SkillsVote:当智能体技能库长到百万级,怎么不让它把Agent带歪?
最近调智能体的时候碰到一个挺别扭的现象:往 SKILL.md 库里堆的技能越多,Agent 反而越容易跑偏。
直觉上这事不应该。技能多了,覆盖面广了,Agent 该更聪明才对。但实际上一个 Easy 任务,本来 baseline 能稳过,挂上一堆乱七八糟的技能描述后,模型反而开始照着某条不相关的 SKILL 去执行,最后 fail。
这不是个例。Anthropic 的 Claude Code Skills、OpenAI 的 Codex Skills 都开始把"技能即文件"当作 Agent 能力扩展的标准接口,GitHub 上的 SKILL.md 文件已经数以万计。但当你真把这些公开技能拉下来用,会发现一个尴尬的现实:质量参差不齐、环境耦合严重、彼此冗余甚至冲突,Agent 选错一个就直接拖崩任务。
这周看到 MemTensor 团队(《Memory³》那群人)放出的 SkillsVote 论文,正好就在治这个病。核心思路一句话:把 Agent Skill 当作有生命周期的工件来管——收集、画像、推荐、归因、演化每一步都要有门控,凭证据投票决定一条 skill 能不能进 Agent 上下文、能不能反过来改库。
效果不算夸张但很扎实:离线演化在 Terminal-Bench 2.0 上把 GPT-5.2 拉了 7.9 个点,在 SWE-Bench Pro 上线上演化拉了 2.6 个点,全程不改模型参数。
下面把这套机制拆开聊。
论文信息
| 项 | 内容 |
|---|---|
| 标题 | SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution |
| 作者 | Hongyi Liu, Haoyan Yang, Tao Jiang, Bo Tang, Feiyu Xiong, Zhiyu Li |
| 机构 | MemTensor (Shanghai) Technology |
| arXiv | 2605.18401 |
| 项目页 | skills.vote · github.com/MemTensor/skills-vote |
一、问题:技能库为什么会"反噬"Agent?
先说清楚 Agent Skill 是什么。它不是简单的 prompt 模板,也不是单纯的工具调用。一个标准的 SKILL 包是一个目录:
my-skill/
├── SKILL.md # 必需,描述能力、适用条件、用法
├── scripts/ # 可选,可执行脚本
├── references/ # 可选,参考文档
└── assets/ # 可选,模板、示例
它既包含可执行代码,又包含不可执行的流程指导——比 RAG 检索到的文本块要"重",比微调一个工具调用又要"轻"。这种半结构化的中间态正在成为公开 Agent 生态的事实标准。
