MetaAgent-X:让设计器和执行器一起进化,自动 MAS 的天花板被端到端 RL 撞穿了
一个让我皱眉很久的现象
做多智能体系统(MAS)的人多少都遇到过一种尴尬:你花了很多力气去优化"谁来当协调者"、"什么时候调用反思"、"投票还是辩论",搭出来的工作流在 GPT-4 当执行器时表现亮眼,换到一个 7B / 8B 的小模型上,反而比直接单 agent 提示还差。
这不是错觉。论文里有组数据让我看了挺久——AFlow 用官方搜出来的"最佳工作流"挂到 Qwen3-8B 上跑 OlympiadBench,从单 agent 的 55.0% 直接掉到 35.3%,掉了快 20 个点。ADAS 更难看,从 55.0% 掉到 32.9%。
为啥?因为这些自动 MAS 方法默认一个前提:底下的执行器是固定的、是足够强的大模型。一旦执行器跟不上设计的复杂度——比如让一个不太会写代码的小模型去执行"先批评再重写再投票"——多 agent 反而成了灾难放大器。
这就是论文反复强调的那个词:frozen-executor ceiling(冻结执行器天花板)。设计器再聪明也撞墙。
那么很自然的问题:能不能让设计器和执行器一起训?听起来简单,做起来全是坑——奖励怎么分?谁先训?两个角色互为对方的环境,怎么保证稳定?这篇 MetaAgent-X 就是给这套端到端训练做了一个相对完整的回答。
核心摘要
这篇论文要解决的是自动 MAS 里一个被忽略的痛点:现有方法要么免训练做测试时搜索(AFlow / ADAS),要么只训设计器、冻结执行器(MAS-GPT / ScoreFlow / MaAS),都没人真的把"设计 + 执行"做端到端联合优化。结果就是执行器水平给整个系统封了顶。
作者提出 MetaAgent-X——一个把 Designer(生成 MAS 脚本)和 Executor(跑 MAS)放在同一个共享策略里、用 GRPO 端到端联合训练的框架。两个关键技术:(1) 执行器-设计器分层 Rollout,每个 query 先采 M 个 design,每个 design 再跑 N 次,构造 M×N 矩阵,把设计质量和执行质量解耦;(2) 分阶段协同进化——别一起训,每 K 步轮流当 active role,让对方扮演稳定环境。
效果:在 Qwen3-8B 上六个数学和代码基准平均拉到 38.33%,比单 agent baseline 涨 11.17 个点,比最强 RL-based MAS 基线 MaAS 涨 6.11 个点;Qwen3-4B 上 AIME24 直接拉满到 33.33%,最大单项提升 21.7%。
