DEPO:把"少 token + 少步骤"同时塞进 KTO 的偏好优化
论文:DEPO: Dual-Efficiency Preference Optimization for LLM Agents arXiv: 2511.15392v1(2025-11-19)|AAAI 2026 接收 作者:Sirui Chen, Mengshi Zhao, Lei Xu, Yuying Zhao, Beier Zhu, Hanwang Zhang, Shengjie Zhao, Chaochao Lu 项目主页:https://opencausalab.github.io/DEPO
我为什么把这篇放进 AAAI 2026 推荐清单
读这篇之前,我已经连看了几篇 efficient-reasoning 方向的论文——基本上都在做一件事:减少 LLM 一次回答里生成的 token。问题是这种"一次回答省 token"的视角对智能体场景不够用。智能体每一步都要调外部 API、和环境交互一次,端到端的延迟和成本不只看每步多长,还看你跑了多少步。我在自己跑 ReAct agent 的时候踩过这个坑——某个版本每步从 800 token 砍到 300 token,单看似乎效率提升 60%,但实际任务 latency 几乎没变,因为模型变笨之后步数从 6 步涨到了 14 步,整条轨迹的总 token 反而多了。
DEPO 这篇就是把这个直觉显式化:他们提出 dual-efficiency,把智能体效率拆成两个正交维度——step-level 的"每步多少 token"和 trajectory-level 的"全程多少步",然后构造了一个非常工程化的 KTO 扩展把两者一起优化。我读完的整体感受是:这是一篇定义比方法更值钱的论文——dual-efficiency 这个拆分一旦被业界接受,后面所有 agent 评测都会带这两个轴,目前的 step 数 / token 数单独看的做法会逐渐被淘汰。
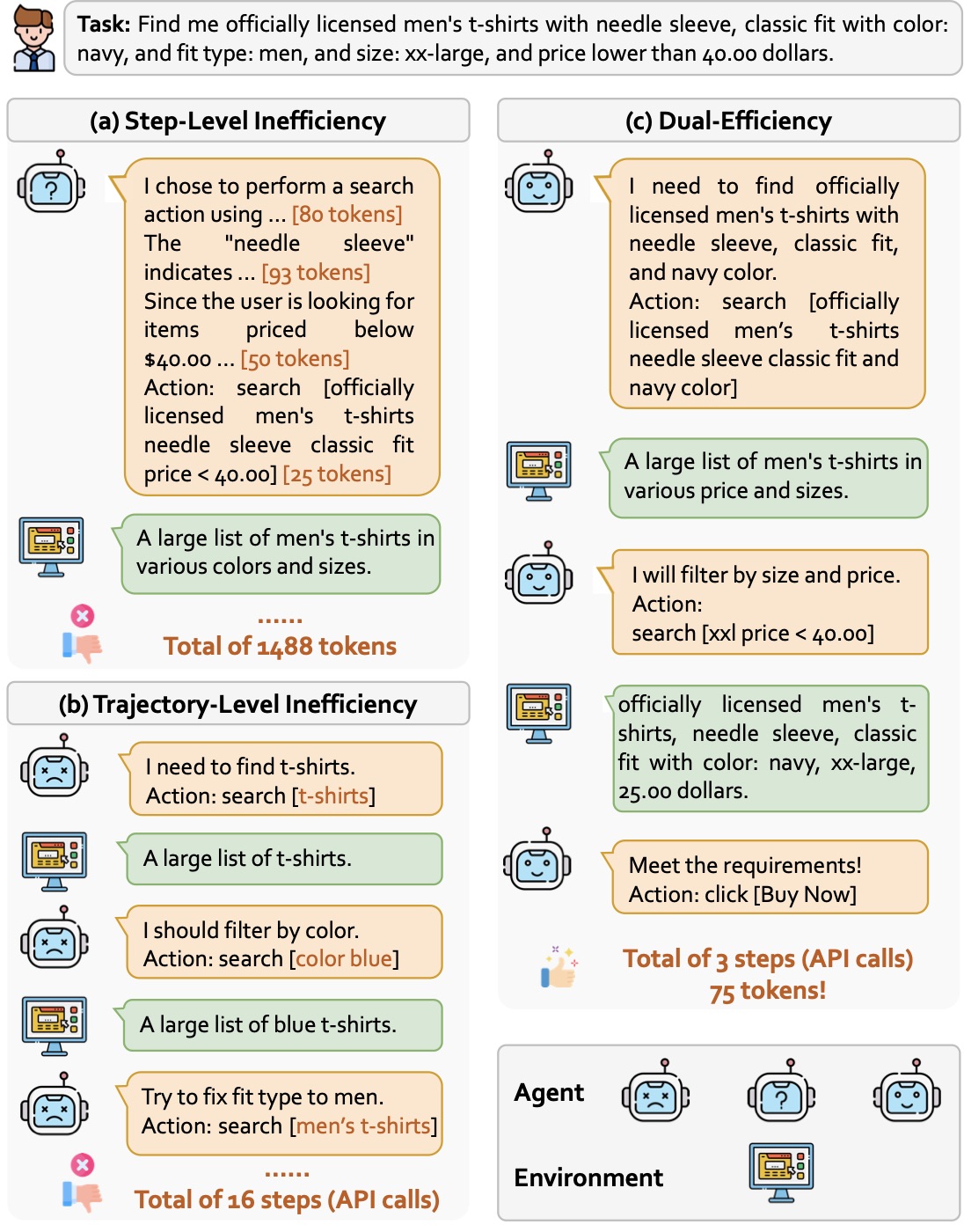
上面这张图用三个子图把概念讲得非常直观:(a) 每步话太多但步数合理(典型 R1-Distill 的 overthinking 模式),(b) 每步很简洁但总步数多(reasoning 不到位反复试错),(c) DEPO 想要的状态——每步简洁 + 总步数少。
一、问题定义:dual-efficiency 凭什么是两个维度
