UnPRM:用"不确定性"省 60% PRM 标注成本,再回头修一遍多数投票
我读这篇论文的时候,脑子里一直在打架。
一边是"PRM 又一次降本 N 倍"的常见叙事——MC 采样、Adaptive Binary Search、LLM-as-Judge,过去一年里 EpicPRM、Math-Shepherd、PRM800K 都在卷这个赛道。另一边是它后半段那个稍微不太一样的设定:Majority Vote 和 PRM 各有各的失败模式,把它们融合一下能不能在 Best-of-N 上做得更好?
这第二件事让我多停了一会儿。把"explicit 的 PRM 信号"和"implicit 的 majority 信号"做成可加权的混合,乍看是工程小聪明,但确实抓住了一个我自己用 BoN 时反复见过的现象:当 LLM 在 128 个采样里只有不到 20 个命中正确答案时,majority vote 会把模型集体跑偏的错误固化下来,而 PRM 这时反而能选出少数派的正确解。
论文:Uncertainty-Based Methods for Automated Process Reward Data Construction and Output Aggregation in Mathematical Reasoning 作者:Jiuzhou Han、Wray Buntine、Ehsan Shareghi(Monash 团队) arXiv: https://arxiv.org/abs/2508.01773 收录:AAAI 2026 代码:https://github.com/Jiuzhouh/UnPRM
整篇论文实际上是两个独立但同源的贡献,被绑成了一篇:
- 贡献 A:用 token 级 entropy 做不确定性,引导 PRM 训练数据的"采样 + 标注"。40K 数据训出来的 UnPRM,能在 ProcessBench 上压住 Math-Shepherd(445K)/ RLHFlow(253K)/ EurusPRM(500K)这一票更大数据集的 PRM。
- 贡献 B:发现 Majority Vote 和 PRM 在不同答案频率区间各有盲区,提出 HMR 和 WRF 两种混合聚合策略,在 BoN 上稳定优于两者中任意一个。
下面我按这两条主线分别拆。
1. 第一条主线:用不确定性做 PRM 数据的"采样 + 标注"
1.1 PRM 标注的真痛点:人工太贵,自动太糊
PRM800K 那批人工标注是 RLHF 时代的"金本位",但每条解的每一步都要人看,成本不可持续。后续自动标注大致两条路:
- MC 路线(Math-Shepherd、OmegaPRM):从某一步往后采 N 条续解,看正确率,作为这一步对错的代理。
- LLM-as-Judge 路线(GenPRM、ReasonGenRM):让强模型直接对每一步打 critique。
