π-Bench:当 AI 助理被要求"猜你想说但没说的话",9 个旗舰模型集体翻车
核心摘要
你有没有过这种体验:跟 AI 助理说"帮我准备下周客户汇报的 deck",它真就生成了一份模板——但完全没考虑你三周前那次会议里定的格式规范、你老板偏好的指标口径、这个客户专属的术语表。它"完成了任务",但完全没"读懂你"。
这就是这篇论文要量化的那道坎。π-Bench 提出了一个挺扎心的问题:当用户的话只说了一半,AI 智能体能不能主动把另一半挖出来? 它给 9 个旗舰模型——GPT-5.4、Claude 4.6 Opus、Gemini 3.1 Pro、DeepSeek V3.2、Kimi K2.5、Qwen3.6 Plus 等——出了 100 道横跨 5 个职业角色的多轮长程任务,每道题都埋了 hidden intents(隐藏意图),然后用两个分数:Proc(主动性,看智能体能不能在用户开口前自己解决或追问)和 Comp(完成度,看最终交付物对不对)分别打分。
结论挺有意思:Comp 和 Proc 是两件事。Kimi K2.5 拿到 61.6 的 Comp 但 Proc 只有 43.1——能干活,但要你一句一句喂;Seed2.0 Pro 反过来,Proc 58.4 高于 Comp 52.1——能猜你想要什么但活儿干得糙。即便最好的模型,平均 Proc 也才到 67%。这个 benchmark 的价值不在于又分出谁强谁弱,而在于把"任务做完"和"减轻用户负担"这两个维度切开了。后者才是真正决定 AI 助理用得舒不舒服的那一层。
论文信息
- 标题:π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
- 作者:Haoran Zhang、Luxin Xu、Zhilin Wang、Runquan Gui、Shunkai Zhang、Haodi Lei、Zihao He、Bingsu He、Chicheng Qin、Tong Zhu、Xiaoye Qu、Yang Yang、Yu Cheng、Yafu Li
- arXiv:2605.14678(v3, 44 页)
- 发布:2026 年 5 月
为什么需要这么一个 benchmark
先抛一个判断:现在 Agent 评测的主流方向,其实在回避真正的难题。
主流 Agent benchmark——AgentBench、tau-bench、Mind2Web 之类——基本都默认用户开口的一刹那目标就清晰:API 怎么调、表单填什么字段、网页点哪个按钮。但真实助理场景不长这样。你说"准备客户汇报",没人会告诉你格式 16:9 还是 4:3、关键指标用 GMV 还是 DAU、客户偏好深色背景还是浅色。这些"没说但很重要"的东西,论文里叫 hidden intents(隐藏意图)。memory benchmark 是另一条路,但它聚焦"记得住、调得出",π-Bench 的设定不一样——记忆只是手段,识别什么需求没说出来、并主动补上才是目的。还有一类 proactive agent benchmark 主要建在手机/GUI 场景上(视觉轨迹、设备上下文、即时澄清、消费级短任务),对真实的长期专业助理来说太薄了。OpenClaw 这种长程办公助理,它需要在一个持久化工作区里反复读写文件、协调工具、跨会话保持决策一致——session 3 定的命名规范,到 session 17 要自动沿用,而不是每次都问一遍。
