LogicRAG:把图谱从离线建变成推理时即时拼,GraphRAG 这条路是不是走偏了
核心摘要
GraphRAG 这一路的方法过去两年很热,但用过的人多半都被建图成本劝退过——光是把语料预处理成图,token 烧掉几千万、跑几个小时是常态,知识库一更新还得重做一遍。LogicRAG 的作者把问题反过来想:与其离线建一个跟 query 不对齐的大图,不如在推理那一刻,针对当前 query 临时拆一个小 DAG,按拓扑序逐个子问题去检索。结果是:建图开销直接归零,2WikiMQA 上 string accuracy 从 HippoRAG2 的 50.0 干到 64.7,提了 14.7 个点;query-time token 用量比 GraphRAG 低 62%,比 LightRAG 低 69%。这篇论文 AAAI 2026 中了,作者来自香港理工大学。我读完最大的感受是:它没有引入什么新组件,只是把"图"放在了正确的位置——不是知识的全局索引,而是当前推理的局部脚手架。
论文信息
- 标题:You Don't Need Pre-built Graphs for RAG: Retrieval Augmented Generation with Adaptive Reasoning Structures
- 作者:Shengyuan Chen, Chuang Zhou, Zheng Yuan, Qinggang Zhang(通讯), Zeyang Cui, Hao Chen, Yilin Xiao, Jiannong Cao, Xiao Huang
- 机构:The Hong Kong Polytechnic University
- 录用:AAAI 2026
- arXiv:https://arxiv.org/abs/2508.06105
- 代码:https://github.com/chensyCN/LogicRAG
一、先聊聊 GraphRAG 这条路上踩过的坑
做过 GraphRAG 的同学应该都有这种体验。一开始看 Microsoft 的 GraphRAG 论文,觉得思路很漂亮——把语料先 NER + 关系抽取,建一张 entity-relation 图,再做 community detection 形成层次摘要,多跳问答效果立竿见影。
然后你真去落地。
第一个坑是建图成本。把 2WikiMQA 这种 6000 多篇 passage 的小语料用 GraphRAG 跑一遍预处理,作者的实测数据是:prompt token 加 completion token 加起来超过 3500 万,runtime 接近 200 分钟。LightRAG 也差不多 3600 万 token、100 分钟出头。HippoRAG 因为不抽关系、只做 entity 提取相对便宜,但也要 2000 多万 token 和 40 多分钟。
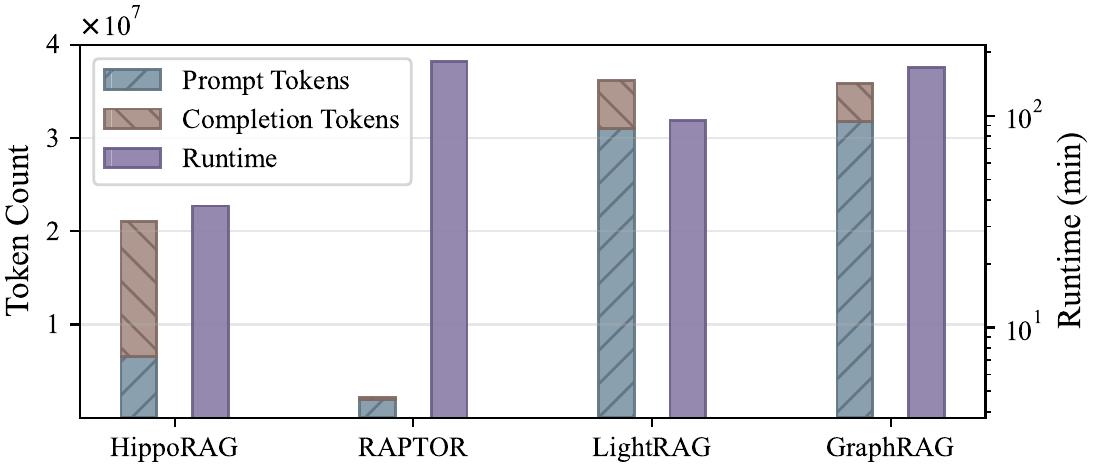
图1:GraphRAG 类方法在 2WikiMQA 上的预处理开销,token 上千万、时间上百分钟是常态
这只是 6000 篇 passage 的小数据集。真实业务里语料动辄百万级,建图基本是不可能的事。更要命的是知识库一旦更新,理论上整个图都需要重新算或者做增量维护——而增量维护本身又是一个研究问题。