我得先承认一件事:很多论文里的"我们提出 XX 概念"读起来都像装样子。但 DEPO 这个 dual-efficiency 不是装样子——作者用 POMDP 的标准设定把任务建模成 \((\mathcal{S}, \mathcal{A}, \mathcal{O}, \mathcal{T}, \mathcal{R})\),然后明确指出智能体的成本来自两个独立来源:
- token 成本:LLM forward 一次的 GPU 时间和 KV cache,这取决于每步生成的 token 数 \(\overline{T}_{\text{token}}(\tau)\)
- interaction 成本:每一步 agent 要调环境(WebShop 的页面查询 / BabyAI 的 grid 动作 / 任何真实场景的 API),这取决于 \(T_{\text{step}}(\tau)\)
这两个成本不可互换:少 token 不一定少步数,少步数不一定少 token。所以效率这件事天然是两个维度的,不能只盯着一个砍。论文的目标函数因此被写成:
约束只施加在成功的轨迹上——这一点我特别赞同。让模型在难题上保留必要的长链推理,在简单题上学会快速结束,这才是工程上想要的。不分难易一刀切的 length penalty 是过去 efficient-reasoning 一系列工作的常见缺陷。
二、方法:把 efficiency bonus 直接塞进 KTO 的 implied reward
DEPO 的核心方法只有一个公式,但写得很优雅。先回顾 vanilla KTO 的 implied reward:
KTO 用这个 reward 配 sigmoid 偏好损失。DEPO 做的事就是在 reward 上加一个 efficiency bonus:
这个设计有几个我觉得很聪明的点。
第一,bonus 的形式是反比例 \(\alpha / T\)。这不是凭空选的——反比例函数有"边际递减"的特性:当 \(T\) 已经很小时,bonus 增加变缓,避免模型在已经够短的回答上继续疯狂砍 token;当 \(T\) 还很大时,bonus 增加陡峭,强力推动模型缩短长回答。这种凸函数形式比 \(\alpha \cdot e^{-T}\) 或 \(\alpha \cdot (1-T/T_{\max})\) 都更稳健。
第二,bonus 只加在 desirable 上。这看起来不对称——为什么不在 undesirable 那边加 penalty?后面消融实验给了答案:双向施加反而会让模型过度紧张,token 用量在某些场景反而上升近一半。我想这是因为单边奖励让"好样本变得更好"是稳定的,双边操作让 desirable 和 undesirable 的边界扩大太快、训练 dynamics 不可控。这个发现挺反直觉的,值得记一下。
