一个 query 写五份草稿、互评后再选最好的那一条去更新——DRAFT-RL 把 RL 训练里的"独白"改成了"群聊"
核心摘要
做过反思式 RL 调模型的人,多半对一个画面不陌生:模型给出一份 trajectory,另一个 critic 模型说一句"你这步不对",再让本体改一遍——听上去很像人类的反思流程,但训练曲线告诉你,单条响应的反思空间太窄了,一旦初始那条路走偏,后面的"修补"很难把它扳回来。这篇 AAAI 2026 论文 DRAFT-RL(来自 BUPT / HKUST(GZ) / Bristol)把套路换了一下:每个 Agent 一次性产 K=5 份短草稿(每步 ≤5 词,借用 Chain-of-Draft 的写法),然后 N=3 个 Agent 互相打分,再用学出来的 reward model 把"最有戏的那一条"挑出来,喂给 PPO + imitation learning。结果是 MATH 上 +3.7%、HumanEval 上 +3.1%、HotpotQA F1 +3.1%,关键是收敛步数少了 33–42 个百分点——单看绝对涨幅不算炸裂,但"省训练步"这件事在 RL 里几乎是真金白银。
定位:不是新算法,更像是一套多路径并行 + 同伴互评的 RL 训练外壳。idea 很自然——CoT/CoD 走了那么久 inference-time 路径多样化,DRAFT-RL 把它搬进了 training loop 而已——但工程价值实打实,尤其是收敛速度那张图,是这篇文章最值钱的一页。
论文信息
| 项目 | 内容 |
|---|---|
| 标题 | DRAFT-RL: Multi-Agent Chain-of-Draft Reasoning for Reinforcement Learning-Enhanced LLMs |
| 作者 | Yuanhao Li, Mingshan Liu, Hongbo Wang, Yiding Zhang, Yifei Ma, Wei Tan |
| 机构 | 北京邮电大学(BUPT)、香港科技大学(广州)、布里斯托大学 |
| 发表 | AAAI 2026(预印本 2025 年 11 月 25 日提交 arXiv) |
| arXiv | https://arxiv.org/abs/2511.20468v1 |
🎯 一个让我皱眉的训练日志
先说个真实场景。RL 训 LLM 推理任务时,标配套路是这样的:rollout 一条 trajectory → 跑 reward → PPO 更新。后来大家觉得"一条 trajectory 太单薄",于是就有了 Reflexion、ChatEval 这类反思式框架——让 critic 模型评估一下,agent 再修一版,再评估,再修。听起来很优雅。
但一旦你把训练曲线打开看,就会发现一个尴尬:反思的范围被绑在了那条初始路径上。如果第一份 response 在大方向上就走偏了(比如 MATH 题里选错了一类解法),后续的"自我反思"很难从根上把它扭回来——绝大多数 critic 反馈都是局部的微调建议,不会让模型重启一条完全不同的思路。
说实话,我之前在做类似的工作时也碰到过这个问题。reward 在涨,但生成多样性肉眼可见在塌缩——模型越学越保守,不愿意走任何"不熟悉但可能更好"的解法路径。这是单 trajectory RL 的老毛病了,加 KL 约束、加 entropy bonus 都只能缓解,不能根治。
DRAFT-RL 的切入点就是这里:别在一条线上反思了,一开始就并行铺多条,让多样性进 RL 的 loss,而不只是 inference 时的 trick。
📖 三个核心问题,DRAFT-RL 想一起解决
把论文 Introduction 里列的痛点翻译成工程语言:
- 决策不稳定 —— LLM 在不熟悉场景下随机性大,单次采样容易跑偏;
- 探索不充分 —— 标准 RL 一个 state 一个 action,alternative path 直接被丢掉;
- 训练慢 —— RL on LLM 本来就贵,每步 rollout 都是真金白银的算力;
- 难以自纠 —— 错误一旦写进 trajectory,单 agent 很难发现自己错在哪。
