多Agent投票投出个寂寞?这篇AAAI 2026把冷战时期的情报学方法搬了进来
核心摘要
多Agent系统里最让人头疼的不是Agent本身不够聪明,而是把几个Agent的答案凑到一起的那一步——投票投不出共识、独裁又容易被一个偏见带偏。南开大学的这篇 AAAI 2026 工作(AgentCDM)干了一件挺有意思的事:把冷战时期 CIA 用来对付分析师认知偏差的方法 Analysis of Competing Hypotheses(竞争性假设分析法)搬到了 LLM 多 Agent 决策里,让决策 Agent 不是去"挑一个答案",而是去"枚举所有假设、画证据矩阵、做反向证伪"。更狠的是用两阶段强化学习把这套结构化推理范式内化进模型——第一阶段强制走完整 ACH 流程,第二阶段把脚手架慢慢撤掉。在 MMLU-PRO 上 Mistral-7B 直接涨了 29.3 个点,从 32.5 干到 61.8。我看完的第一反应是:这套思路本身比具体涨幅更有价值,因为它给"集体智慧"这个被滥用的词第一次给出了可操作的方法论。
论文信息
- 标题:AgentCDM: Enhancing Multi-Agent Collaborative Decision-Making via ACH-Inspired Structured Reasoning
- 作者:Xuyang Zhao, Shiwan Zhao, Hualong Yu, Liting Zhang, Qicheng Li
- 机构:南开大学计算机学院
- 会议:AAAI 2026
- arXiv:https://arxiv.org/abs/2508.11995
一、多Agent投票为什么经常投出个寂寞
先说一个我自己踩过的坑。
之前调一个 3 Agent 投票系统做选择题,跑了一圈发现一个反常现象:单 Agent 的 Llama-3-8B 准确率 66%,三个 Agent 一起投票之后……还是 66%。改成五个 Agent 投票,66.5%。涨了 0.5 个点。
为什么?因为如果三个 Agent 都是同一个模型,它们在哪道题上犯错是高度相关的——A 错的题 B 大概率也错。投票只对独立错误源有效,对相关错误源约等于没用。
这就是论文一开始就在批的事情。当下大部分 LLM 多 Agent 工作把心思花在角色设定、通信协议、任务规划这些"前戏"上,到了最后一步"怎么把几个 Agent 的答案合成一个最终答案",要么投票,要么找一个 Decider Agent 拍板。
投票的问题前面说了。独裁的问题更隐蔽——你让一个 Decider Agent 去综合三个 Agent 的回答,它会被第一个看似最有道理的 Agent 锚定(anchoring bias),会主动找证据支持自己最初的判断(confirmation bias),会因为某个 Agent 用了肯定语气就高看一眼(subjective validation)。这些都是人类决策里被研究了几十年的认知偏差,LLM 全继承了。
