不要任何人工标注,PRM 也能训出来——EPFL 这套 uPRM 把"+/-"两个 token 玩出花了
你有没有想过一个问题:现在大家都在卷 Process Reward Model(PRM),动不动就讲"细粒度过程监督才是推理的未来",但 PRM 训练数据本身怎么来?
PRM800K 一个数据集 OpenAI 雇人手工标了 80 万个 step 标签,钱是真烧。后来很多工作改用 Math-Shepherd 那一套 —— 用 Monte Carlo rollout 看每一步往后能不能 rollout 出正确答案,把 step-level 标签从 outcome 反推回来。听起来漂亮,但你要么需要 ground truth 答案,要么需要外部 verifier,而且每个 step 要 rollout 几十次,算力成本高得离谱。
说到底,PRM 没标签寸步难行,整个领域的扩展性都被这件事卡住。
EPFL 这篇 Unsupervised Process Reward Models (arXiv:2605.10158) 给了一个让我看完愣了一下的方案:完全不要任何标签,连最终答案对不对都不用知道,靠 LLM 自己 next-token 概率里给 + 和 - 这两个 token 的相对 logit,就能把一个 PRM 训出来。而且不只是能用,还在某些场景(比如 RL 训练)比有监督的 PRM 更稳。
这篇文章我们就来掰开揉碎讲讲它怎么做到的。
核心摘要
论文:Unsupervised Process Reward Models 作者:Artyom Gadetsky*, Maxim Kodryan*, Siba Smarak Panigrahi, Hang Guo, Maria Brbic(EPFL) arXiv:2605.10158 发布日期:2026 年 5 月
一句话:给 LLM 一段推理轨迹,把候选的"第一个错误位置"用 +/- 标记拼成序列丢回 LLM,从 next-token 概率里读出"这个错误位置有多合理",再用这个分数去 RL 训练一个真正的 PRM。
关键效果: - 在 ProcessBench 上,识别"第一个错误步"的 F1 比 LLM-as-a-Judge 基线绝对涨 8.5–13.2 个点,越难的数据集(OlympiadBench、Omni-MATH)涨得越多 - 作为 test-time scaling 的 verifier,跟有监督 PRM 几乎打平(Best-of-8 平均 60.1 vs 有监督的 60.0–60.8),比 majority voting 最多高 6.9 个点 - 当成 RL 奖励信号用,比有监督 PRM 抗 reward hacking 强一个量级——sPRM 训 50 步就崩,uPRM 能稳稳跑完整个训练
我的判断:这篇文章最值钱的不是 ProcessBench 的几个点,是把 PRM 训练从"标签密集"变成"标签为零"这件事本身。论文打通了一条以前没人正经做过的路径,而且实验扎实,几乎所有维度都给了对照。如果你在做 reasoning RL 或者 long CoT 验证,这套方案值得花时间细读。
一、问题在哪:PRM 这个东西到底贵在哪
先把问题讲清楚。PRM 解决的是 ORM 的痛点:
ORM 只看最终答案对不对,给整个轨迹一个标量分。问题是长 CoT 里有 false positive——一条推理过程错了一半但最后蒙对了,ORM 还是给正分;模型学到的就是"瞎蒙也行",强化错误推理路径。
PRM 给每一步打分,密集得多,对长链推理的引导更细。Lightman 那篇 Let's Verify Step by Step 早就证明了这一点。但 PRM 代价是什么?每一步都要标签。
业界目前主要三条路:
| 方案 | 标签来源 | 痛点 |
|---|---|---|
| 人工标 | 专家逐步审核(PRM800K) | 80 万个 step 标签,烧钱烧时间 |
| MC rollout | 每步往后 rollout K 次,看能否到正确答案 | 必须有 ground truth 答案,每步几十次 rollout 算力炸裂 |
| Implicit PRM | 用 ORM-style 数据反推(DPO/CE) | 还是要 outcome 标签,且过程信号本身被压缩到一个 outcome 上 |
注意一件事——这三条路全都需要某种形式的 ground truth:要么是人工的 step 标签,要么是题目的最终答案。所以"无监督 PRM"听起来像伪命题:你都不知道哪步对、最终对没对,PRM 训啥?
