LLMdoctor:用小模型 doctor 在 token 级别给冻结的 patient 大模型做"对齐处方"
论文:LLMdoctor: Token-Level Flow-Guided Preference Optimization for Efficient Test-Time Alignment of Large Language Models arXiv: 2601.10416 |AAAI 2026 作者:Tiesunlong Shen, Rui Mao, Jin Wang, Heming Sun, Jian Zhang, Xuejie Zhang, Erik Cambria
我读这篇之前的几个执念
我读 alignment 方向的论文会带几个固执的偏见:
第一,测试时对齐(test-time alignment)这条路径长期被低估。RLHF / DPO 把模型跟某一组偏好绑死之后想换组偏好就要重训,对企业用户是灾难——同一个模型给医疗、法务、电商三个客户用,每家都要重训一遍。Test-time alignment 用一个小的引导模型在推理期工作,理论上应该是终极方案。
第二,token 级 reward 是绕不开的方向。轨迹级 reward 把"喜欢这个回答"摊到几百个 token 上做不可靠的信用分配——典型的 reward hacking 来源。但已有的 token-level 工作(如 Selective DPO、TReg)大多自己训一个独立 token RM,要么贵要么标注不可信。
第三,Generative Flow Networks 在 LLM 里被低估。GFlowNet 的 flow conservation 是天然适配 token 自回归的——每个 token 都是状态转移、整段轨迹是 trajectory、每个状态的 incoming flow 必须等于 outgoing flow。理论上把 GFlowNet 的 SubTB 损失搬到 LLM 偏好优化里应该非常自然。
LLMdoctor 这篇神奇的地方在于——上面三条它一次全占了。token 级 reward 来自 patient 模型自己的 positive/negative behavioral variants(不另训 RM);test-time alignment 用 doctor 模型在解码期工作(patient 全程冻结);TFPO 用 GFlowNet 的 SubTB 把 token 级 reward 转化成 doctor 模型的训练目标。我读完后第一感觉是"这是把对的几块拼图拼到了一起"——单看每块都不算 dramatically novel,但组合起来形成一套完整的、可工程落地的范式。
一、Patient-Doctor 范式:把对齐这件事拆成"诊断 + 处方"
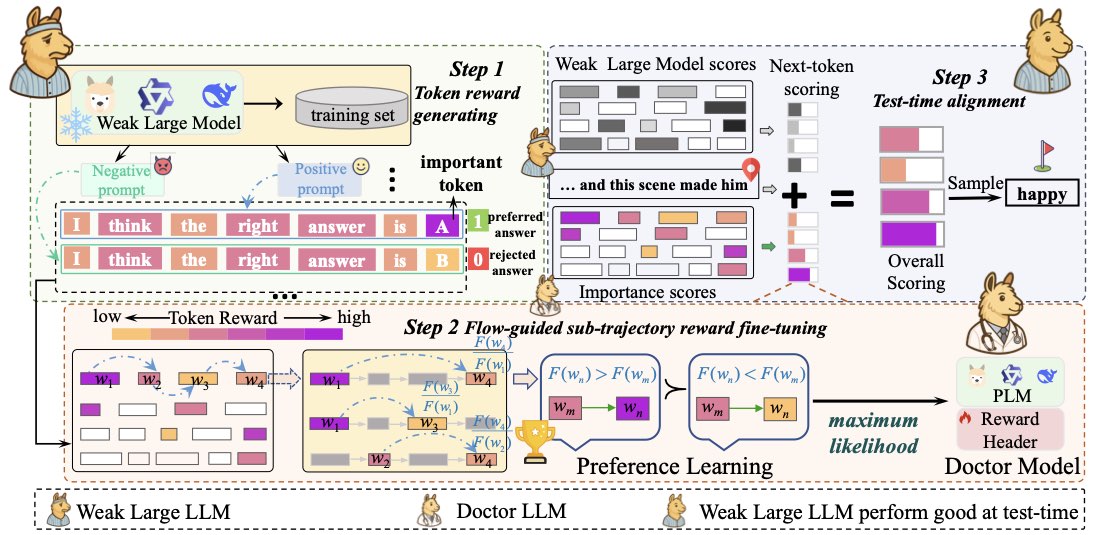
整个框架分三个阶段,对应医疗类比里的"看诊 → 培训医生 → 给病人开方":
Stage 1(Token-Level Reward Acquisition):拿一个 SFT 过但没做过偏好对齐的大模型当 patient(论文里默认 LLaMA-7B-SFT)。通过两个不同的 system prompt 让 patient 表现出 positive face \(\pi^{\text{pos}}\)(被指示要 helpful、accurate、polite)和 negative face \(\pi^{\text{neg}}\)(被指示要 unhelpful、omit critical info)。注意——两个 face 共享同一组参数,差别只在 prompt。这是关键巧思,省掉了训独立 RM 的成本。
