用数学训出来的 PRM,跑到代码任务上还能涨 4 个点——这事让我对"PRM 是不是被高估了"重新想了一遍
核心摘要
过程奖励模型(PRM)这两年是 LLM 推理圈的香饽饽:每一步都打分、推理走偏当场叫停,听着比"等到最后再判对错"的 ORM 高级多了。但真要做工程落地,PRM 该多大?训多少步?测试时配 MCTS 还是 Best-of-N?数据要不要按目标域专门收?这些问题答案都在 vibe 里,没几篇硬刚。这篇 AAAI 2026 / arXiv 2506.00027(美团 + 北大 + 宾州州立)做的就是这种"枯燥但极其有用"的 study:从 0.5B 到 72B 七档规模 + 三种数据集(PRM800K、Math-Shepherd、自建 ASLAF)+ 四种测试搜索(MCTS / Beam / BoN / Majority),把 PRM 的所有维度横扫了一遍。最反直觉的一条结论:用纯数学数据训的 PRM,搬到 HumanEval+ / MBPP+ / LiveCodeBench / BigCodeBench 这些代码任务上,平均比代码训的 PRM 还高 4 个点——也就是说"PRM 学到的东西"比我们想象的更通用,这对"是不是要为每个域单独做一个 PRM"这种工程决策是个有力的反例。
定位:不是新方法,是一篇把 PRM 几个长期争议问题——规模收益、数据多样性、跨域泛化、搜索策略——一次性测清楚的实证 study。读完不会让你拍桌子叫绝,但下次设计 PRM pipeline 时,几个具体决策可以直接照着做。
论文信息
| 项目 | 内容 |
|---|---|
| 标题 | From Mathematical Reasoning to Code: Generalization of Process Reward Models in Test-Time Scaling |
| 作者 | Zhengyu Chen, Yudong Wang, Teng Xiao, Ruochen Zhou, Xuesheng Yang, Wei Wang, Zhifang Sui, Jingang Wang |
| 机构 | 美团、北京大学、宾夕法尼亚州立大学 |
| 发表 | AAAI 2026 |
| arXiv | https://arxiv.org/abs/2506.00027v1 |
