给智能体一张"地图":PEEK 把长上下文里反复重学的那部分缓存了下来
核心摘要
你有没有遇到过这种情况——同样一份 50k 条用户反馈的语料,业务方今天问"用户更喜欢功能 A 还是 B",明天问"新手引导抱怨最多的是什么",后天又来新一轮。每一次,智能体都从零开始爬一遍:先摸清这份语料长啥样,再确认有几个标签、字段怎么排,最后才进入正题。等它把"地形"摸清楚,token 烧得差不多了,回答还没那么准。
PEEK 这篇 NeurIPS 2026 的工作给出的方案很朴素,朴素到让人有点意外:别让智能体每次重学了——把那些"关于上下文本身"的可复用知识,缓存到一个叫 context map 的小工件里,常驻在 system prompt 里。这个 map 固定大小(默认 1024 token),里面记的不是任务策略、不是聊天历史,而是"这个上下文有什么、怎么组织、哪些常量和模式历史上有用"。靠 Distiller-Cartographer-Evictor 这三个模块去维护它。
效果数字相当能打:在 OOLONG 长上下文推理基准上,比强基线高 6.3–34.0 个点,比当前 SOTA 的 prompt learning 框架 ACE 还高 7.8–15.0 个点;同时迭代次数少 93–145 次,成本低 1.7–5.8 倍。换底座到 GPT-5.5、Qwen3-Coder、甚至 OpenAI Codex 都通用。
我对这篇的判断是:它真正的贡献不是"缓存"这个想法本身,而是把"缓存什么"这件事讲清楚了——四象限里那个一直空着的"主动维护外部上下文知识"的格子,PEEK 把它填上了。这是一篇思路漂亮、实验也比较扎实的系统论文,对在做 agent 工程的人有直接启发。
论文信息
- 标题:PEEK: Context Map as an Orientation Cache for Long-Context LLM Agents
- 作者:Zhuohan Gu、Qizheng Zhang、Omar Khattab、Samuel Madden
- arXiv:2605.19932(2026 年 5 月)
一、问题:智能体每次都在重学"地形"
先说一个我在做长文档 agent 时碰到过的痛点。
假设你给 agent 一份 50k 条的客户反馈 CSV,业务方一周内大概率会问 10 多个不同的问题。理论上 agent 应该越问越快——第一轮它已经知道了表结构、字段含义、有哪些常见标签、文本里特殊的分隔符是什么。但实际跑起来你会发现,第二轮第三轮它还在做几乎同样的探索动作:读前几行、统计行数、确认字段、试探格式。
为什么?因为现有的几类做法,没有一类是专门为"这个上下文本身"做记忆的。
长上下文窗口:直接把材料塞进 context window,每次都重新让模型扫一遍。token 烧得多,而且模型对长输入的注意力其实是衰减的。
RAG:按 query 检索相关片段。问题是 RAG 是被动的——你问什么它取什么,它不会主动维护"对这个语料的整体理解"。
Context Offloading(典型代表 RLM):把上下文存成外部变量,让 agent 写代码去 inspect、slice、recurse。灵活,但每次都要现场摸索。
History Compaction / MemAgent:把历史轨迹压缩。问题是它压的是"agent 干了什么",不是"agent 学到了什么关于上下文的事"。
Prompt Learning(ACE 是当前 SOTA):把 prompt 当成可学习对象,往里面累积任务级的策略和反思。这个思路其实最接近 PEEK,但它学的是"该怎么做这类任务",不是"这份语料是什么样子的"。
PEEK 用一张 2x2 的图,把整个设计空间归类得很清楚:
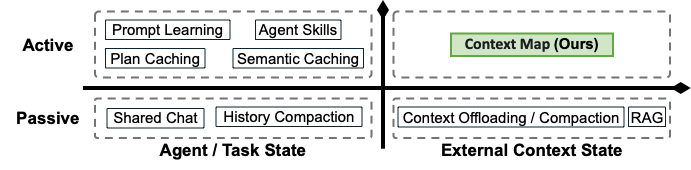