以上四条,前两条是同一类问题(单路径),后两条是另一类(信用分配 + 自检)。DRAFT-RL 的设计正好对应:multi-draft 解前两条,peer evaluation 解后两条,再用 reward-aligned selection 把它们串起来。
🏗️ 方法:Multi-Draft → Peer-Eval → Reward-Aligned Selection
整个框架其实可以用一句话讲清楚:
每个 Agent 对同一个 query 写 K 份短草稿;其他 Agent 对每份草稿打分;reward model 把所有信号合成一个 reward,挑出最优那一条;用这条最优草稿做 PPO + imitation。
下面拆开讲。
1. Multi-Draft Generation:一份 query,五份草稿
每个 Agent \(A_i\) 给 query \(q\) 生成 \(K=5\) 份草稿 \(\{d_i^1, \ldots, d_i^K\}\)。三个细节让多样性不流于形式:
- 温度梯度:5 份草稿的 sampling temperature 从 0.2 到 0.8 阶梯分布——低温拿稳的,高温拿野的;
- 策略性 prompt:第 k 份草稿被显式提示"试一种和前面不同的思路";
- 历史条件:第 k 份草稿的 context 里塞进前 k-1 份的摘要,让模型主动绕开已有路径。
每份草稿都是 Chain-of-Draft 风格——也就是每个 reasoning step 限制在 ≤5 个单词。这点看似过于苛刻,但实际效果是让步骤可比、可评分:5 个词的步骤,peer agent 一眼就能判断它在做什么、对不对。这和 verbose CoT "让模型自由发挥写一段" 是两个味道——CoD 把推理步压成"打卡式"的小颗粒,方便结构化处理。
2. Peer-Guided Evaluation:互评机制
K=5 份草稿出来后,由其他 Agent(即 \(A_{j \neq i}\))对它们打分。打分维度有五个:reasoning coherence、step validity、relevance、completeness、answer correctness。每个 peer 给出一个 [0, 1] 区间的 scalar 评分 \(s_j(d_i^k)\) 加一段定性反馈 \(f_j(d_i^k)\)。
这一步的关键是 cross-checking——一个 Agent 自己看自己写的草稿,倾向于自圆其说;让别的 Agent 来看,反而更容易揪出"步骤跳跃"、"假设没说清"、"答案和过程对不上"这些问题。论文的人评结果(Table 6)也佐证了这点:DRAFT-RL 在 Clarity 和 Correctness 维度的得分都比 Reflexion 和 RLAIF 高出 0.3–0.4 分(5 分制)。
3. Reward-Aligned Selection:reward model 做最终裁判
光靠 peer 打分还不够——peer 也是 LLM,会有偏见。所以训练一个独立的 reward model \(R_\phi\)(12 层 transformer,100M 参数,按域分别训),把 peer scores 和 task-specific 信号(执行结果、ground truth match 等)综合一下:
每个 query 选出 reward 最高的那条 \(d^*\),喂给 PPO 做策略更新,同时用 imitation learning 让 actor 直接模仿 \(d^*\):
PPO 部分负责"探索 + 优势归因",imitation 部分负责"加速收敛、防止 PPO 在多模态 reward 下震荡"——这套 PPO + behavior cloning 混合的写法,在 RLAIF 后期工作里也能见到,本身不算新,但和多草稿选择配合起来就有意思了:imitation 的 target 不是固定的 expert demo,而是当前批次里被 reward model 选出来的最优草稿——相当于一个动态的、自我演化的 expert pool。
🧪 实验:三个域、九个 baseline、五个种子
实验设置
骨干都是 Claude-3.5-Sonnet + 130M LoRA adapter,3 个 Agent(每个独立 adapter),K=5。reward model 12 层 transformer 100M 参数。训练在 64×A100 上跑了 125k GPU-hours——这是 RL 训练里中等偏上的预算。