对偏好数据集 \(\mathcal{D} = \{(x, y_+, y_-)\}\) 里每条样本的每个 token \(y_t\),计算 patient 在两个 face 下的 log-likelihood 差:
这个差值越大说明 token \(y_t\) 越能"区分好坏行为"——它是这条响应里真正承载偏好信号的 token。把 \(\Delta_t\) 做归一化和 tanh 平滑得到 \(S_t \in (0, 1)\),再结合人类偏好标签 \(\text{sign}(y) \in \{+1, -1\}\) 和稀疏阈值 \(\theta\) 得到最终 token reward:
这个公式的几个细节我反复琢磨:
- \(\text{sign}(y)\) 控制方向:如果 token 在 \(y_+\) 里就奖励,在 \(y_-\) 里就惩罚——这把 trajectory 级的 binary 标签精准转化为 token 级的有向信号。
- \(\mathbf{1}[S_t > \theta]\) 控制稀疏性:只有"足够 discriminative"的 token 才拿到非零 reward,连接词如
the/and几乎都被过滤——这避免了 reward hacking 把分数摊在 neutral token 上的老问题。 - 不需要训 RM:这是 patient-doctor 范式的核心 leverage——patient 自己通过 prompting 当了一回 RM。
我一开始怀疑"两个 prompt 跑一遍模型就能造 token reward"是不是太朴素,论文给了一个 information-theoretic 证明(Appendix D,引理 D.1):在合理假设下 \(\Delta_t\) 是 token 对偏好判断信息增益的下界。这给了方法理论 foundation,不只是 ad-hoc trick。
Stage 2(TFPO):训一个小的 doctor 模型 \(\hat{\pi}_\theta\),目标是把 stage 1 拿到的 token-level reward 内化进 doctor 的策略分布。这一步是论文最 technical 的部分,下一节展开。
Stage 3(Online Alignment):推理期 doctor 和 patient 各自前向一次,按公式融合两个分布:
\(\alpha\)、\(\beta\) 是控制 fluency vs alignment 的权重,在推理时可以动态调。这意味着同一个 doctor + patient 组合,给客户 A 调 \(\beta=0.5\)(保守对齐),给客户 B 调 \(\beta=2.0\)(强对齐),不需要重训。
二、TFPO:用 GFlowNet 的 SubTB 损失把 token reward 写成训练目标
这一节我读了三遍才理顺。GFlowNet 在 LLM 里不是新东西(GFlowNet-EM、GFlowNet for tree-of-thoughts 都做过),但 LLMdoctor 把 SubTB 用在偏好优化里是我见过最干净的应用。
Flow 的定义
把生成过程看成一条 trajectory:\(s_0 \to s_1 \to \dots \to s_L\),其中 \(s_t = (y_1, \dots, y_t)\) 是前缀状态。定义穿过状态 \(s_t\) 的 flow:
