Many-Shot CoT-ICL:把上下文窗口当课程表来排,几何任务直接拉高 5.42 个点
论文:Many-Shot CoT-ICL: Making In-Context Learning Truly Learn 作者:Tsz Ting Chung(HKUST)、Lemao Liu(复旦)、Mo Yu(微信 AI · 腾讯)、Dit-Yan Yeung(HKUST) 会议:ICML 2026 链接:https://arxiv.org/abs/2605.13511
一段被实验打脸的常识
去年大半年时间,圈里对长上下文 ICL 的共识其实挺统一的:示例塞得越多越稳,顺序怎么排都差不多,相似度检索是黄金法则。DeepMind 那篇 Many-Shot ICL 把这套结论按到了 200 多个示例上,Gemini 1.5 在分类任务上的曲线漂亮得像教科书。
我也是在这个框架下做工程的,前段时间想着把这套搬到数学题上——反正手里有几万道 MATH 题的 CoT 解答,再加上 Qwen3-14B 的 128K 窗口,往里灌 100 多个带 CoT 的 demo,应该能起飞才对。
结果第一组实验出来,几何任务的准确率不升反降。我当时以为是 prompt 模板没调对,又试了几轮发现不是——把同一组示例打乱顺序重跑五次,标准差竟然比 16-shot 还大。
直到看了 HKUST 和微信 AI 的这篇 ICML 2026 论文,我才意识到这不是工程 bug,而是这条 scaling 路径在 CoT 上根本不成立。这篇论文把这件事拆得很干净:标准 many-shot ICL 在推理任务上整套规则都不再适用——scaling 行为变了、相似度检索失效了、顺序方差还在长。作者顺手提出一个叫 CDS 的排序方法,在几何任务上拉了 5.42 个百分点,比我预想的简洁很多。
下面把这篇论文我觉得最有意思的几点挑出来讲。
核心摘要
