PPPO 论文解读:前缀决定推理,RLVR 只优化开头就够了
一句话先讲清楚
论文标题: Well Begun, Half Done: Reinforcement Learning with Prefix Optimization for LLM Reasoning
arXiv 编号: 2512.15274,AAAI 2026
作者团队: Yiliu Sun、Zicheng Zhao、Yang Wei、Yanfang Zhang、Chen Gong
一句话总结: 这篇论文从人类思维里"路径依赖"的现象出发,发现 LLM 推理也存在类似的"开端锁定效应"(Beginning Lock-in Effect, BLE)——前 15% 的 token 几乎决定了答案对不对。基于这个发现,作者提出 PPPO:只把 RL 梯度回传给前缀 token,并通过"渐进式前缀比例"和"多续写累积奖励"两个改造把它做成可训练的范式。结果是:在 Qwen3-1.7B/4B/8B 上跑 AIME'24/AIME'25/MATH 500/AMC'23/GPQA Diamond 五个 benchmark,相对 GRPO 平均涨 18 个点,而训练 token 只用了 26.17 个百分点。
读完之后我的第一反应是:这个发现非常符合直觉,但敢真的"只在前缀上回传梯度"是需要一些勇气的。RLVR 范式自 GRPO 起就默认对全 token 一视同仁地算 advantage,PPPO 直接砍掉 65% 以上的梯度回传位置——这是对"梯度均衡"信仰的一次直接挑战。
1. 为什么我会专门挑这篇论文出来读
最近读了一连串 RLVR/PRM/对齐的论文:DeepSeek-R1 的 GRPO、字节的 DAPO、清华的 INTUITOR,还有上一篇刚解读的 DEPO(双效率偏好优化)。这条线最近的关键词都是效率——怎么用更少的 token、更少的 sample、更少的算力达到同样甚至更好的效果。
PPPO 是这条线里立场最激进的一个:别人在做采样效率或奖励效率,它做的是梯度位置效率。
我之所以对这种"砍掉大部分梯度位置"的思路有兴趣,是因为之前在调 PPO/GRPO 的时候有过类似的直觉——很多答案的"翻车"是发生在前几十个 token 里的,比如理解题意理解错、单位换算时贸然写了"先取整再除",后面再怎么算也救不回来。但当时没有量化到"前 15%"这么具体,更没把它做成训练目标。PPPO 把这个直觉量化、做成消融、跑了完整实验,并且数字相当好看。
另一个让我决定深读的点:它不是单独的一招。Progressive Prefix Retention(前缀比例从短到长)+ Continuation Accumulated Reward(多续写累积奖励),这两招组合起来是有逻辑闭环的——前缀短意味着噪声大、reward 估计不稳,所以必须用"多续写累积"来稳住信号。这种"两招互补"的设计往往说明作者真的把训练跑通过、不是从概念上拍脑袋。
2. 核心现象:什么是 Beginning Lock-in Effect
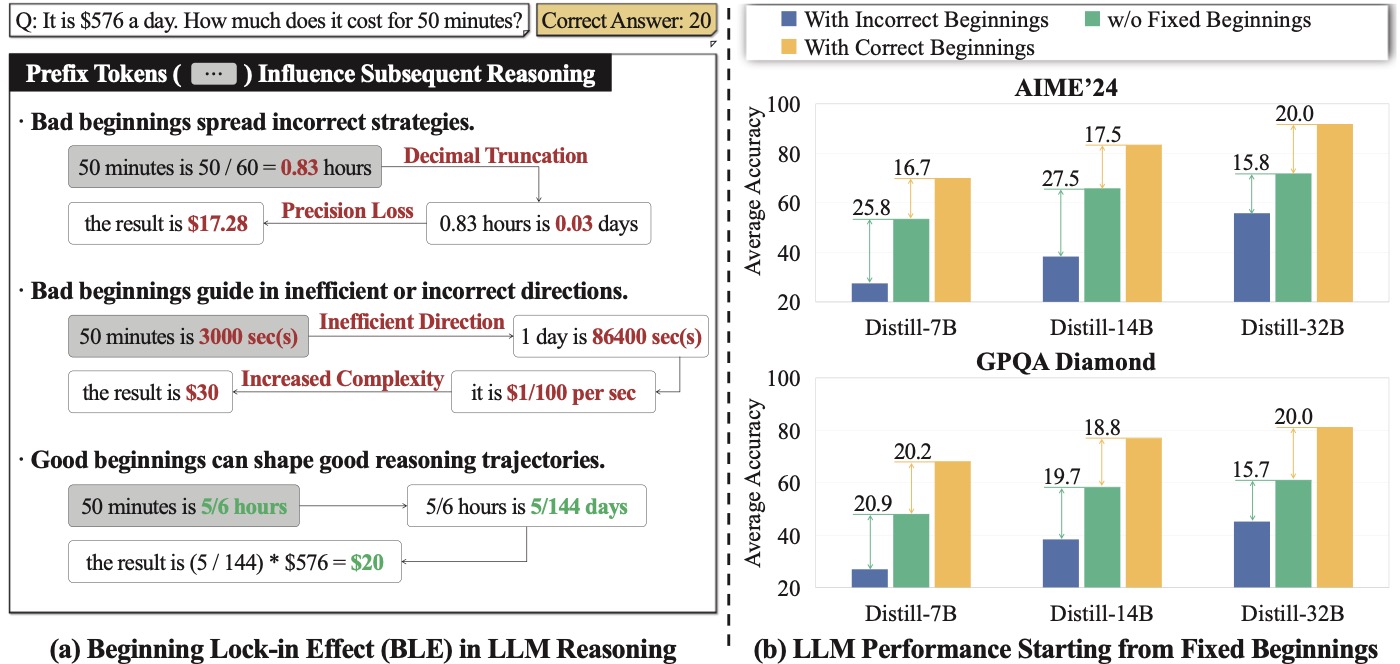
作者的实验设计很干净,我觉得值得详细复述一下:
- 在 AIME'24 和 GPQA Diamond 两个推理 benchmark 上,每道题用 DeepSeek-R1-Distill-Qwen 系列(7B/14B/32B)各采 4 个正确答案 + 4 个错误答案。
- 把每个答案的前 15 个百分点 token 抠出来当作"前缀"。