第三,bonus 是 parameter-independent 的常数偏移,不参与梯度计算。这意味着它只影响 sigmoid 偏好损失里的 margin,不会让 reward 和参数耦合得太紧。从工程角度看,这种"加性 offset"的实现方式让 DEPO 能直接复用任何 KTO 训练框架——把 reward function 修改一行就行,没有架构侵入。
数据怎么造:MCTS 加上双层标签 + rephrasing
光有训练目标不够,desirable / undesirable 数据从哪来?DEPO 用 MCTS 滚出大量轨迹,然后按两个维度打标签:
- 奖励阈值:\(r(\tau) \geq \kappa_0\) 的进 desirable,\(\kappa_2 \leq r(\tau) < \kappa_1\) 的进 undesirable,中间的扔掉(保证 margin)
- 步数阈值:步数 < 7 的进 desirable,\(\geq\) 7 的进 undesirable
更狠的是,desirable 轨迹还要过一遍 GPT-4.1 mini 做 rephrasing——只改 Thought 部分让它更简洁,Action 不动,并且 rephrase 后的 token 数严格少于 rephrase 前。我读到这里第一反应是"这不是相当于在用 GPT 的偏好做 distillation 吗",但仔细想想这是必要的:MCTS 滚出来的原始轨迹自然语言部分质量参差不齐,不做归一化的话 efficiency bonus 会被随机噪声污染。这个 rephrasing 步骤其实把 dataset quality 这件事规范成了"在保留语义和成功率的前提下做最大压缩",是个干净的设计。
最后训练流程是经典两段式:先 BC(只用 desirable 子集做 SFT),再 DEPO 做偏好对齐。BC 阶段提供"基础动作语法",DEPO 阶段把 efficiency 偏好打进去。
三、主实验:60.9% token 节省 + 29.3% 性能提升的双赢
WebShop + BabyAI 两个环境的主表是这篇论文最有说服力的部分。我把核心数字摘出来:
| Backbone | 设置 | Succ. ↑ | T@All ↓ | S@All ↓ |
|---|---|---|---|---|
| Llama-3.1-8B | BC 基线 | 0.48 | 1851 | 14.85 |
| Llama-3.1-8B | + KTO | 0.48 | 887 | 8.87 |
| Llama-3.1-8B | DEPO(本文) | 0.50 | 726 | 7.73 |
