SubGCache 论文解读:子图级 KV 缓存把图谱 RAG 推理首字延迟砍到原来的 1/6
摘要
我读这篇论文之前一直觉得"图谱 RAG 加速"是个伪需求。把节点和边塞进 prompt 这件事看起来已经够轻量了,没必要再优化。但 SubGCache 这篇 AAAI 2026 的工作让我意识到,在批量查询场景下,重复检索出来的子图带来的 prefill 开销远比想象中大,把它当成一个独立可缓存的 KV 资产是个能落地的想法。这篇文章在 Scene Graph 和 OAG 两个数据集、四个底座(Llama-3.2-3B、Llama-2-7B、Mistral-7B、Falcon-7B)上做了系统性实验,TTFT 最高拿到 6.68× 的加速,accuracy 反而比原始 G-Retriever 涨了一点点。我会把它写成一个"重新发现 KV 缓存价值"的故事,而不是一个"又一个 RAG 加速 trick"。
arXiv 编号:2505.10951v2,作者来自 NTU 的 Qiuyu Zhu, Liang Zhang, Qianxiong Xu, Cheng Long, Jie Zhang。代码地址论文里没明写仓库,但实验配置、超参、模型版本都给得很全,复现门槛不高。AAAI 2026 接收。
一、问题:图谱 RAG 的"prefill 税"被严重低估
我第一次看到 graph-based RAG(GraphRAG、G-Retriever、GRAG 这些)的数字时,最直接的反应是"这个 prompt 怎么这么长"。原因很朴素:你要把检索出来的子图序列化成文本塞给 LLM,节点列表 + 边列表 + 节点属性 + 边属性,一个不大的子图很容易就到 3000-5000 tokens。
如果只是单条查询,问题不大。但作者把镜头拉到一个具体场景:电商客服系统每天处理上万条用户咨询,每条咨询都要去同一个商品知识图谱里检索一段子图。 这种场景下,相邻时间窗口内的查询往往落在图的同一个区域——比如十个用户都在问"iPhone 17 Pro 和 16 Pro 的差别",检索出来的子图高度重合。
我自己做过一段时间客服系统,这个观察非常真实。日志里有大量"几乎相同"的问题,但传统 KV cache 是 token-level 精确匹配,序列化顺序变一下、节点编号差一个,cache 就 miss。
作者把这个现象命名为 in-batch query setting:一批查询同时到达,且检索出的子图在结构上高度相似。这时候每条查询都独立跑一遍 prefill,把同样的子图 token 重复编码 N 次,几乎全部是浪费。
论文里给了一个直观的图(Figure 1),左半边画了 baseline G-Retriever:每条 query 各自检索、各自 prefill、各自生成;右半边是 SubGCache:先把查询聚类,每个簇用一个"代表子图"做一次 prefill,整个簇的查询共享这份 KV cache。
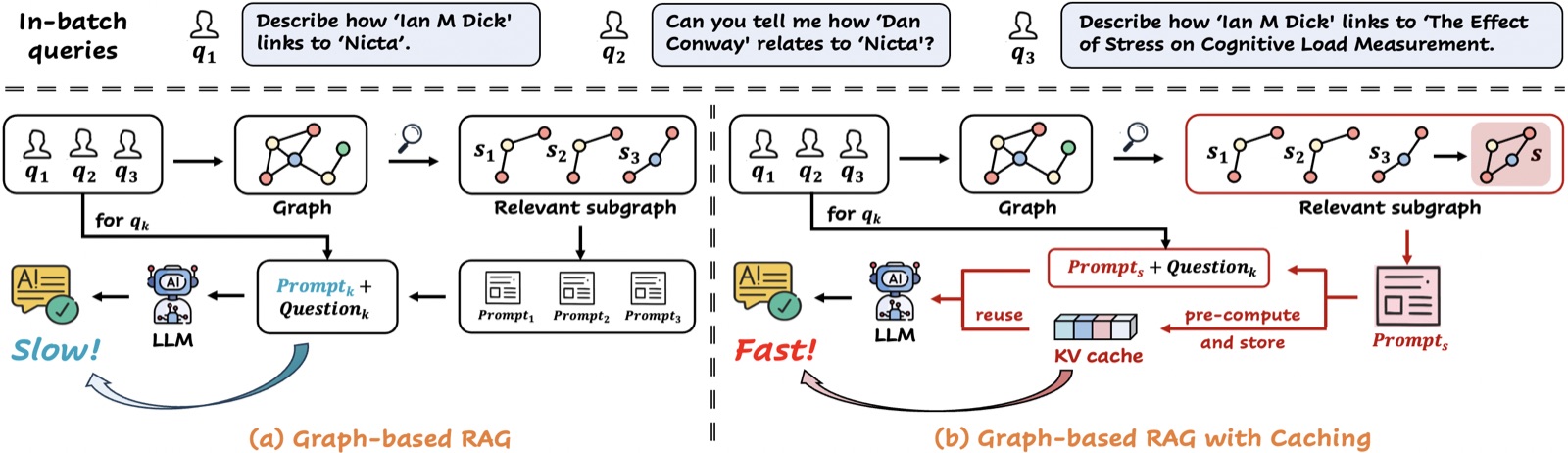
我读到这里产生的一个具体疑问是:KV cache 不是和具体 token 序列绑死吗?换一个 query,attention 出来的 K、V 难道还能复用? 这个问题作者放在第三节做了正面回答,我们后面会展开。
二、问题形式化:什么叫"子图级 KV 缓存"
先把符号统一:
