给Claude 3.7一个GitHub仓库让它干活,54个真实任务它只做对了48%
AAAI 2026 | GitTaskBench:第一个系统评测"代码智能体复用GitHub仓库解决真实任务"能力的基准
一段话先把这事讲清楚
如果你最近在调 Claude Code、OpenHands、Cursor Agent 这类东西,可能也碰到过同一个尴尬:跑 SWE-Bench 的分数已经飙到 80 多了,号称"前沿",但你真把一个不太热门的 GitHub 仓库丢给它,让它"克隆下来跑通然后处理这张图片"——它经常死在 pip install 那一步。
GitTaskBench 干的就是这件事:把代码智能体真正放到一线开发者每天都在做的场景里——拿一个 GitHub 仓库,看懂它,配好环境,调用它的能力解决一个具体任务,然后把结果交出来。一共 54 个任务,覆盖图像、语音、视频、文档、生理信号、网页、安全 7 个领域。最强组合 OpenHands + Claude 3.7 的任务通过率(TPR)只有 48.15%,最近被 RepoMaster + Claude 3.5 推到 62.96%。看起来不算低,但真把错误掰开看:65% 的失败都死在环境配置和依赖解析这种"看起来不该卡"的地方。这篇 benchmark 的价值不在分数榜,在于它把代码智能体那层"前沿"光环揭开了一角,让你看到下面的脏活有多脏。
论文与作者
- 论文标题:GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
- arXiv ID:2508.18993v2(2025-09-14 修订)
- 作者:Ziyi Ni, Huacan Wang, Shuo Zhang, Shuo Lu, Ziyang He, Wang You, Zhenheng Tang, Yuntao Du, Bill Sun, Hongzhang Liu, Sen Hu, Ronghao Chen, Bo Li, Xin Li, Chen Hu, Binxing Jiao, Daxin Jiang, Pin Lyu(共 18 人,三位通讯作者:Huacan Wang、Daxin Jiang、Pin Lyu)
- 机构:UCAS、CASIA、BUPT、NUS、StepFun、HKUST、SDU、PINAI、USYD、PKU、USTC(中科院自动化所、阶跃星辰等多机构联合)
- 会议:AAAI 2026
- 代码与项目页:https://github.com/QuantaAlpha/GitTaskBench , https://gittaskbench.github.io/
为什么需要这样一个 benchmark
我先讲一个很直观的对比,能帮你理解作者到底在跟谁较劲。
过去两年代码 benchmark 卷得很猛,但你拉一个时间轴看,几乎所有线都在朝"代码生成本身"这个方向走:
- HumanEval、MBPP 在做单函数级别的代码生成;
- ClassEval、RepoBench、CrossCodeEval 把粒度从函数推到类,再推到仓库级别的代码补全;
- SWE-Bench 把"修一个 GitHub issue"作为终点,最近 Claude 4-sonnet 把它干到 80.2%,基本快饱和了;
- MLE-Bench、PaperBench 把场景换成"复现 ML 论文 / Kaggle 比赛",但说到底还是写代码。
这条线的问题是什么?写代码只是一个开发者一天工作里的一小段。真实场景里更高频的动作其实是这样的:
"我需要把这段语音去噪。GitHub 上有个 SpeechBrain,clone 下来,按它 README 的说明装环境、下权重、跑 inference,最后把降噪后的 wav 交出来。"
