检索器返回再继续生成。一个 2-hop 的题目可能就要 2-3 轮检索,3-hop 题目能轻松上 4-5 轮。每一轮检索本身可能就几百毫秒,再加上生成新 thinking 的时间,整体首 token 出来都要几秒,更别说完整答案。生产环境对这种 P95 是非常敏感的。
第二个更隐蔽,叫脆弱性。模型只能基于"当前已有上下文"生成下一条 query,如果第一条 query 写偏了,召回的就是无关文档,无关文档进入上下文又会进一步污染下一条 query,循环往复。论文管这个叫"unrecoverable path"——一旦走错就难以回头。我之前调一个生产 Agent 的时候,确实遇到过模型在某个错误的实体名上反复检索 5 轮还出不来,最后 timeout 直接挂掉。这种 case 排查起来非常烦,因为模型本身的思维链看起来很合理,错只错在第一步召回偏了。
作者用 Qwen2.5-72B-Instruct 做了一个非常直接的对比实验,把这两个痛点直接量化出来:
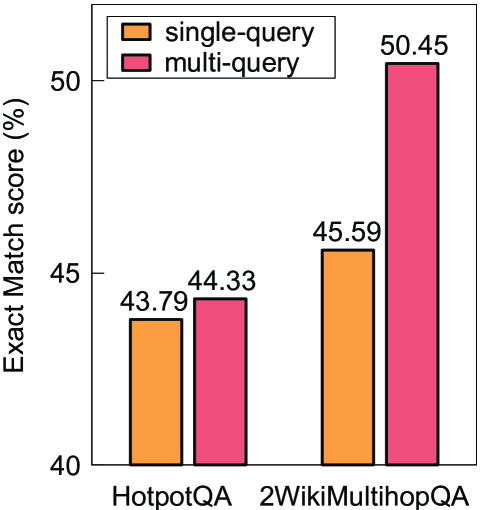
图 1(左):在 HotpotQA 和 2WikiMultihopQA 上,多查询模式的 EM 分数都高于单查询。2WikiMultihopQA 上从 45.59 直接跳到 50.45,差了将近 5 个点——这是个相当能说明问题的数。
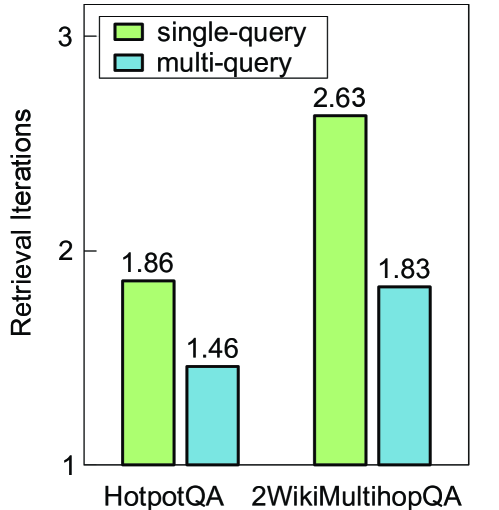
图 2(右):对应的平均检索轮次,多查询从 1.86 降到 1.46(HotpotQA)、从 2.63 降到 1.83(2Wiki)。一次发多条 query,整体反而需要更少的轮次。
这两张图放在一起看,结论非常硬:多查询不仅能减少串行的轮数(解决延迟),还能因为同时拿到多个角度的证据而提升答对率(解决脆弱性)。一举两得,几乎不存在 trade-off。
但问题是——光在 prompt 里写"你可以一次发多个 query"是不够的。Qwen2.5-72B 这种大模型自己 prompt-only 能玩明白,7B 量级的模型基本压根不会主动 batch query,要么一次只发一条,要么把多条 query 拼成一条乱七八糟的长串。要让一个小模型真正学会"在合适的时机生成 1-3 条平行 query 并能消化并行返回的多份证据",光靠提示词不行,得训练。这是 RAG-R1 要做的事。
二、方法:两阶段训练 + 多查询并行架构
整体架构就一张图,但信息密度很高。
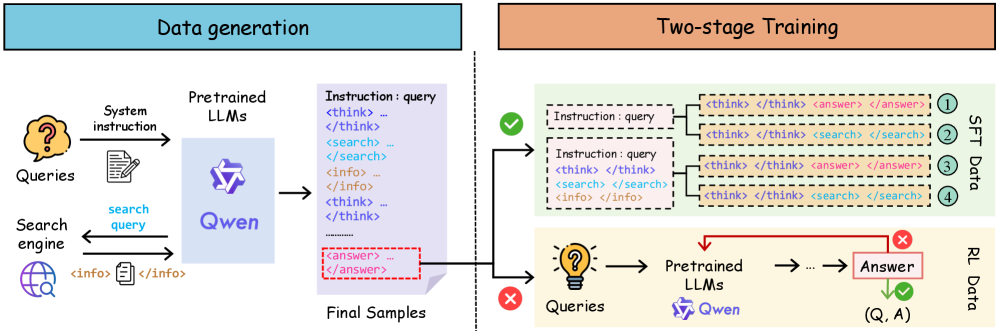
图 3:左半部分是数据生成——拿系统指令喂给预训练 Qwen,让它配合搜索引擎产生带 think/search/info/answer 标签的轨迹,对的(绿色对勾)和错的(红色叉)都留着。右半部分是两阶段训练:对的轨迹按照分段策略切成 4 类样本喂给 SFT 学格式,错的轨迹(保留有正确答案的)扔进 RL 阶段做基于结果的强化学习。
我把整个 pipeline 拆成三块讲:先看冷启动的 SFT 怎么做、再看 RL 阶段的关键设计、最后讲多查询并行这个核心创新到底是怎么实现的。
2.1 第一阶段:格式学习 SFT
这个阶段的任务说起来朴素:让模型学会按 <think>...</think><search>...</search><information>...</information><answer>...</answer> 的格式输出。但有个细节是真值得说的——SFT 数据的分段策略。
直观做法是把整条轨迹(think→search→info→think→search→info→answer)当成一个完整样本喂下去训练。但这样有个大坑:模型会顺手学会"生成 information 段",也就是开始幻觉式地编造检索结果。这个问题在很多 SFT 阶段都出现过。
