一篇综述把多智能体的"协作—归因—自演化"串成一条因果链:LIFE 框架的意义
写在前面
做 Agent 这两年,有个困惑我一直没想清楚:
为什么单个 LLM 越来越强,多智能体系统反而越来越脆?
你一定见过这种场景。一个 Planner + Retriever + Executor 的小团队,单跑某个组件的时候每个都挺正常,凑成系统跑长任务,出错的方式千奇百怪——而且最让人头疼的是错误总在最不该出的地方暴露出来。明明 Retriever 在第 3 步给错了,最后崩在第 8 步的 Verifier 那里;明明 Planner 的子目标漏了一项,问题却在 Executor 调工具失败时才显形。等你回头去复盘,长长的 trace 里几千上万 token,根本不知道该从哪一步开始追。
更尴尬的是下一步——就算你定位到了错误,系统也没法真正改掉它。你只能手动改 prompt、重新设计 topology、换一个角色分配,下一次跑可能又出新问题。
这其实是当下 LLM 多智能体系统最深的一个结构性矛盾:单体能力越强、协作组织越复杂,错误传播越隐蔽,自我改进就越难闭环。
最近读到一篇综述,把这个问题终于讲清楚了——它不是再综述一次"Agent 能力有哪些"或"多智能体协作怎么做",而是把单体智能、协作组织、故障归因、自我进化这四件事用因果关系串起来,给了一个名字叫 LIFE。看完之后我有一种"这条线本来就该这么画"的感觉。
下面把核心内容梳理一遍。
核心摘要
这篇综述的核心判断是:现有的 LLM 多智能体综述都在各自的角落里转——单体能力是一波,协作机制是一波,自我进化又是一波,但没人把"系统部署之后会失败、失败之后怎么诊断、诊断之后怎么改进"这条闭环串起来讲。尤其是故障归因(failure attribution)这个方向,过去一年才作为独立研究领域冒出来,之前的综述基本没覆盖。
作者提出 LIFE 渐进框架,把多智能体系统的完整生命周期拆成四个因果耦合的阶段:Lay the capability foundation(奠定能力基础)→ Integrate agents through collaboration(协作整合)→ Find faults through attribution(归因发现故障)→ Evolve through autonomous self-improvement(自主进化)。每一阶段依赖前一阶段、约束下一阶段。
最值得看的是归因—进化的闭环那部分:他们明确指出,失败归因不只是"事后查 bug",更是自我进化的搜索空间约束器——没有可靠的归因,进化就只能瞎调;没有可执行的进化,归因就只能停留在分析报告。这个 coupling 此前几乎没人正面写。
适合什么人看?正在做或打算做多智能体系统的工程师/研究者,特别是那些已经搭起原型、开始头疼"为什么改一个 prompt 就连锁出问题"的人。综述类文章读起来不像方法论文那样烧脑,但能给你一个把碎片化经验串起来的全局视角。
论文信息
- 标题:Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems
- arXiv:2605.14892
- 作者:Shihao Qi, Jie Ma(通讯), Rui Xing, Wei Guo, Xiao Huang 等 17 位作者
- 版本:v2,2026 年 5 月
一、为什么需要 LIFE:把"分裂的三波综述"接起来
先聊聊问题动机。
你去搜 LLM 多智能体相关综述,基本能看到三条平行线:
- 第一条线:单体 Agent 能力综述。讲推理、记忆、规划、工具调用——把单个 Agent 当成一个独立的决策系统拆。代表作如 Wang et al. 2024、Xi et al. 2025。
- 第二条线:多智能体协作综述。讲角色分工、通信协议、编排拓扑、交互模式。代表作如 Guo et al. 2024、Tran et al. 2025。
- 第三条线:智能体自我进化综述。讲 Agent 如何通过环境反馈自动调整 prompt、记忆、工具、workflow。这条线最年轻,2025 年才陆续出现。
这三条线各自都有不错的覆盖,但有一个共同的问题——它们把多智能体系统的生命周期切断了。
举个例子。第一条线讲单体 Agent 的 Reasoning,会把 CoT、Tree-of-Thoughts、PRM 这些方法分门别类列出来,但不会去追问:当这些单体能力被装进多智能体系统后,它们的失败模式会不会因为"多个 Agent 互相喂错误信息"而被放大?
第二条线讲多智能体协作的拓扑(centralized/distributed/hybrid),会列各种 MetaGPT/AutoGen/AgentVerse 之类的框架,但很少正面讨论:不同的协作拓扑会让什么类型的故障变得"可观测/可归因",什么类型的故障变得"几乎追不到根因"。
第三条线讲自我进化,会讲 prompt rewriting、memory update、topology evolution,但几乎不讨论:进化的"信号"从哪来?如果故障归因没做好,那进化的方向其实是随机的。
作者在 Introduction 里说得很直接:
Bridging this gap requires a closed-loop framework in which failure diagnosis directly informs structural self-improvement.
