把多跳 RAG 写成一段 Python 程序:当推理过程从"自由发挥"变成"编译器说话"
一段开场白
先聊一个我在工程上经常碰到的尴尬场面。
做多跳 RAG 的同学应该都有过这种经验——问一句"Jed Hoyer 和 John William Henry II 谁年纪大",模型先去搜了一通,搜回来的文档里混进了一个 Henry II of England(1133 年出生的英格兰国王),然后它真的拿这个数据去比较生日了。整条推理链看起来很顺,每一步"看起来都对",但最终答案错得离谱。
更糟的是,你想 debug 它都不知道从哪下手。模型在自由文本里推理,中间状态是"嵌在叙述里"的——没有变量、没有断点、没有 stack trace。错误是它自己产出的,反思也是它自己做的,相当于让被告自己当法官。
这篇 5 月刚挂出来的 PyRAG,给出了一个我觉得很顺眼的解法:别让模型在文字里推理了,让它写一段 Python 程序,每步调一个 retrieve 或者 answer 工具,中间结果存成变量,最后由 Python 解释器跑出答案。
核心摘要
PyRAG 把多跳 RAG 重新表述成"程序合成 + 执行"——给定一个问题,分解 Agent 切成原子子查询,规划 Agent 写出一段调用 retrieve(query) 和 answer(query, docs) 的 Python 代码,由 Python 解释器逐步执行,中间答案作为变量在步骤之间传递。这套形式化天然支持两个不用训练的能力:编译器驱动的自修复(拿运行时异常当反馈去改代码)和执行驱动的自适应检索(某一步证据不够就把 topk 调大重跑那一步)。
在五个 QA 基准上,免训练版本 PyRAG 相比 Vanilla RAG 平均提升 11.8 个 EM,在 Bamboogle 上直接干到 25.5 个点;RL 训练版本 PyRAG-RL 在 7B 量级 RL 方法里拿到平均 EM 最高分 39.2,并且把同样的训练管线迁移到 Qwen3-4B 和 LLaMA-3.1-8B 都能稳定泛化。
我自己读完的感觉是:这是一篇"问题表述(problem formulation)"层面的工作。它没有发明新的检索器、没有提新的奖励函数,但把"多跳 QA 是什么"这件事换了一种描述,整条管线该装的东西自然就装上了。属于那种事后看会拍大腿"对,本来就该这样"的类型。
论文信息
- 标题:Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
- 作者:Jiashuo Sun, Jimeng Shi, Yixuan Xie, Saizhuo Wang, Jash Rajesh Parekh, Pengcheng Jiang, Zhiyi Shi, Jiajun Fan, Qinglong Zheng, Peiran Li, Shaowen Wang, Ge Liu, Jiawei Han
- arXiv:2605.12975 (2026 年 5 月 13 日)
- 代码:https://github.com/GasolSun36/PyRAG
为什么"自由文本推理"是个糟糕的接口
要理解 PyRAG 在解决什么,得先看清楚现在主流多跳 RAG 的几条路子各自烂在哪。论文里那张对比图特别清楚:
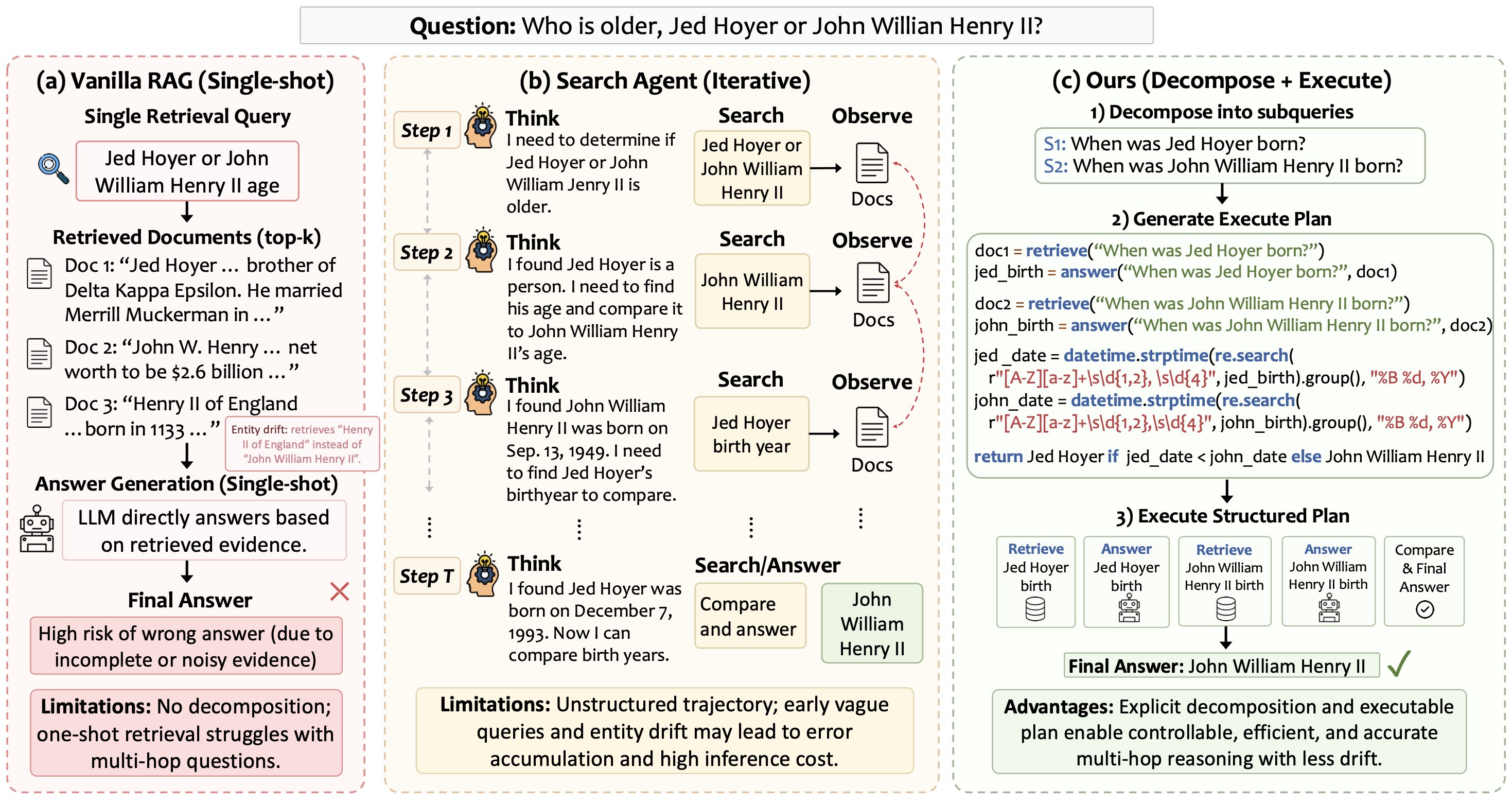
图1 给的例子还是那个"谁年纪大"的多跳问题。左边 Vanilla RAG 一把检索完事,问题中两个人名拼在一起搜,回来的 top-k 文档里既有 Jed Hoyer 也混进了一个无关的 Henry II of England,模型直接拿这堆东西生成答案,错率很高。中间 Search Agent 用 ReAct 那套 Think-Search-Observe 迭代了好几轮,但中间出现典型的 entity drift——第 3 步它去搜 "John William Henry II" 的时候,因为前文积累的不确定性,查询慢慢漂成了 "Henry II of England",错误就这样跨步扩散。右边是 PyRAG,先切两个子查询,然后写一段 Python:每个人各起一行 retrieve,再用 answer 抽出生日字符串,再用 datetime.strptime 解析成日期对象,最后一个三目表达式比较大小返回结果。
看明白这张图,PyRAG 的卖点就站住了一大半。
我用工程语言重新说一遍这几种范式的本质区别:
| 维度 | Vanilla RAG | Search Agent(ReAct/Self-Ask) | PyRAG |
|---|---|---|---|
| 推理表示 | 一次性自然语言生成 | 多步自然语言交替 | Python 程序 |
| 中间状态 | 完全隐式 | 嵌在 prompt 历史里 | 显式变量 |
| 检索查询 | 来自原问题 | LLM 现编 | 来自分解出的子查询 |
| 反馈信号 | 无 | LLM 自反思 | 编译器异常 + 执行结果 |
| 可追踪性 | 低 | 中(但叙述化) | 高(trace 即代码执行轨迹) |
| 错误检测 | 由产出错误的同一个模型 | 由产出错误的同一个模型 | 由 Python 解释器 |
关键差异在最后两行。Search Agent 路线最大的脆弱点不是"它不知道要分步",而是"分步的状态没地方存"——它只能把上一步的答案塞进下一步的 prompt 里继续生成,中间任何一处叙述漂移,下游全跟着歪。所谓的"self-reflection"其实是让同一个 LLM 既当运动员又当裁判,本身就是个没有 grounded 信号的反思。
PyRAG 干的事情,说到底就是把"中间状态"从 prompt 历史里搬到 Python 变量空间——这一搬就连带把"反馈来源"也从模型自身搬到了 Python 解释器。
顺便提一句,之前 PAL、Program-of-Thoughts 这类工作也用过 code 来辅助推理,但它们假设证据在输入里就给齐了(封闭表格、给定文档),重点是用代码做算数和符号操作。开放域多跳 QA 不一样,后面的检索查询要依赖前面的答案——而前面的答案又是检索出来才知道的。所以 PyRAG 才需要 retrieve / answer 这两个运行时才执行的工具调用,不能在合成代码的时候就预知答案。这是它和早期 program-guided reasoning 的本质分界。
PyRAG 的三段式:分解、规划、执行
整体框架不复杂,论文那张大图把所有部件都标了出来:
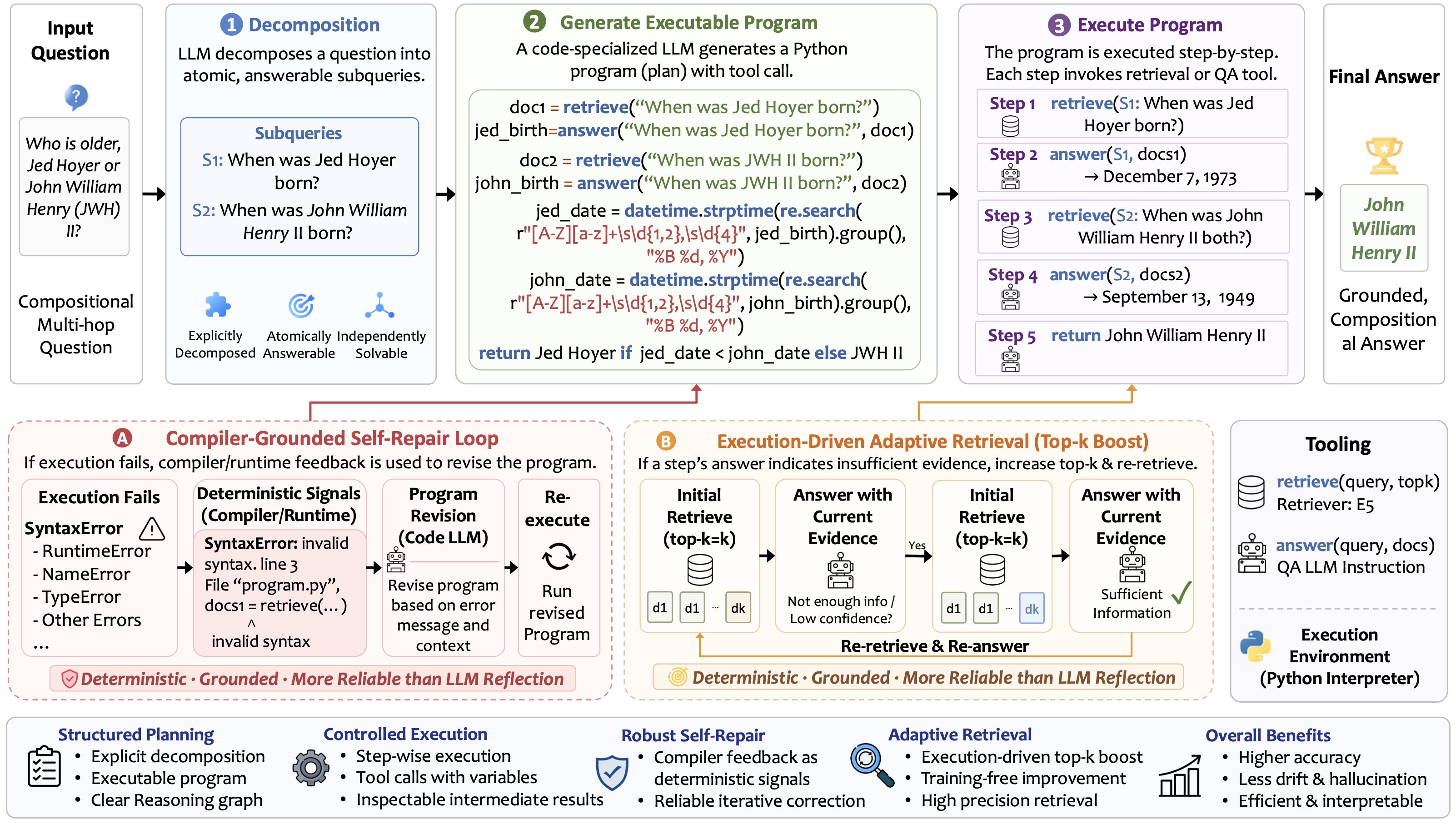
图2 从左到右分三段。Decomposition Agent 把输入问题切成原子可答子查询(S1: When was Jed Hoyer born? S2: When was John William Henry II born?);中间 Plan Agent 是核心,用一个 code-specialized LLM 生成完整的 Python 程序,包含 retrieve、answer 调用,以及把字符串型生日解析成 datetime 对象再比较的逻辑;右边 Execute Program 把代码丢给 Python 解释器逐步跑,每步记录到 trace 里。下方两个浅色框是两个 refinement 机制:A 是 Compiler-Grounded Self-Repair,编译/运行异常作为信号让 Plan Agent 改代码再跑;B 是 Execution-Driven Adaptive Retrieval,当某一步 answer 返回"unknown"之类的兜底响应时,把那一步的 topk 从 5 提到 10 重跑。
来逐部分聊聊,重点是后两个。
Plan Agent:让 code LLM 干 code LLM 擅长的事
这部分的设计哲学其实很简单——既然要写程序,就该让 code-specialized 模型来写。论文里专门做了一个对照实验(4.2 节的 Effect of Model Specialization):
- 在 Vanilla RAG 这个接口下,把 instruction-tuned 模型换成 code-specialized 模型,HotpotQA 上 28.9 → 29.1,2WikiMQA 上 18.9 → 18.6——基本没差别甚至略降。
- 在 PyRAG 这个接口下,code 模型一致优于 instruction 模型,HotpotQA 上 +1.8,2WikiMQA 上 +6.9,Bamboogle 上 +2.0。
这个结果其实挺有意思的。它在告诉我们一件事:code model 的能力不是普适地"更强",而是要在 program synthesis 这种和它训练目标对齐的接口下才显形。同一个能力,接口错了就发挥不出来。论文里把这个结论上升为"model capability and reasoning interface must be co-designed",我觉得这话说得到位。
写 prompt 工程的同学应该会有共鸣——你能感觉到某个模型"内部其实知道答案",但它就是不肯按你要的格式输出。这就是接口和能力的错配。
两个工具 API:retrieve 和 answer
API 设计得很克制,只有两个:
为什么 answer 还要单独存在、不直接让 plan 模型自己看 docs?因为这样把规划和理解做了干净的分离。Plan Agent 只负责知道"我需要从这堆文档里抽什么",至于具体怎么抽是 Answer Agent(一个 instruction-following LLM)的事。Plan Agent 自己看不到检索回来的文档内容——这在工程上是一个干净的解耦。