我的判断:这篇论文的价值不在某一个新算法(GRPO 是 DeepSeek 的,分层信用分配的思路在多智能体 RL 里也有先例),而在把"自动 MAS"这条线推到了端到端可训练这个临界点。如果你做的是中小模型上的 Agent 系统,这个范式很可能是接下来一两年的标配。
论文信息
- 标题:MetaAgent-X: Breaking the Ceiling of Automatic Multi-Agent Systems via End-to-End Reinforcement Learning
- 作者:Yaolun Zhang, Yujie Zhao, Nan Wang, Yiran Wu, Jiayu Chang, Yizhao Chen, Qingyun Wu, Jishen Zhao, Huazheng Wang
- arXiv:2605.14212(2026 年 5 月提交,目标会议 NeurIPS 2026)
- 链接:https://arxiv.org/abs/2605.14212
为什么"端到端"这件事被卡了这么久
我先把问题摆开。自动 MAS 这条线其实热闹了挺久,但你看下来会发现一个奇怪的事——大家都在绕开"训执行器"这个最贵的部分。
把现有方法分一下,大致是这么三档:
| 范式 | 代表方法 | 设计器 | 执行器 | 局限 |
|---|---|---|---|---|
| 训练免搜索 | AFlow, ADAS | 离线搜索一个固定工作流 | 调用 API 大模型 | 一旦换底座模型完全失灵 |
| 半训练 | MAS-GPT, ScoreFlow, MaAS, FlowReasoner | RL 训练 | 冻结 | 撞执行器天花板 |
| 端到端 | MetaAgent-X(本文) | 共享策略联合训 | 共享策略联合训 | 信用分配 + 训练稳定性问题 |
为什么前两档统治了这么久?说实话不是因为大家想不到端到端,是因为真做起来有两个非常硬的拦路虎:
第一个,参数层的脱节。设计器和执行器只通过"prompt 文本"耦合,没有梯度信号从下游执行结果反传到上游的设计策略。换句话说,设计器知道"我设计了什么",但完全不知道"这个设计真的好用吗"——因为它从来没在自己的参数里见过执行结果。
第二个,协同进化机制说不清。即使你硬把两个角色一起训,会发生什么?论文里那条绿色的崩溃曲线后面会讲到。一句话:两个角色互为环境,同时更新等于每一步梯度都在追一个移动靶,训着训着就崩了。
