Latent Reasoning Refinement:在不训练任何参数的前提下,给 Coconut 套一层"心理调节器"
论文标题:Efficient Post-Training Refinement of Latent Reasoning in Large Language Models arXiv:2506.08552v2 代码:github.com/anord-wang/Lateng-Reasoning 作者:Xinyuan Wang, Dongjie Wang, Wangyang Ying, Haoyue Bai, Nanxu Gong, Sixun Dong, Kunpeng Liu, Yanjie Fu 单位:Arizona State University, University of Kansas, Clemson University AAAI 2026 接收 / DOI 10.1609/aaai.v40i40.40659
一句话感受
读完这篇我一开始有点犹豫——它的故事很简洁,方法很轻,benchmark 涨幅在 +5% 量级。和 GenPRM 那种 1.5B 打 GPT-4o 的视觉冲击比起来,明显是另一个 league。
但读到第二遍时,我意识到这篇的价值不在数字,而在它问对了一个被忽视的问题:Coconut 那条把 reasoning 压进 latent space 的路线,在 inference 阶段是不是还有空间?过去一年所有 latent reasoning 工作都在卷"怎么训得更好"——这篇直接绕开训练,问"训完之后还能怎么改"。
它给的两个 building block 都极其朴素: 1. Contrastive Reasoning Feedback Search:找一个"强 checkpoint"和一个"弱 checkpoint",用它们俩对当前 hidden state 的 forward 输出之差作为梯度方向,更新当前 latent。 2. Residual Embedding Refinement:每步 latent 更新时不要全替换,按 \(\alpha \cdot h^{t-1} + (1-\alpha) \cdot f(h^{t-1})\) 做残差混合。
加起来 MathQA +5.10%、ProsQA 最大 +7.7%、StrategyQA +2.63%。全部 training-free,没有任何参数更新——只在 forward 上算几次 MSE 梯度。
这种"不用训"的方法学价值在哪?我的判断是:当 Coconut 这种 latent reasoning backbone 被 frozen(很多生产场景模型是 frozen 的),你能做的就只剩 inference 阶段调控。这篇 paper 把"latent space inference 期可以怎么调"这个问题的下限抬高了。
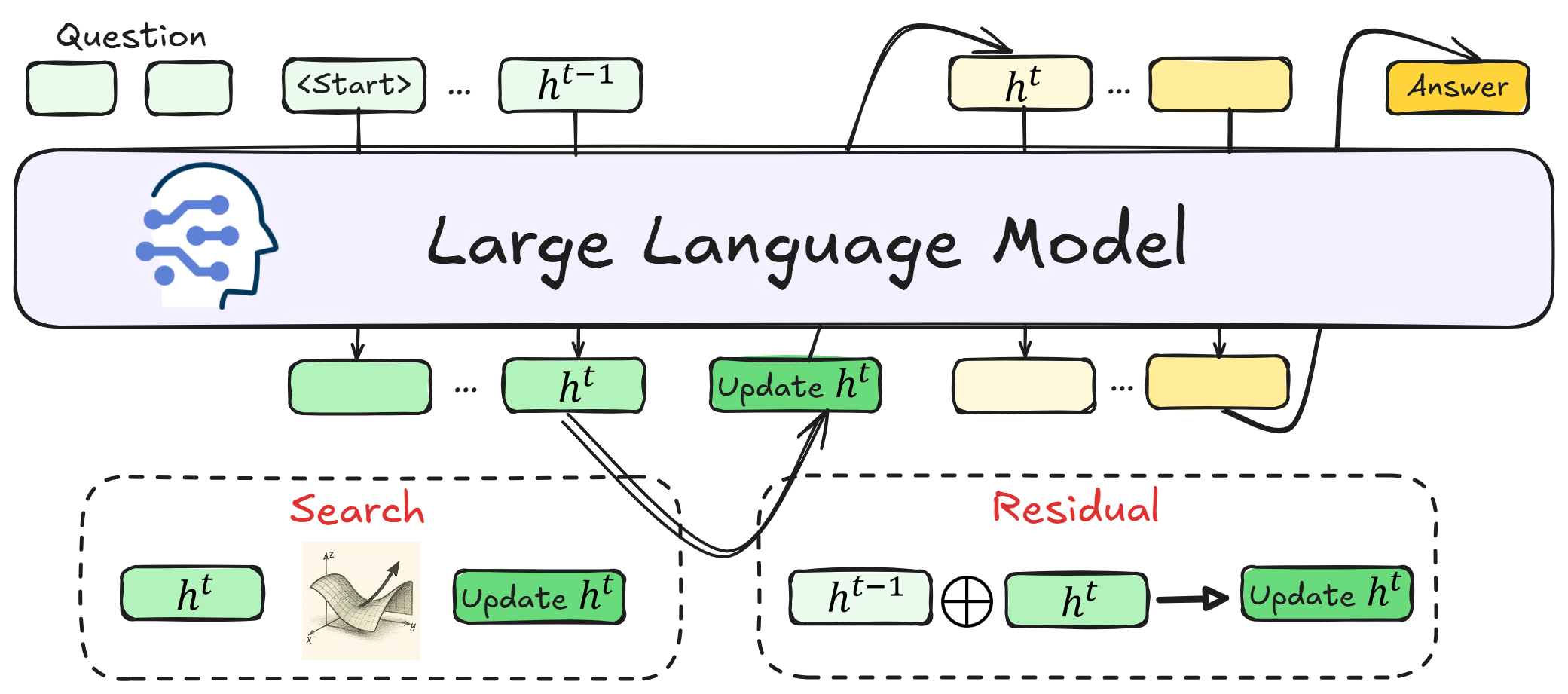
为什么需要"对 latent reasoning 做 post-training refine"
我把作者的 motivation 翻译成研究员视角的两个具体痛点。
