给投机解码的草稿模型加一个"耳麦":从验证器隐藏态算 steering 向量,接受 token 数最多多 35 个百分点
核心摘要
投机解码(Speculative Decoding)现在几乎是大模型推理加速的标配。原理也朴素:让一个小模型先猜 k 个 token,让大模型一次性并行验证,验证通过的就直接采用。问题在于,小草稿模型猜得对不对,取决于它和大模型在分布层面对得齐不齐——这是绝大多数论文反复在做的事。
主流是两条路。一条是把草稿头直接挂在 verifier 顶上从零训练(EAGLE-3、Medusa 这类),靠访问 verifier 的中间表征强行对齐,缺点是接受的 block 通常较短;另一条是直接用一个独立的小型预训练 LLM 作为草稿模型,它本身就会写句子,接受率高,但和 verifier 的对齐只能靠离线手段(比如蒸馏),一旦推理时上下文偏离训练分布就掉点。
这篇 ETH Zürich 的 AAAI 2026 论文要做的事很简单——给独立的预训练草稿模型加一个轻量级的"耳麦":从 verifier 的高/中/低三层隐藏态里算一个 steering 向量,注入到 drafter 每一层 MLP 的 SwiGLU 上投影里去当偏置项。代价几乎为零,但能让接受的 token 数比蒸馏的版本最多再涨 35 个百分点(采样)和 22 个百分点(greedy),同时保留住预训练模型在长序列、跨任务上的泛化能力。
我个人觉得这篇论文最有价值的不是数字,而是它把"激活引导"这套以前主要用来做对齐安全、行为控制的技术,干净利落地搬到了投机解码里。这个跨领域迁移做得很漂亮。
论文信息
- 标题:Steering Pretrained Drafters during Speculative Decoding
- 作者:Frédéric Berdoz、Peer Rheinboldt、Roger Wattenhofer
- 机构:ETH Zürich(苏黎世联邦理工)
- 会议:AAAI 2026
- arXiv:2511.09844
- 代码:https://github.com/ETH-DISCO/SD-square
- 方法名:SD²(Steered Speculative Decoding)
一、为什么会有这篇论文:投机解码里那个永远的痛
先简单回顾一下投机解码的基本盘,因为后面所有讨论都建立在这个语境上。
投机解码的核心动机:自回归生成是串行的,一个 token 接一个 token 出,GPU 大量算力被浪费在等待 KV Cache 和参数加载上。投机解码的招式是让一个轻量 drafter 先一口气猜出 k 个候选 token,然后让 verifier(大模型)用一次前向把这 k 个 token 的概率分布全部算出来,再用拒绝采样(Rejection Sampling)逐位验证。被接受的 token 直接拿走,被拒的位置从联合分布里重采一个,整个 block 的吞吐就这么上来了。Leviathan 等人 2023 年那篇经典论文证明了这个过程是无损的——最终生成的 token 分布严格等于直接用 verifier 跑出来的分布。
听起来很美。但工程上的核心矛盾很尖锐:
drafter 猜得越准,单 block 吞吐越高;但 drafter 越准往往意味着它越大,drafting 本身的延迟就成了新瓶颈。
围绕这个矛盾,社区分成了两派。
1.1 依赖式草稿头:EAGLE / Medusa 这一脉
第一派把草稿头直接挂到 verifier 上,让草稿头能直接读 verifier 的隐藏态。代表作是 Medusa(Cai et al. 2024)和 EAGLE 系列(Li et al. 2024、2025)。这一派的逻辑是:既然要对齐 verifier,干脆让 drafter 直接看到 verifier 的内部状态。EAGLE-3 进一步把高、中、低三层的 hidden states 拼接起来喂给 drafter,让对齐做到极致。
这套方案的优点是 drafter 极小(往往只有几层 transformer),延迟可以忽略;缺点是它说到底是"特化"产物,没有独立生成能力,泛化性受限——一旦输入分布偏离训练数据,接受率掉得很快。
1.2 独立式草稿模型:直接用一个小 LLM
第二派直接用一个独立的预训练小 LLM 作为 drafter,比如用 Llama 160M 给 Vicuna 13B 起草,用 Qwen3 0.6B 给 Qwen3 14B 起草。这类 drafter 因为本身就是一个完整的 LLM,泛化能力强,跨任务掉点少,长上下文也撑得住。
但问题在哪?它和 verifier 的对齐只能靠离线手段——常见做法是蒸馏(DistillSpec),让 drafter 的输出分布去逼近 verifier。蒸馏是 offline 的,一旦训练数据分布和推理数据分布不一致,它的对齐就退化了,甚至会比未蒸馏的 baseline 还差。
我之前在调一个类似的小模型蒸馏方案时,碰到过特别明显的现象:在训练分布内的对话任务上蒸馏版本能涨不少,但一切到代码生成、数学题这种"严肃"任务,蒸馏版本反而比原始预训练版本掉 5%—10% 的接受率。论文里 Llama 3.1 + Llama 3.2 那一组就是教科书级别的复现:在 GSM8K 和 HumanEval 上,蒸馏版本反而比 Pretrained 还差。
1.3 论文要解决的问题
作者的诊断很清晰:预训练草稿模型 + 蒸馏的组合,泛化好但对齐死板。能不能让对齐变成在线的、动态的,根据当前生成上下文实时调节?