RAG-R1 的处理方式是把每条完整轨迹按"模型该思考"或"模型该检索"的切点切成多个小样本,分成 4 类:
| 样本类型 | 形态 | 训练目标 |
|---|---|---|
| 第 1 类 | instruction → think → answer | 学会用内部知识直接答 |
| 第 2 类 | instruction → think → search | 学会判断需要外部知识、并发 query |
| 第 3 类 | instruction → think → search → info → think → answer | 学会消化检索结果做最终回答 |
| 第 4 类 | instruction → think → search → info → think → search | 学会基于检索结果继续追问 |
注意每一类的输出段都不包含 <information> 内容——<information> 只在 prompt 部分以 context 的形式存在。这一刀切下去,模型就学不到"自己生成 information"这个坏习惯了。这个设计很聪明,属于那种"看完会拍大腿"的工程细节。
通过第 1、2 类样本,模型学的是自适应决策:当前问题用内部知识够不够、要不要发起搜索。通过第 3、4 类样本,模型学的是怎么用外部知识:拿到检索结果后是收尾还是继续追问。
2.2 第二阶段:检索增强 RL
SFT 给了模型格式和初步能力,但要真正提升答对率,还得靠 RL。
RL 数据筛选这块作者做了相当严谨的事。直接拿全部数据上 RL 是行不通的——简单题模型已经会了,难到无解的题怎么 rollout 都答不对。论文的做法是:
- 拿 SFT 结果跑一遍训练数据,挑出答错的题(这些是模型当前 capability boundary 上的题,最适合 RL)
- 用 Qwen2.5-72B-Instruct 做 stochastic rollout(temperature=1.2,最多 10 次重采样),把那些"模型至少能答对一次"的题留下来
- 同时把 25% 答对的题混进去做正例
最终拿到 2488 个"挑战但可解"的样本。这个量看着不大,但对 PPO 训练来说够了,关键在样本质量。
优化目标就是标准的带 KL 约束的 PPO:
其中 \(\mathcal{R}\) 是检索系统,rollout 序列里既有模型生成的 token 也有从检索器拿回来的 token。
这里有个关键工程实现——Retrieval Masked Loss。检索器返回的 token 不能参与策略梯度的计算。你想想看,如果不 mask 掉,模型会被迫去"模仿"那些来自外部检索的文本,loss 就会跟着检索器的语言风格跑偏,训练完全不稳定。Search-R1 当时也是这么处理的,RAG-R1 沿用了这个做法。
奖励函数极简,就是基于结果的 EM 匹配:
没有格式奖励——因为格式已经在 SFT 阶段学完了,RL 阶段只关心答案对不对。这个干净的奖励信号配合 RL 数据筛选,让训练能稳定地围绕"准确率"这一个目标优化。
2.3 多查询并行:这才是核心
如果只是上面两阶段训练,那不过是又一个 Search-R1 变体。RAG-R1 真正的差异点在第 4 节这部分——让模型在每次 search 时自适应生成最多 3 条并行 query。
具体做法是改造系统指令和检索器协议:
模型在 <search> 标签里输出多条 query,用逗号分隔。检索器接到后并行执行多次召回,然后把结果按 JSON 格式拼回去:
{
"query": ["query_1", "query_2"],
"documents": [
[...], // query_1 的 top-3 文档
[...] // query_2 的 top-3 文档
]