其中 \(Q(s_t)\) 是从 stage 1 的 token reward \(\{r_k\}_{k<t}\) 派生的"前缀分数"(一个正值权重,编码偏好信息),\(V_\phi(s_t)\) 是 doctor 模型上加的一个 value head 学出来的 value 估计。这个分解很巧妙——\(Q\) 提供来自外部的偏好先验,\(V\) 提供来自 doctor 自身的 learnable 估计。
Subtrajectory Balance 损失
对任意 \(0 \leq m < n \leq L\) 的子轨迹 \(s_m \to s_n\),要求 forward flow 等于 backward flow(取均匀 backward policy \(\hat{\pi}_B = 1\)):
取对数得到训练 loss:
这个 loss 的妙处在于——它把原本 \(\mathcal{O}(1)\) 个 trajectory 级监督信号扩展成 \(\mathcal{O}(n^2)\) 个 subtrajectory 级监督信号。一条长度 \(n\) 的轨迹有 \(\binom{n}{2} \approx n^2/2\) 个子轨迹,每个子轨迹都能贡献一个监督约束。这是为什么 LLMdoctor 在小规模数据上也能训得稳的关键——监督信号密度上去了。
Value 判别损失
光有 SubTB 不够——SubTB 主要保证 flow 守恒,但不直接保证 value 函数能区分好坏 token。再加一个 hinge loss:
对于偏好的 token \(y_w\) 和不偏好的 \(y_l\),要求 \(V_\phi\) 给前者打更高分(margin \(\gamma\))。这样训完的 value 函数本身就是个隐式的 reward predictor。
最终 loss 组合:
Diversity 保证:TFPO 为什么不会 mode collapse
GFlowNet 跟标准 RL 最大的区别是——它学的是按 reward 比例采样的策略 \(p(\tau) \propto R(\tau)\),而不是只采 reward 最高的那条路径。这意味着 TFPO 训出来的 doctor 天然保留生成多样性。论文 Appendix E 给了证明,核心论点是 SubTB 收敛时策略的熵下界由 reward 分布的 entropy 给定——只要 reward 不是退化的 delta 分布,策略就保持有意义的随机性。
我自己的直觉解释:传统的 RLHF/DPO 是"reward maximization"——找到让 reward 最大的策略,模型必然向某个 mode 塌陷。GFlowNet 是"reward matching"——让策略的采样概率跟 reward 成正比,所以高 reward 的多个 mode 都被保留。这个 diversity 保留对 instruction-tuned 模型至关重要——你不希望对齐之后所有回答都长一个样子。
三、主实验:对齐效果直接超过 DPO 全量微调
LLMdoctor 在 HH-RLHF(300 prompt 用 GPT-4o head-to-head)上的核心结果:
| 对比 | Win + ½Tie (%) |
|---|---|
| LLMdoctor vs Greedy | 92.95 |
| LLMdoctor vs Top-p Sampling | 91.25 |
| LLMdoctor vs Naive RS | 82.30 |
| LLMdoctor vs ARGS (test-time SOTA) | 76.00 |
| LLMdoctor vs CARDS | 72.45 |
| LLMdoctor vs GenARM | 62.10 |