说到底,作者想测的是这样一种"老员工感"——跟你共事久了的同事,你不用每次都把背景重讲一遍。这个能力现在是不是真的在前沿模型身上出现了?π-Bench 给了一个比较硬核的回答方式。
π-Bench 长什么样

图1:π-Bench 总览。左:5 类用户角色;中:每个角色 1 个 episode 含 20 个多轮 session,sessions 之间存在跨会话依赖结构(强依赖组 6 组、独立任务 5 个);右:双指标评估
整个 benchmark 的设计可以拆成三层:
第一层:5 类角色 × 20 个会话 = 100 个任务
5 个职业角色覆盖了不同工作流:
| 角色 | 典型任务 | 工作流特点 |
|---|---|---|
| Researcher | 文献综述、rebuttal 准备、研究规划 | 不标准化,难度高 |
| Marketer | 内容策划、数据分析、报告 | 中等结构化 |
| Law Trainee | 法律文书、案件移交 | 风险导向,判断密集 |
| Pharmacist | 文献摘要、实验记录、药物设计 | 高度结构化、文件锚定 |
| Financier | 财务分析、风险评估 | 风险判断密集 |
所有角色都是跟领域专家一起构造的,不是 LLM 拍脑袋编出来的——这点很重要,回头会看到 Pharmacist 这类高度文件锚定的角色得分明显高于 Researcher。
第二层:跨会话依赖
20 个 session 不是相互独立的。论文里安排了 6 组强依赖(每组 2-3 个 session 共享必要的 carry-over 信息)和 5 个独立任务。比如 session 3 你跟智能体说"客户 deck 用 16:9,关键指标用 GMV",到 session 17 说"准备这个客户的月度更新",强助理应该自动沿用前面定的格式和指标,而不是从头问一遍。
第三层:每个 task 的解构
一个 session 由四部分组成:初始请求 \(u_1\)(意图明确但故意欠规约)、hidden intents \(\mathcal{I} = \{i_1, ..., i_m\}\)(被故意藏起来的隐含约束/偏好/依赖)、checklist \(\mathcal{C} = \{c_1, ..., c_n\}\)(可验证的最终交付清单)、以及两套 graders(rubric-based 用 LLM 判细则 + rule-based 用脚本验证文件存在、字段、工具调用)。
这里有个关键设计——hidden intent 和 checklist 是两层独立的结构。前者是 latent 偏好/约束,后者是客观可验证的交付义务。这个区分直接决定了 Proc 和 Comp 是两个分数,而不是同一个分数的两个分量。
核心机制:Hidden Intent 怎么追踪

图2:每个 session 是一个 turn-based 循环。每个 hidden intent 最终被打三种标签之一:completed / inferred / provided——这个三态划分是整个评估的灵魂
这块我得展开聊一下,因为它是整篇论文最值钱的设计。每一个 hidden intent 在 session 结束时必然被分配为以下三态之一:
-
Completed(已解决):智能体在用户没明说的情况下,自己产出了符合该 intent 的动作或交付物。比如用户没说文件命名规则,但智能体直接沿用了之前定的命名规范——这是最高级别的主动。
-
Inferred(已追问):智能体没直接解决,但提了一个精准问题正中要害,用户在下一轮揭示需求,然后智能体据此行动。这也算主动——主动澄清。