EPFL 这篇就是来回答这个问题的。
二、核心 idea:让 LLM 自己当裁判,但要它"批量评分"
2.1 单条轨迹的打分函数
先看最朴素的版本。给定一条推理轨迹 \(\tau = (x, y_1, \dots, y_T)\) 和一个候选的"首个错误位置" \(j\),构造这样一个序列:
意思就是:前 \(j-1\) 步标 +(对),第 \(j\) 步标 -(错)。如果整条轨迹都对,那就 \(j = T+1\),全部标 +。
把这个序列丢给 LLM,读出每个标记位置上 LLM 给 + 和 - 的 next-token 概率(在 {+,-} 上重新归一化),然后定义打分:
直觉很简单:如果 LLM 真的认为前 \(j-1\) 步是对的、第 \(j\) 步是错的,那它在那些位置上给 +/- 的概率就应该高,分数就高。所有可能的 \(j\) 里取 argmax,就是 LLM-as-a-Judge 的基线。
到这里没什么新东西,就是 LLM-as-a-Judge 标准玩法。
2.2 关键转折:批量联合评分
但作者发现,LLM 单条评估的判断力不稳,把多条轨迹拼一起评估反而准得多。这不是这篇论文的原创观察,之前 RULER、batched evaluation、序列化 ICL 都有类似发现,本质是利用 LLM 的 in-context learning:让模型看多个样例之后,它对每一个样例的判断会更校准。
所以作者把 \(N\) 条轨迹的标记序列拼成一个长序列:
然后联合打分:
注意这里第 \(n\) 条轨迹的概率是条件在前 \(n-1\) 条轨迹及其标记上算出来的——前面已经"打好分"的轨迹给后面的轨迹当 in-context 例子。
到这里我皱了一下眉头。这个 ICL 效果有个明显的失败模式:如果所有 \(j_n\) 都标在同一个位置,LLM 可能因为模式一致性给一个虚高的分数——比如全标 \(j=3\),LLM 的 in-context 会自我强化。作者也注意到了这点,在 Appendix 里给了一个简单的 degenerate regularizer 来压住这种坍缩。
2.3 把分数蒸馏成一个真正的 PRM
光有打分函数还不是 PRM——你还需要一个能在测试时独立给每一步打分的模型。作者的做法是把一个真正的 PRM \(r_\theta\) 训出来,让它的预测分布 \(p_\theta(j | \tau)\) 去优化上面的联合分数:
第二项是 entropy regularization,防止 \(p_\theta\) 过早 collapse 到某个固定位置。这个 \(\gamma\) 选得不好就废——作者在 Appendix 里有完整消融,太小直接坍掉,太大学不到东西。
PRM 架构上跟 Lessons of Developing PRMs 那篇基本一样:每个 step 之后塞一个特殊 token [*],过 LLM 拿最后一层 hidden state,再过一个 2 层 MLP 出二分类 logit。LoRA 微调,base 模型就是用来打分的那个 LLM 自己。
所以本质上这是一种 self-training:模型用自己的 next-token 概率给自己生成训练信号,把这个信号蒸馏成一个专门的 PRM。这个想法跟之前 STaR、Beyond Self-improvement 那一系是一脉相承的。
2.4 一些工程细节
几个让我觉得作者很懂工程的地方:
计算开销:8 张 H200,uPRM 训练约 5.5 小时,对照的有监督 PRM SFT 约 4.25 小时——多花的那 1.25 小时跟省下来的人工标注成本相比,几乎可以忽略。
只在训练阶段需要联合评分:测试时 PRM 跟普通 PRM 一样独立打分,没有额外 context length 开销。这个设计很重要——很多 ICL trick 在推理时还要拖着几条样例跑,部署起来很难受。