这就是为什么作者反复强调"设计器与执行器的协同进化动力学不清楚"——不是没人想,是想了也没法稳定训。
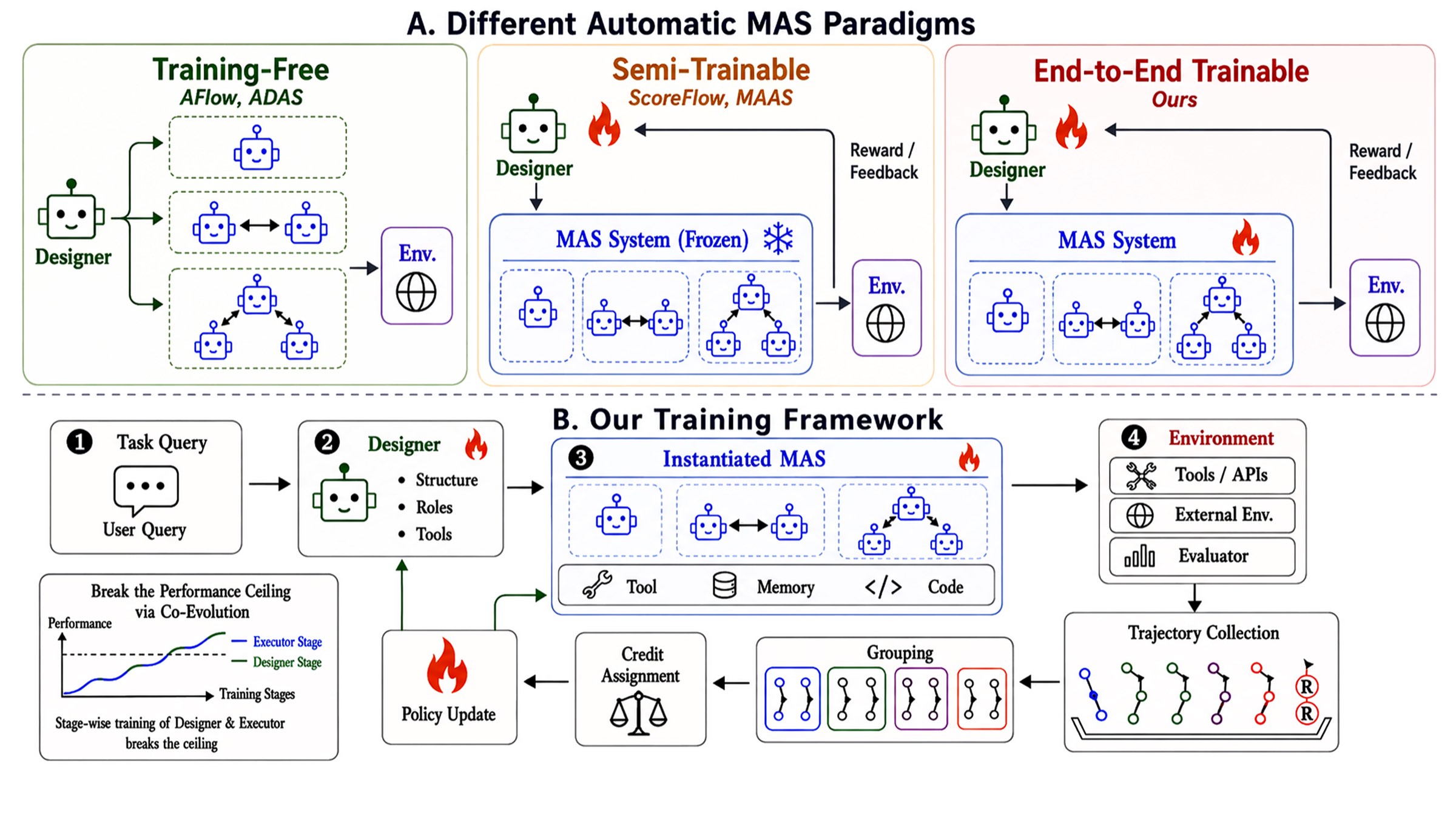
图1:三种自动 MAS 范式的对比和本文整体训练框架。注意左下角那条"楼梯型"曲线——这是分阶段训练的标志性 pattern,后面实验图会再出现一次
方法:三件事,每件都不复杂但少了任何一件都不行
整套方法可以拆成三块:怎么生成 rollout、怎么算 advantage、怎么调度训练阶段。三件事环环相扣,少一件就崩。
在线系统构造:让 Designer 输出 Python 脚本
这是一个很值得注意的工程选择。传统 MAS 设计器输出的是 JSON 配置或者结构化模板,作者这里直接让 Designer 输出Python 脚本——脚本里指定 agent 角色、交互协议、工具调用、控制流。
为什么是脚本?说实话我第一反应是有点疯狂,让模型生成可执行代码风险不小。但回过头想,这其实是一个相当聪明的选择——脚本既给了 Designer 足够灵活的表达空间(不需要预定义所有结构),又能复用已有的代码安全沙箱(工具调用、内存管理这些 infra 都是现成的)。
框架里预定义了一组"积木":协调结构(投票/反思/单 agent)、agent 模板、工具接口。Designer 把这些拼成具体的多 agent 工作流,Executor 在环境里跑。每次 rollout 记录的东西包括:轨迹、环境观察、工具调用、最终的 outcome reward。
分层信用分配:M×N 评估矩阵把"设计的锅"和"执行的锅"分开
这是整篇论文我觉得最值的一块。
回到那个核心问题:MAS 失败了,是 Designer 设计得烂还是 Executor 执行得烂?标准单层 rollout 完全分不开——奖励信号是混在一起的,等于让 Designer 背 Executor 的锅、让 Executor 背 Designer 的锅。
作者的做法很直接:对每个 query \(q\),先让 Designer 采样 \(M=4\) 个不同的 MAS 设计 \(\{d_1, ..., d_M\}\),再让 Executor 对每个设计跑 \(N=4\) 次执行。这就构成了一个 \(M \times N\) 的评估矩阵。
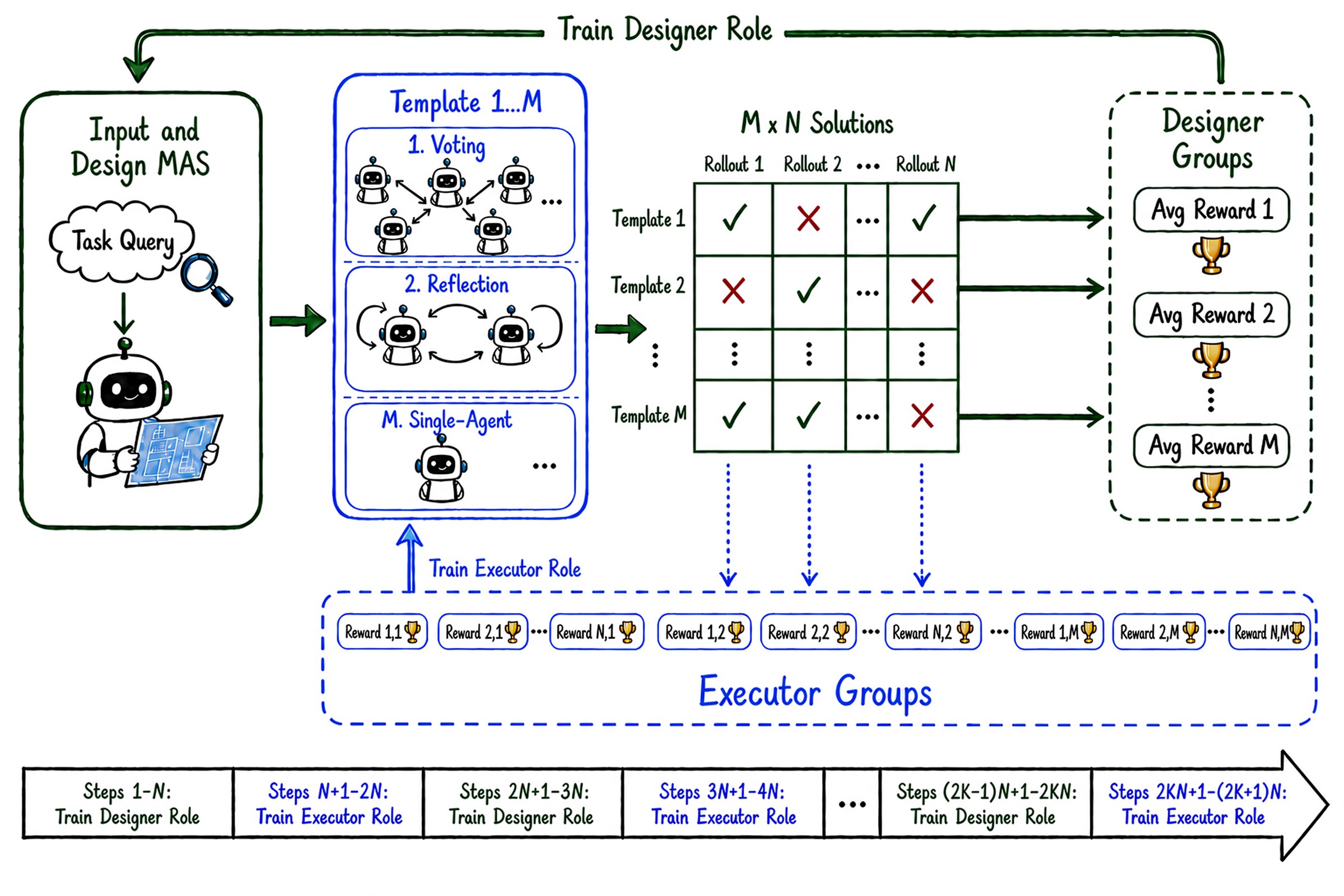
图2:分层 rollout + 分阶段训练的完整 pipeline。这张图把所有核心机制都画在了一起,是全篇最关键的一张图