这就引出了 SD²(Steered Speculative Decoding,作者用的简称是 \mathrm{SD}^2,下文按习惯写 SD²)。
二、方法核心:从 verifier 隐藏态里"挤"出 steering 向量
2.1 一张图看清三种 drafter 范式
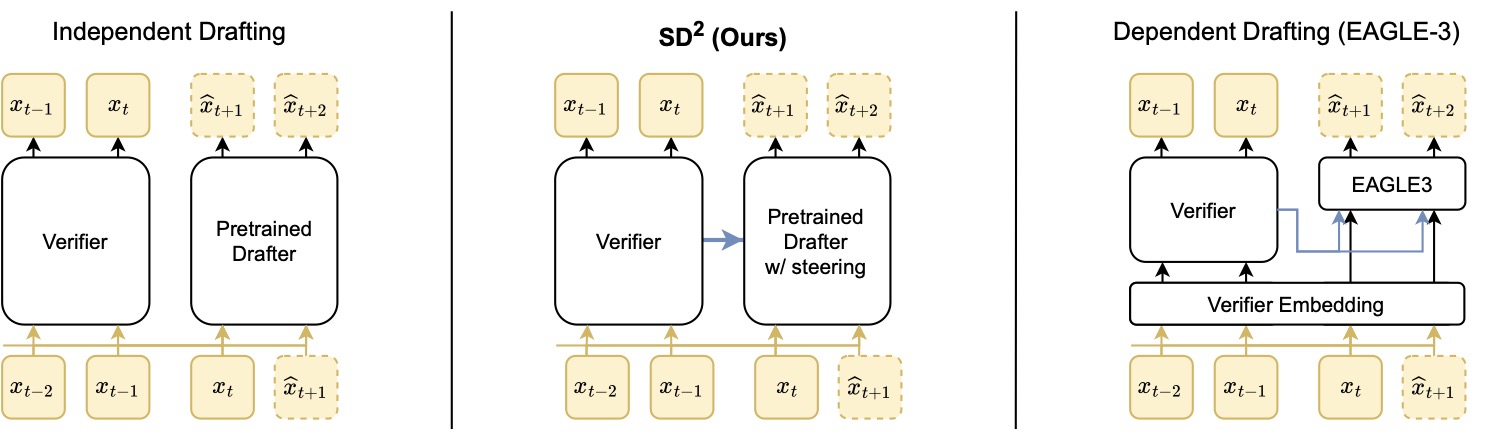
图1:三种草稿范式的对比。左边是传统 Independent Drafting,drafter 完全独立,看不到 verifier 内部。右边是 EAGLE-3 这种依赖式范式,drafter 共享 verifier 的输入嵌入,并把 verifier hidden states 拼接成特征喂进去。中间的 SD² 走折中路线:drafter 还是一个完整的预训练 LLM,但在每次 verification 之后,从 verifier 的隐藏态里抽出一个轻量的 steering 向量,注入 drafter 来做动态对齐。
这张图把 SD² 在生态里的定位说得很清楚。SD² 不是另起炉灶训练一个新 drafter,而是在已有的预训练 drafter 基础上加一个低成本"接口",让它能动态读 verifier 的"意图"。
2.2 steering 向量从哪儿来
作者的核心观察来自 Samragh et al. 2025 的一个有意思的发现:自回归 LLM 的中间隐藏态会隐式编码未来若干 token 的信息,即使它从来没有被明确训练去做这件事。你想想看,verifier 在算第 t 个 token 时,它的中间层激活里其实已经"知道"接下来几个 token 大概会是什么。
SD² 要做的就是把这个"未来信号"挤出来。
具体怎么挤?借鉴 EAGLE-3 的做法,从 verifier 的三个不同深度——高层 \(h_t\)、中层 \(m_t\)、低层 \(l_t\)——抽取激活,拼接后通过一个线性层 \(W_{hml}\) 投影:
这个 \(g_t\) 就是 steering 向量。注意它是在 verification 阶段顺手算出来的,因为反正 verifier 都要做一次完整的前向,hidden states 本来就在那儿,几乎是零额外开销。
2.3 怎么注入到 drafter 里
这是整个方法最巧的地方。
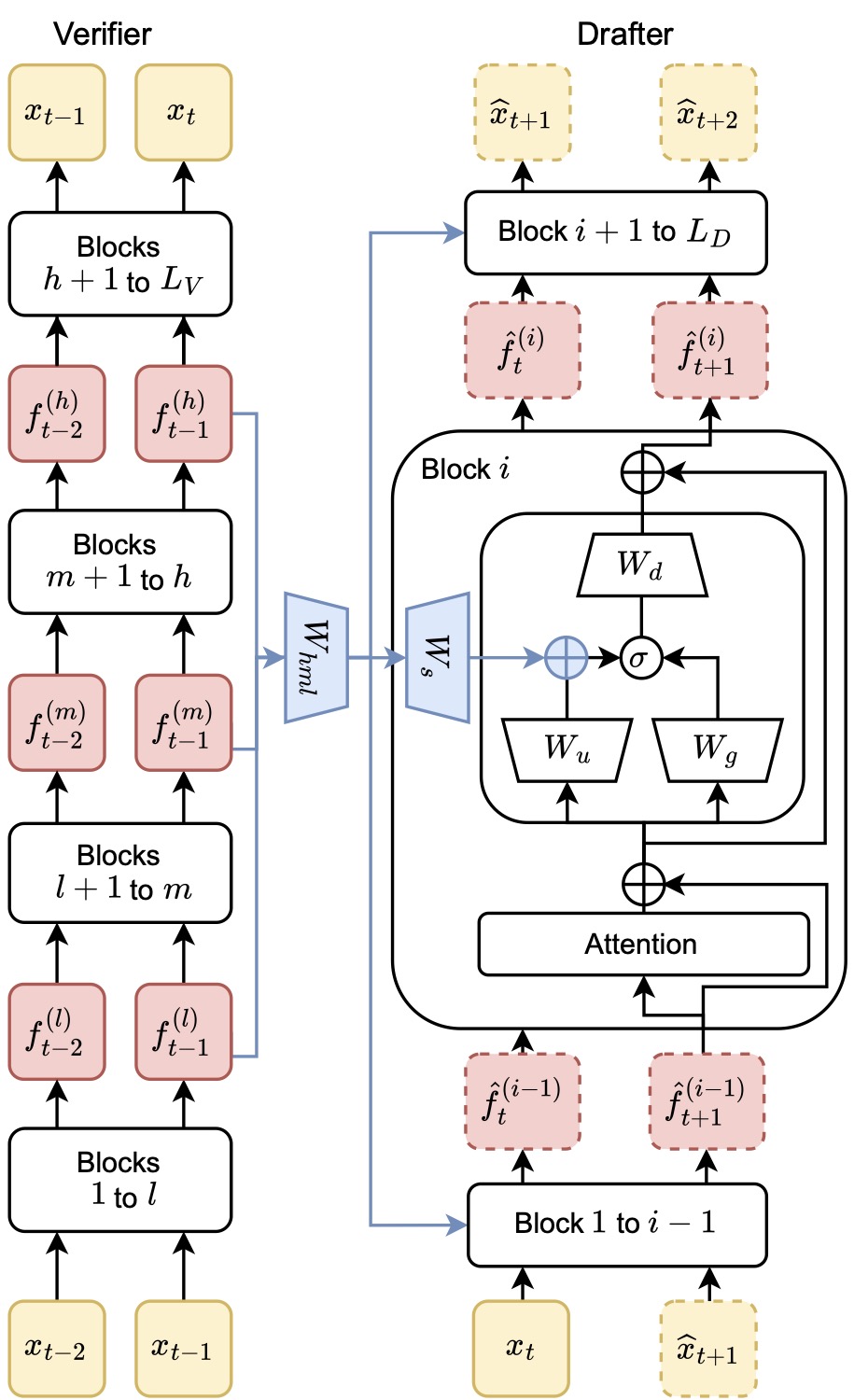
图2:SD² 的 steering 机制详细架构图。左边是 verifier,从底到顶分别抽 low / medium / high 三层激活;中间通过 \(W_{hml}\) 投影成 steering 向量 \(g_t\);右边是 drafter 的每一个 transformer block 内部,\(g_t\) 再经过 \(W_s\) 变成 bias,被加到 SwiGLU 的上投影路径里。
SwiGLU 是现代 LLM 标配的激活函数,原本计算是这样:
其中 \(W_u\) 是上投影、\(W_g\) 是 gate、\(W_d\) 是下投影。SD² 把它改成:
差别就一处:在上投影输出的位置加一个偏置项 \(W_s g_t\)。
这里有几个工程细节值得说道:
第一,\(W_s g_t\) 在每个 drafting 阶段只算一次。 因为它和 drafting 位置 \(i\) 无关,所以 drafter 在猜接下来 8 个 token 的整个过程中,这个 bias 是常数,可以缓存。
