当模型已经"想明白"了还在絮叨——这篇论文教你怎么让它闭嘴
论文:Stop When Reasoning Converges: Semantic-Preserving Early Exit for Reasoning Models arXiv:2605.17672 代码:https://github.com/giovanni-vaccarino/PUMA
一、先聊个让人皱眉的现象
你有没有跟 DeepSeek-R1、o1 这种推理模型打过交道?
让它做一道数学题,它先 Let me think step by step...,分析、计算、验证、自我修正——这一套挺好。但你往下翻就会发现,它在某个点其实已经把答案算出来了,然后开始反复"再确认一下"、"换个角度验证"、"等等让我重新看看",能再生成上千个 token。最后吐出来的答案,跟它中段那个就一模一样。
之前在做推理加速的时候我就特别困扰这个事。表面上看是模型很"严谨",实际上是它不知道该在哪儿停下。
这篇论文一上来就甩了一个数:在五个主流 LRM 上分析,41% 到 52% 的推理 token 是在模型已经得到最终答案之后生成的。
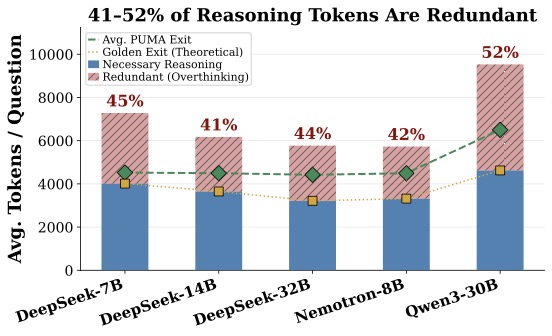 图1:在 DeepSeek-7B/14B/32B、Nemotron-8B 和 Qwen3-30B 上的过度思考分解。蓝色是"必要推理",红色斜纹是"答案已出之后的冗余继续"。最夸张的 Qwen3-30B 浪费比例高达 52%,平均每个问题烧掉超过 5000 个冗余 token。
图1:在 DeepSeek-7B/14B/32B、Nemotron-8B 和 Qwen3-30B 上的过度思考分解。蓝色是"必要推理",红色斜纹是"答案已出之后的冗余继续"。最夸张的 Qwen3-30B 浪费比例高达 52%,平均每个问题烧掉超过 5000 个冗余 token。
这就是 PUMA 这篇论文要解决的核心痛点。但它没有止步于"砍掉冗余"——它问了一个更有意思的问题:怎么判断模型已经"想清楚了"?
二、核心摘要:一个被忽略的信号维度
先说结论:
PUMA 的核心洞察很简单:现有的早退方法都在看"答案准没准备好",但真正该看的是"推理过程有没有收敛"这件事。这俩不是一回事。一个轻量级嵌入模型监控推理步骤之间的语义冗余,一旦发现连续步骤在原地踏步(互相在重复同一件事),才去触发答案验证。在 5 个推理模型 × 5 个挑战性 benchmark 上,平均省 26.2 个百分点 的 token,准确率不掉反升,墙钟加速 1.28×–1.40×。
这篇论文有意思的地方在于:它没有发明全新的早退机制,而是指出了既有方法的盲点——答案级信号天生是滞后且噪声的,必须用一个推理级信号来"门控"它。这个分离 where to stop 和 whether safe to stop 的设计,我觉得是真的漂亮。
三、问题动机:答案就绪 ≠ 推理收敛
要理解 PUMA 为什么要这么设计,得先搞清楚为什么纯答案级信号会翻车。
现有的 inference-time 早退方法基本分两派:
- 置信度派:在中间某个点诱导模型先吐一个 trial answer,看 token 生成概率高不高,高就停。代表是 DEER。
- 一致性派:在多个中间点诱导 trial answer,看是不是连续 k 次给的答案都一样,一样就停。代表是 Dynasor、Answer Convergence。
听起来挺合理。但你想想看下面这个场景——
