SDAR:让每个 token 自己决定蒸馏强度——多轮 Agent RL 的一次"非对称信任"修补
你有没有踩过这样的坑:手里有一个看起来很合理的"老师",但用它蒸馏学生的时候,学生反而越练越烂。
我最早碰到这个问题是在做工具使用 Agent 的时候。当时拍脑袋的逻辑是:既然 RL 的轨迹级奖励太稀疏(一条 trajectory 几百个 token 共享一个 reward),那就再叠一个 token 级的蒸馏 loss 当辅助监督,让"老师"逐 token 教学生。模型选型也很省心——老师就是同一个模型,只是在 prompt 里多塞了一些 privileged context(参考答案、技能库、检索片段),所谓 On-Policy Self-Distillation(OPSD)。
结果:单轮任务上确实涨点,一搬到多轮 Agent 场景,KL 散度起飞、success rate 横着走。
最近浙大和美团出的这篇 Self-Distilled Agentic Reinforcement Learning(简称 SDAR),就是冲着这个具体的坑去的。他们没有发明新算法,而是非常诚实地指出:把 OPSD 朴素地拼到 GRPO 上,在多轮 Agent 上不仅不涨,还会比纯 GRPO 还差——尤其在小模型上塌得很难看。然后给了一个非常简单的修法:用一个 sigmoid 门控,让每个 token 自己决定要不要被蒸馏,以及被蒸馏多强。
读完我的第一反应是:"这事儿是不是太工程了?"但越往下看,越觉得这个判断"小模型上 teacher 平均比 student 还弱"的观察非常扎实,且整个修法落地代价极低——只加一个门控、保留 GRPO 主干、跑出来涨幅还不小。
一句话核心
| 项目 | 内容 |
|---|---|
| 痛点 | 把 OPSD 拼到多轮 Agent 的 GRPO 上,会因为「教师其实经常比学生弱」+「多轮轨迹漂移」而双重崩盘 |
| 核心方案 | 把 OPSD 当作带 sigmoid 门控的辅助 loss,让每个 token 用 detached 的 teacher-student gap 自己决定监督强度——正 gap 加大蒸馏,负 gap 软衰减 |
| 关键效果 | Qwen2.5-3B 上 ALFWorld 涨 9.4 个点、Search-QA 涨 7.0 个点、WebShop-Acc 涨 10.2 个点;Qwen3-1.7B 上 ALFWorld 从 GRPO 的 46.1 干到 53.9,而朴素 GRPO+OPSD 反而塌到 32.0 |
| 我的判断 | 不是底层突破,是对 OPSD 在多轮 Agent 上"伪命题"的一次精准纠正。值得复现,思路可以直接搬到自己的项目里。但它的 base RL 还是 GRPO,没碰 PPO/DAPO 那些更复杂的变体——能不能泛化还是个问号 |
论文信息
- 标题:Self-Distilled Agentic Reinforcement Learning
- 作者:Zhengxi Lu、Zhiyuan Yao、Zhuowen Han、Zi-Han Wang、Jinyang Wu、Qi Gu、Xunliang Cai、Weiming Lu、Jun Xiao、Yueting Zhuang、Yongliang Shen
- 机构:浙江大学 / 美团 / 清华大学(一作在美团实习期间完成)
- arXiv:2605.15155
- 代码:github.com/ZJU-REAL/SDAR

图1:SDAR 总览。左上:训练过程中 teacher-student gap 的演化——GRPO+OPSD(蓝)越训 gap 越负(教师越来越拖后腿);SDAR(橙)保持收敛趋势。右上:ALFWorld 上的 success rate 训练曲线,SDAR 从 step 80 后开始反超并持续拉开。下排:三个 benchmark 上 SDAR 几乎都是最高柱。
1. 问题:OPSD 在多轮 Agent 上为什么不 work?