| 资助 | NSFC 62476009 |
🎯 一个工程团队真正纠结的问题
我之前在做推理增强系统时,关于 PRM 的几个决策卡过很久:
第一个:PRM 该多大? 用 0.5B 训不动,用 32B 训不起,7B 是不是甜蜜点?没人敢拍胸脯,大家都凭"差不多够用"的直觉。
第二个:训练数据要不要专门为目标域准备? 我们要做代码补全的 PRM,就必须用代码 trajectory 训吗?还是说先用大量 math 数据起步,再加点 code 微调?
第三个:测试时搜索用哪个? Best-of-N 简单粗暴,MCTS 复杂但据说强,Beam Search 是个折中。在线服务有延迟约束,这个决策非常关键。
第四个:训练步数多少够? PRM 训练曲线通常长得很怪——前几千步几乎不动,然后突然涨一波——什么时候停?
这篇论文的价值就在于,把上面四个问题用对照实验全测了一遍。不是给一个石破天惊的新方法,而是把决策依据落到具体数字上。说实话,这种活儿写出来不性感,但工程上的含金量比某些"提了 0.3 个点"的新算法更高。
📖 PRM 的训练 Recipe:ASLAF(自动步骤级标注与过滤)
论文先给了一个做 PRM 训练数据的完整 pipeline——叫 ASLAF(Automatic Step-Level Annotation and Filtering):
- 采集多任务多难度的推理任务,每题分解为中间步骤序列;
- LLM 多解 rollout,用蒙特卡洛估计 + 二分查找定位错误的步骤;
- 多模型集成过滤:用不同 LLM 交叉验证步骤正确性,只有所有 LLM 都同意是错的,才标错;意见不一致的样本直接丢掉。
第三步的"严格交集过滤"是关键。LLM-as-judge 的常见问题就是单模型偏差——一个 LLM 觉得对、另一个觉得错时,标签噪声就上来了。ASLAF 的做法就是宁可丢数据也要保标签纯度。最后得到一个 1.2M 规模的过滤集(PRM800K + Math-Shepherd 合成),实验里抽 400K 用。
PRM 的架构没玩花活:从 Qwen2.5 系列初始化,把语言建模头换成两层线性的 scalar-value 头,每个 step 输出一个 [0,1] 的概率:
二元交叉熵,没什么悬念。
🏗️ 实验一:PRM 规模到底要多大?(收益递减)