两条路都不便宜——MC 要采几十上百条 trajectory,LLM-as-Judge 又得跑 GPT-4 级别的 inference。EpicPRM 那篇用了 Adaptive Binary Search,把"找到第一个错误步"的开销压下来一些,但本质还是要在错误解的所有步上反复 verify。
UnPRM 的关键 insight 是:LLM 出错的地方,大概率就是它自己最不确定的地方。如果能用每一步的 token 级 entropy 来排序 candidate steps,就能在前 1~2 个最可疑步上找到错误,省掉对前面正确步的浪费验证。
1.2 不确定性怎么算
定义很直接。对一条 n token 的解,取每个 token 的 log-prob,softmax 之后得到 \([z_1, z_2, ..., z_n]\),求 entropy:
我对这个定义有一个小不舒服的地方:标准 token-level entropy 应该是用 LLM 在每个位置上对整个词表的输出分布算 \(-\sum_v p(v|x_{<i}) \log p(v|x_{<i})\),而论文这里把 token log-prob 序列再 softmax 一次得到一个新的概率向量,再算 entropy。这不是经典定义。它衡量的更接近"哪几个 token 在这条解里相对最不确信",而不是"模型在每个位置整体多不确信"。结果上能 work,是因为这两个量在大多数 case 下高度相关,但严格说不是一回事。
不管怎么样,作为代理指标——它在后面的 ProcessBench 评测和成本分析里用得很顺。
1.3 数据生成与标注流程
整个 pipeline 我先用伪代码梳理一下:
对 MATH 训练集中 3500 道题:
对每道题用 Llama-3.1-8B / Qwen2.5-7B / Mistral-7B 各采 32 条解(temp=0.8)
按 ground truth 拆成 correct / incorrect
从 correct 里挑 entropy 最大的 2 条("被勉强做对的")
从 incorrect 里挑 entropy 最大的 6 条("被自信地做错的")
→ 进入标注阶段
对每条 correct 解:所有步打 True
对每条 incorrect 解:
对每一步 s_t 算 step-level entropy u(s_t)
算 Δu(s_t) = u(s_t) - u(s_{t-1}) 作为"不确定性突变"
按 Δu 降序排
对排序后第 1 个候选步 s_i:
从 s_i 开始 adaptive 采样 N 条续解
计算 MC-perplexity MC_PPL(s_i):
= (correct 续解的 logPPL 之和) / (全部续解的 logPPL 之和)
if MC_PPL(s_i) < τ: # τ = 整道题初始状态的 MC_PPL
s_1..s_{i-1} 标 True,s_i..s_T 标 False
break
else: 看下一个候选步
这里有两个我觉得很巧但论文没充分强调的设计:
第一,"从 correct 里挑最不确信的 2 条"这个选择。直觉上 PRM 训练集里塞确定无误的 correct 解没意义——容易学偏成"看长度"或"看格式"。挑 entropy 最大的 correct 解,相当于喂"勉强做对的边界样本",逼 PRM 学会区分"看似漂亮但有微小问题的步骤"和"真正稳健的步骤"。这个数据筛选思路在 active learning 里有先例,但放在 PRM 数据构造里我没在别的地方见到这么明确的表述。
第二,按 Δu 而不是 u 排序找错误。原始 entropy u(s_t) 高可能只是因为这一步本身长(计算密集)或者用了少见词。差分 Δu 把"本步相比上一步的不确定性增量"提取出来——这才是"模型从这一步开始拿不准了"的真信号。从 Table 4 看,Llama / Qwen / Mistral 三个模型平均只需要验证 1.33 / 1.51 / 1.34 个候选步就能定位错误(最优是 1.0),说明这个排序非常精准。
1.4 成本:比 Adaptive Binary Search 省 40%~52%
| 算法 | Verified Steps | Sampled Num | Generated Tokens |
|---|---|---|---|
| Adaptive Binary Search | 3144 | 104.98K | 36.44M |
| UnPRM 本文 | 1498(省 52%) | 69.25K(省 34%) | 21.75M(省 40%) |
测试集是 1500 条解(460 correct + 1040 incorrect)。注意这里的对照是 EpicPRM 的"找第一个错误步"路线——它已经是当时最经济的自动标注方案之一。UnPRM 在它基础上再省一半 verified steps。
这个数字我信。逻辑也清楚:Binary Search 要在所有步上做对数次验证,UnPRM 直接按"最可疑步"排序后命中即停,平均只查 1.5 个候选步。
1.5 ProcessBench:40K 打 200K~500K
| 模型 | 训练数据量 | GSM8K | MATH | Olympiad | Omni-MATH | Avg |
|---|---|---|---|---|---|---|
| Math-Shepherd-PRM-7B | 445K | 47.9 | 29.5 | 24.8 | 23.8 | 31.5 |
| RLHFlow-PRM-Mistral-8B | 273K | 50.4 | 33.4 | 13.8 | 15.8 | 28.4 |
| RLHFlow-PRM-Deepseek-8B | 253K | 38.8 | 33.8 | 16.9 | 16.9 | 26.6 |
| EurusPRM-Stage2-7B | 500K | 47.3 | 35.7 | 21.2 | 20.9 | 31.3 |
| Qwen2.5-Math-7B-RanPRM40K | 40K | 35.5 | 25.5 | 15.7 | 17.3 | 23.5 |
| Qwen2.5-Math-7B-SimPRM40K | 40K | 51.2 | 38.5 | 29.5 | 27.4 | 36.7 |