Designer 的 advantage:对每个设计 \(d_i\),先对它的 \(N\) 次执行结果求平均,得到 \(\bar{R}^{\mathcal{D}}_i = \frac{1}{N} \sum_{j=1}^{N} R(e_{i,j}, d_i)\)。然后在同一个 query 的 \(M\) 个设计内部做 GRPO 风格的归一化:
为什么要先对 N 次执行平均?这是关键。如果你只跑一次执行,那这次执行可能恰好走运或踩雷,把 Designer 的好坏完全淹没了。平均 N 次相当于做了去噪,让 reward 更能反映设计本身的质量。
Executor 的 advantage:所有 M×N 个轨迹归到同一个 query 的 group 里做归一化。注意这里有个微妙的设计——Executor 的 group 跨越了不同 design,这意味着 Executor 不仅在比"同一个设计下我这次跑得怎么样",还在比"不同设计下哪种执行更值得鼓励"。这比单层归一化稳定得多。
消融实验里有一组对比直接验证了这个设计:\(M=4, N=4\) 在 AIME24 上拿到 40.0%,而 \(M=8, N=1\)(同样总 rollout 数,但每个设计只跑一次)只有 33.3%。差了 6.7 个点,纯粹是因为没做 N 次去噪。
分阶段协同进化:别让两个角色同时改
数学上写出来挺漂亮。整个 return 是个嵌套期望:
Designer 的策略分布决定 Executor 看到什么 prompt,Executor 的策略分布决定 Designer 收到什么 reward。两个互为环境,同时改就会陷入非平稳性。
作者的做法很朴素——每 \(K=30\) 步切换 active role:
每个阶段只有 active role 的轨迹回传梯度,但共享参数 \(\theta\) 一直在更新。这意味着 Executor 阶段学到的能力会自动迁移到 Designer 阶段(同一个权重),反之亦然。
这套设计有个有意思的不对称性:作者偏好用 Executor 优先开局。理由是冷启动 SFT 后 Designer 已经有了基本的指令遵循能力(能生成合理的 MAS 脚本),但 Executor 的能力还很弱——这时候用 Designer 阶段去训,reward 信号噪声会很大,因为弱 Executor 跑不出有意义的差异。先把 Executor 培养起来,给 Designer 一个能稳定区分设计好坏的"评测者",再让 Designer 去推天花板。
实验:21.7% 的提升从哪来?