痛点一:CoT 是 verbose 的,但 Coconut 是 rigid 的。 CoT 的问题大家都熟——一题动辄输出几百个 reasoning token,慢、贵、还会因为表达冗余引入错误累积。Coconut 是 Meta 那篇把 reasoning 全部压进 hidden state 的工作([hao2024training]),思路非常漂亮:让 reasoning 在 continuous space 里循环,每步 \(h^t = f(h^{t-1})\),不输出任何文本,最后再 decode 成 answer。但 Coconut 的代价是这条 latent 轨迹一旦进入推理就没有任何修正机制——前一步往哪偏,后面只能跟着偏下去。
痛点二:Latent space 没有梯度信号。 显式 CoT 可以靠 self-consistency / Best-of-N 这类外部多采样修正轨迹;Coconut 只跑 forward pass,连一个让模型"知道自己跑偏了"的信号都没有。这就是 latent reasoning 论文里反复出现的 "trajectory drift" 问题。
作者的两条 motivation 来源也很有意思:
- 对比方向的 idea 来自 RLHF——relative comparison 比 absolute supervision 更高效。
- 残差更新的 idea 来自 ResNet + 人脑工作记忆——保留前一步信号,避免 abrupt shift。
把 RLHF 和 ResNet 拼到 Coconut 上做 inference 期校准,这种交叉的玩法本身就值得读一下。
方法:两条朴素的 forward-only 操作
整个方法用两个公式就能讲清楚。先说对比搜索。
Contrastive Reasoning Feedback Search
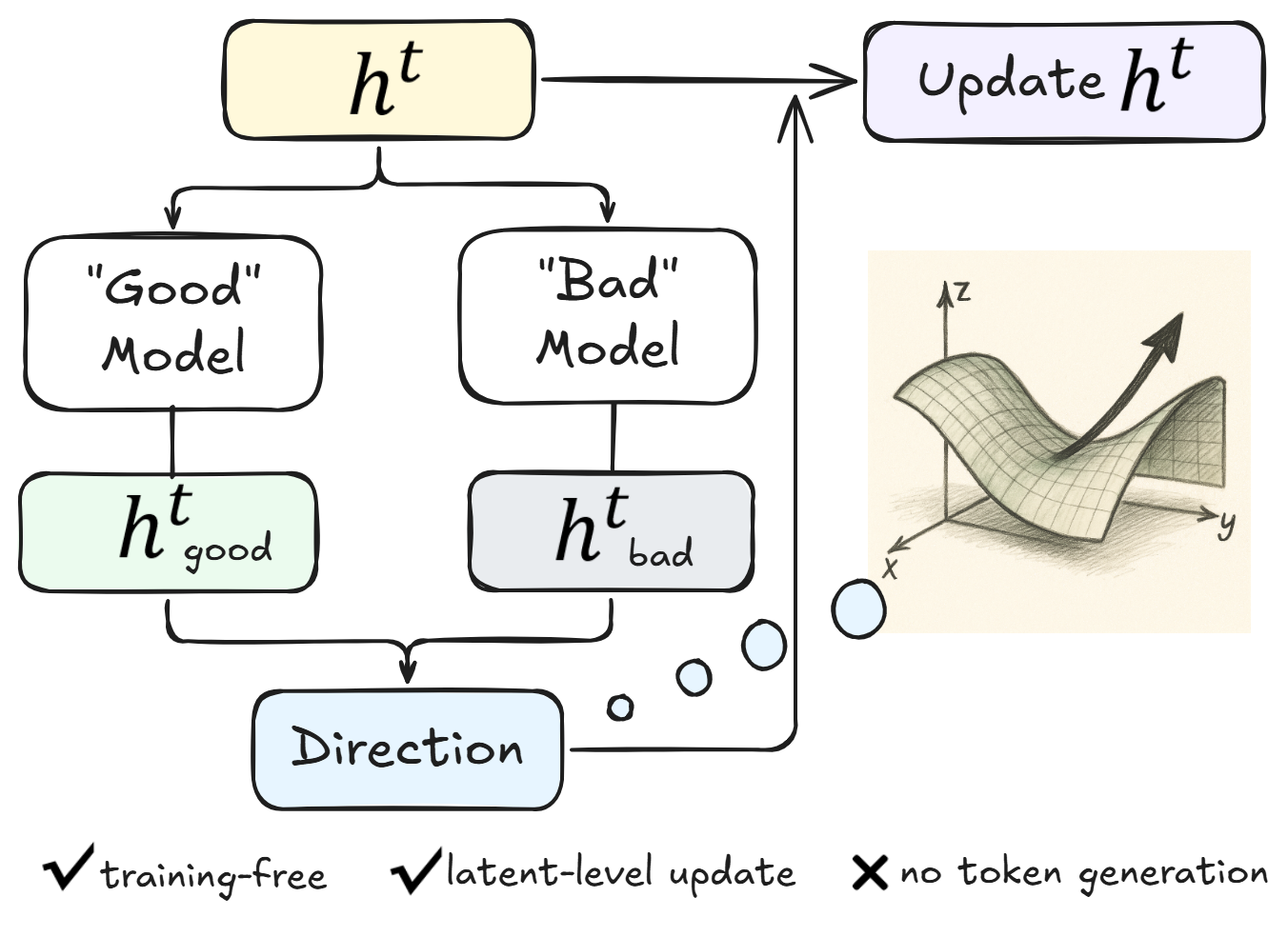
给定当前 latent state \(h^t\),作者会找两个辅助 checkpoint——一个"强"(good)和一个"弱"(bad)。这两个 checkpoint 都是从同一个 CoT 训练 trajectory 上不同 epoch 切下来的快照——比如 epoch 30 是 good、epoch 5 是 bad。注意作者说得很清楚:good 和 bad 都比最终的 Coconut 模型弱,它们的存在只是为了定义一个相对方向。
每一步分别用 good model 和 bad model 对当前 \(h^t\) 做 forward,得到 \(h^t_{\text{good}}\) 和 \(h^t_{\text{bad}}\)。然后按下式更新:
这个公式的直觉是: - 我希望当前 latent 更靠近 good model 的输出 → 减小 \(\text{MSE}(h^t_{\text{good}}, h^t)\) - 我希望当前 latent 远离 bad model 的输出 → 增大 \(\text{MSE}(h^t_{\text{bad}}, h^t)\) - 这两条加起来给了一个梯度方向,沿着它走 \(\eta\) 步。
注意几个关键点:
第一,整个过程不更新模型参数。梯度只是用来算"该往哪个方向调 \(h^t\)",模型本身完全 frozen。这才是它能号称 training-free 的原因。
第二,good 和 bad 是相对的,不是绝对意义上的强教师。这点作者反复强调——他们用的是 CoT 训练过程中的 early checkpoint(bad)和 late checkpoint(good)。这种用 training trajectory 自带的 implicit ordering 来构造对比方向的做法很取巧,不依赖任何外部强模型。