也就是说,缺的不是"再写一篇综述",而是一个把这些环节串起来、看清楚相邻阶段如何耦合的框架。这就是 LIFE 的由来。
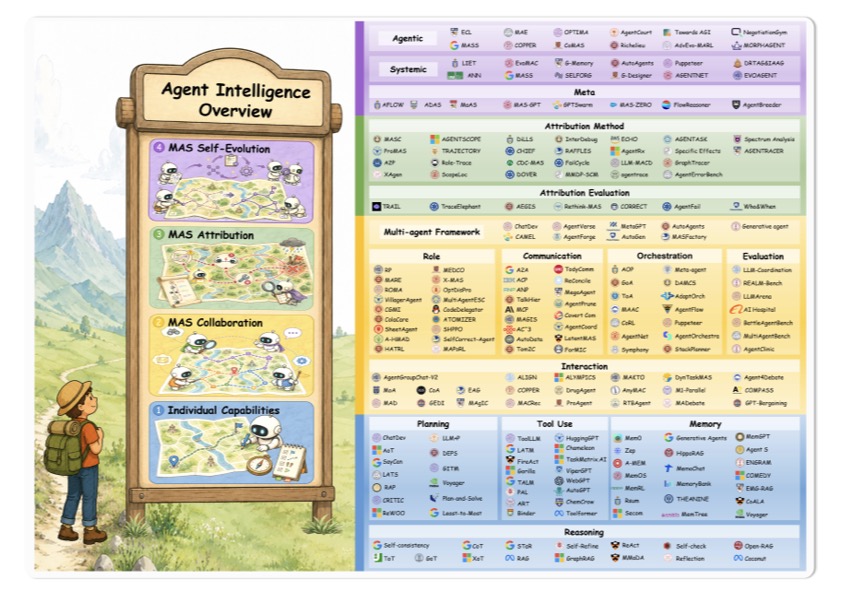
这张总览图能传递的信息其实比标题多——它不是"四个并列的话题",而是一段有方向的旅程。每一阶段都明确依赖前一阶段铺好的底座。
二、LIFE 的四个阶段:先看一张全景图
讲细节之前,先看作者画的 LIFE 全景图,这张图我反复看了好几遍,觉得很贴切。
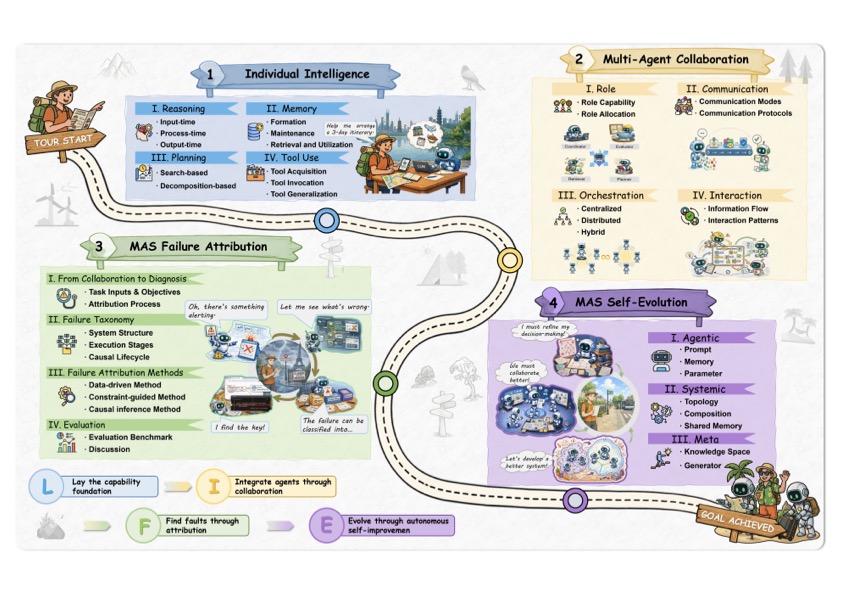
我特别喜欢这个图的几个细节:
- 用同一个场景(旅行规划)贯穿四阶段。你能看到同样的几个 Agent(Hotel/Restaurant/Weather/Attractions)在每个阶段都出现,但承担的角色不同:在阶段 ② 是协作执行者,在阶段 ③ 出错被诊断,在阶段 ④ 进化升级。
- 每阶段的 4 个子主题用同样的视觉层级。这其实在暗示一件事——综述的内部组织是"对齐的",每个阶段都是 4 个子维度,方便横向比较。
- 底部一行从 L → I → F → E 是渐进字母,不是装饰。L 是"垫底子",I 是"集成起来",F 是"找出毛病",E 是"进化升级"。读完整篇综述再回看这个字母排序,会觉得设计得很走心。
OK,路线图看完了,下面挨个聊。
三、阶段 L —— Individual Intelligence:把单体 Agent 当成"四维能力的有机闭环"
第一阶段是单体智能。作者没有按"能力列表"的方式罗列,而是先给了一个形式化定义,把 Agent 描述成一个结构化的序列决策系统:
分别对应观测空间、动作空间、工具返回观测、记忆状态、推理函数、规划函数、工具执行函数。然后在每个时间步 \(t\),Agent 走这样一个闭环:
这套形式化的意义不在于公式本身——其实挺标准的——而在于它把"推理-记忆-规划-工具"四个能力的耦合关系明确画出来了:记忆既是输入(\(c_t\))又是输出(\(m_{t+1}\));推理结果会喂给规划;规划生成的动作会通过工具返回观测,再回到记忆更新。
这个公式串起来看,作者的潜台词是:后续讲多智能体的所有"协作"问题,其实都是这个单体闭环的扩展和耦合。你之后会看到,故障归因那一节,作者直接把多智能体的轨迹定义成一个时序的 \((i_t, u_t)\) 序列——这就是从单体的 \(u_t\) 自然扩展上去的。
四维能力的具体分类我就不展开列了,但有几个反直觉的观察值得提:
1. Reasoning 不是"用 CoT 就行",而是按数据流分三段。 作者把推理增强分成 Input-Stage(RAG/多模态注入)、Process-Stage(搜索空间扩展 + 路径验证)、Output-Stage(可靠性评估 + 行为调控)。这个划分挺扎实的——因为它对应了推理失败的三个不同环节:输入信息不够、推理路径错了、输出没校验。
2. Memory 不是单一概念,而是 Formation/Maintenance/Retrieval 三个独立环节。 我之前做项目时一直把 Memory 当成"一个向量库 + retrieve",看完这块意识到 maintenance(写入策略、压缩、更新)才是真正决定 Memory 是否能长期 work 的关键。