Trajectory packing:作者没把 \(N\) 当超参,而是设计了一个动态打包策略最大化 GPU 显存利用率,同时保证信噪比稳定。这种工程细节论文里写得不多但很实用。
三、实验:从三个维度证明这玩意儿真能用
作者从三个维度验证 uPRM:(1)直接评估错误步识别能力;(2)作为 test-time verifier;(3)作为 RL 奖励信号。
3.1 ProcessBench:识别第一个错误步
ProcessBench 是 Qwen 团队 2025 年放出来的 benchmark,专门评估 PRM 找"第一个错误步"的能力。报 F1(错误轨迹定位准确率和正确轨迹判全对率的调和平均)。
| 数据集 | LLM-as-a-Judge | uPRM | 绝对提升 |
|---|---|---|---|
| GSM8K | 49.8 | 58.3 | +8.5 |
| MATH | 42.8 | 52.6 | +9.8 |
| OlympiadBench | 29.4 | 42.7 | +13.3 |
| Omni-MATH | 26.6 | 39.8 | +13.2 |
注意一个细节:越难的数据集,uPRM 涨得越多。GSM8K 这种小学题涨 8.5 个点,到 OlympiadBench、Omni-MATH 这种竞赛题级别直接涨 13 个点。作者解释是:当题目越难、LLM 单条判断越不可靠时,"批量联合评分"带来的 ICL 增益就越值钱。
我觉得这个结论挺有意思——它反过来说明 LLM-as-a-Judge 在简单任务上其实已经够用了,真正需要这套联合评分的是难题。这跟我之前调 reward model 时的体感是一致的:简单任务的 RM 怎么训都差不多,难任务才能拉开 gap。
但有一点要警觉:这里 uPRM 用的 base 模型是 Qwen2.5-14B-Instruct,跟 LLM-as-a-Judge baseline 用的是同一个底座,所以 baseline 不算被刻意削弱。这点 controlled setup 做得是干净的。
3.2 Test-time scaling:当验证器用
这部分是这篇论文里我最想看的——因为它直接对标"有监督 PRM"。
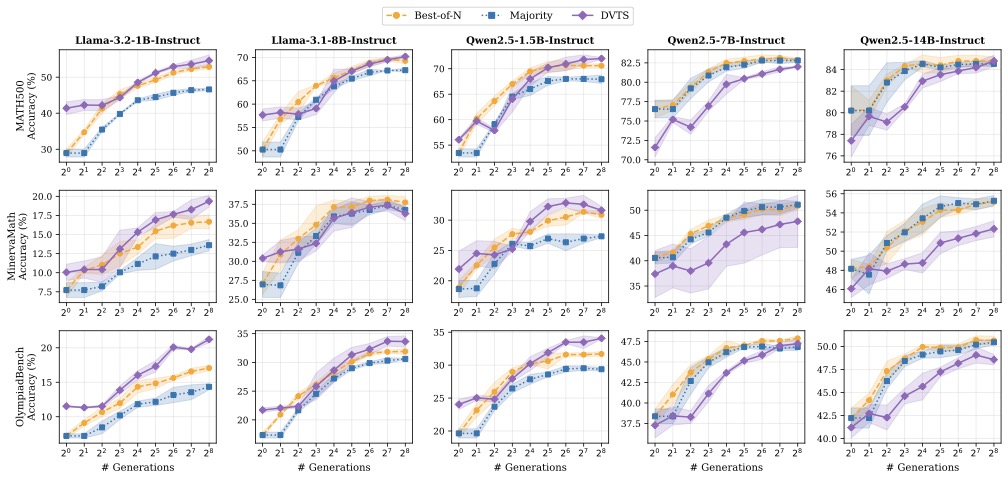
图1:从 Llama-3.2-1B 一直到 Qwen2.5-14B 五个不同规模的 policy,在三个数据集上做 test-time scaling。紫色 DVTS 在小模型上明显领先,但在大模型上反而不如 Best-of-N 或 majority voting。
直接说几个观察:
小模型上效果炸裂:Llama-3.2-1B 上从 1 个 candidate 的 14.6% 涨到 256 个 candidate 的 31.7%,绝对涨 17.1 个点。DVTS+uPRM 比 majority voting 高 6.9 个点。
大模型上 PRM 收益边际递减:到了 Qwen2.5-14B 这个量级,majority voting 本身就是非常强的 baseline,PRM 的优势被吃掉一大半,DVTS 甚至会拖后腿。这个现象不是 uPRM 独有的,Lessons of Developing PRMs 和 Liu et al. 之前都报告过类似规律——PRM 的价值跟 base policy 的强度反向相关。
跟有监督 PRM 比 Best-of-8(Qwen2.5-Math-7B-Instruct policy):
| PRM | MATH-500 | Minerva | Olympiad | Avg. |
|---|---|---|---|---|
| pass@8 (上界) | 91.5 | 55.5 | 60.3 | 69.1 |
| Math-Shepherd-PRM-7B | 86.8 | 47.3 | 47.1 | 60.4 |