第三,这个梯度更新不是 backprop 到模型权重,而是对 latent embedding 自身求导。因为 \(h^t\) 是 forward pass 得到的,但当你把它当成一个 leaf tensor 写进 PyTorch 的 autograd graph 时,可以算 \(\partial \text{MSE} / \partial h^t\)。这是 inference 期间的小型 inner loop,开销远小于真正的训练。
Residual Embedding Refinement
这部分更朴素,一行公式:
对的,就是个加权平均。\(\alpha\) 是固定的(不训练,因为是 train-free 设定),叫 memory rate。\(\alpha=0\) 就是原版 Coconut(完全用 \(f(h^{t-1})\) 替换),\(\alpha=1\) 就是冻死不更新了。中间某个值表示"留一部分上一步信号 + 一部分新算的输出"。
灵感来源是 ResNet 的 skip connection 和人脑的 working memory。我个人的看法是,把它和 Search 一起用其实是在做两件互补的事情: - Search 是主动的、有方向的调整——告诉 latent 该往哪走。 - Residual 是被动的、稳定的调整——保住上一步的有效信号别丢了。
只用 Search 容易在某些步把 latent 推得过头;只用 Residual 没有方向感,只能维持稳定。两个一起才有"既稳又准"的效果。
主结果:MathQA +5.10%,ProsQA +7.7%,但 GSM8K 输给 CoT
主表(论文 Figure 4)画得很大但数值没在正文给精确数字。我把图里读出来的近似值整理成表(GPT-2 base 117M backbone):
| Benchmark | No-CoT | CoT | Coconut | Ours | Gain over Coconut |
|---|---|---|---|---|---|
| GSM8K | 16.5 | 42.76 | 36.3 | 36.9 | +0.6 |
| MathQA | 23.0 | 35.3 | 38.25 | 40.20 | +1.95 |
| AQUA | 22.8 | 24.7 | 28.5 | 31.3 | +2.76 |
| ProsQA | 75.0 | 77.5 | 82.0 | 85.7 | +3.67 |
| StrategyQA | 50.6 | 57.5 | 59.4 | 62.0 | +2.63 |
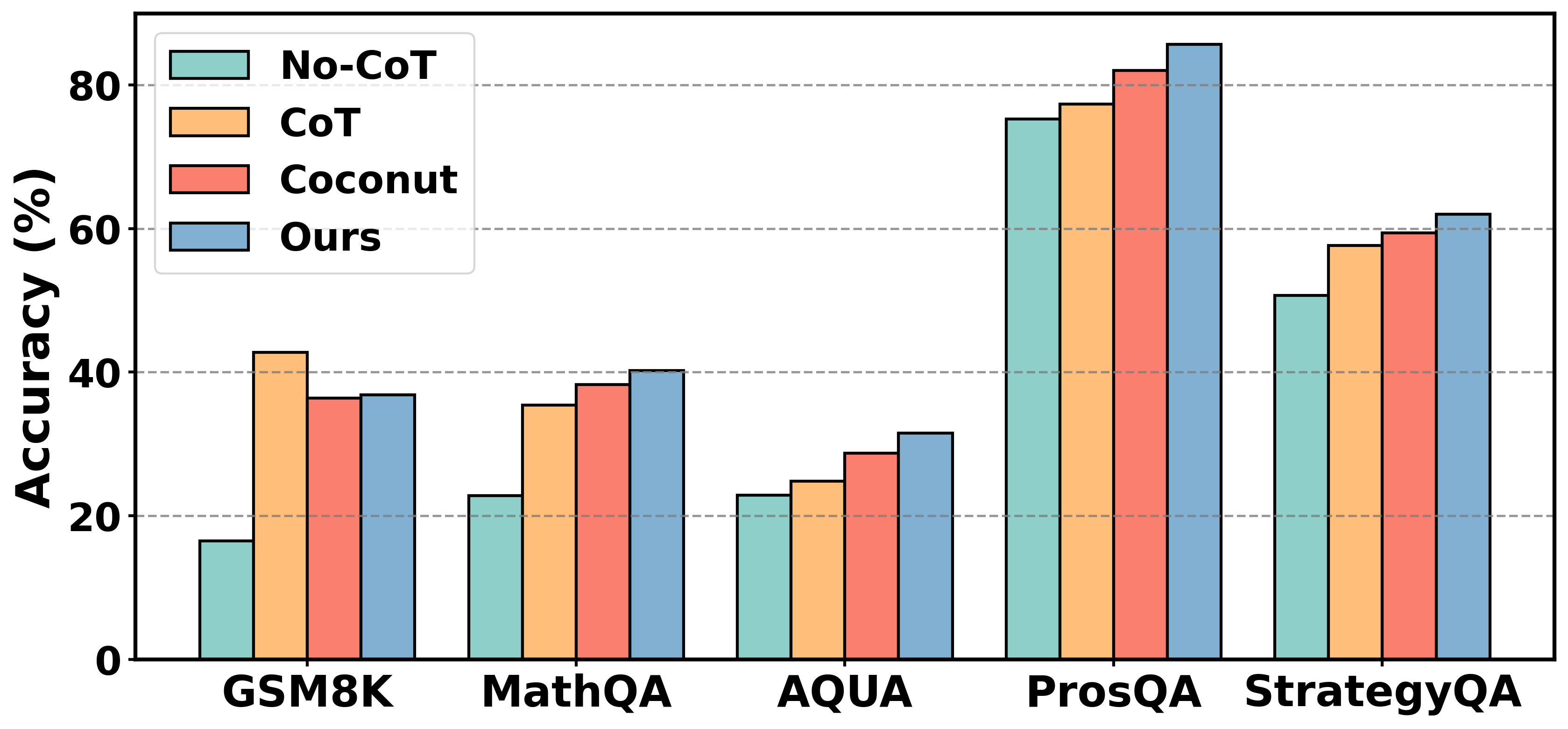
我从这张表里读出几个 takeaway。
第一,提升真实但很小。Gain 在 +1.95 到 +3.67 之间,绝对值都没破 5(消融表里 MathQA +5.10 是和 Latent only 38.25 比,包含了 backbone 优化的部分)。这种量级的提升必须放在"零训练成本"的语境下评判才合理。如果你愿意付训练代价,比如继续训 Coconut 10 个 epoch,你能拿到比 +5% 更大的收益——但那就不叫 training-free 了。