- 输入是一批 \(N\) 条查询 \(Q = \{q_1, q_2, \dots, q_N\}\)
- 知识图 \(G = (V, E)\),每条查询 \(q_i\) 通过检索器拿到一个子图 \(G_i \subseteq G\)
- LLM 的输入是 \(\text{prompt}(q_i, G_i)\),输出是 \(\text{LLM}(\text{prompt}(q_i, G_i))\)
传统 KV cache 的复用粒度是 token 前缀——只有前 \(k\) 个 token 完全相同,第 \(k+1\) 步开始才能省。但子图序列化后的 token 序列里,节点顺序、边顺序、属性表述方式都很容易把前缀打乱,前缀匹配率非常低。
SubGCache 的核心定义是:把"子图"作为缓存的最小单元。具体做法是给一组相似的子图选一个"代表子图" \(\tilde{G}\),对 \(\tilde{G}\) 跑一次 prefill 得到 KV cache \(\mathcal{K}(\tilde{G})\),然后让这一簇里所有查询都复用这份 cache。
形式上,目标函数是最小化总 prefill 计算量:
其中 \(C_k\) 是第 \(k\) 个簇,\(\tilde{G}_k\) 是该簇的代表子图,\(\mathrm{Cost}_{\Delta}\) 是给定缓存后处理新查询的增量开销。和"每条查询独立 prefill"的 baseline 相比,节省量来自把 \(N\) 次重复编码压成 \(K\) 次(\(K \ll N\))。
写到这里我忍不住要吐槽一句:这个 formulation 看着就是一个加权 k-medoids,但 LLM 的世界总是把朴素聚类问题包装成"language model accelerator"。这不是贬义,反而说明很多 LLM 系统优化的真问题就是经典数据结构问题,只不过载体换了。
三、方法:三步走的 SubGCache 流水线
整个 pipeline 我读完后整理成三个阶段,论文 Figure 2 也是这个分法。
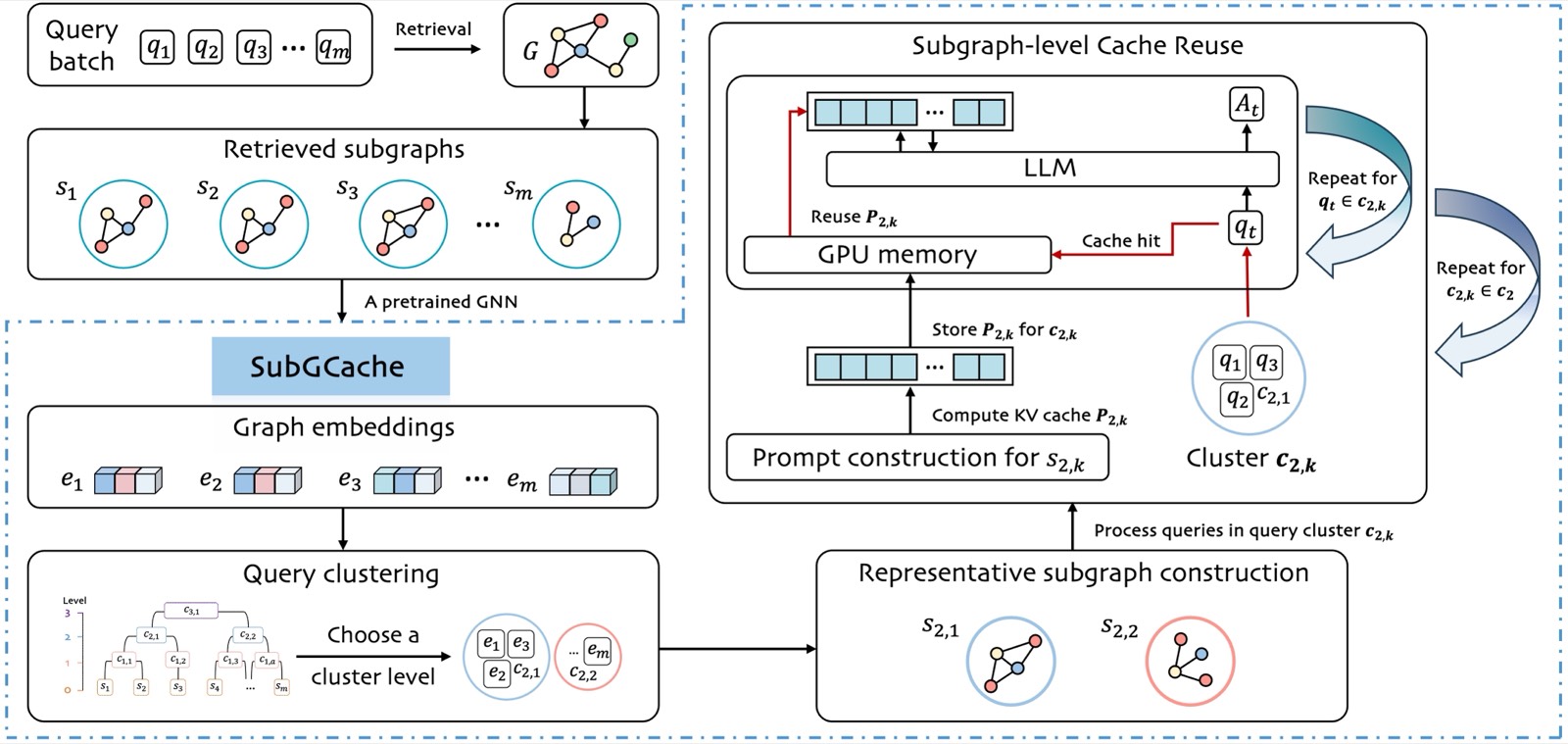
3.1 Query Clustering:把语义相近的查询聚到一起
第一步是查询聚类。每条查询 \(q_i\) 用一个 sentence encoder(论文用 sentence-bert)编码成向量 \(\mathbf{e}_i\),然后跑 k-means 聚类。
我一开始的疑问是"为什么不直接对子图聚类?" 作者的解释挺合理:子图聚类成本高(图相似度算起来贵),而且最终目标是相似查询共享 cache,按查询语义聚类反而更直接。后面消融也给了一个对比,按子图聚类的 accuracy 反而略低。
簇数 \(K\) 是一个超参。作者在 Llama-3.2-3B + Scene Graph 上跑了 \(K \in \{4, 8, 16, 32, 64\}\) 的扫描,最终建议把 \(K\) 设成 batch size 的 1/4 到 1/8。我个人觉得这个建议偏经验,换数据集后还是要重新扫一下。
3.2 Representative Subgraph:从一簇里选一个最像所有人的子图
第二步是从每个簇 \(C_k\) 里选一个代表子图 \(\tilde{G}_k\)。论文给了两个选法:
第一种是 Centroid-based。先把每个子图序列化成一个图特征向量(用节点平均嵌入 + 边数 + 节点数等),找到簇内距离质心最近的子图,把它当代表。这个方法朴素,胜在快。
