Solvita:四智能体闭环 + 可训练知识网络,让大模型在 Codeforces 打到 Legendary Grandmaster
写在前面
竞赛编程这件事,我一直觉得是个挺好的"照妖镜"——你能看出一个模型到底是真的会推理、还是靠见过类似题在硬背模板。
最近 OpenAI、Anthropic 那批商用 Coding Agent(Codex CLI、Claude Code)在简单题上已经能打到不错的水平,但稍微难一点的题——比如 AetherCode 这种专门收 Codeforces 高难度题的榜——它们的 pass@1 还是会掉到 40% 出头。问题不在底模不够强,而在"打法"本身有问题。
这篇 Solvita 给了一个让我看完之后觉得"嗯,这条路是对的"的方案。它不是又训一个更大的代码模型,也不是又造一个 RAG 检索库,而是搭了一个四智能体闭环系统,每个 agent 背后挂一张可训练的图结构知识网络。系统跑着跑着,每个 agent 都在变聪明,但底层 LLM 一个权重都没动。
更刺激的是 Codeforces 实测部分——三个不同底模(GPT-5.4、Claude Opus 4.6、DeepSeek V4 Pro)套上 Solvita 跑 12 场比赛,全部进入 Legendary Grandmaster(≥3000 分) 的段位带;同样的底模裸跑,最高只能停在 Grandmaster 段位(2700–2850)。
300 多分的差距,全靠这套 agentic loop 撑出来。
📖 核心摘要
痛点:现在的多智能体编码框架(AlphaCodium、MapCoder、AgentCoder 这一票)说到底都是无状态的——每道题从零开始解,前面踩过的坑、调过的 bug、攒下来的经验,下一道题完全用不上。RAG 试图加记忆,但它只是把相似文本拼回 prompt,没有真正改变模型的推理路径。
方案:Solvita 拆成 4 个 agent —— Planner(策略选择)、Solver(代码合成 + 补丁修复)、Oracle(认证测试构造)、Hacker(对抗性攻击),每个 agent 背后挂一张可训练的图结构知识网络。所有失败信号(判错、攻破、规模超时)通过 contextual bandit 更新对应网络的边权重,下次遇到相似问题就走更靠谱的路径。
核心效果:5 个前沿底模 + 3 个 benchmark 共 15 个格子里赢了 14 个;Codeforces 12 轮实测从 GM 段冲进 LGM 段(≥3000 分);用 patch 补丁机制比每次重写代码节省 88%~92% completion token,同时 pass@1 还更高。
我的判断:这是个架构层的真创新,不是堆 prompt 也不是改 RAG。把"可训练参数"从 LLM 权重转移到外挂知识图的边权上,这个 trick 让"无需更新底模即可持续学习"变得真正可行。Hacker 那块尤其漂亮——把"自己攻自己"做成强化学习信号,这在 code agent 里我还没见过同样系统化的实现。
论文信息
- 标题:Solvita: Enhancing Large Language Models for Competitive Programming via Agentic Evolution
- arXiv:2605.15301
- 作者:Han Li, Jinyu Tian, Rili Feng, Yuqiao Du, Chong Zheng, Chenyu Wang, Chenchen Liu, Shihao Li, Xinping Lei, Yifan Yao, Weihao Xie, Letian Zhu, Jiaheng Liu(共 13 位)
- 提交日期:2026 年 5 月 14 日
- 学科:cs.AI