这件事不需要从零写一个降噪模型,但它要求智能体能:看懂仓库文档、装一个 Python 环境、解决依赖冲突、找对入口脚本、把 I/O 路径接上、最后把输出文件按格式交出来。它考的不是写代码的能力,而是用代码的能力。
GitHub 上有 2800 万个仓库、1.9 亿个公开项目——这是真实开发者天天都在用的"轮子库"。但之前的 benchmark 几乎没人系统地评测过:智能体到底能不能像一个会用 Google 的初级开发者那样,把这些轮子拿过来用上。
GitTaskBench 就是来填这个洞的。下面这张表是它跟现有同类 benchmark 的定位对比:
| Benchmark | 任务数 | 任务类型 | 多模态 | 复用仓库 | 仓库级生成 | 自动配环境 |
|---|---|---|---|---|---|---|
| RepoBench | 7778 | 代码补全 | ✗ | ✓ | ✗ | ✗ |
| SWE-Bench-Verified | 500 | 程序修复 | ✗ | ✓ | ✗ | ✗ |
| LiveCodeBench | 584 | 编程竞赛题 | ✗ | ✗ | ✗ | ✗ |
| MLAgentBench | 13 | ML 任务 | ✓ | ✗ | ✓ | ✗ |
| MLE-Bench | 72 | Kaggle 比赛 | ✓ | ✗ | ✓ | ✗ |
| PaperBench | 20 | 复现论文代码 | ✓ | ✗ | ✓ | ✓ |
| GitTaskBench | 54 | 用户向真实任务 | ✓ | ✓ | ✓ | ✓ |
注意最后两列。同时勾选"复用仓库"和"自动配环境"的,整张表只有 GitTaskBench 一个。这就是它最核心的占位。
benchmark 长什么样:54 个任务,7 个领域
先看张总览图,把 GitTaskBench 的输入输出格式建立起来:
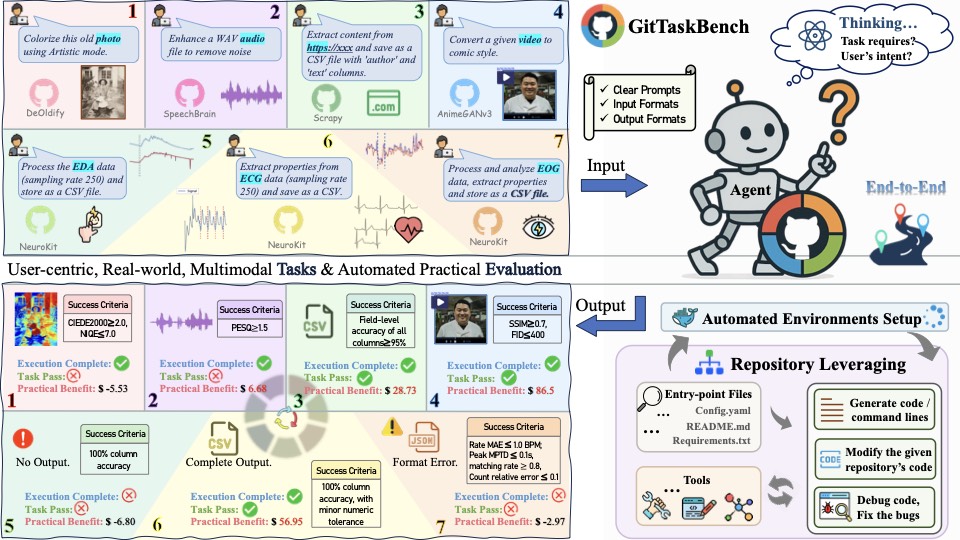
图1:GitTaskBench 总览。每个任务给定一个仓库(DeOldify、SpeechBrain、Scrapy、AnimeGANv3、NeuroKit 等)+ 一段自然语言指令,Agent 要端到端跑出符合"成功标准"的输出,最后还会算一个经济收益(绿色收入减红色成本)
每个任务的格式都长这样:
- 仓库:一个真实的、可运行的 GitHub Python 项目,星标 ≥50,最近 5 年有活动;
- 指令:一句自然语言描述,例如"用 Artistic 模式给这张老照片上色";
- 输入数据:图像/音频/CSV 等具体文件;
- 预期输出:可以是文件、文本、可视化结果,明确格式(比如 .jpg、.csv);
- 成功判据:具体的可计算指标,例如语音降噪要求 PESQ ≥ 2.0 且 SNR ≥ 15 dB,图像上色要求 CIEDE2000 ≤ 22 且 NIQE ≤ 7。
这套设计有两个细节我觉得做得很扎实:
第一,人类完成时间平均 1.34 小时(最长 3 小时)。说明这些任务不是"5 分钟脚本糊弄一下就能过"的,而是真正需要去看代码、搭环境、调参数才能跑通的。
第二,5 位计算机博士做了 100% 完成率验证。也就是说每个任务都是先由人按仓库 README 跑通过、产出过合格输出的,才会被收录。这就堵住了"任务本身就有问题导致谁都做不出来"的退路——失败一定是 Agent 的锅。
任务的领域分布看下面这张玫瑰图:
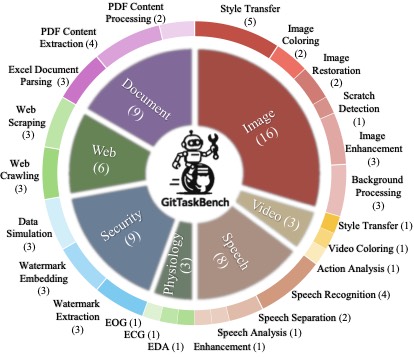
图2:任务领域分布。重头戏是图像处理(16 个)和生理信号(8 个),都是典型的"得装好深度学习环境 + 下权重 + 跑模型"的硬骨头任务
核心仓库统计也挺有意思(来自论文 Table 2):