3. Planning 的 search-based vs decompose-based 是两种正交思路。 Decompose 是 LLM 直接生成子目标树(Plan-and-Solve、Least-to-Most),search 是把 plan 看成搜索问题(LATS、Voyager)。当任务规模变大时,前者会"思考一团乱麻",后者会"无谓地展开"——这是后续多智能体协作要解决的问题,单体很难两全。
第一阶段的 take-away:单体 Agent 是一个闭环系统,不要把它拆成"组件列表"来看。后面所有的多智能体协作问题,本质上都是把多个这样的闭环耦合在一起带来的新问题。
四、阶段 I —— Multi-Agent Collaboration:从"个体闭环"到"组织结构"
到了多智能体阶段,问题的性质变了。作者把多智能体协作拆成四个维度:Role(角色)、Communication(通信)、Orchestration(编排)、Interaction(交互)。
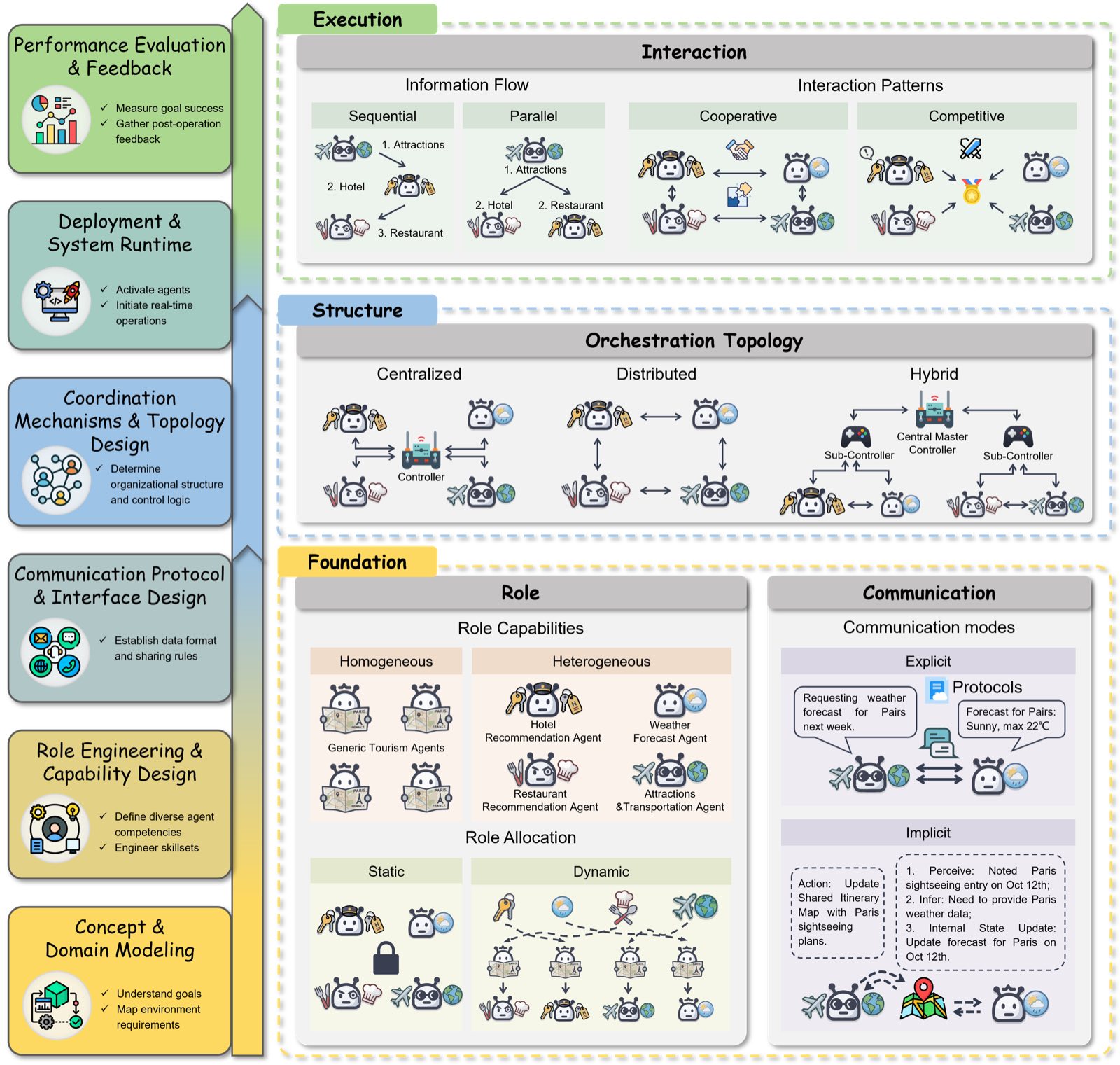
这张图我看过几遍,越看越觉得它隐含了一个重要主张:四要素是有层次的,不是并列的。Role 和 Communication 是基础(你得先决定有哪些角色、怎么通信),Orchestration 是中间层(决定他们的组织拓扑),Interaction 是最上层(决定具体怎么动起来)。这个层次感解释了为什么很多多智能体框架"看起来什么都做了,但还是不 work"——往往是基础层的 Role 设计就有问题,上层的 Orchestration 再花哨也救不回来。
简单走一遍:
Role:角色能力(同质 homogeneous vs 异质 heterogeneous)+ 角色分配(静态 vs 动态)。MetaGPT 这种把 PM/Architect/Engineer 写死的,是典型的异质 + 静态;AutoAgents 让 Planner 在运行时动态创建专家 Agent,是异质 + 动态。
Communication:显式通信(Agent 之间发明文消息)vs 隐式通信(通过共享黑板/共享内存间接传递)。MCP(Model Context Protocol)、A2A(Agent-to-Agent)这些近期标准化协议,本质上就是想让显式通信变得"可互操作",让生态系统的 Agent 能跨框架调用。
Orchestration:拓扑三选一——集中式(一个 Controller 调度所有 Agent)、分布式(peer-to-peer 自组织)、混合式(多层级)。集中式简单但单点失败;分布式抗故障但难调度;混合式是当前主流框架的折中。
Interaction:信息流的形态(顺序/并行)+ 任务关系(合作/竞争)。竞争式交互(debate、self-consistency 投票)在很多 reasoning 任务上确实涨点,但要小心它的代价——计算开销倍增 + 评估难度上升。
这一段最有意思的判断在 Discussion 部分:作者点出当下多智能体协作研究的最大盲点是评估。各种花哨的 framework 都自己设计 benchmark,结果是横向不可比、绝对性能未必比提示工程优化的强单体更好。这一点其实业界已经吐槽了一段时间——pan2025whymultiagentfail 这篇就直接做了大规模实证,发现很多多智能体系统在简单任务上反而被强单体打败。