作者把这个问题点得很清楚:问题不在 Agent 本身,而在决策机制太原始。

图1:作者举了一个谜语的例子——"我有城市但没有房屋;我有山脉但没有树木;我有水域但没有鱼。我是什么?"标准答案是地图(Map)。Agent1 说题目逻辑矛盾无解,Agent2 说是地球仪,Agent3 说是地图。投票机制三票分散,决策瘫痪;普通 LLM 作裁判被 Agent1 的"逻辑矛盾"绕进去给了错误答案;只有 ACH 协议引导下的决策 Agent 通过列假设、收集证据、做交叉检验,最终选出"地图"这个真正贴合谜语本质的答案。
二、ACH是什么——一个被CIA用了几十年的反偏差工具
ACH 全称 Analysis of Competing Hypotheses,中文翻译"竞争性假设分析法",是 CIA 资深分析师 Richards Heuer 在 1999 年的著作《Psychology of Intelligence Analysis》里系统化的方法。
聊一聊为什么这东西被发明出来。情报分析这个职业最大的敌人不是没信息,是有太多信息但充满矛盾——一份报告说某国在备战,另一份说它在准备外交斡旋,第三份说它内部经济崩盘。一个分析师如果不警觉,会下意识挑那些支持自己最初判断的证据,把矛盾证据合理化掉。这就是著名的"伊朗革命情报失败"——大量预警信号被忽略,因为它们不符合分析师对沙赫政权稳固的预设。
ACH 的核心思路反直觉到有点别扭:不要去找证据支持你最看好的假设,而要去找证据反驳所有假设,然后看哪个假设被反驳得最少。
它把这个流程拆成七步,论文里直接给了完整的 prompt 模板:
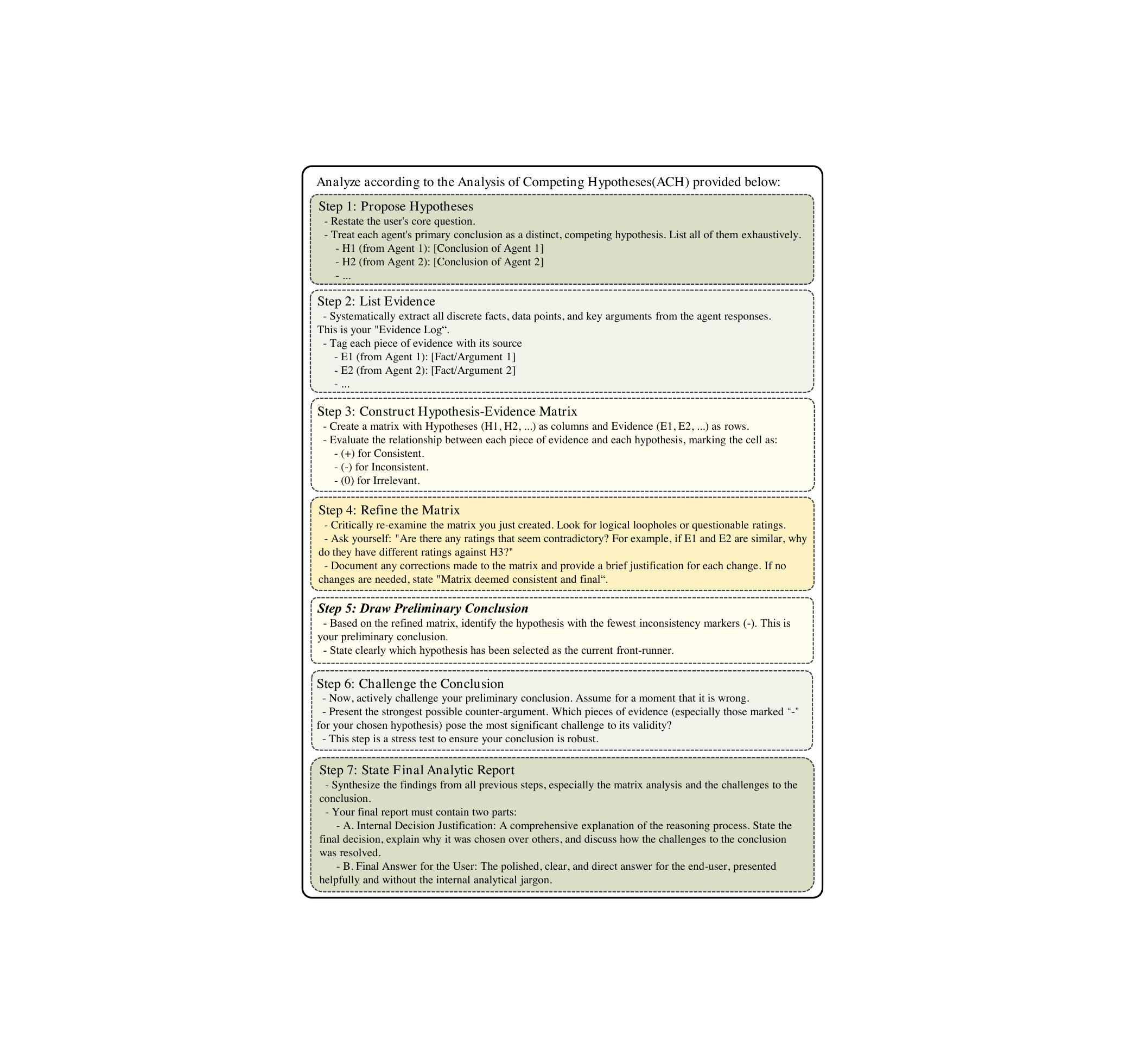
图2:AgentCDM 的 ACH 协议七步流程。从假设枚举到证据收集,到矩阵交叉评估,再到元认知审查、反向证伪、对抗测试,最后生成结构化报告。每一步都有明确的产出物,整个流程是可机器化执行的。
我把这七步用大白话翻译一下:
- 列出所有假设:把每个 Agent 的结论各自当成一个独立假设 H1、H2、H3……穷尽,不要先入为主
- 收集所有证据:从 Agent 们的分析里把所有事实、论点、关键词都抽出来,标号 E1、E2、E3……
- 构造假设-证据矩阵:行是证据列是假设,每个格子标三种状态——支持 +、反对 -、无关 0
- 元认知审查:重新检查矩阵里的判断有没有逻辑漏洞,比如同样的证据为什么对 H1 和 H2 给了不同评级
- 初步结论:选反对证据(-)最少的那个假设,注意不是支持证据最多的