| 维度 | 平均值 | 范围 |
|---|---|---|
| 仓库数 | 18 | — |
| 文件数 | 204 | 7–1157 |
| 类数 | 263.61 | 2–1130 |
| 函数数 | 1274.78 | 25–4915 |
| 依赖数 | 1242.72 | 33–6979 |
| 函数调用数 | 8651.28 | 180–40552 |
| 代码行数 | 52.63 K | 0.575 K–351.42 K |
| token 数 | 448.95 K | 4.87 K–2888.35 K |
最后一行很关键:单个仓库平均 44.9 万 token,最大的接近 290 万 token。这意味着哪怕你用 Claude 3.7 的 200K 上下文,也根本塞不下整个仓库。Agent 必须真的"会找路"——只读 README、只看入口脚本、按需 grep 关键模块——才有可能搞定。这也是为什么很多看似"长上下文很猛"的模型在这里反而吃亏。
数据是怎么造出来的:4 步严控
我特意翻了下他们的构建流程,这块写得比一般 benchmark 论文要细:
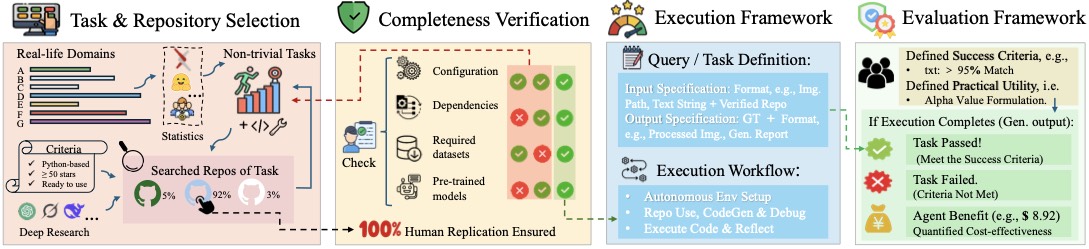
图3:构建流水线。注意"完备性验证"这一步是博士级人工去按仓库 README 跑通的,确保 100% 人类成功率,这是一个非常硬的质量门槛
四步流程拆开来讲:
- 领域与仓库选定:从用户日常需求倒推领域,再去 GitHub 找候选仓库。硬门槛是:Python 写的、≥50 stars、近 5 年有活动(含 issue 更新)、提供可下载权重和简单 setup。
- 完备性验证:人工按 README 完整跑通整个任务,验证仓库本身没有"暗坑"。如果某些资源被门控(比如要登录才能下权重),就把资源补齐、把外部说明 inline 进 README,做到 self-contained。
- 执行框架设计:Agent 收到的输入只有两个——仓库 + 任务定义 prompt。要求端到端:从理解仓库 → 生成/修改代码 → 配环境 → 执行 → 输出最终结果。
- 评测框架开发:每个任务都配手写的测试脚本,跑出来给一个 ECR(执行完成率)和 TPR(任务通过率)。所有 54 个任务一行 shell 命令就能批量跑完。
我特别想夸一下"完备性验证"这一步。坦率讲,很多 benchmark 在这块就是糊一下——拍脑袋选个仓库、看个 star 数就放进去,结果模型跑不通到底是模型的锅还是仓库自己年久失修,根本扯不清。GitTaskBench 这条 100% 人类成功率的硬门槛,把 Agent 失败的"借口空间"压到最小。
最关键的两个评测指标:ECR 和 TPR
这俩名字都是缩写,但区别挺重要,必须讲清楚。
ECR(Execution Completion Rate,执行完成率):Agent 有没有成功跑完,并且产出格式合法的输出文件。三个判据:(1) 输出文件存在、(2) 输出文件非空、(3) 输出格式能被测试脚本读取。
TPR(Task Pass Rate,任务通过率):在 ECR 通过的基础上,进一步看输出质量是不是达到了任务的成功判据。比如语音任务的 PESQ ≥ 2.0、图像任务的 CIEDE2000 ≤ 22。
这两个指标的差值很说明问题——ECR 高但 TPR 低,意味着 Agent 把脚本跑通了,但跑出来的东西质量不行。Claude 3.7 在 OpenHands 下 ECR 72.22%、TPR 48.15%,差距就是 24 个点,这 24 个点全是"跑通了但没跑对"。
α-score:把 token 成本和人工市场价拉进一个公式