第二,bias 加在 gate 之前还是之后?作者做了消融,加在 SwiGLU 上投影 + gate 之前的位置(也就是 \(W_u a + W_s g_t\))效果最好,比简单地加在 MLP 输出之后好。原因不难想:gate 之前注入意味着 steering 向量会和当前 token 的内容做交互(被 \(\sigma(W_g a)\) 过滤),而不是粗暴的全局偏移,控制粒度更细。
第三,steering 还会影响 attention 的 K/V。因为 MLP 输出会进入下一层 attention 的输入,所以 steering 向量的影响会"渗透"到注意力计算里去。这意味着 drafter 在猜第 \(i\) 个候选 token 时,不只受当前 \(g_t\) 影响,还受所有历史 \(g_{t'}\) 的影响——steering 是有"记忆"的。
2.4 训练目标:随机 offset + KL 散度
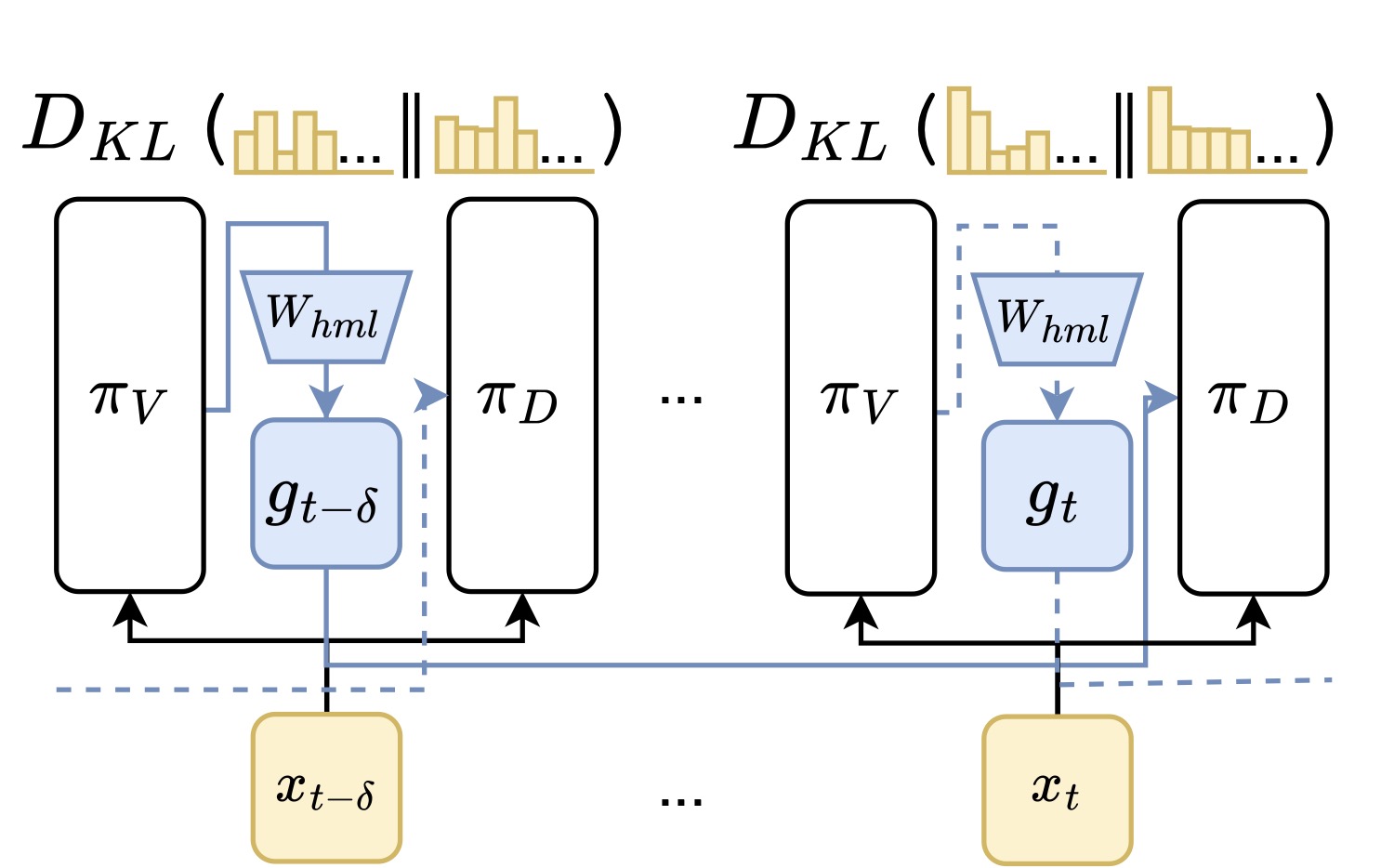
图3:SD² 的训练流程。每个训练步随机抽一个 offset \(\delta \in [1, k]\),让 drafter 用 \(g_{t-\delta}\) 去预测 \(\pi_D(x_t | x_{1:t-1}, g_{t-\delta})\),损失是 verifier 与 drafter 输出分布的 KL 散度。这样 steering 机制必须学会编码"未来 \(k\) 个位置"内的信息,而不是只懂"下一步预测"。
训练这套机制需要解决一个细节:drafter 在投机解码里要连续猜 k 个 token,但 steering 向量只在 block 起点算一次。也就是说,drafter 在猜第 1 个 token 时用的是最新的 \(g_t\),但猜第 8 个 token 时用的还是同一个 \(g_t\)(已经过期了 7 步)。
如果训练时只用 \(g_{t-1}\) 去预测 \(x_t\),模型就只会"看一步",长 block 上必然崩。
作者的处理是随机化:每步训练时均匀随机抽一个 offset \(\delta \in [1, k]\),让 drafter 用 \(g_{t-\delta}\) 去预测 \(\pi_D(x_t | x_{1:t-1}, g_{t-\delta})\)。这样 steering 机制就被迫学会"通过这一个 \(g\) 编码未来 \(k\) 步内的所有 token 信息"。
损失函数选的是 KL 散度(DistillSpec 那篇论文的结论是 KL 比 TVD 更好用)。verifier 全程冻结,drafter 和 steering 模块(\(W_{hml}\)、\(W_s\))一起训练。
2.5 一个关键的初始化技巧
\(W_s\) 初始化为 0,\(W_{hml}\) 初始化成让 \(W_{hml}[h_t, m_t, l_t]^\top = h_t + m_t + l_t\)。
这个细节特别重要,作者在论文里说"如果不这么初始化,模型会发散"。我能理解为什么——\(W_s = 0\) 意味着在训练初期,steering 向量根本不影响 drafter 的输出,drafter 看上去就是它原本预训练的样子。然后 \(W_s\) 慢慢从 0 长出来,学会哪些方向能提升对齐。如果一开始就让 steering 全力干预,预训练 drafter 的内部表征会被一个还没学好的随机投影撕得稀烂,loss 直接爆炸。
工程上类似的技巧很常见,比如 LoRA 把一个矩阵初始化成 0,让 adapter 从恒等变换开始演化。SD² 这里是同一个直觉。
三、实验结果:数字到底有多硬
3.1 主表:4 组 verifier-drafter × 5 个数据集