我特别想强调一下知识库更新这件事。学术论文的 benchmark 是静态的,跑一次建图就完事了,所以 GraphRAG 看起来很美。但真实业务里语料永远在变——产品文档每周迭代、政策法规每月更新、用户反馈每天新增。每次更新都重建图谱,运营成本扛不住;做增量更新,工程复杂度爆炸(节点合并、边重新计算、社区重新聚类,每一步都是一个独立工程)。这是 GraphRAG 路线在企业落地遇到的真实壁垒,不是论文里那种"我们的方法 efficiency 更优"的对比能解决的。
第二个坑更隐蔽,预构图和真实 query 的逻辑结构对不上。
GraphRAG 建的是"实体-关系"图,这是一种通用、静态的结构。但你查的问题是有特定推理逻辑的。比如"Luka Dončić 在 2025 年 6 月效力的球队所在城市的市长是谁",这里面有一个明确的三跳依赖链:球队 → 城市 → 市长。再比如"A 和 B 哪个先获得诺贝尔奖",这是一个比较结构,两条独立查询路径最后做对比。
预构的 entity-relation 图捕捉不到这种 query 级别的逻辑。它能告诉你 Luka 和 Lakers 之间有 plays_for 边,能告诉你 Lakers 和 Los Angeles 之间有 located_in 边,但它不知道这个特定 query 需要按什么顺序、什么粒度去把这些信息串起来。所以最后还是要靠 LLM 在 retrieve 完之后做推理,图谱的作用退化成了一个高级版本的 chunk 索引。
我之前在做一个企业知识库的 RAG 项目时,团队也尝试过 GraphRAG 路线。建图花了一周,效果对比 vanilla RAG + 简单 rerank 也就涨了 3-4 个点,但维护成本翻了 5 倍——文档一更新,运营同事就来问"图什么时候能更"。后来还是把这个分支砍了。
LogicRAG 的作者把这两个坑直接列成 paper 的 motivation,并且给出了一个挺颠覆的方向:既然 query 才是真正决定推理结构的东西,那图就应该围绕 query 来建,不是围绕语料来建。
二、核心思路:把图从"索引"变成"脚手架"
LogicRAG 的设计直觉用一句话讲:别再为整个语料建图,针对当前这个 query 临时拆一张 DAG 就够了。
更具体地:
- 不预处理语料:语料就是 chunk + embedding,跟 vanilla RAG 一样
- 每来一个 query:先让 LLM 把 query 拆成若干 subproblems,再让 LLM 标注 subproblems 之间的逻辑依赖,组成 DAG
- DAG 拓扑排序:得到一个线性的执行顺序,前面解的子问题答案当作后面子问题的检索上下文
- Greedy 解每个子问题:单步 RAG 解一个 sub,结果塞进 rolling memory,往下传
- 两层剪枝:context pruning 防止 memory 膨胀,graph pruning 把同优先级的子问题合并检索
整个 pipeline 的好处在于:图是临时的、跟随 query 形状的、用完即弃的。建图开销摊到每个 query 上几乎可以忽略(无非就是多让 LLM 跑一次 decomposition prompt),但拿到的是一个跟当前推理逻辑完全对齐的结构。
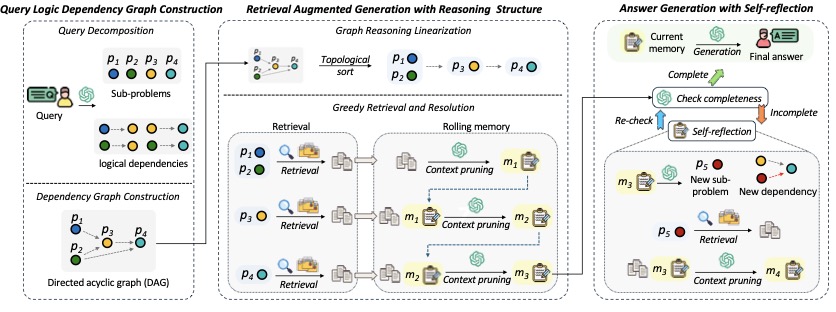