先把背景理一下,免得后面看 loss 表达式一脸懵。
先聊一句 GRPO:DeepSeek R1 这一波把 GRPO 推成了 LLM RL 的"工业标配"。它的核心区别于 PPO 的地方在于:不用 critic,而是对同一 prompt 采样一组 G 个 response,用组内 reward 的相对排序当 advantage。简洁、好实现,但代价是 advantage 估计有偏。在多轮 Agent 的场景里,一条 trajectory 几百个 token 共享一个最终的轨迹级 reward——这就是所谓的信用分配难题:哪个 token 真正决定了成败?GRPO 对此其实没什么有效手段,所有 token 平摊一个 advantage。
正是这个稀疏监督问题,让大家想到要加 token 级的辅助 loss——蒸馏自然进入视野。
On-Policy Distillation(OPD):学生用自己采样的轨迹,被老师用 token 级的概率分布做监督。它的好处是天然避开了 offline distillation 的分布 mismatch。
On-Policy Self-Distillation(OPSD):老师和学生是同一个模型,区别只在于老师能看到 privileged context——比如检索回来的技能库、参考答案,而学生只能看到测试时的原始上下文。这种设定下"老师"其实只是"开了挂的自己"。
听起来很美。问题是,搬到多轮 Agent 上之后:
1.1 多轮 OPSD 的不稳定性
第一个观察很直接:学生一旦开始偏离老师走过的那条 trajectory,token 级监督就不再可靠。错误会沿轨迹累积,越后面的 turn 偏差越大。
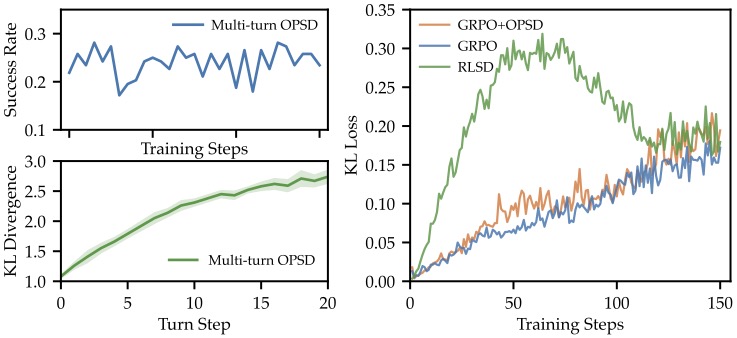
图2:预实验观察。左:multi-turn OPSD 单独训,success rate 完全没起来(上),且 KL divergence 随轮数从 1.0 涨到 2.8(下),轨迹越长老师越没用。右:RLSD(把 teacher-student gap 直接当 advantage 权重)训练初期 KL loss 飙到 0.30+,远超 GRPO 和 GRPO+OPSD。
这就是为什么 TCOD 之类的工作要专门做 curriculum learning——按 turn 数分阶段、按轨迹深度调度蒸馏强度。但这些方法都依赖手工设计的 rigid schedule,不够自适应。
1.2 一个更扎心的发现:教师其实经常比学生弱
第二个观察才是真正"打中我"的地方。
作者在 Qwen2.5-3B-Instruct 上跑了一个预实验:统计学生采样的所有 token 上,teacher-student log-prob gap \(\Delta_t = \log \pi_T(y_t|s_t^+) - \log \pi_\theta(y_t|s_t)\) 的分布。
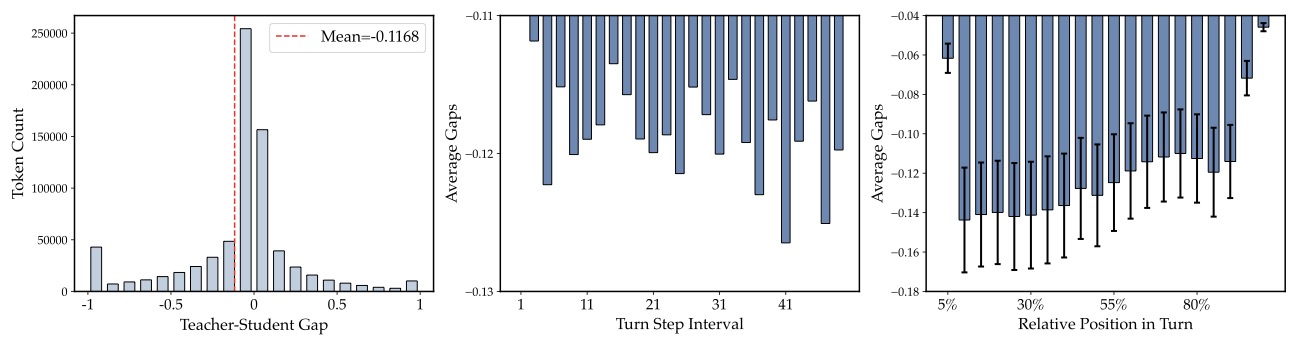
图3:Teacher-Student gap 的三视角分析。左:token 数按 Δ 分布的直方图,均值 -0.1168,约 50% 以上 token 落在负 gap 区间。中:随多轮 step 推进,平均 gap 从 -0.116 进一步降到 -0.130。右:单 turn 内部,相对位置越靠后 gap 越负。