但事情一旦上规模就难看了。论文里点了几个我之前也踩过的坑:
坑一:原始轨迹不能直接当技能。Agent 跑完一个任务留下一堆 step,里面混着真正起作用的策略、试错过程、环境噪声、特定任务的常量。直接把这条 trajectory 存下来当"经验",下次复用就是灾难。
坑二:技能描述不等于技能可用。开源 SkillsMP、skills.sh 上的技能,星标高、下载量大并不代表能在你的环境跑通。一个 SKILL.md 里写着"在 Ubuntu 22.04 上自动配置 Apache",但它默认你有 sudo、有外网、装了 certbot——这些前置条件根本不在搜索界面里。
坑三:渐进式披露不是免费午餐。Claude Code 和 Codex 的官方做法是"渐进披露"——先给 Agent 看一堆轻量元数据,需要时再加载全文。听起来很优雅,但当库里有几百上千条技能,仅凭名字和描述就能选对吗? SkillRouter 那篇论文已经实证过:技能正文里才是决定性的路由信号。
坑四,也是最致命的:库污染。Agent 跑完任务,你想"学到点东西"自动更新库。但如果不加判断地把每次成功经验写回去,库里很快就堆满了:
- 任务特定的常量(这次任务的端口号被写成 SKILL 的固定步骤)
- 环境侥幸(其实是缓存命中,不是技能起作用)
- 评估信号本身的歧义(评测 verifier 给了 success,但实际跑出来不对)
这就是核心矛盾:库越大覆盖面越广,但搜索空间也越大、污染风险也越大。
SkillsVote 想干的事:把"技能进 Agent 上下文"和"经验回写技能库"这两个动作都套上证据门控——让 skill 真正"投票"进 context,让证据真正"投票"回 library。论文名字 SkillsVote 就这么来的。
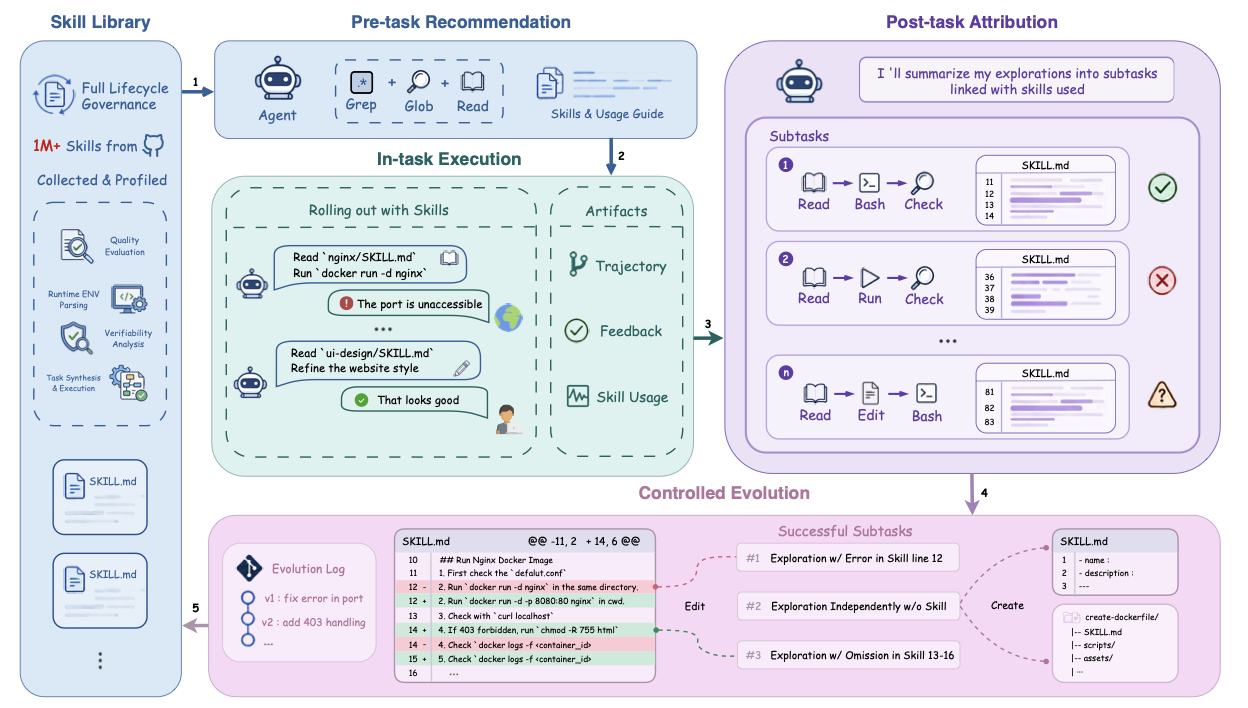
图1:SkillsVote 全生命周期闭环。一个百万级技能库经画像后,执行前通过 Agentic Library Search 暴露相关技能与用法指南;执行中记录轨迹和反馈;执行后把轨迹拆解成 skill-linked 子任务做归因;最终只让"成功且可复用"的发现回写库,触发 Edit 或 Create 操作
二、收集与画像:百万级技能怎么"挑食"
第一个阶段是收集。SkillsVote 从 GitHub 抓了一百万级的 SKILL.md 文件作为开源语料库,但关键不是抓得多,而是怎么打标签。
每个 skill 被画了三个维度的像:
1. 运行需求画像(Runtime Requirements)
这一层很务实,就是把"这个 skill 跑起来需要什么"显式拆出来:
- 操作系统假设(macOS only? Ubuntu only?)
- 写权限、sudo 需求
- 网络访问(要不要外网?要不要特定 endpoint?)
- API key / 环境变量
- 命令行工具(curl、jq、docker?)