图2:整体框架——Query 拆 DAG → 拓扑排序 → 滚动记忆推进 → 自反思补充节点
这张图的三段式结构值得仔细看。
第一段(左)DAG 构建:query 进来后,LLM 用 few-shot prompt 拆出 \(p_1, p_2, p_3, p_4\) 四个子问题,再让 LLM 标边——比如 \(p_1, p_2\) 是叶子(无依赖),\(p_3\) 依赖 \(p_1, p_2\),\(p_4\) 依赖 \(p_3\)。论文用拓扑排序做合法性验证,如果 LLM 标出环就重新生成。
第二段(中)线性化 + 贪心检索:DFS 拓扑排序得到 \(p_1 p_2 \to p_3 \to p_4\)。然后逐个解:\(p_1, p_2\) 同级,先并行做 retrieval 拿到 chunks,喂给 LLM 总结成 \(m_1\) 这个 memory;接着用 \(m_1\) 当 context 解 \(p_3\),retrieval + 总结成 \(m_2\);最后用 \(m_2\) 解 \(p_4\)。这里的关键是 memory 是滚动压缩的,不是 chunk 简单拼接。
第三段(右)自反思与动态扩图:解完所有节点后让 LLM 检查"这堆 sub-answer 够不够回答原 query"。如果不够,让 LLM 提出新的子问题 \(p_5\),加到 DAG 里,重新跑 retrieval。这一步是论文相对低调但其实挺重要的设计——它解决了"初始 DAG 拆得不全"的鲁棒性问题。
三、技术细节:三个值得拆开聊的点
3.1 DAG 构建的三个考量
论文把 DAG 构建拆成三步,作者用了不同符号标注:
- Decomposition Accuracy:用 few-shot prompt 让 LLM 做任务分解。这一步质量决定上限,作者承认对 prompt 设计敏感
- Dependency Modeling:基于子问题之间的逻辑前后关系标边,用拓扑排序检测无环。如果有环就让 LLM 重生成
- Dynamic Adaptation:检索结果不够时动态加节点
我对第二点其实有点保留意见。让 LLM 自己标依赖,说到底就是把"判断 query 逻辑结构"这个能力外包给 GPT-4o-mini。如果是那种依赖关系一目了然的多跳题(HotpotQA 风格),LLM 标得没问题。但如果是真实业务里那种长 query、多个并列条件 + 嵌套约束的复杂查询,LLM 标的依赖未必准确。论文里没有给出这一步的单独评估指标,比如"DAG 的标注准确率",这是我读完比较想问作者的一个问题。
3.2 Greedy retrieval 的形式化
作者把检索过程写得很清楚。给定 DAG 里的子问题 \(p_i\),它的检索上下文不是只来自原 query,而是依赖父节点已解出的答案:
简单理解:解 \(p_3\) 的时候,retrieval query 不是 \(p_3\) 本身,而是 \(p_3\) 加上 \(p_1, p_2\) 的 sub-answer 拼出来的更具体的 query。这就是所谓 context-aware retrieval。
举个例子。原 query 拆成:\(p_1\) "Luka 在 2025 年 6 月效力哪支球队",\(p_3\) "那支球队所在城市的市长是谁"。直接拿 \(p_3\) 去 retrieval 没用——"那支球队"是什么不知道。但解完 \(p_1\) 拿到"湖人",再把 \(p_3\) 改写成"湖人所在城市的市长是谁",retrieval 就有意义了。