| LLMdoctor vs DPO | 61.00 |
最让人惊讶的是最后一行——LLMdoctor 在 test-time 对齐 vs DPO 全量微调拿到 57.8 赢 / 35.8 输 / 6.4 平的胜率。这意味着用一个小的 doctor 模型在推理期工作的效果比把整个模型在偏好数据上 DPO 一遍还要好。这个结果如果能复现,对工业落地是革命性的——不再需要为每组偏好单独 fine-tune。
第二个让我赞叹的对比是 GenARM vs DPO 大约 52.25 个点的胜率(接近平分秋色),但 LLMdoctor vs GenARM 直接拿到 62.10 个点——LLMdoctor 比 SOTA 的 test-time 方法又有一个明显跨越。我倾向于相信这种"递进胜率"是 token-level + flow-guided 两个改进叠加的结果,单独任一个都不够。
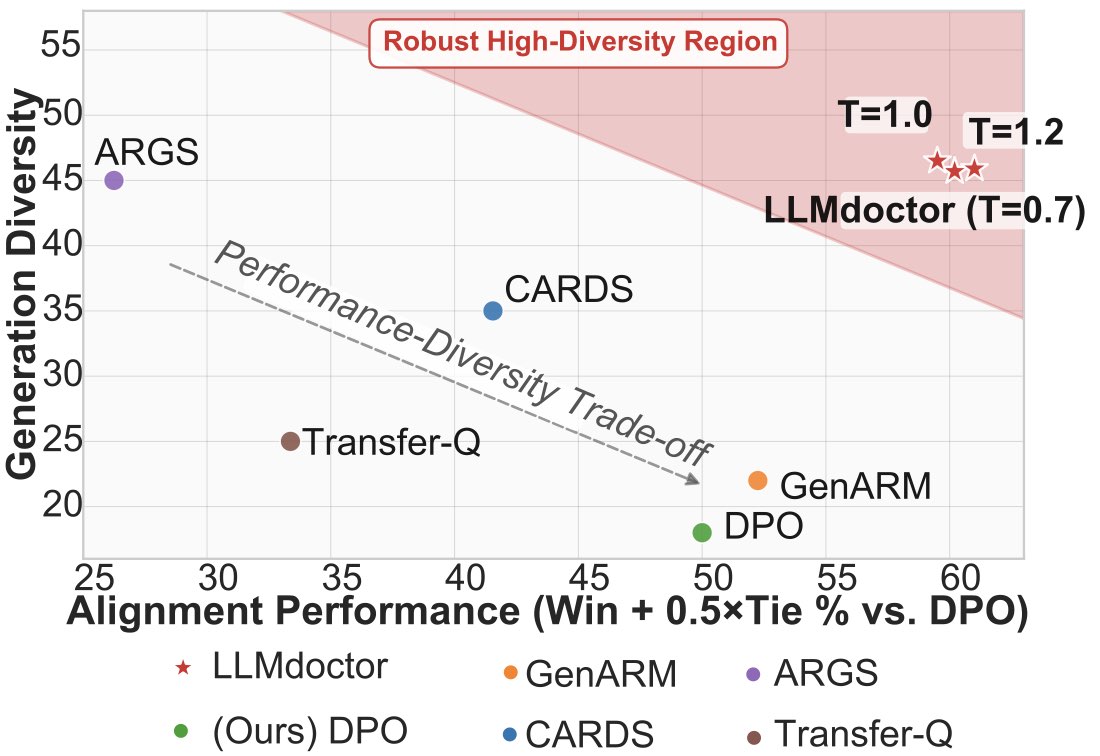
Diversity 这一维度
Fig.6 那张 performance vs diversity 散点图(横轴 diversity,纵轴 win rate vs DPO)显示:DPO 性能高但 diversity 低,标准 sampling diversity 高但性能低,LLMdoctor 同时拿到高 win rate 和高 diversity——居于散点图的右上角,几乎是 Pareto 最优点。这个验证了 TFPO 多样性保留的理论承诺。我猜测如果做 self-consistency 采样(同一 prompt 采 N 次取多数票),LLMdoctor 会比 DPO 收益更大,因为采样的多样性正是 self-consistency 的前提。
四、Multi-Dimensional Preference:Pareto frontier 全面碾压
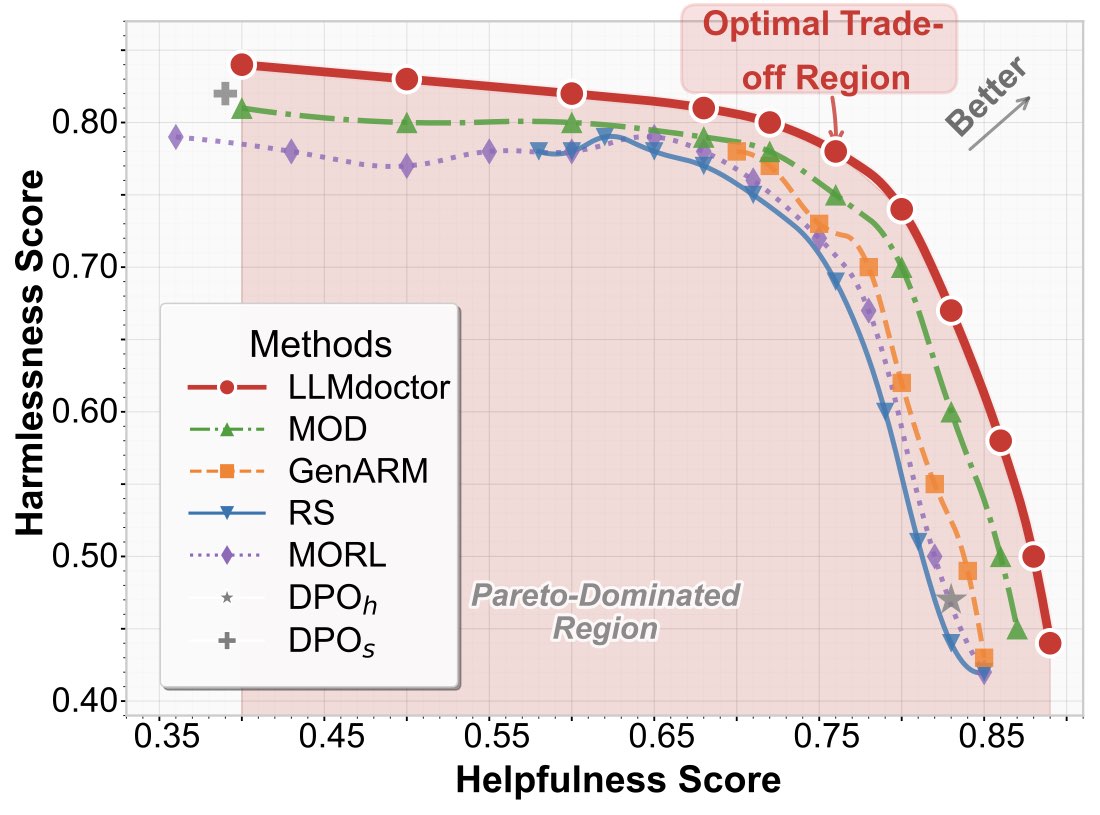
PKU-SafeRLHF-10K 上 LLMdoctor 用两个独立训的 doctor 模型——一个对齐 helpfulness、一个对齐 harmlessness——在推理期通过权重 \(\beta_h\)、\(\beta_s\) 动态融合。Pareto frontier 整个支配其他方法(包括 Reward Soups、MORL 等多目标方法)。
这个能力是 RLHF/DPO 体系做不到的——做完一次 alignment 之后比例就锁死了。要换比例只能重训。LLMdoctor 这种 modular doctor 的范式让多目标对齐变成"加法操作",对于现实场景(不同用户、不同任务对 helpfulness/safety/conciseness 有不同 trade-off)极有用。
五、Weak-to-Strong Guidance:用 7B doctor 引导 70B patient
这是论文里我最看重的实验。Tulu2 系列上做实验:固定 7B doctor,分别引导 7B / 13B / 70B 的 patient SFT 模型。每个 scale 都跟在该 scale 上做 DPO 全量微调的基线对比,用 AlpacaEval 2 的 length-controlled win rate 衡量。
结果:
- 7B patient + 7B doctor LC win rate 65.2 个点(vs DPO 7B 64.8)
- 13B patient + 7B doctor LC win rate 74.3 个点(vs DPO 13B 71.5)