- MCP server 依赖
我自己之前接 Claude Code 的时候就吃过这亏——一个号称"自动配置 nginx"的 skill 直接 sudo apt install nginx,但容器里根本没 sudo,整条 chain 卡死。把这些隐含假设拿出来当一等公民,对工程落地至关重要。
2. 质量画像(Quality)
三个子指标:一致性(步骤之间有没有自相矛盾)、完整性(关键步骤是不是少了)、任务导向性(是不是真的在解决一个问题,还是写成了纯科普)。
3. 可验证性画像(Verifiability)
这一层我觉得是整篇论文里最聪明的设计之一。问的是:这个 skill 能不能合成出可以被客观判断成败的任务?
- 成功条件是不是低歧义?
- 沙箱能不能复现?
- 任务实例的构造成本是不是合理?
通过这一关的 skill,SkillsVote 会反向合成任务——基于 skill 本身,生成 instruction + 可复现环境 + 可执行 verifier,跑真实 Agent-Model 组合,记录成功率、成本、执行轨迹。这一步把"静态描述"和"动态执行行为"挂上了钩。
不是所有 skill 都适合这条路。偏好驱动的(比如"让网页更美观")、开放世界的、硬件密集的,就停留在 profiled corpus 里,不强行做 benchmark 化。这点也很务实——不是所有经验都能机器验证,强行验证反而失真。
三、推荐:Agentic Library Search 而非静态匹配
收集与画像把"原料"备好了。接下来是执行前的第一道门——决定哪些 skill 暴露给 solver agent。
主流做法有两种,论文都不满意:
- 直接全库暴露:上下文爆炸,注意力被无关 skill 稀释
- 静态语义检索(top-k embedding):把 SKILL.md 当文本块切,丢掉了文件结构信息
SkillsVote 的做法叫 Agentic Library Search——简单说就是让一个独立的 recommender agent 去库里"逛",它不解题,只选 skill:
"Given a task and a profiled skill library, SkillsVote runs a separate recommendation stage. The agent does not solve the task. It searches the local skill library, selectively reads candidate SKILL.md files and related resources, and selects skills..."
这个 recommender 用文件系统原生的工具(grep、glob、read)逐个看候选 SKILL.md、看相关 reference,最后输出一个紧凑的技能子集 + 一份简短的用法指南。
这套思路其实和同期的 DCI、CodeScout、SWE-grep 是一脉相承的——让 Agent 直接和语料库交互,而不是消费一个固定 top-k 接口。我之前的判断是:这类"agentic retrieval"会逐步替代传统向量检索在长尾、结构化文档场景的位置,SkillsVote 算是把这个思路落到了技能库场景。
为什么不直接训一个 router 模型?SkillRouter 是那条路。SkillsVote 选择走通用 Agent 接口,好处是不需要额外训练,坏处是推理多一道。tradeoff 写得挺坦诚。
一个细节值得拎出来:recommendation 的输出会被记录下来作为后续归因的锚点。也就是说,执行完之后,系统能回看"我当初推荐了 X 这条 skill,Agent 到底有没有用?用对了吗?"——这是后面演化阶段做精确信用分配的前提。
四、归因:子任务级别才是黄金粒度
执行完成后,怎么把轨迹变成可以更新库的"经验单元"?这是论文最核心的设计冲突。
现有方案分两极:
- 任务级总结:把整条轨迹压成一句"我做了 X 任务,成功/失败"。粒度太粗,信用分配做不了——这次任务过了,到底是哪条 skill 起作用?
- 步骤级抽取:每个 tool call 都标注。粒度太细,单个命令行很少能构成"可复用的技能知识"。
SkillsVote 提出第三种粒度:子任务级归因(subtask-level attribution)。
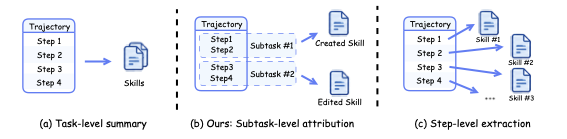
图2:三种归因粒度的对比。子任务级是中间的甜点——足够大能承载"过程知识",足够小能定位"责任归属"
那什么叫一个 subtask?论文给了非常明确的定义:
A subtask is the smallest semantically complete unit that can support library evolution: it has one standalone objective, one primary evaluation signal, and at most one associated skill context.