- 让原模型从这个前缀续写 8 次,记录 average accuracy。
结果:
- 用"正确答案的前缀"启动,准确率最多上升 20.2 个点;
- 用"错误答案的前缀"启动,准确率最多下降 27.5 个点(DeepSeek-R1-Distill-Qwen-14B 在 AIME'24)。
这个 27.5 点的下降幅度非常震撼——前 15% 的 token 没被自己写出来,而是被一个"坏开头"塞过来,整个 14B 模型就崩了 1/4 以上的能力。这不是"prompt 影响输出分布"那种弱效应,开头一锁,后面跑不掉才是真正的强效应。
更狠的是后续验证:作者在坏前缀后面加 "wait" 或 "however" 这类反思触发词(这是 s1 那篇论文 muennighoff2025s1simpletesttimescaling 用过的招数),按理说应该能让模型"回头看一下"。结果发现,准确率最多只能恢复 9.2 个点——恢复幅度远不及"被坏前缀拉下去"的 27.5 点。
我觉得这个对比实验是整篇论文最有说服力的证据。它不是说"前缀重要"那种空话,而是说"前缀坏了你救不回来"。这个 asymmetry(损害容易、修复困难)才是 BLE 这个名字里 Lock-in 的真正含义。
把它和上一篇 LLMdoctor 的 Δ_t = log p_+ - log p_- 联系起来看会很有意思:LLMdoctor 是在每个 token 上都看正负 face prompt 的差,PPPO 则是直接说"只有前缀的差才真正决定结果"。两个工作其实指向同一个现象——token-level 的 reward signal 是高度非均匀的——只是 LLMdoctor 用 reward shaping 来表达这种非均匀,PPPO 用 gradient masking 来表达。
3. 方法:PPPO 怎么把这个发现做成训练范式
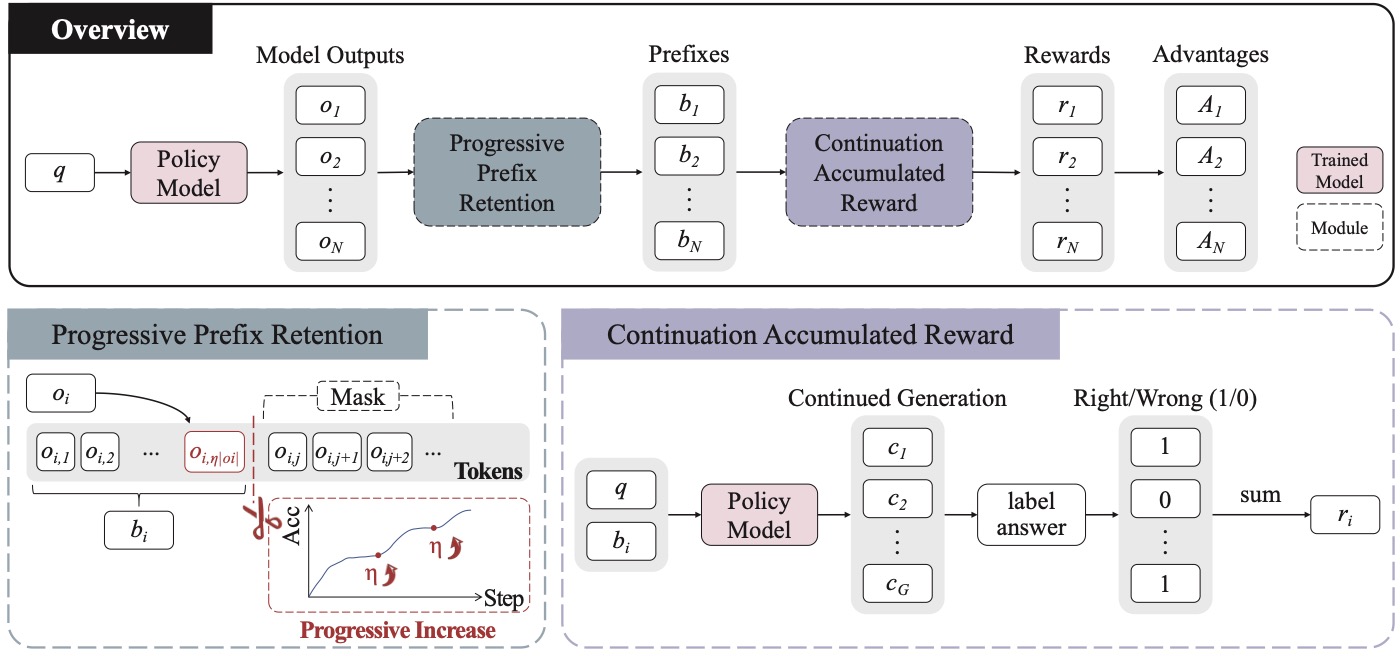
3.1 整体框架是 GRPO 的改造版
PPPO 的目标函数继承自 GRPO 的形式:
关键改造是 \(\mathrm{H}(j, \mathbf{o}_i)\) 这一项 indicator function:
通俗讲就是:只有 token 位置 \(j\) 在前 \(\eta \times |\mathbf{o}_i|\) 范围内,梯度才会回传。 后面的 token 还是会被采样、还是会被计入 reward,但不在梯度更新的目标里。
这一点我读到的时候停了一下:它不是把后面的 token mask 掉不算 reward,而是 reward 算(因为 reward 是基于完整答案的对错),只是不让后面的 token 通过反传去调整 policy。这相当于对 GRPO 做了一次"只优化 H 区"的限制。
3.2 第一招:Progressive Prefix Retention
直接把 \(\eta\) 设成一个固定的小值(比如 15%)会有问题——前 15% 太短,模型很快就"学会怎么开头",但学不到 "开头之后衔接到主体" 的能力。直接设成大值(比如 50%)又退化回普通 GRPO,丢掉 BLE 的红利。
作者的策略是:\(\eta\) 从 15% 起步,按 5% 的步长往上加,加到 35% 停止。具体什么时候加?看验证集准确率有没有继续上升:
15% 是 BLE 的"起点"(前文实验里前 15% token 是关键),35% 是"BLE 基本稳定下来"的位置(performance 转折在 35% 附近)。这个 schedule 是数据驱动的,不是拍脑袋。
在 ML 设计层面这是个很经典的 curriculum learning 思路——先学简单子问题(短前缀),再扩展到复杂任务(长前缀)。但具体到 LLM RL 里把它做成"训练步数 + 验证集触发"的自适应版本,确实是个新组合。
3.3 第二招:Continuation Accumulated Reward
这一招是"前缀短了之后必须配的解药"。前缀只有 15% 太短,单次采样的奖励信号噪声非常大——同样一个前缀 \(\mathbf{b}_i\),续写一次可能对,续写一次可能错。
作者的处理是:对每个前缀 \(\mathbf{b}_i\) 采 \(G\) 个独立续写 \(\{\mathbf{c}_j\}_{j=1}^G\),把每个续写的 reward 累加起来作为这个前缀的 reward:
注意累加而非平均,这点在 GRPO 的 advantage 归一化里其实没区别(因为后面 \(\mathrm{mean}\)/\(\mathrm{std}\) 会做 normalization),但在 reward magnitude 上会更显眼,更不容易被 clip 截断。
实验里 \(G = 8\)。这意味着每个 training step 的总采样量是 \(N \times G = 8 \times 8 = 64\) 个 sequence,与基线 GRPO/DAPO(每 step 64 个 sample)完全相同——所以"算力公平比较"是站得住脚的。
读到这里我突然反应过来:PPPO 不是省采样,是把一个 question 采 64 个 sample 重新分配成 8 个前缀 × 每个前缀 8 个续写。这种 sample 预算的重分配实际上是一个双层 sampling 的思路(hierarchical sampling)——把 reward 评估的方差从单层采样转移到 prefix 评估上来。
3.4 一个我没在论文里看到但值得问的问题
前缀的 advantage 是怎么算的? 论文给的 advantage 公式是标准 GRPO:
也就是说,每个前缀 \(\mathbf{b}_i\) 的所有 token 共享同一个 advantage(来自 8 个续写的累积 reward 与 batch 内其他前缀的对比)。这是 token-level 的 GRPO 在做 prefix-level credit assignment:前缀好坏靠续写来"事后追溯"。这是个干净的设计,但也意味着前缀内部的 token 之间无法相互区分——前缀的第 5 token 和第 50 token 拿到一样的 advantage。如果未来有人想做 PPPO 的精细化版本,这里大概率是个突破口(比如配合 DEPO 那种 step-level 偏好)。
4. 实验:数字到底有多漂亮
4.1 主表(5 benchmark × 3 backbone × 5 baseline)
主表是这篇论文最有冲击力的部分。我把它整理成更清楚的形式:
Qwen3-1.7B:
| 方法 | AIME'24 | AIME'25 | MATH 500 | AMC'23 | GPQA Diamond | 平均 |
|---|---|---|---|---|---|---|
| Backbone | 25.83 | 18.33 | 76.05 | 56.93 | 28.16 | 41.06 |