图1:四象限分类——左上是 prompt learning、agent skills、plan/semantic caching;左下是 shared chat、history compaction;右下是 RAG、context offloading、context compaction;右上空着,PEEK 来填。
这张图是这篇论文最有说服力的"卖相"。你看着就会想:是啊,这个格子确实一直没人专门去做过。RAG 是被动取用,Compaction 是被动压缩,Prompt Learning 是关心任务而不是上下文。"主动维护对外部上下文的理解"——这件事居然没有一个明确的对应方法。
说实话,我看到这张四象限的时候,第一反应是"这个发现有点像 KV cache 之于推理优化"——明明是显而易见的位置,但真正写一篇系统性的论文把它做实,是需要点眼力的。
二、核心思路:把"定位知识"当作一种缓存
PEEK 的核心抽象叫 context map,可以理解成"一个常驻在 system prompt 里、固定 token 预算、专门用来记录关于外部上下文的可复用知识"的小工件。
作者用了一个很到位的类比:硬件 cache 是把"频繁使用的数据"放在离 CPU 近的地方;context map 是把"频繁使用的关于上下文的知识"放在离 LM 近的地方(就是 prompt 里)。
那这张 map 里到底放什么?作者设计了 5 个 section:
| Section | 作用 | 例子 |
|---|---|---|
| Context Roadmap | 上下文索引——里面有什么、在哪 | "单一文本块(约 38k 字符),含 388 条 general-knowledge 问题" |
| Context Understanding | 高层理解——结构、关键实体、关系 | "数据集围绕 6 个互斥的答案标签:human being、description、abbreviation、location、numeric value、entity" |
| Domain Constants | 精确数值或枚举 | 标签集合、阈值、特定 ID |
| Reusable Results | 已经算过的中间结果 | "human being: 62; description: 80; abbreviation: 28..." |
| Parsing Schema | 格式与分隔符 | "每条记录形如 Date: ... \|\| User: ... \|\| Instance: ..." |
前两个是必备,后三个按需填充。整张 map 一开始几乎是空的(只有标题),所有内容都是 agent 跑着跑着自己攒出来的——作者刻意不预填、不手工设计,因为那样就违背了 PEEK 的核心承诺:自动从交互中发现并积累上下文知识。
来看一个实际的 map 长什么样:
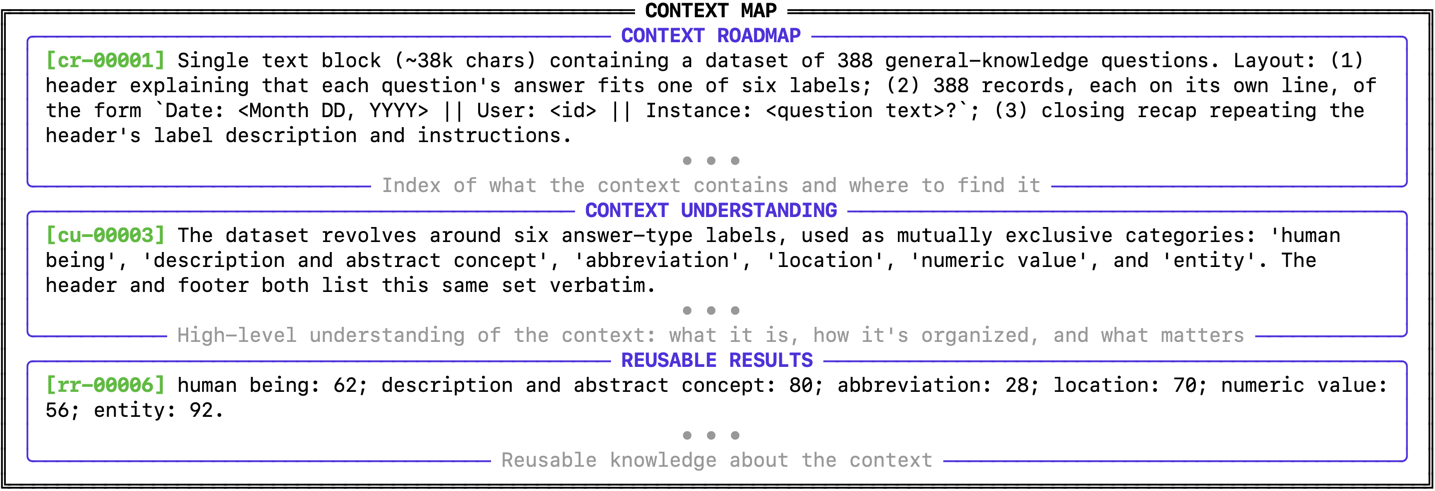
图2:实际跑出来的 context map(节选)。可以看到 Roadmap 记录了语料的物理结构,Understanding 记录了语义层面的标签集合,Reusable Results 直接把统计结果缓存了——下次再问"哪个标签最多"就不用重新数了。
这个例子我觉得特别有说服力。第三段那个 [rr-00006]——human being 62、description 80、abbreviation 28……如果这是 GPT-5-mini 真的在第一轮跑出来缓存下来的,那第二轮、第三轮再问相关问题,它根本不需要再扫一遍 38k 字符的文本块,直接读 map 就行。这才是 cache 真正的价值——把昂贵的计算变成廉价的查表。
每个条目都有稳定 ID([cr-00001]、[cu-00003]、[rr-00006]),这是工程细节里很关键的一笔——它让后续的"删除"、"替换"、"覆盖"操作可以精确到具体条目,而不是整段重写。这一点和数据库 record-level update 的思路是一致的。