这就引出了下一阶段——为什么多智能体会失败?失败了能不能归因?
五、阶段 F —— Failure Attribution:综述里最值钱的一块
我个人认为这一章是整篇综述里最值得仔细读的一节。原因有两个:
- 故障归因(failure attribution)是一个最近才独立出来的研究方向,2025 年才陆续有 Who&When、TRAIL、AgenTracer、AgentFail 这些代表工作。之前的综述基本没正面覆盖。
- 这是连接"协作"和"自我进化"的关键枢纽——没有归因,进化就是瞎调;有了归因,进化才有方向。
作者先给了一个非常清晰的形式化。设系统执行轨迹为:
其中 \((i_t, u_t)\) 是 \(t\) 时刻活跃的 Agent 和它的动作。再定义一个轨迹评估函数 \(Z(\tau)\),\(Z(\tau)=1\) 表示最终结果异常。那么故障归因模型 \(f\) 的任务是:
也就是说,给定系统配置 \(\Omega\)、用户查询 \(q\)、完整轨迹 \(\tau\),找出是哪个 Agent 在第几步引入了导致最终失败的关键错误。这是 agent-step pairwise 的最小定义,实际研究中已经扩展到 multi-agent、multi-step、causal-chain 多种粒度。
5.1 失败为什么这么难归因?传播机制是关键
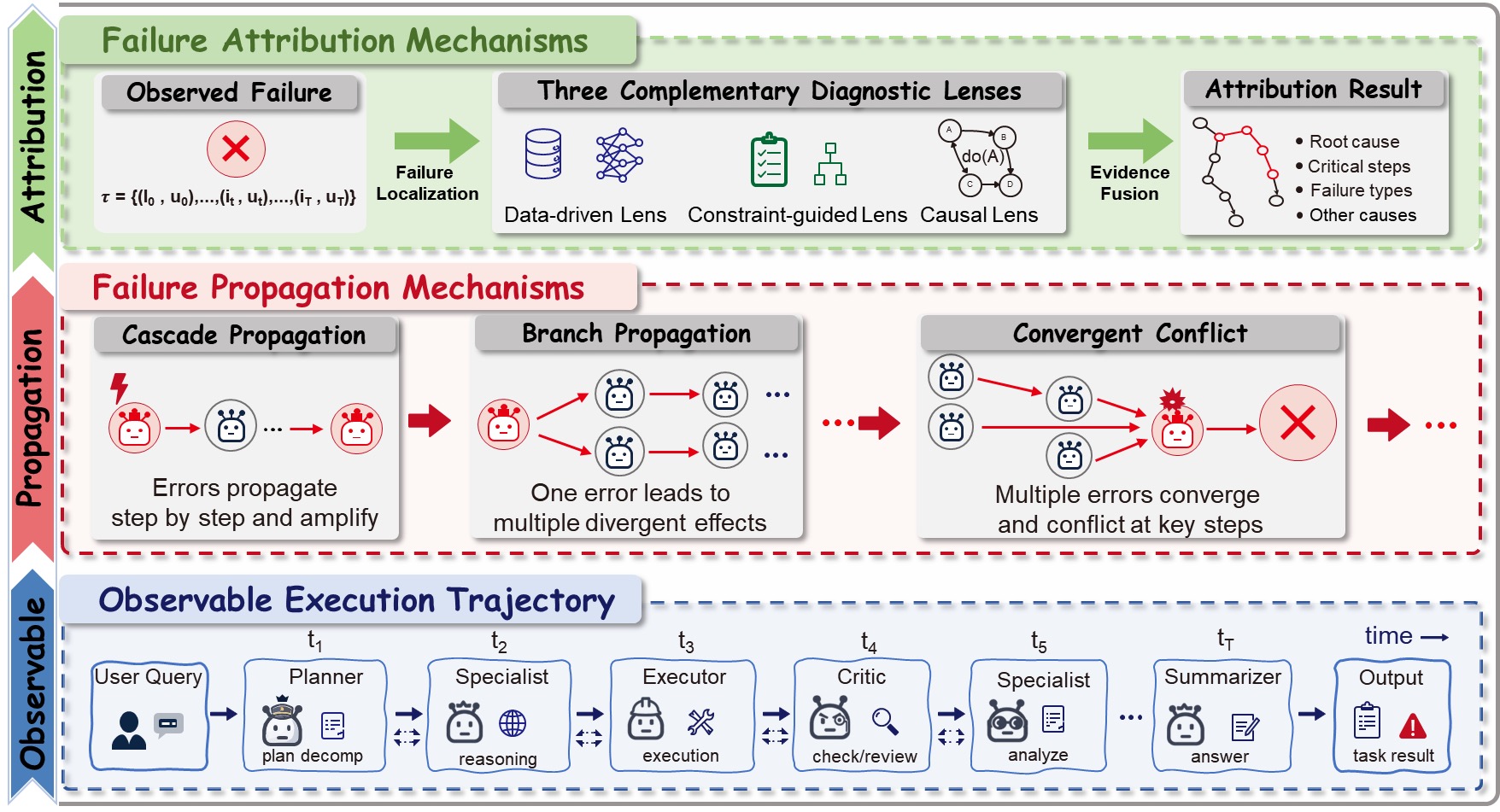
这张图把"失败传播的三种形态"画得特别清楚,这是我之前调多智能体最深的痛——
- 级联传播:一个 retriever 给了错信息,下游 verifier 没察觉就当真,executor 按错信息执行,最后输出错误。错误"原封不动"地往下传,但每经过一个 Agent 就被"加固"一次。
- 分支传播:一个错误派生出多条问题路径。比如 Planner 把一个错误子目标分给三个 specialist,三个 specialist 各自做出三个相关但不一致的输出,最后 Summarizer 怎么拼都拼不对。
- 汇聚冲突:两条不同路径上的错误在某个汇合点冲突,导致系统直接崩。比如 Weather Agent 说会下雨,Attractions Agent 推荐了室外景点,Summarizer 在生成最终行程时报错。
理解了这三种形态,你就能理解为什么"看 trace 找 bug"这么难——错误最先暴露的位置往往不是错误真正发生的位置。这就是 ma2026demystifying(FailCycle)那篇论文的核心观察:failure origin ≠ failure manifestation。
5.2 三大归因方法路线
作者把归因方法分成三条互补的路线,我用表格梳理一下:
| 路线 | 核心思路 | 代表方法 | 主要优势 | 主要短板 |
|---|---|---|---|---|
| Data-driven(数据驱动) | 把归因当成"学习问题"——用大量带标注的失败轨迹训练专用归因模型 | AgenTracer(反事实重放 + 错误注入造数据 + 训小模型)、AEGIS(上下文感知错误注入 + SFT/RL/对比学习多范式)、GraphTracer(信息依赖图建模) | 自动化、可扩展、适合在线诊断 | 依赖造数据,对真实未见过的失败模式泛化弱 |
