CoT-SAE 论文解读:用稀疏自编码器看穿"思维链是否真在思考"
摘要
这篇文章我读完后第一反应是"它做了一件早就该有人做的事"。Chain-of-Thought 火了三年,但学界对 CoT 是不是真在反映模型内部的推理过程一直处于"嘴上吵架、手上没法验证"的状态。作者用 sparse autoencoder(SAE)+ activation patching 这套机制可解释性的工具组合,把 CoT 的"忠实性"问题第一次落到 feature 级因果证据上。结论也比预期更微妙:CoT 在 Pythia-2.8B 上确实诱导出更稀疏、更可解释、可因果转移的特征,但在 Pythia-70M 上完全失效。规模阈值这个发现,比"CoT 有用 / CoT 没用"的二分结论更有信息量。
arXiv 编号:2507.22928v1,作者来自 Leiden University 的 Xi Chen, Aske Plaat, Niki van Stein。代码地址:https://github.com/sekirodie1000/cot_faithfulness。AAAI 2026 接收。
一、问题:CoT 到底在不在"思考"
让我先把这个问题讲清楚。
CoT 是一种 prompting 技巧:给模型加一句"Let's think step by step"或者三个带详细中间步骤的 few-shot 例子,模型就会在最终答案之前生成一串"中间推理"。在 GSM8K 这种数学题上,CoT 能把 Pythia-2.8B 的准确率从 30% 多拉到 50% 多。这个数字是真的,没人否认。
但是,这串"中间推理"是模型真的在那么想,还是模型先用某种隐式机制算出了答案,然后再补一段听起来合理的解释?这个问题学界叫 CoT faithfulness——"CoT 链条是否忠实反映模型内部的实际计算路径"。
我自己长期觉得这是个伪问题——只要 CoT 能提性能就行,管它"忠实"不忠实。但这篇文章让我意识到,这个问题不解决,CoT 就只能停留在"魔法咒语"层面。如果中间步骤和内部计算没关系,那基于 CoT 的可解释性、错误检测、安全监控通通是空中楼阁。
之前的工作做过两类尝试。一类是 attributional methods——看输入 token 重要性、看 CoT 步骤被打乱后准确率怎么变。问题是这些都是相关性,不是因果。模型可能因为 CoT 长度变了、token 分布变了而抖动,不一定是"中间步骤本身"在起作用。