| Qwen2.5-7B | BC 基线 | 0.43 | 2068 | 14.94 |
| Qwen2.5-7B | + KTO | 0.43 | 942 | 11.71 |
| Qwen2.5-7B | DEPO(本文) | 0.56 | 893 | 16.67 |
(数字基于 WebShop + BabyAI 的混合表现,原文 Table 1 完整有 12 列)
关键观察:
- DEPO 比 KTO 在 token 上再降 18.4%(Llama)/ 18.1%(Qwen)——这意味着 DEPO 不只是"BC + KTO 的简单叠加",efficiency bonus 确实带来了独立的优化方向。
- Qwen-7B 上 DEPO 把 Succ. 从 0.43 拉到 0.56,相对提升约 29 个点。这说明 efficiency 和 performance 在这里并不冲突,反而存在协同——可能是因为短回答更聚焦、长回答容易跑偏。
- DeepSeek-V3 在 WebShop 的 Succ. 只有 0.11,T@All 高达 6769。一个 671B 的 MoE 在 WebShop 上被一个 8B 的 BC + DEPO 压制到这种程度——再次印证 agent 任务里 alignment 比 raw capability 重要。
- R1-Distill 系列(Qwen-7B / Llama-8B)的 Succ. 都是 0 或 0.02。这是 dramatic 的反例——蒸馏出来的"reasoning"模型在 ReAct 任务上完全不能用,反复 overthinking 直到撞步数上限。这是支持 dual-efficiency 概念最有力的证据:你不能假装 step-level efficient(短回答)就够了。
四、泛化能力:在数学题上同样省 token 不掉点
DEPO 训练时只用了 WebShop + BabyAI 数据,但作者把训完的模型直接搬去 GSM8K / MATH / SimulEq 三个数学基准上测——结果出乎意料地好。
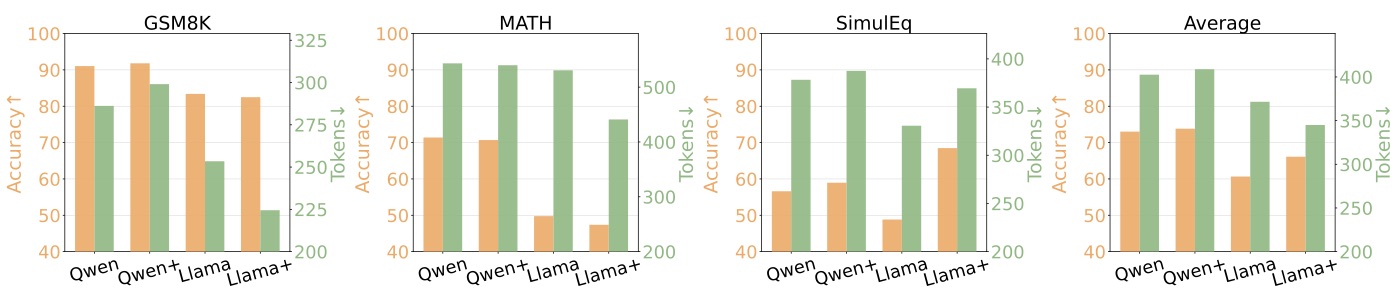
四个子图(GSM8K / MATH / SimulEq / Average)显示:
- Llama-3.1-8B + DEPO 在 SimulEq 上 accuracy 从 19.9 提到 28.8(+8.9 个绝对点),平均 token 从 537 降到 354
- Qwen2.5-7B + DEPO 在 SimulEq 上 accuracy 从 30.7 提到 34.4,但平均 token 反而略涨