这套指标算是论文的小亮点。作者觉得只看 ECR/TPR 不够——一个 Agent 哪怕通过率 100%,但跑一次烧 30 美元,而对应任务在 Fiverr 上人工价就 5 美元,这事就根本不该让 Agent 干。
于是他们提出了 α-score:
变量解释(结合工程直觉):
- \(T\):任务是否成功(0/1),与 ECR 一致;
- \(MV\):人工完成这个任务的市场价(从 Upwork、Fiverr、Freelancer 三个平台抓的真实报价,例如 Fiverr 上一张老照片修复约 10 美元);
- \(Q\):质量因子(0–1),由 5 位人工评审员对比 Agent 输出与人工 ground truth,从"远低于人类(0)、有大差距(0.25)、中等差距(0.5)、接近(0.75)、不可区分或更优(1)"五档投票,多数票胜出;
- \(C\):Agent 实际操作成本,约等于 API 调用费用。
这个公式我第一眼看到是有点眼前一亮的——它把"模型分数好不好"翻译成"这玩意儿到底值不值得用"。结果也很有意思(后面会讲):DeepSeek V3 的 α 反而是综合最高的,因为 token 太便宜;Claude 3.7 虽然成功率高,但成本经常吞掉收益甚至变负值。
不过我也得说一句实话——\(Q\) 因子靠 5 人投票打分,这块的主观性其实挺大的。论文里没给 5 个 rater 之间的一致性指标(比如 Cohen's kappa),所以严格讲这个分数的稳定性是一个开放问题。如果你打算引用 α-score,得心里有数。
重头戏:实验结果
测的框架是三个:Aider、SWE-Agent、OpenHands。LLM 涵盖 GPT-4o/4.1/o3-mini、Claude 3.5/3.7、Gemini-2.5-pro、DeepSeek-V3、Qwen3-8b/14b/32b、Llama3.3-70b。所有结果都是 2 次独立运行求平均。
先看主榜单(Up-to-Date Leaderboard),各个组合在 TPR 上的排名:
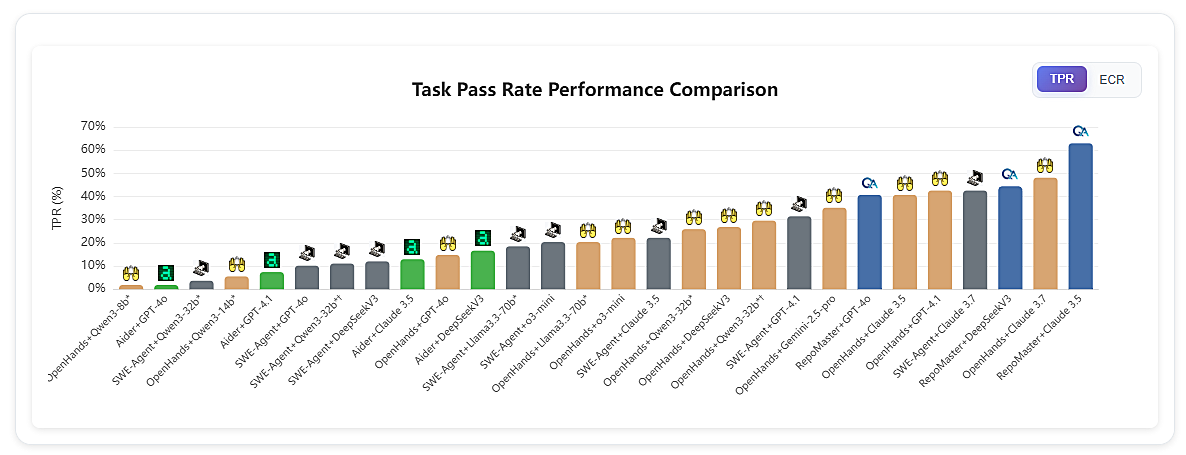
图4:横轴是不同的 Framework+LLM 组合,纵轴是 TPR。注意最右侧那批 60% 上下的成绩是 RepoMaster 这个新框架推动的,论文 v1 时的 SOTA 还停在 Claude 3.7 + OpenHands
完整数据表(论文 Table 3,我挑了关键行):
| Framework | LLM | ECR (%) ↑ | TPR (%) ↑ | Input tok (k) | Output tok | Cost ($) ↓ |
|---|---|---|---|---|---|---|
| Aider | GPT-4o | 5.56 | 1.85 | 10.67 | 492.67 | 0.0316 |
| Aider | DeepSeek V3 | 20.37 | 16.67 | 7.51 | 599.64 | 0.00269 |
| SWE-Agent | GPT-4.1 | 38.89 | 31.48 | 301.11 | 2098.33 | 0.661 |
| SWE-Agent | Claude 3.5 | 41.67 | 22.23 | 455.34 | 943.30 | 1.38 |
| SWE-Agent | Claude 3.7 | 64.81 | 42.59 | 552.79 | 807.63 | 1.67 |
| OpenHands | GPT-4.1 | 55.56 | 42.59 | 465.94 | 1535.47 | 0.942 |
| OpenHands | Claude 3.5 | 53.70 | 40.74 | 2858.00 | 24929.47 | 8.95 |