划重点:单目标、单评估信号、最多关联一个 skill。轨迹只在这三个边界变化时才切开,不是 Agent 每发一条命令就切一刀。
切完之后,每个 subtask 沿三个轴做归因压缩:
Axis 1 - Outcome evidence(结果证据类型)
这条 subtask 的成败是怎么被判定的?
- 客观环境反馈(命令退出码、文件内容比对)
- 人类偏好("这个 UI 看起来更好")
- 没有显式评估信号
这一分类很关键。它防止"verifier-backed 成功"、"主观目标成功"、"没证据的声称成功"被一视同仁。后面演化的时候,没证据支撑的 subtask 直接被挡在门外。
Axis 2 - Responsibility assignment(责任归属)
这条 subtask 成了/没成,到底是谁的功劳/责任?
- 技能引导执行(exposed skill 真的发挥作用了)
- 独立探索(Agent 自己想出来的)
- 看了无关 skill 后的探索(推荐错了,但 Agent 自救了)
- 环境因素(这次成了纯粹是网络通了)
- 评估信号本身(verifier 给了 success,但其实是误判)
Axis 3 - Reusable delta(可复用增量)
如果这条 subtask 和 skill 有关,到底是 SKILL.md 里的哪几行实际影响了执行? 是不是发现了 SKILL.md 里漏掉的前置条件?是不是发现了原步骤的错误?
注意只提取可复用的发现——任务特定的常量、试错的中间状态、机械操作的重复步骤都被丢掉。
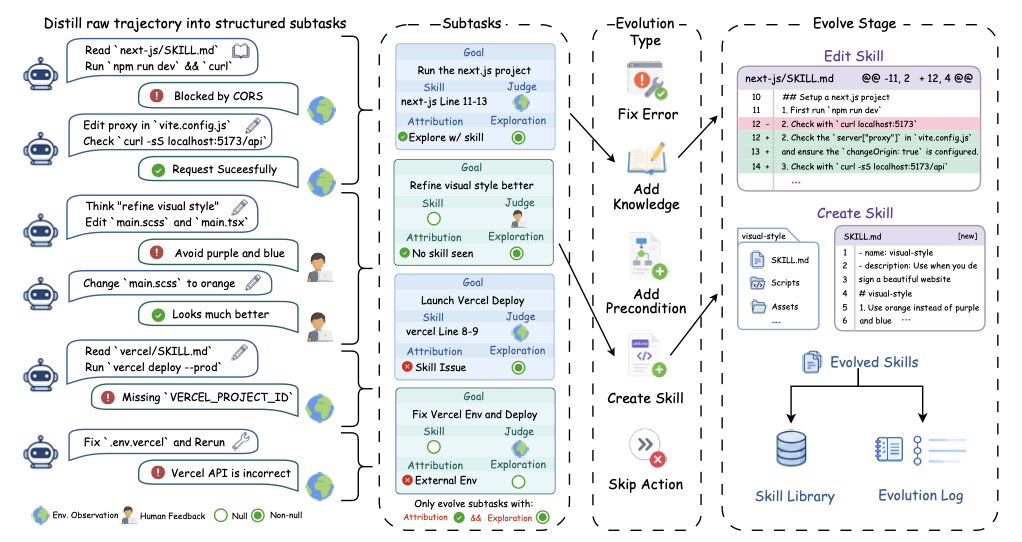
图3:从原始轨迹到 Skill Library 更新的完整流水线。注意中间那一栏的演化类型分类——Fix Error / Add Knowledge / Add Precondition / Create Skill / Skip Action,每种动作对应不同的库变更模式。最右侧 Edit Skill 是用 diff 形式精确改 SKILL.md 的几行,Create Skill 是新建一个完整的 skill 目录
五、演化:证据门控 + 聚合 + 路由
有了归因好的 evolvable units,怎么让它们影响持久化的技能库?SkillsVote 把这一步形式化为三个阶段:
Admissibility(准入)
只有成功 + 含可复用探索的 subtask 才能进入更新候选。失败的、不确定的、证据弱的,可以留着做诊断用,但不能直接触发 skill 变更。
这一条听起来朴素,但很多 skill-evolution 系统在这一步就翻车——它们把"失败 case"也喂回去希望模型"学到教训",结果学到的是噪声。
Aggregation(聚合)
通过准入的 units 在编辑前先按"它们支持同一个可复用过程/前置条件/绕坑方案"聚类合并。多次观察证据强化一次变更,而不是产出重复或碎片的 edits。这一条工程上很重要,否则同一个发现可能在不同任务里被独立写入 5 次,库会迅速臃肿。
Routing(路由)
合并后的证据组,被路由到具体的更新动作:
- Edit Skill:证据扩展了 Agent 实际用到的那条 skill → 最小修改(修错、补知识、加前置)
- Create Skill:证据反映的是当前 skill 边界外的独立能力 → 新建一个完整 skill 目录
- Skip:证据弱、冗余,或者和目标 skill 语义不对齐 → 跳过
"Skill evolution is conservative by design: every library change must be supported by attributed execution evidence, localized to the relevant skill boundary, and expressed as reusable procedural knowledge rather than a trajectory recap."
