GenPRM:让 1.5B 的过程奖励模型,靠"边写边推理边跑代码"打赢 GPT-4o
论文标题:GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning arXiv:2504.00891v2 项目主页:ryanliu112.github.io/GenPRM 作者:Jian Zhao, Runze Liu, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi, Xiu Li, Bowen Zhou 单位:清华大学、上海 AI Lab、北邮、哈工大 AAAI 2026 接收 / DOI 10.1609/aaai.v40i41.40797
一句话感受
读完这篇我第一反应是"PRM 终于跳出了那个 0~1 的小框框"。
过去两年大家训 PRM 都在卷一件事——给每一步打 0/1 标签,softmax 出个概率分数,谁的 F1 高谁牛。但我心里一直有个疑惑:LLM 是生成模型,凭什么我们让它做的最重要的工作是"输出一个 scalar"?这等于把语言模型当回归头用,pretrain 那么多 token 全浪费了。
GenPRM 给的答案非常干脆:让 PRM 在打分前先用自然语言写一段 CoT,再写一段 Python 代码跑一跑,最后再决定 Yes/No。仅用 23K 来自 MATH 的数据,1.5B GenPRM 在 ProcessBench 上 Maj@8 拿到 63.4 的 F1,超过 GPT-4o 的 61.9;7B 模型 Maj@8 拿到 80.5,把 Qwen2.5-Math-PRM-72B(78.3)整个比下去。10 倍参数差被一个测试时 8 路投票抹平了。
这件事的味道,和 OpenAI o1 把"思考"留在推理阶段是一样的——只不过这次思考的不是答题人,而是阅卷人。
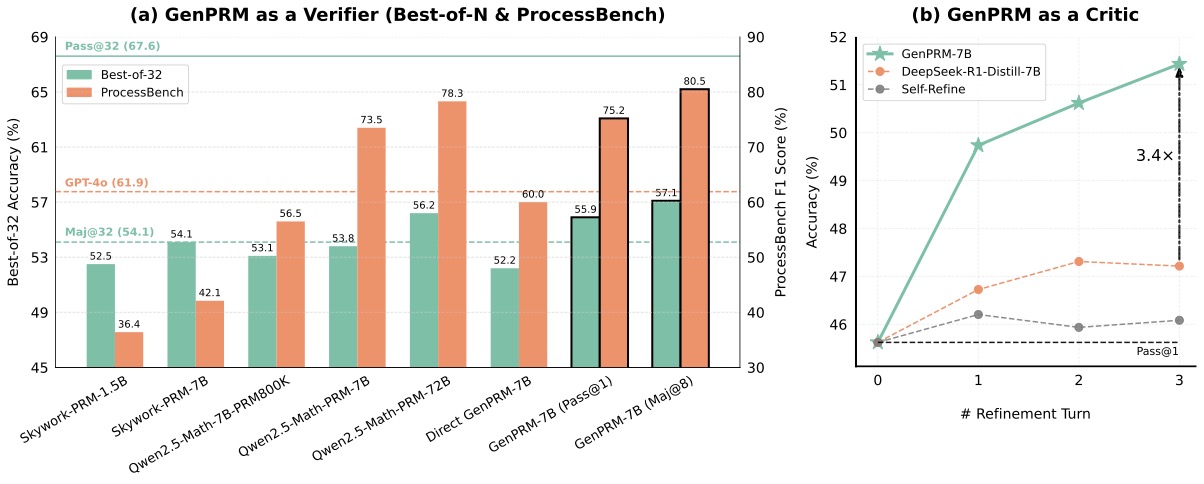
上面这张是论文 Figure 1 的开场图,左边告诉你 7B 的 GenPRM Maj@8(最右两根带边框的柱子)在 ProcessBench F1 上达到 80.5、Best-of-32 上达到 57.1,把 Qwen2.5-Math-PRM-72B(72B 参数)压在身下;右边告诉你做 Critic 时 GenPRM-7B 三轮 refine 拿到 3.4× 于 DeepSeek-R1-Distill-7B 的提升幅度。两组实验的 takeaway 用一句话概括:生成式 PRM 可以把测试时计算的红利吃满,scalar 式 PRM 不能。
为什么需要 GenPRM:三个我观察到的痛点
我按自己做 PRM 的经验把作者的 motivation 翻译成研究员视角:
痛点一:PRM 越来越像一个"黑盒判官"。 你给它一道题、一段过程,它返回 0.78。这个 0.78 是什么意思?哪一步出错了?为什么错?你不知道。靠 attention 可视化也只能看个大概。这种打分方式让 PRM 变成了一个无法 debug 的工具,甚至训练数据里的噪声你都无从查证。
痛点二:PRM 的判断力卡死在训练分布上。 我自己跑过的实验,Math-Shepherd 那一档训出来的 PRM 在 GSM8K 还行,一换到 OlympiadBench 直接掉到 25 上下。论文里 Table 1 也印证了这一点:Math-Shepherd-PRM-7B 在 OlympiadBench 只有 24.8,到 Omni-MATH 是 23.8。这种泛化坍塌的根源很简单——分类头的容量天花板就在那里。
痛点三:PRM 不能从"测试时算力"中获益。 策略模型可以靠 BoN、self-consistency、MCTS 越想越准;PRM 输出一个标量,再多算几次结果还是那个标量。这是一个对称性的破坏——验证者 reasoning 能力远低于被验证者。直到有一天我意识到,这其实是把 LLM 的生成能力浪费了。