| RLHFlow-PRM-Mistral-8B | 86.6 | 46.9 | 46.4 | 60.0 |
| Skywork-PRM-7B | 87.4 | 46.6 | 48.4 | 60.8 |
| Qwen2.5-Math-7B-PRM800K | 87.1 | 47.1 | 46.9 | 60.4 |
| Qwen2.5-Math-PRM-7B | 87.0 | 47.2 | 47.7 | 60.6 |
| Implicit PRM (CE) | 86.3 | 47.4 | 46.6 | 60.1 |
| Implicit PRM (DPO) | 86.5 | 47.2 | 46.4 | 60.0 |
| sPRM(同设置有监督版) | 86.3 | 46.7 | 47.1 | 60.0 |
| uPRM | 86.5 | 46.7 | 47.1 | 60.1 |
uPRM 跟 sPRM 完全打平(60.1 vs 60.0),跟所有有监督 PRM 在误差范围内。Skywork-PRM-7B 高 0.7 个点,但人家是专门训过的 math-specific 模型。而 uPRM 是从一个通用的 Qwen2.5-14B-Instruct 出发训出来的,没看过任何 step 标签,也没看过任何 ground truth 答案。
说实话,这个结果让我有点意外。我原本以为无监督方法跟有监督 PRM 至少会有 1-2 个点的 gap,毕竟 PRM800K 是 OpenAI 真金白银堆出来的高质量数据。结果在 Best-of-8 这种实际部署场景下,gap 几乎消失了。
3.3 RL 奖励信号:uPRM 真正的杀手锏
但 TTS 还不是这篇论文最有意思的部分。作者把 uPRM 当 RL 奖励信号去训 policy,对比有监督 PRM 和 verifiable reward (VR),结果出现了一个非常有戏剧性的现象。
先看主表(PURE 框架,RLOO 算法,MATH level 3-5 训练数据):
| Policy | Reward 来源 | MATH-500 | Minerva | Olympiad |
|---|---|---|---|---|
| Qwen2.5-7B | VR | 74.1 | 34.2 | 34.8 |
| sPRM+VR† | 75.4 | 29.4 | 36.9 | |
| uPRM† | 73.2 | 35.0 | 37.5 | |
| uPRM+VR† | 73.2 | 35.8 | 35.7 | |
| Qwen2.5-Math-7B | VR | 80.1 | 35.9 | 41.8 |
| sPRM | 崩了 | 崩了 | 崩了 | |
| uPRM | 82.9 | 37.9 | 42.1 | |
| uPRM+VR | 82.1 | 36.3 | 43.8 | |
| Qwen2.5-Math-1.5B | VR | 70.0 | 26.0 | 33.5 |
| sPRM† | 74.7 | 27.8 | 35.0 | |
| sPRM+VR† | 74.4 | 28.7 | 36.3 | |
| uPRM | 73.5 | 31.8 | 36.6 | |
| uPRM+VR | 74.3 | 31.5 | 35.8 |
†表示在 reward hacking 之前的最后一个 checkpoint。
注意"崩了"那两行:Qwen2.5-Math-7B 用 sPRM 训练直接崩,Qwen2.5-7B 用 sPRM 也崩,连第一个 checkpoint 都没撑到。Qwen2.5-Math-1.5B 用 sPRM 撑到几百轮也最终崩。而 uPRM 全程跑完了所有训练,没出 reward hacking。
这个现象怎么解释?看训练曲线就一目了然。