实验配置覆盖了从极不对齐到很对齐的全谱:
| Verifier | Drafter | 容量比 | 同源? |
|---|---|---|---|
| Vicuna 1.3 13B | Llama 160M | 81× | 否(不同训练数据) |
| Qwen3 14B | Qwen3 0.6B | 23× | 是 |
| Qwen3 8B | Qwen3 0.6B | 13× | 是 |
| Llama 3.1 8B-Instruct | Llama 3.2 1B-Instruct | 8× | 是 |
数据集:UltraChat(对话,训练分布内)、HumanEval(代码)、XSum(摘要)、Alpaca(指令跟随)、GSM8K(数学推理)。其中只有 UltraChat 是训练用过的,其他 4 个全是 OOD(分布外)测试。
主表的结果非常长,挑几组关键数字:
Vicuna 1.3 13B + Llama 160M(容量比最大、最不对齐的一组)
| 方法 | UltraChat τ | HumanEval τ | XSum τ | Alpaca τ | GSM8K τ | 平均 τ | 平均加速 α |
|---|---|---|---|---|---|---|---|
| Pretrained | 1.93 | 1.68 | 2.08 | 1.83 | 1.90 | 1.88 | 1.00 |
| Distilled | 2.90 | 2.50 | 2.13 | 2.50 | 2.22 | 2.45 | 1.32 |
| SD² | 3.45 | 3.19 | 2.46 | 2.99 | 2.72 | 2.96 | 1.61 |
T=1 采样下,SD² 平均 block efficiency 从 1.88 涨到 2.96,吞吐快了 61 个百分点。在训练分布内的 UltraChat 上更是从 1.93 一路冲到 3.45,吞吐快了 83 个百分点。
Llama 3.1 8B + Llama 3.2 1B(容量比最小、原本就对齐很好的一组)
| 方法 | 平均 τ | 平均 α |
|---|---|---|
| Pretrained | 4.91 | 1.00 |
| Distilled | 4.78 | 0.97 |
| SD² | 5.00 | 1.00 |
这组就很有意思了——原始预训练版本本来就跟 verifier 对齐得不错(同一家族、同一训练数据),蒸馏反而变差了,SD² 也只是勉强追平 Pretrained。
这两组数据放一起看,结论挺有趣:SD² 的边际效益和"原始对齐程度"成反比——drafter 本来就和 verifier 同源、对齐得好,那 SD² 没什么发挥空间;drafter 是从外面拉来的小模型、和 verifier 八竿子打不着,SD² 就能创造奇迹。
3.2 不同模型组合下的接受 token 数
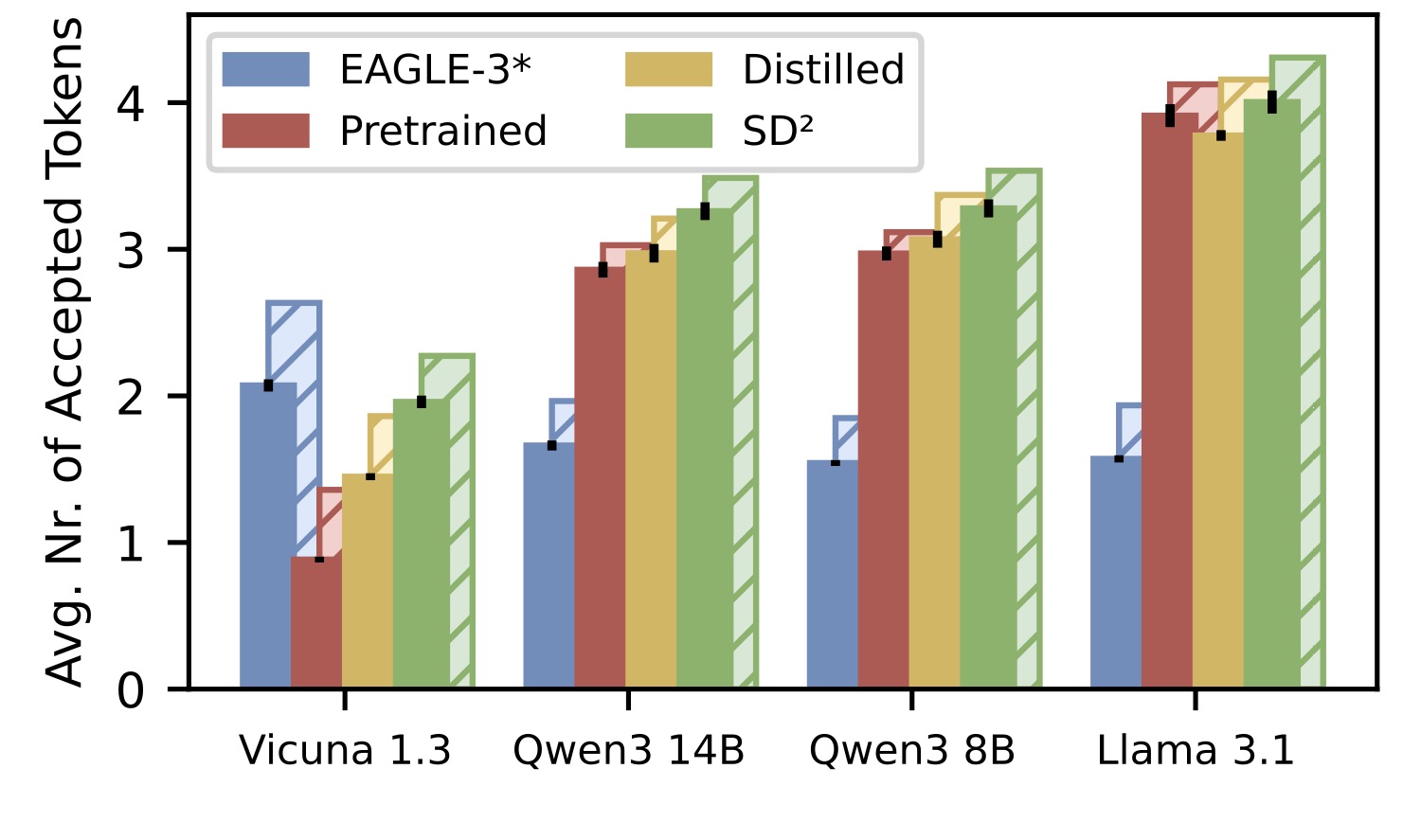
图4:四种方法(EAGLE-3、Pretrained、Distilled、SD²)在四组 verifier-drafter 配对下,每个 block 平均接受的 token 数。SD² 在所有配对里都是最高的。Vicuna 那组(最左)特别值得注意:Llama 160M 的活跃参数量还不到 EAGLE-3 的一半,原始预训练 drafter 接受率被 EAGLE-3 完全压制(Pretrained 0.9 vs EAGLE-3 2.0),但加了 SD² 之后追到 2.0+,把架构差距拉平了。