另一类是 causal activation patching——把 CoT pass 的某层激活替换到 NoCoT pass 上,看输出怎么变。这个方法是因果的,但粒度太粗:一层有几千个神经元,每个神经元因为 polysemanticity(一个神经元同时编码多个语义)和 superposition(多个特征叠加在同一个方向),patching 后的效果很难归因。
作者想要的是特征级因果分析——把激活拆成单义(monosemantic)、可解释的特征,然后在特征级做 patching,看具体哪些特征是 CoT 带来的、它们对答案的因果贡献多大。SAE 正好提供了这个工具。
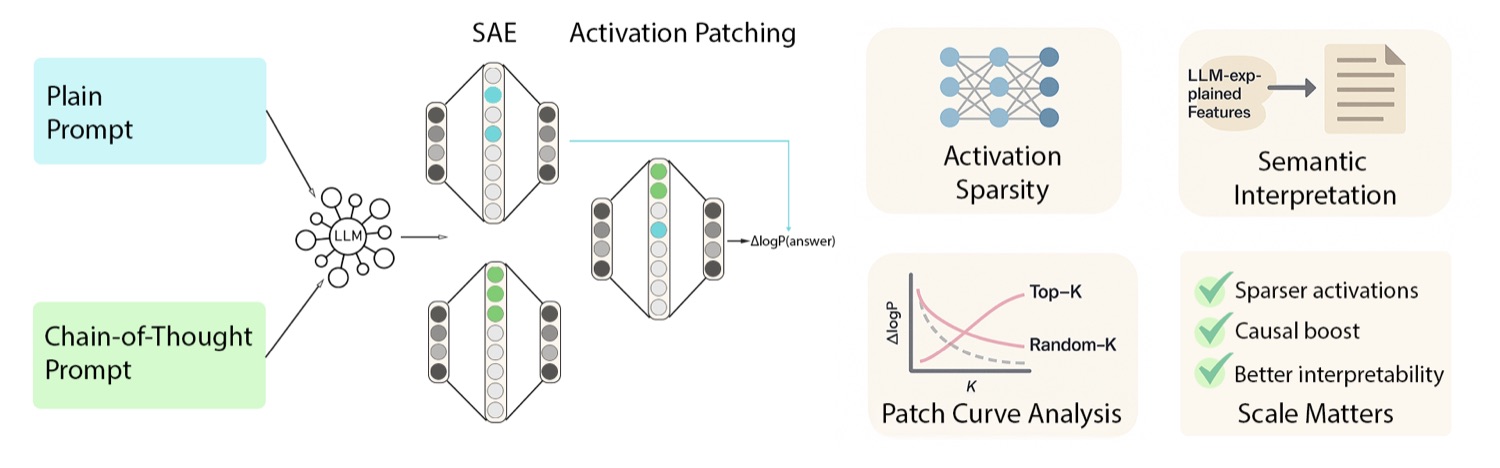
二、方法骨架:SAE + activation patching 的四件套
整个方法可以拆成四个组件,我按顺序讲。
2.1 Feature Extraction:用 SAE 把高维激活拆成稀疏字典
SAE 的核心思想很朴素:把模型某层的激活向量 \(\mathbf{x} \in \mathbb{R}^{d_{\text{input}}}\) 通过一个 encoder 映射到一个比原维度更高、但稀疏的隐空间 \(\mathbf{h} \in \mathbb{R}^k\)(\(k > d_{\text{input}}\)),再用 decoder 重建回去。损失函数是
L1 项强迫 \(\mathbf{h}\) 在大多数维度上接近 0,只有少数维度被激活。每个被激活的维度对应一个"特征方向",理论上是单义的——一个特征只编码一个语义概念。
这个想法 Anthropic 在 2023 年的 Towards Monosemanticity 那篇文章里已经讲透。SAE 不是这篇论文的发明,作者贡献是把 SAE 用在"对比 CoT 和 NoCoT 的特征字典"这个新场景下。
具体做法是:在 Pythia-70M 和 Pythia-2.8B 两个模型上,分别用 GSM8K 训练集做两次激活采集——一次 CoT prompt(三个详细推理示范)、一次 NoCoT prompt(只给当前题目)。每个模型的 layer-2 残差流上分别训两个 SAE,得到 \(\mathbf{D}_{\text{CoT}}\) 和 \(\mathbf{D}_{\text{NoCoT}}\) 两个字典。
字典大小通过 dictionary ratio 控制——4 表示字典大小是输入维度的 4 倍,8 是 8 倍。字典越大,每个特征越稀疏、越单义,但训练越难。
2.2 Causal Intervention:activation patching 在特征空间做手术