-
Provided(被动给出):智能体既没解决也没问对地方,用户被迫主动把这个需求 throw 出来。这是被动的标志。
主动性分数定义就出来了:
直接 completed 和精准 inferred 给等权——这点设计挺到位的。有些 intent 只能通过澄清解决(你不能让智能体猜你的预算上限),有些可以直接推断(命名规范这种可以 carry 过来),都属于 agent driven 的主动行为。完成度更直接,每个 checklist item 跑 grader,平均得分:
为什么 Proc 和 Comp 会脱钩? session 是直到所有 hidden intent 都进入终态才结束的——意思是,就算智能体一开始很被动,最后所有信息都被用户喂完了,它依然能把活儿干完拿到不错的 Comp 分,但 Proc 会很低(大部分 intent 都打 provided 标签)。所以这两个分数分开看才有意义:Comp 衡量最终能不能干完,Proc 衡量过程中要不要用户费劲推着走。一个好助理,应该 Comp 和 Proc 双高。
主实验:9 个旗舰模型横扫一遍
| 模型 | Avg Proc | Avg Comp | Researcher (P/C) | Marketer (P/C) | Pharmacist (P/C) | Law Trainee (P/C) | Financier (P/C) |
|---|---|---|---|---|---|---|---|
| GPT-5.4 | 67.0±2.1 | 65.6±1.8 | 46.0/66.4 | 78.2/67.1 | 75.9/71.5 | 56.9/61.9 | 78.1/61.2 |
| Gemini 3.1 Pro | 57.1±0.9 | 60.0±0.8 | 41.1/59.2 | 65.0/62.1 | 71.0/72.1 | 50.0/55.3 | 58.6/51.1 |
| Claude 4.6 Opus | 65.5±1.4 | 67.6±1.5 | 50.3/74.5 | 75.0/74.6 | 82.8/68.6 | 45.7/57.2 | 73.8/63.2 |
| DeepSeek V3.2 | 53.3±1.9 | 57.8±3.0 | 29.0/66.9 | 69.1/59.4 | 75.9/62.6 | 33.2/51.1 | 59.1/48.9 |
| MiniMax M2.7 | 55.6±3.2 | 60.0±1.8 | 33.4/63.9 | 71.9/61.9 | 77.1/63.6 | 38.6/52.5 | 57.2/58.1 |
| Kimi K2.5 | 43.1±0.2 | 61.6±1.9 | 28.9/63.5 | 41.2/62.3 | 70.1/74.8 | 34.8/54.4 | 40.4/52.9 |
| Seed2.0 Pro | 58.4±0.9 | 52.1±3.8 | 38.9/59.6 | 71.4/44.2 | 77.0/67.6 | 46.0/44.7 | 58.7/44.5 |
| GLM-5.1 | 58.4±0.8 | 63.6±2.9 | 41.8/61.6 | 62.6/69.1 | 75.2/70.3 | 45.5/57.3 | 66.7/59.8 |
| Qwen3.6 Plus | 64.0±1.1 | 64.1±0.6 | 40.1/70.0 | 77.5/66.6 | 79.7/70.2 | 45.7/60.2 | 77.1/53.6 |