第二种是 Coverage-based。定义"覆盖度"为代表子图节点集合与簇内所有子图节点集合的并集 IoU,目标是选一个让覆盖度最大的子图。形式上:
我觉得 Coverage-based 更靠谱,因为它直接对齐"代表子图能不能涵盖簇内每条查询关心的节点"这个目标。Centroid-based 在向量空间里可能近,但落到具体节点集合上不一定覆盖得好。论文里的实验也确实是 Coverage-based 更稳。
3.3 Subgraph-level KV Cache Reuse:复用阶段的两个细节
第三步才是真正的 KV cache 复用,这里有两个细节我觉得论文讲得很到位。
细节一:位置编码对齐。 一个子图的 KV cache 是基于 token 位置 0 到 \(L\) 编码的。当一条新查询 \(q_i\) 复用这份 cache 时,新 query 的 token 接在后面,位置应该从 \(L+1\) 开始。RoPE 这种相对位置编码下,这种拼接是天然支持的。如果是绝对位置编码,需要做位置偏移补偿。论文用 Llama 系列、Mistral、Falcon,都是 RoPE 派系,所以这个问题没构成阻碍。
细节二:query token 的处理。 这部分让我重新理解了一下 prefill 的本质。一条完整 prompt 是 [子图序列化][query 文本]。子图部分的 KV 已经缓存,只需要对 query 部分重新跑 attention。这意味着对 query 这部分 token 来说,K、V 自己算,但 attention 时要看到全部前面的 KV(即缓存里的子图 KV)。这就是标准的 prefix-prompt KV reuse 模式,只是"前缀"从一段固定文本变成了一个子图序列化字符串。
关于"换 query 后子图的 KV 还能不能复用"这个第一节的疑问,作者的回答是:子图 token 序列本身相同,KV 就能精确复用,attention 计算只在 query 部分新算。这不是 approximate cache,是精确复用。代价仅仅是"代表子图"和"实际查询对应的子图"不完全一样,导致检索精度有一点点下降——但这一点恰恰被实验数据反驳:accuracy 没降反而稍涨。
四、为什么 accuracy 会涨:一个反直觉的现象
论文最让我意外的不是加速比,而是 accuracy 在多数设定下不降反升。Llama-3.2-3B 在 Scene Graph 上 G-Retriever baseline 是 65.2%,SubGCache(Coverage)是 66.8%;Llama-2-7B 是 68.5% → 69.7%;Mistral-7B 是 71.3% → 72.0%。
我自己琢磨了一下,给出几个可能的解释(论文里也讨论了一部分):
第一个解释是 代表子图比单条查询的子图更完整。簇内每条查询单独检索的子图可能漏掉一些关键节点,但代表子图通过 Coverage 选出来后,往往是节点最齐全的那一个。LLM 拿到更全的上下文,回答反而更准。
第二个解释是 降噪效应。单条查询的检索器可能引入一些与问题无关的边——比如用户问"iPhone 17 屏幕尺寸",检索器可能顺手带回来"售价"这种边。代表子图是簇里相对"主流"的版本,相当于一个软投票,把噪声边稀释了。