这个改写动作论文写得比较隐晦,实际上就是让 LLM 拿 memory 去 rewrite sub-query。工程上不复杂,但效果区别很大。
3.3 双重剪枝
Context pruning(rolling memory):每解完一个子问题,把当前 memory + 新检索的 chunks 让 LLM 做 query-oriented summarization,输出一个固定长度的字符串当作下一步的 memory。公式很朴素:
这个设计的关键是 summarization 是 query-oriented 的——不是无脑总结所有内容,而是围绕原 query 提取相关事实。这能避免传统 multi-step RAG 里那种"context 越滚越长,最后塞爆 LLM"的问题。
工程上有个细节作者没明说,但读代码能看出来:rolling memory 不是简单的字符串拼接。它每次都是把"上一步的 memory"和"新一轮 retrieval 拿到的若干 chunks"一起喂给 LLM,让 LLM 用一个 summarization prompt 输出新 memory。这意味着每跑一个子问题,LLM 实际上会被调用两次——一次做 retrieval-conditioned QA 拿到 sub-answer,一次做 memory 更新。这是 LogicRAG 比 vanilla RAG 慢的主要原因之一。
Graph pruning(unified subquery):DAG 里同 topological rank 的子问题(叶子或兄弟节点)合并成一个 unified query 一次性检索:
这其实是论文里我最喜欢的一个设计。比如比较型问题"A 和 B 哪个公司更大",子问题是"A 公司规模"和"B 公司规模",这两个无依赖、可并行。Graph pruning 直接把它们合成一个 unified retrieval,少做一轮,token 也省了。
更隐性的好处是一致性。两个子问题分开 retrieval 的话,可能拿到来自不同 source 的 chunk,回答口径不一致——比如一个用 2023 年的财报数据,另一个用 2024 年的预测数据。合并之后 LLM 在同一个 context 里同时回答两个问题,至少在数据来源上不容易错位。这一点对企业级问答场景挺重要的。
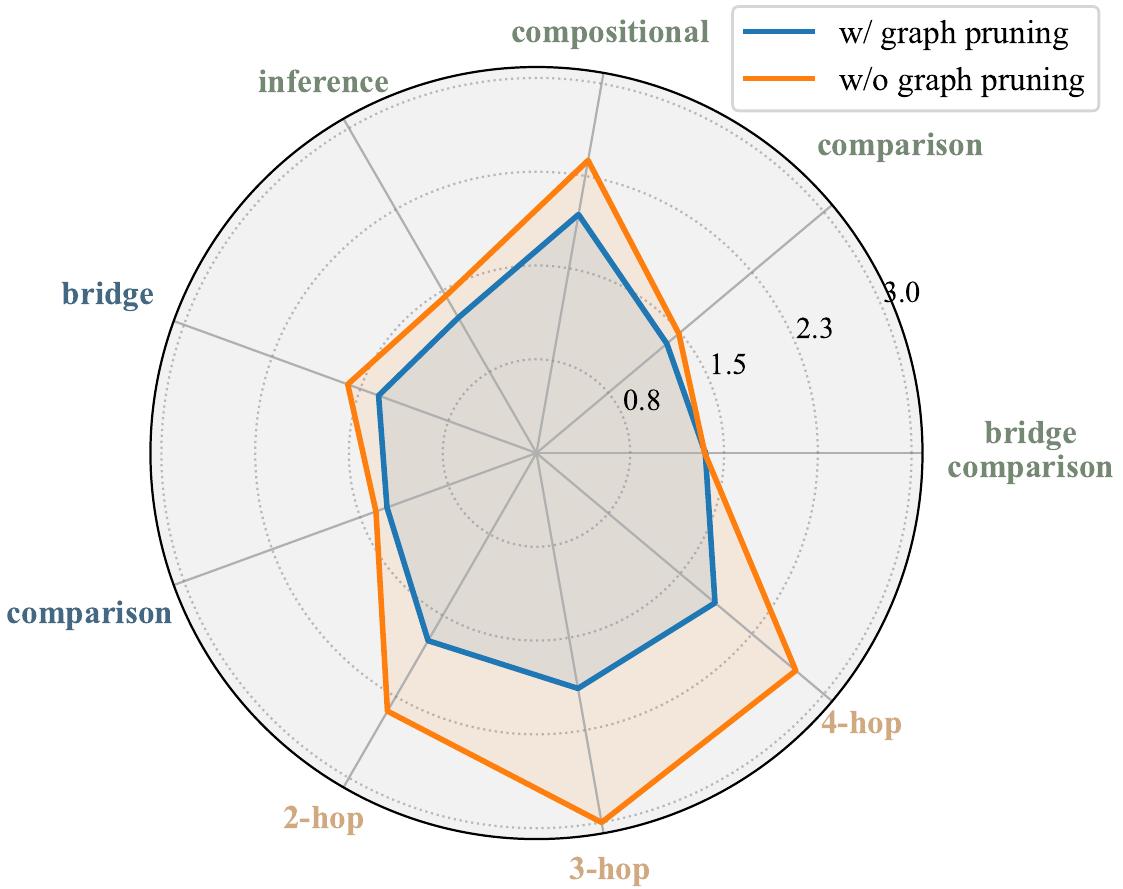
图3:graph pruning 把多种 query 类型的检索轮数普遍压低,4-hop 类问题原本要 3 轮,剪枝后 2 轮搞定
这张图里有个挺有意思的发现作者专门拎出来说。4-hop 问题的 retrieval 轮数比 3-hop 还少,反直觉吧?作者的解释是:当 query 太长太复杂时,LLM 容易"过度自信"——基于一部分信息就给答案了,懒得再拆更深。这其实是个潜在的失败模式:模型表现得好不一定是因为方法更聪明,可能是因为模型偷懒、提前收敛。作者愿意直接把这个观察写进论文,挺难得。
四、实验:不仅赢效果,更赢成本
4.1 主实验
LogicRAG 在三个多跳问答 benchmark 上全面跑赢 GraphRAG 路线的所有 baseline。