关键操作是这样:对同一个数学题目,分别拿 CoT 和 NoCoT 两份隐藏激活 \(\mathbf{x}_{\text{CoT}}\)、\(\mathbf{x}_{\text{NoCoT}}\),用 SAE 编码得到稀疏特征 \(\mathbf{h}_{\text{CoT}}\)、\(\mathbf{h}_{\text{NoCoT}}\)。挑一个特征子集 \(S\),做一次特征拼接:
然后把 \(\mathbf{h}_{\text{patch}}\) decode 回激活空间,喂回模型继续往后跑,看正确答案的 log-probability 怎么变。变化量定义为
\(\Delta \log P > 0\) 说明把 CoT 特征注入 NoCoT 后,模型对正确答案更有信心——这是 CoT 特征具有因果效力的直接证据。
这一步我觉得设计得很干净。注意是在 SAE 的特征空间做替换,而不是在原始激活空间。前者的语义粒度更细、单义性更强,patching 后的效果可以归因到具体特征上。
特征子集 \(S\) 怎么选?作者给了两种方案:
- Top-K:按 \(|\mathbf{h}_{\text{CoT}} - \mathbf{h}_{\text{NoCoT}}|\) 从大到小排序,取前 K 个差异最大的特征
- Random-K:从全字典里随机抽 K 个
Random-K 是关键的对照组——如果 Top-K 显著好于 Random-K,说明因果效力集中在少数关键特征;如果 Random-K 反而更好,说明 CoT 信息是分散的。这个对照组的设计后面会带来一个意外发现。
2.3 Structural Analysis:activation sparsity
第三块是结构分析。定义 layer \(l\) 的激活稀疏度为:
\(T\) 是序列长度,\(d\) 是隐藏维度,\(\epsilon\) 是接近 0 的阈值。这个量直接告诉你"这一层有多少神经元几乎没在干活"。
为什么测这个?作者的逻辑是:稀疏激活意味着模型在做"模块化计算"——少数神经元高激活、对应特定子任务,其他神经元保持沉默。这种模式被认为是更可解释的内部组织方式。如果 CoT 让模型更稀疏,间接证明 CoT 在重塑内部计算结构。
2.4 Semantic Interpretation:让 GPT 给特征起名字
最后一步是给 SAE 提取出来的特征起一个自然语言描述。具体做法沿用 OpenAI 2023 年的 automated interpretation pipeline:
- 对每个特征,找出它在数据集上激活最强的若干个 token 上下文片段
- 把这些片段喂给 GPT-3.5-turbo,让它生成一句话描述这个特征"在编码什么"
- 用这个描述去预测特征在新文本上的激活模式
- 预测和真实激活的相关系数,就是这个特征的"解释分"
解释分越高,说明这个特征越单义、越好用语言描述。这一步本身没什么新东西,但用来对比 CoT 和 NoCoT 下特征的解释分分布,是有趣的角度。
三、关键实验:三组结果一致指向"规模阈值"
实验在 Pythia-70M(小,6 层 512 维)和 Pythia-2.8B(中等,32 层 2560 维)上跑。GSM8K 训练集,每个 condition 最多 1000 道题。layer-2 的残差流,最后一个 token 位置的激活作为分析对象。
3.1 解释分对比:大模型 CoT 显著提升语义连贯性
第一组结果是 SAE 特征的解释分对比。
| Model | CoT Mean | NoCoT Mean | t-stat | p-value |
|---|---|---|---|---|
| Pythia-70M | 0.018 | 0.016 | 0.082 | 0.935 |
| Pythia-2.8B | 0.056 | -0.013 | 2.96 | 0.004 |
70M 上 CoT 和 NoCoT 几乎没区别(t=0.082,p=0.935),CoT 甚至略输。2.8B 上 CoT 把均值从 -0.013 拉到 0.056,统计显著(p=0.004)。
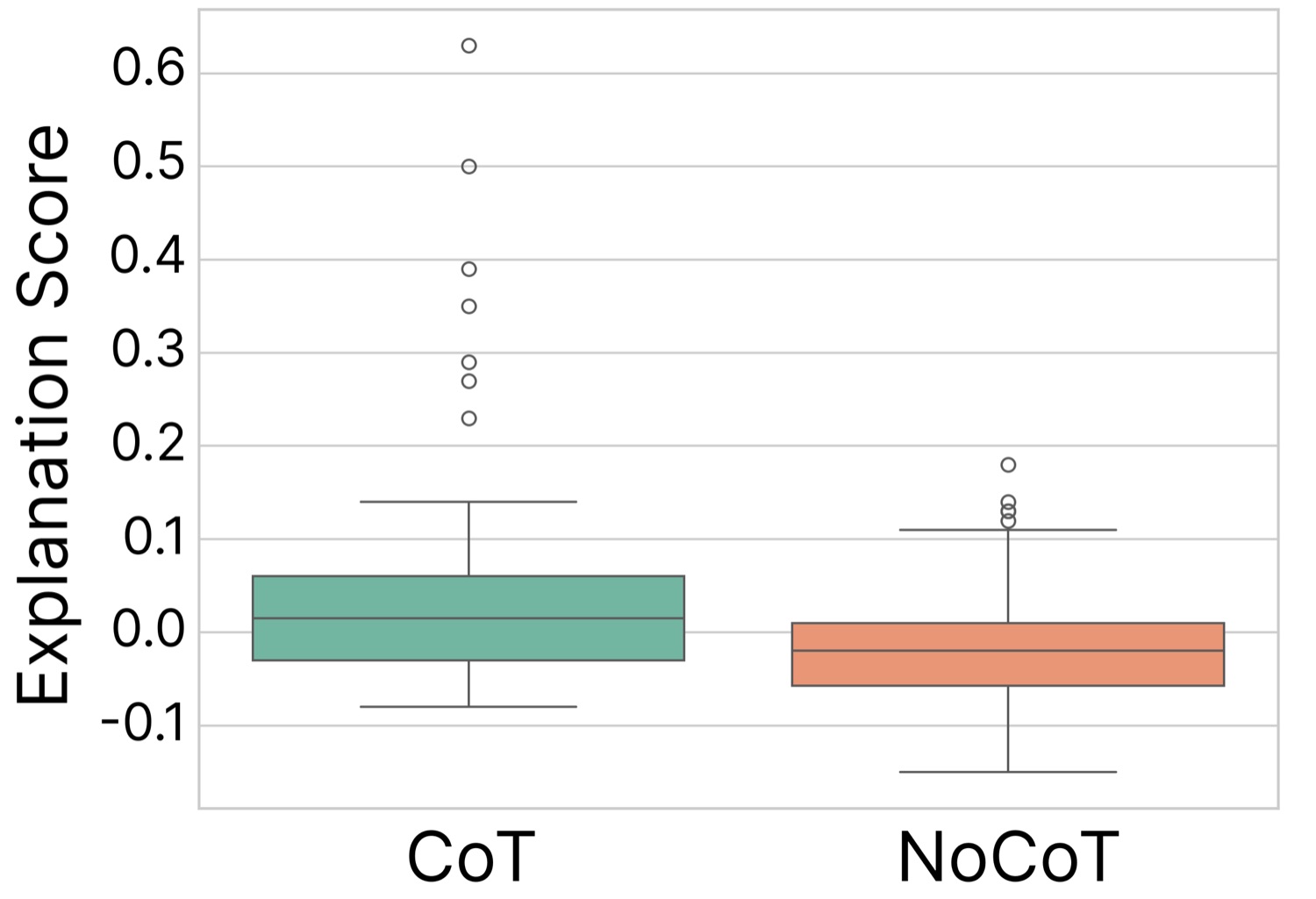
我一开始看到 70M 这个 0.082 的 t 值差点笑出来——这跟没差区别。但作者敢把这个负面结果放出来,是这篇论文最让我尊敬的地方。如果只挑 2.8B 的好看数据写,文章会更好卖,但叙事会变成"CoT 让特征更可解释",丢掉了"小模型上完全无效"这个真正有价值的洞察。
3.2 Activation patching:CoT 特征能不能因果转移
第二组实验是核心。把 Top-20 个差异最大的 CoT 特征 patch 到 NoCoT 跑里,看正确答案的 \(\Delta \log P\) 分布。
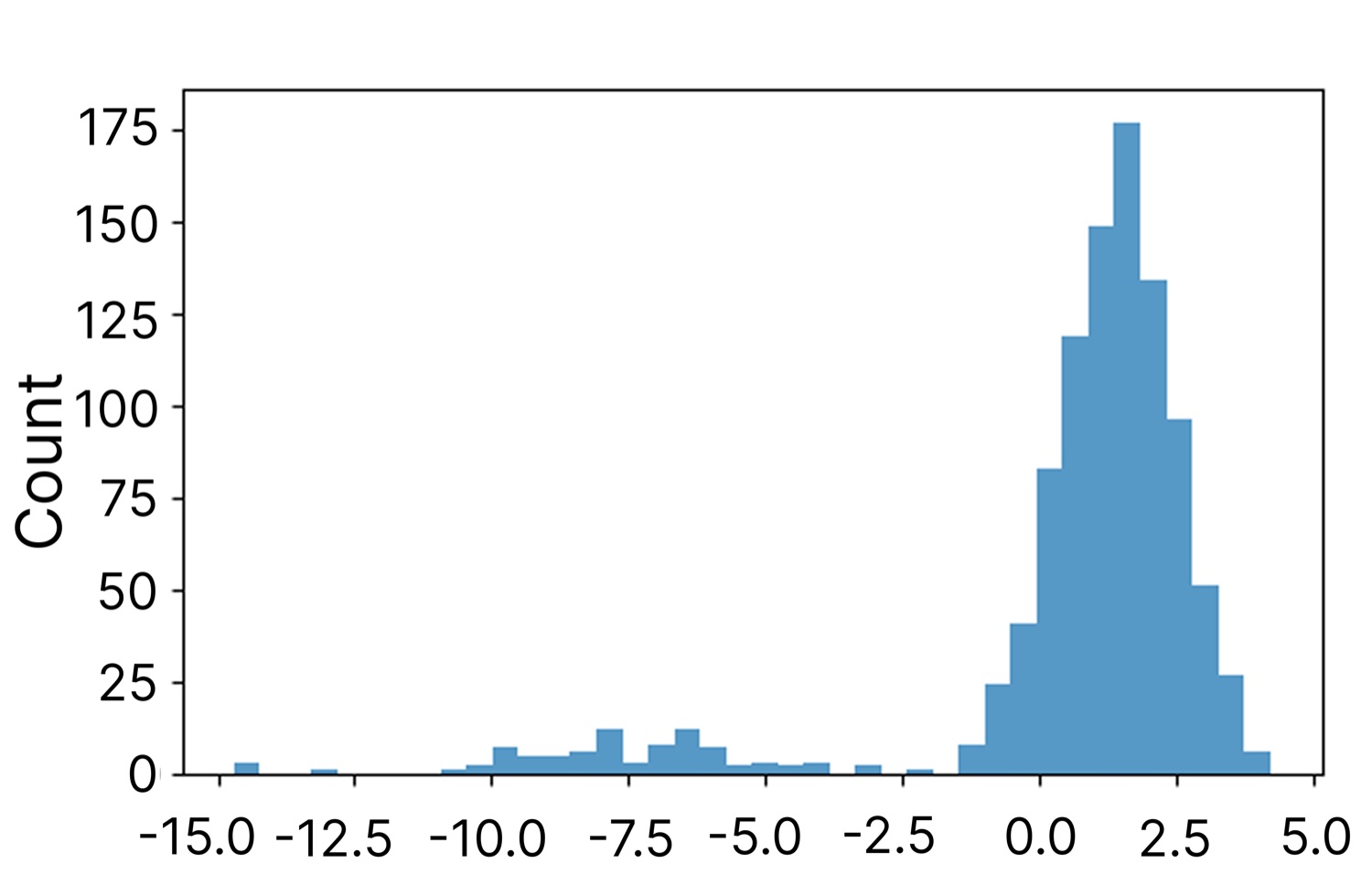
Pythia-2.8B 上分布明显右偏——patching 后 log-probability 普遍正向变化,最高拿到 +3.2 左右。Pythia-70M 上分布近似对称,正向负向各占一半,方差还很大(极端值能到 ±30),等于"CoT 特征移植过去经常打架"。