| Qwen2.5-Math-7B-UnPRM40K | 40K | 53.5 | 43.4 | 33.6 | 30.8 | 40.3 |
| Qwen2.5-Math-7B-EpicPRM40K | 40K | 53.1 | 44.6 | 31.8 | 33.6 | 40.7 |
| Qwen2.5-Math-7B-PRM800K | 264K | 68.2 | 62.6 | 50.7 | 44.3 | 56.5 |
| Qwen2.5-Math-PRM-7B | 1.8M | 82.4 | 77.6 | 67.5 | 66.3 | 73.5 |
我盯着这张表反复看,有几个有意思的发现:
- UnPRM40K 平均 40.3,比同样 40K 的 SimPRM40K(36.7)高 3.6 个点,说明"按不确定性挑 candidate solution"比"按相似度挑"信号更强。
- UnPRM40K 比 4x~12x 数据量的 RLHFlow / Math-Shepherd / EurusPRM 都强 9~14 个点,这个对比很硬。
- UnPRM40K 跟 EpicPRM40K(40.7)几乎打平,但 UnPRM 在 GSM8K / MATH / Olympiad 上略高,EpicPRM 在 Omni-MATH 上反超。这说明"找最不确定的错误步"和"找第一个错误步"是各有偏好的标注哲学——UnPRM 倾向标注"模型自己迷路的地方",EpicPRM 倾向标注"链条上第一个崩的地方"。前者对 in-distribution 的 MATH/GSM 友好,后者对 OOD 的 Omni-MATH 略好。
- 跟 Qwen2.5-Math-PRM-7B (1.8M, 73.5) 还差 33 个点——这条提醒我们别神化 40K:人工标注 + 大数据量仍是 PRM 的天花板。UnPRM 卖的是"在自动标注 + 小数据 + 低成本"这个 niche 上的 Pareto 改进,不是范式级颠覆。
2. 第二条主线:Majority + PRM 的混合聚合
第一条主线讲完,论文换了一个频道,开始处理"BoN 怎么聚合答案"的问题。这块给我的启发反而比 PRM 数据构造那块更大。
2.1 Majority 和 PRM 各自在哪里翻车
论文 Figure 3a 把 MATH 测试集 500 道题在 Qwen2.5-Math-7B-Instruct 上 128 采样的 gold-answer 频率画了个分布:
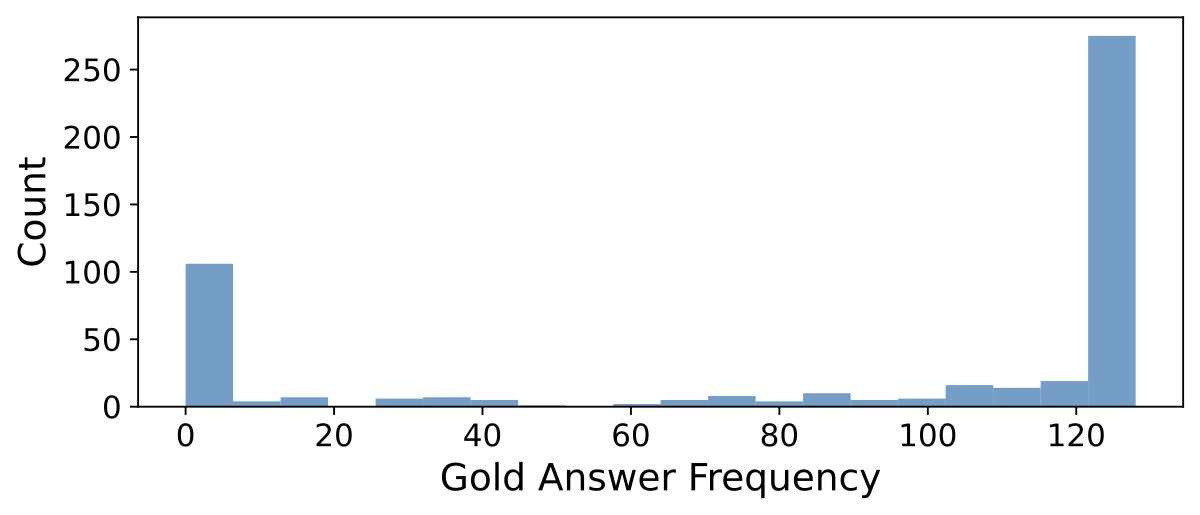
横轴是"在 128 条采样里正确答案出现了多少次",纵轴是问题个数。两端密度都很高: - 一端是 250+ 道题,128 条全对(Majority 闭眼选都行) - 另一端是 100 道左右,128 条一次都没对(再聪明的 PRM 也救不回来) - 中间是真正吃功夫的 100~150 道题,gold answer 频率在 1~120 之间分布