超过一半的 token,老师反而给出更低的概率——也就是说,朴素 OPSD 在大多数 token 上的梯度方向是"把学生往老师的劣势区域推"。
这个现象作者归结为三个原因:
- Skill Quality:检索回来的技能可能压根不相关,或者重复、缺失。
- Skill Utilization:即便技能相关,老师也可能没有足够的探索经验来落地这些技能(这就是经典的 "learning by cheating" 问题——开挂的老师未必比脚踏实地的学生强)。
- Multi-turn Drift:随着轨迹展开,teacher-student gap 会沿 turn 越拉越宽(图3 中),早期的微小不匹配会被放大。
核心结论:privileged context 提供的指导是非对称的。正 gap(老师确信、学生还没学会)→ 强信号,应该多蒸馏;负 gap(老师其实拿不准)→ 弱信号,应该衰减。
说实话,看到这个观察的时候我"咯噔"了一下。之前我自己做 RAG 蒸馏的时候,默认假设是"开了挂的老师肯定比学生强"。但 OPSD 的"老师"说到底就是同一个 base model,开挂只是多看几行检索内容——它能不能用好那些 context,跟模型本身的 utilization 能力强相关。小模型上这个假设直接不成立。
2. 方法:让每个 token 自己决定监督强度
理解了问题之后,SDAR 的设计就特别直观。三个核心选择:
- RL 主、蒸馏辅:GRPO 的 policy loss 完全不动,保留 advantage 的无偏性。OPSD 作为辅助 loss 加在外面。
- 不直接用 Δ 做权重:直接拿 raw gap 当系数会在训练早期产生巨大梯度(这就是 RLSD 翻车的原因)。
- 用 sigmoid 门控做平滑、有界的调制:让 token 自己说话。
整体目标:
其中 SDAR 的 loss 形式:
- \(\text{sg}[\cdot]\) 是 stop-gradient——门控只影响"乘多大",不影响梯度方向
- \(\beta\) 是 sigmoid 的 sharpness(论文里取 5.0)
- \(\lambda_{\text{SDAR}}\) 是整体辅助 loss 的权重(论文里取 0.01)
这套门控的实际行为: - 当 \(\Delta_t \gt 0\)(老师比学生更确信这个 token),\(g_t \to 1\),蒸馏强度拉满 - 当 \(\Delta_t \lt 0\)(老师其实比学生差),\(g_t \to 0\),蒸馏被软衰减 - 当 \(\Delta_t \approx 0\),\(g_t \approx 0.5\),温和调制
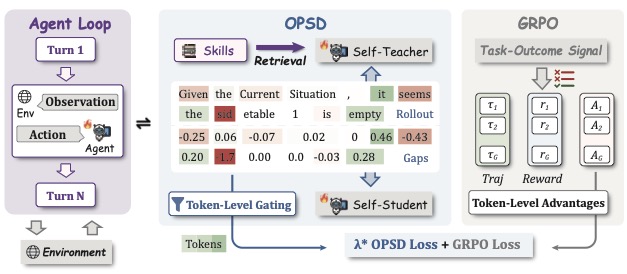
图4:SDAR 整体框架。中间这块是核心——同一个模型在 Self-Teacher 分支看到 Skills(开挂),在 Self-Student 分支看不到(裸跑),两者在每个 token 上算出 gap,然后被 Token-Level Gating 调制成 OPSD Loss。右侧 GRPO 分支照常算 token-level advantage。两个 loss 通过 λ 加权合成最终目标。
2.1 三种门控变体
作者还讨论了另两种门控信号:
| 门控类型 | 公式 | 直觉 |
|---|---|---|