| OpenHands | Claude 3.7 | 72.22 | 48.15 | 9501.25 | 85033.05 | 29.8 |
| OpenHands | Gemini-2.5-pro | 51.85 | 35.19 | 760.88 | 35173.29 | 2.18 |
| OpenHands | DeepSeek V3 | 45.37 | 26.85 | 4717.78 | 31957.67 | 1.31 |
| OpenHands | Qwen3-32b (think) | 44.44 | 29.63 | 208.00 | 8755.35 | — |
| OpenHands | Llama3.3-70b | 27.78 | 20.37 | 132.69 | 872.93 | — |
挑几个让我有点感觉的点说说。
OpenHands 是综合最强的框架,但代价惊人。OpenHands+Claude 3.7 的 TPR 48.15% 是当时 SOTA,但跑一次 54 个任务的 token 成本是 29.8 美元——这个数字在 SWE-Agent+Claude 3.7 上是 1.67 美元,差了 17.8 倍。差距来自哪?看 Output token:OpenHands 用了 85033 个,SWE-Agent 只用了 807 个,差了 100 倍。OpenHands 的执行轨迹更长、更"探索式",确实换来了准确率,但烧钱也是真烧。
GPT-4.1 的性价比相当能打。OpenHands+GPT-4.1 拿到 ECR 55.56%、TPR 42.59%,TPR 跟 SWE-Agent+Claude 3.7 平手,但成本只要 0.942 美元——是 Claude 3.7 的 1/30。如果你真要在生产环境部署,这个组合可能是更现实的选择。
Aider 真的弱。所有组合 TPR 都没破 17%,最强的 Aider+DeepSeek V3 才 16.67%。我猜原因是 Aider 太聚焦"代码编辑"这一个动作,对"探索仓库 + 配环境"这种需要主动 trial-and-error 的工作流支持不够。
开源模型还是有差距,但 Qwen3-32B 让我有点意外。开 think mode 后,Qwen3-32B 在 OpenHands 下 TPR 拿到 29.63%,input token 还压到 208K(比 Claude 3.7 的 9501K 少 45 倍)。这说明思考链确实对仓库理解有帮助,而且推理优化模型在长上下文上反而比某些非推理大模型更稳。Gemini 2.5 Pro 在 think mode 下表现拉胯,论文给的解释是"长 token 任务里思考链反而成了上下文负担"——这一点其实很值得后面单独研究。
领域差异:纯文本任务 vs 多模态任务
主表只能看出"哪个模型好",但更细的洞察在领域分解里。看这张雷达图:
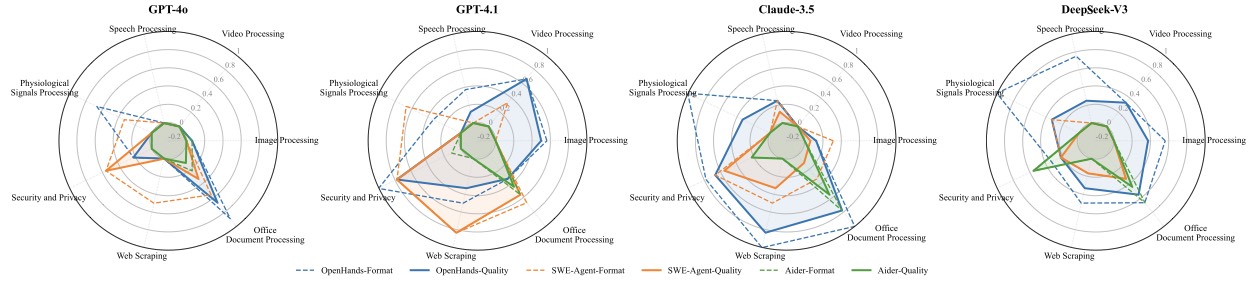
图5:横向看 4 个模型,纵向看 8 个领域。所有模型在 Office Document Processing(办公文档处理)上都表现很好,雷达图凸出明显;但在 Image Processing 和 Speech Processing 上几乎所有模型都瘫在中心点附近
这张图传递的信号其实很清楚:Agent 在纯文本的、API 调用型的任务上能打,但在涉及深度学习模型的多模态任务上几乎瘫痪。
为什么?论文给了一个很到位的解释。处理 Excel 用 Eparse、切 PDF 用 PyPDF,这些库的特点是:装一行 pip、import、调用一个 API 函数就完事了。整个工作流很浅。
但你看 DeScratch 这种图像修复仓库,完整流程是:
- 装 PyTorch + 一堆 vision 依赖;