- 70B patient + 7B doctor LC win rate 达到 82.5 个点(vs DPO 70B 82.0)
让一个 7B 的 doctor 引导一个 70B 的 patient 达到跟 70B DPO 全量微调几乎同等的对齐效果——这是个相当夸张的结论。换算成实际成本:70B DPO 训练大概要 8×A100 持续几天,而 LLMdoctor 只需要训一次 7B doctor(几小时),之后所有 scale 的 patient 都能复用这个 doctor。我估计这能把 alignment 的工业成本降一个数量级。
理论上这意味着 alignment 的"capability ceiling"由 patient 决定,而不是由 doctor 决定。论文 Appendix B(Token-Level Ceiling Effect 证明)给了 formal argument:当 token-level reward 用 ratio 形式的 KL 推导时,ceiling 效应被消除——因为 ratio 不依赖 doctor 的绝对 capability,只依赖它的"区分能力"。这对应到我前面提到的 \(\Delta_t\) 用差值不用绝对 likelihood,是同一个数学事实的两个表述。
六、Alignment Signal Dynamics:value gap 看出 doctor 的 foresight
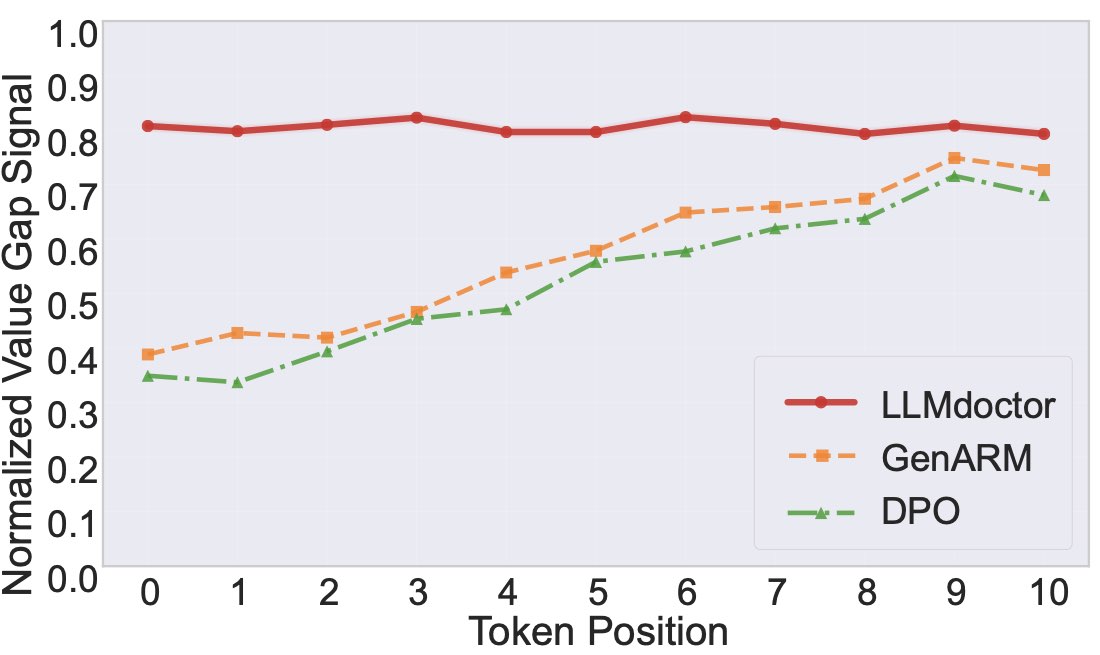
这是篇里我读得最有快感的图。作者定义了一个 value gap——在生成 preferred response 的每一步,比较"模型给出的下一个 token logit"和"基础 SFT 模型给出的 logit",看模型有多 confident 选对正确 token。
LLMdoctor 的 value gap 曲线显示:
- 早期 token 的 gap 大(前 30% 序列长度)—— doctor 在序列开头就能很 confident 把生成轨迹 steer 向 preferred direction
- 后期 gap 趋稳——一旦轨迹定向,doctor 不再频繁干预,让 patient 自然续写
- GenARM 等基线的 gap 在中段才上升——它们的 token-level signal 是从轨迹级 reward "摊"下来的,前期信号弱
这个观察验证了 token-level reward 设计的核心动机:重要 token 通常出现在序列早期(开头几句决定整段回答的语气和方向),sequence-mimicking 方法把信号摊得均匀反而错失了关键信号。
七、几点批判性思考
1. Positive/Negative face prompt 的设计是隐藏的工程成本
论文 Appendix F 给了 positive 和 negative face 的 prompt 模板。我读完发现这两个 prompt 写得相当用心——positive face 强调 honest / helpful / informative;negative face 强调 vague / off-topic / withhold critical info。换个 domain(比如代码、医疗、法务)这两个 prompt 必然要重新设计。这意味着 LLMdoctor 的"零额外训练"承诺并不完全 free——它换成了 prompt 工程成本。