三、系统设计:Distiller、Cartographer、Evictor
光有 map 这个数据结构还不够,关键是怎么维护它。PEEK 把这件事拆成三个模块,每个模块对应一个 LLM 调用:

图3:三段式的 cache policy。注意红框那个 FIX-SIZED MAP——它是常驻在 system prompt 里的,不会被 history compaction 抹掉。
Distiller:从 trajectory 里挖什么
每次 agent 跑完一个任务,会产生一条很长的 trajectory:planning、action、observation、reasoning,哗啦哗啦一堆。Distiller 做的事是把这条 trajectory 当输入,吐出三样东西:
- diagnosis:agent 这次主要时间花在了哪——是在做"摸地形"(orientation)还是真在解任务,哪里卡住了,哪里走得顺。
- tags:对当前 map 里每个条目打标签——helpful、harmful、neutral、stale。这是为后面的 eviction 排优先级用的。
- cache candidates:哪些信息值得加进 map。这里最关键的设计是只保留可迁移的上下文知识,扔掉任务特定的规则。
第三点是 PEEK 跟 ACE 等 prompt learning 方法本质区别的地方。ACE 学的是"这类任务应该怎么解"——这是任务特定的策略;PEEK 学的是"这份语料长什么样"——这是上下文特定的知识。前者是 playbook,后者是 map。
作者特意提到:Distiller 不依赖 ground truth 也不依赖 final answer,只用执行信号(reasoning 步骤、工具调用、observation)。这点对工业落地很重要——很多真实场景没有标注,没法做 supervised reflection。
Cartographer:从想法到编辑操作
Distiller 给出的是"应该加什么"、"应该删什么"的高层意图。Cartographer 把这些意图翻译成具体的 Add / Delete / Replace 操作,每个操作精确指向一个条目 ID。
为什么要把 Distiller 和 Cartographer 拆开?作者在 ablation 里专门做了一组"Monolithic Update"——把这两步合成一次 LLM 调用,结果掉了 7.7 个点。
我觉得这个拆分的理由很 solid。让一个 LLM 同时做"诊断"和"编辑",它会容易混淆——把任务特定的细节当成上下文知识塞进去(leaky),或者重复添加已经存在的条目(duplicative),或者把稳定条目轻易覆盖掉。分离 diagnosis 和 edit 是工程上经典的"先想清楚再动手"的做法,跟数据库里 query planning 和 query execution 分离是一个道理。
Evictor:固定 budget 怎么留下最有价值的
Map 是有 hard token budget 的(默认 B=1024),超过就得驱逐。Evictor 的策略很直接:
- 按 Distiller 累积的分数升序删——分数低的先走
- 同分按时间,老的先走
- Section 级有保护层级:
Parsing Schema最先删,然后Reusable Results、Domain Constants,Context Roadmap和Context Understanding受最高保护
这个保护层级我觉得是经验之谈。Roadmap 和 Understanding 是"地图本身",删了等于把方向感丢了;Parsing Schema 和 Reusable Results 相对容易再生成(只要重新扫一遍数据)。
伪代码长这样:
def peek_loop(context, queries, budget_B, evolve_steps_m):