| Gap gating(默认) | \(g_t = \sigma(\beta \Delta_t)\) | 直接看老师比学生强多少,最有针对性 |
| Entropy gating | \(g_t = \sigma(\beta h_t)\) | 学生熵越高(越不确定)就越要蒸馏,但容易误激活在"不确定但其实选对了"的 token |
| Soft-OR gating | \(g_t = \sigma(\beta[1-(1-h_t)(1-\Delta_t)])\) | 任一个信号大就激活,但选择性会被稀释 |
消融实验后默认用 Gap gating。
2.2 为什么用 reverse KL 而不是 forward KL
这个细节我觉得挺值得展开。OPSD 的 token 级 loss 选哪种 divergence 不是无关紧要的:
- Reverse KL \(D_{\text{KL}}(\pi_\theta \| \pi_T)\) 是 mode-seeking:学生倾向于把概率质量集中在老师支持的某个模式上,自动忽略老师不支持的 token。
- Forward KL \(D_{\text{KL}}(\pi_T \| \pi_\theta)\) 是 mode-covering:学生被迫覆盖老师所有的支持区域,会不加区分地吸收所有信号,包括不可靠的负向指导。
在 partial reverse distillation 的场景下(老师经常比学生差),mode-covering 等于"无差别吃下所有不可靠信号",这跟 SDAR 的门控哲学正好相反。所以默认用 reverse KL,跟 gating 形成"双重过滤"。
这个细节让我觉得作者是真的在思考工程意义,不是为了 ablation 而 ablation。
3. 训练动态:门控真的在起作用吗?
光设计漂亮不行,得证明门控真的在做作者宣称的事。论文给了一组关键的训练动态图:
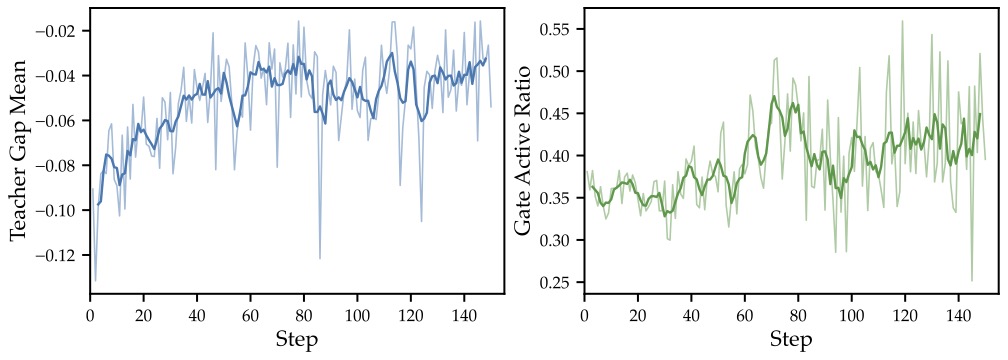
图5:Qwen2.5-7B 在 ALFWorld 上的训练动态。左:mean teacher-student gap 从 -0.10 收敛到接近 -0.04,证明 SDAR 没有让 gap 越来越负(避开了图3 中观察到的恶化趋势)。右:gate active ratio 训练初期严格低于 0.5(正确地抑制了负向 token),后期缓慢爬升,反映学生进步、更多 token 进入构建性蒸馏区间。
两个关键发现:
- 训练初期 gate active ratio 严格 < 0.5——也就是说,门控正确识别并压制了那超过一半的负 gap token。
- 随着训练推进,更多 token 进入"老师能给正反馈"的区间,ratio 缓慢上升——这就是作者说的 token 级自适应 curriculum。
对比图1 左上的 GRPO+OPSD 曲线:朴素拼接的 gap 越训越负,说明蒸馏 loss 把学生往老师的劣势区域推。SDAR 的 gap 保持稳定甚至收敛——这就是门控在做的事。
4. 实验结果:数据说话
主表覆盖三个模型规模(Qwen2.5-3B、Qwen2.5-7B、Qwen3-1.7B)× 三个 benchmark(ALFWorld、Search-QA、WebShop)× 多个 baseline。我把 SDAR 关心的核心对比挑出来:
4.1 主结果对比