Figure 3b 在这同一个测试集上把四种聚合方法(Majority / PRM / HMR / WRF)的 per-question 正确性按 gold-answer 频率画成 swarm plot:
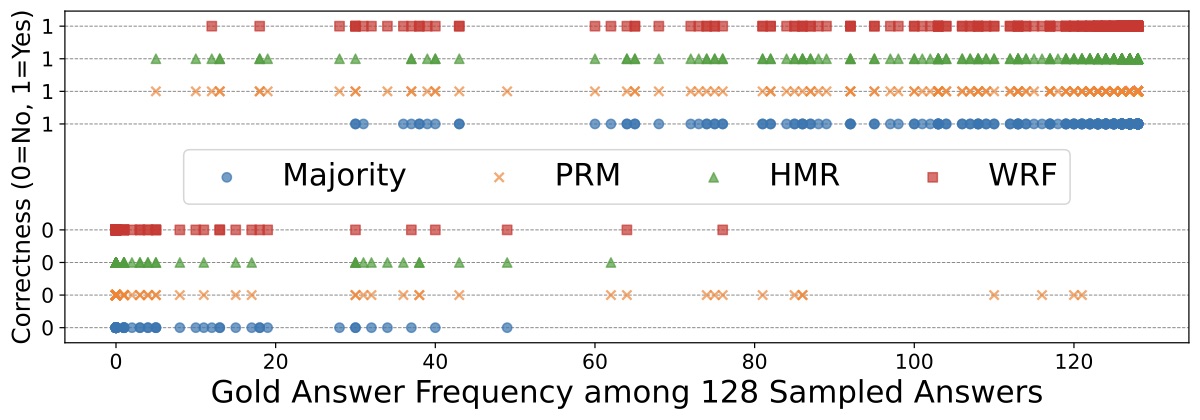
Majority 在高频区(gold > 60)几乎不出错,但在低频区(gold < 20)大面积失守——因为这时 majority 选中的不是 gold answer。PRM 反过来:低频区还能挑出少数派正确解,但在高频区它有时反而选了错的少数派——PRM 的训练分布不一定 cover 所有 case,它会被一些"高 reward 但答案错"的解骗到。
这两个失败模式是互补的。所以混合策略的存在意义是清楚的——不是"试试看效果会不会更好",而是"两个方法的失败区间不同,叠加在数学上几乎一定能改进"。
2.2 HMR:先看共识,没共识再看 PRM
HMR (Hybrid Majority Reward) Vote 的逻辑很简单:
- 如果 majority 答案在 N 个采样里出现频率 \(f_{\text{maj}} \geq N/2\)(绝对多数),直接选 majority。
- 否则,对每条解用 PRM 打 step-wise 分,取 min 作为 solution-level reward,选 reward 最高的解的答案。
这个 fallback 设计抓得很对:majority 在"绝对多数"时基本无敌,PRM 只在"没人能形成共识"时才被请出来。
2.3 WRF:把频率和奖励都归一化后加权
WRF (Weighted Reward Frequency) Vote 更精致一点:
- 对每个 candidate answer \(a\),先收集所有产生这个答案的 solutions,对每条解用 PRM 算 step-wise min reward。
- 对每个独特答案 \(a\) 算两件事:平均 PRM reward \(m_a\)、出现频率 \(f_a\)。
- min-max 归一化得到 \(\hat{m}_a, \hat{f}_a \in [0, 1]\)。
- 最终得分 \(\text{score}_a = \alpha \hat{m}_a + (1 - \alpha) \hat{f}_a\),论文设 \(\alpha = 0.5\)。
WRF 的优点是它没有"硬切换"——HMR 在 \(f_{\text{maj}} = N/2\) 这个临界点会有不连续行为,WRF 是平滑加权。这也解释了后面 mid-frequency(gold answer 出现 20~40 次)区间 WRF 比 HMR 更稳。
2.4 不同 PRM × 不同 reasoner 上的稳健性
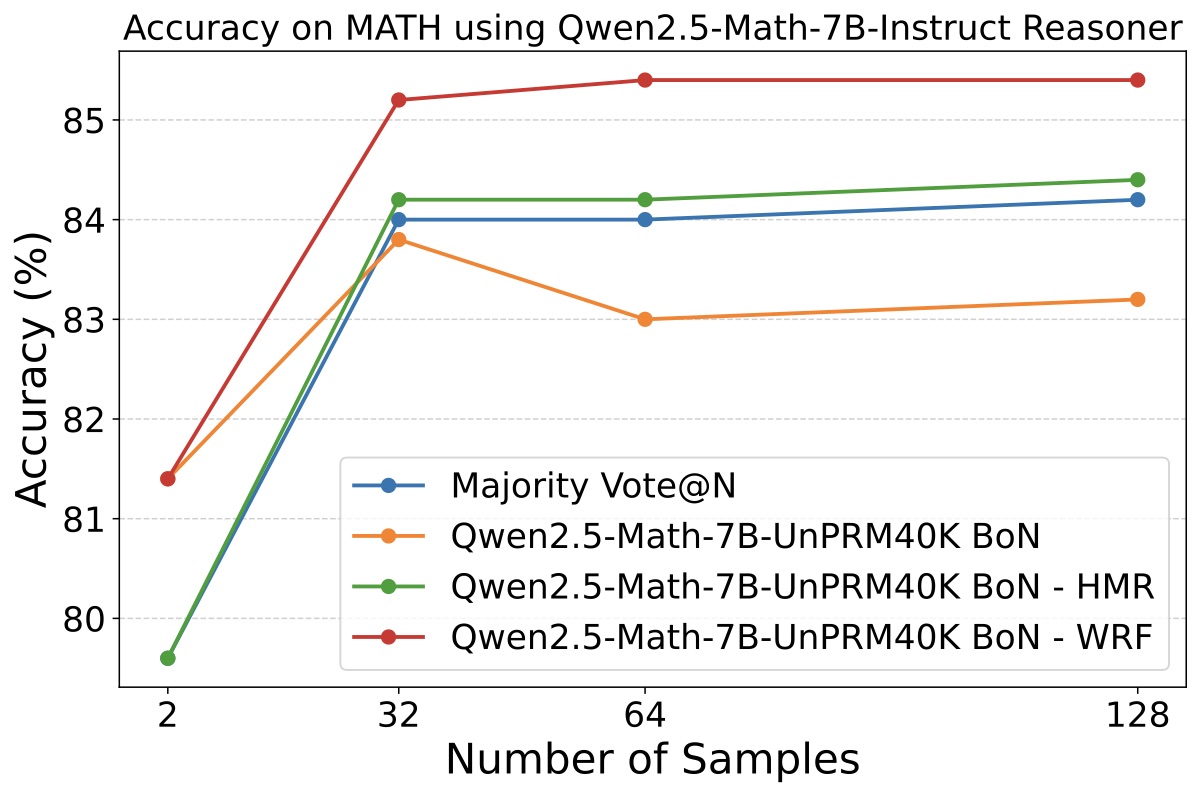
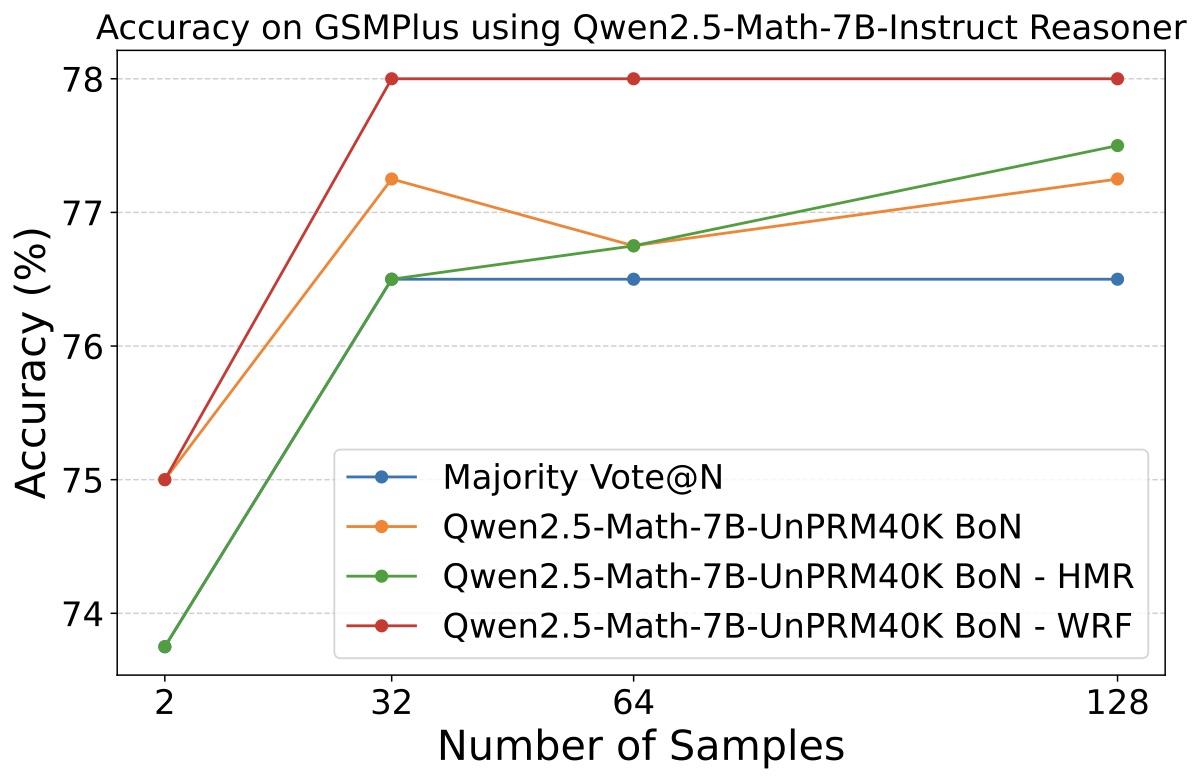