第二,GSM8K 是个反例,CoT 在那里独占鳌头。42.76% vs Ours 36.9%,差了 6 个点。作者在正文里坦诚地解释了这件事:GSM8K 的题目是开放式数值题(不是多选),需要长链算术,人类做这种题都要写在纸上算,全压在 latent space 里硬扛容易出错。MathQA 虽然也是数学题,但是多选题——latent reasoning 只需要"挑一个"而不是"算出一个数",难度低很多。这个解释让我对 latent reasoning 的适用边界有了更清晰的认识:latent space 适合 selection 任务,不适合 generation 任务。
第三,"非数学" reasoning 任务才是 latent refinement 的甜区。ProsQA(结构化逻辑推理)+3.67,StrategyQA(常识组合推理)+2.63,AQUA(符号推理)+2.76。这三个任务的共同点是 reasoning step 不需要精确算术——只要 latent 大致方向对就够了。
Inference-only 居然比 Training+Inference 更好
论文 Q2 部分给了一个反直觉的实验:在 ProsQA 上比较四种 latent refinement 启用策略:
| Setting | Accuracy Gain | Train Time | Train Mem (GB) |
|---|---|---|---|
| 原版 Coconut | baseline | — | — |
| 只在 Inference 应用 latent refinement | 4.47 | 0 (24 sec inference) | 31.23 |
| 继续训 10 epoch + Inference | +1.63 | 54+ min | 39.04 |
| Training + Inference 都用 | < +1.63 | 更长 | 更大 |
最大收益来自 inference-only。在 train + infer 都用的设定下,反而退化。
作者给的解释我觉得是这篇 paper 最值得思考的洞察:
在训练时,refinement 只影响 forward pass,不进入 backward gradient,所以模型没法真正学会怎么用它。在数据有限时,这种额外信号反而可能让模型困惑或者干扰收敛。然后 inference 时再 apply 一次,相当于做了第二次调整,可能"overshoot"正确方向。
我读到这里的反应是:train-free 不是因为训不动,而是因为训了反而不好。 这是一个很反直觉、但在 latent reasoning 这个场景里说得通的发现。Refinement 本质是 inference 期对 latent state 做一次轻量校准;如果你在 train 阶段也用,等于让模型预先把这种校准烙进权重里,而它的固化形式可能不如 inference 期动态调整灵活。
这给我一个工程暗示:所有依赖 forward-only 的 inference 期校准方法,都应该认真验证一下"训练时启用"是不是反而有副作用。这不是一句空话——很多工作默认 train + infer 一致是最优,但这篇用 ProsQA 上的三个 dataset 一致性观察证明了反例。
消融:Search 和 Residual 都不可少
论文 Q3 部分在 MathQA 上拆开了两个组件:
| Variant | Accuracy (%) | Gain over Latent only |