测了 Qwen2.5 七档:0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B。同一份生成模型 rollout 的样本,让不同规模的 PRM 来评分选 Best-of-N。
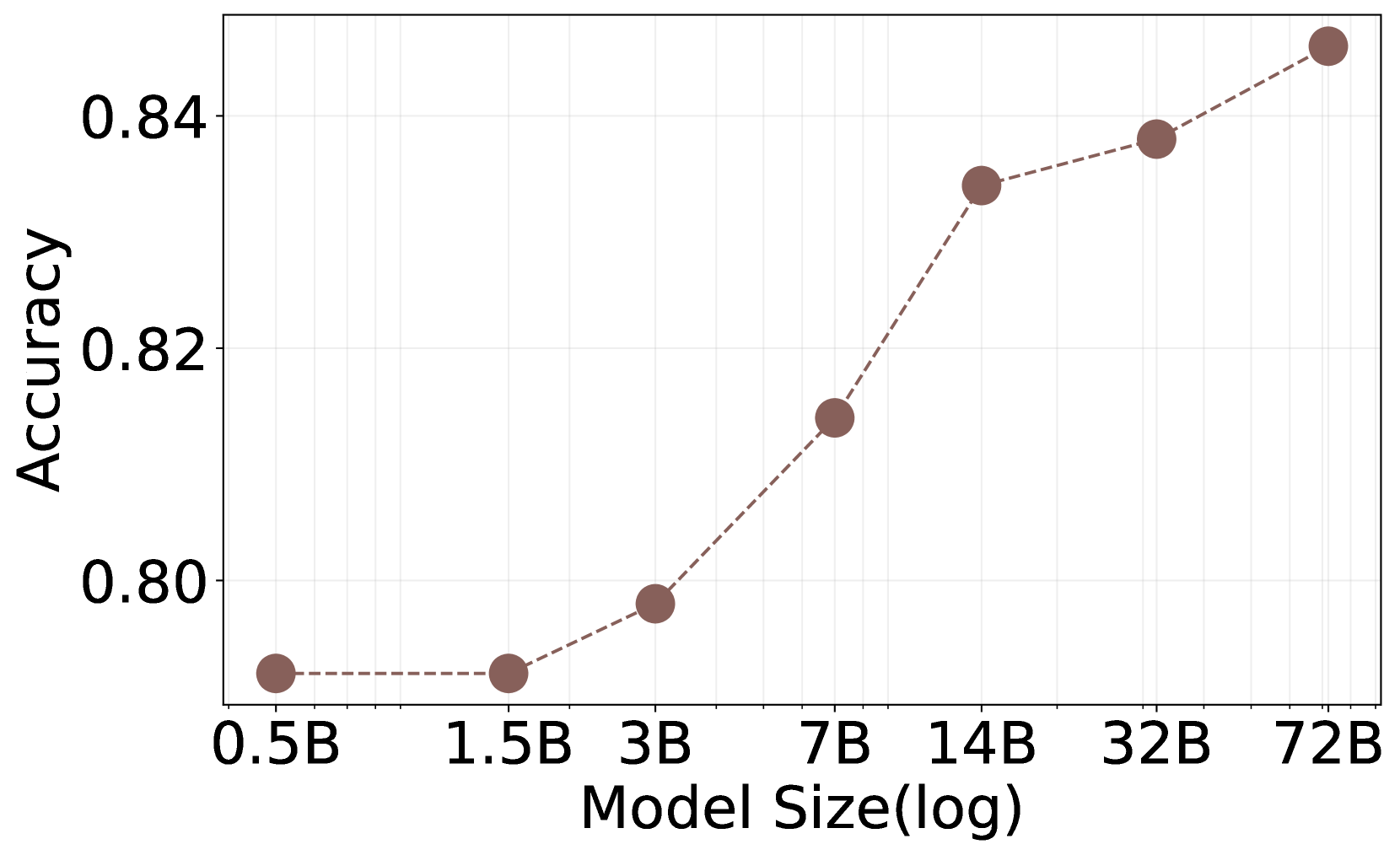
图1:论文 Figure 1。横轴是 PRM 模型规模(log scale),纵轴是评估准确率。0.5B 和 1.5B 几乎一样卡在 0.79;3B 后开始爬,到 14B(0.834)大幅跃升,之后 32B(0.838)和 72B(0.846)涨幅极小——典型的 diminishing returns。
我看到这张图的第一反应是:14B 是个明显的甜蜜点。从 14B 到 72B,规模翻了 5 倍,准确率只涨了 1.2 个点——这种 ROI 在工程上是劝退的。如果你做线上服务,PRM 是和主模型并跑的"额外开销",14B 比 72B 省一个数量级的显存,准确率几乎不亏。
但有件事论文没明说:这条曲线只在 PRM800K 一个数据集上做的。这个 benchmark 本身的天花板可能就在 0.85 附近,曲线最后压缩可能是 benchmark 饱和而不是真正的 PRM 能力饱和。MATH-500 那条曲线(图未单独展示)有类似但更平的 plateau,所以"14B 够用"这个结论我会保留:对中等难度题目大概率成立,对极难推理任务(比如 AIME 这种)可能要更大模型才能脱离 plateau。
🏗️ 实验二:训练步数和涌现现象
PRM 训练曲线有个很怪的现象——训练初期几千步几乎不动,然后突然跳一档:
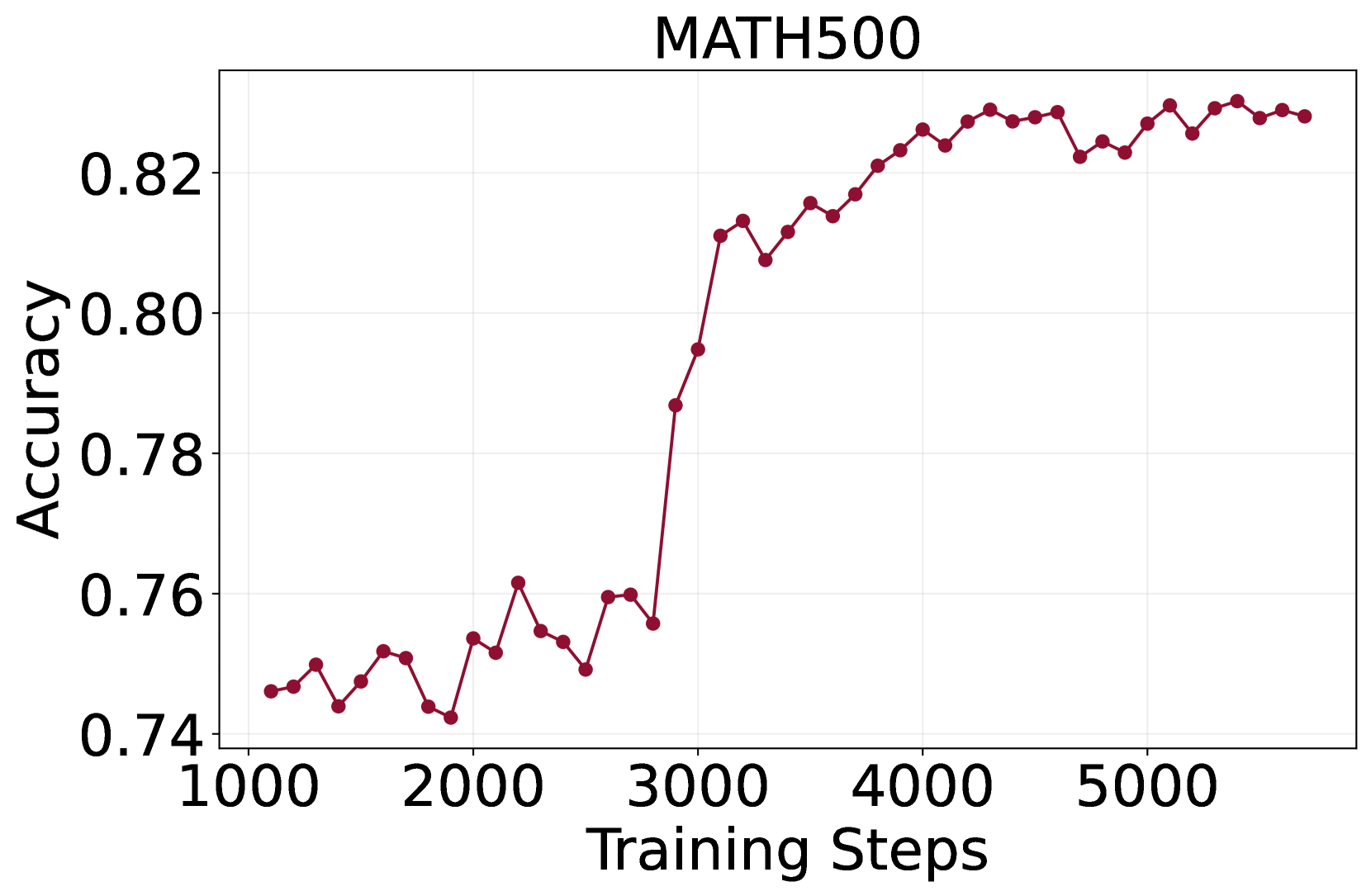
图2:论文 Figure 2 的 MATH-500 子图。横轴是训练步数(1000–5500),纵轴是准确率。前 2700 步左右一直在 0.74–0.76 抖动,2800 步突然跳到 0.81,之后逐步上升到 0.83 并平稳。这种"先平台后跃迁"的形态在 PRM800K 子图上更明显——从 0.81 直接跳到 0.86。
这个 emergence 现象其实在 LLM 训练里不算新鲜,但在 PRM 这种"判别任务"上看到是有点意外的。我的猜测是:PRM 学习的不是"步骤是否符合表面格式"(这种浅层信号几百步就学会了),而是"步骤在整个推理链里的因果作用"——这种深层结构需要积累足够多的对比样本才能浮现。