GenPRM 把这三个痛点同时解决:CoT + 代码让判断过程显式可读;生成式打分让 PRM 享受 LLM 的预训练知识泛化;多路 reasoning + 多数投票让 PRM 也能 scale up 测试时算力。
方法核心:把 PRM 重写成一个"会写代码的小型 reviewer"
整个方法可以拆成三块:模型形态、数据合成、测试时扩展。
模型形态:从 Discriminative → Direct Generative → Generative + Code
论文给了一张极简的对比图,把三种 PRM 的形态画清楚了:
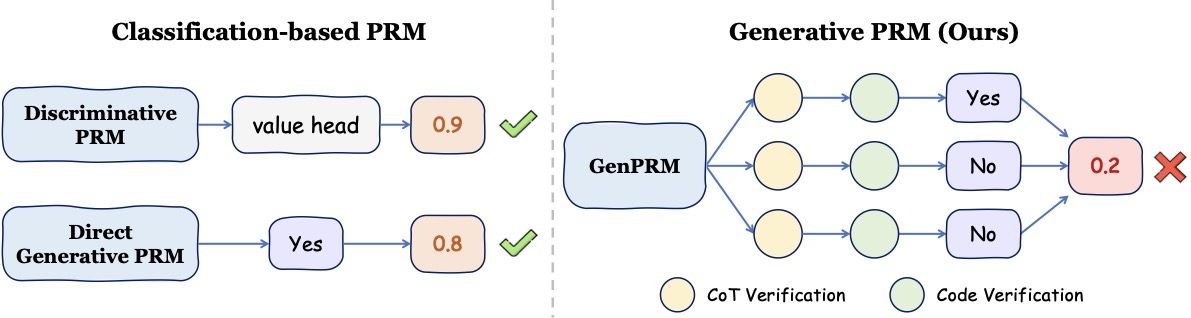
- Discriminative PRM(如 Math-Shepherd):在 LLM 顶上接一个 value head,二分类交叉熵训练,每步输出一个 [0,1] 之间的分数。
- Direct Generative PRM(如 RLHFlow):去掉 value head,让模型直接生成 token "Yes" 或 "No",用 SFT 训。打分时取 P(Yes) 作为 reward。这一步已经迈进生成式了,但还没有 reasoning。
- GenPRM(本文):在 Yes/No 之前插入一段 rationale——先写
<analyze>标签内的 CoT 自然语言分析,再写<verify>标签内的 Python 代码并执行,把[Code Output: …]拼回上下文,最后再生成 Yes/No。
形式化地,完整 reward 形式是:
其中 \(v_t\) 是当前步的 rationale(CoT + 代码)、\(f_t\) 是代码执行反馈。这个公式看着复杂,但拆开就是一句话:第 t 步的判断要 condition 在前面所有步的 reasoning + 代码运行结果上。代码不是装饰,是实打实参与下一步推理的输入。
我特别欣赏的一个设计是 QwQ-32B 在合成 rationale 时,如果 CoT 推理结论和代码执行结果不一致,模型会自动触发 self-reflection 直到达成共识。这意味着训练数据里天然包含了"先推错、看到代码 output、然后改正"的范本——GenPRM 在 inference 时也学会了这种回头反思的行为,这个能力是分类式 PRM 永远没有的。
数据合成:23K 数据怎么挑出来的
GenPRM 一共只用 23K 训练样本,全部来自 MATH 的 7.5K 题。这个数据规模在 PRM 这个领域简直是奢侈的小——Qwen2.5-Math-PRM 用了 ~344K,Math-Shepherd 用了 445K。能用 1/15 的数据反超大模型,说明 pipeline 里每一步过滤都做得很狠。
整个 pipeline 是六阶段的,论文 Figure 2 给了一张总览:
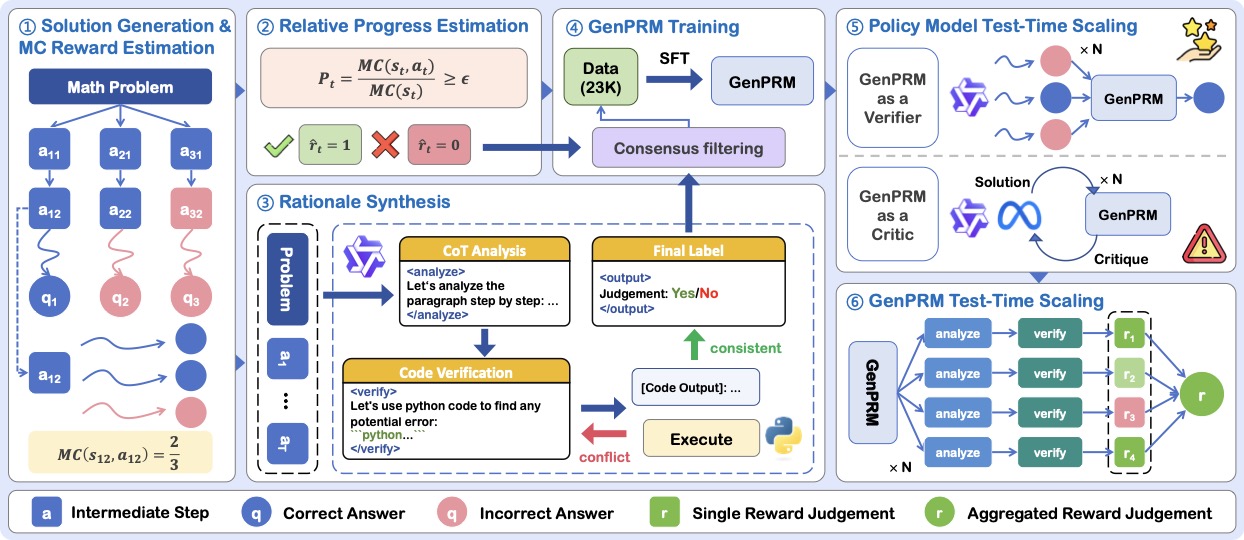
我重点说三个最关键的设计——Step Forcing、动态 K 的 MC 估计、和 RPE 标签估计——因为这三件事直接决定了数据质量。
Step Forcing 解决"步骤切分太碎"的问题。 朴素做法是用 \n\n 切步骤,但 LLM 的换行习惯非常随意,一个数学推导经常被切成 20 个支离破碎的小步骤,标签噪声大到没法用。GenPRM 改成强制要求生成模型按 Step 1: ... Step T: ... 的格式输出,让步骤切分天然带语义。这是个工程小 trick,但实测带来的标签清洁度提升比你想的多。
动态 K 的 MC 估计平衡精度与算力。 用完成式采样估计每步的 MC 分数(即从当前步出发能走到正确答案的概率)时,难题需要更多采样才能让方差收敛,简单题则浪费算力。作者用 Pass@1 自适应:
这个分段函数看起来朴素,但它是对"PRM 标签噪声主要来自难题样本不够"这件事的精准回应。论文里也说,对于反复采 2048 条都既找不到正确路径又找不到错误路径的题,直接丢弃。
Relative Progress Estimation:PRM 标签的关键创新。 传统硬标签(hard label)是这样的:MC > 0 就标 1,否则标 0。问题在于,作者发现很多步骤 MC 大于 0 但本身是错的——只是 completion 模型运气好把它救回来了。这种情况标 1 显然不对。
RPE 把"正确"重新定义成"对接下来求解有正向 progress":
直觉是这样:当前状态 \(s_t\) 的 MC 是已知的"基线难度",加上这一步动作后到达 \(s_{t+1}\) 的 MC 是新的"难度"。如果比值大于阈值(默认 0.8),说明这一步让问题变得更容易解了——这才叫一个好的中间步骤。
这个公式神似 GRPO 的相对优势估计,区别只是粒度从 trajectory 降到了 step。我觉得这就是这篇论文最锋利的概念创新——把 RL 里的 advantage 思路直接搬进 PRM 标签估计,一下子把"绝对正确"和"相对有用"区分开了。
消融实验印证了这件事的威力:
| Estimation | Threshold | GSM8K | MATH | OlympiadBench | Omni-MATH | Avg |
|---|---|---|---|---|---|---|
| Hard label (\(P_t > 0\)) | — | 72.9 | 78.9 | 73.2 | 68.0 | 73.2 |
| Diff form (\(P_t \ge -0.5\)) | — | 75.8 | 80.2 | 72.8 | 68.6 | 74.3 |
| Ratio form | 0.8 | 78.7 | 80.3 | 72.2 | 69.8 | 75.2 |
| Ratio form | 1.0 | 76.4 | 77.4 | 68.1 | 67.2 | 72.3 |
注意倒数第二行:阈值卡到 1.0(严格意义上的"必须让问题变更容易")反而掉到 72.3,说明保留少量"持平"的步骤给训练带来了必要的容忍度。0.8 是个很实用的甜点。
一致性过滤:丢掉一半数据换来质量
这一步在论文里只有一句话,但我觉得是 GenPRM 能用 23K 打过 344K 的核心。
QwQ-32B 在合成 rationale 之后,会输出一个 final label(-1 表示全对,否则是首个错误步的 index)。作者把这个 LLM-as-judge 的标签和 RPE 估出来的标签做交叉验证:只要有一步标签不一致,整条解决方案直接丢弃。这个过滤直接干掉了大约 51% 的数据。
剩下的就是"两套独立标签都同意"的高一致性子集——23K。我自己的判断是,这种 RPE × LLM-as-judge 的双源验证,比单纯靠 MC 估计或者单纯靠 LLM 评分都更鲁棒,因为前者抓的是"行为正确性",后者抓的是"逻辑正确性",两者交集才是真正可信的标签。
ProcessBench 主表:1.5B 打 GPT-4o,7B 打 72B
直接上数据。下面是论文 Table 1 的精简版(F1 score, ProcessBench 官方四子集):
| Model | # Train | GSM8K | MATH | Olympiad | Omni-MATH | Avg |
|---|---|---|---|---|---|---|
| GPT-4o-0806 | unk | 79.2 | 63.6 | 51.4 | 53.5 | 61.9 |
| o1-mini | unk | 93.2 | 88.9 | 87.2 | 82.4 | 87.9 |
| Skywork-PRM-1.5B | unk | 59.0 | 48.0 | 19.3 | 19.2 | 36.4 |