论文用 Qwen2.5-Math-7B-Instruct 作为 reasoner,跑了 UnPRM40K / Qwen-PRM-7B (1.8M) / PRM800K 三个 PRM × Majority / PRM / HMR / WRF 四种聚合 × MATH/GSMPlus 两个数据集,画了 6 张子图。挑两张代表性的:
我抓到三个一致出现的现象:
- HMR 和 WRF 几乎在所有 (PRM, reasoner, dataset, N) 组合上都稳定胜过 Majority 和 PRM 单项。这点很硬,不是 cherry-pick。
- WRF 比 HMR 总体更稳,特别是 N=64 / 128 的高采样数下差距更明显。这是因为采样越多,gold-answer 频率分布越稀疏,硬切换型的 HMR 越容易在临界点附近震荡。
- 当 PRM 单独表现弱于 Majority 时,HMR/WRF 的提升最大——因为这时 fallback 到 majority 的部分起到了校正 PRM 错误的作用。这个现象证明了"两个方法在互补区间救对方"的猜想。
2.5 这部分对我的启发
如果你做 BoN 推理 / inference-time scaling 这一类工作,这两个混合聚合策略的实现成本几乎为零(HMR 是 if-else + min-reward,WRF 是 min-max norm + 加权和),但带来的稳健性提升很值得搞。我个人觉得 WRF 的 \(\alpha\) 应该是可学的而不是固定 0.5——不同 PRM 在不同数据上质量不一样,让 \(\alpha\) 在 validation set 上调一下大概率能再榨出点性能。论文留了这个口子,没去做。
3. 我的几条批判笔记
读完整篇,我有几个想说的:
第一,"40K 打 500K" 的故事被表 1 一定程度上削弱了。表里 Qwen2.5-Math-PRM-7B (1.8M) 的 73.5 摆在那儿,差距 33 个点。论文卖的是"小数据 + 自动标注 + 低成本",但读者很容易被引导成"40K 就够了"。其实想做 SOTA 该上人工标注 + 大数据,UnPRM 是给"没那么多预算" 的团队的方案。这一点论文写得算克制,但还是值得明确强调。
第二,"3 个 LLM 各采 32 条"这个采样配置没消融。Llama / Qwen / Mistral 三家差别很大(Mistral 数学能力明显弱于另两家),它们对 UnPRM40K 的贡献分布是不均匀的——Table 4 显示 Llama 贡献了 20264 条样本,Qwen 12019,Mistral 8223。如果只用一家 LLM 采样,UnPRM 还能保持 40.3 平均分吗?这个消融如果做了会更可信。
第三,HMR 的硬切换条件 \(N/2\) 没消融。0.5 这个阈值看着很自然,但 0.4 / 0.6 在不同 N 下表现可能差很多。如果做了 sensitivity 分析就能避免读者怀疑这个数字是 cherry-pick 的。WRF 的 \(\alpha = 0.5\) 同样有这个问题。