- 处理 CUDA 版本兼容;
- 下预训练权重(可能在某个 Google Drive 上要爬过去);
- 配运行时参数(输入图像路径、输出尺寸、模型 ckpt 路径);
- 跑 inference,处理可能的 OOM;
- 把输出按指定格式存盘。
这个链条上任何一环出问题,结果就是输出空文件或者直接 crash。LLM 在每个独立子步骤上其实都"会",但把这些子步骤拼成一个能容错的端到端流水线,需要的是工程直觉——这个东西现在的 Agent 框架还没有给到。
我自己之前在搭某个图像处理 demo 的时候有过同样的体验:让 Cursor Agent 自己去 clone 一个 vision 仓库跑通,95% 的时间都在跟环境搏斗。它会反复尝试 pip install xxx==1.2.0 → 失败 → 换 1.3.0 → 又失败,有时候要 20 多轮才能爬出依赖地狱。这个 benchmark 用数据把这种感觉量化了。
超参数敏感性:timeout 和 max_iteration 真的关键
作者额外做了一组消融,证明"环境配置占用了大头时间"这个判断不是拍脑袋。
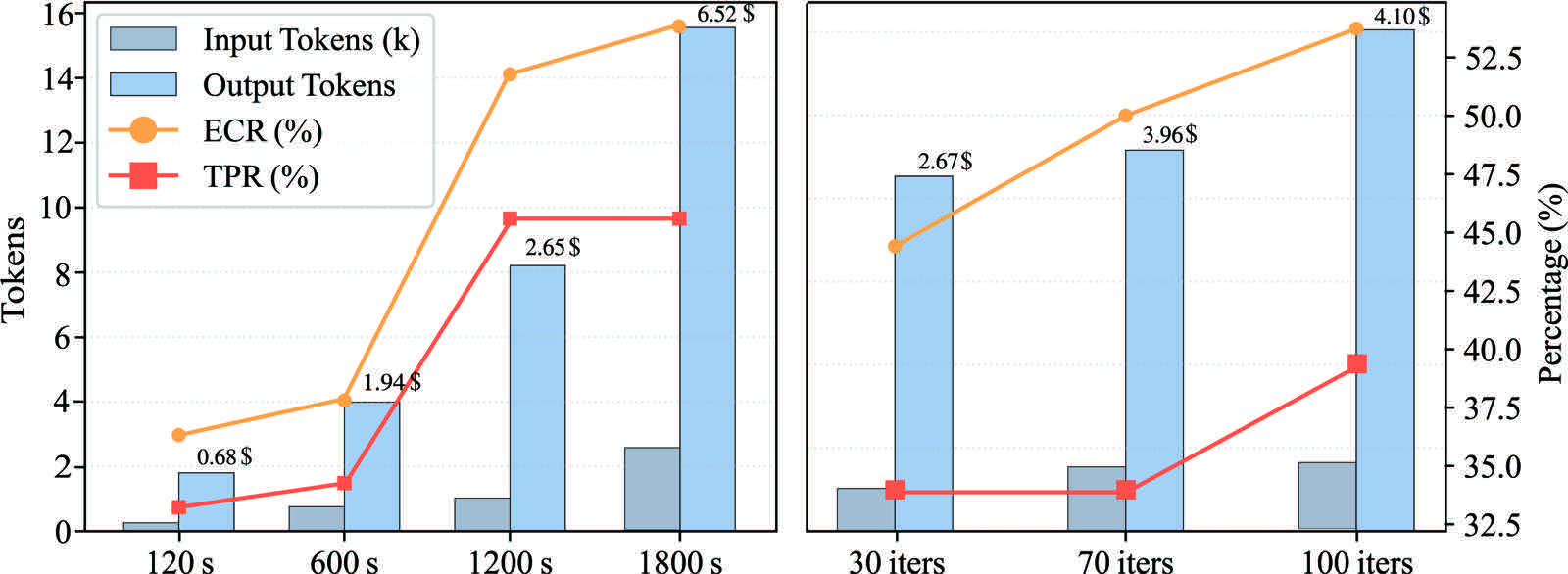
图6:左图横轴是 timeout(120s/600s/1200s/1800s),右图横轴是 max_iteration(30/70/100)。橙线是 ECR,红线是 TPR。timeout 从 120s 涨到 1800s,ECR 从约 36% 涨到约 56%,TPR 从约 33% 涨到约 45%;右图 max_iteration 从 30 涨到 100,TPR 也从约 33% 涨到 39%。代价是 token 用量和单次成本随之飙升(标注从 0.68 美元到 6.52 美元)
具体数据:把 timeout 从 120s 拉到 1800s,ECR 涨了约 20 个点、TPR 涨了约 12 个点;把 max_iteration 从 30 拉到 100,TPR 同样有稳定提升(约 6 个点)。代价是单次成本从 0.68 美元飙到 6.52 美元——长 timeout 不是免费午餐。
这个消融的工程含义是:Agent 失败的相当一部分原因不是它"不会",而是你给它的预算不够。pip install 一个含 CUDA 编译的包可能要 5 分钟,120s 的 timeout 直接超时;某个依赖冲突可能要 50 轮试错,30 步上限根本不够。
如果你在做 Agent 产品,这个发现挺实用的——别一上来就把超参数压得很紧追求"快",先放开让它把任务做完,再去优化中间的低效步骤。
α-score 的领域分布:哪些任务 Agent 干起来真的赚钱
回到经济价值这条线,看 α 在不同仓库上的分布:
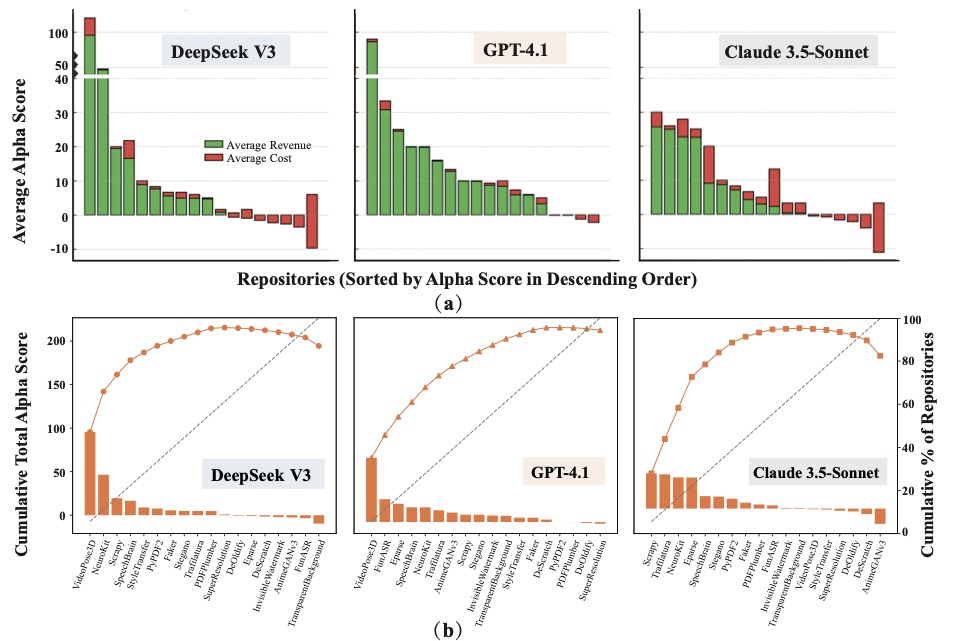
图7:(a) 三个模型在 18 个仓库上的 α 分解。VideoPose3D、FunASR、NeuroKit 这些任务 MV 高(人工市场价高),Agent 一旦做对就大赚;图像处理类任务 MV 普遍只有 5–10 美元,成本一上来就翻负。(b) 累积 α 曲线,越偏离 45 度对角线说明收益越集中在少数几个仓库
几个有意思的发现:
贵任务做对了就回本。VideoPose3D(3D 姿态估计)、FunASR(语音识别)、NeuroKit(生理信号分析)这类仓库,人工外包价能到 50–100 美元一单。Agent 哪怕跑一次烧 5 美元,只要做对了就净赚 50+。
便宜任务必须严控成本。图像处理类任务在 Fiverr 上市场价就 5–10 美元一单,Agent 跑一次烧 1–2 美元已经吃掉了大半,做错一次就亏本。