更隐蔽的问题是 prompt 的两端要对齐 patient 的指令理解能力。如果 patient 模型对某种 instruction 不敏感(比如指令微调不充分的小模型),\(\pi^{\text{pos}}\) 和 \(\pi^{\text{neg}}\) 的差距会很小,token reward 信号就稀。这一点在 LLaMA-7B-SFT 上工作很好,但能不能迁移到 8B、70B Llama-3 base 模型上需要额外验证。
2. SubTB 在长序列上的 \(\mathcal{O}(n^2)\) 复杂度
对长度 \(n\) 的轨迹做 SubTB 训练要枚举 \(\binom{n}{2}\) 个子轨迹。HH-RLHF 平均响应长度 200 token 还能接受(200×100 = 20000 个 subtraj),但如果应用到 reasoning 长 trajectory(5K token CoT)就会爆炸(5000×2500 = 1.25e7)。论文没讨论这个 scaling limit,实际工程化估计要做 subtrajectory 的随机采样,这会引入 variance。
3. Token-level reward 假设了 SFT 模型已经"会说话"
stage 1 用 SFT 模型的 prompt-induced behavior 当 reward 来源——这隐含假设 SFT 模型本身已经能理解 prompt 并产生 distinguishable behavior。如果 patient 是个 base model(比如纯预训练没 SFT 的模型),\(\Delta_t\) 信号会非常弱。这给 LLMdoctor 的 applicability 划了一条边界——它适用于"已经懂指令、缺偏好"的模型,不适用于从零开始的 alignment。
4. GPT-4o 评估的潜在偏差
主实验 head-to-head 都用 GPT-4o 当 judge。GPT-4o 自己被 OpenAI 训成了某种 helpful/harmless 风格,它给"风格相近"的输出打高分是有偏的。如果 LLMdoctor 输出的风格碰巧跟 GPT-4o 的 default style 接近(比如都是 OpenAI 风的对齐 tone),评分会被高估。最严格的验证应该用人类标注,论文没做这个。
5. 跟 DPO 比的样本效率没说清楚
LLMdoctor 训 doctor 的开销是 patient 的某个比例(具体没给数字)。如果 doctor 是 patient 的 1/10 大小,训一次 doctor 的算力大概是 DPO patient 的 1/10——但这只是单次成本。换 preference 配置时 LLMdoctor 不需要重训(用 \(\beta\) 调),DPO 要全部重训,长期 cost ratio 是 LLMdoctor 远低于 DPO。这一点应该在论文里量化呈现而不是默认读者自己算。
八、对从业者的实操建议
读完 LLMdoctor 之后,我会在自己的对齐管线里做这几个调整:
- 重新评估是否需要 DPO 全量微调。如果你的场景需要灵活切换 preference 配置(多客户、多场景),LLMdoctor 这种 test-time 方案应该作为默认方案。
- doctor 模型大小取 patient 的 1/10 量级即可。论文用 7B doctor 引导 70B patient 工作良好,没有迹象表明 doctor 必须更大。
- token reward 的 prompt-based 提取值得复用。即使你不用 TFPO,positive/negative face 这套提取 token-level signal 的方法也能用在传统 DPO 加速收敛、或者做 reward shaping。