保守是这套设计的灵魂。库不是越大越好,每一次变更都要可追溯、可审计、可回滚。
六、实验:到底有没有用,能涨多少
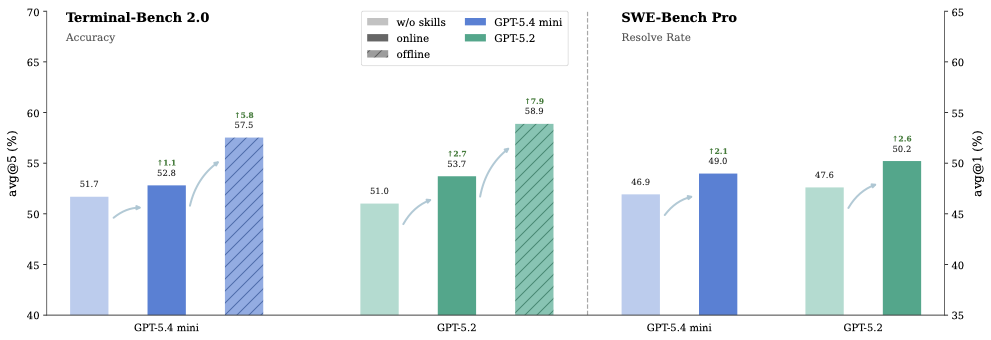
图4:主结果。两个 benchmark、两个模型、三个 setting 的总览。离线演化在 TB 2.0 上效果最显著,在线演化在两个 benchmark 上都稳定为正
实验用的是 Codex Agent + GPT-5.2 / GPT-5.4 mini,benchmark 选 Terminal-Bench 2.0(89 个困难终端任务)和 SWE-Bench Pro 公开集(731 个长程软件工程任务,11 个仓库)。
主表 1:Terminal-Bench 2.0 (avg@5 Accuracy)
| Model / Setting | Overall (89) | Easy (4) | Medium (55) | Hard (30) |
|---|---|---|---|---|
| GPT-5.2 Medium | 51.0 | 75.0 | 54.9 | 40.7 |
| ↳ online | 53.7 (+2.7) | 75.0 | 62.9 (+8.0) | 34.0 (-6.7) |
| ↳ offline | 58.9 (+7.9) | 90.0 (+15.0) | 65.1 (+10.2) | 43.3 (+2.7) |
| GPT-5.4 mini Medium | 51.7 | 75.0 | 61.8 | 30.0 |
| ↳ online | 52.8 (+1.1) | 75.0 | 63.6 (+1.8) | 30.0 |
| ↳ offline | 57.5 (+5.8) | 65.0 (-10.0) | 64.7 (+2.9) | 43.3 (+13.3) |
主表 2:SWE-Bench Pro Public (avg@1 Resolve Rate)
| Model / Setting | Overall (731) | 部分仓库(ansib / openl / quteb / nodeb) |
|---|---|---|
| GPT-5.2 Medium | 47.6 | 49.0 / 64.8 / 62.0 / 47.7 |
| ↳ online | 50.2 (+2.6) | 56.2 / 63.7 / 68.4 / 72.7 |
| GPT-5.4 mini Medium | 46.9 | 52.1 / 55.0 / 64.6 / 61.4 |
| ↳ online | 49.0 (+2.1) | 51.0 / 59.3 / 68.4 / 61.4 |
几个值得看的点:
1. 离线演化是最稳的信号
48 个 Terminal-Bench Pro 历史任务蒸出来的冻结库,迁移到 89 个未见过的 TB 2.0 任务,GPT-5.2 涨 7.9 个点。这个数据点说明:轨迹蒸出来的技能不是只对源任务过拟合,是真的形成了可迁移的操作经验。
2. 在线演化收益更小但稳定为正
从空库开始边跑边学,TB 2.0 上 GPT-5.2 涨 2.7、SWE-Bench Pro 上涨 2.6。说实话这个数我看到的第一反应是"还行"——在线场景本来就更难,早期没什么积累,能稳住不掉点已经不容易。
3. 一个让人警觉的负向数据