| Model | Method | ALFWorld | Search-QA | WebShop-Score | WebShop-Acc |
|---|---|---|---|---|---|
| Qwen2.5-3B | GRPO | 75.0 | 36.4 | 79.8 | 63.3 |
| GRPO+OPSD(朴素拼接) | 81.2 | 44.6 | 77.8 | 66.4 | |
| Skill-SD | 73.4 | 44.1 | 75.9 | 64.0 | |
| RLSD | 79.7 | 43.8 | 84.4 | 66.4 | |
| SDAR | 84.4 | 43.4 | 85.0 | 68.0 | |
| Qwen2.5-7B | GRPO | 81.2 | 42.0 | 80.9 | 72.6 |
| GRPO+OPSD | 80.4 | 47.0 | 86.8 | 76.5 | |
| Skill-SD | 85.1 | 47.8 | 86.1 | 76.5 | |
| RLSD | 82.0 | 49.0 | 87.4 | 77.3 | |
| SDAR | 85.9 | 49.0 | 89.4 | 82.8 | |
| Qwen3-1.7B | GRPO | 46.1 | 40.8 | 67.3 | 38.3 |
| GRPO+OPSD | 32.0 ⬇️ | 42.2 | 70.7 | 38.3 | |
| Skill-SD | 52.3 | 40.8 | 81.8 | 53.9 | |
| RLSD | 42.2 | 40.6 | 74.0 | 50.8 | |
| SDAR | 53.9 | 41.9 | 76.8 | 58.6 |
几个关键观察:
(1)小模型上朴素 OPSD 真的会塌
Qwen3-1.7B 上 GRPO+OPSD 的 ALFWorld 只有 32.0%,比纯 GRPO(46.1%)还差 14 个点。这就是"教师其实比学生弱"+"多轮漂移"双重作用的具体表现。SDAR 在同样设定下做到 53.9%,逆袭 7.8 个点。
(2)WebShop-Acc 上 SDAR 拉开最大
Qwen2.5-7B 上 WebShop-Acc 从 GRPO 的 72.6 提到 SDAR 的 82.8,涨了 10.2 个点。WebShop-Acc 衡量的是"完全买对商品"的严格成功率,这个指标对 token 级精确度敏感——一个错的属性、一个错的选项就 0 分。SDAR 的 token 级门控在这里发挥了最大作用。
(3)Skill-GRPO 暴露"伪学习"问题
Skill-GRPO 训练时挂着 skills,测试时不挂的话(Skill-GRPO 列),ALFWorld 上 3B 从 80.5(带 skills)暴跌到 60.2(不带 skills)——比纯 GRPO 还差。这说明 Skill-GRPO 是把 skills 当外部拐杖,没有真正内化到参数里。
SDAR 的测试设定完全不需要 skills,但依然超过 Skill-GRPO 带 skills 的版本——这是作者重点强调的"skills internalization"。
说实话,看到 Skill-GRPO 这个对比的时候,我才意识到"用了 skills 在 RL 里"和"模型真的学会了 skills"完全是两回事。这个对比设计得挺巧妙的。
4.2 鲁棒性:随机检索也能涨?