| Constraint-guided(约束引导) | 把归因当成"结构化诊断流程"——通过 scope delimitation、错误分类、责任边界等约束缩小搜索空间 | SDBL(先圈定范围再定位)、A2P(因果假设生成 + 最小修正 + 结果预测)、DoVer(干预+重放验证假设)、AgentRx(自动生成约束并逐步检查) | 可解释、可审计、root cause 有据可查 | 强依赖人工先验,跨任务迁移性差 |
| Causal-inference(因果推断) | 把归因当成"因果效应估计"——通过反事实重放、干预分析识别真正驱动失败的关键行为 | Agent-Specific Effects(多智能体 MDP 下的反事实效应估计)、CDC-MAS(因果发现 + Shapley value)、CHIEF(轨迹重构成层次因果图) | 真正回答 "为什么失败",区分根因和传播症状 | 计算开销高、依赖可重放的环境 |
我个人最看好的是 causal-inference 这条路线,原因是它在概念上最干净——它能区分早暴露的错误和真正驱动失败的错误,这是 data-driven 和 constraint-guided 都做不到的。但代价也最大:它需要可重放的环境,需要构建因果图,工程实现复杂度上一个台阶。
5.3 归因评估:从单点失败到多因失败
归因评估也分三种典型场景:单点失败(错误集中在一个 Agent 的一步)、传播链失败(错误从源头一路传播到最终症状)、多因失败(多个独立错误共同导致失败)。对应的输出粒度也有五种:Agent-Level Label、Step-Level Label、Failure Type Label、Propagation Chain、Multi-Cause Set。评估准则包括定位准确率、失败类型准确率、因果链一致性、多因覆盖、解释和修复实用性。
数据集方面,作者整理了一张表,Who&When(184 条)是最早的 benchmark;TRAIL(148 条)把失败分类更细;AgentFail(307 条)扩展到 platform-orchestrated workflow;CORRECT-Error(2000+,合成)和 AGENTRACER(合成)走自动构造路线。目前真正"高质量 + 大规模"的开放数据集还很缺,这是接下来一年这个方向最大的瓶颈。
5.4 我对这一章的几个判断
读完归因这一章,我有几个比较强的判断,说出来供参考:
1. 归因 ≠ 后处理 debug 工具,而是 MAS 的"内置传感器"。 当前大部分归因方法还停留在 offline 模式(系统跑完了再分析 trace),但真正有价值的是 online 归因——在错误传播过程中就预警和阻断。AgentAsk、Trajectory Graph Copilot、Trajectory Guard 这几篇代表了这个方向,但它们还很初步。
2. 现有归因方法基本都假设"单因单果",这在工程中根本不成立。 真实的多智能体失败几乎都是多因耦合,但 Who&When、TRAIL 这种主流 benchmark 都只标注"一个责任 Agent + 一个关键步骤"。这导致一个尴尬局面——模型在 benchmark 上做得越准,离真实场景越远。FailCycle、MMDP-SCM 这些往多因方向走的工作还很少。