主表:Qwen3-8B
这张表信息量大,我挑几个有意思的对比拎出来说。
| Method | LiveCodeBench | APPS | CodeContests | AIME24 | AIME25 | OlympiadBench | Avg |
|---|---|---|---|---|---|---|---|
| SA(单 agent 直接 prompt) | 22.80 | 30.20 | 15.75 | 18.30 | 20.90 | 55.00 | 27.16 |
| SA + GRPO | 25.70 | 37.00 | 12.12 | 18.30 | 26.67 | 54.80 | 29.10 |
| AFlow | 28.60 | 27.40 | 15.80 | 16.67 | 20.83 | 35.31 | 24.10 |
| ADAS | 20.00 | 27.00 | 12.20 | 13.30 | 16.70 | 32.90 | 20.35 |
| ScoreFlow | 25.90 | 26.50 | 13.30 | 28.90 | 20.00 | 51.30 | 27.65 |
| MaAS | 24.29 | 30.00 | 15.15 | 45.80 | 29.20 | 48.90 | 32.22 |
| AFM-Coder | 29.10 | 28.00 | 21.20 | 12.00 | 8.00 | 21.80 | 20.35 |
| MetaAgent-X\(_\text{SFT}\) | 36.00 | 32.00 | 13.00 | 33.00 | 20.00 | 59.00 | 32.17 |
| MetaAgent-X\(_\text{RL}\) | 41.00 | 38.00 | 17.00 | 40.00 | 33.33 | 61.00 | 38.33 |
第一组对比:SA → MetaAgent-X\(_\text{RL}\),平均从 27.16% 涨到 38.33%,涨了 11.17 个点。这是单 agent 用 RL 训完后到 MAS 端到端训完的总收益。
第二组对比:SA + GRPO → MetaAgent-X\(_\text{RL}\),平均从 29.10% 到 38.33%,9.23 个点。这部分增益纯粹来自 MAS 结构 + 端到端联合训练,因为 SA + GRPO 已经把"单 agent 上的 RL 训练"做满了。
第三组对比:MaAS → MetaAgent-X\(_\text{RL}\),从 32.22% 到 38.33%,6.11 个点。这是和最强 RL-based MAS 基线的对比——MaAS 训设计器+冻结执行器是已经做得相当不错的方法,但端到端联合训能再吃 6 个点。
但这张表里我也想说几句不那么乐观的话。
有几个数字其实蛮微妙的。MaAS 在 AIME24 上拿到了 45.80%——比 MetaAgent-X\(_\text{RL}\) 的 40.00% 还高 5.8 个点。AFM-Coder 在 CodeContests 上 21.20%,也比 MetaAgent-X\(_\text{RL}\) 的 17.00% 高。论文用"平均"作为主指标,确实 MetaAgent-X 是最均衡的,但单项最强不等于它。这说明作者的方法是在做"全面均衡"的优化,而不是单点暴力突破。读这种表不能只看 best 数字。