更有意思的是 patch curve——把 K 从 2 加到 128,看 \(\Delta \log P\) 怎么演化。2.8B 上 K=2 时 \(\Delta \log P\) 就跳到 +3.2,然后逐渐饱和。这意味着只要少数几个 CoT 特征就能把 NoCoT 推到接近 CoT 的状态——CoT 的因果信号是强的、可分离的。70M 上 patch curve 是单调下降,加越多 CoT 特征性能越差。
3.3 一个反直觉发现:Random-K 比 Top-K 更好
最让我重新思考的是 Random-K 对照组的结果。
按理说 Top-K 选的是差异最大的特征,因果效力应该最强。但在 Pythia-2.8B 上,Random-K 经常打败 Top-K。具体数字:模型对正确答案的置信度(log-prob)从 1.2 提升到 4.3,这是 Random-K 的成绩。Top-K 反而没这么夸张。
这个现象怎么解释?作者给的答案是:在 2.8B 这种模型里,CoT 的有用信息不是集中在少数顶峰特征上,而是分散在大量中等激活的特征里。Top-K 选的是"激活差异绝对值最大"的特征,往往是局部峰值;Random-K 反而能 cover 到那些激活不强、但成片协同工作的"支撑特征"。
这个发现对我的认知冲击挺大的。我之前一直假设"重要特征 = 高激活特征",但 SAE 视角下事情不是这样。CoT 重塑的是一个分布式、协作式的内部网络,而不是几个 single-killer feature。这也部分解释了为什么 mechanistic interpretability 这么难——很多重要计算根本不在你直觉关注的"明亮"地方。
3.4 Activation sparsity:CoT 让大模型变得明显更稀疏
第三组结果是激活稀疏度。
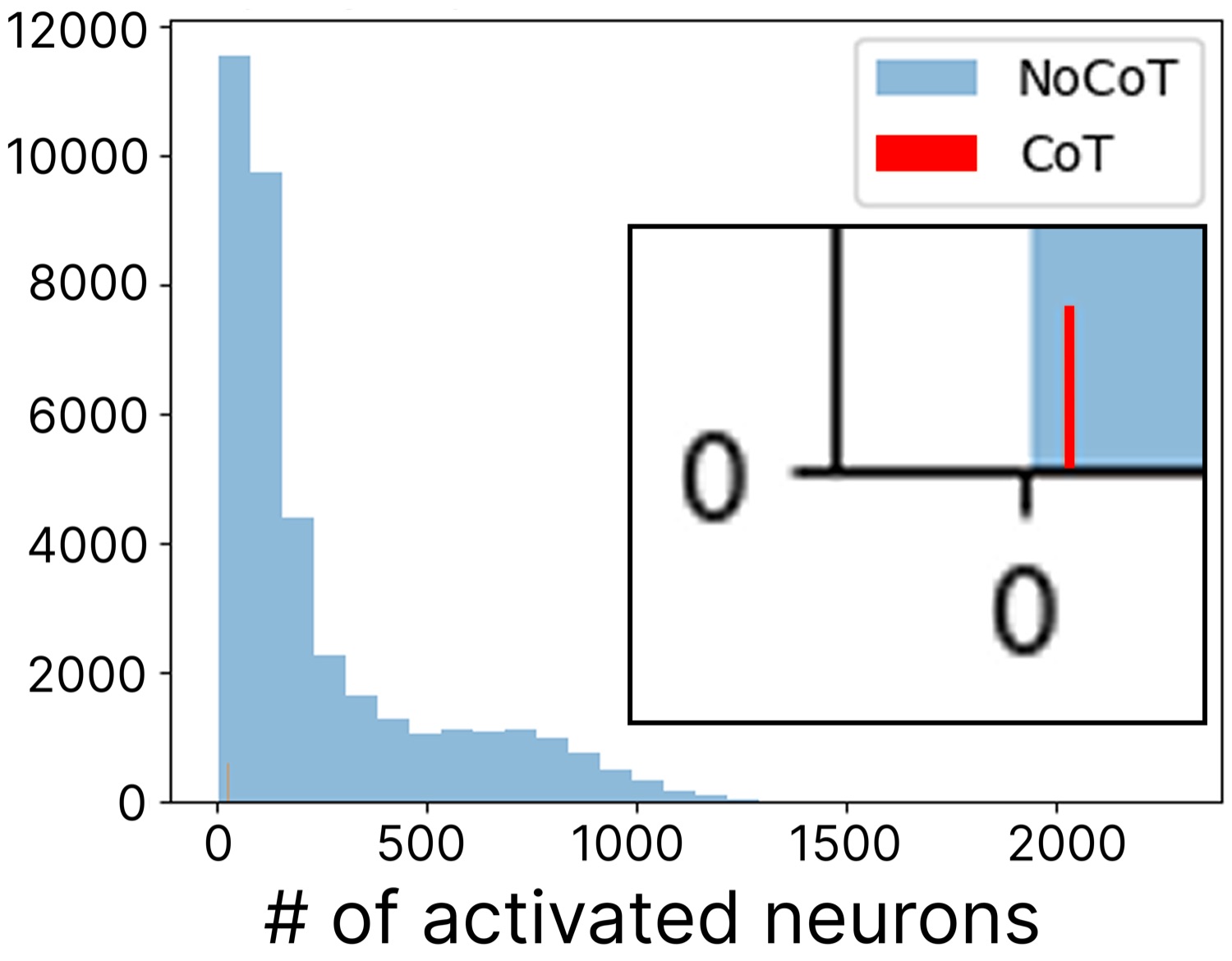
2.8B 上 CoT 让残差激活的稀疏度显著上升——绝大多数神经元贴近 0,少数高激活。70M 上效应弱,CoT 和 NoCoT 的稀疏度分布重叠很大。
如果再把粒度降到 SAE 特征层面,结果更明显:CoT 下每个特征激活的神经元个数普遍少,且方差大(有些特征用极少神经元,有些用一组)。NoCoT 下每个特征都用更多神经元,分布更均匀。