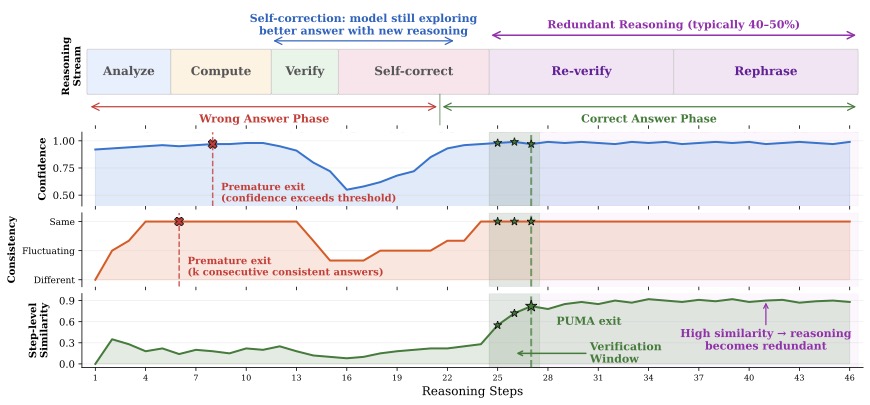 图2:一道题的完整推理轨迹。横轴是推理步骤(46 步),上方色带显示模型在每个阶段做什么——前面是 Analyze/Compute/Verify,中段 Self-correct,后段 Re-verify/Rephrase。三条曲线分别是 Confidence、Consistency、Step-level Similarity。关键看红色虚线标的"Premature exit"——在第 7、8 步时,置信度已经爬到 0.95,一致性也连续给"Same"答案,但其实这时候答案是错的,模型还在 Self-correct 阶段;真正的 PUMA 退出点(绿色星标)在第 25 步附近,已经过了自我修正,进入了 Rephrase 期。
图2:一道题的完整推理轨迹。横轴是推理步骤(46 步),上方色带显示模型在每个阶段做什么——前面是 Analyze/Compute/Verify,中段 Self-correct,后段 Re-verify/Rephrase。三条曲线分别是 Confidence、Consistency、Step-level Similarity。关键看红色虚线标的"Premature exit"——在第 7、8 步时,置信度已经爬到 0.95,一致性也连续给"Same"答案,但其实这时候答案是错的,模型还在 Self-correct 阶段;真正的 PUMA 退出点(绿色星标)在第 25 步附近,已经过了自我修正,进入了 Rephrase 期。
这张图我盯了挺久。它讲的故事是:
模型在"Wrong Answer Phase"(错误答案阶段)里,置信度可能很高、答案可能很稳定——但它并不知道自己错了。这时候如果纯靠这两个信号停,等于在错误答案上敲死了棺材板。直到第 16 步左右模型自己发现不对,置信度才掉下去开始自我修正,最终在第 22 步左右收敛到正确答案上。
真正可靠的"该停了"信号,是推理步骤之间开始互相重复——一句话翻来覆去地说,没有新增内容。这个时候才是真的收敛。
说实话,看到这张图我才真正理解 PUMA 在做什么。它说到底就一件事:"答案稳"只是个表层现象——可能是真的算明白了,也可能是模型在错误答案上死磕。要更准的信号,得看推理过程本身——它还有没有在产生新内容。
这个观点其实跟 Kuhn 等人那篇 Semantic Entropy 一脉相承:把不确定性建模成"多个输出之间语义是不是塌缩",而不是"token 概率有多低"。PUMA 是把这个 across-output 的思路,搬到了 within-trajectory 上:最近几个推理步骤如果语义塌缩了,说明探索结束了。
四、PUMA 怎么工作:双门控架构
理解了动机,方法就很自然了。
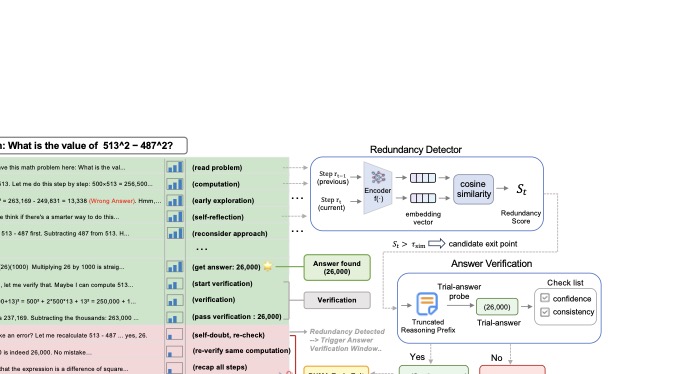 图3:PUMA 架构总览。一个 513² − 487² 的数学题——左侧的轨迹可以看到模型从 read problem 开始计算,到 get answer: 26000 实际上已经得出答案,但还在 start verification、self-doubt、recap all steps 这些环节里来回打转。Redundancy Detector 用 Qwen3-Embedding-0.6B 对相邻两步做嵌入并算余弦相似度,超阈值就 flag 一个候选退出点;Answer Verification 在这些候选点上诱导 trial answer,检查置信度+一致性后才真正停。
图3:PUMA 架构总览。一个 513² − 487² 的数学题——左侧的轨迹可以看到模型从 read problem 开始计算,到 get answer: 26000 实际上已经得出答案,但还在 start verification、self-doubt、recap all steps 这些环节里来回打转。Redundancy Detector 用 Qwen3-Embedding-0.6B 对相邻两步做嵌入并算余弦相似度,超阈值就 flag 一个候选退出点;Answer Verification 在这些候选点上诱导 trial answer,检查置信度+一致性后才真正停。
整个流程拆成三块讲:
1. Redundancy Detector:用嵌入模型"嗅"重复
这是 PUMA 的关键武器。形式上很简单:
把当前步骤 \(r_t\) 和前 \(k\) 步(默认 \(k=1\),只看上一步)的嵌入做余弦相似度,取最大值。\(s_t^{(k)} > \tau_{sim}\) 就标记为候选退出点。
听起来这不就是普通的语义相似度吗?
不是。作者特意强调一点:通用的句子相似度模型不行。原因是——两个推理步骤可能 topic 相似但实际上一个在算新东西、一个在验证旧东西;也可能字面上完全不一样但讲的是同一件事。所谓"推理进展性"这个概念,通用嵌入捕捉不到。
所以他们干了一件挺工程化的事:拿 Qwen3-Embedding-0.6B 做底座,用 LoRA + InfoNCE 对比学习 fine-tune,让它专门学"哪些步骤是在推进推理、哪些是在原地踏步"。监督数据怎么造的论文留到附录,但思路就是构造正样本对(真正在新增信息的步骤对)和负样本对(互相重复/复述的步骤对)。
我对这个设计的判断是:这是整篇论文的工程含金量所在。如果 detector 只是个通用 sentence encoder,整套系统就立不住。可惜论文正文里没展开太多 detector 的训练数据规模和 ablation,得翻附录。
2. Answer Verification:决定要不要真的停
光标记冗余还不够——detector 觉得"重复"了,可能模型只是在做正常的中间复述,不该停。所以加一层验证:
在第一次 detector flag 之后,PUMA 再等 \(L-1\) 个 flag(默认 \(L\) 是 verification window 大小),每次都诱导一个 trial answer \(A_{t_\ell}\) 和它的置信度 \(C_{t_\ell}\)。三个条件同时满足才真的停:
翻译成大白话: - 第一个候选点的置信度要够高(\(\lambda\) 卡阈值) - 后续 \(L-1\) 次的答案要跟第一次完全一致 - 后续的置信度不能比第一次掉得太多(\(\epsilon\) 是容忍度)
这个设计的精妙之处在于:detector 决定 where(在哪些点考虑停),verification 决定 whether(这些点上真的停吗)。两者解耦。这也是为什么 PUMA 比 DEER、Dynasor 强——后者每一步都在做 trial answer probing(贵),而且没有推理级门控,容易被错误答案"骗"过去。
3. Loop Breaker:兜底机制
有些情况下 verification 永远过不了——比如模型一直纠结在两个答案之间反复横跳,verification 的一致性条件就永远不满足。这时候如果不兜底,PUMA 就退化成 Full CoT 了,省不了 token。
Loop Breaker 的逻辑很简单:在推理超过某个最小步数后,如果 detector 连续 \(m\) 步都报告冗余,并且历史上有过一个置信度"够用"的 trial answer,就强制停下。它不是用来追求精度的,是用来兜效率底线的。
整个三件套合起来:detector 是低成本前置过滤、verification 是高质量决策、loop breaker 是 worst-case 兜底。这是一个挺典型的"分层 + 异步"系统设计——把昂贵的操作(probing)局限在少数候选点上。
五、实验:数字说话
主表很长,挑代表性结果看:
主实验:5 模型 × 5 benchmark
下面是论文 Table 1 的核心子集(Overall 列,跨 MATH-500、AIME24/25、GPQA-D、OlympiadBench 平均):
| Method | DS-7B Acc / TR | Nemotron-8B Acc / TR | Qwen3-30B Acc / TR |
|---|---|---|---|