| + GRPO | 27.50 | 20.00 | 82.10 | 60.24 | 29.80 | 43.93 |
| + DAPO | 30.83 | 23.33 | 83.60 | 63.03 | 31.82 | 46.52 |
| + INTUITOR | 27.29 | 17.71 | 78.13 | 60.99 | 29.96 | 42.82 |
| + DAPO-FT | 31.25 | 23.96 | 83.93 | 62.80 | 31.44 | 46.68 |
| PPPO | 38.65 | 28.96 | 87.80 | 62.89 | 39.52 | 51.58 |
Qwen3-4B:
| 方法 | AIME'24 | AIME'25 | MATH 500 | AMC'23 | GPQA Diamond | 平均 |
|---|---|---|---|---|---|---|
| Backbone | 48.75 | 35.42 | 84.46 | 72.67 | 43.59 | 56.98 |
| + GRPO | 52.08 | 37.71 | 88.40 | 76.77 | 46.78 | 60.35 |
| + DAPO | 56.46 | 42.08 | 92.33 | 81.63 | 49.37 | 64.37 |
| + INTUITOR | 51.04 | 35.42 | 88.26 | 75.83 | 46.43 | 59.40 |
| + DAPO-FT | 56.25 | 42.08 | 92.38 | 82.00 | 49.21 | 64.38 |
| PPPO | 63.54 | 53.44 | 94.60 | 83.06 | 52.07 | 69.34 |
Qwen3-8B:
| 方法 | AIME'24 | AIME'25 | MATH 500 | AMC'23 | GPQA Diamond | 平均 |
|---|---|---|---|---|---|---|
| Backbone | 52.29 | 38.75 | 86.06 | 75.08 | 46.12 | 59.66 |
| + GRPO | 58.75 | 42.29 | 91.00 | 79.44 | 50.51 | 64.40 |
| + DAPO | 63.13 | 48.75 | 93.21 | 83.96 | 55.18 | 68.85 |
| + INTUITOR | 55.42 | 40.83 | 91.20 | 78.24 | 49.31 | 63.00 |
| + DAPO-FT | 63.75 | 49.38 | 93.65 | 84.11 | 54.77 | 69.13 |
| PPPO | 72.19 | 59.69 | 94.73 | 86.75 | 58.13 | 74.30 |
我看这张表的几个观察:
- PPPO 在 14/15 个 (model, benchmark) 组合里都是 SOTA——只有 Qwen3-1.7B 上的 AMC'23 略输给 DAPO(62.89 vs 63.03)。这个稳定性在 RL 论文里相当少见。
- AIME'25 上的提升幅度最猛。Qwen3-4B 上从 GRPO 的 37.71 涨到 PPPO 的 53.44,绝对提升 15.7 个点;Qwen3-8B 上从 42.29 涨到 59.69,17.4 个点。AIME'25 是难度最高的奥数题,BLE 在难任务上的 leverage 更大——这符合"开头错了就再也救不回来"的直觉,因为难题往往一步错就步步错。