|---|---|---|
| Latent only(Coconut baseline) | 38.25 | — |
| + Residual refinement | 40.02 | +4.63 |
| + Latent Search | 39.79 | +4.03 |
| 完整版(Residual + Search) | 40.20 | 5.10 |
我反复盯着这张表看了两遍。直觉里我以为 Search 是主菜(提供方向感),Residual 是配菜(保稳定)。但实际数字表明:
Residual 单独用(+4.63)比 Search 单独用(+4.03)更强。
这个事实重新定义了我对这套方法的理解。Residual 不是"防止崩坏"的安全带,而是"主动累积上下文"的核心机制。Coconut 默认每步用 \(f(h^{t-1})\) 替换 \(h^{t-1}\),这相当于丢掉 100% 的上一步信号——而 reasoning 这种任务里,上一步的中间状态非常宝贵。把 \(\alpha\) 从 0 调到合理值(论文里没明说最优 \(\alpha\),从 sensitivity 实验看 MathQA 偏好 \(\alpha \to 1\)),等于给 Coconut 装了一条 short-term memory。
两个都用比单用提升非常有限(+0.18 vs +0.41)。说明这两个组件的收益没有完全独立——它们都在做"让 latent 不要漂走"这件事,只是路径不同。Residual 通过保留信号防漂;Search 通过主动校准防偏。在 MathQA 这种比较"乖"的多选任务上,它们的 overlap 比较大。
我猜在更难的任务(比如 ProsQA)上,两者的协同效应会更明显——因为更长的 reasoning chain 既需要稳定(Residual)又需要修正(Search)。
Hyperparameter sensitivity:MathQA 吃 memory,AQUA 吃 search step
Q5 的 sensitivity 实验是一个很有意思的对照。两个超参: - \(\eta\):Search step length(latent 更新的步长) - \(\alpha\):Memory rate(残差混合的权重)
在 MathQA 和 AQUA 上分别画热力图: - MathQA:accuracy 随 \(\alpha\) 增大单调提升,对 \(\eta\) 不敏感。 - AQUA:accuracy 对 \(\alpha\) 不敏感,但对 \(\eta\) 敏感得多。
作者的解释——MathQA(数学)需要稳定积累中间步骤(memory),所以 \(\alpha\) 高更好;AQUA(常识 QA)需要灵活校正方向(search step),所以 \(\eta\) 更关键。
这个观察我觉得非常实用:部署时别一套超参吃所有任务。如果你的下游是数学题,先把 \(\alpha\) 调高(0.7~0.9)再调 \(\eta\);如果是常识或多跳 QA,反过来。论文没给最优值的精确数字,但这个 task-dependent sensitivity 的现象已经足够指导调参方向。
跨 backbone 泛化:117M 到 3B 都能用
Q6 在 GPT-2 (117M) / Qwen-2.5 (1.5B) / LLaMA-3.2 (3B) 三个 backbone 上 MathQA 评估:
| Backbone | Latent only | Ours | Gain |
|---|---|---|---|
| GPT-2 (117M) | 38.25 | 40.20 | 5.10 |
| Qwen-2.5 (1.5B) | 42.29 | 43.04 | +1.77 |
| LLaMA-3.2 (3B) | 39.30 | 41.10 | +4.58 |
我注意到 Qwen 上提升只有 +1.77,明显比 GPT-2 和 LLaMA 小。作者没解释为什么,我的猜测是: - Qwen-2.5 1.5B 本身的 latent reasoning baseline 就比另外两个高(42.29% 是表里最高的 Latent only),可能已经接近 latent reasoning 在 MathQA 上的天花板,refinement 的边际收益自然下降。 - 也可能是 Qwen 的 hidden state 几何性质和 GPT-2/LLaMA 不一样,Search 的对比方向在那里效果衰减。
无论哪个原因,这都提示这个方法的收益不是线性的——你不能假设在所有 backbone 上都能拿到 +5。但好消息是它至少不退化(三个 backbone 都正向涨)。
inference 成本也很可控:117M ~ 3B 全部在 7 分钟内完成、显存 < 24GB。这个 cost profile 是符合 training-free 故事的——它没有把"省训练"换成"贵推理"。
Token efficiency:相比 CoT 省 92%+
这是我读到最后才注意到的一组数字(论文 Table 6):
| Dataset | CoT (avg tokens/query) | Latent (avg tokens/query) | Reduction |
|---|---|---|---|
| MathQA | 66.71 | 5.02 | 92.47% |
| AQUA | 72.73 | 5.31 | 92.65% |
注意这里的 5.02 和 5.31 token 是整个 latent reasoning 过程总共生成的文本 token 数——因为 latent reasoning 在中间步骤完全不出 token,只在最后 decode 答案。
92%+ 的减少是个很惊人的数字。但要冷静看待:
- 这是和原版 Coconut 共享的优势,不是这篇 paper 独有的。Coconut 的 selling point 之一就是 token saving。
- 不能直接换算成 92% 的 cost reduction——latent reasoning 在中间步骤跑 forward pass 仍然有计算开销,只是没有 KV cache 增长和 token 输出而已。
- Search 模块需要额外的 forward(good model + bad model 各跑一次),这部分成本论文没算进 token 里。如果你算上 Search 的 wallclock,整体效率比纯 Coconut 是要打折扣的。
但从"输出 token 计费"这个商业 API 的视角看,92% 仍然是真实的。如果你做的是 latency-sensitive 的部署,这个数字非常有吸引力。
我的批判性笔记
这篇 paper 在我看的 AAAI 2026 推荐论文里属于"中规中矩但有想法"的类型。我必须诚实指出几个问题。