表1:9 个旗舰模型在 π-Bench 上的整体表现,每格为 Proc / Comp(%),均值取 3 次独立运行
我看到这个表第一反应是:好家伙,没一个模型是 Proc 和 Comp 都拉满的。Proc 范围 43.1-67.0,Comp 范围 52.1-67.6,差距都挺大。
几个有意思的现象。没有全能选手,只有偏科冠军——GPT-5.4 拿了 Proc 第一 67.0 但 Comp 只有 65.6,输给 Claude 4.6 Opus 的 67.6;Claude Opus 反过来 Proc 65.5 略低。两家咬得一样紧,只是 GPT 更偏主动、Claude 更偏靠谱。Qwen3.6 Plus 是个意外——Proc 64.0、Comp 64.1,两者都接近 GPT-5.4,而且方差是所有模型里最低的(1.1 / 0.6)。说实话这个数据让我有点惊讶,国产模型在这种长程隐式意图任务上能站到这个位置。Kimi K2.5 是个有趣的反例:Comp 61.6 不算差,Proc 只有 43.1——是所有模型里最低的。意思就是它能干活,但要你一步一步喂指令。Seed2.0 Pro 反过来,Proc 58.4 但 Comp 52.1,能猜中你想要什么但实现质量不行。领域差异巨大——Pharmacist 几乎所有模型都打到 70+,Researcher 的 Proc 集中在 30-50。原因前面说了,Pharmacist 任务高度文件锚定 hidden intent 容易推断;Researcher 任务工作流不标准化,rebuttal、文献综述这些活儿需要更深的领域判断。
解耦分析:为什么 Comp 和 Proc 不能合二为一
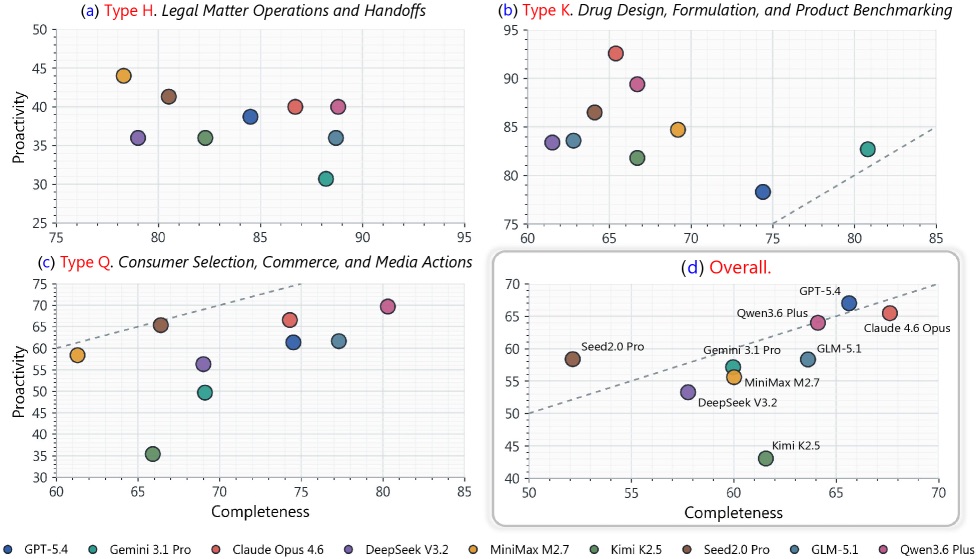
图3:四象限散点。Type H (Legal handoffs):Comp 84.1% vs Proc 38.1%——能起草文件但漏掉移交细节;Type K (Drug design):Proc 84.9% vs Comp 68.0%——能推断科学约束但综合写作弱;Type Q (Consumer):完成导向;(d) Overall 整体呈正相关但 Kimi K2.5 / Seed2.0 Pro 严重偏离对角线
我先说结论:这张图证明了 Proc 和 Comp 测的是不同能力,不同任务类型会让模型暴露不同短板。
看 Type H(法务移交)那一象限——所有模型几乎都聚在右下角,平均 Comp 拉到 84.1% 但 Proc 只有 38.1%,差了 46 个点。论文的解释很直接:智能体能起草请求中明确要求的法律文件,但漏掉了"案件是否已经准备好移交给同事"这件事的所有 hidden intent——缺哪些证据材料、有哪些 blocker、下一步谁做什么。这些东西用户必须自己提,智能体不会主动 surface 出来。这折射出工程实践里一个普遍现象:当前 LLM 智能体很擅长按 spec 干活,但很不擅长判断什么没说。Type K(药物设计)反过来,Proc 84.9% 高于 Comp 68.0%——hidden intent 通常是具体的科学约束,从工作区文件里有迹可循;但要写完整、技术细节正确的综合报告需要更深的领域深度,所以 Comp 反而拖后腿。(d) 整体散点图最直观——Kimi K2.5 远离对角线偏右下,Seed2.0 Pro 偏左上,是 Proc-Comp 解耦最典型的例子。
消融实验:历史会话到底有没有用?