GPT-5.2 + online 模式在 Hard 子集上掉了 6.7 个点。论文自己也指出这一点:早期在线库还没积累出有效证据,但已经开始影响 Agent 决策,对难任务反而是噪声。这一点很诚实,没有藏。
推荐机制到底干了什么——消融

图5:推荐机制在 Hard 子集上的消融。这张图把"技能暴露不是中性的"这件事说得很清楚——红色块占比明显比绿色多
数据更直接:
- online 模式无推荐:mean gain/loss = +3.3 / 负 6.7(净负)
- online 模式有推荐:mean gain/loss = +6.0 / -6.0(净中性)
- offline 模式无推荐:mean gain/loss = +11.3 / -3.3
- offline 模式有推荐:mean gain/loss = +15.3 / 负 2.0(净大幅正向)
结论很硬:推荐不是锦上添花,是必需品。尤其在早期在线场景,它的主要作用是当噪声过滤器,挡住稀疏、未充分指定、弱相关的 skill。
这也解释了为什么主表里平均涨幅不算特别夸张——skill 是重尾效应:匹配对了显著加分,乱暴露则严重减分。两边一抵消,平均数就温和了。但消融里看分布,才看得到 SkillsVote 真正的价值。
七、离线演化动态:库是怎么"长大"的
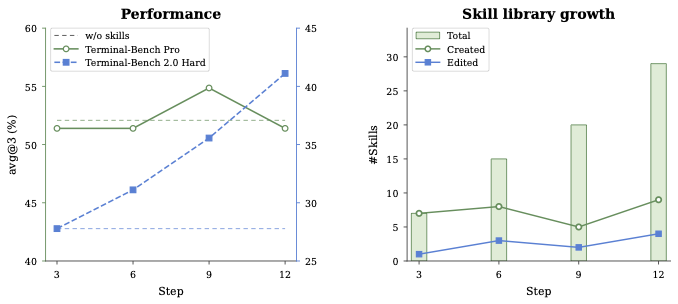
图6:离线演化的动力学。两个观察:(1) 源端表现可以波动,但迁移端单调上升,说明库的价值在"迁移性"而非"源任务拟合";(2) Edit 数量稳定增长,说明系统在合并证据而非简单堆叠新技能
这张图给了一个挺漂亮的实证:库越演化,迁移效果越好,但源端基准分反而不稳定。
我的理解是,这恰好证明了 SkillsVote 没有把 verifier 信号直接当训练目标——ground truth 只在归因阶段用来判定子任务成败,并不进入 reusable delta。所以"答案常量"会被丢掉,留下来的是"操作经验"。
右图的 Edit 列也很有意思。如果你的 evolution 设计是 append-only(每次成功就新建一个 skill),库会指数膨胀但内容高度冗余。SkillsVote 显示出明显的 Edit 行为——多次证据汇聚到同一条 skill 上做精修,这是 aggregation 阶段在起作用。
八、几个我觉得需要拍醒的地方
聊完干货说几句不太"客气"的判断。
1. 平均涨幅不算特别能打
7.9 / 5.8 / 2.6 / 2.1,这些数都还行,但你把它放在最近一年各种 Agent 自演化论文里看,并不算碾压。论文的核心价值不在数字大小,而在那套治理框架——它解释了为什么涨幅会有重尾、为什么 Hard 任务会掉点、为什么离线比在线效果好。这些机制性洞察可能比数字本身更有价值。
2. 推荐 stage 多了一道额外开销
跑一个独立的 recommender agent 去搜库,不是免费的。论文没特别强调成本对比,但工程上要注意——这道额外的推理调用,到底比"全库暴露 + solver 自己挑"省了多少 token?省下来的 token 又比多花的 token 多多少?这块期待后续 ablation。
3. Hard 任务在线掉点这件事还得继续治
GPT-5.2 online 模式在 TB 2.0 Hard 上掉 6.7 个点,这数不能装作没看见。论文给的解释是"早期证据不足",但这意味着 SkillsVote 在冷启动阶段对难任务是有副作用的。实际部署时是不是应该对 Hard 任务做更激进的过滤,或者在没积累到阈值之前直接走 no-skill baseline?这块论文没给方案。