baseline 选得挺扎实,分三档:
- Prompting:CoT、CoD、Self-Consistency
- Framework:ReAct、Reflexion、ChatEval
- RL:RLHF、RLAIF
三个域:Code(MBPP / HumanEval)、Math(GSM8K / MATH)、QA(HotpotQA / MMLU)。
主结果(Code 合成)
| 方法 | MBPP | HumanEval | Complexity | Time(s) |
|---|---|---|---|---|
| CoT | 68.2 | 74.4 | 2.3 | 12.4 |
| CoD | 71.5 | 77.8 | 2.7 | 8.9 |
| Self-Consistency | 70.1 | 76.2 | 2.4 | 15.6 |
| ReAct | 69.8 | 75.1 | 2.5 | 18.7 |
| Reflexion | 73.4 | 79.2 | 2.8 | 22.3 |
| ChatEval | 75.9 | 81.2 | 3.1 | 25.1 |
| RLHF | 76.8 | 82.7 | 3.0 | 16.2 |
| RLAIF | 78.1 | 84.5 | 3.2 | 14.8 |
| DRAFT-RL | 82.6 | 87.6 | 3.6 | 19.4 |
MBPP +4.5、HumanEval +3.1,这个幅度在已经 80%+ 的高位上拿到,是真的能打。要注意的是:DRAFT-RL 的 Time(s) 是 19.4 秒,比 ChatEval 的 25.1 秒还快——这有点出乎意料,毕竟 5 份草稿听起来应该比单条 trajectory 慢得多。看到这里我愣了一下,仔细想了想:Multi-Draft 是并行采的,墙上时间不是 5 倍,而是 1 倍多一点,加上 CoD 把每步压到 5 词、单步本身更短,综合下来反而比 ChatEval 那种串行多轮反思更快。
主结果(数学推理)
| 方法 | GSM8K | MATH | Algebra | Geometry | Calculus |
|---|---|---|---|---|---|
| CoD | 87.1 | 45.9 | 54.8 | 41.7 | 39.2 |
| ChatEval | 89.7 | 49.2 | 58.4 | 45.1 | 43.8 |
| RLHF | 90.3 | 50.6 | 59.7 | 46.3 | 45.1 |
| RLAIF | 91.8 | 52.1 | 61.2 | 47.8 | 46.9 |
| DRAFT-RL | 94.2 | 55.8 | 65.1 | 51.4 | 50.3 |
MATH 上 +3.7、Algebra +3.9、Geometry +3.6——这几个细分领域恰恰是需要结构化符号操作的,多草稿带来的"试不同解法"价值最大。
主结果(QA)
| 方法 | EM | F1 | MMLU-0S | MMLU-5S | 平均 hops |
|---|---|---|---|---|---|
| RLAIF | 76.7 | 87.4 | 79.2 | 81.5 | 2.9 |
| DRAFT-RL | 79.1 | 90.5 | 82.4 | 84.7 | 3.2 |
HotpotQA F1 +3.1,平均检索 hops 从 2.9 涨到 3.2——这个数其实挺有意思:DRAFT-RL 不只是答得更准,检索链更深。说明它真的在做 multi-hop 推理,而不是靠"更精准的单跳"刷分。
训练动力学(这才是真正的卖点)
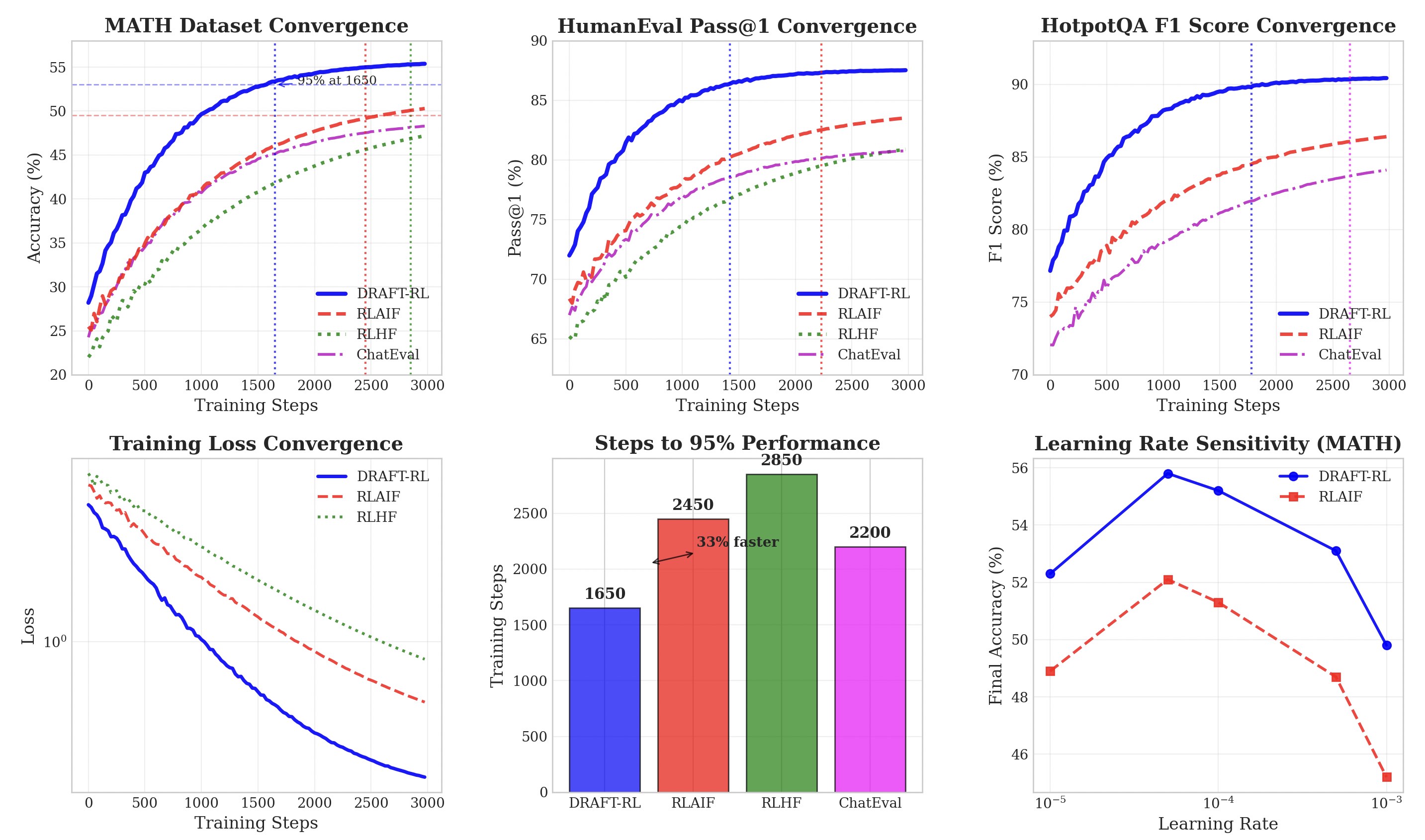
图1:论文唯一的训练曲线图。左上、中上、右上分别是 MATH / HumanEval / HotpotQA 的收敛曲线——DRAFT-RL(蓝色)在 1500–2000 步附近就到达 RLAIF(红色虚线)2500+ 步才到的水平。左下是 training loss,DRAFT-RL 下降明显更陡。中下是"达到 95% 性能的训练步数"柱状图:1650 vs 2450(RLAIF)vs 2850(RLHF),DRAFT-RL 比 RLHF 少了 33%。右下是学习率敏感性——DRAFT-RL 在 LR 选择上比 RLAIF 鲁棒得多,5e-5 附近有明显平台。