| Full CoT (baseline) | 58.0 / 0.0 | 64.3 / 0.0 | 81.7 / 0.0 |
| No-Think | 38.7 / 79.9 | 32.8 / -80.5 | 68.8 / 45.3 |
| CCoT (prompt 压缩) | 50.4 / 58.6 | 48.8 / 34.1 | 54.3 / 55.5 |
| Plan&Budget | 47.8 / 47.9 | 52.1 / 18.6 | 59.6 / 53.9 |
| Answer Convergence | 35.1 / 81.9 | 21.9 / 83.7 | 23.2 / 90.9 |
| Dynasor | 45.9 / 36.6 | 58.3 / -4.7 | 79.7 / 3.0 |
| DEER | 57.9 / 21.5 | 61.2 / -30.7 | 81.3 / 22.4 |
| PUMA (ours) | 60.2 / 35.6 | 64.7 / 20.1 | 82.5 / 28.2 |
几个关键观察:
第一,prompt 压缩派翻车特别明显。Qwen3-30B 在 CCoT 下从 81.7 掉到 54.3,掉了 27 个点,相当于把推理模型直接打回去了。CoD 更狠掉到 45.3。说实话这个结果让我想起一个老问题——让它"简短回答"其实就是在告诉它别推理了这件事。对越强的推理模型反作用越大。
第二,答案级早退的极端不稳定。看 Nemotron-8B 这一列:Dynasor 居然让 token 多了 4.7%(红色负数表示更慢),DEER 多了 30.7%。原因就是这俩在每一步都要做 trial-answer probing,遇上不收敛的轨迹反而拖慢了。没有推理级门控的早退方法,效率上限被 probing 频率卡死了。
第三,PUMA 的稳定性是真的能打。三个模型上准确率全部 ≥ Full CoT(DS-7B 还涨了 2.2 个点),同时省 20%–35% 的 token。这个 "accuracy 还能涨" 的现象,论文给的解释是——LRM 在 overthinking 阶段会"想着想着把对的改成错的",PUMA 在收敛点停下反而避免了 drift。这点我觉得挺有道理,之前确实在 R1 上观察到过类似现象。
推理质量:不只看准确率
这是 PUMA 比其他方法多走的一步——用 LLM-as-Judge 评估保留下来的推理链质量:
| Metric | Full CoT | PUMA | CCoT | Plan&Budget | Dynasor | DEER |
|---|---|---|---|---|---|---|
| Completeness | 67.6 | 64.8 | 64.1 | 62.5 | 57.2 | 62.4 |
| Coherence | 41.5 | 57.5 | 51.6 | 48.6 | 46.9 | 37.9 |
| Conciseness | 15.7 | 40.2 | 30.5 | 27.2 | 25.0 | 19.1 |
| Justification | 51.8 | 54.8 | 54.5 | 51.6 | 46.5 | 46.7 |
| Avg. | 44.1 | 54.3 | 50.2 | 47.5 | 43.9 | 41.5 |
注意 Full CoT 自己的平均分只有 44.1——这是因为它太啰嗦了,Conciseness 维度只能拿 15.7 分。PUMA 的优势在于把冗长的尾巴砍掉,留下的部分反而成了一个更紧凑、更连贯的解题叙事。
我对 LLM-as-Judge 这种评估方法一直有保留——GPT-5.4 自己也是个推理模型,它对"什么是好的 CoT"的偏好可能跟人类不完全一致。但至少作者给出了一个非数字指标的评估维度,没有只看 accuracy/token 这俩。
墙钟延迟:token 省了,时间真的省了吗?