而且这个分工天然支持变量复用:第一步抽出来的生日字符串 jed_birth 可以在第三步的字符串处理中复用,第二步的 john_birth 同样可以。文本表示做不到这点——你的"上一步答案"只能以"我刚才说他生于 1973 年 12 月 7 日"这种叙述化形式出现在 prompt 里,不能被精确引用。
Execution-Guided Reflexion:两个不用训练的"白送"能力
这部分是我最喜欢的设计,因为它真的是从形式化里长出来的,不是硬塞的。
Compiler-Grounded Self-Repair:程序跑出运行时异常(SyntaxError、NameError、TypeError 等),把 traceback 喂回去让 Plan Agent 改一版。和 LLM self-reflection 的本质区别在于,这个信号是确定性的、grounded 的——Python 解释器告诉你第几行哪个变量没定义,这是事实,不是另一个 LLM 的猜测。
Adaptive Retrieval:如果 answer() 调用返回了哨兵词("unknown"、"cannot answer"),系统就把那一步的 topk 从 5 提到 10 重跑。注意这是"哪一步缺证据就只调哪一步",而不是整条链推倒重来——这种局部修复的颗粒度,文本范式同样做不到。
论文在 efficiency 分析里给了个数:self-repair 大概在 5% 的 query 上触发,adaptive retrieval 在约 20% 的 query 上触发。说明大多数情况下 plan 一把过,主要是"证据不够"这个问题更普遍——这其实也间接说明 Plan Agent 写出可执行代码的能力本身已经很可靠了。
主实验:能打的数字
先看免训练设置下的主表。原文用 Qwen2.5-7B-Instruct 和 Qwen2.5-72B-Instruct 两个 backbone:
Qwen2.5-7B-Instruct(免训练)
| 方法 | PopQA | HotpotQA | 2WikiMQA | MuSiQue | Bamboogle | 平均 |
|---|---|---|---|---|---|---|
| Direct Inference | 14.0 | 18.3 | 12.6 | 3.1 | 12.0 | 12.0 |
| CoT | 5.4 | 9.2 | 10.8 | 2.2 | 23.2 | 10.2 |
| Vanilla RAG | 26.7 | 28.9 | 18.9 | 4.7 | 16.0 | 19.0 |
| Self-Ask | 29.4 | 30.2 | 21.5 | 6.8 | 22.1 | 22.0 |
| IRCoT | 32.6 | 32.7 | 24.8 | 9.1 | 24.3 | 24.7 |
| ITER-RETGEN | 31.4 | 32.5 | 28.9 | 8.7 | 29.6 | 26.2 |
| PyRAG | 33.5 | 34.0 | 33.4 | 11.8 | 41.5 | 30.8 |
| Δ vs Vanilla | 涨 6.8 | 涨 5.1 | 涨 14.5 | 涨 7.1 | 涨 25.5 | 涨 11.8 |