- GPQA Diamond 上的提升也很大。Qwen3-1.7B 上从 GRPO 的 29.80 → PPPO 的 39.52,提升 9.7 个点。GPQA 是研究生级 STEM 推理,不是纯数学。这说明 BLE 不仅在数学题里有,在物理化学生物推理里同样存在。
- DAPO-FT 的 Forking Tokens 对比最值得看。DAPO-FT 是给关键 forking token 加权重的方法,思路上和 PPPO 最接近——都意识到了 token 不该一视同仁。但 DAPO-FT 的提升相对 DAPO 只有零点几个点,PPPO 相对 DAPO 平均提升 5 个点以上。找出关键 token 加权不如直接砍掉无关 token 的梯度——一个是软调,一个是硬切。
4.2 训练 token 用量:26.17%
摘要里的"26.17% 训练 token"其实是这样算出来的:基线方法每个 token 都参与梯度,PPPO 只在前 \(\eta \times |\mathbf{o}_i|\) 个 token 上回传梯度,\(\eta\) 在训练过程中从 15% 升到 35%,加权平均下来约 26%。
但要注意:这里说的是"参与梯度回传的 token 占比",不是"训练总采样量"减少。PPPO 仍然要采 64 个 sample(8 prefix × 8 continuation),forward 和 reward 计算的开销和 GRPO 一样。真正省的是 backward pass——梯度只在前 26% 的位置上算。
对实际工程来说,这意味着:
- 显存可能省一些(因为 backward 时需要存的中间激活值少了 65%+)
- 每 step 的训练时间可能省一点,但不会省 65%(因为 forward 是大头)
- 真正的"红利"在收敛速度上——同样的训练步数,PPPO 学得更好
4.3 跨模型迁移:PPPO 训出来的前缀对小模型也好用
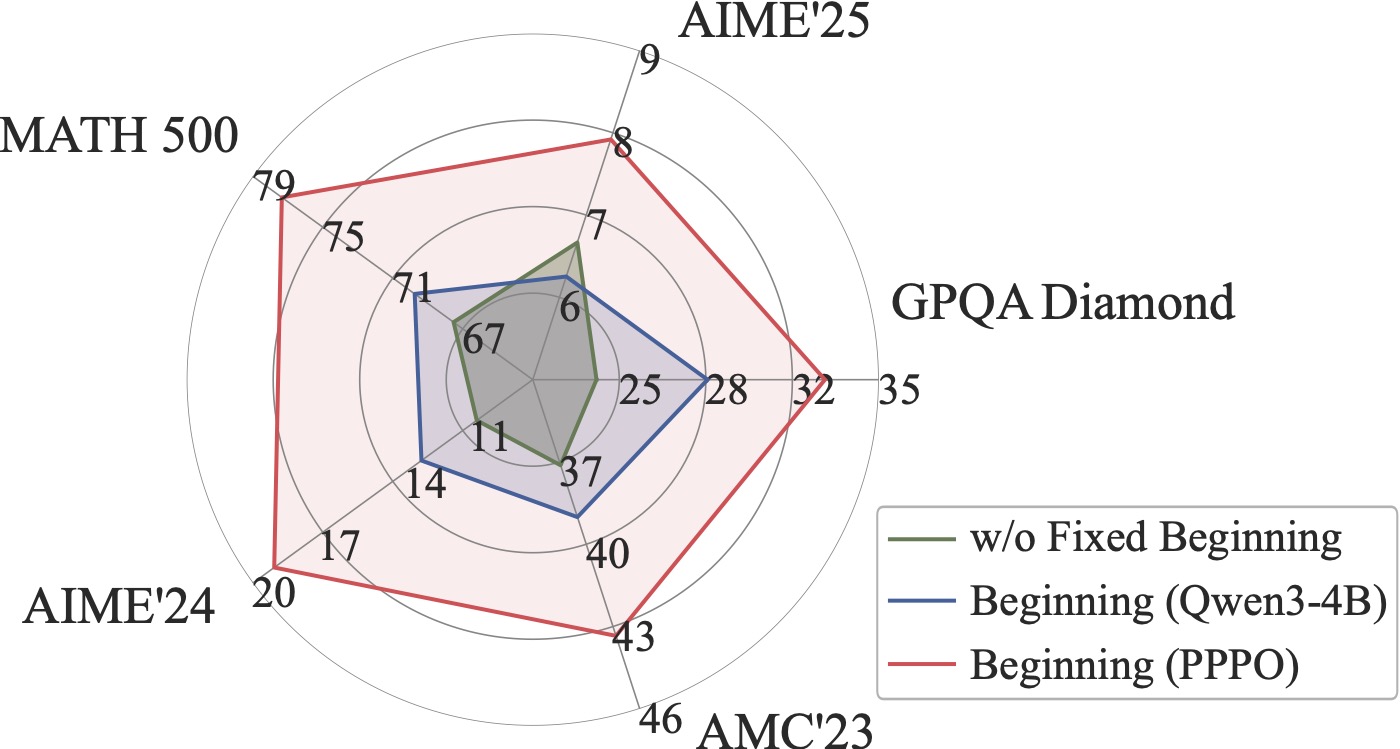
这张图我觉得是 BLE 假设最强的旁证:作者拿 Qwen3-4B 训出来的 PPPO 模型生成前缀,把这些前缀拿去给 Qwen2.5-7B-Instruct(一个完全不同代际的小模型)当启动,发现 Qwen2.5-7B 的准确率显著高于"用未训练的 Qwen3-4B 前缀启动"。
这说明 PPPO 学到的"高质量前缀模式" 不是模型自己的内部 representation 偏好,而是任务层面真实存在的"好开头"模板——所以才能跨模型迁移。这一点对实际使用很有意义:未来可以考虑把 PPPO 训练好的小模型当"前缀生成器",给大模型当 prompt 前缀,做一种新型的 inference-time alignment。
4.4 消融:Continuation 数量 G 与 Progressive 策略
| G | 采样策略 | avg@4 ↑ | var@4 ↓ |
|---|---|---|---|
| 1 | Single | 60.46 | 3.30 |
| 4 | Multiple | 66.11 | 1.47 |
| 8 | Multiple | 69.36 | 0.63 |
| 16 | Multiple | 69.53 | 0.56 |
这张表也很说明问题:
- 从 G=1 到 G=8,准确率涨 8.9 个点(60.46 → 69.36),方差降 5 倍(3.30 → 0.63)。