| GenPRM-1.5B (Pass@1) | 23K | 52.8 | 66.6 | 55.1 | 54.5 | 57.3 |
| GenPRM-1.5B (Maj@8) | 23K | 51.3 | 74.4 | 65.3 | 62.5 | 63.4 |
| Math-Shepherd-PRM-7B | 445K | 47.9 | 29.5 | 24.8 | 23.8 | 31.5 |
| Skywork-PRM-7B | unk | 70.8 | 53.6 | 22.9 | 21.0 | 42.1 |
| Qwen2.5-Math-PRM-7B | ~344K | 82.4 | 77.6 | 67.5 | 66.3 | 73.5 |
| Universal-PRM-7B | unk | 85.8 | 77.7 | 67.6 | 66.4 | 74.3 |
| Direct Generative PRM-7B | 23K | 63.9 | 65.8 | 54.5 | 55.9 | 60.0 |
| GenPRM-7B (Pass@1) | 23K | 78.7 | 80.3 | 72.2 | 69.8 | 75.2 |
| GenPRM-7B (Maj@8) | 23K | 81.0 | 85.7 | 78.4 | 76.8 | 80.5 |
| Qwen2.5-Math-PRM-72B | ~344K | 87.3 | 80.6 | 74.3 | 71.1 | 78.3 |
| GenPRM-32B (Pass@1) | 23K | 83.1 | 81.7 | 72.8 | 72.8 | 77.6 |
| GenPRM-32B (Maj@8) | 23K | 85.1 | 86.3 | 78.9 | 80.1 | 82.6 |
我把几个最戳眼的对比拎出来:
第一组对比:GenPRM-1.5B(Maj@8)63.4 vs GPT-4o 61.9。1.5B 的本地小模型把闭源旗舰打了。注意 GenPRM-1.5B 的 Pass@1 只有 57.3,单纯靠 8 路投票把它拔了 6 个 F1 点上去。这条事实意味着,测试时算力对 GenPRM 是真正可加和的——不像分类式 PRM 那样早早饱和。
第二组对比:GenPRM-7B(Maj@8)80.5 vs Qwen2.5-Math-PRM-72B 78.3。10 倍参数差被抹平。更让我 surprise 的是 GenPRM-7B 训练数据只有 23K,对手是 ~344K。这个性价比已经不在一个 league。
第三组对比:GenPRM-7B 80.3(MATH 子集 Pass@1)vs Direct Generative PRM-7B 65.8。这俩用同样的 23K 数据训,差别仅在前者带 CoT + Code,后者不带。差距 14.5 个 F1 点——rationale 不是包装,是结构性的能力来源。
第四组对比:GenPRM-32B(Maj@8)82.6——这是全表(除了 o1-mini 那种 RL 训出来的推理王)的天花板。32B 比 7B 高了 2 个点,回报率明显衰减。这个观察在论文 Table 8 里也印证:1.5B → 7B 是 +18 F1 点,7B → 32B 只剩 +2 点。7B 是 GenPRM 的甜点尺寸,做工程部署的人可以直接锚定这个 size。
我额外注意到的一个细节:GSM8K 子集
GenPRM-1.5B 在 GSM8K 上只有 52.8,比 Skywork-PRM-1.5B 的 59.0 还低。我反复看了几遍才理解:GSM8K 太简单,分类式 PRM 即使粗暴也够用;难题(MATH/Olympiad/Omni-MATH)才是 generative reasoning 的主场。论文里也有一句关键陈述:
我们也发现测试时算力扩展在更难的题目上带来的提升比简单题目大得多。