- 对抗性测试:故意假设这个初步结论是错的,找最强的反驳论点,做压力测试
- 最终报告:写完整推理过程 + 给用户的最终答案
第 5 步是 ACH 的灵魂。找反对最少而不是支持最多——因为支持证据可能来自确认偏差,但反对证据如果被忽略,错误会立刻暴露。这是从证伪主义里来的思路,Popper 那一脉。
第 6 步也很关键。初步选完之后还要再自己打自己一巴掌,看能不能推翻。这一步在 LLM 上的工程价值我觉得被低估了——它把"反思"做成了流程里的必经步骤,而不是依赖模型自发想到去反思。
到这里其实已经能看出来,这篇论文最有价值的不是它训了个 7B 模型,而是它把一个在 LLM 时代之前就被人类专家验证了几十年的认知工具,翻译成了可以塞给 LLM 的结构化 prompt。
三、光给prompt不够,得让模型内化——两阶段训练登场
如果只是写个 ACH prompt,那这就是个 prompt engineering 工作。论文真正下功夫的地方在第二部分——怎么把这套结构化推理塞进模型权重里。
为什么不能只靠 prompt?两个原因。一是 ACH 流程巨长,每次推理都跑完七步成本高;二是基础模型在长 prompt 引导下容易"敷衍"——表面上写了七步,实际上每步都是水的,最后还是凭直觉拍。
作者的解法是两阶段强化学习。
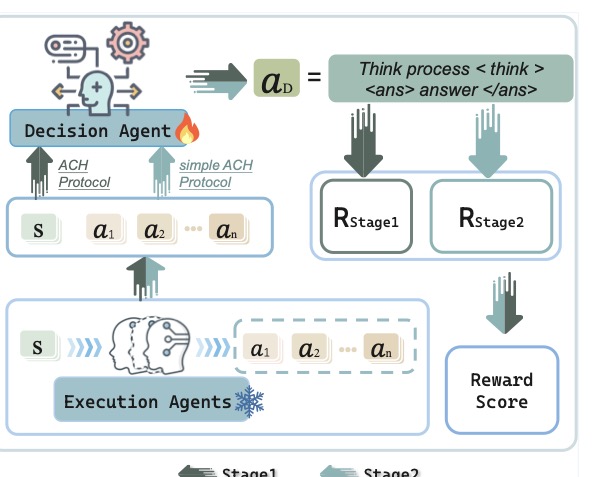
图3:整个框架的核心结构。Execution Agents 是冻结的(雪花标记),生成候选答案;Decision Agent 是被训练的(火焰标记),接收原始问题 s 和候选答案 a1...an,在 Stage 1 用完整 ACH Protocol 引导,Stage 2 切换到 Simple ACH Protocol,逐步内化推理过程。最终输出格式是 think+answer 的结构化 token。
Stage 1:脚手架阶段——强制走完整流程
第一阶段的 reward 由三部分组成:
三个分别在管什么:
- Format reward:强制模型把思考写在
<think>标签里,答案写在<answer>标签里。这是 DeepSeek-R1 之后大家都在用的格式约束 - Accuracy reward:答案对不对,rule-based 一眼判断(选择题嘛)
- ACH reward:这个是新东西。用 pattern matching 检查
<think>里有没有按 ACH 七步走——有没有列假设、有没有画矩阵、有没有做对抗测试
ACH reward 这一步是脚手架的核心。说实话我第一反应是有点担心——pattern matching 这种硬约束,会不会让模型学到的就是"复读 ACH 模板"而不是真的在思考?