3. 归因—修复闭环还远没建立。 作者整理的 39 个归因方法表里,明确支持 downstream repair 的不到一半。这是这个领域当下最大的工程 gap——能定位却不能修复,价值就打了对折。
六、阶段 E —— Self-Evolution:从"事后总结"到"系统级蜕变"
到了最后一阶段——自我进化。这一节我觉得是综述里最有理论野心的一块。
作者把静态多智能体系统的描述扩展成一个离散时间的演化过程:
其中 \(k\) 是"代次"(generation),系统的每个组件(Agent 集合、环境、通信协议、编排拓扑、协作策略)都随 \(k\) 演化。演化由一个映射 \(\Gamma\) 驱动:
其中 \(H^{(k)}\) 是历史上下文(包括过去的执行轨迹 \(\tau\)、归因结果、peer-agent 评价等)。优化目标是在任务分布 \(\mathcal{D}_{\text{task}}\) 上的期望提升:
这个形式化的妙处在于:进化的"信号"从哪来?正是上一阶段的归因结果 \(H^{(k)}\)。这就把"故障归因"和"自我进化"在数学上正式 couple 起来了。我之前看其他自我进化综述,从来没人这样明确把归因当成进化的"输入"。
6.1 三层进化目标:Agentic / Systemic / Meta
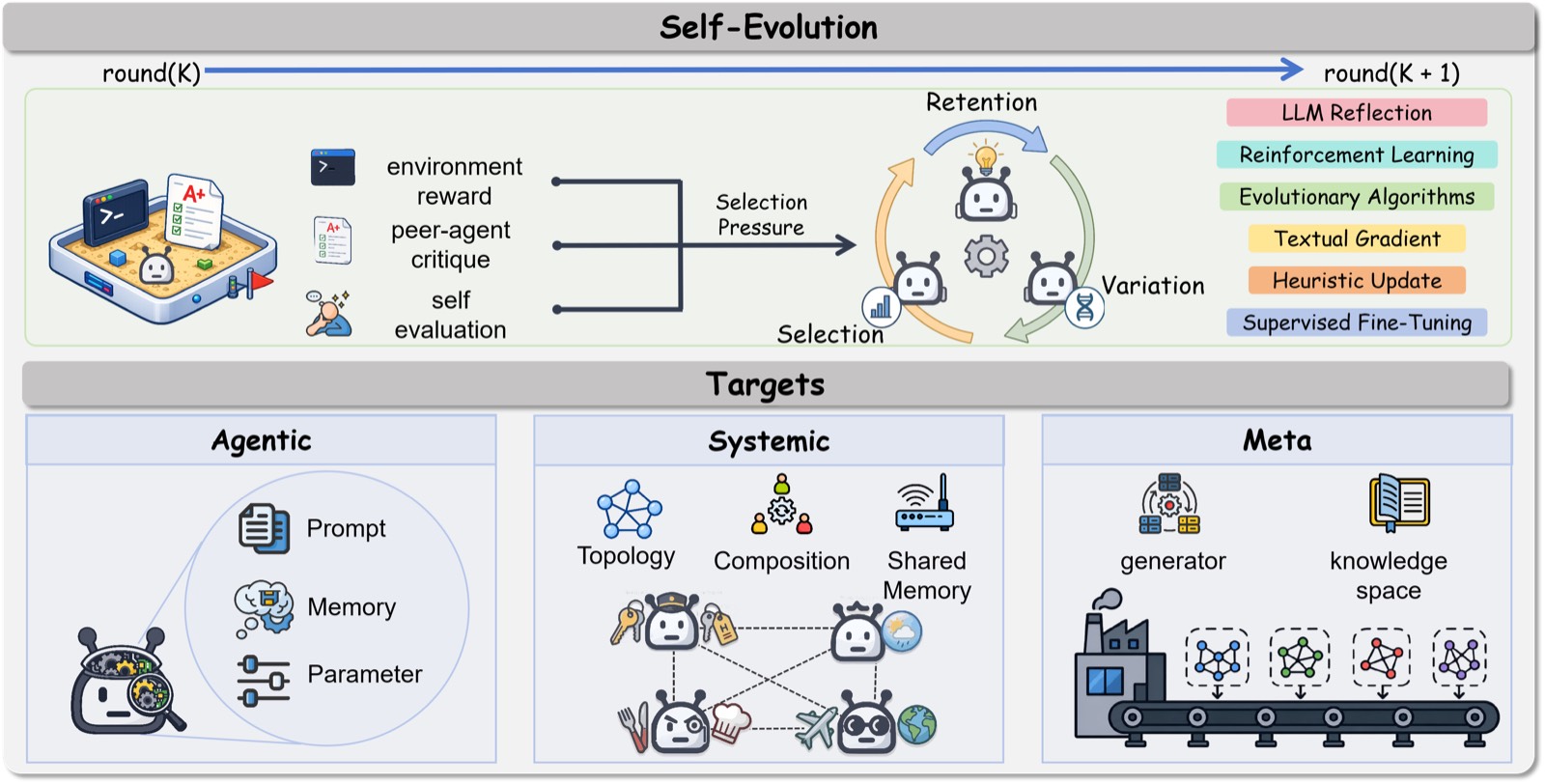
作者把 \(\Gamma\) 进一步分解成三层:
简单说:
- Agentic Evolution:进化单个 Agent 的内部——prompt、memory、参数。比如 MorphAgent 动态改写 Agent profile,CoMAS 用 interaction reward 训 LLM 参数,Optima 用 SFT+DPO 提升通信效率(90% token 节省 + 2.8× 性能)。
- Systemic Evolution:进化系统的组织结构——拓扑(topology)、组成(composition)、共享记忆(shared memory)。比如 G-Designer 用 VGAE 解码任务自适应的稀疏拓扑,AutoAgents 在 drafting 阶段合成 task-specific 团队,EvoMAC 把多智能体网络当成可微的"文本计算图"做 textual backpropagation。
- Meta Evolution:把整个系统配置 \(S\) 当成一个候选,在多个候选中评估、重组、选择,积累跨任务的"系统设计知识"。这是最高层的进化——不是改某个 Agent,也不是改某个拓扑,而是学习什么样的系统设计适合什么样的任务。
三层的关系不是平行而是递进——Agentic 是局部优化,Systemic 是结构优化,Meta 是设计优化。每往上一层,搜索空间更大、收敛更难、可迁移性更强。
6.2 演化机制:变异-选择-保留的进化论范式
作者把进化过程类比生物演化的 "Variation–Selection–Retention" 三段式(这点其实和 Donald T. Campbell 的演化认识论一脉相承):
- Variation:通过 LLM reflection、reinforcement learning、evolutionary algorithm、textual gradient、heuristic update、SFT 等机制生成新的系统状态。