Bamboogle 上 41.5 vs 16.0,提升 25.5 个点。这个数据集是 Press 等人在 Self-Ask 那篇文章里特地为"分解推理"压力测试设计的,组合多跳成分高、容易出现 entity drift。PyRAG 在这种最考验"中间状态管理"的基准上吃得最饱,符合它的设计预期——也算是一种"内在一致"的证据。
PopQA 这种相对偏单跳的基准,PyRAG 没拖后腿(33.5 vs 26.7),说明结构化分解的开销没有伤害到简单 query。这点其实挺关键,很多花哨的多跳方法在单跳上反而会变差。
再看 RL 训练设置(7B 量级,HotpotQA 训练域内、其余三个域外):
| 方法 | HotpotQA | 2WikiMQA | MuSiQue | Bamboogle | 平均 |
|---|---|---|---|---|---|
| Vanilla RAG | 28.9 | 18.9 | 4.7 | 16.0 | 21.3 |
| RAG-SFT | 32.4 | 22.6 | 6.8 | 27.1 | 22.2 |
| RAG-RL | 35.2 | 34.7 | 9.6 | 29.6 | 27.3 |
| ZEROSEARCH | 34.6 | 35.2 | 18.4 | 27.7 | 29.0 |
| Search-R1 | 37.0 | 41.4 | 14.6 | 36.8 | 32.4 |
| StepSearch | 38.6 | 36.6 | 22.6 | 40.0 | 34.5 |
| ReSearch | 43.5 | 47.6 | 22.3 | 42.4 | 38.9 |
| PyRAG-RL | 40.5 | 49.4 | 20.7 | 46.1 | 39.2 |
平均 EM 上 PyRAG-RL(39.2)压住了 ReSearch(38.9)拿第一,但坦率讲两者差距很小。真正值得说的是两点:
第一,PyRAG-RL 在 Bamboogle 上拿了 46.1,比第二名 ReSearch 高 3.7 个点,比 Search-R1 高 9.3 个点。Bamboogle 的难点和它打中靶心。
第二,论文把同样的训练管线迁移到 Qwen3-4B 和 LLaMA-3.1-8B 都跑了一遍,分别拿到 36.3 和 40.9 的平均 EM,比同 backbone 的 RAG-RL 高出 10.9 和 11.9 个点。这个跨架构的稳定性比绝对分数更说明问题——说明它学到的不是某个模型的"快捷方式",而是真的把结构化规划这个先验注入进了不同的 backbone。
我对这套结果的判断是:RL 训练版本的提升幅度比免训练版本要温和,因为 ReSearch、StepSearch 这些同期 RL search agent 也已经把搜索智能体路线推得很高了。PyRAG-RL 的价值更多体现在"提供了一个更结构化的载体让 RL 信号回传",而不是"碾压式领先"。要论震撼程度,免训练那张表里 11.8 个点的平均提升其实更让我意外。
消融:每个部件值多少分
论文最干净的一张消融图是这个:
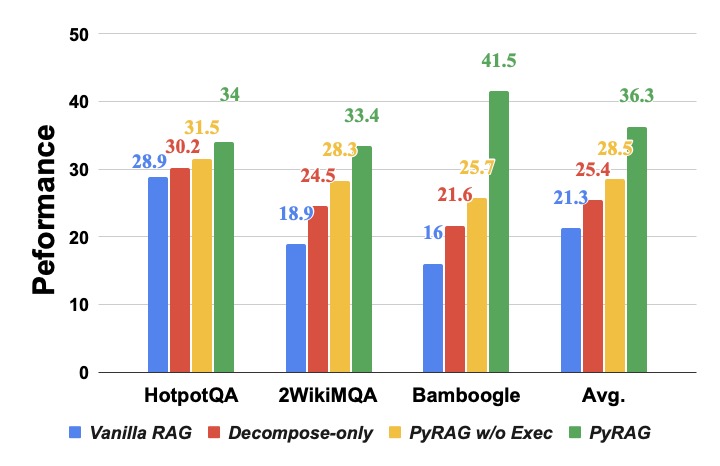
图3 在三个多跳基准 + 平均上,逐步往 Vanilla RAG 里加结构:只加分解(Decompose-only)、加分解+规划但不执行(PyRAG w/o Exec,让 LLM 看着 plan 自己模拟)、完整 PyRAG。平均 EM 从 21.3 → 25.4 → 28.5 → 36.3。