}
模型看到这个结构化的 JSON,就能明确知道"哪段文档是哪个 query 召回的",不会把召回结果搞混。
这里有几个非常关键的设计选择:
第一,最多 3 条 query。不是越多越好——再多就是浪费检索带宽。论文实验下来 3 条是个甜点。
第二,并行执行。这是延迟优化的关键。3 条 query 同时发给检索器,等价于 1 次串行检索的延迟(而不是 3 次)。这一步把"轮次×单轮延迟"的乘法关系拆掉了。
第三,自适应。模型可以选择只发 1 条,也可以发 2-3 条。不是强制每次都发 3 条。这点很重要——简单问题就 1 条够了,复杂的多角度对比题才需要 2-3 条。这种"模型自己学会该发几条"的能力,是 RL 阶段训出来的。
理解多查询并行最直观的视角是:它把"决策树式"的串行检索变成了"BFS 式"的并行探索。单查询模式像 DFS——一条路走到黑再回退,错一步可能就回不来了。多查询模式像 BFS——同时探索几条 promising 的路径,发现哪条对就往下走。这个类比对工程师来说应该挺熟悉的。
三、实验结果:硬数据
3.1 主实验:7 个 QA 基准
实验全部在 Qwen2.5-7B-Instruct 上做,retrieval 用 BGE-large-en-v1.5 + Wikipedia KILT 切片(29M passages,每段 100 词),top-3 文档。所有 baseline 都用同样的 retriever 配置,这点公平性是没问题的。
| Methods | NQ | PopQA | TriviaQA | HotpotQA | 2Wiki | Musique | Bamboogle | Avg. |
|---|---|---|---|---|---|---|---|---|
| Direct Inference | 0.132 | 0.148 | 0.360 | 0.183 | 0.236 | 0.031 | 0.080 | 0.167 |
| Standard RAG | 0.328 | 0.353 | 0.476 | 0.284 | 0.253 | 0.048 | 0.152 | 0.271 |
| IRCoT | 0.183 | 0.328 | 0.434 | 0.276 | 0.356 | 0.060 | 0.144 | 0.254 |
| Search-o1 | 0.277 | 0.294 | 0.474 | 0.348 | 0.384 | 0.107 | 0.296 | 0.311 |
| Search-R1 | 0.387 | 0.422 | 0.531 | 0.377 | 0.351 | 0.135 | 0.376 | 0.368 |
| R1-Searcher | 0.404 | 0.410 | 0.522 | 0.442 | 0.513 | 0.158 | 0.368 | 0.402 |
| RAG-R1-sq | 0.429 | 0.477 | 0.599 | 0.492 | 0.520 | 0.187 | 0.440 | 0.449 |
| RAG-R1-mq | 0.423 | 0.479 | 0.608 | 0.495 | 0.563 | 0.192 | 0.440 | 0.457 |
表 1:主实验结果(EM 分数)。RAG-R1-sq 是论文方法的单查询版,RAG-R1-mq 是多查询并行版。粗体是当前最好。
几个观察:
第一,单查询版 RAG-R1-sq 已经吊打所有 baseline。平均 0.449 vs R1-Searcher 的 0.402,差 4.7 个点。这说明两阶段训练框架本身(SFT 数据分段策略 + RL 数据筛选)就已经很强了,跟多查询其实没关系。也就是说,论文的两个贡献是可拆分的——你只想用单查询版,也能拿到一个相当强的 RAG-RL 基线。