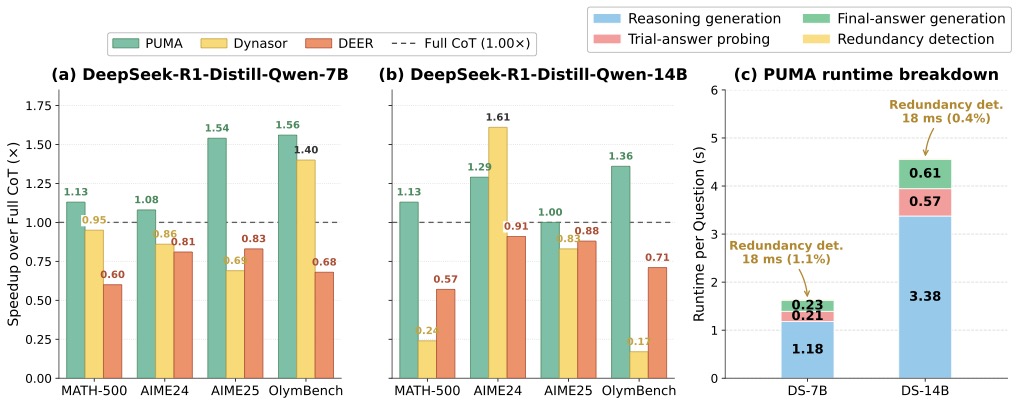 图4:(a) DS-7B 上 PUMA 平均加速 1.40×,最高在 OlymBench 上 1.56×;DEER 在所有 benchmark 上都比 Full CoT 慢(0.60×–0.83×)。(b) DS-14B 上 PUMA 平均 1.28×,但 Dynasor 在 AIME24 反超到 1.61×、OlymBench 直接砍到 0.17×——极度不稳定。(c) 是 PUMA 的运行时分解:Redundancy Detector 的开销只占 0.4%–1.1%(18ms),Trial-answer probing 占 0.2–0.57 秒——加起来微不足道。
图4:(a) DS-7B 上 PUMA 平均加速 1.40×,最高在 OlymBench 上 1.56×;DEER 在所有 benchmark 上都比 Full CoT 慢(0.60×–0.83×)。(b) DS-14B 上 PUMA 平均 1.28×,但 Dynasor 在 AIME24 反超到 1.61×、OlymBench 直接砍到 0.17×——极度不稳定。(c) 是 PUMA 的运行时分解:Redundancy Detector 的开销只占 0.4%–1.1%(18ms),Trial-answer probing 占 0.2–0.57 秒——加起来微不足道。
这张图回答了一个非常实际的工程问题:token 减少 26%,墙钟时间真的能减下来吗?
不一定。trial-answer probing 是有成本的——每次都要让模型多生成几十个 token 出答案。DEER 因为 probing 太频繁,反而比 Full CoT 还慢。
PUMA 之所以能把 token 节省转化成真实加速,关键在于它只在 detector flag 的少数候选点上 probe,而不是每步都来一遍。Redundancy Detector 自己加的 18 毫秒开销几乎可以忽略。
这是个挺关键的工程洞察:efficiency-oriented 系统设计里,"信号过滤" 比 "信号本身" 更重要。Dynasor 的 trial-answer 一致性信号其实也能用,但它不知道在哪里用,就只能每步都查,开销就上来了。PUMA 是把"检测"和"决策"拆开,让昂贵的决策只在少数关键点发生。
Ablation:每个组件有多重要?
| Configuration | Acc | TR | Probe× |
|---|---|---|---|
| PUMA (full) | 60.2 | 35.6 | 1.0× |
| w/o Redundancy Detector Gate | 56.1 (掉 4.1) | 46.0 | 3.3× |
| w/o Loop Breaker | 59.2 (掉 1.0) | 22.6 | 1.3× |
| w/o Answer Consistency | 57.3 (掉 2.9) | 37.8 | 1.2× |
| w/o Confidence Gate | 53.7 (掉 6.5) | 55.3 | 0.6× |
几个值得讲的细节:
- 去掉 Redundancy Detector Gate(每一步都做 verification):probing 量飙到 3.3×,准确率掉 4.1。这证明 detector 不只是个效率优化,它本身就有"过滤噪声候选点"的语义作用。
- 去掉 Loop Breaker:token reduction 直接腰斩(35.6 → 22.6)。说明确实有相当比例的轨迹会进入"verification 永远过不了"的死循环状态,需要兜底。
- 去掉 Confidence Gate:token reduction 反而涨到 55.3——因为停得更激进了;但 accuracy 直接掉 6.5 个点。这个对照很说明问题——单纯追求 token reduction 没有意义,关键是 reduction-per-quality。
早退行为分布:PUMA 都从哪儿停的?