这张图最值得看的是 Vicuna 那一组。Llama 160M 在 EAGLE-3 面前原本是被吊打的——参数量只有人家的不到一半,原始 Pretrained 接受率不到 1.0。但加了 SD² 之后,Llama 160M 的 SD² 版本和 EAGLE-3 打平,证明独立式 drafter + 动态 steering 这条路,在小模型尺度也能和依赖式范式掰手腕。
3.3 OOD 任务上的对比:SD² 不会像蒸馏那样过拟合
这是论文里我最看重的一个结论。
蒸馏的最大问题是过拟合训练分布。回看 Llama 3.1 + Llama 3.2 在 HumanEval 上的数据,Pretrained 是 6.43,Distilled 掉到 6.25,SD² 是 6.49。蒸馏掉了 0.18,SD² 反而微涨。
为什么 SD² 不容易过拟合?我的理解是这样:蒸馏是把 drafter 的整体参数都向训练分布"拽"过去;而 SD² 是给 drafter 加了一个"开关",drafter 主体仍然保留预训练时的能力,只在每次推理时根据当前 verifier 的隐藏态做局部调节。当推理上下文偏离训练分布时,steering 顶多是"指路指得不准",但不会把 drafter 主体能力毁掉。
这个性质在长序列生成上也成立。
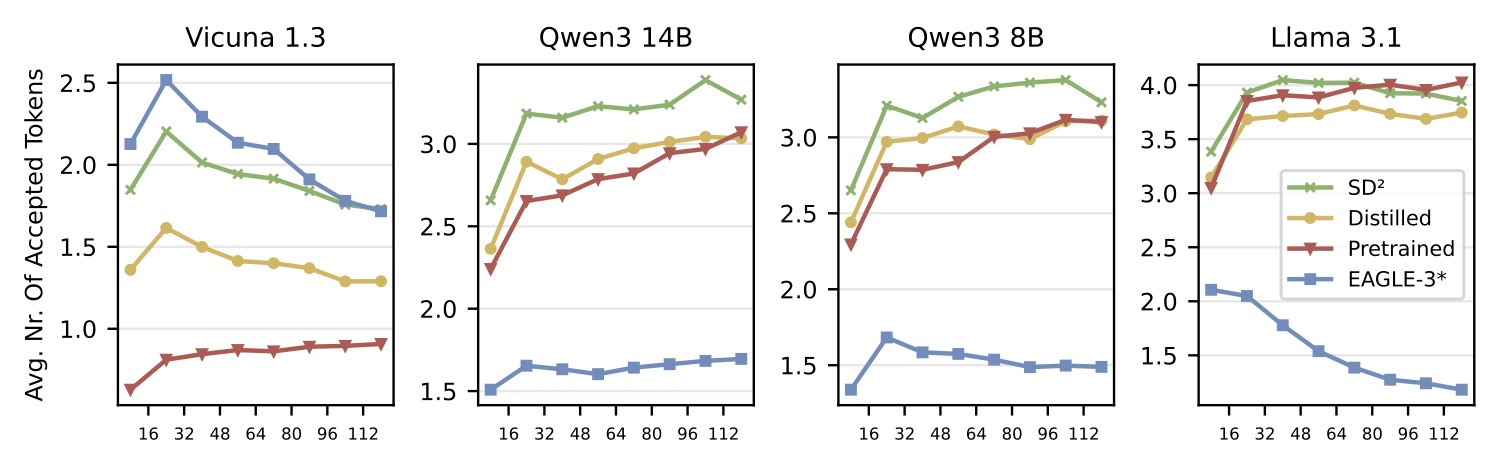
图5:不同方法在长序列不同位置上的 block 接受 token 数。横轴是当前 block 末尾 token 的位置,纵轴是该位置附近 block 平均接受了多少个 token。预训练 drafter 因为见过大量长文本,长序列性能不掉;SD² 在它之上做了"非破坏性"增强,优势在整段序列上保持稳定。
这张图的信号很清楚:SD² 没有侵蚀预训练 drafter 在长序列上的优势。它只是在每个位置上稳定增加 0.3—0.5 个 token 的接受量,不挑序列位置。
3.4 一段定性对比:HumanEval 上三种 drafter 的输出
论文里有一张特别有意思的定性对比(Table 2)。同样的 HumanEval 任务("判断列表里是否有任意两个数距离小于阈值"),三种 drafter 输出长这样(绿色被接受、红色被拒、蓝色是 verifier 重采):
- Pretrained:
Here is the implemented Python function...—— 只接受了 "Here is the implemented Python functionhas" 这个开头,立刻就被 verifier 拒了大段,重采为To。 - Distilled:开头几乎一样,被拒得也类似。
- SD²:
To solve the problem, we need to determine whether any two numbers in a list are closer to each other than a given threshold...—— 一气呵成接受了一长段语义连贯的英语。
这段对比很说明问题。SD² 不只是数字上接受率高,它生成的是和 verifier 风格一致的连贯文本。也就是说,steering 向量真的把 verifier 的"意图"传递了过来。
但作者也老实指出了一个有意思的副作用:在某些位置,steering 会让 drafter 产生英文字母表之外的奇怪 token(论文里用 [?] 标注)。这是 hidden state 干预的固有风险——你在改一个高维表征,改得稍微偏一点点,模型就可能输出乱码。这是个 honest 的承认,比那种只放好结果的论文要踏实。