作者自己也意识到了这个问题,所以才有了 Stage 2。
Stage 2:撤脚手架——逐步放手
第二阶段的关键改动是把硬 pattern matching 换成软的语义相似度:
把 ACH reward 换成 soft ACH reward——用 BGE-M3 模型把当前思考过程和标准 ACH 协议都编码成向量,算余弦相似度。这样模型不用一字不差按模板写,只要语义上还在做"列假设、找证据、做证伪"这件事就行。
同时引入 课程退火(curriculum annealing)——训练过程中,给模型的 prompt 在"完整 ACH 协议"和"简化 ACH 协议"之间动态切换,切换概率用余弦退火:
其中 \(t = i/T\),是当前训练步数占总步数的比例。
直观理解:训练初期 \(p_{full}\) 接近 1,模型基本看完整协议;训练后期 \(p_{full}\) 接近 0,模型主要看简化协议(甚至自己想结构)。中间是个平滑过渡。
第二阶段的 reward 总分:
这个设计我挺欣赏的。它解决的是一个 RL 训练里很现实的问题——直接撤掉硬约束模型会崩溃(reward 一下子从有形变成无形),但一直留着硬约束模型又学不到泛化能力。课程退火 + 软奖励的组合就是在这两个极端之间找个平衡点。
策略优化用的是 GRPO(DeepSeek-R1 那套),不需要 critic model,省显存。每个 prompt 采 5 个 rollout,每个 batch 256 个 prompt,在 A800 上跑 50-100 轮。规模不算大,可复现性应该不错。
四、实验数据有多能打
直接看主表。这张表横跨 5 个基座模型(包括 GPT-4)× 3 个数据集(MMLU、MMLU-PRO、ARC-Challenge)× 多种决策方法。
MMLU-PRO 上的主要数字(准确率 %):
| 基座模型 | Single Agent | Informed Dictatorial | 最优投票方法 | Qwen-7B-R1 + ACH | AgentCDM |
|---|---|---|---|---|---|
| glm-4-9b-chat | 47.4 | 48.3 | 47.9 | 57.5 | 63.9 |
| Llama-3-8B | 41.2 | 40.8 | 41.6 | 54.4 | 63.7 |
| Mistral-7B | 32.5 | 31.7 | 32.1 | 48.6 | 61.8 |
| Qwen-2-72B | 49.2 | 51.1 | 49.5 | 60.8 | 65.7 |
| GPT-4 | 69.0 | 71.2 | 69.8 | 68.5 | 71.0 |
| 平均 | 47.9 | 48.0 | 48.1 | 58.0 | 65.2 |
几个值得停下来看一眼的数:
Mistral-7B 从 32.5 到 61.8——涨 29.3 个点。这个幅度在 MMLU-PRO 这种高难度榜单上不太常见。我看到这个数的第一反应是有点怀疑,但仔细看实验设置:Single Agent 是 Mistral 自己单独跑;AgentCDM 是用 5 个不同基座的 Agent(包括 Mistral 自己)生成候选答案,然后由训练好的 Decision Agent(基于 Qwen-7B-Base 训出来的 AgentCDM)做最终决策。所以这个对比其实是"单 Mistral vs 异构 Agent 池 + 智能决策器"——涨 29.3 个点的本质是把决策能力外包给了一个更聪明的裁判,Mistral 只是贡献了候选答案池里的一员。