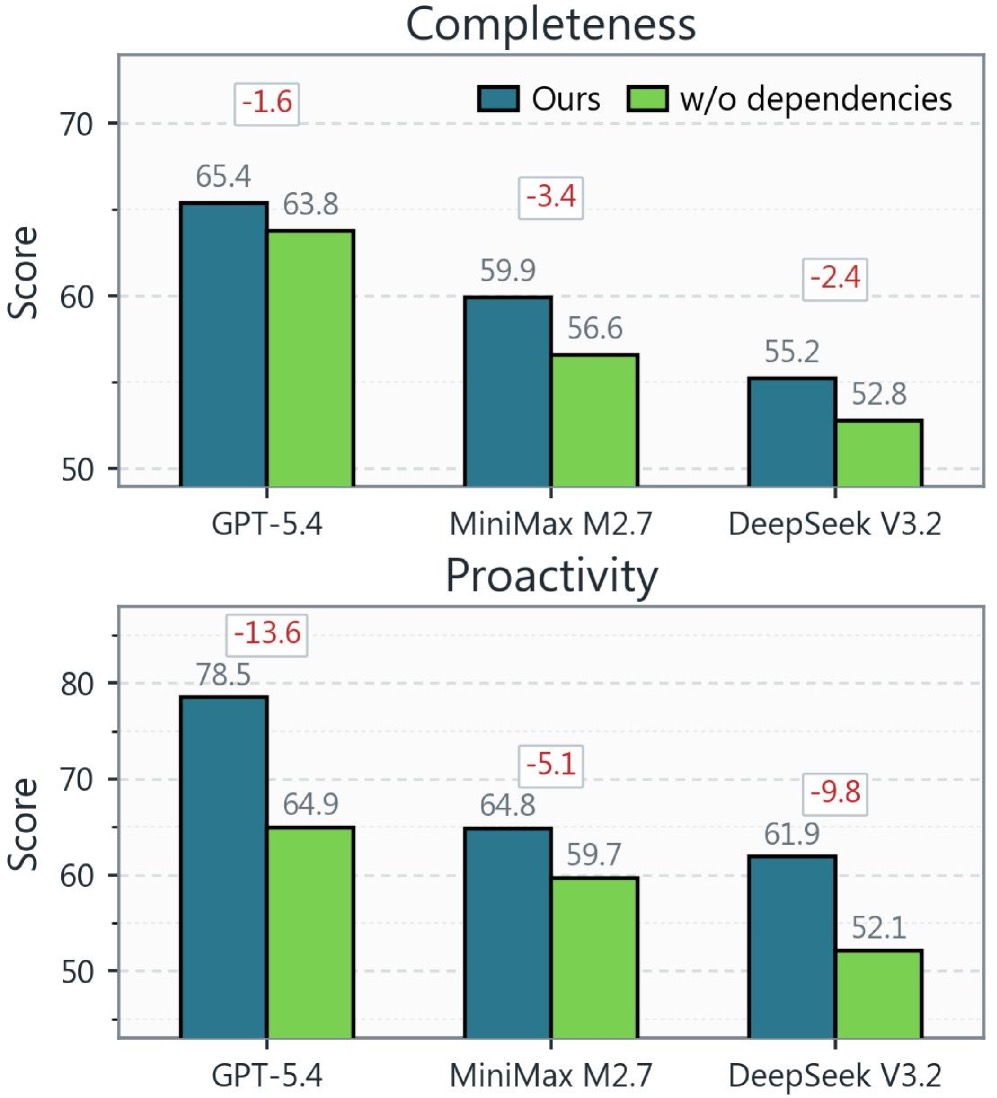
图4:消融研究。每个强依赖组的最后一个 task 上,对比原始轨迹(Ours)与去掉前序 session(w/o dependencies)后的得分。结论一目了然:去掉历史,Comp 变化不大,Proc 大幅下滑
这个消融做得很干净,一句话总结:所谓"老员工感"真的来自历史对话,而且只对 Proc 有用,对 Comp 几乎不影响。具体数字:
| 模型 | Comp(有依赖→无依赖) | Proc(有依赖→无依赖) |
|---|---|---|
| GPT-5.4 | 65.4 → 63.8(-1.6) | 78.5 → 64.9(掉 13.6 个点) |
| MiniMax M2.7 | 59.9 → 56.6(-3.4) | 64.8 → 59.7(-5.1) |
| DeepSeek V3.2 | 55.2 → 52.8(-2.4) | 61.9 → 52.1(-9.8) |
平均 Comp 只掉 2.5 个点,平均 Proc 掉 9.5 个点。去掉历史后,原本能从前序 session 推断出来的 hidden intent(客户格式偏好、命名规范、上次会议决议)就推不出来了,智能体只能等用户重新告诉它(intent 被打 provided 标签,Proc 直接掉分);但被告知之后执行能力没变,所以 Comp 变化不大。GPT-5.4 掉 13.6 个点是最猛的,反过来说明它原本就是最依赖历史信息做主动推断的模型——这恰恰是它 Proc 第一的来源。模型越强,这个差就越大。
我对这篇论文的判断
先说我喜欢的。问题选对了——"主动性"这件事在工程落地里特别痛,我之前调一个长程办公助理 demo 的时候,最难调的不是模型能不能完成单步任务,而是它能不能记住三周前定的设定还沿用、能不能在用户没说之前主动 surface 关键问题。这种能力以前没法量化,作者把它抠出来做了系统化定义。三态划分 completed / inferred / provided 是这篇论文的灵魂——把主动行为细分成"直接做对"和"精准提问"两种,让 Proc 这个分数有可解释性,不是黑盒指标。跨会话依赖落到了实处,6 组强依赖+消融实验证明,前序 session 信息确实对 Proc 起作用,把 benchmark 跟 memory 这条线连起来,但又不是单纯测记忆,而是测"用记忆提升主动性"的复合能力。