第二,多查询版再涨 0.8 个点(0.457 vs 0.449)。在 2WikiMultihopQA 上涨幅最大,从 0.520 到 0.563(涨 4.3 个点),这个数据集恰好是多跳推理最复杂的——多 query 并行的优势在多跳场景里被放大了。
第三,论文摘要里的"13.7 个百分点"是怎么来的。这是 RAG-R1-mq 相对 R1-Searcher 在平均 EM 上的相对提升:(0.457 − 0.402) / 0.402 ≈ 13.7%。是相对涨幅,不是绝对涨幅。这点在阅读时要注意——绝对涨幅是 5.5 个点,已经很能打了,但宣发口径用了相对值会更好看。
说实话我对 baseline 的选择有一点保留意见。Search-R1 和 R1-Searcher 都是这条线上很硬的工作,但论文没对比 ZeroSearch、ReSearch、DeepRetrieval 这些更新的同期工作。当然 v6 是 2026 年 1 月的版本,有些工作时间线对不上情有可原。整体的 baseline 还算公平。
3.2 消融实验:每个组件都不能少
| Methods | HotpotQA | 2Wiki | Musique | Bamboogle | Avg. |
|---|---|---|---|---|---|
| RAG-R1-sq | 0.492 | 0.520 | 0.187 | 0.440 | 0.410 |
| RAG-R1-sq w/o SFT | 0.415 | 0.406 | 0.138 | 0.312 | 0.318 |
| RAG-R1-sq w/o RL | 0.425 | 0.433 | 0.150 | 0.368 | 0.344 |
| RAG-R1-sq w/o Filter | 0.452 | 0.462 | 0.159 | 0.408 | 0.370 |
| RAG-R1-mq | 0.495 | 0.563 | 0.192 | 0.440 | 0.423 |
| RAG-R1-mq w/o SFT | 0.413 | 0.423 | 0.129 | 0.392 | 0.339 |
| RAG-R1-mq w/o RL | 0.427 | 0.490 | 0.143 | 0.424 | 0.371 |
| RAG-R1-mq w/o Filter | 0.491 | 0.543 | 0.186 | 0.424 | 0.411 |
表 2:消融实验。w/o SFT 是直接从预训练模型上 RL;w/o RL 是只做 SFT 不上 RL;w/o Filter 是 RL 阶段不做数据筛选直接全量训练。
几个有意思的发现:
SFT 比 RL 重要一点点(w/o SFT 平均 0.318 vs w/o RL 0.344,单查询版下)。这有点反直觉——按理说 RL 是涨点的关键,但消融显示去掉 SFT 反而掉得更狠。我的理解是:w/o SFT 意味着模型从一开始就不会按 think-then-search 格式输出,连基础格式都没学会,RL 直接就乱掉了。SFT 是"建立行为框架",RL 是"在框架内优化精度",这个先后关系很重要。这跟 R1-Searcher 那篇的 cold-start 思路一致。
RL 数据筛选贡献了 4 个点(sq 上从 0.370 涨到 0.410,mq 上从 0.411 涨到 0.423)。这部分往往容易被忽略——大家都关注 RL 算法本身,但其实"喂什么样的题给 RL"才是更关键的事。无解题会让模型陷入"怎么搜都搜不出来"的反复循环,污染策略梯度。
多查询版本的健壮性更强(mq w/o Filter 还能保持 0.411,sq w/o Filter 掉到 0.370)。这其实印证了论文的核心论点——多查询本身就是一种健壮性增强机制,对训练数据噪声的鲁棒性更好。