map = init_empty_map()
for i, Q in enumerate(queries):
# 把 map 拼到 system prompt 里
prompt = system_msg + map + Q
action, trajectory = agent_loop(prompt, context)
if i <= evolve_steps_m: # 只在前 m 个 query 更新
diag, tags, cands = distiller(trajectory, map)
edits = cartographer(diag, tags, cands, map)
map = apply(map, edits)
map = evictor(map, budget_B)
return actions
注意 m:作者发现 cache evolution 可以在很少几个 query 之后就冻结(实验里 \(m \leq 4\) 就够了)——也就是说 PEEK 不需要一直在线学习,前几个 query 把 map 攒起来,后面纯粹复用就行。这是它比 ACE 便宜的关键原因之一:ACE 是 always-on adaptation,每个 query 都触发 reflector + curator 调用。
四、实验:到底好多少
实验设计可圈可点。两个 benchmark:
- OOLONG:长上下文推理与信息聚合,从论文里 10 个 split 中挑了 3 个最难的(trec_coarse、agnews、yahoo)
- CL-bench:上下文学习基准,每个 context 配多个相关任务(最多 12 个),用 GPT-5.1 当 judge,报 solving rate(粗粒度)和 rubric accuracy(细粒度)
底座是 RLM agent + GPT-5-mini,对比 5 种基线:base RLM、Shared Chat、RAG、Compaction Agent (MemAgent)、ACE。
主表:PEEK 把所有人都甩在后面
| 方法 | TREC-Q-coarse↑ | AGNews↑ | Yahoo↑ | CL Solve↑ | CL Rubric↑ |
|---|---|---|---|---|---|
| RLM (base) | 30.3 | 46.5 | 23.0 | 14.0 | 54.5 |
| RLM + Shared Chat | 32.0 | 49.6 | 23.0 | 12.0 ↓ | 51.3 ↓ |
| RLM + RAG | 36.6 | 63.1 | 29.0 | 14.0 | 55.6 |
| RLM + Compaction Agent | 42.0 | 49.5 | 30.0 | 20.0 | 54.6 |
| RLM + ACE (online) | 48.8 | 61.6 | 42.0 | 20.0 | 53.5 ↓ |
| RLM + PEEK | 58.1 | 69.4 | 57.0 | 26.0 | 63.4 |
几个值得停下来想一想的点:
Yahoo 这一栏特别炸。从 23.0 到 57.0,整整涨了 34 个点。Yahoo Topics 是 OOLONG 里出了名的难——10 个语义重叠度高的 topic 类别,模型很容易混淆。这个涨幅说明 PEEK 把"标签集合是哪些、彼此怎么区分"这种关键定位知识真的存进了 map 里。
Shared Chat 在 CL-bench 上掉了 2 个点。这个是反直觉的——你以为把历史 trajectory 留着应该越用越好用?但作者的原话是"raw context becomes noise that degrades rather than aids"。这个我深有体会,做 agent 工程的人应该都见过:trajectory 越累越长,模型反而被噪声淹没,关键信息找不到。