理解了这一点,这个数就不那么离谱了。它告诉你的不是 AgentCDM 让 Mistral 变强了,而是在 Mistral 也能贡献候选答案的多 Agent 系统里,AgentCDM 这个裁判能榨出多少集体智慧。
GPT-4 几乎没涨,从 69.0 到 71.0,只涨了 2 个点。这其实更说明问题——GPT-4 单跑已经很强,多 Agent 协同的边际收益就小。同样的,glm-4-9b 涨了 16.5 个点,Llama-3-8B 涨了 22.5 个点。一个规律:底座越弱,AgentCDM 带来的相对提升越大。
Voting-Based 方法集体扑街。Plurality、Borda Count、IRV、Minimax……6 种投票方法在所有基座、所有数据集上的平均提升基本都在 ±0.5 个点之内,跟 Single Agent 没有显著差异。这印证了开头说的——同源 Agent 的投票几乎等于没投,因为错误高度相关。
Informed Dictatorial 也很拉。让一个 Agent 看完所有候选答案再决策,平均只涨 0.1 个点,甚至在 MMLU 上 Mistral 还掉了 8.5 个点。原因前面分析过:无结构的 prompt 让 Decider Agent 容易被某个候选答案锚定。
把这些放一起看,AgentCDM 的核心贡献其实可以这么概括:当你用同源 Agent 投票或随便找个 Agent 当裁判都不 work 的时候,结构化推理 + 异构 Agent 池 + 训练过的决策器 这三件套能榨出来真正的集体智慧。三个缺一不可,缺了结构化推理就被偏差带偏,缺了异构性就还是相关错误,缺了训练就内化不了 ACH 流程。
五、消融实验——两个阶段真的都必须吗
消融表(数字是准确率 %):
| 方法 | MMLU | MMLU_PRO | ARC-Challenge |
|---|---|---|---|
| Full(两阶段全用) | 78.5 | 65.2 | 96.0 |
| Vanilla prompt(不训练,纯 prompt) | 72.6 | 52.5 | 89.0 |
| Scaffolding-Only(只用 Stage 1) | 68.1 | 49.4 | 84.0 |
| Exploration-Only(只用 Stage 2) | 71.5 | 52.1 | 89.7 |
最有意思的不是 Full 最好——这是预期的。最有意思的是 Scaffolding-Only 比 Vanilla prompt 还差。
这个数我盯着看了一会儿。直觉上你会觉得,至少做了 SFT 加 ACH 强化训练,应该比啥都不做的 Vanilla prompt 强吧?但数据告诉你不是——Stage 1 训完的模型在 MMLU 上 68.1,比啥都不训的 prompt 还低 4.5 个点。
为什么?我的理解是:Stage 1 用硬 pattern matching 做 ACH reward,模型学到的是"复读 ACH 模板的句式",但因为 reward 只在格式上对齐、在语义上没有梯度,模型其实在牺牲推理质量来换格式分。Stage 1 一结束就停,模型卡在了"形式上像 ACH 但内核是 shallow heuristic"的局部最优里。
Stage 2 的真正作用是把模型从这个局部最优里拉出来——用语义相似度替代字面匹配,给模型重新探索的空间。所以 Full 才比两个单独阶段都好得多。
这个发现其实给后续工作一个很重要的启发:结构化推理的训练不能只靠模板约束,必须有"撤掉模板"的二次训练,否则模型会学到形式而丢掉内核。这条结论可以迁移到很多任务上,不止 ACH。
六、跨数据集泛化——简单数据真的训不出好决策