这个递进特别能说明问题:
- 分解单独加进去,平均涨 4.1 个点——切子查询本身就改善了检索质量(每次只搜一个实体,比把两个塞一起搜要干净)。
- 规划但不执行再加 3.1 个点——把推理写成"假装是程序"的结构,即使不真跑,也能让 LLM 自己沿着结构更连贯地推理。这部分有点像 plan-and-solve 的味道。
- 真正的执行再加 7.8 个点——这是单步最大的跳跃。Bamboogle 上一下从 25.7 涨到 41.5。
最后这一跳是整个 PyRAG 的灵魂。前两步算是"形似",最后一步才是"神似"——只有真的把中间答案当变量传递、由解释器保证状态一致性,错误才不会跨步累积。"plan 但不 exec"和"plan 且 exec"之间差了 7.8 个点,这就是确定性反馈相比"模型自己脑补一遍"的价值。
效率:用 3.7 次 LLM 调用换 Search Agent 的精度
我看到这个图的时候有点意外:
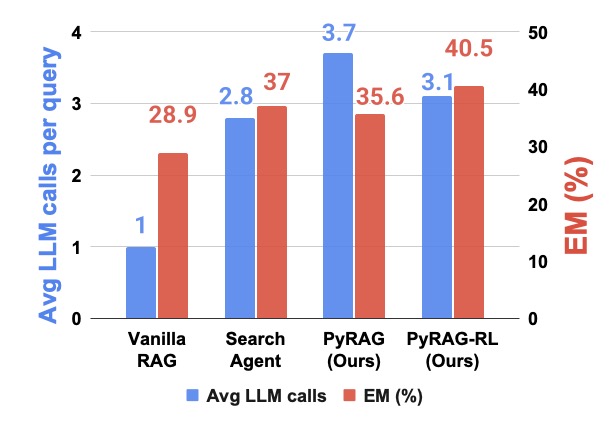
图4 是 HotpotQA 上 100 个采样 query 的平均 LLM 调用次数(蓝)和 EM(红)。Vanilla RAG 调用 1 次,EM 28.9;Search Agent 调用 2.8 次,EM 37;PyRAG 调用 3.7 次,EM 35.6;PyRAG-RL 调用 3.1 次,EM 40.5。
直观感受是 PyRAG 免训练版本调用次数比 Search Agent 还多一点(3.7 vs 2.8),EM 反而略低一点(35.6 vs 37)。这看起来不够"漂亮"。
但有几点要看清楚:
第一,PyRAG 的 3.7 次里有 ~5% 是 self-repair 重跑、~20% 是 adaptive retrieval 重跑。剩下的是 1 次 plan(decompose 和 plan 合并成一次调用)+ 若干次 answer。如果只看一发命中的 case,PyRAG 的调用数会更低。
第二,RL 版本把数字反过来了——PyRAG-RL 3.1 次调用、EM 40.5,比 Search Agent 调用更少、精度更高。这说明 RL 在做一件事:让 plan 写得更精准,从而少触发那两个 refinement 机制。这是"程序框架 + RL 优化"的复合收益。
第三,"LLM 调用次数"这个指标其实有水分。Search Agent 的每次调用 prompt 会随着历史越来越长,token 成本不是线性的;PyRAG 的每次 answer 调用 prompt 短而且固定,单次成本更低。但论文里没拿 token 数对比,这块算个小遗憾。
错误分布:瓶颈不是程序写不对,是检索召回不上来
PyRAG 还做了一件别的工作不太愿意做的事——手工标 100 个错例:
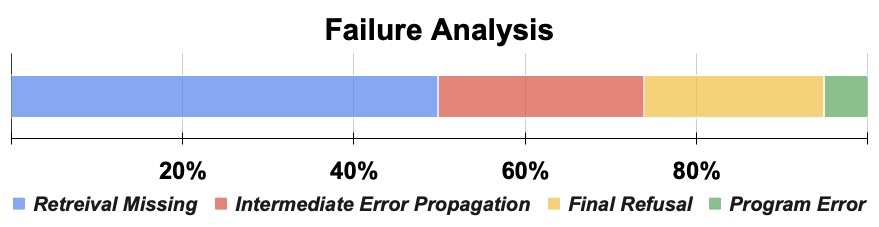
图5 横向堆叠条:Retrieval Missing 约 50%、Intermediate Error Propagation 约 23%、Final Refusal 约 22%、Program Error 约 5%。