ACE 在 CL-bench rubric 上还掉了 1 个点。作者解释是 "consistent with a playbook that indicates task-specific optimization that trades off partial correctness elsewhere"——翻译过来就是 ACE 学的是任务策略,过度针对粗粒度的 solve 优化,细粒度的部分正确性反而被牺牲了。这个观察其实挺扎心的,也间接证实了 PEEK 关于"任务策略 vs 上下文知识"区分的洞察。
性能快照可视化
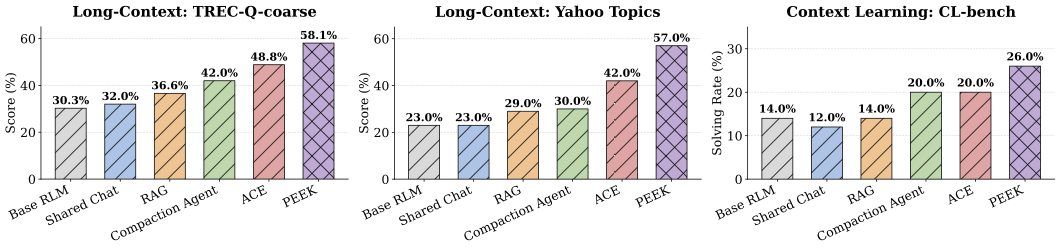
图4:从 base RLM 到 PEEK,单看 TREC-Q-coarse 是 30.3 → 58.1;Yahoo 是 23.0 → 57.0;CL-bench solve 是 14.0 → 26.0。每一栏 PEEK 都比第二名高 8 个点以上。
不只是更准,还更便宜
这一节我觉得是这篇论文最值钱的部分。如果 PEEK 只是"更准",那它跟 ACE 没什么本质区别——都是把 prompt 当成可学习对象。但 PEEK 在迭代数和成本上同时碾压:
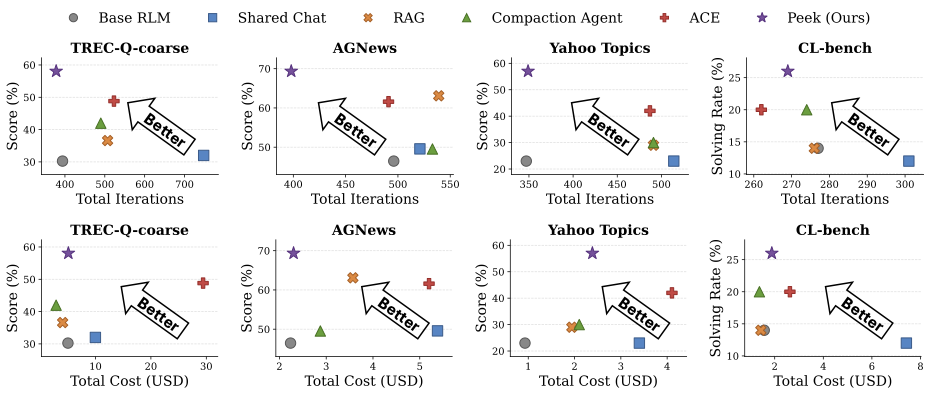
图5:星号是 PEEK,红十字是 ACE。Yahoo 那张图最戏剧——PEEK 在大约 350 次迭代、2 美元成本下达到 57 分,ACE 在 500 次、4 美元下才 42 分。差距是肉眼可见的。
具体数字:
- OOLONG 上 ACE 比 PEEK 多用 93–145 次迭代,成本贵 1.7–5.8 倍
- CL-bench 上 Shared Chat 比 PEEK 贵 3.9 倍,质量却更差
为什么 PEEK 这么便宜?我的理解是两层原因:
- Cache evolution 可以早停(\(m \leq 4\))。PEEK 跑完前几个 query 把 map 攒起来后就不再更新了,后续 query 是纯复用。ACE 是每个 query 都触发 reflector + curator,always-on。
- Map 让 agent 少摸地形了。一旦 map 里写了"标签集合是 6 个、记录共 388 条、格式是 X",下次 agent 就不需要再 grep、count、parse,直接进入主任务。这反映在迭代数上。
说实话,看到 ACE 在 CL-bench 上掉点的时候,我有点意外——ACE 是公认的 SOTA prompt learning 框架。但仔细看作者的对比,PEEK 和 ACE 优化的是不同的对象,所以这不是 ACE 不行,而是它和 PEEK 解决的问题维度不同。如果你的场景是同一个 agent 反复处理同一个外部上下文(比如企业内部文档库),PEEK 显然更合适。如果你的场景是 agent 处理各种不同的任务(比如通用编码助手),ACE 可能更对路。
跨模型/跨 agent 泛化
这块作者做得比较扎实。除了主实验的 GPT-5-mini,还测了:
- GPT-5.5(前沿大模型):PEEK 比 ACE 在 OOLONG 上高 18.1–17.0 个点,CL solve 高 12 个点
- Qwen3-Coder-Next-FP8(开源):在它 code-centric 训练的劣势下,PEEK 还是把 Yahoo 从 32 拉到 58
- OpenAI Codex 替代 RLM:PEEK 反而涨得更猛——TREC-Q-coarse +44 个点、Yahoo +52 个点
最后一点尤其重要:PEEK 的算法和 prompts 完全不变就能挂到 Codex 这种生产级编码 agent 上还能涨那么多。这说明 context map 这个抽象不依赖具体 agent 架构,是个通用的设计。