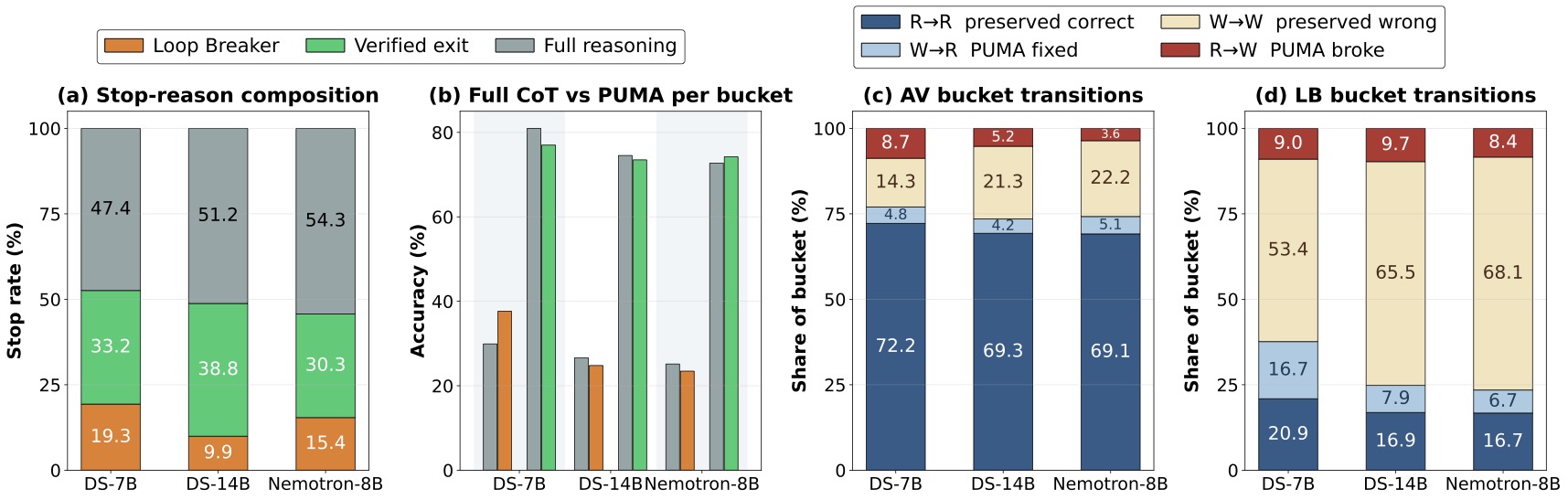 图5:(a) 在三个模型上,verified exit / Loop Breaker / Full reasoning 的分布。DS-14B 上 verified exit 占 38.8%,Loop Breaker 占 9.9%,剩下 51.2% 走完了全部推理。(b) 三种退出 bucket 的准确率对比——verified exit 的准确率基本和 Full CoT 持平,Loop Breaker 的稍低(但本来就是兜底)。(c)(d) 是 R→R / W→R / R→W / W→W 转移矩阵:verified exit 里 R→R(保留正确)占 69%–72%,R→W(破坏正确)只有 3.6%–8.7%;Loop Breaker 里 W→W(兜底已错的)占 53%–68%,说明它主要在切已经答错的尾巴。
图5:(a) 在三个模型上,verified exit / Loop Breaker / Full reasoning 的分布。DS-14B 上 verified exit 占 38.8%,Loop Breaker 占 9.9%,剩下 51.2% 走完了全部推理。(b) 三种退出 bucket 的准确率对比——verified exit 的准确率基本和 Full CoT 持平,Loop Breaker 的稍低(但本来就是兜底)。(c)(d) 是 R→R / W→R / R→W / W→W 转移矩阵:verified exit 里 R→R(保留正确)占 69%–72%,R→W(破坏正确)只有 3.6%–8.7%;Loop Breaker 里 W→W(兜底已错的)占 53%–68%,说明它主要在切已经答错的尾巴。
这张图最有意思的是 (c)(d) 这两个转移矩阵。Verified exit 的失误率 R→W 只在 3.6 到 8.7 这个区间——也就是说在它判定"该停了"的那些 case 里,破坏正确答案的概率很低。而 Loop Breaker 主要在切 W→W 的尾巴这件事——这些答案 Full CoT 也是错的,多想也想不对,干脆早点停省 token。
这两种行为模式加起来构成了 PUMA 整体收益的来源:verified exit 贡献质量保持下的 token 节省,loop breaker 贡献"反正都错就别浪费"的兜底节省。
六、可迁移性:这玩意儿能跨模态吗?