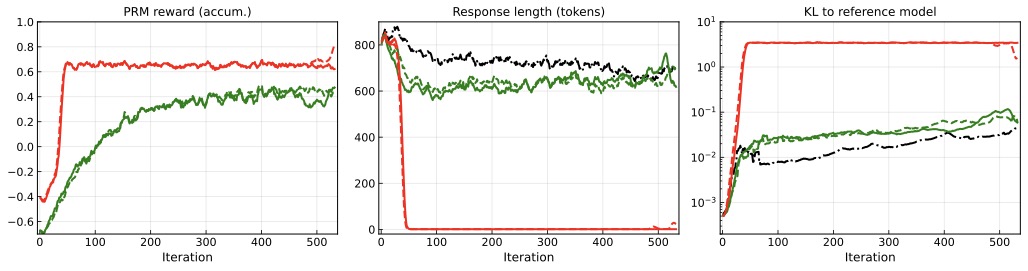
图2:sPRM(红色)的 PRM reward 几乎瞬间冲到 0.7 顶住,但 response 长度从 800 token 暴跌到接近 0,KL 也飙到 reference model 的 \(10^0\) 量级。这是教科书级的 reward hacking——policy 学会了用一种空响应或退化模式来骗 PRM 给高分。绿色 uPRM 的 reward 是缓慢爬升的,response 长度保持在 600-700 之间,KL 控制在 \(10^{-1}\) 以下,行为正常。
这个图挺震撼的。sPRM 不是"训练效果不好",是被 policy 直接骗废了——50 步内 policy 就找到了 sPRM 的奖励漏洞,给一个非常短的 degenerate response 就能拿满分。
为什么 uPRM 抗 hacking?我的猜测(论文里也提到了类似想法):uPRM 通过联合评分训练出来的判断分布更"软"、更不集中。sPRM 是 SFT 出来的,对每个 step 给的二分类 logit 非常硬;policy 一旦找到一个 trick 就能让它相信"全对"。而 uPRM 训练目标里有 entropy regularization,加上 in-context 对照评分,分数面更"光滑",policy 不容易找到陡峭的 hacking 漏洞。
但作者也很坦诚:uPRM 不是完全免疫 reward hacking,只是"频率更低、严重程度更轻"。这种实事求是的表述比"我们彻底解决了 reward hacking"那种营销话术让我觉得靠谱很多。
最后一个让我惊喜的数:Qwen2.5-Math-1.5B 用 uPRM 训练,平均比 VR 高 4 个点。这意味着无监督 PRM 给 RL 提供的过程信号比 ground truth 答案监督还要有效——这件事如果换成几年前我肯定不信。
3.4 消融:γ 怎么选?
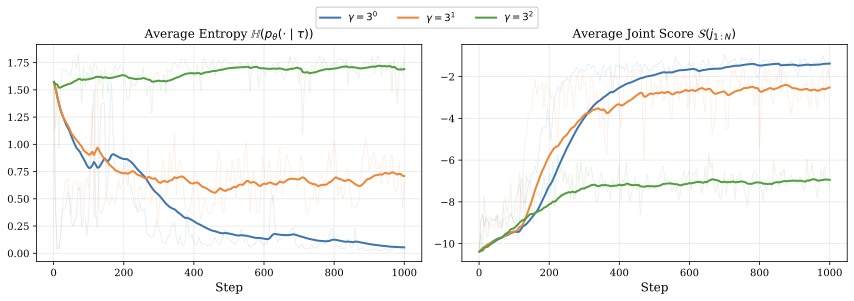
图3:γ 太小(蓝色 γ=1)模型很快坍缩到 deterministic 分布,熵跌到 0;γ 太大(绿色 γ=9)模型学不动,熵保持在 1.7 附近、联合分数稳定在 -7 不动;γ=3(橙色)是甜点。
这个消融做得挺干净的。坦率讲,需要手调 γ 是这套方法的一个工程缺陷——但好在 γ 的选择直接看训练曲线就能判断:熵跌到 0 就是 collapse,熵纹丝不动就是没学进去。
四、批判性审视:这篇论文的几个值得追问的地方
我尽量不当 cheerleader,几个地方我自己也没完全说服自己:
1. base model 选 Qwen2.5-14B-Instruct 是否"作弊"?
作者明确 uPRM 用的 base 是 Qwen2.5-14B-Instruct,而很多有监督 PRM 是基于 Qwen2.5-Math-7B 训的(小一倍且专门 math)。从模型容量和通用能力上 14B-Instruct 确实更强。
但反过来想:uPRM 的核心成本就是这个 14B 模型作为打分器。如果换成 7B 通用模型,效果会怎么样?论文没系统报告这个对比。我直觉是会掉一些,但能掉多少不好说。这是一个值得后续工作做透的点。
2. ProcessBench 数据集是 Qwen 团队做的,而 base model 是 Qwen——会不会有 base model contamination?
虽然 uPRM 训练阶段没看 step label,但 base 模型 Qwen2.5-14B 在预训练阶段是不是已经间接看过 ProcessBench 类似的数据?这件事很难严格排除。
不过这个 concern 对所有用 Qwen 系列的 PRM 都存在,不是 uPRM 独有的问题。
3. "没有 reward hacking"是不是因为训练步数还不够?