- Selection:选择压力的来源——environment reward(环境反馈)、peer-agent critique(同伴评价)、self-evaluation(自我评估)。
- Retention:保留更优的状态进入下一代。
这其实跟 OpenAI、DeepMind 那些做 evolutionary search 的工作思路一致,但作者强调了一件事——选择压力的"质量"决定进化速度。如果选择压力来自有偏 reward(reward hacking)或者错误的归因结果,那进化就是在"越走越歪"。这又把球踢回故障归因——归因质量直接决定进化质量。
6.3 我对自我进化这一章的几个判断
1. Agentic Evolution 的可解释性 vs Parameter Evolution 的能力上限,是个根本权衡。 Prompt evolution 能让你看清楚"系统在学什么",但天花板是 context window。Parameter evolution 能突破天花板,但你完全看不到系统在内部记下了什么。当下的工程实践基本都是混合:Prompt 改快循环,Parameter 改慢循环。
2. Systemic Evolution 的 topology 这一支特别有意思,但 evaluation 极其薄弱。 G-Designer、Puppeteer、MASS 这些工作能"自动生成拓扑",但它们的 evaluation 通常只在一两个 benchmark 上做。到底什么样的拓扑适合什么样的任务?这个问题还没有 systematic answer。
3. Meta Evolution 是远期目标,当前实现都还很初步。 真正能跨任务积累"系统设计知识"的方法非常少。AFlow、ADAS、MaAS 这些算是早期探索,但距离"真正的 AutoML for MAS"还差得远。
七、LIFE 的真正价值:把"归因—进化"耦合显式化
通读全篇之后,我觉得这篇综述最有原创价值的部分不是四阶段分类——这种分类前人多多少少都做过——而是它正面写出了归因和进化的双向耦合。
具体来说:
Attribution 决定 Evolution 的搜索方向。 你的归因能识别到哪一层(Agent / Step / Module / Causal Chain),决定了你能在哪一层做修复。如果你只能归因到"是某个 Agent 出错",那你只能改这个 Agent;如果你能归因到"是某个交互边的通信协议出错",那你才能去改 Systemic 层的 communication。归因的粒度,就是进化的粒度上限。
Collaboration 决定 Attribution 的可观测边界。 反过来,你的协作结构决定了什么类型的失败"可以被看到、可以被归因"。集中式拓扑的失败容易归因(因为 Controller 看到全局),分布式拓扑的失败极难归因(因为没有 global view)。协作的拓扑设计,就埋下了归因的难度。
作者把这种耦合称作 attribution–evolution closed loop,并指出它在过去的综述里几乎没被正面写过。我同意这个判断——这种 cross-stage coupling 才是 LIFE 框架真正的贡献,比四阶段分类本身更值钱。