四、消融:为什么是这个 steering 机制、为什么要解冻 drafter
4.1 三种 steering 机制对比
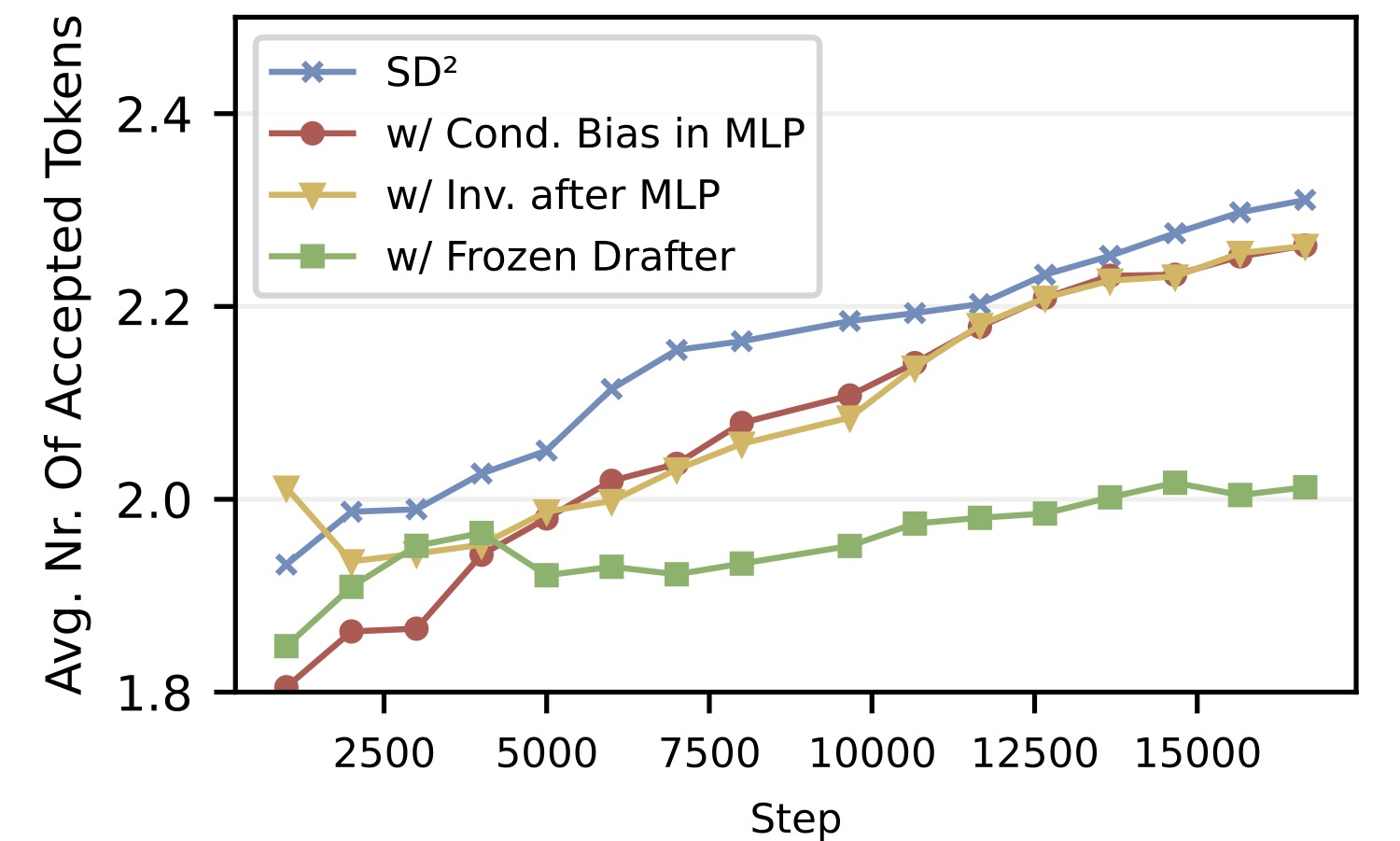
图6:消融实验,对比三种 steering 注入方式 + 冻结 drafter 变体在 Vicuna 1.3 7B + Llama 160M 上的接受 token 数随训练步数变化。SD²(蓝线,把 bias 加进 SwiGLU 上投影内部)始终领先;变体 Inv. after MLP(黄线,把 bias 直接加到 MLP 输出后面)和 Cond. Bias in MLP(红线,bias 还依赖于上一层激活)相近且都不如 SD²;Frozen Drafter(绿线,只训 steering 不训 drafter)明显落后。
作者评估了三种注入方式:
- MLP 之后加 bias(最简单):\(\tilde{f}^{(l)} = f^{(l)} + W_s g_t\)
- MLP 上投影里加 bias(SD² 选用):见公式 \(W_u a + W_s g_t\)
- 条件 bias:bias 不仅依赖 \(g_t\),还依赖上一层激活 \(f^{(l-1)}\)
三种里第 2 种胜出。我的理解是:第 1 种是粗暴的全局偏移,drafter 没机会过滤;第 3 种参数太多,反而难训;第 2 种正好——bias 进入 SwiGLU 的 gate 通道,能被 \(\sigma(W_g a)\) 自适应过滤,控制粒度刚好。
4.2 解冻 drafter 提升明显
论文还做了一组重要消融:只训 steering(drafter 冻结)vs 同时训 drafter 和 steering。结果是:
- 冻结 drafter,光靠 steering 也能让接受 token 数从基线 1.0 涨到 ~2.0(涨 100 个百分点);
- 解冻 drafter 一起训,能涨到 ~2.3。
这个结果挺有信息量的。只训 steering 就能涨 100 个百分点,说明 verifier hidden states 里确实藏着大量未被使用的预测信号。这是对 Samragh et al. 关于 LLM 内部表征隐式编码未来 token 那个观察的有力佐证。
而解冻 drafter 之后还能再涨,说明 drafter 主体也需要小幅"重新校准"才能最优地接收 steering 信号。这算是个 lossless gain,付出的代价是训练阶段需要存 drafter 的梯度。
五、几个我看完之后的判断
5.1 这套方法到底处于什么位置
老实讲,我在读到 abstract 提到 "35% 接受 token 提升" 时是有点警觉的——投机解码这个方向已经卷到 EAGLE-3 这种把 verifier hidden states 直接拼进 drafter 输入的程度了,再涨 35 个百分点是个很大的数字。
读完正文之后,这个数字的可信度是站得住的,但需要加一些限定条件:
第一,35% 的最大涨幅出现在最不对齐的配置上(Vicuna 13B + Llama 160M),且是在训练分布内(UltraChat)。在已经对齐很好的同家族配置上(Llama 3.1 + Llama 3.2),SD² 几乎追平 Pretrained。
第二,SD² 是和"独立式 drafter + 蒸馏"这条线对比,不是和 EAGLE-3 对比。论文很诚实地标注了 EAGLE-3* 只用 chain decoding 模式作为参照点(关掉了 EAGLE-3 真正发挥威力的树解码),所以严格意义上 SD² 没有正面打 EAGLE-3。