这跟我做实验的直觉完全一致——容易的题,PRM reasoning 的边际价值很低;难题里多一段 CoT 抓出错误的概率才会显著提升。所以 GenPRM 真正的应用场景是用来给奥赛级 / 研究级的难题做过程监督,不是给小学应用题打分。
Critic 模式:GenPRM 不只是验证者,还是迭代修订器
到目前为止说的都是 verifier 角色(多个候选解里挑一个)。GenPRM 真正惊艳的地方在 critic 角色:把它对每一步的 <analyze> 反馈直接喂给生成模型,让生成模型 refine 自己的解。
论文 Table 3 的核心数据(Avg 是 Gemma-3-12b-it 和 Qwen2.5-7B-Instruct 两个 generator 的平均):
| Critic | Turn 1 | Turn 2 | Turn 3 |
|---|---|---|---|
| Zero-shot | 45.7 | — | — |
| Generator self-refine | 46.3 | 46.0 | 46.1 |
| DeepSeek-R1-Distill-7B | 46.8 | 47.3 | 47.2 |
| GenPRM-7B | 49.8 | 50.7 | 51.5 |
几个观察:
Generator self-refine 完全无效。Turn 1 → Turn 3 准确率从 46.3 掉到 46.1,反而退步了。这是 self-refine 文献里被反复确认的现象——生成模型自己 critique 自己,倾向于一致地确认自己的错误。
DeepSeek-R1-Distill 略有提升但很快饱和。Turn 1 是 46.8,Turn 3 是 47.2,三轮总收益 0.4 个百分点。这个模型本身是强推理模型,但作为 critic 时缺乏对"哪一步具体错"的精准定位能力。
GenPRM-7B 单调提升 + 不饱和。45.7 → 49.8 → 50.7 → 51.5,每一轮都涨。Figure 1 (b) 那张折线图把这个差距画得非常醒目:到第三轮 GenPRM 比 DeepSeek-R1-Distill 高了 4.3 个百分点,提升幅度是 R1-Distill 的 3.4×。
为什么 GenPRM 能持续 refine? 我的理解是 <analyze> 标签里的内容天然就是"针对错误步骤的详细解释"——这种 step-localized 的反馈比通用的 self-critique 信息密度高得多。Generator 拿到 第 3 步的 a 系数算错了:应该是 (-3)² = 9 而不是 -9 这种具体反馈,比拿到 "请重新检查你的解答" 有用 10 倍。
推理组件消融:CoT 是主菜,Code 是调味
论文 Table 4 做了一个非常诚实的拆分实验:训练时是否带 CoT?是否带 Code?推理时是否启用?四种组合下的 ProcessBench Avg:
| Train CoT | Train Code | Infer CoT | Infer Code | Infer Exec | Avg |
|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | ✗ | ✗ | 60.0 |
| ✗ | ✓ | ✗ | ✓ | ✗ | 64.2 |
| ✗ | ✓ | ✗ | ✓ | ✓ | 69.6 |
| ✓ | ✗ | ✓ | ✗ | ✗ | 78.8 |
| ✓ | ✓ | ✓ | ✓ | ✗ | 79.9 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 80.5 |
我挑出三组对比来读:
只 CoT vs 只 Code:78.8 vs 64.2。CoT 比 Code 重要太多了(差了 14.6 个百分点)。这件事其实有点反直觉——很多人会觉得代码验证更"硬"、更可靠,但实际上 PRM 的判断力主要还是来自自然语言的细粒度 reasoning。代码只能验证"这一步算出来的数值对不对",但很多过程错误是逻辑层面的(用错了定理、漏了条件、变量替换错),代码无能为力。
Code 加上 Execution vs Code 不执行:69.6 vs 64.2。给代码一个真实的 [Code Output] 反馈,对模型用代码做判断的能力是有帮助的(+5.4 F1 点)。但你要意识到这个收益完全消化在了"只用 Code"这条线里——加上 CoT 之后,再加 Code Execution 只多 0.6 F1 点(79.9 → 80.5)。
完整版 vs 只 CoT:80.5 vs 78.8。代码 + 执行只贡献最后 1.7 个百分点。
这张表的诚实之处在于它告诉读者:如果你算力紧张,可以丢掉 code execution,只保留 CoT,性能损失非常有限。但如果你要做真正的难题(Olympiad 级),那 1.7 个点也很值得守住。
数据规模与模型规模的 scaling
论文 Table 8 / Table 9 给了两组朴素的 scaling 实验。我把它们合并解读:
模型 scaling(Pass@1 / Maj@8 ProcessBench Avg): - 1.5B:57.3 / 63.4 - 7B:75.2 / 80.5 - 32B:77.6 / 82.6
数据 scaling(GenPRM-7B Pass@1): - 25%(≈5.75K):71.7 - 50%(≈11.5K):74.5 - 100%(23K):75.2
两个 take-away: 1. 模型尺寸有断崖式甜点:1.5B 太弱,32B 边际衰减,7B 是工程上的最优解。 2. 数据 scaling 早期收益巨大:5.75K → 11.5K 涨 +2.8 F1,11.5K → 23K 只涨 +0.7 F1。这意味着如果你想自己复刻 GenPRM,10K 量级的高质量数据就能拿到大部分性能;继续往上加性价比低。
我的批判性观察是:作者没有给出 50K / 100K 数据规模下的曲线。所以"23K 是甜点"这个结论严格来说只在 [5.75K, 23K] 这个窗口被验证了。如果数据再往上 scale,可能会出现第二轮提升,也可能完全饱和。这是个 future work 的留白。
推理 token 成本:透明地告诉你这事不便宜
PRM 工程化最关心的就是 latency 和 cost。论文 Table 10 给了 GenPRM-7B 的输出 token 统计:
| Benchmark | Per Step | Per Response |
|---|---|---|
| MATH | 344.7 | 2771.4 |
| AMC23 | 416.2 | 3200.2 |
| AIME24 | 432.5 | 4112.9 |
| Minerva Math | 503.3 | 4877.1 |
这是 Pass@1 的数字。Maj@8 大约要乘以 8——也就是给一个 AIME24 题目的解答打分,要花 ~33K 输出 token。和分类式 PRM 那种"给每步出个 scalar"的开销根本不在一个量级。
这就是 GenPRM 的代价:性能上去了,inference cost 也跟着上去了。 论文也很坦诚地把这条放在 Limitation 里,并指出未来可以尝试动态剪枝 reasoning(参考 Dyve 那种 fast/slow 切换)。
我的实战建议是:生产环境用 GenPRM 当 verifier 时,给候选解的数量做严格上限(比如 BoN-8 而不是 BoN-32),把算力花在 critic refine 的迭代上而不是 verifier 的多采样上——后者是论文 Table 3 证明边际收益更高的方向。
我比较欣赏的几个细节