这个结果和上面的 Random-K 现象是一致的:CoT 在 2.8B 里诱导出 structured sparsity——少量高激活特征 + 大量中等激活的支持特征 + 极多近零神经元。这种结构正好解释了为什么 Random-K 能 cover 到那些"中等激活但有用"的支持特征。
四、规模阈值是怎么回事
把三组结果连起来看,故事是清晰的:CoT 在 2.8B 有效(解释分提升、因果转移成功、激活更稀疏),在 70M 完全无效甚至负向。这个差异作者称为 scale threshold——小模型容量不够,CoT prompt 还不能在内部诱导出真正"模块化"的计算路径,反而可能把已有的小模型推理能力打散。
我想推一步:为什么会有规模阈值?
可能的原因有几个层面。
容量层面:要把"读题—分步骤推理—汇总答案"这个流程编码成可分离的内部子模块,需要足够多的隐藏维度。70M 只有 512 维,可能根本装不下"步骤分离"这种结构,CoT prompt 进来只能继续走原来那个混在一起的子网络。2.8B 的 2560 维有富余,CoT prompt 才能激活出一组专门处理"中间推理"的特征。
预训练数据层面:Pythia 是在 Pile 上训的。Pile 里包含一些数学题、逻辑题、code,但密度不高。70M 在这种数据上很可能根本没学到"分步骤"的技能;2.8B 学到了一部分,CoT prompt 才能"调用"这部分学到的技能。
优化层面:小模型的训练动力学和大模型不同,小模型更容易陷入"shortcut"——找一个最快路径过 loss,不发展冗余结构。这种 shortcut 模型对 prompt 变化不敏感,CoT 也激活不了什么新东西。
这三个解释我都觉得有道理但都是后验解释。要真正回答"规模阈值在哪儿"这个问题,需要在 70M、410M、1B、2.8B、6.9B、12B 这一整个 Pythia 系列上扫一遍,找出从无效到有效的转折点。作者把这个留给了 future work,我觉得是这篇文章最值得的 follow-up。
五、和已有工作的关系
我把这篇文章的位置在 mechanistic interpretability 的版图上标一下。
和 Anthropic 的 SAE 工作(Bricken 2023, Cunningham 2023, Templeton 2024):那些工作主要在做"SAE 能否提取出单义特征"的本身验证。这篇文章拿 SAE 当工具,比较 CoT 和 NoCoT 下的特征字典差异,应用层贡献。
和 CoT faithfulness 的早期工作(Yeo 2024, Lanham 2023, Turpin 2023):那些工作做的是 input-level 或 output-level 的扰动实验——改 CoT 步骤、删一段、看准确率。这篇是 first feature-level causal study,把因果证据下沉到内部表征。