不过这里要打个折扣——GPT-5.5 那一栏 base RLM 跑一次就花了 $148.84,所以作者只在三个 split 上各跑了 100 个样本(论文里说"unable to run the entire benchmark")。样本量小一点,结论强度要打折,但趋势仍然是清晰的。
消融:哪些设计是必要的
| 变体 | TREC-Q-coarse | AGNews | Yahoo |
|---|---|---|---|
| Base RLM | 30.3 | 46.5 | 23.0 |
| PEEK No Eviction(攒到 budget 就冻结) | 52.0 | 66.9 | 35.0 |
| PEEK Monolithic(Distiller+Cartographer 合并) | 46.9 | 67.5 | 47.0 |
| PEEK B=512 | 46.1 | 69.1 | 31.0 |
| PEEK B=1024(默认) | 58.1 | 69.4 | 57.0 |
| PEEK B=2048 | 44.6 | 63.2 | 53.0 |
几个有意思的发现:
No Eviction 还能拿 52/66.9/35 分。说明就算你不做主动 eviction、就算 cache policy 不那么聪明,光是"有一个 context map"这件事就已经能涨很多——平均 +10.2 个点的差距是 Evictor 带来的精修。
Monolithic 掉了 7.7 个点。验证了 Distiller / Cartographer 拆开是必要的。
Cache size 4 倍变化(512 ↔ 2048),效果差异不大。512 平均 +15.5 个点,2048 平均 +20.3 个点。作者的判断是 map 存在比 map 多大更重要。这个发现挺有工程价值的——你不用太纠结 budget 调多大,1024 是个甜蜜点,再大反而可能引入噪声。
等等,2048 反而比 1024 差?我盯着这个数字想了一会儿。1024 在 TREC-Q-coarse 是 58.1,2048 掉到 44.6——这个反转挺反直觉。我猜(论文没明说)是因为 budget 大了之后,Distiller 对"什么是 worth caching"的判断变得宽松,开始把一些次要的、半相关的东西也写进 map,反而稀释了关键信息的浓度。这是 cache 系统里的经典问题:cache 大不一定好,命中率取决于内容的相关性,不是容量。
五、我的判断:哪些值得抄,哪些要打问号
先说亮点。
最值钱的洞察是那张四象限图。把"主动维护外部上下文知识"作为一个独立的设计维度提出来,逻辑非常自洽。我接下来几个月做 agent 工程,估计会反复用这个框架去归类自己的设计——这是真正能改变思考方式的工作。
Distiller / Cartographer 分离是个干净的工程抽象。我之前在做类似的 prompt 自更新机制时,确实犯过把"诊断"和"编辑"塞进一个 LLM call 的错——结果就是 prompt 变得越来越乱,又删不掉旧的、又不停加新的。如果重做,我会直接借鉴这个设计。
条目级 ID + section 化结构让 map 可以做精确编辑。这是从数据库设计借来的思路,但真用到 prompt 工程里,能避免"整段重写"导致的不稳定。
再说我觉得需要打问号的地方。
"主动维护外部上下文知识"真的需要单列一个象限吗?仔细想想,PEEK 做的事和 prompt learning 在机制上几乎完全一样——都是让 LLM 反思 trajectory、更新 prompt 里的某段文本。差别只在于"反思的对象是任务还是上下文"。这个差别是足够重要到需要单独立类,还是只是同一类方法换个用法?我觉得作者的论证是"任务特定 vs 上下文特定信息混进 map 会变差"(ablation 里有体现),但这个区分在工程上其实很模糊——什么算任务特定?什么算上下文特定?很多边界 case 怎么办?