跑了几篇 PRM 论文之后,再读 GenPRM,有些工程化细节让我觉得这篇是在"真做事"而不是"水 paper":
第一,Step Forcing 的格式约束。Step 1: ... Step T: ... 这种朴素的 prefix 让步骤切分天然带语义,比 \n\n 切分干净太多。这种小 trick 是工程师视角才会想到的。
第二,QwQ-32B 在数据合成时的 self-reflection 行为。当 CoT 推理结论和代码运行结果冲突时,模型会自动反思直到一致——这件事相当于把"反思"作为一个免费的训练信号灌进了 GenPRM。这个设计很优雅。
第三,把 critic 的 <analyze> 内容作为 step-localized feedback 喂给 generator——而不是把整个 GenPRM 输出(包括 code 和 verification)都塞回去。论文实现细节里特别提到:critique refine 时只提取 <analyze> 标签内容,且只关注被 PRM 标为负的步骤。这是非常克制的工程选择,避免了上下文爆炸。
第四,epsilon = 0.8这个看似随手的超参其实经过精细的消融搜索:[0.1, 0.5, 0.8, 1.0] 四档里只有 0.8 拿到最优;0.1(接近 hard label)和 1.0(严格 progress)都退化得很明显。说明作者真的把这个超参当成一个关键设计而不是随便填的。
我的批判性笔记
写到这里我必须强行抑制一下夸赞。一篇论文从研究员视角看,必须能回答这样几个问题:方法是否唯一?泛化是否真实?工程是否可控?
第一,"23K 数据训出 SOTA"的故事是否过度浪漫了? 作者反复强调"仅用 23K 数据",但读者要看清楚:这 23K 是在 7.5K 道 MATH 题上经过 RPE × LLM-as-judge 双过滤、丢弃 51% 噪声后挑出来的。真实的训练成本 = 7.5K 道题 × 平均 50+ 条采样路径 × QwQ-32B 推理 × 代码执行。光说"23K 数据"会让人误以为这是个轻量级方法,实际上数据合成阶段的算力消耗一点也不轻。
第二,纯数学场景之外的泛化是个未知数。 这点作者在 Limitation 里也坦率承认。GenPRM 完全在 MATH 上训练,所有 evaluation 都在 GSM8K / MATH / Olympiad / Omni-MATH / AMC / AIME / Minerva 上做——全是数学。它能不能迁移到代码、医疗、agentic 任务?论文没有给任何证据。从 Math-Shepherd 等前人工作的经验看,纯数学训出来的 PRM 跨域到代码确实有泛化(可以参考 PRM Generalization (arXiv 2506.00027) 的研究),但 GenPRM 这种带 code execution 的形态会不会让代码域的 inductive bias 反而变成劣势,仍然是开放问题。
第三,code execution 的安全性和可控性。 论文里 QwQ-32B 合成的 Python 代码会被自动执行。作者没说怎么处理 sandbox、超时、依赖管理这些工程问题。如果代码出现 import os; os.system("...") 之类的恶意调用怎么办?数据合成阶段还可以容忍,但部署阶段如果让 GenPRM 在生产环境执行用户输入触发的代码,风险点很多。这是工程化时必须重做的安全层。
第四,inference 成本对实际部署是劝退级的。 Maj@8 在 AIME24 单题需要 33K 输出 token——按 GPT-4o 类商业 API 的定价折算,单次评分接近 0.5 美元。如果你拿它做 BoN-32 验证,等于一道题的评估成本比题目本身的解答成本还高。GenPRM 在学术 benchmark 上是 SOTA,但在工业场景里,相比直接用 GPT-4o 当 critic 是否有 ROI 优势,需要看具体场景。