和 activation patching 的经典工作(Meng 2022 ROME, Wang 2022 IOI circuit):经典 activation patching 在原始激活空间做,受 polysemanticity 困扰。这篇在 SAE 特征空间做,粒度细很多。
这篇文章在 mechanistic interpretability 的工具链上是承上启下:上承 SAE 单义特征提取,下启 CoT 内部机制研究。落点是 AAAI 2026,作者只用了 Pythia-70M 和 2.8B 两个模型——这是一篇"做实做透两个 case study"的工作,不是"在 N 个模型上扫"那种。我觉得这种取舍恰当,毕竟 SAE 训练成本不低。
六、几个我会追问的点
读完后我留下几个问题。
第一,layer-2 是不是最有信息量的层? 作者只在 layer 2 的残差流做了分析(70M 共 6 层、2.8B 共 32 层)。layer 2 在 70M 是中段,在 2.8B 是早段。中段和早段的语义抽象层次完全不一样,混在一起比可能掩盖了真实差异。如果在 2.8B 的 layer 16 或 layer 24 做,CoT 的因果效应可能更强或更弱,是个值得扫的维度。
第二,"final token activation"是个合理代表吗? 作者只取最后一个 token 位置的激活。但 CoT 的本质是中间步骤——理论上 CoT 信号最浓的地方应该是"reasoning chain 中间某些 token",不是最后一个。这种采样方式可能把 CoT 的真实因果效力低估了。
第三,GSM8K 之外能否泛化? GSM8K 是数学题,链式推理很明显。但 CoT 的应用场景远不止数学——常识推理、代码、分析任务都用 CoT。这些任务的"CoT 信号"在内部分布完全可能不同。作者把 GSM8K 当唯一 testbed 是个限制。
第四,SAE 训得好不好怎么验证? SAE 本身是个生成模型,loss 收敛不代表特征单义。如果 SAE 没训好,提取的特征带polysemanticity,整套结论的基础会动摇。论文里没看到 SAE 重建质量、特征单义度的独立评估。
这四个问题里第一和第二我觉得是必须回答的,论文 limitation 部分有提到第二点但展开不够。第三是对外推合理性的根本质疑,第四是对方法本身的内部检验。这些不影响核心 finding,但严谨的下一步工作应该把这些都补上。