实验都是反复同上下文的场景,这是 PEEK 最擅长的工作负载。但真实世界很多 agent 任务并不是这样——比如客服 agent,每个 conversation 都是新上下文;比如代码助手,每次进的可能是不同 repo。这些场景下 context map 还能 work 吗?论文里没正面回答这个问题。
Cache 的"冷启动"问题没充分讨论。PEEK 的 map 一开始是空的,前几个 query 是它在攒地图的过程。这意味着头几个 query 会比较慢、比较贵、质量也不一定最好。论文报告的指标是平均下来的,没有 break down 到"前 m 个 query 的成本"vs"后续 query 的成本"。如果你的实际场景每个上下文只问 2-3 个问题,PEEK 的回报期可能还没到。
和 KV cache 的关系。作者特意区分说"PEEK 是 agent-level artifact,KV cache 是 model-level optimization"。但实际工程里这两件事会互动——map 在 system prompt 里是稳定的,KV cache 命中率应该会很高。这部分的协同效应论文里只是顺带一提,我觉得是个值得展开的工程话题。
六、对工程的启发
如果你也在做 agent 系统,下面几条我觉得直接可以抄:
1. 把 prompt 显式拆成可学习的部分和稳定的部分。PEEK 的 map 在 system prompt 里有明确的边界——5 个 section、固定 budget、条目有 ID。这种结构化的可学习区域,比"让 LLM 自由编辑 prompt"稳定得多。
2. 缓存什么 ≠ 缓存历史。这是我读完最大的体会。Trajectory、聊天记录、摘要这些都是"过程",不是"知识"。真正值得存的是从过程里蒸馏出来的、关于这份数据/上下文的可复用 understanding。
3. 给每个 cache 条目加 ID 和优先级。这样后续的 update / eviction 可以是 surgical 的,而不是粗暴的整段覆盖。这一点说起来简单,但真做的时候很容易忽略。
4. Cache evolution 可以提前冻结。不是所有阶段都需要 always-on adaptation。前 m 个样本攒完知识后冻结,能省一大笔成本。这个 m 可能比你以为的小得多(PEEK 实验里 ≤ 4 就够)。
5. 小 budget + 高质量 选择 > 大 budget + 大杂烩。1024 token 的 map 干掉了 2048 token 的版本,给的启示是 cache 的命中率取决于内容质量,不是容量。
最后,我对这篇的整体评价是:思路 8.5 分,实验 8 分,叙事 9 分。它不是那种"全新算法"的论文,本质上是把"prompt 是可学习对象"这个老主意应用到一个之前没人专门关注的子象限。但它把这件事讲得清晰、做得彻底、实验数据也撑得住,是一篇很标准的 systems paper 范例。如果你做 long-context agent 或者企业内部知识库 agent,这篇值得花一两个小时仔细读,并且 map 这个数据结构可以直接搬到自己的系统里改一改用。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我