- 从 G=8 到 G=16 几乎没有继续提升(69.36 → 69.53)。G=8 是 sweet spot。
这种 saturation curve 本身也是有价值的——它告诉社区"做这件事到 G=8 就行了,再加 sample 是浪费"。对资源有限的团队是个非常实用的 guideline。
至于 Progressive 策略,作者跑了 5 个固定 \(\eta\) 的对照组(\(\eta = 15\%, 25\%, 35\%, 50\%, 100\%\)),Progressive 比固定 \(\eta=35\%\) 平均高 2.19 个点,且训练 token 数还少 8.83 个点。这说明 progressive 不是花架子——curriculum 真的有效。
5. 我的批判性思考
5.1 这篇论文的强项
- 现象发现清晰。BLE 的实验设计(正确前缀 vs 错误前缀对照组)干净利落,27.5 个点的下降幅度足够刺激。
- 方法到位。Progressive + Continuation Accumulated 两招互补,不是堆砌 trick。
- 实验全面。3 个 backbone × 5 benchmark × 5 baseline,14/15 SOTA,趋势单调。
- 数字漂亮但合理。AIME'25 +17 个点、GPQA +9 个点这种幅度,配合"前缀决定一切"的故事,整体可信度不错。
5.2 我有保留的地方
-
DAPO 已经做了很多 token-level 优化。PPPO 的 baseline 表里 DAPO 已经比 GRPO 高很多(Qwen3-4B 平均 +4 点),DAPO-FT 甚至已经在做 forking token 加权。PPPO 在 DAPO-FT 之上再涨 5 个点,但论文没有给出"PPPO + DAPO 的 dynamic clip"组合的实验——理论上两者是正交的,组合应该会更好,但作者没做。
-
训练 token 26.17% 的算法是值得 scrutiny 的。这个数字的分母是"baseline 方法的 token 总数"还是"完整答案的 token 总数"?如果是前者,那 baseline 的 max_response_length=10240 也包含了被截断的 token;如果是后者,那 26% 这个数字会被"答案平均长度"影响。这块论文叙述不够精确。
-
G=8 的开销其实不小。虽然总 sample 数和基线一样是 64,但每个 sample 的 reward 计算(验证答案对错)需要跑完整推理——baseline 是 64 次推理,PPPO 也是 64 次推理,但 PPPO 多了一层"前缀截断 + 重新采续写"的开销。如果 reward 是用一个外部 LLM judge 来打分(比如 GPT-4o),那 PPPO 的 inference cost 会比基线高一倍以上(因为前缀 + 续写都要 inference)。
-
BLE 假设的边界没说清。论文测的都是数学和 STEM 推理任务,这些任务的特点是"答对答错有明确二值结果"。在更软的任务(写作、对话、代码 review)上,BLE 是否还成立?没看到讨论。我个人猜测在长链式推理(数学、定理证明)上 BLE 会很强,在短链式或低链式任务上效应会减弱。
-
恢复幅度只有 9.2 个点这一结论建立在 wait/however 这种简单触发词上。如果换成更强的反思 prompt(比如显式给出"重新检查上面的推理是否合理"),恢复幅度可能会更大。BLE 的 lock-in 强度可能没作者描述得那么绝对。