作者还做了一组让我比较惊讶的实验——直接把 PUMA 用到代码生成(LiveCodeBench)和视觉-语言推理(MathVista、MathVision)上,不重新训练 detector、不调超参。
结果: - LiveCodeBench:token 减少 18%–19%,pass@1 变化 \lt 1.5 点 - MathVista / MathVision:token 减少 23.8%–33.6%,accuracy 变化 \lt 1.5 点
这个零样本迁移的效果挺出乎我意料的。我原本以为 detector 用 LoRA 在数学推理步骤上 fine-tune 过,应该对训练分布很敏感。但实际上 "推理步骤的语义重复" 是一个相当通用的现象这件事——不管你是在写代码、在解几何题、还是在做 VQA,"原地踏步"的语义模式都有共性。
这一点说明 PUMA 的方法论比它表面上看着要广——它其实是把"推理过程的语义动态"作为一个独立信号引入了,这个信号脱离任务而存在。
七、还能更进一步:把停止策略内化进模型
最后一个实验我觉得是论文里最有想象力的部分:用 PUMA 选出的退出点作为监督信号,教模型自己学会"该停了",部署时直接走 vLLM,不带 PUMA 模块。
| Method | Avg. Acc | Avg. TR |
|---|---|---|
| Full CoT (base) | 63.0 | 0.0 |
| PUMA (inference) | 66.2 | 24.3 |
| Standard-SFT | 61.4 | -32.5 |
| FixedExit-SFT | 54.1 | 28.3 |
| PUMA-SFT | 66.9 | 19.3 |
| PUMA-DPO | 64.1 | 48.8 |
| Standard-GRPO | 65.8 | -3.4 |
| FixedExit-RL | 63.2 | 37.4 |
| PUMA-RL | 67.0 | 34.9 |
几个挺有意思的点:
FixedExit baseline 的对照特别狠。FixedExit-SFT 也是在"截短的推理链"上 SFT,但截断位置是固定间隔(每 N 步切一次),而不是 PUMA 选的"语义收敛点"。结果 FixedExit-SFT 的 accuracy 只有 54.1,PUMA-SFT 是 66.9——差了 12.8 个点。这强力证明了一件事:PUMA 选的退出点不仅仅"更短",而是"更有语义意义"——它选在了推理自然收敛的地方,模型从这种监督里能学到真东西。
PUMA-RL 超过了 inference-time PUMA 本身(67.0 vs 66.2,TR 34.9 vs 24.3)。这是一个挺反直觉的结果——本来你以为 inference-time PUMA 是上界(毕竟它有 detector 实时监控),但 RL 训完之后模型把这种"什么时候该停"的判断内化了,反而比外部信号更准。
PUMA-DPO 把 TR 推到了 48.8% 同时还涨了 1.1 个 accuracy。这个 DPO 配方挺巧妙——把"PUMA 截短的链"和"完整的链"配对,相同正确性下偏好短的。这种 preference learning 的方式说到底就是在告诉模型:短答案不丢分的时候,你应该选短答案这件事。
八、我的判断:这论文好在哪、有什么问题
真正打动我的地方
第一,问题诊断准。 "推理收敛 ≠ 答案就绪"这个区分,乍听不显眼,但展开了讲特别有道理。图 2 那张轨迹图把这件事讲得非常清楚——错误答案上的高置信度是真实存在的现象,是个 trap。在这之前我对早退方法的关注点都在 "怎么让停得更早",没想过 "停得早可能是停在了错的地方"。
第二,架构设计干净。 "detector 决定 where,verification 决定 whether" 这种分层让方法既能扛住计算成本、又能保持准确率。这种"过滤+决策"的两层结构在工程上是经典套路(参见 cascading classifier、KV cache 加速里的 speculative decoding),用在早退这个 setting 上挺自然。
第三,实验做得真厚实。 5 模型 × 5 benchmark 的主表、4 维度的 LLM-as-Judge 评估、墙钟延迟分解、ablation、零样本跨模态、三种 internalization paradigm(SFT/DPO/GRPO)。论文有意识地把每一个可能的质疑点都覆盖到了——"是不是只是 token 减少没真省时间?"延迟分解;"是不是把推理截烂了?"质量评估;"是不是只在数学题上有效?"代码+VLM;"是不是只是推理时 trick?"内化训练。
让我皱眉的地方