七、对从业者的实用启示
如果我是一个想用 CoT-SAE 这套方法的研究者或工程师,我会从这篇文章里抽出几条可执行建议。
建议一:做 mechanistic interpretability 时,模型规模选大一点。70M 几乎告诉我们什么都没发生。如果你研究的现象是 emergent 的(CoT 就是典型 emergent capability),小模型上做的实验大概率会得出"什么都没用"的结论,但这个结论是模型容量限制的伪信号,不是现象本身的特性。最低我建议从 1B 起步,最好 7B+。
建议二:activation patching 的对照组里务必加 Random-K。Top-K 直觉上对,但实际上经常被 Random-K 打败。如果你只报 Top-K,会掩盖"信号是分布式的"这个重要事实。
建议三:解释分对比 + activation sparsity + activation patching 这三组互相印证的设计是好范式。任何一种方法单独都有缺陷(解释分依赖 LLM 评判、稀疏度间接、patching 受 SAE 质量影响),三者一致的结论才比较可靠。
建议四:CoT 在生产中真的有用吗?这篇文章给的答案有限——它只说"CoT 在大模型里诱导出可因果转移的特征",不直接等于"CoT 能改善准确率"。如果你的下游任务是数学题、且模型 ≥ 1B,CoT 大概率有效;其他场景需要单独验证。
八、写在最后
我把这篇论文的核心贡献用一句话总结:第一次在 feature 级提供 CoT faithfulness 的因果证据,并发现这种因果效力存在明确的规模阈值。
它给我的最大启发不是某个具体技术,而是一种研究态度——把大家嘴上吵架的问题变成可以测量的因果实验。CoT faithfulness 这个问题被讨论了三年,大部分讨论停留在理论辩论或 input-level 扰动实验。这篇文章把战场拉到了内部表征层面,给出了清晰的、可重复的、带规模依赖性的答案。
这种"把哲学问题转成实证问题"的能力,是 mechanistic interpretability 这个方向最值得发扬的特质。我个人会把这篇文章推荐给两类读者:一类是研究 CoT、reasoning、prompting 机制的同行,论文给的方法论可以直接复用;另一类是 SAE 应用方向的研究者,作者用 Pythia + GSM8K + 一块 A100 跑出有意义的结论这件事,本身就是对"SAE 能不能上小预算 case study"的一个有力示范。