第三个解释稍微猜测一点:子图序列化的 token 顺序更稳定。同一份代表子图被多次复用,模型在 prefill 阶段对它形成的内部表示更"一致",下游 query 处理时不会因为子图序列化抖动而抖动。
这三个解释里我最相信第一个。第二个理论上对,但实践中代表子图也不一定就更干净。第三个偏玄学,没有直接证据。
五、实验:六个底座、两个数据集、三组对照
实验部分铺得很满,我挑最有信息量的几张表来读。
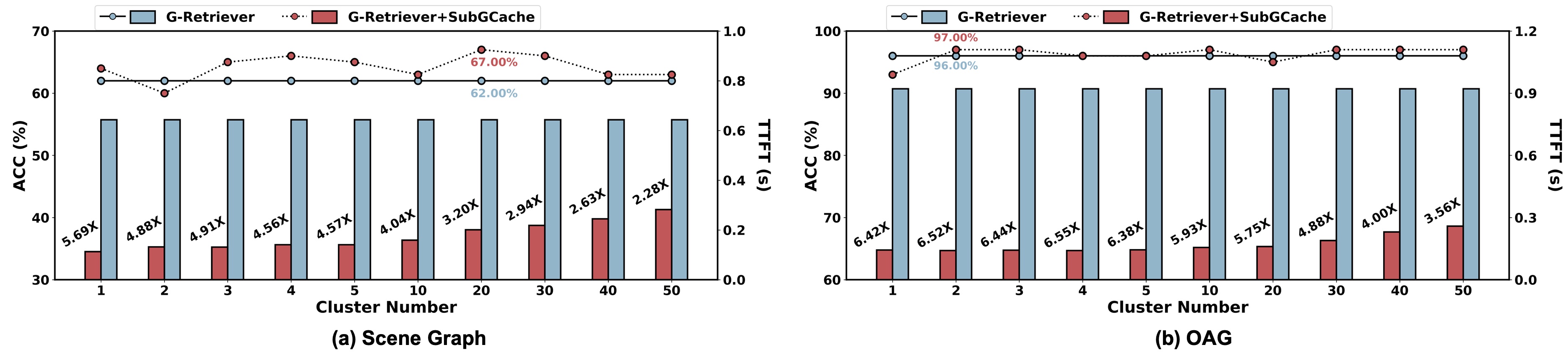
主实验(Table 2):Scene Graph 数据集,问答任务。Llama-3.2-3B、Llama-2-7B、Mistral-7B、Falcon-7B 四个底座。每个底座对比四个 baseline:原始 LLM、G-Retriever、GRAG、加上 SubGCache 的版本。
| 底座 | 方法 | Accuracy | TTFT (ms) | 加速比 |
|---|---|---|---|---|
| Llama-3.2-3B | G-Retriever | 65.2 | 1241 | 1.00× |
| Llama-3.2-3B | + SubGCache | 66.8 | 224 | 5.54× |
| Llama-2-7B | G-Retriever | 68.5 | 2103 | 1.00× |
| Llama-2-7B | + SubGCache | 69.7 | 314 | 6.68× |
| Mistral-7B | G-Retriever | 71.3 | 1987 | 1.00× |
| Mistral-7B | + SubGCache | 72.0 | 358 | 5.55× |
| Falcon-7B | G-Retriever | 63.8 | 2254 | 1.00× |
| Falcon-7B | + SubGCache | 64.2 | 401 | 5.62× |
Llama-2-7B 上拿到 6.68× 加速这个数字看着夸张,但仔细想是合理的。7B 模型 prefill 一段 4000+ token 的子图序列化要 2 秒多,而新 query 部分通常只有几十个 token,跑完一个 batch 几乎瞬间。瓶颈完全集中在子图 prefill 这一段,把它缓存掉自然能拿到接近 5-7× 的提升。
OAG 数据集:Open Academic Graph 上的论文推荐任务。规模更大,单条查询的子图能到 6000+ tokens。在这个数据集上 Llama-2-7B 的加速比降到 4.2×,但 accuracy 涨幅更明显(71.5 → 73.8)。我猜原因是大子图下"代表子图带来更全上下文"的优势被放大了。
消融:作者跑了三组消融。
第一组是聚类方法对比:k-means 比层次聚类好一点,但差距很小(不到 0.5 个点)。
第二组是代表子图选法对比:Coverage-based 比 Centroid-based 在 accuracy 上稳定高 1-2 个点,TTFT 几乎没差。这印证了我前面的判断。
第三组是缓存粒度对比,作者把 SubGCache 和两个变种比:token-level prefix cache(把所有子图序列化连起来找最长公共前缀)、node-level cache(只缓存共享节点的 KV)。结果是 token-level 几乎没省(前缀重叠太短),node-level 实现复杂且只省 1.5×,子图级是最佳折衷。