4. 与 SkillRouter / DCI / Trace2Skill 的关系
论文的相关工作梳理得很全,但要客观说一句——recommend-as-search 的核心思想 DCI 和 CodeScout 已经在做,subtask-level attribution 也不是 SkillsVote 独创(AgentProcessBench、Trace2Skill 都有类似思路)。SkillsVote 真正的贡献是把这些点串成了一个"治理"的全栈框架,特别是把 evidence-gating + aggregation + routing 这条链路打通。它是一个系统级的整合工作,不是某个单点突破。这个定位认清楚了,论文的价值就清楚了。
九、工程启发:这套思路怎么搬到自己的项目里
如果你也在做 Agent 经验复用,下面几条 takeaway 我觉得值得直接抄:
Takeaway 1:永远不要把原始轨迹直接当经验。先切子任务,子任务用"单目标、单评估信号、最多一个关联技能"三条边界来切——这是个非常好的工程标准,比"按时间窗"或"按 tool call"都靠谱。
Takeaway 2:每条 skill 都必须有运行需求画像。OS、权限、网络、依赖,这些当作 schema 字段写进 SKILL.md 的 metadata。当库变大,光靠语义检索是选不出能跑的 skill 的。
Takeaway 3:写库要有 evidence gating。一个最小可行的实现:每次想把经验回写库前,先问三个问题——
- 这条经验有客观成功信号吗?(环境反馈 / 测试通过)
- 这条经验的成功能归因到具体某条 skill 吗?
- 这条经验是"可复用的操作模式"还是"任务特定的常量"?
三个问题都过了,才能动库。这个 gate 在自己的项目里实现并不复杂,但收益巨大——它直接挡掉了 80% 的库污染。
Takeaway 4:Edit 优于 Create。当多条证据指向同一个 skill 的同一个弱点时,优先选择精修(diff 几行),而不是新建一条 skill。库的大小不是质量指标,library compactness 才是。
Takeaway 5:离线冷启动比在线热启动更稳。如果有一批历史任务,强烈建议先离线蒸一个 cold-start library,再上线演化。论文的离线效果(+7.9)比在线(+2.7)好得多,工程上也对得上——离线场景能用完整任务集做对照、做归因,证据强度高得多。
收尾
回到开头那个观察:技能多不等于 Agent 强。这件事在 RAG 时代我们就吃过亏(检索文档越多 hallucination 越多),现在到 Skill 时代又要重新交一遍学费。
SkillsVote 给出的答案不算颠覆性,但它把治理这件事正式提上了台面——Skill Library 不是仓库,是有版本、有审计、有门控的工程制品。在 Claude Code、Codex 的 Skill 生态还在野蛮生长的当下,这个视角的重要性会越来越凸显。
我自己最大的感受是:当 Agent 能力增强的路径从"训更大的模型"转向"治更好的外部经验库",这条路线下,工程治理的权重会比模型能力的权重更高。SkillsVote 这种生命周期框架,可能就是这条路线的雏形。
至于最终数字会不会再涨一截,等 v2 论文吧。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我