3.3 效率分析:延迟降 11.1 个百分点是怎么算的
| Methods | HotpotQA Time/RI | 2Wiki Time/RI | Avg. Time | Avg. RI |
|---|---|---|---|---|
| Search-R1 | 7.79 / 2.44 | 8.90 / 3.01 | 8.35 | 2.73 |
| R1-Searcher | 10.98 / 2.31 | 10.93 / 2.40 | 10.96 | 2.36 |
| RAG-R1-sq | 7.69 / 2.14 | 8.72 / 2.72 | 8.21 | 2.43 |
| RAG-R1-mq | 6.72 / 1.89 | 8.11 / 2.43 | 7.42 | 2.16 |
表 3:A100 上的平均推理时间(秒)和检索轮次(RI)。所有方法均未使用推理加速。
RAG-R1-mq 相对 RAG-R1-sq 平均省 9.6% 的时间(7.42 vs 8.21)和 0.27 轮检索(2.16 vs 2.43)。摘要里说的"降 11.1 个百分点"应该是相对某个参照值的口径,从这张表看 mq 比 sq 是 9.6%,比 R1-Searcher 是 32.3%。具体取哪个口径作者没特别说明,但 9.6%-11% 这个量级是一致的。
注意一个细节:RAG-R1-mq 的检索轮次(2.16)甚至低于 RAG-R1-sq(2.43)。这说明多查询不只是把单查询的 N 轮压成 1 轮——它还在帮模型"少走错路",因为一次拿到多角度证据,第二轮就更不容易走偏。这是个非常漂亮的副作用。
3.4 在线搜索泛化
作者还测了一个有意思的场景:训练时只用离线 Wikipedia,但推理时切到 Google 在线搜索(用 BeautifulSoup4 抓页面 + GPT-4o-mini 摘要)。
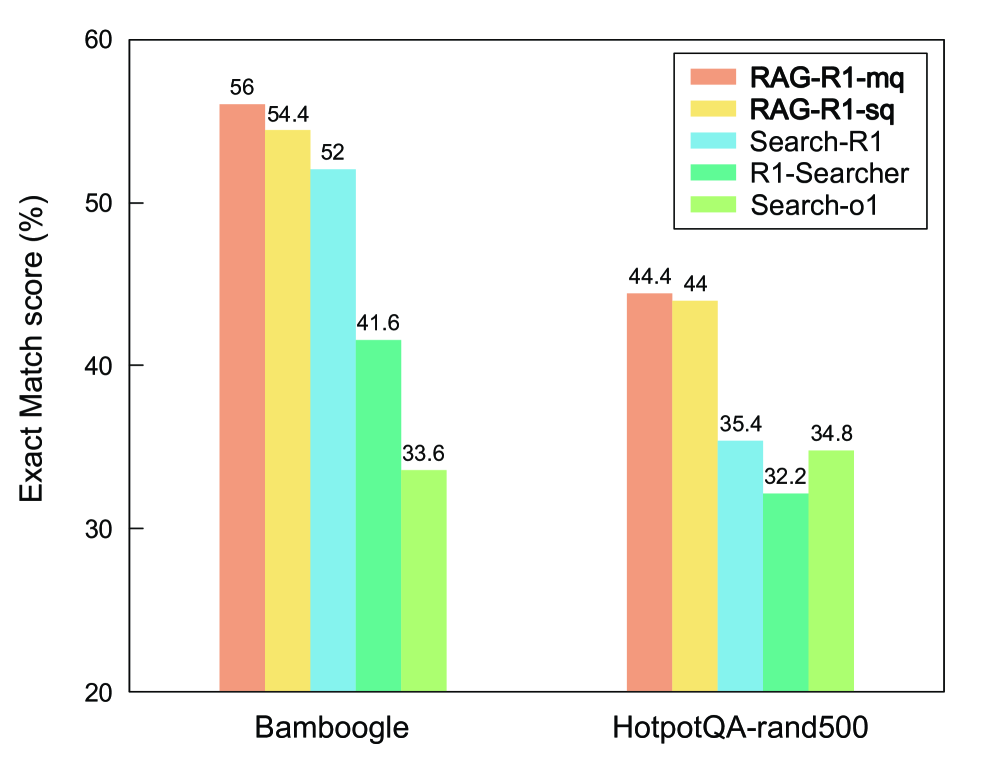
图 4:在 Bamboogle 和 HotpotQA-rand500 上切换到 Google 在线搜索后,RAG-R1-mq 仍然是最优的。Bamboogle 上 56% vs Search-R1 的 52%,HotpotQA 上 44.4% vs Search-R1 的 35.4%。
这个实验我觉得挺有价值的——它说明 RL 训出来的 search 能力不是死记硬背离线 corpus 的格式,而是真的学会了"什么时候发什么样的 query"。换到完全没见过的搜索引擎一样能 work。Search-R1 在 HotpotQA 上从离线的 0.377 掉到在线的 0.354,RAG-R1-mq 反而保持在 0.444,泛化能力差距非常显著。
四、几点判断
4.1 这篇论文最值钱的是什么
我觉得真正能落地的工程价值是自适应多查询这个抽象。RAG-RL 这条线现在已经卷得很厉害,谁都在比 EM 分数。但分数提升一两个点对工业部署其实意义有限——延迟才是生产环境的硬约束。RAG-R1 把"准确率"和"延迟"同时拿下,而且没有牺牲任何一边,这是它跟其他工作不一样的地方。
第二个值钱的点是SFT 数据分段策略。把完整轨迹切成 4 类样本,避免模型生成虚假 information——这个 trick 看着不起眼,但对小模型上 SFT 至关重要。我之前在做类似 Agent 训练的时候就踩过这个坑,模型动不动就开始"幻觉式生成 tool 输出",最后只能用各种 mask 和约束来兜底。RAG-R1 这个分段方案是个干净的解法。
4.2 哪些地方还可以质疑
多查询的并行度是定死的(最多 3 条)。但实际中有些题可能 1 条就够了,有些题(比如 5-hop 的复杂对比题)可能需要 5 条。论文没讨论"动态决定并行度"的策略,模型只能在 0-3 之间选。我觉得这是个可以扩展的方向——让模型预测一个"我需要发几条 query"的元决策。