工程启发是:别在前 2000 步就因为曲线不动而 early stop。论文里所有实验都是 5000+ 步的训练量,这个数比一般 RM 训练要长。
🏗️ 实验三:训练数据多样性的影响
把 ASLAF 和单源数据集(PRM800K、Math-Shepherd)做横评,控制总训练样本数都是 400K:
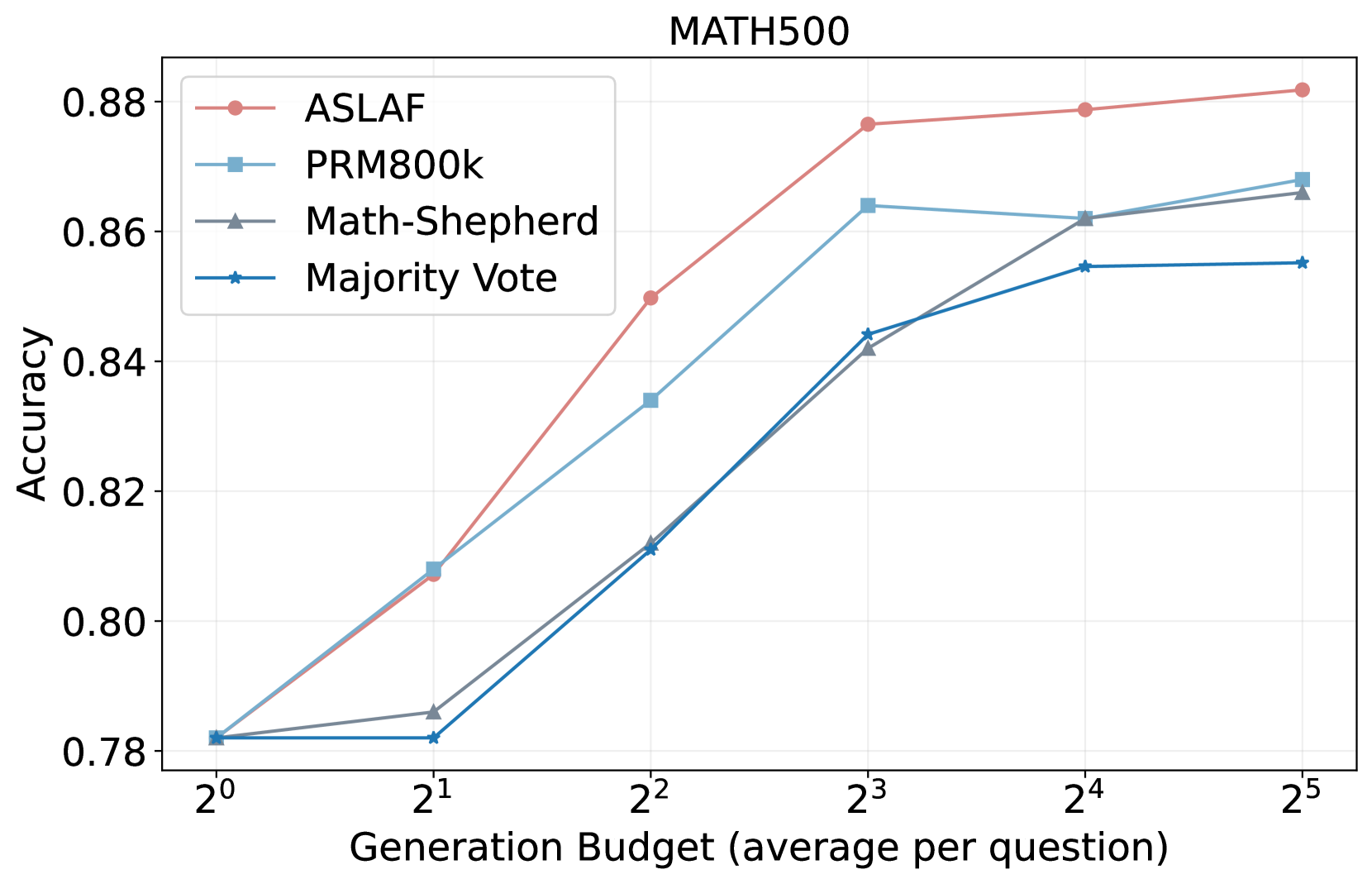
图3:论文 Figure 3 的 MATH-500 子图。横轴是生成预算(每题候选数 2^k),纵轴是 Best-of-N 选出的最优解准确率。四条曲线:ASLAF(红,论文方法)> PRM800K(浅蓝)> Math-Shepherd(灰)> Majority Vote(深蓝)。在 N=8 时 ASLAF 已达 0.876,PRM800K 还在 0.864;到 N=32 时 ASLAF 维持 0.882,但 PRM800K 涨到 0.867 仍有 1.5 个点的差距。
数据多样性这个结论,PRM 圈里早就传,但缺硬实验——这篇论文把它落在数字上:同样 400K 样本,多源混合 + 严格过滤的数据集(ASLAF),在不同生成预算下都比单源数据集稳定高 1–2 个点。Majority Vote 作为 baseline 全程垫底,再次说明"靠多数票"在数学推理上不靠谱(容易被多个错答的同形式答案带偏)。
🏗️ 实验四:测试时搜索策略对比(MCTS vs BoN vs Beam vs Majority)
这是这篇论文最实用的一节。同一个 PRM(ASLAF 训练),换四种搜索策略,看哪个 ROI 最高。
按生成预算(计算量)排序
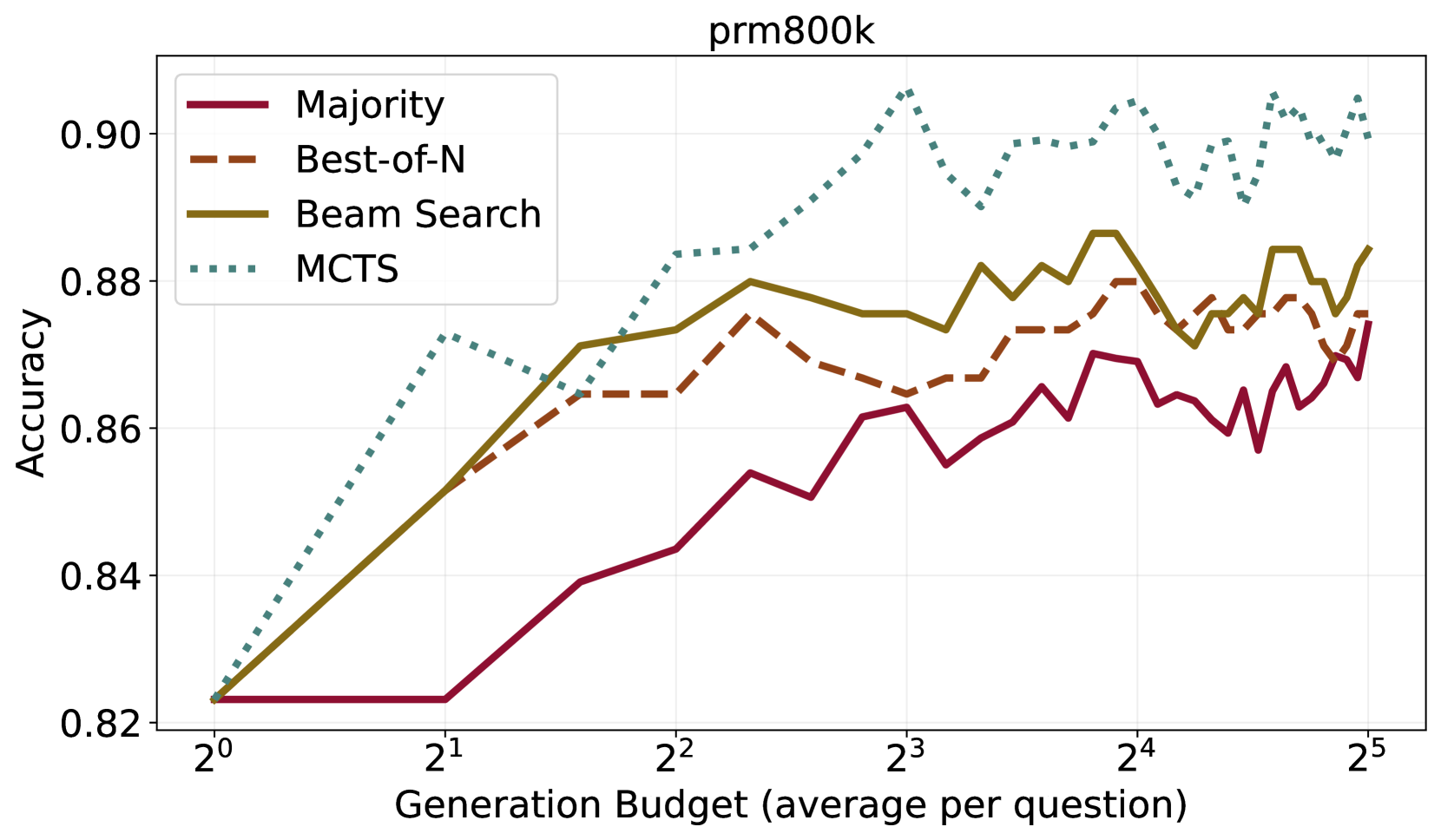
图4:论文 Figure 4 的 PRM800K 子图。横轴是生成预算(2^0 到 2^5),纵轴是准确率。MCTS(绿色虚线)几乎全程领先——在 2^3 预算时已达 0.90,而 Best-of-N(橙虚线)和 Beam Search(黄实线)卡在 0.875 附近,Majority Voting(红实线)最差,0.86 出头。
按测试时间(墙上时钟)排序
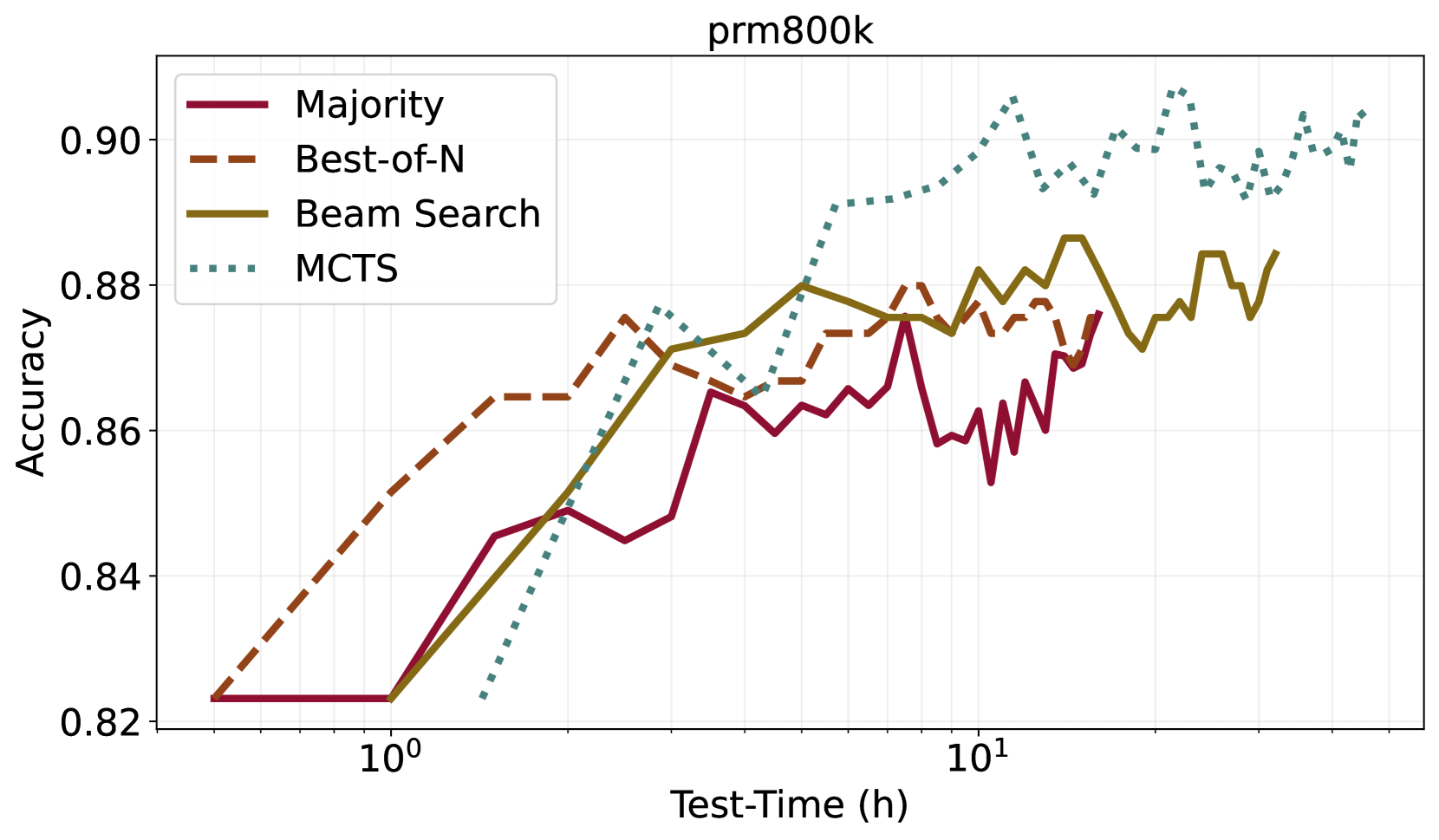