🤔 为什么需要 Solvita?现有 code agent 卡在哪里
先说一个我自己写 agent 时一直绕不开的痛点。
你给一个多智能体框架(比如 AlphaCodium)扔 100 道题进去,它第 100 道题的表现和第 1 道题是一样的——因为它根本不记得前 99 道题踩过的坑。每一道题都是 cold start,每一次都是把同一套 prompt 模板灌进 LLM 重来一遍。
这就是所谓的"stateless multi-agent"问题。
那 RAG 呢?RAG 看起来在加记忆,但它做的事说穿了就是"相似度检索 + 文本拼接"。把之前解过的题翻出来塞回 prompt,让模型"参考一下"。问题是:
- 检索是静态的:相似度算法本身不学习,不会因为某次检索结果"帮上了忙"就在下次倾向于推同类内容。
- 拼回 prompt 不改变推理路径:模型该怎么推还怎么推,只是多了一段上下文。如果模型一开始就走错了路,给它多看几个"参考解法"反而可能加重它的偏见。
回头看人是怎么进步的——一个 OI 选手刷题刷到第 1000 道,他和第 1 道时的差距绝不只是"见过更多模板"。他攒下来的是:
- 哪类问题用哪种策略更稳(Planner 该干的事)
- 哪些写法容易出 bug、哪些 invariant 必须先保住(Solver 该懂的)
- 怎么造测试数据才能逼出自己代码的边界 bug(Oracle / Hacker 该练的)
这些是可迁移的元能力,不是单道题的记忆。
Solvita 想做的就是把这套"元能力的积累"塞进系统里。但它的做法很克制——不动 LLM 权重,所有学习发生在外挂的知识图上。
🏗️ Solvita 架构:四个 agent 的闭环
直接看图。
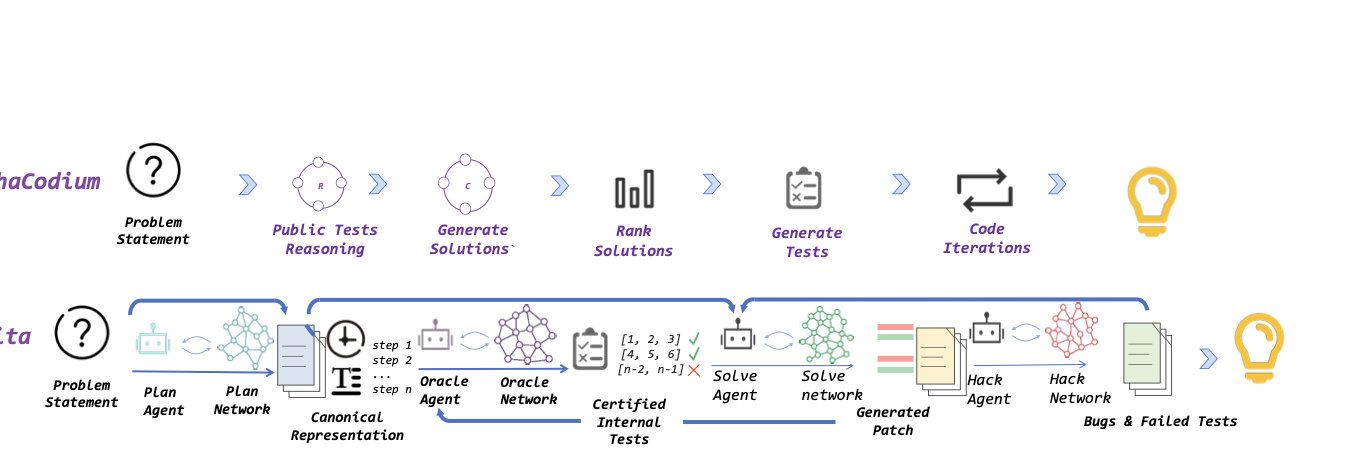
图 1:Solvita 架构总览。每个 agent 都配一个可训练的知识网络(绿色/紫色/红色节点的小图)。Planner 出策略 → Oracle 造认证测试 → Solver 写代码并打补丁 → Hacker 发起对抗攻击,任何一环的失败都会通过事件总线传播到全部 4 张知识网络。
四个 agent 的分工,用大白话讲一遍:
| Agent | 干什么 | 知识网络存什么 |
|---|---|---|
| Planner | 把题面翻译成形式化数学规约,挑算法范式(DP / 贪心 / 图论...),给出复杂度估计 | 哪类问题历史上用哪种策略成功率高 |
| Solver | 写代码,失败时打补丁(SEARCH/REPLACE)而不是从头重写 | 三层图:题目 Q 节点 ↔ 解法分解 M 节点 ↔ 可复用技能 S 节点 |
| Oracle | 造认证过的内部测试——既要找出错解,又要保住对解 | 哪些 certification 策略对哪类题最有信号 |
| Hacker | 主动攻击候选代码,找 corner case、复杂度爆炸点、哈希碰撞 | 漏洞目录:什么类型的 bug 对应什么攻击路径 |
闭环的关键在事件总线:Hacker 找到一个 bug,这个事件不只更新 Hacker 自己的网络——Planner、Solver、Oracle 全都收到通知。下次遇到结构相似的问题,Planner 会更倾向规避那种容易出 bug 的策略,Solver 会更小心那种写法,Oracle 会优先生成针对那类边界的测试。
一次"经验",四处复用。这是我觉得 Solvita 设计上最漂亮的一笔。
🧠 知识网络怎么"训练"?Contextual Bandit + 图结构
这里是我读得最仔细的一段,也是最容易被一句"用强化学习训练"糊弄过去的地方。
每个 agent 的知识网络都是一张图。以 Solver 网络 为例,它是三层结构:
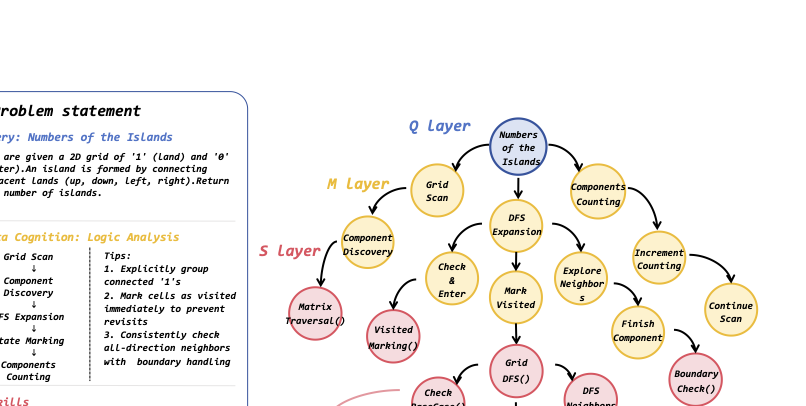