这个跨域泛化的结果让我有点意外,也有点存疑。WebShop 和 GSM8K 的任务结构差异巨大——一个是带页面观察的多步交互、另一个是单步数学推理。DEPO 在前者上学到的"少 token + 少步"偏好为什么能迁移到后者?我的猜测是 efficiency bonus 实际上在训练 LM head 的某种简洁性 prior,这个 prior 本身是 task-agnostic 的——就像 instruction-tuning 训出来的"听话" prior 也能跨域迁移。但作者没在论文里给出深层机制分析,这是一个明显的遗留问题。
五、Sample efficiency:25% 数据就够用
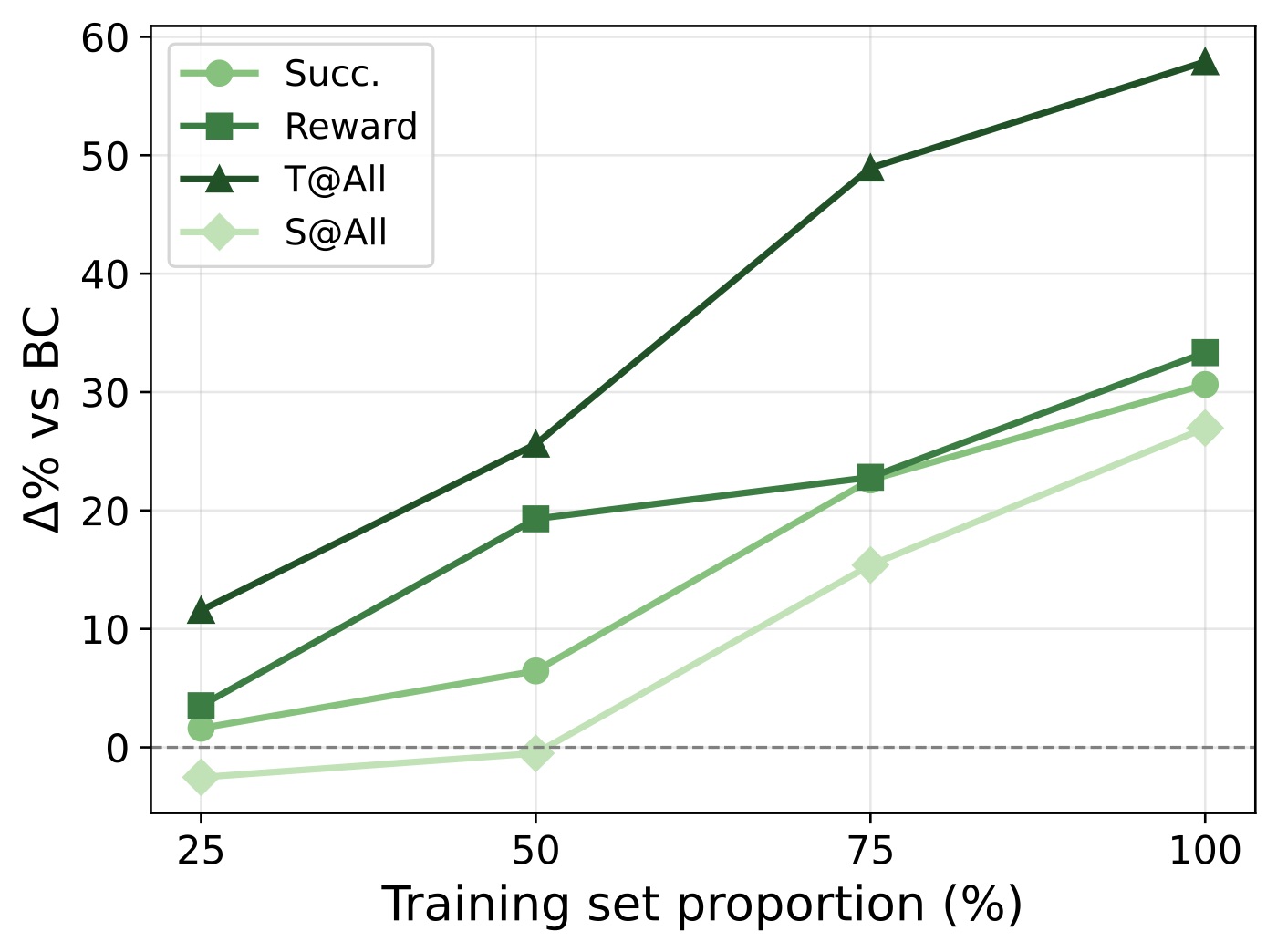
只用 25% 的训练数据(BabyAI 245 样本,WebShop 783 样本),DEPO 在 T@All 上已经能比 BC 基线提升 10% 以上。100% 数据时 T@All 改善接近 60%。这条曲线没有明显饱和迹象——继续加数据应该还能涨。
我个人最看重的是 25% 这个数字——这意味着如果你做一个新 domain(比如内部业务的 agent),你不需要造几万条 trajectory,造个一两千条就能看到明显效率提升。这对工业落地非常友好。对比之下 GRPO 这类 online RL 方法对样本量的要求要高一个数量级。
六、消融:双边惩罚 vs 单边 bonus 的反直觉结论
最有意思的消融在 undesirable penalty 这一块。
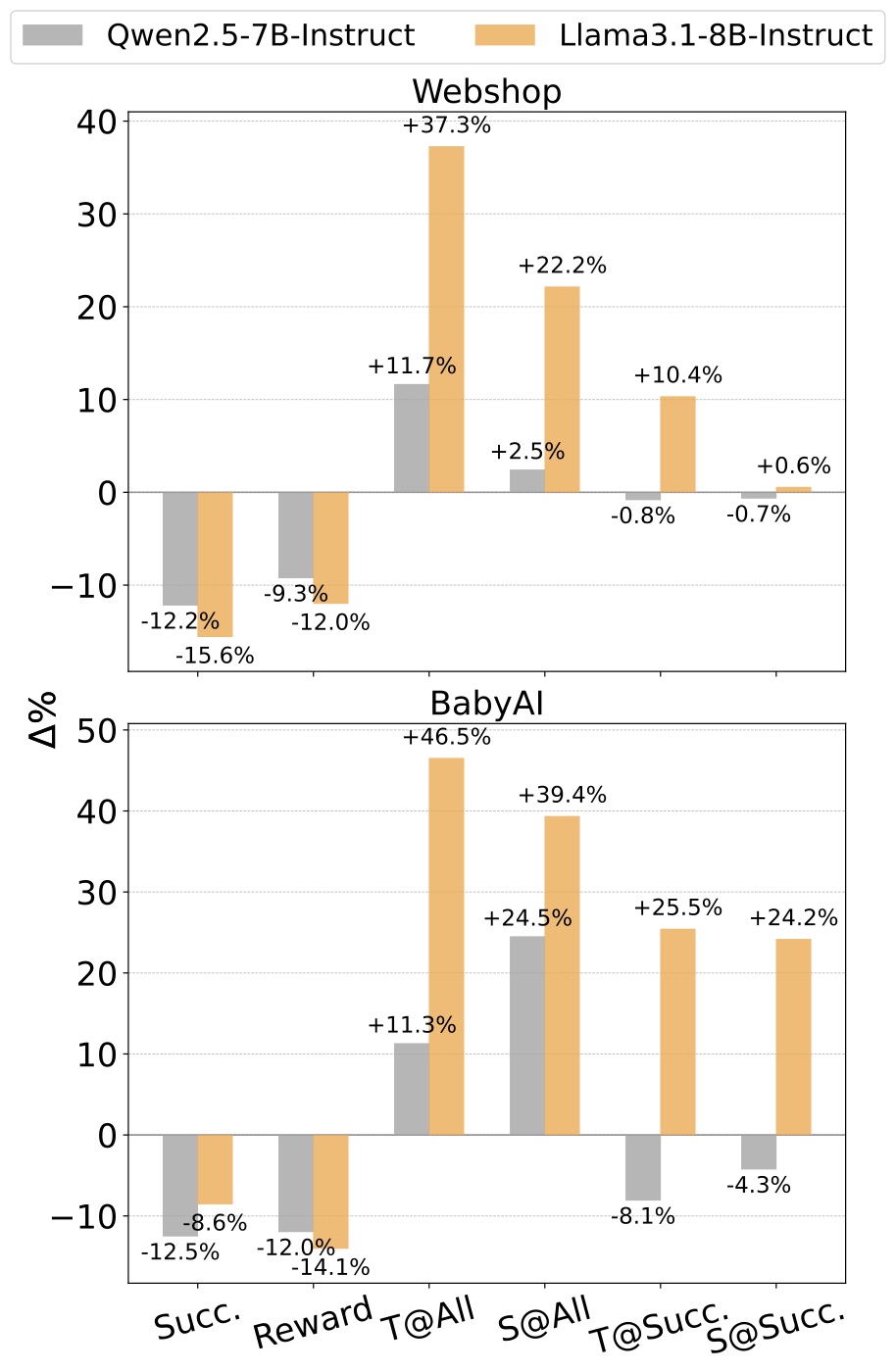
图里每个点表示"DEPO + undesirable penalty"相对"DEPO(仅 desirable bonus)"的相对变化。直觉上加 penalty 应该让 undesirable 离 desirable 更远、训得更稳,但实际:
- Llama-3.1-8B 在 BabyAI 上:T@All 暴涨 46.5 个百分点,S@All 暴涨 39.4 个百分点——加了 penalty 反而 token 多了 46%,步数多了 39%
- Qwen2.5-7B 在 WebShop 上:T@Succ. 微降但 Succ. 也跟着降
作者给的解释是"对低质量样本注入信号没有意义",我觉得这只是表层。更深层的解释可能是:在 KTO 里 desirable / undesirable 的定义已经很清晰(基于 reward 和步数双重过滤),undesirable 那一支已经被 sigmoid 损失推向 0 了,再叠 efficiency penalty 等于让模型"特意学习不好的轨迹的特征"——这是有害的,因为模型实际上只需要知道"不要往那边去",不需要精细描述那边长什么样。