5.3 这篇论文最大的启示
我读完之后写在笔记本上的一句话是:RLVR 的下一步是承认 token 不平等。
GRPO 从 PPO 简化而来,去掉了 critic,改用 group baseline;DAPO 在 GRPO 上加了 token-level dynamic clip;DAPO-FT 给 forking token 加权;PPPO 直接砍掉非前缀 token 的梯度。这条线越走越激进,但方向是一致的——承认每个 token 在 reward 里的贡献是高度非均匀的。
如果这个方向继续走下去,下一步可能是:
- token-level cluster 化:把 token 按"reward contribution"聚类,每类用不同的学习率
- dynamic prefix length:不用固定的 \(\eta\) schedule,而是用一个小 critic 实时预测"这道题的 BLE 在哪里截断"
- PRM × PPPO:把 PRM(process reward model)的 step-level reward 嫁接到 prefix 区间里,做更精细的 credit assignment
PRM 那条线我前两天刚解读过 GenPRM 和 PRM-Generalization 两篇,正好可以与 PPPO 形成正交。GenPRM 是给每个 step 打分,PPPO 是只优化前 35% step——把两者结合就是"在前 35% step 上用 PRM 打的细粒度分数做 advantage",理论上应该比纯 PPPO 更精细。这是我觉得未来一年很可能会出现的 follow-up。
6. 这篇论文怎么和最近读的几篇串起来
最近读的论文里有几条非常清晰的线索:
| 论文 | 核心改造的位置 | 关注的"非均匀性" |
|---|---|---|
| GRPO | 整段输出 | (无) |
| DAPO | clip threshold | clip 的非均匀 |
| DAPO-FT | forking token 加权 | token 重要性的非均匀 |
| PPPO | 前缀 token gradient mask | 位置(time)的非均匀 |
| LLMdoctor | token-level reward via face prompt | reward signal 的非均匀 |
| GenPRM | step-level process reward | reasoning step 的非均匀 |
| DEPO | step-level + trajectory-level KTO | 偏好类型的非均匀 |
把这张表横着看,会发现 2025 末到 2026 初的一个非常一致的趋势:所有人都在攻击 RLVR 里"all token created equal"这个隐含假设。每篇论文的切入点不同——位置(PPPO)、reward signal(LLMdoctor)、process step(GenPRM)、preference granularity(DEPO)——但目标都是一个:把不均匀性显式地建模进训练目标。