图 2:Solver 知识网络。"Numbers of the Islands"这道题 Q 节点连到几个 M 节点(Grid Scan / DFS Expansion / Components Counting),每个 M 节点再下接 S 节点(具体技能如 Matrix Traversal、Visited Marking)。当 Solver 选了某条 Q→M→S 路径并成功了,对应的边权增强;失败了就削弱。
具体怎么更新?所有 agent 共享一个 contextual bandit policy(参考 Li et al. 2010 的 LinUCB 那一支)。拆开看就这几个要素:
- 特征:当前问题的特征 \(\Phi(x)\)(标签、复杂度、约束规模...)
- 动作:选哪条边、调用哪个历史经验
- 奖励:根据这次调用的结果(pass / fail / detected bug / preserved correct)算出来
我把 Hacker 的奖励公式拎出来看一下,这个公式挺能反映 Solvita 的设计哲学:
其中: - \(g_{\text{valid}}\):生成的攻击样本里有多少通过了 validator(生成的输入合法吗) - \(g_{\text{break}}\):合法输入里有多少真的攻破了候选代码(合法且有效的攻击比例) - \(g_{\text{sev}}\):被攻破样本的平均严重度(attack 出 RE 的权重比 attack 出 WA 高) - \(\kappa(c)\):编译失败的惩罚
最重的权重压在 \(g_{\text{break}}\) 上——也就是说,Solvita 真正奖励的是"能不能攻破",而不是"生成了多少合法测试"。这个权重设计非常工程师的脑子:你不能让 agent 为了刷"我生成了 1000 个 valid input"的指标而摸鱼,必须逼它真去捅出 bug。
更巧的是,Hacker 攻破一次之后,那个失败事件同时写到 Planner、Solver、Oracle 三张网络里作为 contrastive 样本——告诉 Planner 这种策略路径有雷,告诉 Solver 这种写法有坑,告诉 Oracle 这种边界要纳入测试。Hacker 一次成功攻击,全系统受益。
说实话,我看到这个 contrastive 跨网络传播的设计时停顿了一下。这就是把强化学习里的 credit assignment 问题在多 agent 系统里彻底打开了——不是只奖励直接动作的 agent,而是让奖励信号沿着因果链反向流过整个系统。
🔧 Solver 内循环的杀手锏:patch 补丁,不是全量重写
这是一个工程上特别有价值、但很多 multi-agent 框架都做错了的地方。
绝大多数现有框架(包括 AlphaCodium)在 Solver 修复 bug 时是"全量重写"——把上次的失败代码扔掉,让 LLM 重新生成一版。听起来很合理,但实际跑起来你会发现:
LLM 经常把上次已经写对的部分也改坏了。
我之前在调一个类似的 self-correction loop 时就被这事坑过——模型修了一个边界 bug,但顺手把主逻辑里一个本来对的循环边界也"优化"了,结果通过率不升反降。
Solvita 的做法是只让 Solver 输出 SEARCH/REPLACE 补丁块——明确告诉模型:"你只能改这一段,别动其他地方"。这个小改动在实验数据里效果很可观:
| Backbone | 策略 | CC pass@1 | APPS pass@1 | AC pass@1 | 平均迭代次数 | Token 节省 |
|---|---|---|---|---|---|---|
| GPT-5.4 | 全量重写 | 75.76 | 62.10 | 41.25 | 5.18 | 67.4% |