跨数据集泛化表:
| 训练集 \ 测试集 | MMLU | MMLU_PRO | ARC-Challenge |
|---|---|---|---|
| MMLU | 78.5 | 55.0 | 91.0 |
| MMLU_PRO | 80.8 | 65.2 | 94.0 |
| ARC-Challenge | 74.9 | 52.0 | 89.5 |
注意第二行——在 MMLU_PRO 上训练的模型,迁移到 MMLU 上 80.8,比直接在 MMLU 上训出来的 78.5 还高;迁移到 ARC-Challenge 上 94.0,比直接训的 89.5 还高 4.5 个点。
这个现象在大模型里其实不算稀奇,但意义挺重要:用难数据训出来的结构化推理能力,迁移到简单数据上是降维打击。反过来,第三行 ARC-Challenge 训出来的模型迁到 MMLU_PRO 上只有 52.0,掉了 13 个点。
工程上的启示:如果你要训一个通用决策 Agent,优先去找最难、最有歧义、最容易出现 Agent 分歧的数据来训,不要在简单选择题上反复迭代。学到的不只是知识,而是处理冲突的元能力。
七、Agent 数量越多就越好吗——有趣的反转
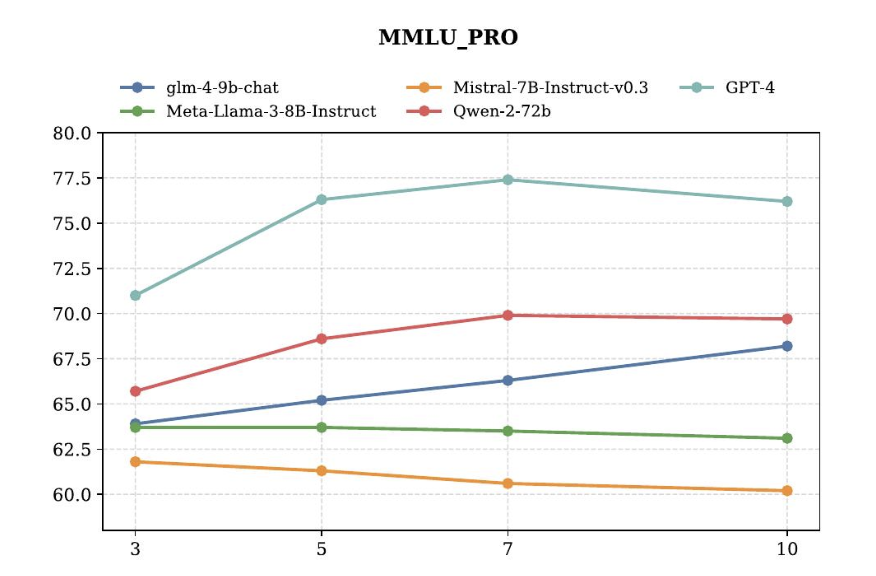
图4:随着 Agent 数量从 3 增加到 10,五个基座模型表现出截然相反的趋势。GPT-4、Qwen-2-72B、glm-4-9b 稳定上升或饱和;Llama-3-8B 基本持平;Mistral-7B 反而越来越差,从 62 跌到 60 出头。
这张图给出了一个反直觉但很重要的结论:Agent 数量不是越多越好,取决于基座能力。
强模型(GPT-4、Qwen-2-72B)多多益善,因为每个 Agent 的输出信噪比都高,凑得越多信号叠加越强;弱模型(Mistral-7B)反而越加越差,因为每个 Agent 都在贡献低质量答案,决策器要处理的噪声放大得比信号快。
这个发现对实际部署有直接指导意义。如果你在搭一个多 Agent 系统,预算允许的话用少量强模型而不是大量弱模型——后者的"集体智慧"可能根本不存在,反而是"集体糊涂"。
八、异构 Agent 池下的鲁棒性
| Qwen-7B-Instruct + ACH | AgentCDM | |
|---|---|---|
| MMLU | 75.2 | 78.9 |
| MMLU_PRO | 55.9 | 67.9 |
| ARC-Challenge | 87.2 | 93.0 |
这个表是为了证明 Stage 2 的价值。设置是这样:从 5 个不同模型的输出里随机抽 3 个给决策 Agent。Qwen-7B-Instruct + ACH 是没训练过、纯靠 prompt 走 ACH 的对照;AgentCDM 是训练过的。
MMLU_PRO 上差距 12 个点。这说明 训练带来的不只是会按 ACH 流程走,更重要的是能在嘈杂冲突来源异构的输入里做出稳健判断。这个能力 prompt engineering 很难给你,必须靠训练把它压进权重。
九、我的判断——亮点、问题和工程启发
聊点主观的。
这篇论文真正打动我的地方
用一个被人类专家验证了几十年的工具来填补 LLM 多 Agent 的方法论空白。说实话当前的多 Agent 工作很多停留在"加 Agent、设角色、定通信"的工程层面,缺一个理论支撑——为什么这么搭就 work,为什么换一种就不 work。AgentCDM 给了一个答案:因为人类决策也面临同样的认知偏差,而我们已经知道怎么对付这些偏差。直接拿来用就完了。