作者还做了一个让我有点意外的鲁棒性测试:把 skill 检索质量人为变差,看 SDAR 会塌成什么样。
具体做法是固定 SDAR 的超参(\(\lambda=0.01\)、\(\beta=5.0\)),换四种不同质量的检索策略:
- UCB Retrieval:把技能选择当多臂老虎机问题,按 UCB 准则在线学习
- Keyword Matching(KM):用关键词匹配任务描述,直接命中预定义类别
- Full Retrieval:把所有相关技能全部拼到 context
- Random Retrieval:完全随机选一个技能
| Retrieval | ALFWorld | WebShop-Score | WebShop-Acc |
|---|---|---|---|
| UCB | 86.8 (+5.6) | 87.5 (+6.6) | 81.2 (+8.6) |
| Keyword Matching | 85.9 (+4.7) | 89.4 (+8.5) | 82.8 (+10.2) |
| Full Retrieval | 83.2 (+2.0) | 87.2 (+6.3) | 78.1 (+5.5) |
| Random Retrieval | 83.1 (+1.9) | 82.5 (+1.6) | 73.6 (+1.0) |
| w/o OPSD(pure GRPO) | 81.2 | 80.9 | 72.6 |
随机检索都能涨——ALFWorld 涨 1.9 个点、WebShop-Score 涨 1.6 个点、WebShop-Acc 涨 1.0 个点。
这个发现让我对门控机制的"过滤能力"有了新的认识。如果门控真的在起作用,那低质量检索带来的噪声会被自动衰减——这就是为什么随机检索也能跑赢 baseline。
不过我也有个怀疑:随机检索的提升幅度(+1.9)跟 KM(+4.7)拉开了 2.5 倍,说明门控并不是"完全过滤"噪声,只是软衰减。能涨主要还是因为正向信号没被淹没。这个结果支持作者的故事,但不能解读成"检索质量不重要"——它更准确的解读是"门控对检索噪声有 graceful degradation"。
换个角度想,这个结果其实揭示了一个反直觉现象:随机给学生看一些不相关的内容,反而能轻微提升性能。可能的原因是 random skills 在 token 级上提供了少量"正确"信号(毕竟同任务的常见动词、状态描述都可能撞上),而 SDAR 的门控把负信号全部过滤了。这相当于一种"廉价数据增强"。
4.3 关键消融:β 和 λ 的工程意义
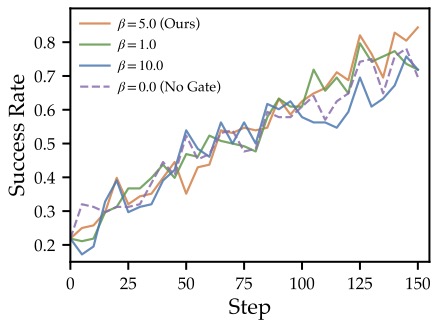
图6:sharpness β 的消融。β=0 退化为均匀蒸馏,继承了朴素 OPSD 的不稳定性;β=10 把门控逼近二元化,丧失了对 borderline token 的渐变调制能力;β=5 是 sweet spot。
几个工程结论: - β=0(无门控)= 朴素均匀蒸馏,最差。证明门控不是装饰,是核心。 - β=10 又下滑——把 sigmoid 逼近 step function,丢失了 borderline token 的平滑过渡。 - λ=0.01 是最优。λ=0.1 时蒸馏 loss 主导,把学生往老师的劣势区域推(因为平均 gap 是负的);λ=0.001 时蒸馏太弱起不到作用。
λ=0.01 这个值很有工程含义:它说明在 partial reverse distillation 的场景下,蒸馏只能作为微小辅助信号,不能作为主导。这个观察对所有 RL+蒸馏混合方法都有参考价值。
5. 我的判断
读完整篇论文,我有几个明确的判断:
5.1 不是底层突破,但是精准纠正
SDAR 没有发明新的 RL 算法,也没有提出新的蒸馏框架。它做的事情,其实就是把 OPSD 在多轮 Agent 上的伪命题暴露出来——之前所有 OPSD 工作都默认"老师比学生强",SDAR 用一个简单的预实验证明在 self-distillation 场景下这个假设是错的。
然后给了一个工程代价极低的修法:一个 sigmoid 门控、一个 stop-gradient、一个 λ 加权——三行代码的事。
这种"指出伪问题 + 给出最小修补"的论文,其实是我最喜欢的类型。比起那些"新算法 + 全套 ablation"的论文,SDAR 的核心 insight 更扎实,迁移性也更强。
5.2 局限在哪?
但批判地看,几个问题作者没有充分讨论:
(1)base RL 锁死在 GRPO
所有实验都是 GRPO + SDAR。但 GRPO 本身的 advantage 估计是有偏的(group-relative,没有 critic)。SDAR 宣称"保留 RL advantage 的无偏性"——这个无偏性其实是在 GRPO 的偏估计基础上谈的。换成 PPO、DAPO、VAPO 之后还能 work 吗?