另一个观察:MetaAgent-X\(_\text{SFT}\) 已经拿到 32.17%,比所有基线方法都强或者持平。也就是说冷启动 SFT 蒸馏 DeepSeek-V3.2 轨迹这一步本身就吃掉了大头,端到端 RL 在 SFT 之上再涨 6 个点。这不是贬低 RL 的贡献,是想说:如果你没有一个高质量的 SFT 冷启动,单靠 RL 大概率训不出来。
Qwen3-4B:小模型上提升更猛
4B 模型上 MetaAgent-X\(_\text{RL}\) 平均拉到 34.18%,比 SA 涨 12.80 个点;最大单项是 OlympiadBench 从 33.20% 到 58.20%,涨了 25 个点。AIME25 上从 19.10% 到 26.67%,把单 agent 直接干翻一倍多。
这个数据其实回到了开头那个观察:自动 MAS 在小模型上反而更有空间——因为冻结执行器的天花板对小模型来说更低,端到端训练能把这个天花板顶得最猛。
真正的杀器:那条绿色的崩溃曲线
整个论文里我觉得最有说服力的实验是分阶段调度的消融。
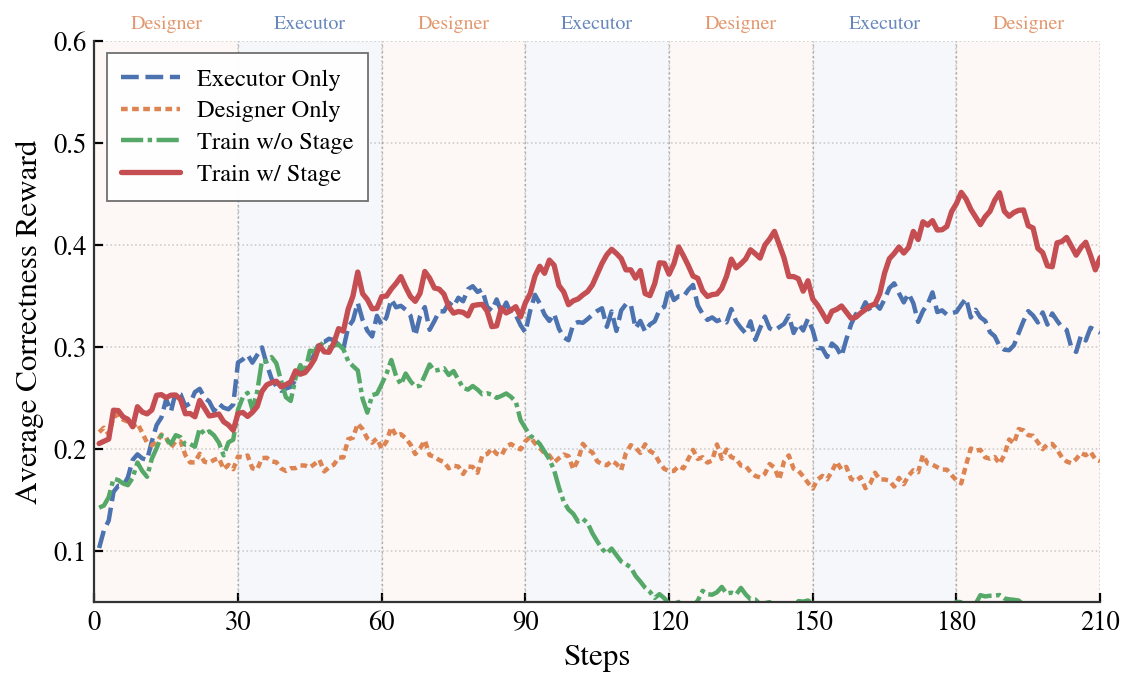
图3:四种训练调度的 reward 曲线对比。顶部色带标注了 stagewise 训练的当前阶段(Designer/Executor 交替)。绿色那条崩溃曲线是这篇论文最关键的"反面教材"
这张图至少告诉了我们三件事:
-
同时训两个角色(绿线)真的会崩。前 60 步上得很快,因为两个角色的奖励信号都还相对清晰;从第 90 步开始急转直下,到 150 步后基本归零。作者描述这时候模型在做什么——"生成大量无意义 token 直到达到最大长度"。这是非平稳性导致的典型模式崩溃。
-
只训 Designer(橙色点线)几乎没收益。这个其实和直觉相反——你可能觉得"反正 Executor 已经是 SFT 后的还行模型,光优化 Designer 应该能涨点"。但实际数据说不能,整个训练过程 reward 稳定在 0.18-0.22。说明没有 Executor 同步进化,Designer 学到的"更好结构"其实没人能执行。
-
只训 Executor(蓝虚线)会撞天花板。前 60 步上得很快(0.10 → 0.34),但之后基本饱和。配合 stagewise(红实线)才能看到天花板一次次被推高——每次 Executor 阶段把当前设计的潜力榨干,每次 Designer 阶段往上推一个台阶。
对应的表格更直观:
| Variant | Math | Code |
|---|---|---|
| Coupled(同时训) | 36.7% | 25.2% |
| Designer-only | 38.6% | 27.5% |
| Executor-only | 39.6% | 30.7% |
| Stagewise | 44.8% | 32.0% |
Stagewise 比次优的 Executor-only 在 math 上高 5.2 个点,code 上高 1.3 个点。这是 stagewise 调度的纯增益。
阶段长度 K 怎么选?