第一,绝对性能没有竞争力。GPT-2 117M 在 MathQA 拿到 40.20% 听起来涨了,但这是个多选题任务——四选一的 random 是 25%,CoT 也才 35.3%。比起现在动辄 70%+ 的 7B 数学模型,这个绝对水平离生产可用还非常远。论文没有在更强的 backbone(比如 Qwen-2.5 7B Math)上验证,所以你不知道这套方法叠在一个本来就强的模型上还能不能涨。
第二,"good/bad checkpoint"是个隐形依赖。论文反复强调 training-free,但 Search 模块本身需要两个额外的 CoT checkpoint。这意味着你必须先有一个完整的 CoT 训练 trajectory,才能从中切出 good 和 bad。如果你没有这个 trajectory(比如你直接拿一个开源模型用),这个方法跑不起来。这是 training-free 故事里被掩盖的一个 setup cost。
第三,方法本质是把"训练时该学的东西"挪到了 inference。Residual update 和 Contrastive direction 这两件事,理论上完全可以变成训练目标——比如让模型自己学 \(\alpha\)、自己学 search direction。作者论证 inference-only 比 training+inference 更好,但我对这个结论的 generality 持保留态度。在 ProsQA 上观察到的现象不一定能推广到其他任务,特别是数据更充足的领域。
第四,公式 (3) 的梯度计算开销没有透明披露。论文说 "lightweight",但没有 wallclock benchmark 把 Search 单步开销和 Coconut 单步开销做对比。如果 Search 本身需要 3-5 倍的 forward 时间(good + bad 都要跑),那 92% 的 token reduction 在 latency 上的优势会大幅缩水。这是一个工程化必须看的数字,paper 里却缺失了。
第五,5 个 benchmark 都是分类型 / 短答案任务。GSM8K 是开放式但被作者主动放弃了("latent reasoning 不擅长长链算术")。这意味着这篇方法的实证版图集中在 selection-style reasoning,对长 chain-of-thought 的支持没有证据。用它来做 long-form generation 任务(比如代码生成、agent rollout)是 unjustified 的。
第六,与 GenPRM、Self-Refine、Reflexion 的对比缺失。和 inference-time refinement 这条 broader research line 的代表方法没有 head-to-head 比较。读者很难判断"latent refinement"这条路线相对"显式 self-critique"是更好还是更弱。
工程视角的 takeaway
我把这篇 paper 的可落地点整理成几条:
Step 1:先判断你是不是 latent reasoning 用户。如果你的 stack 已经在用 Coconut 或类似的 hidden-state-recurrent 方法,这篇 paper 是直接增益(+2 到 +5 acc,零训练成本)。如果你跑的是标准 CoT,这篇 paper 不直接适用。