(2)"Skills" 的具体设计被一笔带过
整篇论文把 skill bank 当成黑盒,引用了 SkillRL,没有详细分析 skill 的内容质量。但前面的鲁棒性测试又说"随机检索也能涨"——这两点放在一起其实有点矛盾:如果 skills 质量完全不重要,那 SkillRL 这个工作本身的价值是什么?我怀疑实际情况是"good skills 涨更多、bad skills 也能涨一点",但作者没有给出 skills 内容的细粒度分析。
(3)长轨迹场景的极限测试缺失
ALFWorld、WebShop、Search-QA 这三个 benchmark 都是中等轨迹长度(10-50 turns)。SDAR 宣称解决了"多轮漂移"问题,但更长轨迹(如 SWE-Bench 这种 100+ turn 的代码任务)上效果如何,没有实验支撑。
(4)Search-QA 上 SDAR 输给 GRPO+OPSD
Qwen2.5-3B 的 Search-QA 上,GRPO+OPSD 拿到 44.6(最高),SDAR 只有 43.4。作者没有专门讨论这个反常情况。一个可能的解释是 Search-QA 任务的 token 级 gap 分布跟 ALFWorld 不同(search query 的格式比较固定,老师的检索增强更直接),但这只是猜测。
5.3 工程启发:可以直接搬
如果你正在做: - 多轮 Agent 的 RL post-training - RAG + RL 混合训练 - 任何"用辅助 loss 补充稀疏 reward"的场景
SDAR 的核心思想可以几乎无修改地搬到你的 codebase:
# 伪代码:在你的 GRPO/PPO 训练循环里加几行
with torch.no_grad():
teacher_logp = policy(input_with_privileged_context).gather(-1, sampled_tokens)
student_logp = policy(input_without_privileged_context).gather(-1, sampled_tokens)
delta = teacher_logp - student_logp # detached
gate = torch.sigmoid(beta * delta) # token-level gate
# 蒸馏 loss
aux_logp_teacher = policy(input_with_privileged_context).gather(-1, sampled_tokens)
aux_logp_student = policy(input_without_privileged_context).gather(-1, sampled_tokens)
sdar_loss = -(gate * (aux_logp_teacher - aux_logp_student)).mean()
total_loss = grpo_loss + lambda_sdar * sdar_loss # lambda_sdar = 0.01
工程经验值(来自论文): - \(\lambda_{\text{SDAR}} = 0.01\) - \(\beta = 5.0\) - 用 reverse KL 而不是 forward KL / JSD - gate 必须 detach,避免梯度穿透
5.4 一个更大的追问
SDAR 暴露的"教师其实比学生弱"现象,我觉得不止存在于 OPSD。
在所有 self-distillation 设定下,这个问题都可能存在——只要老师不是一个真正更强的模型,而是同一个 base + 一些外部信息。Self-RAG、self-rewarding、self-refine 这些方法都有类似的潜在风险:我们以为开了挂的自己更强,但实际上它可能只是被外部噪声干扰得更厉害。
SDAR 的门控思路其实可以看作一种通用的"非对称信任"框架——只要你能定义出某种 token 级或样本级的 confidence gap,就可以用类似的 sigmoid 门控做调制。
这才是这篇论文最值钱的地方。技术细节是修补,但思考方式可以泛化。
6. 一句话收尾
如果你之前在做 OPSD/RL 混合训练时被"老师不靠谱"卡过,SDAR 是一个非常实用的修补方案:一个 sigmoid 门控,几行代码,搞定多轮 Agent 上的非对称信任问题。
更重要的是,它指出了一个之前被默认接受的伪命题——self-distillation 的老师不一定比学生强。这个观察的价值,大于方法本身。
参考资料: - 论文:Self-Distilled Agentic Reinforcement Learning, arXiv 2605.15155 - 代码:github.com/ZJU-REAL/SDAR - 相关:GRPO(DeepSeekMath)、OPSD(zhao2026)、RLSD(yang2026)、Skill-SD(wang2026)、TIP(xu2026)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我