DeepSeek V3 是综合 α 最高的模型。虽然它的 TPR 不是最高的,但 token 单价便宜,成本一直压得很低,结果整体收益最大。Claude 3.5 在信息提取类任务上 α 很高,但碰到计算密集的视觉任务就开始亏。GPT-4.1 是最"稳"的——没有特别高的峰值,但也没有特别离谱的负收益。
我得说,这个分析角度挺刷新认知的。我们平时聊"哪个 Agent 强"的时候默认在比 TPR,但放到落地视角,DeepSeek V3 这种"中等 TPR + 极低成本"的组合可能才是真正能跑生产的。
错误分析:65% 的失败死在配环境
这是我个人觉得整篇论文最有价值的一部分。作者把所有失败 case 归成 5 类:
- E1:Environment Setup(环境配置)——依赖冲突、缺 binary wheel、缺系统库;
- E2:Workflow Planning(工作流规划)——卡在某个阶段下不去、执行顺序错;
- E3:Repository Comprehension(仓库理解)——找错入口脚本、API 用错;
- E4:Runtime(运行时)——超时、卡死、被 Ctrl+C 中断;
- E5:Fail to Follow Instructions(不遵循指令)——文件命名错、输出格式错、跳过仓库直接自己实现。
分布看下面这张图:
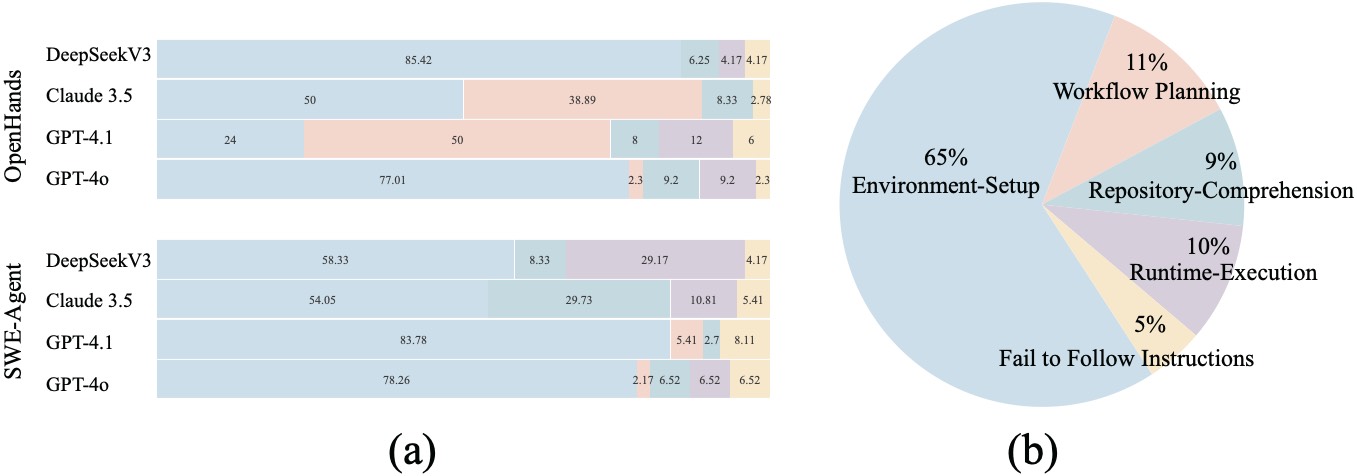
图8:右侧饼图最直观——65% 的失败是 E1 环境配置,11% 是 E2 工作流规划,10% 是 E4 运行时,9% 是 E3 仓库理解,5% 是 E5 不遵循指令
E1 占了 65 个百分点——这个数字我看到的时候真的愣了一下。它意味着:当我们说某个 Agent 解决不了仓库任务时,2/3 的情况它根本没机会展示自己会不会写代码,因为它在 pip install 这一步就死了。
而且这件事很反直觉:环境配置看起来是最"机械"的步骤,理论上应该是 Agent 最擅长的——查报错、装新版本、调环境变量。但现实中它恰恰是最容易失败的,原因可能在几个地方:
- 依赖地狱在 LLM 训练数据里没有显著表征。你看 GitHub README,几乎没人会写"如果你的 CUDA 是 11.8 那就装 torch 2.0.1,是 12.1 那就装 2.1.0"——这种隐性知识在训练语料里很少。
- 错误信息冗长且格式混乱。pip 失败时吐 200 行红字,LLM 在解析这种半结构化输出时容易抓错重点。
- 缺少持久化的经验记忆。Agent 这一轮试错学到的东西到下一轮就忘了,每次都得从头来。
E2(工作流规划,11%)的典型表现是 Agent 在 setup 阶段反复打转出不来;E3(仓库理解,9%)是找错了入口脚本;E5(不遵循指令,5%)有个特别有趣的情况——Agent 干脆绕开仓库,自己写了一份实现交差。说明它"知道"任务该怎么做,但就是不愿意去啃那个仓库。
观察 (a) 子图也挺有意思——OpenHands 上 DeepSeekV3 的 E1 错误占了 85%(异常高),而 GPT-4.1 的 E1 只占 24%、E2 反而占了 50%。这说明不同模型的失败模式是有"性格"的:DeepSeek 死于环境,GPT-4.1 死于规划。如果你要用 Agent,知道你的模型容易在哪一步崩,对部署策略很有指导意义。
我的判断:这篇论文值不值得花时间
先说结论:值得。但理由可能跟你想的不太一样。
这篇论文的真正价值不在"提出一个新方法"——它就是个 benchmark,没什么神奇的算法。它的价值在于把代码 Agent 这个领域里一个被刻意忽略的问题拍到了台面上:
"Claude 4 在 SWE-Bench 上 80.2%"和"OpenHands+Claude 3.7 在 GitTaskBench 上 48.15%",到底哪个更接近真实生产场景的能力?