第四,OOD 评测缺失。所有评测都在 MATH / GSM-family / ProcessBench 这种数学推理上。UnPRM 的不确定性筛选在数学上 work,是因为数学解的"对错有 ground truth、token entropy 与对错强相关"。换到代码生成、open-ended QA、多步 agent 任务上,token entropy 是不是还能做"出错信号"?论文一句没提。
第五,跟 GenPRM / Critique-RM 这一线 generative-based PRM 没正面比较。这条线的代表(前面我刚解读过的 GenPRM, arXiv 2504.00891)在 ProcessBench 上 1.5B 就能打 GPT-4o-mini。UnPRM 跟它们是不同范式(discriminative vs generative),但都打 ProcessBench,应该有 head-to-head 的数据。论文没给。
第六,"不确定性"这个词的定义不太干净。前面提过:用 token log-prob 的 softmax 再算 entropy,不是标准 entropy 定义。这个细节在论文里被一笔带过,但严格 reviewer 会抓。如果换成标准的 token-level distribution entropy(要保留 logits 而不只是 sampled token 的 log-prob),结论是否仍成立?没人知道。
4. 我从这篇里学到的 3 件事
放在结尾——抛开 paper 评判,纯讲方法学层面:
- PRM 数据构造时,"挑最难的 correct + 最难的 incorrect" 比 "挑随机的" 强一档。Active learning 在 RLHF 时代复活了,UnPRM 是个不错的 case study。
- Δentropy(不确定性突变)比 entropy 本身更适合定位错误。原始 u 容易被 token 长度、词频污染,差分 Δu 把"模型从哪一步开始拿不准"这件事抽干净了。这个差分 trick 在很多其他 token-level signal 上也值得试。
- Majority + PRM 的混合聚合在 BoN 推理里几乎是个免费午餐。实现成本几行 Python,性能在多个 (PRM, reasoner, dataset) 组合上稳定提升。如果你在做 inference-time scaling,HMR/WRF 至少应该作为 baseline 跑一次。
最后我想串联一下我前几篇解读:DeCoRL(前一篇,arXiv 2511.19097)讲"模块拆分 + 反事实奖励"——它的 contribution reward 其实也是"哪个模块缺了影响最大"的不确定性度量;GenPRM(再前一篇,arXiv 2504.00891)讲"生成式过程奖励 + 代码验证 + RPE 标签"——它的 RPE 标签其实就是"这一步的相对不确定性"。三篇方法看起来不一样,底层都在做同一件事:用某种不确定性 / 相对差距信号来精准化奖励信号。这条主线值得长线跟踪。