Redundancy Detector 的训练细节藏在附录里。论文正文只说用了 LoRA + InfoNCE,但训练数据怎么造的、有多少、负样本怎么挖,这些都得翻附录。这其实是整个 PUMA 的"核心 IP"——如果 detector 训得不好,整套系统就垮了。我希望作者能开源训练数据和详细脚本(github 仓库里需要确认)。
baseline 选择有点选择性。Answer Convergence 这种纯粹的 trial-answer 一致性 baseline 表现得非常差(DS-7B 上 accuracy 才 35.1),看起来像是把一个不太合理的 baseline 摆在那当陪衬。更现代的 baseline 比如 LightThinker、Chain-of-Draft 应该多对比。不过 prompt-based 的 CCoT、CoD 都有对比,工业界用得最多的 No-Think 也覆盖了,整体不算太差。
\(\tau_{sim}\)、\(\lambda\)、\(\epsilon\) 这些阈值的鲁棒性。论文附录有 sensitivity sweep,但实际部署到不同模型时还是要调。Plug-and-play 是相对的——你换个模型族大概率得 calibrate 一下检测器阈值。
LLM-as-Judge 评估的有效性。用 GPT-5.4 评估"哪个 CoT 更好",等于是用一个推理模型的偏好来判断另一个推理模型的输出。这种评估在学术界用得越来越多了,但它跟 human eval 的相关性其实是没保证的。用 PUMA 自己截短的链去问"哪个更简洁","PUMA 赢"是不是某种 confirmation bias 的产物?这一点论文没讨论。
跟同期工作的关系
PUMA 的 lineage 比较清晰:
- DEER(Yang et al.)是它最直接的 baseline——单点置信度早退,PUMA 在其上加了"何时该做这个判断"的门控;
- Dynasor / Answer Convergence 是一致性派早退,PUMA 用 verification window 借鉴了"多点一致性"的想法,但只在 detector flag 的点上做;
- Semantic Entropy(Kuhn et al.)是它的方法论灵感来源——把"语义塌缩"从 across-output 搬到 within-trajectory;
- LightThinker、C3OT 这些训练时压缩派则是 internalization 实验的对照——PUMA 证明可以把 inference-time 信号当成 SFT/RL 监督。
我觉得 PUMA 在这个 lineage 里的定位是一个"把早退做扎实"的代表作——不是范式革新,但把这个领域之前散乱的信号、方法、评估维度系统性地整合了一遍,并且指出了一个之前没被仔细讨论过的核心问题(推理收敛 vs 答案就绪的分离)。这种"扎实工作"在 LLM 推理加速领域其实非常稀缺。
九、对实际工程的启发
如果你在做 LRM 部署/推理加速,下面几条值得抄作业:
-
不要直接用 trial-answer 置信度做早退。它在错误答案上同样可以很高。至少要叠加一个推理过程的进展信号。
-
昂贵的判断要前置过滤。Trial-answer probing 不便宜,每步都做就是在烧钱。用一个 cheap signal(PUMA 用的是 0.6B 嵌入模型)筛出候选点,再上重型判断。
-
早退不仅可以做成 inference-time trick,还可以变成训练监督。如果你已经在用一个 inference-time 早退方法跑得很稳,可以试试把它截出来的轨迹当 SFT 数据,把这个能力内化到模型权重里——部署时纯 vLLM,没有额外延迟。
-
评估早退方法不能只看 token reduction + accuracy。还要看:retained CoT 质量、墙钟时间、各模型上的稳定性、跨任务可迁移性。
-
"模型已经想清楚了"是一个比"答案稳定了"更深的概念这件事。后者是表征,前者是过程。在 agent、长上下文、test-time scaling 等多个方向上,这个区分都会变得越来越重要。
最后说一句——这篇论文我读下来的感受是它没有那种"我们提出了全新的范式"的浮夸,但每一个设计决策都踩在点上。Detector + Verification + Loop Breaker 的三件套不复杂,但每一件都对应了一个具体的失败模式。这种克制的、问题驱动的工作,可能比那些声称"重新定义 X"的论文更值得读。
如果你也在被 LRM 的 overthinking 问题折磨,PUMA 这条路值得照着走一遍。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我