我觉得这是这篇论文里最有诚意的一张图,因为它把 PyRAG 自己的天花板说清楚了:
- 一半的错来自检索召回。这跟 PyRAG 的设计本身无关——任何 RAG 系统都受制于检索器召回率,PyRAG 用的是 E5-base 在 Wikipedia 2018 dump 上的标准 setup。换更好的检索器(比如 ColBERTv2 或者 Hybrid Retrieval),这块还有提升空间。
- 23% 是中间错误传播。某一步 answer 给了一个不确定的回答,但程序还是把它当变量传下去,导致下游错。这块其实可以再加一个 confidence-aware 的 gating,PyRAG 现在只在拿到"unknown"哨兵词时才触发 adaptive retrieval,对"看似确定但其实瞎编"的中间答案没辙。
- 22% 是 final refusal。Answer Agent 自己拒答了。这是个 prompt engineering 问题。
- 只有 5% 是程序错误。说明 code LLM 写 plan 的可靠性非常高。这也回应了"代码模型的能力终于被对的接口接住了"这个判断。
Program Error 这 5% 里大头是 "Unknown Error"——程序跑通了但 answer 返回了哨兵。真正的 Python 异常(ValueError/TypeError/IndexError/NameError)加起来不到 20% 的程序错误(也就是不到 1% 的总错误)。所以 self-repair 机制虽然好用,但它解决的不是大头问题。
我的判断
读完这篇文章,我的整体感觉是问题表述层面的更新比方法本身更值钱。
它没有训练新的检索器,没有引入新的奖励函数(PyRAG-RL 用的还是标准 GRPO 路线,跟着 Search-R1 那套数据切分),没有用到 long context 或者 toolformer 的复杂结构。它做的事情更基础——把"多跳 RAG 是什么任务"这件事换了一种描述,从"自由文本里的链式推理"换成"程序合成 + 执行"。
这种"换问题表述"的工作有个特点:方法上看起来朴素,但下游的工程红利很大。一旦把推理过程变成可执行代码:
- trace 可观测:每一步的 query、检索到的 docs、变量值都在那里
- 错误可定位:哪一步崩了一目了然,stack trace 比 LLM 的"我反思一下"靠谱多了
- 行为可干预:不满意某一步的检索结果?直接把那一步 topk 调大重跑,不动其他
- 接口可复用:换检索器、换 answer 模型,都不影响 plan 那一层
这些其实是任何严肃的 RAG 产品上线都需要的能力,只是大家之前都在"事后给 LLM 加可观测性",PyRAG 反过来"先把推理结构化,可观测性是副产品"。
值得警惕的地方也有几个。
第一,论文里 7B 和 72B 的 backbone 都用 Qwen2.5 系列,但具体 plan 用的是哪个 code-specialized 模型?文章正文没明确说,得翻附录。如果用的是 Qwen2.5-Coder-32B 这种,那 Plan Agent 的成本就不便宜了,效率分析里"3.7 次 LLM 调用"的实际 token 成本会比表面看起来高。