这个发现的实操价值很大:在 KTO 类方法上加 auxiliary signal 时要谨慎,单边比双边稳。我之前自己做 RLAIF 时就栽过类似的坑——叠了一个 helpfulness penalty 在 rejected 样本上,结果 helpfulness 反而下降。当时不理解原因,看了 DEPO 这个消融才有了相对系统的解释。
Hyper-parameter \(\alpha_1, \alpha_2\) 的联合调优
| Setting | Succ. (BabyAI) | T@All | S@All |
|---|---|---|---|
| \(\alpha_1=3, \alpha_2=3\) | 0.88 | 327 | 9.32 |
| \(\alpha_1=3, \alpha_2=0\)(仅 token) | 0.88 | 326 | 9.71 |
| \(\alpha_1=0, \alpha_2=3\)(仅 step) | 0.84 | 458 | 12.48 |
只优化 \(\alpha_1\) 时 token 数最低但 step 不低;只优化 \(\alpha_2\) 时性能掉了;联合优化才有最佳综合效果。这给我们一个朴素但重要的工程经验——dual-efficiency 这两个维度真的需要分别建模,不能用单一 length penalty 替代。我觉得未来的 efficient-reasoning 工作如果还在用单一 length 信号,应该在论文里至少补一个分维度的 ablation 来证明单维度足够。
七、几点批判性思考
1. MCTS 在 inference 期不在 production 期——但训练成本被低估了
DEPO 训练数据是 MCTS + DeepSeek-V3 跑出来的。WebShop 上的 desirable / undesirable 各 1567 条,BabyAI 上 512 / 471 条。论文里轻描淡写地说"使用 MCTS",但 MCTS 在 max depth 50 + DeepSeek-V3 调用下的成本相当可观。我粗略估计一条 trajectory 至少要 30-50 次 V3 调用,3000 条轨迹就是 10 万次以上 API 调用——这个成本对中小团队不友好,论文应该报告。
2. WebShop / BabyAI 是经典但不够现代的 benchmark