八、几个我觉得没讲透的地方
综述类文章我通常会挑几个"作者似乎在回避"的点说一下。这篇也不例外。
1. "评估方法学"被反复提,但没有给出建设性方案。 作者在每一阶段的 Discussion 都吐槽 evaluation 不统一、benchmark 不可比,但综述本身也没提出一个跨阶段的统一评估范式。这其实可以理解——综述毕竟不是方法论文,但读完会觉得"这个问题被指出了 N 次,下一步怎么办?"
2. "为什么单体能力越强、多智能体越脆"这个核心问题没有正面回答。 综述描述了现象(pan2025whymultiagentfail 那篇的结论),但没有给出系统性的解释。我个人猜测的原因是:单体能力越强、生成的 token 越多、跨 Agent 的信息量越大,错误的"传染面"也越大。但这只是猜测,需要更多理论工作支撑。
3. 工程落地维度的讨论偏少。 综述的视角偏学术,对"如何在生产环境中部署一个 LIFE-aware 的多智能体系统"讨论不多。比如归因模块的延迟和成本、进化频率与系统稳定性的权衡——这些都是工程上最关心的,但综述里几乎没碰。
这不是 deal breaker,只是想说——综述给了你一张地图,但具体怎么走还得自己摸。
九、给工程同学的几个 take-away
如果你正在做或打算做多智能体系统,看完这篇综述我会建议你做几件事:
1. 先设计协作拓扑,把"归因可行性"作为隐含约束。集中式拓扑虽然单点风险大,但归因和修复都容易;分布式拓扑虽然鲁棒,但出了问题极难定位。如果你的业务对可观测性要求高,别盲目追分布式。
2. 在系统设计早期就规划 trace 格式。归因的前提是有可分析的 trace——明确的 agent 标识、明确的时间步、完整的 input/output、明确的 tool call 记录。如果初期 trace 是糊的,后续怎么归因都补不回来。
3. 自我进化先从 Agentic 层开始,不要一上来就搞 topology evolution。Prompt evolution 是最快见效的,memory evolution 是中等成本的,parameter evolution 是最贵的。Systemic 层的进化建议在 Agentic 层稳定之后再做。
4. 把归因数据当成高价值资产。每一次失败的 trace + 标注,都是你训练专用归因模型的素材。建议在工程层面就建立"失败案例库"机制,定期标注、复用、训练。
十、一句话总结
LLM 多智能体研究过去几年的痛点不是"组件不够好",而是组件之间的因果链没人正面理。这篇综述把单体能力 → 协作组织 → 故障归因 → 自我进化这条链显式画出来,并指出归因和进化的双向耦合是当前最值得攻坚的方向。
它给你的不是"答案",而是一张能让你继续往下问的地图。综述类文章能做到这一步,我觉得就值得花两个小时认真读一遍。
参考链接: - 论文:https://arxiv.org/abs/2605.14892 - 同期相关工作:Pan et al. 2025 - Why Multi-Agent Fails、Zhang et al. 2025 - Who&When、Deshpande et al. 2025 - TRAIL
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我