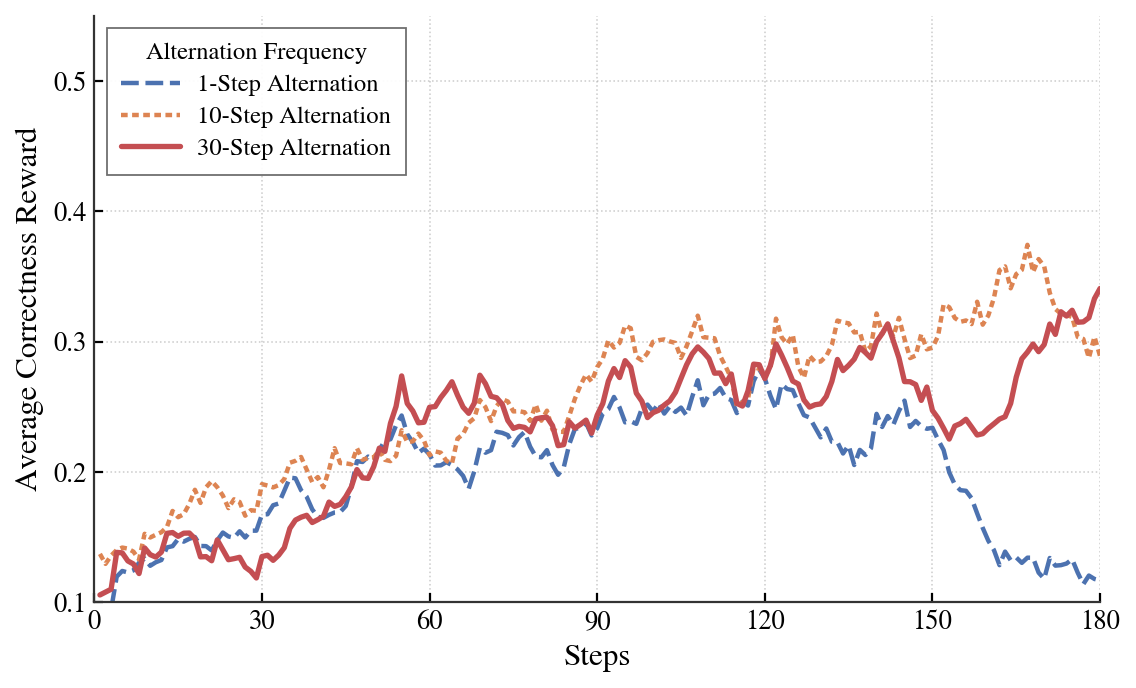
图4:阶段长度 K 的敏感性分析。每步切换会让两个角色都无法稳定学习;K=10 和 K=30 都 work,论文选 K=30
这张图把"K 不能太小"这个直觉做了硬核验证。\(K=1\)(每步都切换)等于让两个角色每一步都在跟一个刚改完的对手训练,根本没机会巩固任何东西——蓝线从 90 步开始彻底崩。\(K=10\) 和 \(K=30\) 都稳定,但 \(K=30\) 给了每个阶段足够时间消化,最终效果略好。
这里其实有个工程取舍:K 越大,单阶段训练越稳定,但对环境变化的响应越慢。如果你跨阶段后另一个角色已经大幅进步,K=30 意味着你要等 30 步才能用上对方的新能力。作者没深挖这个权衡,但这是个值得思考的点。
共享策略 vs 独立策略:一个有点反直觉的结果
| Variant | AIME24 | AIME25 |
|---|---|---|
| Shared | 40.0% | 33.3% |
| Separate | 33.3% | 26.7% |
共享策略(一个模型扮演两个角色)比独立策略(两个模型分别扮演 Designer 和 Executor)强 6.7 / 6.6 个点。
这个结果一开始让我皱眉。直觉上独立策略应该更好——专人专用,不互相干扰嘛。但仔细想想确实是共享更合理:Designer 和 Executor 学的不是两个独立任务,是同一个 meta-agent 优化问题的两面。Designer 需要懂 Executor 的能力边界才能设计合理的 MAS;Executor 需要懂 Designer 的意图才能正确执行。共享参数等于让两个角色"共享对自己系统的认识"。
这个发现其实挺值钱的。它告诉做 Agent 框架的人:别急着把多 agent 拆成多个独立模型,单模型多角色可能是更优的参数化。
谁带来了提升?设计还是执行?