这两个环境都是 2018-2022 的产物,状态空间小、动作空间小。今天真正难的 agent 任务是 SWE-Bench、WebArena、Mind2Web 这些——动作空间动辄上百,trajectory 长度可以 30+ 步。DEPO 在这些更难的 benchmark 上能不能复刻同样的 dual-efficiency 提升,论文没有给。我会保留判断——可能在长 trajectory 上 step bonus 项 \(\alpha_2 / T_{\text{step}}\) 的反比例形式衰减太快,需要重新设计。
3. 跨域泛化的机制不清楚
数学任务上的泛化结果很漂亮,但没有解释。一个可证伪的猜想是:DEPO 实际上压缩了 LM head 的输出熵,让模型更倾向于"高置信度短回答",这种 prior 在数学任务上同样有用。如果这个猜想成立,应该能在 logit entropy 或 attention entropy 上看到统计显著的下降。论文没做这个分析,是个明显的可补强项。
4. Bonus 形式不是唯一选择
反比例 \(\alpha / T\) 形式简洁但不是最优。如果 token 分布是长尾的(少数轨迹特别长),反比例会让中等长度的样本几乎拿不到 bonus 区分度。一个可能的改进是用 \(\alpha \cdot \log(T_{\text{ref}} / T)\),让 bonus 在 reference length 附近更敏感。这对 long-trajectory benchmark 应该有用。
5. 与前几篇推荐论文的串联
读到这里我顺手把这周几篇 efficient-reasoning / preference-optimization 论文做个串联:
- GenPRM(arXiv 2504.00891) 用生成式过程奖励 + 代码验证给每步打分
- UnPRM(arXiv 2508.01773) 用不确定性筛选过程奖励数据
- DeCoRL(arXiv 2511.19097) 用模块拆分 + 反事实贡献奖励驱动并行子步生成
- DEPO(本文) 用偏好优化把 dual-efficiency 直接打进 KTO 的 reward
四篇论文从不同角度回答同一个问题:怎么给 reasoning trajectory 的"内部结构"提供细粒度的奖励信号。GenPRM 和 UnPRM 关注 step-level 标签的质量;DeCoRL 关注 module-level 的贡献;DEPO 关注 efficiency 这个全局指标。我有一个直觉——这条研究路径还会持续 6-12 个月,因为大家慢慢意识到 outcome reward 太粗糙、process reward 太脆弱、需要中间地带。DEPO 这种"从外部观测量(token / step 计数)派生 reward"的思路是个相对鲁棒的 baseline,值得复现。