第二,整个框架对"问题可分解性"有依赖。如果是那种需要在叙述中反复回旋、不容易切成原子子查询的问题(比如需要长篇论证的推理题),PyRAG 这种切片+组合的方式不一定 work。这点论文也算诚实地承认了——Bamboogle 这种典型组合多跳上提升最大,PopQA 这种偏单跳的上提升相对小。
第三,"程序合成"的可信度建立在 code LLM 不会"看起来合规但语义错位"上。论文 Program Error 只有 5%,里面的"Unknown Error"其实包含了"LLM 写出了在 Python 层面合法但语义不对"的代码(比如 regex 不匹配但没抛异常),这部分用编译器抓不出来。如果未来 PyRAG 要往更复杂的任务上扩,比如数学推理、多表 join,这种"语法对、语义错"的盲区会变大。
但这些都不影响它是一个值得跟进的方向。我自己接下来打算试着把这个思路套到内部一个 long-context 检索任务上——之前一直被中间状态没地方存的问题困扰,看 PyRAG 这套接口,感觉至少 trace 可观测这一项就够工程团队心动。
至于学术价值嘛,我比较看好它在以下两个方向上能引出后续工作:一个是把这个程序合成的接口扩展到工具更丰富的场景(不止 retrieve/answer 两个 API),另一个是把"deterministic feedback signal"这件事再往前推一步——比如对 Answer Agent 的"unknown"哨兵之外,是否还能引入更细粒度的 confidence calibration,从而让 adaptive retrieval 触发得更准。
一些工程上的小细节
最后留几个对实际落地有用的观察:
- Decompose 和 Plan 合并成一次 LLM 调用——这是 PyRAG 的工程优化,论文 efficiency 节点出。把分解的子查询和 plan 写在一个 prompt 里输出,省掉一次往返。
- topk 升级策略很温和:默认 k=5,触发 adaptive 后升到 k=10,没有多级升级。简单粗暴但管用,~20% 的 query 会触发。
- retrieval setup 完全跟 Search-R1:E5-base dense retriever,Wikipedia 2018 dump。这点保证了和 RL 训练版基线的公平对比,但也意味着检索召回这块的天花板和 Search-R1 一样。
- HotpotQA 是训练集,其他四个是 OOD:这个对比有点取巧,但同领域的 baseline 也是同样设置,所以可比性还在。
- trace 可以直接当 supervision 信号:论文没明说,但执行轨迹(query + docs + answer 序列)天然适合做 trajectory-level 的 RL 训练,这也是 PyRAG-RL 能 work 的底层原因。
如果你也在做检索增强、agent 工具调用、或者任何需要"可控多步推理"的系统,这篇文章的接口设计值得认真琢磨一下。代码已经开源在 GitHub,复现门槛不高,跑一下 HotpotQA 的免训练版本应该就能感受到那种"trace 终于不是叙述化"的舒服。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我