- 保留 diversity 是 alignment 的隐性指标。不要只看 win rate,要同时报告 distinct-N、self-BLEU 之类的 diversity 指标——LLMdoctor 在这两个轴的 Pareto 表现是它真正赢过 DPO 的地方。
- 多目标对齐用 modular doctor。每个偏好维度训独立 doctor,推理期用 \(\beta_i\) 加权融合。比单一 reward soup 灵活。
九、跟前几篇推荐论文的串联
我把这周读的几篇 alignment 方向论文做个串联:
- GenPRM(arXiv 2504.00891) 用生成式过程奖励 + 代码验证给数学题每步打分
- UnPRM(arXiv 2508.01773) 用不确定性筛选 PRM 数据
- DEPO(arXiv 2511.15392) 把 dual-efficiency(token + step)打进 KTO loss
- DeCoRL(arXiv 2511.19097) 模块拆分 + 反事实贡献奖励
- LLMdoctor(本文) token 级 reward + GFlowNet flow-guided 优化
五篇论文回答的是同一类问题:怎么给 LLM 提供更细粒度的偏好/奖励信号,并把这种细粒度信号转化成稳定的训练目标。GenPRM、UnPRM 关注 step-level;DEPO、DeCoRL 关注 trajectory-level 的某种结构化属性;LLMdoctor 把粒度推到了 token-level——是这条研究线上最细的一档。
我有一个判断——未来 6-12 个月会出现"token-level + step-level"的混合方案。比如把 LLMdoctor 的 token reward 跟 GenPRM 的 step reward 用层次化方式叠加,让模型同时受益于两个粒度的监督。如果你在做 alignment 方向的研究,这个 niche 是个值得挖的方向。
十、结语:从"开方"到"开药"的一次范式跃迁
写到这里我对 LLMdoctor 的看法稳定了——这是 AAAI 2026 我目前读的几篇 alignment 论文里完成度最高的一篇。它不只提出一个新损失函数或新 trick,而是给出了一套完整的 paradigm:
- 概念层:patient-doctor 比喻让 test-time alignment 这件事变得直观可传播
- 方法层:prompt-induced behavioral variants + GFlowNet SubTB 给出了具体可实现的算法
- 理论层:information-theoretic reward 证明、ceiling effect 证明、diversity 证明三件套补齐了数学保证
- 实验层:HH-RLHF + PKU-SafeRLHF + AlpacaEval 三个 benchmark 上分别覆盖单维对齐、多维对齐、weak-to-strong guidance
加上 doctor 模型可以 modular 复用 + 多偏好运行时切换 + diversity 保留这几个工业落地友好的属性,我会把它列入"必复现"清单。
最后一个我个人特别欣赏的细节——论文用了"医生"这个比喻而不是"reward model"或"alignment model"。好的科学命名能让概念跳出技术圈——这是 transformer / attention is all you need / masked language modeling 这些词能广为传播的根本原因。LLMdoctor 这个名字朗朗上口,过几年大概率会变成业界对"token 级 test-time alignment"这类方法的代称。