这篇论文做的是一件听起来很无聊但其实挺关键的事:把 many-shot ICL 在推理任务上的所有"老规矩"系统性地推翻了一遍。三条核心发现——增加 CoT 示例对非推理 LLM 不稳定、相似度检索在推理任务上反而拖后腿、示例顺序方差随 shot 数增长——每一条都和过去两年的主流叙事相反。作者由此提出一个新的解释框架:many-shot CoT-ICL 不是放大版的模式匹配,而是上下文里的测试时学习(in-context test-time learning),prompt 不再是检索池,而是一个有节奏的课程表。基于这个视角,他们推导出两个可操作的原则(易理解性 + 平滑性),并实现了 CDS 这套基于曲率最小化的排序方法,几何任务 64-shot 拉了 5.42 个点。我的判断是:这篇的实证部分很扎实,理论包装比方法本身更出彩,CDS 算法工程上拿来即用没什么门槛,值得花时间细看。
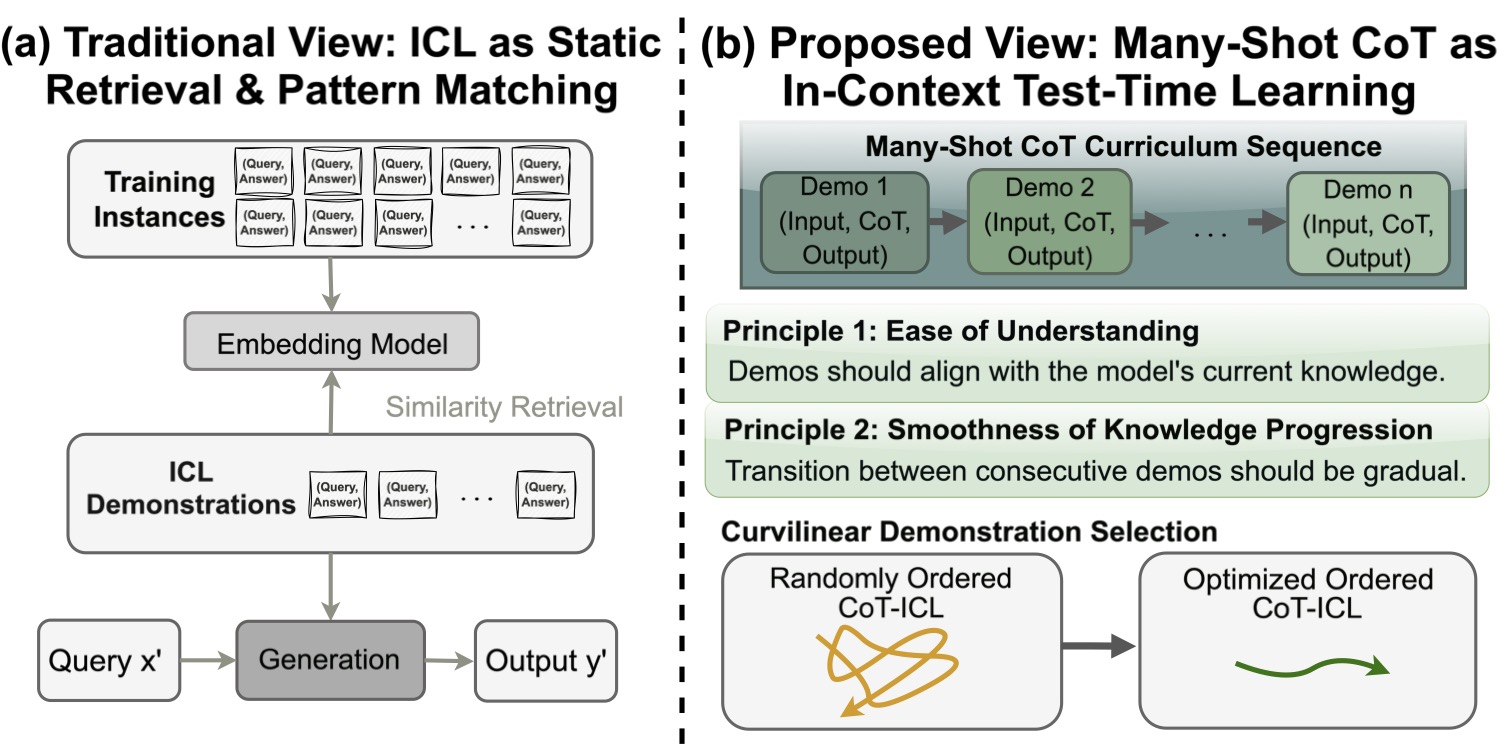
图 1:左侧是常见的检索式 ICL 范式,右侧是论文提出的新视角——把 prompt 看成一条课程序列。下方的两个示意明显说明了 CDS 想干什么:让示例在嵌入空间里走出一条光滑的曲线。
实验设置:把变量摊开看
作者搭了一个三维网格:任务类型 × 模型类型 × 示例配置。
任务方面分两类。非推理那一组是 SuperGLUE、TREC、NLU、BANKING77,标签空间从小到大都有覆盖。推理那一组挑了 GSM8K、MATH、DetectiveQA,前两个是数学,后一个是长文本的叙事推理。
模型方面也分两类,区分依据是有没有显式的思考模式。非推理 LLM 是 Llama-3.1-8B、Llama-3.3-70B、Qwen2.5-7B 和 14B。推理 LLM 这边是 Qwen3-8B、Qwen3-14B、QwQ-32B、DeepSeek-R1-685B。R1 都拉进来了,这个评估范围算是诚意拉满。