图5:论文 Figure 5 的 PRM800K 子图。横轴是测试时间(小时,log scale),纵轴是准确率。这张图反转了 Figure 4 的故事:测试时间 \lt 2 小时的窗口里,Best-of-N(橙虚线)领先,因为 MCTS 的搜索开销在小预算下被放大;测试时间超过 5 小时后 MCTS 反超并稳稳压制其他方法到 0.90。
把这两张图放一起读才有完整结论:
- 预算充足、可以离线慢慢搜:直接上 MCTS,能榨出最后那 2–3 个点;
- 在线服务、有延迟硬约束:Best-of-N 才是务实选择,简单、并行、低延迟;
- Majority Vote 任何时候都不该选——它在两张图上都是垫底。
我的工程经验里,BoN 在 N=8–16 区间是最常见的部署配置(成本可控、提升明显),这篇论文的数据正好支持这个直觉。
🏗️ 实验五:跨域泛化——这才是文章的真正卖点
前面四块实验都很扎实,但都属于"PRM 内部参数调优"。真正反直觉的是这一节:用纯数学数据训的 PRM(PRM-Math),搬到代码任务上跑 Best-of-N,居然平均比专门用代码数据训的 PRM-Code 还要好。
主表(生成模型 = Qwen2.5-Coder-7B-Instruct)
| Reward Model | N | HumanEval+ | MBPP+ | LiveCodeBench | BigCodeBench |
|---|---|---|---|---|---|
| 无(pass@1) | 1 | 81.1 | 72.2 | 14.2 | 49.0 |
| Majority Vote | 8 | 81.5 | 73.7 | 15.6 | 50.7 |
| PRM-Math | 8 | 86.0 | 77.3 | 22.6 | 54.2 |
| PRM-Code | 8 | 84.2 | 78.6 | 18.7 | 52.3 |
LiveCodeBench 上 PRM-Math 比 PRM-Code 高 3.9 个点——这是真的反直觉。
主表(生成模型 = Qwen2.5-Coder-32B-Instruct)
| Reward Model | N | HumanEval+ | MBPP+ | LiveCodeBench | BigCodeBench |
|---|---|---|---|---|---|