作者承认 Qwen2.5-7B 上 uPRM 也最终被 hack。Qwen2.5-Math-7B 之所以全程稳,可能只是因为 train data 跟 base model 的 distribution match 比较好。如果训得更久或者换更 OOD 的 RL 数据,uPRM 还能撑住吗?这是个 open question。
4. ICL degenerate 的现象解释得不够透
作者提到联合评分有一个失败模式:所有 \(j_n\) 都取同一个值时分数虚高。Appendix 给了一个 regularizer 解决,但没深入分析这个 ICL pattern matching 到底什么时候发生、严重到什么程度。如果换成更小/更大的 batch size \(N\),这个问题会怎么变?我觉得这块是后续工作可以挖深的。
5. 跟 Implicit PRM 的对比稍显轻描淡写
Implicit PRM (Yuan et al.) 也是不需要 step label 的方案——用 ORM 数据 + DPO/CE 反推过程信号。Best-of-8 上 Implicit PRM (CE) 平均 60.1,跟 uPRM 的 60.1 完全打平。这意味着在 verifier 这个用法上,uPRM 没有显著优势。uPRM 真正甩开 Implicit PRM 的地方是 RL,但论文里没直接对比 Implicit PRM 作为 RL reward 的效果。这块对比缺失,不算完美。
五、工程启发:什么时候你应该用这套方案
如果你在做的是以下场景,uPRM 的思路值得抄:
a. 做 reasoning RL 但买不起标注:直接用,特别是数学/代码这种 step 边界清晰的任务。8 卡 H200 训 5.5 小时就能出一个 PRM,跟 SFT 差不多的成本。
b. 已经在用 sPRM 做 RL 但被 reward hacking 困扰:试试用 uPRM 替换掉,至少训练稳定性会好不少。或者用 uPRM + VR 这种 mix 方案做兜底。
c. 不确定 PRM 标签质量:现在很多团队用 MC rollout 生成 weak labels 训 PRM,质量参差。uPRM 完全绕开这个问题,至少是一个有竞争力的对比基线。
d. test-time scaling 但不想训 PRM:直接用 LLM-as-a-Judge 的批量联合评分版(公式 4)就行,不一定要训 uPRM。这种用法没有训练成本,纯推理时套一个 batch evaluator 即可。
不太建议用的场景:
a. 你已经有高质量人工标注(PRM800K 级别):那就老老实实做 SFT,没必要转 uPRM。
b. policy 是 70B+ 大模型:从图1看大模型上 PRM 收益本来就有限,majority voting 已经够强了。
c. 极小算力场景:14B base 模型打分本身就吃显存,没卡的话还是 ORM 简单。
六、收尾:这篇论文真正打动我的地方
回到开头那个问题——PRM 没标签寸步难行,整个领域被这件事卡住。
这篇论文给了一个让我觉得"对,就该这么做"的解法:不去想怎么把标签搞得更便宜(MC rollout、Implicit PRM 都是这个思路),而是直接质问"我们到底需不需要标签"。
它的回答是:不需要。LLM 的 next-token 概率本身就编码了对 step 正确性的判断,你只需要一个聪明的方式把这个判断联合起来读出来——批量评分激活 ICL,把单条不可靠的判断变成多条可靠的对照。然后用 RL 把这个联合分数蒸馏到一个独立的 PRM 里。
整个 pipeline 没有一处需要 oracle,但效果跟有 oracle 训出来的 PRM 几乎打平,在 RL 这种最考验 reward model 鲁棒性的场景下甚至更稳。
我会把这篇论文归类到"那种你看完会想去跑一跑代码"的论文。它的创新程度不像 GRPO 那样定义一个时代,但工程价值很高,思路也漂亮——属于那种在不增加任何外部成本的情况下,把一个被认为必须有标签的问题转成无标签的的工作。这种工作不多,每一篇都值得认真读。
如果让我猜,未来 1-2 年里 PRM 这个赛道会从"想方设法搞标签"逐渐转向"从模型自己挖训练信号"。uPRM 是这个转向里一个挺有标志性的工作。
参考文献
- 原文:Unsupervised Process Reward Models, arXiv:2605.10158
- ProcessBench: Zheng et al., 2025
- PURE 框架: Cheng et al., 2025 - Stop summing
- PRM800K: Lightman et al., Let's Verify Step by Step, 2024
- Math-Shepherd: Wang et al., 2024
- Implicit PRM: Yuan et al., Free Process Rewards, 2025
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我