PPPO 在这条线里的位置是最直接、最暴力、也最便于实现的一个。它不需要训额外的 reward model(不像 LLMdoctor 需要 face prompt 计算 Δ_t、不像 GenPRM 需要 process reward judge)、不需要改 advantage 估计(依然用标准 GRPO normalization)、只需要在已有 RLVR 框架上加一行 indicator function。这种"低复杂度高 ROI"的改造正是大公司工程团队最喜欢的。
我个人猜:3 个月内会有人把 PPPO 套到 DeepSeek-R1 / Qwen3 / Llama 4 系列的官方训练 pipeline 里,并且会出现"PPPO + GenPRM 联合微调"这种工作。如果出现了,这篇论文会是这条线的奠基者。
7. 给想跟进这个方向的同行一些建议
如果你在做 RL / 后训练 / 推理增强相关方向,PPPO 给我的实用启示有:
-
在你的 pipeline 里加一行 prefix mask 试试。不需要重新训 reward model,不需要改 advantage 公式。直接在 GRPO loss 里乘一个 indicator,就能拿到 5+ 个点的提升(论文级数据)。这是边际改造里 ROI 最高的一种。
-
做对照实验时优先验证 BLE 假设。把训练好的模型生成的"正确答案前 15%"和"错误答案前 15%"抠出来,让原模型续写,看看准确率差。如果差很大(>10 个点),那 PPPO 在你的任务上大概率有用。如果差很小(<5 个点),那你的任务可能没有明显的 lock-in 效应,PPPO 红利会有限。
-
G(continuation 次数)从 8 起步。论文里 G=8 已经是 sweet spot,G=16 收益边际很小。资源有限的团队可以考虑 G=4 起步看看。
-
Progressive schedule 的 \(\eta\) 起点和终点要根据任务调。论文里 15% → 35% 是数学/STEM 任务的 sweet zone,对长链式推理任务可能要起点低(10%)、终点高(50%);对短任务可能反过来。
-
不要忽略训练 token 节省的工程价值。在大规模 post-training 里,26% 的 backward token 节省意味着可以用同样预算多训 4 倍 epoch,或者把模型规模翻倍。这个优势在小模型 finetuning 上不明显,但到 70B+ 规模会很显眼。
写在最后
PPPO 是那种我读完会心一笑的论文——它讲了一个"听起来很合理"的故事,但敢真的把它推到极限。"开头决定一切"是个老生常谈的直觉,作者的贡献不是发明这个直觉,而是用 27.5 个点的 BLE 实验把它量化、用 prefix gradient mask 把它落地、用 5 benchmark 14/15 SOTA 把它验证。
AAAI 2026 这一波在 RLVR/对齐方向有一个非常明显的共识:把 token 当成同质资源的时代结束了。从 PPPO、LLMdoctor、GenPRM、DEPO 这几篇看,下一阶段的训练方法会越来越"精细"——精细到 token 级、step 级、prefix 级、preference 级。这给做 infra 和算法的同行带来的挑战是:framework 必须支持灵活的 mask、reward shaping、curriculum schedule。如果你还在用最朴素的 GRPO 实现,明年大概率会跟不上社区节奏。
读这篇论文最大的收获是一种"减法的勇气"——别人都在加 trick、加 reward model、加 critic,PPPO 反而砍掉 65% 的梯度位置,结果反而更好。这种"以减为进"的设计美学在 ML 论文里其实少见,值得多想想。