两阶段训练的设计很扎实。脚手架 + 撤脚手架这套思路其实不新(课程学习领域有很多类似工作),但作者把它跟 ACH 协议结合得非常干净——Stage 1 解决"会不会做",Stage 2 解决"做得好不好"。消融实验里 Scaffolding-Only 反而比 Vanilla prompt 差的发现,是这套设计最有说服力的证据。
我觉得还有问题的地方
异构 Agent 池的"异构"程度其实有限。论文里的异构是用 5 个不同的开源/闭源模型来生成候选答案。但真实场景里的 Agent 异构更复杂——同一个模型不同的 prompt 工程会产生异构、调用不同工具的 Agent 会产生异构、有不同知识截止时间的模型会产生异构。论文的设置偏理想化。
所有评测都是 MCQA(多选题)。这是一个限制。选择题的好处是 reward 信号干净,但 ACH 这套方法在开放式生成任务上能不能 work,论文没回答。我个人猜测开放式任务会更难——选择题至少答案空间是有限的,列假设这一步天然清晰;开放式任务你怎么列假设?
对抗性 Agent 没测。作者在 Limitations 里也承认了——当前框架假设所有 Agent 是合作的。如果有 Agent 故意输出错误信息或者尝试操纵决策,AgentCDM 会怎么表现?这是个开放问题,但在真实部署里其实挺重要的,比如多供应商混部场景。
Reward Hacking 的风险。Stage 2 用 BGE-M3 算余弦相似度作为软 ACH reward,理论上模型可以学会生成"语义上跟 ACH 协议相似但内核空洞"的文本骗 reward。论文没讨论这一点。
工程上能拿走的东西
不管你做不做多 Agent,这篇论文里有几个思路是普适的:
-
结构化推理强约束 + 软约束的二次训练——任何"想让模型学到某种思维流程"的任务都可以参考这个模式。直接给硬 reward 模型会学形式不学内核,必须用一个软化阶段拉出来。
-
课程退火做约束撤除——cosine 调度比硬切换稳定得多。如果你在做 SFT → RLHF 的过渡或者类似的二段式训练,可以试试这种平滑过渡。
-
假设-证据矩阵作为推理输出的强制结构——这个套路其实可以直接套用在任何需要"综合多个信息源"的 LLM 任务上:法律分析、医疗诊断、代码审查、多文档问答。不一定非要走完整 ACH,但"列竞争假设 + 找反对证据"这两步几乎是免费午餐。
-
底座越弱越要靠结构化推理——这点对预算有限的团队特别重要。如果用不起 GPT-4 级别的模型,那就靠 ACH 这种结构化方法把弱模型的能力榨出来——Mistral-7B 从 32.5 到 61.8 就是证明。
收尾
回到开头那个问题——多 Agent 投票为什么投不出共识?因为投票是后处理,而决策需要的是结构化前处理。AgentCDM 给出的答案不是"换一种投票方法",而是"把投票这个动作本身废掉,换成证据驱动的假设评估"。
这个思路超越了具体的实现细节。哪怕你用的是 Llama-4、Qwen-3、或者明年的新模型,只要任务里有多个信息源需要综合、有冲突需要解决、有偏差需要规避,ACH 那套七步流程都值得试一试。结构化推理在 LLM 时代不会过时,反而会越来越重要——因为模型能力越强,输出越自信,被它说服的成本就越低,反过来对决策结构的需求就越大。
我个人会把这篇论文放进"过去半年最值得复现的多 Agent 工作"短名单里。代码和模型作者还没放出来,但 ACH 协议本身就是文章里那张图,复制粘贴就能用——这恐怕也是这篇论文最大的价值:它把一个有效的方法论摊开放在桌面上,所有人都能直接拿走用。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我