| GPT-5.4 | 补丁修复 | 82.42 | 67.70 | 49.25 | 3.74 | 91.2% |
| Claude Opus 4.6 | 全量重写 | 73.94 | 64.30 | 45.50 | 5.27 | 68.9% |
| Claude Opus 4.6 | 补丁修复 | 80.61 | 69.30 | 53.75 | 3.86 | 92.0% |
表 1:补丁修复 vs 全量重写,匹配 8 轮迭代预算,相同 retrieval 和 decoding 设置。Token 节省按统一的参考成本 \(T_{\text{ref}} = N_{\max} \cdot \bar{t}_{\text{full}}\) 计算。
注意 AetherCode 上 Claude Opus 涨了 8.25 个点——这种"难题集上吃肉,简单题集吃菜"的提升模式,恰恰说明补丁机制对复杂代码的不变式保持特别关键。题越难,全量重写越容易把对的部分搞坏。
补丁修复还有一个隐藏好处:在我看来这是写 RL 系统时最大的避坑——奖励信号变干净了。全量重写时你不知道一次修复到底是"修对了 bug"还是"运气好重写又对了";patch 机制下你能精确归因到那一小段改动。这对训练知识网络的 bandit policy 来说至关重要。
📊 主实验:5 个底模 × 3 个 benchmark = 15 个格子赢 14 个
直接看主表(pass@1, %,粗体是该列最优):
| Method | GPT-5.4 CC/APPS/AC | Claude Opus 4.6 CC/APPS/AC | Qwen3.6 CC/APPS/AC | DeepSeek V4 Pro CC/APPS/AC | Grok CC/APPS/AC |
|---|---|---|---|---|---|
| Single-pass | 40.00 / 37.90 / 18.00 | 44.85 / 40.10 / 22.75 | 33.94 / 30.80 / 9.50 | 47.27 / 42.50 / 24.00 | 38.18 / 34.60 / 15.50 |
| Codex CLI | 81.82 / 67.10 / 48.50 | 70.30 / 59.80 / 44.25 | 60.00 / 47.90 / 22.50 | 79.39 / 66.30 / 45.00 | 73.33 / 57.20 / 31.50 |
| Claude Code | 70.91 / 60.40 / 42.75 | 80.00 / 69.00 / 54.25 | 58.79 / 46.30 / 21.50 | 76.97 / 64.50 / 43.75 | 72.12 / 55.50 / 29.75 |
| AlphaCodium | 60.61 / 52.40 / 33.00 | 64.24 / 56.20 / 36.50 | 53.33 / 42.30 / 14.50 | 70.91 / 53.40 / 33.00 | 60.61 / 46.10 / 21.00 |
| MapCoder | 57.58 / 54.30 / 30.50 | 60.00 / 55.10 / 38.25 | 50.91 / 41.00 / 16.00 | 66.67 / 54.80 / 35.00 | 62.42 / 44.20 / 19.50 |
| Solvita | 82.42 / 67.70 / 49.25 | 80.61 / 69.30 / 53.75 | 69.70 / 55.10 / 26.00 | 89.09 / 68.10 / 51.50 | 78.18 / 58.50 / 33.50 |
表 2:主结果(pass@1, %)。CC=CodeContests (165题), APPS (1000题), AC=AetherCode (400题)。