我一开始看主表的 +3.7% 没特别激动,毕竟这个量级的提升在 LLM RL 这个圈子里只能算中规中矩。真正让我觉得这篇论文有产业价值的是这张训练曲线图:MATH 上 RLAIF 跑了 2850 步才到 95% 最优,DRAFT-RL 1650 步就到了——42 个百分点的 GPU 时间被省下来。在 64×A100 上,这意味着每个 epoch 省下来都是真金白银。如果你算过自己 RL 训练的电费,就懂这个数的分量。
消融实验
| 配置 | HumanEval | MATH | Hotpot-F1 | MMLU |
|---|---|---|---|---|
| 完整模型 | 87.6 | 55.8 | 90.5 | 82.4 |
| w/o Drafts(去掉多草稿) | 80.5 | 48.7 | 84.2 | 76.8 |
| w/o Peer Eval | 83.8 | 51.3 | 87.1 | 79.2 |
| w/o CoD | 82.4 | 49.6 | 85.8 | 78.5 |
| w/o Reward Model | 84.1 | 52.2 | 88.3 | 80.1 |
| w/o RL Training | 81.7 | 50.4 | 86.4 | 77.9 |
去掉 multi-draft 是损失最大的(–7.1 在 MATH 上)——这等于说"DRAFT-RL 的核心就是多草稿"。其他三个组件去掉后掉得相对温和(–2 到 –4),属于互相可补偿的范畴。这个消融结果说服力很强:真正撑起这套框架的是路径多样性,peer eval 和 reward model 是放大器。
K 与 Agent 数量的甜蜜点
| K | MATH | HumanEval | Time | Diversity |
|---|---|---|---|---|
| 1 | 50.4 | 80.5 | 8.2 | 0.00 |
| 3 | 53.7 | 85.1 | 14.6 | 0.34 |
| 5 | 55.8 | 87.6 | 19.4 | 0.44 |
| 7 | 55.9 | 87.4 | 26.8 | 0.51 |
| 10 | 55.6 | 87.1 | 38.5 | 0.58 |
K=5 是明显的拐点——再加草稿,性能不涨反而轻微下降,但时间继续线性涨。Agent 数量也是 3 最优(4 个开始内卷,agreement 掉到 0.58)。
🤔 批判性笔记
写到这里得说几句实话。
第一,"首个集成 CoD + 多 Agent RL"这种 framing 我是有点保留的。 Tree-of-Thoughts、Graph-of-Thoughts 早就在 inference time 做多路径探索了,把它们的搜索范式搬进训练 loop 这事,从概念上没那么 novel。DRAFT-RL 真正的新东西是 CoD 约束 + peer-as-judge——每步 ≤5 词的硬约束让 peer 评分的方差大幅下降,这才是让 reward model 学得动的前提。但论文 abstract 里"first to integrate"的说法,对同期工业界的工作(比如某些 self-play / self-consistency RL 变体)讲得不够公平。
第二,3.7% on MATH 听起来不大,但读训练动力学才知道值多少。 我前面也吐槽过涨幅一般,但回过头看,训练步数省下三到四成 这个数是 RLHF/RLAIF 圈里少见的——它意味着同样的 GPU 预算下,你可以做更多 ablation、跑更多 seed、试更多 reward 配方。这才是工业落地真正在意的指标。论文把它放在 Section 5.4 而不是 abstract 里,说实话有点埋没。
第三,骨干用 Claude-3.5-Sonnet,base 已经很强。 这意味着 DRAFT-RL 的提升是建立在"已经接近上限的模型还能再涨 3-4%"的基础上——这种场景下小幅提升的"含金量"比在 7B 模型上涨 10% 更扎实。但同时也带来另一个问题:对小模型是否同样有效? 论文没有报小模型 ablation,K=5 的多草稿对 7B 级别的模型是否会因为初始多样性不足而退化成 K=1,这是个开放问题。