第三,SD² 需要访问 verifier 的隐藏态,这一点和 EAGLE 系列一样。如果 verifier 部署在远程黑盒(比如调 API),SD² 用不上。这是这条路线天然的边界。
5.2 真正的工程价值
我个人觉得 SD² 真正值钱的不是数字,而是它可后装这个特性放在工程语境里的份量。
现在很多团队部署的就是"verifier + 独立小型 drafter + 蒸馏"的组合,比如 Qwen3 14B + Qwen3 0.6B 蒸馏一遍。SD² 不需要换 drafter 架构、不需要换训练数据,只是在 drafter 的每层 SwiGLU 上加一个偏置项,再加一个轻量的 \(W_{hml}\) 和 \(W_s\) 矩阵,就能在原有蒸馏方案上再涨一截。改动量很小,集成成本很低。
而且 SD² 的副作用控制得不错:长序列性能没掉、OOD 任务没崩。这种"加上去几乎只赚不亏"的特性在工业部署里很受欢迎。
5.3 几个让我皱眉的地方
第一个是 Table 2 那个奇怪 token 的问题。作者也承认了,hidden state 干预会偶尔产生英文字母表之外的乱码。这种现象在 production 里要怎么兜底?是不是需要加一个简单的字符过滤?论文没展开。
第二个是训练成本。SD² 需要在 drafter 全参数 + steering 模块上训 6 个 epoch(UltraChat)+ 1 个 epoch(ShareGPT),用 A100 80GB。这个量级在工业上不算小,特别是相对于"单纯做一次蒸馏"。论文没列具体训练时间,希望看到。
第三个是和 EAGLE-3 的关系没厘清。SD² 在结构上其实很像 EAGLE-3 的"轻量版"——都用了 verifier 三层 hidden states 拼接 + 线性投影。区别是 SD² 把信号注入到一个独立预训练 drafter 里,而 EAGLE-3 是从零训练一个特化的草稿头。但论文没和真正完整版的 EAGLE-3(带树解码)做端到端速度对比,只是把 EAGLE-3* 作为 block efficiency 参照。我理解作者的论证逻辑("我们这条线是独立 drafter,不是要打 EAGLE-3"),但读者总会想问:在能拿到 verifier hidden states 的场景里,到底应该用 SD² 还是 EAGLE-3?这个问题还是悬着。
5.4 对实践者的几条启发
如果你也在做投机解码相关的工程,这篇论文里有几个点值得直接拿来用:
- 如果你已经在用独立式 drafter + 蒸馏:SD² 的改动很小,可以直接试。模板代码作者已经开源在 GitHub(ETH-DISCO/SD-square)。
- 如果你的 drafter 和 verifier 同家族同训练数据:先看一下基线对齐怎么样,可能 SD² 边际收益不大。
- 如果你在做长上下文场景:SD² 在长序列上的稳定性比纯蒸馏好得多,值得优先考虑。
- steering 向量的注入位置选 SwiGLU 上投影 + gate 之前:这个消融结论可以直接复用,省得自己去试。
- \(W_s\) 初始化为 0:这个 trick 别忘了,否则训练发散概率很高。
5.5 一个更大的图景
读完这篇,我有一个更大的感受:激活引导(activation steering)这个技术,正在从"对齐安全 / 行为控制"的领域,逐步渗透到推理加速的领域。
激活引导最早是 Turner et al. 2023 用来给 LLM "装个旋钮",比如调节模型的乐观程度、安全性、风格。SD² 把它拿来做投机解码里的 drafter 对齐,做法上是把 verifier 当成 steering 的"教师信号源",让 drafter 的行为动态对齐到 verifier 的输出分布。