| 无 | 1 | 82.9 | 77.0 | 25.8 | 57.5 |
| Majority Vote | 8 | 85.8 | 77.6 | 28.2 | 59.4 |
| PRM-Math | 8 | 91.5 | 78.8 | 30.3 | 60.1 |
| PRM-Code | 8 | 89.0 | 78.4 | 29.7 | 60.1 |
更大的生成模型上 PRM-Math 依然全面领先或打平——结论稳定。
主表(生成模型 = QwQ-32B-Preview)
| Reward Model | N | HumanEval+ | MBPP+ | LiveCodeBench | BigCodeBench |
|---|---|---|---|---|---|
| Majority Vote | 4 | 86.8 | 76.0 | 40.1 | 54.6 |
| PRM-Math | 4 | 89.6 | 76.2 | 41.9 | 54.2 |
| PRM-Code | 4 | 86.0 | 79.6 | 41.9 | 53.1 |
QwQ-32B 的推理本身已经很强,PRM-Math 在 HumanEval+ 上仍能多榨 2.8 个点。MBPP+ 上 PRM-Code 占优,这是唯一一个 PRM-Code 略胜的任务。
为什么会这样? 论文给了一个梯度相似度分析(Table 2):用梯度激活法测"PRM 选出来的代码 response"和"PRM 选出来的数学 response"在底层模式上的相似度——结果 MathPRM 选出的 response 和 CodePRM 选出的 response 相似度高达 30.95,明显高于"未经 PRM 选择"的原始数学/代码 response 之间的相似度(26.75)。
| 集合 1 | 集合 2 | 相似度 |
|---|---|---|
| MathPRM 筛选的数学回答 | CodePRM 筛选的代码回答 | 30.95 |
| MathPRM 筛选的数学回答 | 原始代码回答 | 29.07 |
| 原始数学回答 | CodePRM 筛选的代码回答 | 29.42 |
| 原始数学回答 | 原始代码回答 | 26.75 |