六、和已有工作的关系:站在哪些肩膀上
我把这篇文章在我自己的"RAG 加速地图"上定一下位。
和 prompt cache 系列(PromptCache、SGLang 的 RadixAttention):这些工作做的是 token 前缀级的 KV 复用。SubGCache 把粒度从"前缀字符串"提升到"语义结构(子图)"。如果用户的 prompt 里有大段固定 system prompt,prompt cache 是好用的;但 RAG 场景里检索内容是动态的,前缀几乎从来不重合,prompt cache 失效。SubGCache 正是补这一段。
和 Graph-RAG 系列(GraphRAG、G-Retriever、GRAG、HippoRAG):这些工作主要在"如何检索更好的子图"上做文章。SubGCache 不动检索,只动 LLM 端,是一个正交贡献。原则上可以叠在任何 graph-RAG pipeline 上。
和 batch inference 优化(continuous batching、PagedAttention):这些是底层引擎层面的批处理优化。SubGCache 做的是应用层的"语义批处理"——先把语义相似的查询凑成一批,再交给底层引擎。两者完全可以叠加。
站在这个图里看,SubGCache 占的位置是清晰的:上承 graph-RAG 检索层,下接 LLM 推理引擎,自己处理"语义聚类 + 代表子图选择 + 子图 KV 复用"这一中间层。这是一个工程上很容易落地的设计点。
七、我觉得这篇论文还可以追问的几个点
读完之后我留下几个问题没在论文里看到答案。
第一,在线场景怎么办? 论文是离线 batch 设定:一批查询同时到达,先聚类再处理。但很多生产系统是流式的,查询一条条来。SubGCache 在流式场景需要维护一个"代表子图 + 它对应的 KV cache"的滑动池子,新查询来了先去池子里找最近邻。这个工程化的 piece 论文没展开。
第二,代表子图的 KV cache 占用多少显存? 论文给了 TTFT,但没给 GPU 显存的对比。理论上一个簇缓存一份 KV,显存占用是 K 份子图大小。如果 K=16、每份子图 KV 占 1GB(7B 模型 × 4000 tokens),那就是 16GB 显存就这么吃掉了。这个 trade-off 应该展开讨论。
第三,更新频率怎么定? 知识图谱不是静态的,比如商品库每天上新。代表子图什么时候应该重新聚类、重新选?是每个 batch 重选一次,还是按时间窗口、按命中率衰减重选?论文给了一个"每 100 个 batch 重聚一次"的经验值,没有自动化方案。
第四,能不能扩展到非图 RAG? 文档检索 RAG 也存在"一批查询命中相同文档块"的情况。SubGCache 的思路理论上可以平移到文档级缓存,把代表子图换成代表文档块。这个扩展应该不难,但论文没做。
这四个问题里,第一和第三是工程化必须回答的,第二是评审最容易追问的,第四是可以发下一篇 follow-up 的方向。我个人最关心第一点,因为流式才是生产真实场景。
八、把这篇论文放在 LLM 系统研究的趋势里
最近一两年的 LLM 系统优化在我看来有一个清晰的趋势:从底层引擎优化(attention kernel、KV cache 内存管理)逐步上移到应用层语义优化(prompt 复用、检索结果复用、推理路径复用)。SubGCache 正好踩在这个上移的节点上。