评估只有 EM,没有 F1、没有更细粒度的事实性指标。EM 对答案表述的容忍度太低,可能低估了某些方法。如果加上 F1 和 LLM-as-Judge,排名可能会有变化。
baseline 都基于 7B 模型,但多查询的能力其实跟模型规模是有关的——72B 模型 prompt-only 就能搞定,7B 必须训练。论文没在更大尺寸(14B、32B)上验证这套训练框架的扩展性,这是个遗憾。如果在 14B 上 RL 之后多查询带来的相对增益变小,那这套方法的天花板就值得重新评估。
没有讨论失败 case。多查询在哪类题上反而比单查询差?理论上对那种"答案就藏在第一个 query 召回的文档里"的简单题,多查询是冗余的,可能甚至会因为信息过载导致小模型分心。论文里没有这种 case 的细致分析。
4.3 跟同期工作的位置
把 RAG-RL 这条线列一下时间线:
- Search-R1(2025 早期):把 search 当 tool,用 PPO 训 7B 模型
- R1-Searcher(2025 中期):两阶段 RL,先学格式后学准确率
- RAG-R1(2025 中-2026 初,多次 revision):在 R1-Searcher 的两阶段框架上加多查询并行
- 同期还有 ZeroSearch、ReSearch、DeepRetrieval 等
RAG-R1 的位置很清楚——它是这条 RL+RAG 路线上的"工程化推进",把单查询升级成多查询,把训练框架打磨得更扎实。不是颠覆性创新,但是个高质量的迭代。如果你正在做基于 RAG-RL 的智能体应用,这套训练流程是值得照搬的。
五、对工程实践的启发
如果你正在做基于 RAG 的 Agent 系统,这篇论文有几个点可以直接拿去用:
第一,把 search tool 改造成支持 batch query。即使你不打算重新训模型,把检索接口改成支持一次发多个 query 并行检索,已经能在一些 prompt-engineering 的场景里降低延迟。给大模型加个"必要时可以一次发 1-3 条 query"的指令,能力够强的模型(72B+)会自己学会用。
第二,retrieval mask loss 是 RL+RAG 的必备组件。任何时候你在 RL 训练中包含检索结果的 token,都要把这部分 mask 掉,不要让策略梯度污染检索器风格的内容。这不是 RAG-R1 独家的,但论文又强调了一遍其重要性。
第三,RL 数据筛选的"挑战且可解"准则。具体做法是:用当前策略 rollout N 次,挑那些"至少答对 1 次"的题作为训练样本。简单题(次次都对)和无解题(次次都错)都剔除掉。这个 recipe 在很多 RL 训练里都适用,不止 RAG。
第四,SFT 数据的轨迹切分。如果你的训练样本是带工具调用的多轮轨迹,记得在工具调用的边界切样本,不要让模型学会生成工具的输出。这是 Agent 训练里反复被验证的一个工程铁律。
最后想说一句:RAG-R1 的代码已经开源在 inclusionAI 的 AWorld-RL 仓库下(团队来自蚂蚁),训练数据和模型权重都有。要做 RAG-RL 落地的同学可以直接拿来魔改,不用从零开始撸 PPO+检索环境。这种愿意把整套 pipeline 都开源的工作越多越好。
参考资料
- 论文:arXiv:2507.02962
- 代码:inclusionAI/AWorld-RL/RAG-R1
- 相关前置工作:Search-R1(Jin et al. 2025)、R1-Searcher(Song et al. 2025)、Search-o1(Li et al. 2025)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我