几个我看完之后画了重点的地方:
1. 在 DeepSeek V4 Pro 上 CodeContests 冲到 89.09%——比 single-pass 的 47.27 翻了快一倍,比最强的 Codex CLI(79.39)还高出 9.7 个点。这个数有点夸张了。
2. Single-pass 那一行才是真正值得回头看的地基线。GPT-5.4 裸跑在 CodeContests 只有 40%,加上 Solvita 直接到 82.42——翻一倍 这件事在简单题已经被卷烂的今天是真的少见。
3. 唯一没拿第一的格子是 Claude Opus 4.6 × AetherCode(53.75 vs Claude Code 54.25)。差 0.5 个点。诚实地说这是 Claude Code 在自家主场的微弱优势,可能跟 Anthropic 内部对 Claude 的 prompt 优化有关,不算 Solvita 的真败。
4. Open-source agent 框架(AlphaCodium / MapCoder)在所有格子上都被 Solvita 甩开,且越是难题(AetherCode)差距越大。这点很说明问题——简单题谁都能做到 80%,真正的 agentic loop 价值在难题上才暴露。
不过我也要稍微泼一点冷水:这个表里没有跟同期的 RL-trained code model 比(比如 DeepSeek-Coder-RL 那一支用强化学习直接训底模的方案)。Solvita 比的全是"不动权重的 inference-time agent",跨过 RL training 的赛道没看到。所以"SOTA"这两个字得带前缀理解——是 agentic code generation 这个赛道内的 SOTA,不是说"比所有方法都好"。
🔬 消融实验:知识网络真的在累积经验吗?
主表赢不能光看终局数字,必须看消融——验证"知识网络真的在学习",而不是"换了套 prompt 凑巧涨点"。
Solvita 的消融做了一件挺良心的事:在 5318 道题的训练轨迹上分 1.5k / 3k / 4.5k 三个 checkpoint,分别报告每个网络单独加上之后的效果。
数据有点多,我抽 GPT-5.4 这一列看:
| Configuration | CC | APPS | AC |
|---|---|---|---|
| Single-pass | 40.00 | 37.90 | 18.00 |
| Without training (空网络多 agent) | 67.70 | 54.50 | 35.00 |
| + Solver network @1.5k | 70.86 | 57.42 | 38.40 |
| + Solver network @3k | 73.63 | 60.18 | 41.38 |
| + Solver network @4.5k | 75.60 | 61.80 | 43.50 |
| + Hacker network @4.5k | 72.00 | 58.00 | 38.50 |
| + Oracle network @4.5k | 74.10 | 60.50 | 42.70 |
| Full system 三网络全开 | 82.42 | 67.70 | 49.25 |
表 3:组件消融,GPT-5.4 backbone。1.5k / 3k / 4.5k 是训练轨迹上的三个 checkpoint。
从这张表能看出两件事:
第一,"无训练多 agent 框架"已经吃下大部分提升(40 → 67.7,涨 27.7 个点)。也就是说,单"四 agent 闭环 + patch 补丁"这套架构本身就值很多。