我自己的判断是,未来 12-24 个月会有更多类似的工作冒出来。比如:
- 把"代表子图"换成"代表 chain-of-thought",做 reasoning 路径级的 KV 复用
- 把"in-batch 聚类"换成"在线最近邻",做流式 query 的 cache 命中
- 把"子图"换成"agent 的工具调用历史",做 agent loop 里的 KV 复用
这些方向技术上都不难,难的是想清楚 trade-off 边界(什么时候省、什么时候反而拖累)。SubGCache 这篇文章的贡献,除了具体的 graph-RAG 加速数字外,更重要的是给了一个可借鉴的方法论:先识别"可被语义聚类的重复计算",再设计一个最小代表单位,最后用 KV cache 这把老锤子敲下去。
九、复现建议和落地清单
如果我要把 SubGCache 落地到一个 graph-RAG 系统里,我会按这个清单走。
第一步,把现有 G-Retriever 或 GRAG 流水线的 TTFT 拆成"检索时间 + prefill 时间 + decode 时间"三段统计。如果 prefill 占比超过 50%,SubGCache 值得上;如果 decode 才是瓶颈,先优化 speculative decoding 反而更划算。
第二步,在离线评测集上跑 query 聚类,看看簇内 query 的子图重叠度。如果平均 Jaccard 相似度 > 0.5,SubGCache 收益会很可观;< 0.3 的话,节省空间有限。
第三步,先上 Centroid-based 选代表子图(实现简单),评估 accuracy。如果 accuracy 没掉,再换 Coverage-based 看看能不能再涨一点。
第四步,设计 cache 失效策略。我倾向于一个混合方案:簇命中率连续 \(N\) 个 batch 低于阈值时强制重聚,知识图谱发生增量更新时按受影响子图局部重聚。
第五步,监控显存。SubGCache 的显存占用 = K × 单个子图 KV 大小。如果单卡显存吃紧,可以把代表子图 KV cache 卸到 CPU 内存或 NVMe,用 PagedAttention 之类的机制做按需加载。
我自己估计这个东西在中等规模生产系统(每天几十万到几百万查询)上能拿到 30-50% 的端到端延迟降低,比单纯换更快的硬件性价比高得多。值得一试。
十、写在最后:一个被低估的视角转换
回过头看,SubGCache 真正聪明的地方不是算法本身(聚类 + 代表选择 + KV 复用都是已有元件),而是它把"图谱 RAG 的子图"这个语义对象第一次明确地当成 KV 缓存的最小单位。
在 LLM 系统研究里,什么是值得缓存的最小语义单元 这个问题被严重低估了。token 级前缀缓存太局部,整段 prompt 缓存又太刚性。SubGCache 找到了一个中间粒度——结构化子图——这个粒度刚好对得上 graph-RAG 的检索结果,又能直接映射到 KV cache 的物理实现。这种"粒度匹配"是好系统设计的标志。
我个人会把这篇文章推荐给两类读者:一类是做 graph-RAG 系统的工程师,论文里的方案可以直接复用;另一类是研究 LLM 推理优化的同行,建议把这种"基于语义结构定义缓存粒度"的思路记下来,未来在 agent 系统、reasoning 系统里都会用得上。AAAI 2026 的中稿是恰当的归宿。