Step 2:复现优先做 Residual。从消融数据看,Residual 单独用就拿到了 +4.63(90% 的总收益)。Residual 实现极其简单——一行加权平均,不需要额外 checkpoint,不需要梯度计算。先把这块加上,看看 baseline 能到哪。
Step 3:Search 模块按需启用。如果你的下游是常识 QA / 多跳推理(AQUA、StrategyQA 这种),Search 收益更大;如果是数学 selection(MathQA 这种),Search 边际收益小。Search 需要额外两个 checkpoint 和 inner-loop 梯度,工程复杂度高 3-5 倍。
Step 4:Hyperparameter 按任务调。MathQA 类(数值题):\(\alpha\) 调高(0.7+),\(\eta\) 任意;AQUA 类(常识题):\(\alpha\) 中等,\(\eta\) 仔细搜。论文 Q5 的 heatmap 是最好的参考。
Step 5:不要试图把它改成 trainable。作者的反直觉发现——training+inference 比 inference-only 更差——已经踩过这个坑。如果你想把这套 mechanism trainable 化,需要重新设计目标函数(比如显式回传 search direction 的 gradient),不是简单地在 forward 里塞进去。
我的总结
这篇 paper 给我的整体感受是:问题选得好,方案很轻,效果中等。
它真正的贡献不是 +5% MathQA accuracy 这个数字——这个数字在大模型时代不算大新闻。它的贡献是指出了 latent reasoning 范式里一个被普遍忽视的 inference-time 调控空间,并用两个非常 minimal 的 building block 给出了第一个可行的 forward-only refinement 方案。
从研究路线图上看,它是 Coconut 这条 latent reasoning 主线的一个小补丁。如果未来 latent reasoning 真的成为主流(这是一个 open question),那这篇的角色会更像"早期工程化探索"——后续工作大概率会把它的 trick 整合到训练里去(即使作者证明了 inference-only 更好,那也只是当前 setup 下的局部最优)。如果 latent reasoning 没有成为主流,这篇 paper 的实际影响力可能就限于一个有趣的边角实验。
把它放在 AAAI 2026 推荐列表里,我的定位是"latent reasoning 子方向选读"——不是必读,但读完会让你对"PRM/Reasoning 训练之外还能做什么"有新的视角。和 GenPRM (arXiv 2504.00891) 对照着读最有意思——前者是把 reasoning 显式化(让 PRM 写 CoT + 跑代码),后者是把 reasoning 隐式化(在 latent space 里直接调整)。两条路线对 reasoning 监督的态度截然相反,但都在试图回答同一个问题:测试时计算到底应该花在哪里。
下一篇我们去看 DeCoRL (arXiv 2511.19097)——它走的又是另一条路:把 CoT 拆成可并行子步、用模块化奖励逐步打分 + 级联 DRPO。"显式拆步骤" vs "压进 latent" vs "生成式 PRM"——AAAI 2026 这个赛道上的三种思路第一次同台比较。