翻译一下这个表:PRM 不管是数学训的还是代码训的,都倾向于选"含反思 / 步骤分解 / 多 candidate 验证"这种结构化模式的回答——而这种结构化模式在代码任务里恰好对应"先写思路再写代码、出错时反思修正"这类高质量解。所以数学 PRM 学到的不是"数学知识",而是"什么是好的推理过程"——这种元能力才是它能跨域的根本原因。
论文的 Case Study(Figure 6)也支持这点:在一个字符串加密题里,模型第一次用 s.index(char) 写错(无法处理重复字符),PRM 给 0.5371;模型反思后改成 s[(i + k) % length],PRM 给 0.8750——带反思的修正版被显著加分。这种 reflection-aware 的偏好就是 PRM 跨域可迁移的核心。
🤔 批判性笔记
第一,"4% 提升"被论文 abstract 里说成"comparable to code-trained PRMs"是在自谦,但同时也有点回避 LiveCodeBench 上 +3.9 这种明显胜场的解释力。 如果作者敢更主动地说"数学 PRM 反而更通用",会比"差不多"更有冲击力。我猜是为了不挑战"per-domain RM"这种主流叙事。
第二,跨域只测了 math → code,没测 math → 其他任务。 比如 math 训的 PRM 在 commonsense reasoning(CSQA、ARC)上能不能照样涨?没数据。论文的"general reasoning patterns"假设需要更多任务来验证。
第三,ASLAF 数据集还没开源(截至撰文时)。 论文核心方法之一是这个数据 pipeline,没有开源会让复现难度大幅上升——如果后续放出来,这篇文章的工程价值会再上一档。
第四,14B PRM 是不是"普适甜蜜点"? 这个结论在 PRM800K 一个 benchmark 上得出,应该再加几个不同难度的 benchmark(AIME、Putnam)才能确定 plateau 是真的还是测出来的。
第五,MCTS 在文章里赢了所有指标,但 MCTS 的实现细节(UCT 参数、rollout 深度、终止策略)几乎没提。 这些参数对 MCTS 性能影响巨大——如果作者用的是被精调的 MCTS 而 baseline 没被精调,这个对比会有偏。
💡 工程上的几个直接 takeaway
- PRM 选 14B 起步,再大没必要(除非做 AIME 级别难题);