作者最后做了一个非常细致的归因分析(基于 AIME25):约 50% 的提升来自 Executor 在相同结构下的更好执行,另 50% 来自 Designer 选了更合适的结构。
结合 RL 训练后 Designer 选结构的分布:
| Benchmark | Single | Reflection | Ensemble |
|---|---|---|---|
| AIME 2024 | 18.9% | 70.0% | 11.1% |
| AIME 2025 | 15.6% | 73.3% | 11.1% |
| OlympiadBench | 46.4% | 44.8% | 8.8% |
| CodeContests | 26.7% | 62.4% | 10.9% |
| LiveCodeBench | 43.5% | 52.6% | 3.8% |
| APPS | 55.2% | 43.8% | 1.0% |
可以看到 Designer 学到了任务依赖的结构选择:硬一点的数学题(AIME)倾向 Reflection(一个 agent 生成、一个 agent 修正),简单一点的(OlympiadBench、APPS)直接走 Single。Ensemble 在所有任务上都是少数派。
我觉得这是这篇论文除主表外另一个有趣的发现——模型学到的不是全用 ensemble 这种暴力策略,而是按任务匹配结构。这一点和很多自动 MAS 论文"在所有任务上都堆复杂结构"的暴力路线很不一样。
一些直白的判断
写得很值的部分: - 分层 rollout + N 次去噪平均,这套思路在多智能体信用分配里其实有前例(AT-GRPO 等),但用在 MAS 端到端训练里、并配合精确的 design vs execution 解耦,作者讲清楚了。 - 分阶段协同进化那张训练曲线对比图(图3)实在是太能打了。一张图把"为什么不能同时训"、"为什么 Executor-only 撞天花板"、"为什么 Designer-only 没意义"、"为什么 stagewise 能爬楼梯"全说明白了。这是这篇论文我会反复回来看的图。 - 共享策略 > 独立策略这个发现,是个对整个 Agent 训练社区有启发的结论。
让我有点保留的部分: - "21.7% 提升"这个数字主要来自 Qwen3-4B 在 OlympiadBench 上的特殊涨幅。整体看平均提升是 11-13 个点这个量级,仍然很能打,但论文标题里这个数字略有挑最大值的嫌疑。 - 主表上 MetaAgent-X 在单项最佳数上其实没有占绝对优势——AIME24 输 MaAS 5.8 个点,CodeContests 输 AFM-Coder 4 个点。说"全面 SOTA"过头了,"全面均衡 + 平均最优"更准确。 - 用了 DeepSeek-V3.2 做 SFT 冷启动,且 SFT 已经吃了大半增益。如果没有强 teacher 模型做冷启动,这套方法的复现难度会陡增。这一点论文没充分讨论。 - 全程在 Qwen3 上验证,没在 Llama / Mistral 系列上验证泛化性。说实话我对这套方法在其他基础模型家族上的表现还是有点疑问。
和同期工作的位置: - 跟 Chain-of-Agents (AFM) 比,它确实是把整个 Agent 当成一个 chain of thought 直接训,没有显式的"设计 vs 执行"分离。MetaAgent-X 的优势是分得开、能归因、能调度;劣势是工程复杂度高。 - 跟 ScoreFlow / MaAS 比,端到端联合训确实捅破了那个冻结执行器的天花板。但说"完全替代"还早——MaAS 那种"训分布选择器"在某些场景(比如不允许动 Executor 权重的 API-only 部署)依然有它的位置。
给做 Agent 工程的人几条具体启发
如果你也在做类似的事,这篇论文有几条很具体的工程经验是可以直接拿走的:
-
想做端到端 MAS 训练,先想信用分配。不要单层 rollout 完事,至少做 N=2 或 N=4 的执行重复来稳定 design-level reward。M×N 矩阵不是花架子,是必需的。
-
不要同时训两个角色。共享策略 + 分阶段调度(K=30 量级)是经过验证的稳定配方。同时训大概率会崩成无意义 token 重复。
-
共享策略大概率比独立策略好。除非你有非常特殊的隔离需求(比如安全/权限),否则一个模型扮演多角色更优。
-
冷启动 SFT 不可少。蒸馏一个更强 teacher(DeepSeek-V3.2 / GPT-4 级别)的多角色轨迹是必备的,纯 RL 冷启动不太可能 work。
-
让 Designer 输出可执行脚本而不是 JSON 配置。表达力够、复用现有工具栈、自然处理控制流。但你需要一个靠谱的代码沙箱。
-
任务越简单越倾向 Single agent,越难越倾向 Reflection。模型其实自己会学到这个,不用人工规则去强行规划。
一个还没解决的问题
读完之后我还有一个疑问没解决:这套方法的训练成本到底有多重?
每个 query 要采 M=4 个 design × N=4 次执行 = 16 次完整 rollout。如果每个 rollout 涉及多个 agent 多轮交互,单步训练的算力消耗会比单 agent GRPO 高一个数量级。论文说在 8×H200 单节点上完成,但没给具体的训练 step 数和墙钟时间。
如果端到端 MAS RL 训练比单 agent GRPO 贵 5-10 倍但只涨 6-11 个点平均分,那个 ROI 在哪些场景下值得?这个问题论文没回答,但每个想用这套方法的工程团队都需要自己算账。
我猜测这种方法的甜蜜点是模型能力中等、任务复杂度高、推理时多 agent 调用成本可接受的场景——比如做数学竞赛、代码竞赛、复杂工具调用类的 Agent 产品。如果你在做简单问答或者你的底座本来就是 GPT-4 级别,可能直接单 agent + 强 prompt 性价比就够了。
无论如何,这篇论文把"自动 MAS 端到端训"这件事推到了可工程化的临界点。未来一两年,类似的范式大概率会成为开源 Agent 框架的标配。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我