八、给从业者的实操建议
读完这篇后我对自己手头的 agent 项目做了几个调整:
- 评测体系改成 dual-efficiency。不再只报告 Succ.,把 T@All / S@All / T@Succ. / S@Succ. 都加上。一个值得记的口诀是"在 Succ. 同等的两组里看 T 和 S,在 T 同等的两组里看 Succ."
- MCTS + GPT 标注 + KTO 这条流水线复现成本可控(如果有 V3 / GPT-4.1 mini API),DEPO 的核心改动只有 KTO loss 里加一项 \(\alpha_1/\overline{T}_{\text{token}} + \alpha_2/T_{\text{step}}\),五行代码以内。
- 不要在 undesirable 那边加同等强度的 penalty——这是 DEPO 消融给的最重要的 negative result。
- 调 \(\alpha_1, \alpha_2\) 时先固定 ratio 1:1,扫绝对值。论文里 Llama 用 (3,3)、Qwen 用 (2,2),差不多在 reward 自然 scale 的同一量级上。
- 如果你的 agent 跑在长 trajectory(>15 步)任务上,慎用反比例 bonus 形式——可能需要改成 log 或线性递减。
九、收尾:定义比方法更重要
我开头说这篇是"定义比方法更值钱的论文",写到这里更确信这一点。dual-efficiency 这个二维拆分一旦被业界接受,会反过来推动评测、benchmark、reward function 设计往这个方向迁移——而 DEPO 提供的具体方案只是这个 paradigm 下的第一个 baseline。我预期未来一年会有大量论文沿着这条线走:
- online RL 版本的 dual-efficiency(DEPO 是 offline,没用 GRPO 之类的 on-policy)
- dynamic \(\alpha_1, \alpha_2\)(根据任务难度自动调权重)
- 理论分析(efficiency bonus 在 prospect theory 下的 implicit reward 形式到底是什么)
- 真实 production benchmark(SWE-Bench / WebArena 上的复刻)
最后一个个人感受:这种"用一个简洁公式解决一个被普遍忽视的问题"的论文,往往比那种"我们提出了七个新模块"的工作更有长期影响力。Occam's razor 在 ML 论文界依然适用。