| 类别 | 方法 | HotpotQA Str-Acc | HotpotQA LLM-Acc | 2WikiMQA Str-Acc | 2WikiMQA LLM-Acc | MuSiQue Str-Acc | MuSiQue LLM-Acc |
|---|---|---|---|---|---|---|---|
| Zero-shot | GPT-4o-mini | 38.7 | 36.3 | 26.4 | 24.3 | 17.6 | 14.0 |
| Vanilla | VanillaRAG (Top-5) | 44.1 | 53.9 | 46.7 | 45.6 | 21.0 | 23.6 |
| Graph | KGP | 46.4 | 57.1 | 47.5 | 43.7 | 23.3 | 27.5 |
| Graph | RAPTOR | 48.1 | 57.8 | 47.7 | 45.9 | 25.2 | 29.1 |
| Graph | GraphRAG | 39.6 | 45.2 | 46.3 | 43.3 | 16.5 | 23.1 |
| Graph | LightRAG | 47.8 | 57.7 | 43.1 | 36.3 | 18.1 | 19.4 |
| Graph | HippoRAG | 53.7 | 55.6 | 47.7 | 47.2 | 24.9 | 30.1 |
| Graph | HippoRAG2 | 56.7 | 61.9 | 50.0 | 47.1 | 27.0 | 32.6 |
| Ours | LogicRAG | 54.8 | 62.6 | 64.7 | 62.5 | 30.4 | 37.5 |
最显眼的是 2WikiMQA,string accuracy 从 HippoRAG2 的 50.0 干到 64.7,涨了 14.7 个点。LLM accuracy 也从 47.1 干到 62.5,涨了 15.4 个点。这个幅度在已经卷到不行的 RAG 赛道里不寻常。
我看到这个数字时第一反应是怀疑——是不是评估方式有点偏?仔细看了一下,所有方法都用同一个 embedding(all-MiniLM-L6-v2)、同一个 LLM(gpt-4o-mini)、top-3 retrieval,对比是公平的。2WikiMQA 上的提升大,作者的解释是这个数据集的 query 类型最丰富(4 种 type,含 compositional、bridge-comparison 等复杂结构),最能考验"是否能识别 query 的逻辑结构"——预构图谱在这种场景下确实容易吃瘪。
HotpotQA 的 string acc LogicRAG 比 HippoRAG2 略低(54.8 vs 56.7),但 LLM acc 反超(62.6 vs 61.9)。这个细节作者没特别解释。我猜是 HotpotQA 大部分是 bridge 类型 2-hop,预构图谱的 entity 索引刚好能 cover;但答案表述上 LogicRAG 通过 rolling memory 整合得更连贯。
4.2 Query 类型上的细分

图4:按 query 类型分解的精度。MuSiQue 上 hop 数越多精度越低,符合直觉;2WikiMQA 上 compositional 是大头但精度只有中等,是后续优化的关键方向