第四,reward model 跨域共享了多少? 论文说"per domain trained",意味着 Code、Math、QA 各训了一个 reward model。但 Section 5.6 的 cross-domain transfer 又显示 Math→Code 能涨 5.8%——这两件事之间到底是 reward model 的功劳还是 actor 自身的泛化?论文没说清。
第五,125k GPU-hours 在 64×A100 上跑——单算 A100 SXM 时租费用,这是个不便宜的训练。 普通团队复现门槛偏高。如果有人想先在小规模上验证 idea,建议直接抓 K=3、3 Agent、单域试一下,能否看出 +2% 量级的趋势——如果看不到,多半就是 base model 不够强或者 peer 评分质量不够稳。
💡 工程上能借鉴什么
如果你正在做 RL on LLM 的训练,DRAFT-RL 至少提供了三个可以直接试的点子:
- K=5 的多草稿采样喂 PPO:哪怕不做 peer evaluation,单纯把"每个 query 采 5 条 trajectory,挑 reward 最高那条做 PG 更新"作为一个改动加进去,应该就能拿到一部分收益——这是最低成本的一步。
- CoD 约束做 reward 信号:不是说生成全部用 CoD,而是把 ≤5 词的步骤限制作为评分时的对齐口径——让 peer 评分稳一点。
- PPO + imitation 的 0.5 权重混合:这个细节在 RLAIF / RLHF 里其实很多团队默默在用,但 DRAFT-RL 给出了一个明确的 ablation 数字(去掉 imitation 跌 ~3 点)支撑。
如果你本来就在做 multi-agent debate 这一类工作,可以反过来问一句:为什么我的 debate 框架只做 inference 不做 training? DRAFT-RL 用 RL 把 debate 的优势"沉淀"到模型权重里,这个思路值得抄。
🔬 几个开放问题
草稿之间的 dependency 是真随机还是被 prompting 强行引导的? 论文用 temperature [0.2, 0.8] + 策略性 prompt 来制造多样性,但这种"靠 prompt 营造的多样性"在长期训练中会不会塌缩?没有给出长期跟踪曲线。
peer evaluation 的"能力上限"问题。 三个 Agent 都来自同一个 base(Claude-3.5),peer 评分的天花板就是这个 base 模型的能力。如果某道题三个 Agent 都不会,peer 互评会陷入"互相点头说对"的盲区——论文 Table E(zero-shot 泛化)里复杂任务上的提升只有 +5.6(从 54.1 到 59.7),可能就是这个 ceiling 在起作用。
reward model 的脱靶风险。 RM 用的是 peer 评分 + task reward 合成的标签。但 peer 评分本身有偏,task reward 又稀疏(特别是 QA 任务),合成的标签信噪比是个问号。论文 Table C 里 reward 的 r=0.89 with peer eval 听上去高,但和真正 ground truth 的 correlation 没给。
📚 收尾
这篇论文我会把它归类成在反思式 RL 路线上做了一次很扎实的工程整合:concept 不算颠覆,但把 multi-draft、peer eval、reward-aligned selection 三件事放进同一套训练 loop 里调到能跑,并且给出明确的训练步数收益——这种活儿是能落地的。
如果你只关心一件事:RL 训练步数减少了三到四成,这是 DRAFT-RL 的真正卖点,比那个 +3.7% 的精度提升更值得记住。
参考链接
- arXiv:https://arxiv.org/abs/2511.20468v1
- Chain-of-Draft 原文:Xu et al., 2025
- 相关基线:RLAIF (Lee et al., 2023)、Reflexion (Shinn et al., 2023)、ChatEval (Chan et al., 2023)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我