第二,三个知识网络中 Solver 网络贡献最大——从 67.7 涨到 75.6(@4.5k),涨 7.9 个点;Hacker 和 Oracle 各贡献 4–6 个点。但三个网络合起来的 Full system 跑到 82.42,比任何单一网络都高得多——说明它们之间不是替代关系,是叠加增益。
第三个细节我特别留意——每个网络的 @1.5k → @3k → @4.5k 这条线是单调上升的。Solver network 在 CodeContests 上 70.86 → 73.63 → 75.60,每 1500 道题大约涨 1.5~3 个点。这条曲线告诉我:知识网络确实在"经验越多越聪明",不是早期就饱和的假学习。
质疑环节:我看到 @1.5k 和 @4.5k 的差距大约只有 5 个点,那么如果继续扩到 10k、20k 题,能不能再涨?论文没给出更长的训练曲线,这是我会想追问作者的地方。可能存在 collapse 或者 saturation 风险,目前的实验规模还不足以判断。
🏆 Codeforces 真人擂台:从 GM 段冲进 LGM 段
这一节是 Solvita 论文里我觉得最能打动人的部分。
离线 benchmark 跑得再高,code agent 圈一直有个老问题:这些题模型见过没? AetherCode 号称"post-cutoff",但谁也保不齐数据污染。
Solvita 直接上 Codeforces 在 LLM 训练截止日期之后的 12 场比赛(rounds 952–963,混合 Div.2 和 Div.1+2),共 76 道题。每场比赛在官方时限内单次连续跑完,比赛结束后不允许任何修正——和人类选手一样的约束。
评级用 CodeElo 的方法:把 agent 的成绩插入官方 standings,反算 Elo 期望,得到每场的"等效评级"。
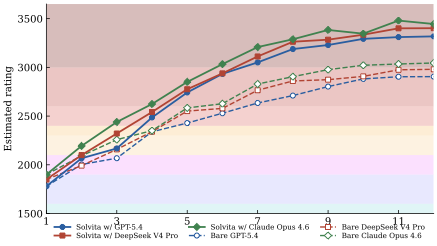
图 3:实线(Solvita)vs 虚线(裸底模)在 12 轮比赛中的评级演进。三条实线全部冲过 3000 分线进入 Legendary Grandmaster 段位(最深的红色带);三条虚线停在 2700–2850 分的 Grandmaster 段。
看这张图我有几个具体的观察:
1. Solvita 的三条实线在第 6 轮之后收敛到 ±80 分之内,而裸底模的三条虚线散布在 140 分的范围。这告诉你 Solvita 的增益不依赖于特定底模——GPT-5.4、Claude Opus 4.6、DeepSeek V4 Pro 三家完全不同的训练路线,套上同一套 Solvita 框架最后都到同一个高度。这种"跨底模收敛性"是个挺强的信号——说明涨的点真不是某个底模的内化特长被激发,而是 agentic loop 自己撑出来的能力。
2. Solvita 在第 1 场比赛就比裸跑高 200 分左右(约 1800 → 2000)。这个是冷启动加成——还没经过比赛积累经验,只靠四 agent 架构本身就值这 200 分。
3. 第 1 场到第 12 场之间 Solvita 涨了大约 1300 个评级点(1800 → 3100+)。这中间真正的"在比赛中学习"加成大约 500–700 分。也就是说,架构本身的红利 ≈ 学习累积红利,两者数量级相当。
至于 Legendary Grandmaster 这个段位的分量——Codeforces 全球大约只有 50–100 人长期保持在 LGM 段以上。所以你可以理解为:在这 12 场比赛的窗口里,Solvita 把一个底模的水平从"全球前 1%"推到了"全球前 0.001%"。
当然,12 场样本量不算大。也要客观说一句:Codeforces 评级是有方差的,单场比赛因为题型偏好造成的浮动很正常。再多跑 12 场会不会稳定在 LGM?这个论文没法回答。
🔍 错误类型分解:到底卡在哪里没解决?