这张图我觉得比主表更有信息量。它揭示了 LogicRAG 真正擅长什么:comparison 类(HotpotQA 83%、2WikiMQA 89%)。原因好理解——比较型问题天然适合 DAG 结构(两条独立路径 + 一个汇总节点),graph pruning 又能把两条路径合并为一次 retrieval。
不擅长的是 inference 和 compositional。2WikiMQA 上 inference 只有 39%,compositional 只有 50%,但 compositional 又占了 44.4% 的样本。作者直接承认这是 future work。我读到这里挺欣赏的——没有掩盖弱点,而是把弱点指出来当作后续研究方向。
4.3 效率对比
| 方法 | 单次查询平均时间 (s) | 单次查询平均 token |
|---|---|---|
| ZeroShot | 5.88 | 216.2 |
| VanillaRAG | 4.28 | 489.7 |
| G-retriever | 12.50 | 1000.0 |
| KGP | 70.72 | 11097.8 |
| Raptor | 5.79 | 2568.0 |
| GraphRAG | 13.05 | 4699.8 |
| LightRAG | 35.14 | 5730.6 |
| HippoRAG | 6.30 | 2608.8 |
| HippoRAG2 | 5.89 | 2809.2 |
| LogicRAG | 9.83 | 1777.9 |
注意这张表只统计 query-time 的开销,不包含建图。即便如此,LogicRAG 单次查询 1778 token,比 GraphRAG(4700)省 62%,比 LightRAG(5731)省 69%。如果把建图开销摊进去,差距会更夸张——GraphRAG 的 3500 万建图 token 即便摊到 1000 个 query 上,每个 query 还要分摊 3.5 万 token,跟 query-time 比是数量级的差异。
延迟上 LogicRAG 9.83 秒,比 vanilla RAG 慢一倍多(4.28 秒)。这是合理代价——多了 query decomposition、DAG 构建、多轮 retrieval、self-reflection 这些步骤。但比 GraphRAG(13 秒)和 LightRAG(35 秒)还是快很多。
4.4 top-k 的 Pareto 分析
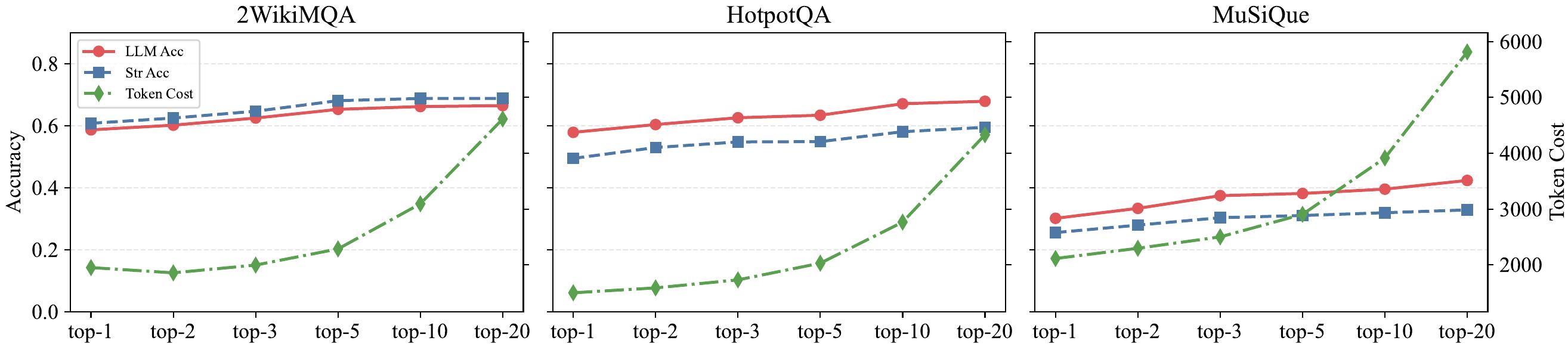
图5:top-k 增大时精度有提升但 token 成本陡增,作者建议 top-3 或 top-5 是最优工作点
这个分析是常规操作但有用。MuSiQue 上 top-20 时单 query 平均超过 6000 token,明显不划算。作者把 default 设成 top-3 是合理的工程选择。这也呼应了 context pruning 的设计动机——既然 top-k 大了边际收益递减还烧 token,那就不如把多轮检索的结果做 query-oriented summarization,只保留有用的。
五、我的判断
5.1 真正的贡献是什么
我读这篇论文时一直在问自己一个问题:它的核心创新到底是什么?