我个人的答案是后者。SWE-Bench 的任务都在预配置好的环境里、目标是修一个 bug——这是一个相对干净、约束很强的设定。GitTaskBench 把"自己装环境、自己找入口、自己处理报错"这层脏活加进来后,分数立刻被砍掉一半。这个差距才是 Agent 距离真正"能干活"的真实距离。
论文做得不错的地方:
- 任务的真实性。54 个任务都是博士级人工跑通过的,配的成功标准都是该领域成熟的指标(PESQ、CIEDE2000 这些),不是拍脑袋的。
- α-score 这个角度。把成本-收益拉进评测,比单看 TPR 更接近落地视角。哪怕你不认可这个具体公式,"评测 Agent 必须考虑经济性"这个观点是站得住的。
- 错误分析。 这块给了非常具体的工程指引,告诉你做 Agent 要重点优化哪些地方(dependency management、execution planning、resource handling)。
我觉得有点遗憾的地方:
- 任务规模偏小。54 个任务、18 个仓库,统计意义上不算大。某些领域(视频、语音)只有 3 个任务,得出"agent 在视频任务上不行"这种结论的样本量是有点单薄的。
- Q 因子的主观性没量化。5 人投票的一致性是多少?没说。这块想严谨化的话需要补 inter-rater reliability 指标。
- 缺 RepoMaster 的对比细节。论文摘要提到 RepoMaster+Claude 3.5 把 SOTA 推到 62.96%,但正文里这个新框架并没有展开。考虑到这是它当时最关心的"前沿"参照点,少了这部分有点可惜。
- 没有 think-mode 时间开销分析。Qwen3-32B 开 think mode 涨了 18 个点 TPR,但 think 本身要花多少时间?没说。这对实际部署很重要。
对工程的启发
如果你正在做代码 Agent,或者在评估要不要把 Agent 接进生产,这篇论文有几个直接可用的 takeaway:
- 不要只看 SWE-Bench 分数。它代表的是"理想环境下修 bug"的能力,跟"在真实仓库上端到端跑任务"是两件事。建议用 GitTaskBench 这种 benchmark 做二次验证。
- 环境配置是当前 Agent 最大的瓶颈。如果你做产品,与其训练更聪明的模型,不如先做好这几件事:缓存常用依赖镜像、维护一个"成功配置模板库"、给依赖冲突准备 fallback 链。
- timeout 和 max_iteration 不要压得太紧。120s 的 timeout 在涉及 CUDA 编译的场景下根本不够,建议至少 600s 起步。
- 选模型要看场景。纯文本任务用 GPT-4.1 性价比最优;多模态/计算密集型任务上 Claude 3.7(如果预算够),DeepSeek V3 是综合 α 最高的折中选择。
- 对低 MV 任务要严控成本。图像处理这种单价 5–10 美元的任务,Agent 跑一次成本必须压到 1 美元以下才有商业价值。Aider+DeepSeek V3 在这种场景下可能比 OpenHands+Claude 更合适。
- 错误处理优先级:E1(环境)→ E2(规划)→ E4(资源)→ E3(仓库)→ E5(指令)。按这个顺序投入资源 ROI 最高。
最后留一个问题
我看完这篇之后一直在想一个事——既然 65% 的失败都死在环境配置,那解决这个问题最自然的思路是什么?
一个方向是给 Agent 装一个工程师人格——让它在环境配置阶段表现得像一个有经验的运维:先扫一遍 README 找硬约束,再用 conda/uv 这类工具锁定版本,依赖冲突时降级而不是升级。
另一个方向是预编译镜像 + 仓库特征匹配。给每个常见仓库打 tag,当任务进来时直接 load 对应的预配好的 Docker 镜像。这其实就是把"环境配置"这个动作从 Agent 运行时提到 benchmark 准备时——但这样做又违背了"测试 Agent 自主配环境的能力"的初衷。
哪条路更合理?我自己也还没想清楚。但我直觉是:短期内第二条路更工程友好,长期看第一条路才是 Agent 真正能"独立工作"的方向。
如果有读者在做这块,欢迎交流。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我