我对这种"残余错误"的分析特别在意——因为它告诉你方法的天花板在哪。
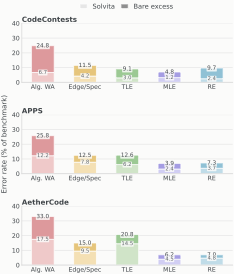
图 4:GPT-5.4 在三个 benchmark 上的错误率分解。Alg.WA = 算法错误,Edge/Spec = 边界 / 规约不匹配,TLE = 超时,MLE = 内存超限,RE = 运行时错误。
直觉上你可能以为:Hacker 这么强,TLE 和 RE 类的错误应该被压得很低。
但 AetherCode 这个最难的 benchmark 上,Alg.WA 仍然占了 16.5%,是所有类别里最高的。这告诉我:Solvita 解决了"代码能跑但跑出错"的细节问题,但没能解决"算法本身就想错了"的高阶推理问题。
这其实挺有意思——Hacker 攻击和 Oracle 测试覆盖的是"实现层"的 bug,但如果 Planner 一开始就选错了算法范式(比如该用 DP 你选了贪心),Oracle 造的测试再认证、Hacker 攻得再狠,也救不回来。Planner 网络对算法选型的判断力才是真正的瓶颈。
这也是为什么 Solver 网络贡献最大、Hacker 网络贡献最小——前者直接影响"写对率",后者只是确保"错的能被发现"。
💡 我的判断:Solvita 值不值得跟?
亮点:
- 架构层的真创新。把"可训练参数"从 LLM 权重移到外挂图的边权上,这个抽象层级的迁移让我想起 Hopfield 网络到现代记忆增强模型的演化——Solvita 等于在 code agent 这个垂直领域复刻了类似思路。
- 失败信号跨网络传播。一次 Hacker 攻击成功,全系统四张网络都更新,credit assignment 在多 agent 系统里被打得非常通。这种设计在以往的 multi-agent 框架里我没见过同等深度的实现。
- patch 补丁 vs 全量重写的对比是真硬货。88%~92% 的 token 节省 + 更高 pass@1,这个组合是工程上立刻就能复用的 trick——任何做 code self-correction 的项目都值得借鉴。
- Codeforces 真实赛场实测给了离线 benchmark 数据非常强的背书。
可疑的地方:
- 训练规模只到 5318 题。知识网络能不能扩到 50k、500k 题?论文没给。如果存在饱和或 collapse,那这套方法的天花板就有限。
- 缺少与 RL-trained 底模的对比。Solvita 比的全是 inference-time agent,但如果用同样的 5318 题去 RL 训一个底模,效果可能也不差——这个对照实验缺失。
- 5318 题的训练数据怎么来的、是否覆盖测试 benchmark 的同分布,paper 的 data pipeline 一节有但我读得不细,需要警惕 leakage 风险。AetherCode 是 post-cutoff 的没问题,但 CodeContests 和 APPS 是不是有重叠?
对工程的启发:
如果你也在做 code agent / 工具调用 agent / 任何需要"agent 越用越聪明"的系统:
- 强烈建议看看 Solvita 的事件总线 + 跨 agent contrastive 传播机制,这个设计哲学可以直接迁移到非 coding 场景。
- patch 补丁 vs 全量重写这件事,今天就值得在自己的 self-correction loop 里试一下。
- 不要再迷信"加个 RAG 就有记忆"——Solvita 让我重新意识到,结构化、可训练的图记忆和"塞文本回 prompt"完全是两件事。
最后一个追问:
Solvita 的每个 agent 网络都是单一任务驱动(Solver 学写代码、Hacker 学攻击)。但 OI 选手真正强大的能力是跨任务迁移——他做 ACM 题积累的策略选择能力,能直接用在面试题、用在生产代码 review 上。Solvita 的知识网络能不能跨 domain 迁移?比如把 Solver network 训练好之后挪到代码修复任务、或者形式化验证任务上去?
这个问题论文没回答。但我觉得这才是这条路真正有想象空间的地方——如果能跨 domain,那"agent 持续进化"就不再只是一个 OI 训练 trick,而是一个能撬动整个 AI 工程化方向的范式。
🔗 参考
- 论文链接:https://arxiv.org/abs/2605.15301
- 相关工作:
- AlphaCodium (Ridnik et al., 2024) — 多步代码生成 pipeline
- MapCoder (Islam et al., 2024) — 多 agent 代码生成
- LinUCB / Contextual Bandit (Li et al., 2010) — Solvita 知识网络的底层算法
- CodeElo (Quan et al., 2025) — Codeforces 评级估计协议
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我