不是 query decomposition——那玩意 DSP、IRCoT 之前都做过。
不是 multi-step RAG——HippoRAG 系列、Self-Ask、ReAct 都是这个套路。
不是 DAG 建模——形式逻辑、知识图推理领域用了几十年。
真正的贡献是把"图"从一个全局静态结构挪到了 query-local 的临时结构。这个挪动的影响是结构性的:
- 离线建图开销变成零——这条单点就够 LightRAG / GraphRAG 路线认真反思了
- 图自动跟 query 形状对齐——避免了"通用图谱 vs 特定逻辑"的失配
- 知识库更新无成本——chunk + embedding 只需要增量索引,不用重建图
从 paper 看,作者的写作没把这层意思说得特别透。摘要里讲"adaptive reasoning structures",introduction 讲"avoid pre-built graph",但没有直接挑明"图的位置错了"这层批判。我觉得这是作者写作上的克制——不想把同行得罪太狠。但读者要识别出来。
5.2 哪些地方还可以挑挑刺
第一,DAG 构建的可靠性没有独立评估。整个方法的上限取决于 LLM 拆 query 的质量。如果 GPT-4o-mini 拆错了或者标错依赖,下游全错。论文给出端到端 accuracy,但没给"DAG 标注正确率",这其实是核心瓶颈。
第二,self-reflection 那部分实验细节偏少。论文说"如果当前答案不完整就动态加节点",但加多少次、多深就停下、加错了怎么办,这些都没展开。我猜实际实现里是有循环上限的,应该把超时/失败的比例也报一下。
第三,benchmark 偏简单。HotpotQA、2WikiMQA、MuSiQue 都是 multi-hop QA 的经典 benchmark,但每个 query 都是封闭、有明确答案的。真实业务里 RAG 经常面对 open-ended 问题(比如"帮我总结这个产品的市场反馈"),LogicRAG 的 DAG 拆解能不能处理这种 query,论文没回答。
第四,跟最新的 reasoning model 路线没有正面比较。OpenAI o1、DeepSeek-R1 这些 reasoning model 自己就能做 multi-step 推理,配上 vanilla RAG 也能拿不错的多跳 QA 分数。LogicRAG 用的是 gpt-4o-mini,没有跟 reasoning model 对比。如果 reasoning model 自己拆 query 的能力就足够强,LogicRAG 这套外部脚手架的边际价值有多大?这是个开放问题。
5.3 工程落地的启发
如果你正在做企业 RAG 或者 agent,LogicRAG 这套思路有几个可以直接借鉴的点:
第一,别再为整个语料建图了。除非你的语料完全静态、规模不大、查询模式固定,否则离线建图的 ROI 很难打正。把图放到 query-time,开销线性摊到每个查询上更可控。
第二,rolling memory 的 query-oriented summarization 很值钱。我们之前做长链路 agent 时也踩过这个坑——多轮 tool call 的输出累积到一定长度后,LLM 就开始忽略前面的关键信息。query-oriented summarization 比朴素拼接好得多,等于是给 memory 做了一次 attention pruning。
第三,graph pruning 的 unified subquery 思路在工程上很实用。你可以把它理解成"批量化 RAG 调用"——同优先级的并行子问题合成一个 retrieval,单次拿回所有相关 chunk。在 latency 敏感的产品里这能省一大半 round-trip。
第四,self-reflection 的退化情况要兜底。LLM 在长 query 上容易过度自信、提前收敛,这是论文自己观察到的现象。生产环境里需要硬性规则——比如 query 包含 N 个实体就至少跑 N-1 次 retrieval、置信度低于阈值就强制回到补充阶段。不能完全依赖 LLM 的自我评估。
第五,DAG 这层抽象可以扩展到更广的 agent 场景。如果你换个角度看,LogicRAG 的核心其实不是 RAG,而是"用 DAG 做 LLM 的 task scheduling"。把"检索"换成"工具调用",整套机制依然成立——decompose query → DAG dependency → topological execution → rolling memory → self-reflection。我自己觉得这是这篇论文最有迁移价值的地方。如果你在做 agent,把这套结构挪过去试试,多半能减掉很多冗余的 LLM round-trip。
六、结尾
LogicRAG 这篇论文的写作算不上炸裂,方法组件也都不新——decomposition、DAG、topological sort、summarization、self-reflection,每一个零件单拎出来都不是首次提出。但作者把它们拼起来后,对"GraphRAG 该不该预构图"这个问题给出了一个挺有杀伤力的回答:图错不在图本身,错在它被放在了离线。
这条路径如果继续往下走,我觉得会催生一批"运行时结构化推理"的方法:query-time DAG、query-time KG、query-time skill graph 都可能。原本"先建库再查询"的二阶段范式,会逐渐被"查询即构建"的一阶段范式蚕食。在 LLM 推理成本持续下降的趋势下,这个交易越来越划算。
如果你也在 RAG / agent 这条线上做工程,这篇论文值得花两个小时认真过一遍。把 GraphRAG 那条路的执念放下,可能是 2026 年做 RAG 系统的一个隐性优势。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我