第五,QwQ-32B 这个数据合成依赖太重。 整个 pipeline 里 rationale 全靠 QwQ-32B 生成。如果你要复刻这套方法,你需要先有一个推理能力极强的 32B 模型来做老师。这等于把"训 PRM"变成了"先要有强 reasoning 模型"——某种意义上是 distillation 的变种。这个路径不是任何团队都能复现的。
我会怎么用 GenPRM:工程 takeaway
如果让我把这篇论文落地到一个实际项目里,我会按如下顺序:
Step 1:先评估自己是否真的需要 generative PRM。如果你的任务是 GSM8K 这种简单题,分类式 PRM 已经够好;如果你做的是奥赛级、长 reasoning chain 的题,GenPRM 的优势才显现。先看 Pass@1 的天花板再决定。
Step 2:复用 23K 训练数据。作者已经开源了模型和数据(ryanliu112.github.io/GenPRM),如果你不需要特别定制,直接拿 GenPRM-7B 当 verifier 用就好,省掉数据合成的算力。
Step 3:如果要训自己的版本,关键是把 RPE 和 consensus filtering 这两步做好。其他步骤可以参考论文的实现,但 RPE 阈值(0.8)和 LLM-as-judge 一致性过滤(51% 丢弃率)这两个数字是这篇 paper 跑实验调出来的甜点,不要轻易动。
Step 4:部署时只保留 CoT 不保留 Code,性能损失 ~1.7 F1 点,但 inference 速度能快 2-3 倍(不用执行代码、不用等 stdout)。Critic 模式比 Verifier 模式更划算:三轮 refine 的提升幅度(+5.8 平均 acc)比 BoN-8(典型 +3 到 +5 acc)更可观。
Step 5:如果跨域应用(比如做 coding agent 的 step verifier),先在你自己的目标域 benchmark 上跑一下 zero-shot GenPRM,再决定是否需要继续训练或者 finetune。论文没有跨域证据,所以这块要自己摸。
我的总结
我喜欢 GenPRM 的一个原因是它把"PRM 应该长什么样"这个问题重新打开了。它没有在分类式 PRM 上做小修小补,而是直接换了范式——让阅卷模型像考生一样写草稿、跑代码、然后再下结论。这种范式让"reasoning model"的概念第一次延伸到了过程监督这个原本被认为只能用 scalar 解决的领域。
但我也清楚地看到,这篇 paper 的工业落地路径还很远:算力消耗、跨域泛化、code execution 的安全性,这三件事没有一件是可以靠"加更多 GPU"解决的。它的真正价值更多在科研层面——让我们认识到 PRM 不是非要做成黑盒打分器,给 PRM 解锁测试时算力的红利之后,验证者的能力上限被实质性地推高了。
回到 AAAI 2026 这个语境。我个人把它放在"PRM/RL 子方向必读 top-3"的位置,和数学训 PRM 跨代码域泛化研究(arXiv 2506.00027)、UnPRM(arXiv 2508.01773)这两篇放在一起读最有收获——前者告诉你 PRM 的训练数据多样性怎么设计,后者告诉你怎么把 uncertainty 当训练信号,GenPRM 告诉你 PRM 的输出形态可以被彻底重新定义。三篇组合起来,几乎覆盖了 PRM 工程化的全部关键决策点。
下一篇我们去看 Latent Reasoning Refinement (arXiv 2506.08552)——它走的是另一个路线:不让 PRM 显式输出 reasoning,而是在 latent 空间做精修。两条路线对照着读,能看清楚"显式 reasoning vs 隐式 reasoning"在 PRM/refine 这个赛道上的张力。