这个跨领域迁移其实挺漂亮的。我猜接下来可能会看到激活引导被用到更多地方:MoE 路由、KV cache 压缩、量化误差补偿……凡是涉及"两个模型行为对齐"或者"模型局部行为微调"的场景,激活引导都可能是一个轻量级的工具。这条线值得持续关注。
六、收尾
回到最开始那个问题——投机解码的 drafter 怎么和 verifier 对得齐?
社区已经探索了好几年。Medusa / EAGLE 走的是"特化"路线,从零训练特定形状的草稿头;DistillSpec 走的是"离线对齐"路线,把 drafter 蒸成 verifier 的近似。SD² 提出了第三种思路——保留 drafter 的独立性和泛化性,但通过运行时从 verifier 隐藏态抽信号注入 drafter,做轻量的动态对齐。
它不是颠覆性的工作,更像一个"把激活引导这个工具借过来给投机解码用"的优雅尝试。但优雅本身就是好东西。在现在这个动辄堆十几个 trick 的论文环境里,能用一个简单的 SwiGLU bias 注入 + KL 蒸馏目标解决问题,且 ablation 做得干净、限制讲得诚实,这种工作我个人是非常欣赏的。
如果你正在被独立式 drafter + 蒸馏这条线的"分布外掉点"困扰,SD² 值得花一两天调一调。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我。
参考文献
- Berdoz, F., Rheinboldt, P., Wattenhofer, R. (2025). Steering Pretrained Drafters during Speculative Decoding. AAAI 2026. arXiv:2511.09844
- Leviathan, Y., Kalman, M., Matias, Y. (2023). Fast Inference from Transformers via Speculative Decoding.
- Chen, C., Borgeaud, S., et al. (2023). Accelerating Large Language Model Decoding with Speculative Sampling.
- Cai, T., et al. (2024). Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads.
- Li, Y., et al. (2024). EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty.
- Li, Y., et al. (2025). EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test.
- Zhou, Y., et al. (2024). DistillSpec: Improving Speculative Decoding via Knowledge Distillation.
- Turner, A. M., et al. (2023). Steering Language Models with Activation Engineering.
- Samragh, M., et al. (2025). Your LLM Knows the Future: Uncovering its Multi-Token Prediction Potential.