- 训练别在 plateau 阶段就停,至少 5000 步起,等 emergence 现象出现;
- 数据用多源混合 + 严格交集过滤(ASLAF 思路),别迷信单源大数据集;
- 测试搜索:在线 BoN,离线 MCTS,Majority Vote 永远别用;
- 如果你只能训一个 PRM,优先用数学数据——它在代码任务上反而比专门训的代码 PRM 更好。
第 5 点是最反直觉的,但也是这篇论文最让人意外的工程启发。如果你团队在为"我要不要为 X 域专门训一个 PRM"纠结,先用数学 PRM 跑一下基线,可能比你想象的好。
🔬 还没解决的问题
为什么数学 PRM 在 MBPP+ 上反而被代码 PRM 超过(86.0 → 78.6 vs 84.2 → 79.6)? 论文没解释。我的猜想是 MBPP+ 题目偏短、推理链短,反思类模式不容易展现出来——这种"短任务"上 PRM 选哪个差别不大,反而代码 PRM 学到的"语法模式"更直接有用。但这是猜测,需要更细的 case 分析。
梯度相似度 30.95 vs 26.75 这个差距是不是显著? 论文没给统计显著性。直观看 4 个百分点差距不算大,但跨域研究里这种间接证据本来就难。理想情况下应该补一个 random baseline(随机选 response)的相似度,看 PRM 选择带来的"模式聚类"是否真的显著。
📚 收尾
这篇论文我会归类成PRM 工程化的实证基线——它不会让你今晚睡不着想用上某个新算法,但会让你下次设计 PRM pipeline 时少踩坑。"数学训的 PRM 跨代码任务更通用"这个发现如果未来被更多任务验证,对工业界 per-domain RM 的默认做法是个挑战——可能我们一直在用错的方式做 PRM 工程。
对做过 RLHF/PRM 训练的人,强烈推荐花 30 分钟读一遍 Section 4 和 5。
参考链接
- arXiv:https://arxiv.org/abs/2506.00027v1
- 相关基础工作:PRM800K (Lightman et al.)、Math-Shepherd (Wang et al.)
- 测试时 scaling 综述:DeepMind Test-Time Compute (Snell et al., 2024)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我