但有几个地方让我皱眉。100 个任务可能偏少,每个角色才 20 个 session,强依赖组才 6 个。统计层面(3 个 seed 取均值、方差多数 \lt 2.0)控制不错,但具体到 Type H/K/Q 这种细分类别,样本量很小,结论鲁棒性要打个问号。user agent 和 grader 都用 GPT-5.4 跑的,存在潜在循环依赖——GPT-5.4 当 simulated user 时,自己作为被评模型可能会被自己更好理解。论文做了独立 frontier 模型审计宣称分歧率 \lt 4%,但跨家族的多 judge ensemble 会更可信。主动性的边界问题:over-clarify 的 agent(什么都问一遍)也能拿到 inferred 分。论文用 turn count 作为补充缓解但没完全闭环,未来 v2 应该引入"问题质量"维度。5 个角色全是知识工作者,没覆盖代码 agent、数据科学 agent、运营 agent 这些场景。
工程启发与收尾
如果你在做 Agent 产品,这篇论文有几个直接的工程启示:
1. 别只盯 task completion。Kimi K2.5 那种"能干活但要你喂"的特性,用户用着会很累但 task success 不一定低,传统 success rate 抓不到。建议加一个类 Proc 的指标——在用户给出明确指令之前,agent 主动解决或精准追问的占比。
2. 跨 session 偏好沿用要专门设计。消融数据证明这是 Proc 高分模型的核心区别能力。memory 模块不能只存"事实记忆",还要专门做"latent 偏好提取"——从历史里抽出隐性约束(格式、命名、口径、流程偏好)并在新任务中检索匹配。这块现在多数 memory 框架做得不够细。
3. 把 hidden intent 做成显式的、可标注的对象,让 grader 单独打分。光用 LLM-as-judge 给一个总分太粗了,分维度打才看得清真实弱点;并且 Proc 这个分数可以直接当 RL reward 用,引导模型学"主动澄清+主动推断"的行为。
π-Bench 这篇论文最值钱的不是跑出来的具体数字(虽然 GPT-5.4 / Claude Opus / Qwen3.6 Plus 三巨头并立这个结论也挺有信息量),而是它把"主动性"从一个模糊的产品体验词,变成了一个可量化、可消融、可对比的研究对象。最近一年 Agent benchmark 在卷工具调用、卷长程规划、卷代码生成,但很少有人正经测"AI 知不知道用户没说什么"。
回到开头那个"帮我准备客户 deck"的例子——什么时候 AI 助理跟你工作半年后,开口就知道"这个客户要用 16:9 + GMV 口径 + 那套术语表",而不是每次都问一遍——那才是 personal assistant 真正落地的时刻。π-Bench 至少把这条路标出来了,剩下就看接下来一年模型能不能在 Proc 这一栏继续往上爬。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我