示例数从 few-shot 一路扫到 128-shot(部分实验到 124)。所有任务统一用开放生成 + exact match 评估,避免 multiple choice 评估方式带来的虚高。
有个细节挺值得注意——作者特别提了一句,几何任务里一个 CoT demo 的长度差不多是 BANKING77 单条示例的 30 倍,所以 CoT-ICL 在实际工程里最多也就 100 多个示例就把上下文撑满了,再多塞不下。这其实就限定了"many-shot CoT-ICL"的真实工程边界——它不是说要塞 1000 个示例,而是说在 16 到 128 这个区间内,到底有没有正向的 scaling。
发现一:scaling 行为是设置依赖的
第一个让我皱眉的实验结论:示例越多越好这件事,只在某些组合里成立。
作者把非推理 LLM 在两类任务上的曲线画在一起,得到了一个很反差的结果。在分类任务(暖色系曲线)上准确率稳步爬升;但在推理任务(冷色系曲线)上,曲线要么震荡,要么直接往下走。
我一开始以为这是参数规模不够。结果作者把 Llama-3.3-70B 也拉进来测了一遍——一样翻车。看图 2:
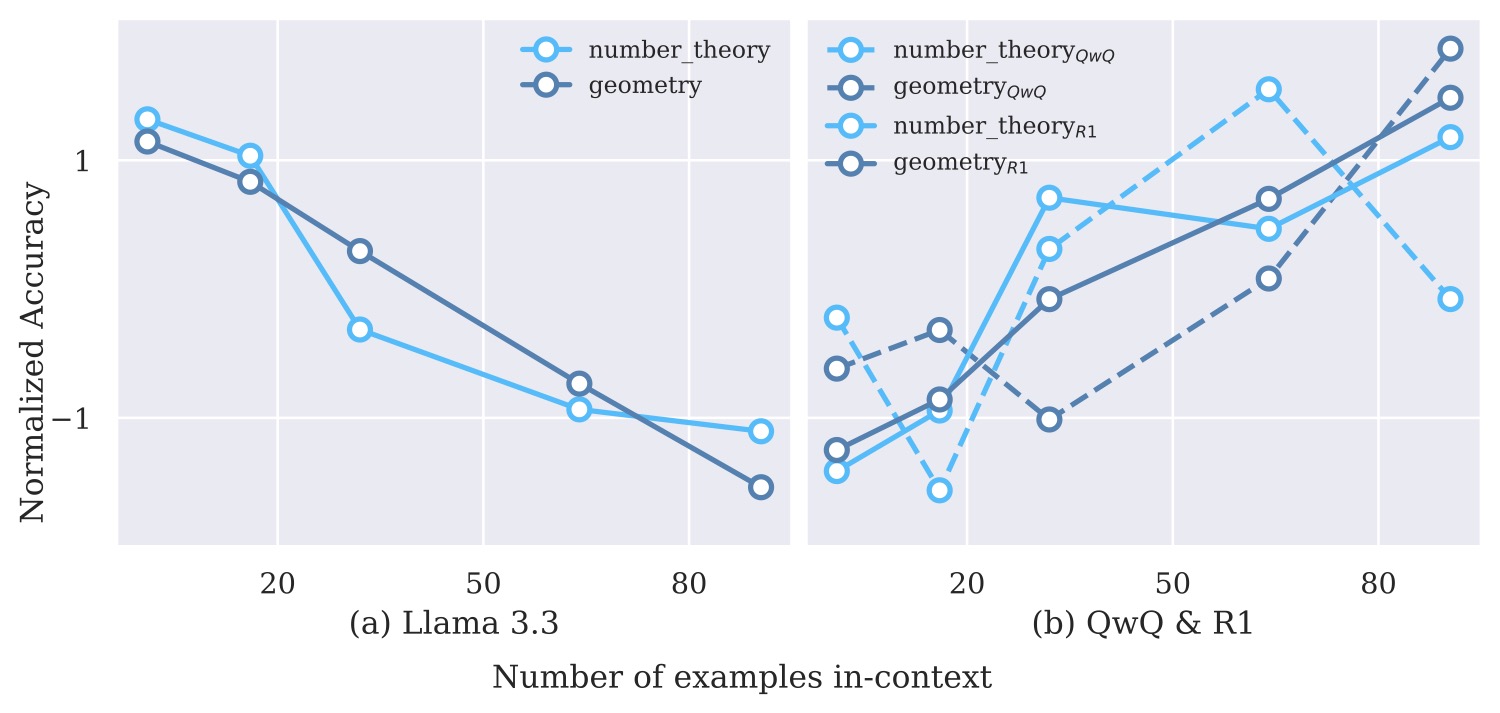
图 2:同样是数学推理任务,70B 的 Llama-3.3 是负向 scaling,QwQ-32B 和 R1 是正向 scaling。这说明问题不是参数量不够,而是模型的"推理范式"有没有训进去。
70B 的非推理模型也会被 CoT-ICL 拖累。这个结果其实挺有意思的——它把"加更多示例就一定有用"这个直觉给彻底打掉了。Llama-3.3 在分类任务上是优等生,但你给它看 90 道几何题的完整解答,它反而越看越糊涂。
而切换到推理 LLM 之后画风突变。QwQ-32B 和 R1-685B 在数学任务上从 16-shot 到 90-shot 几乎是单调上升,Qwen3 家族的结果也是同样的趋势:
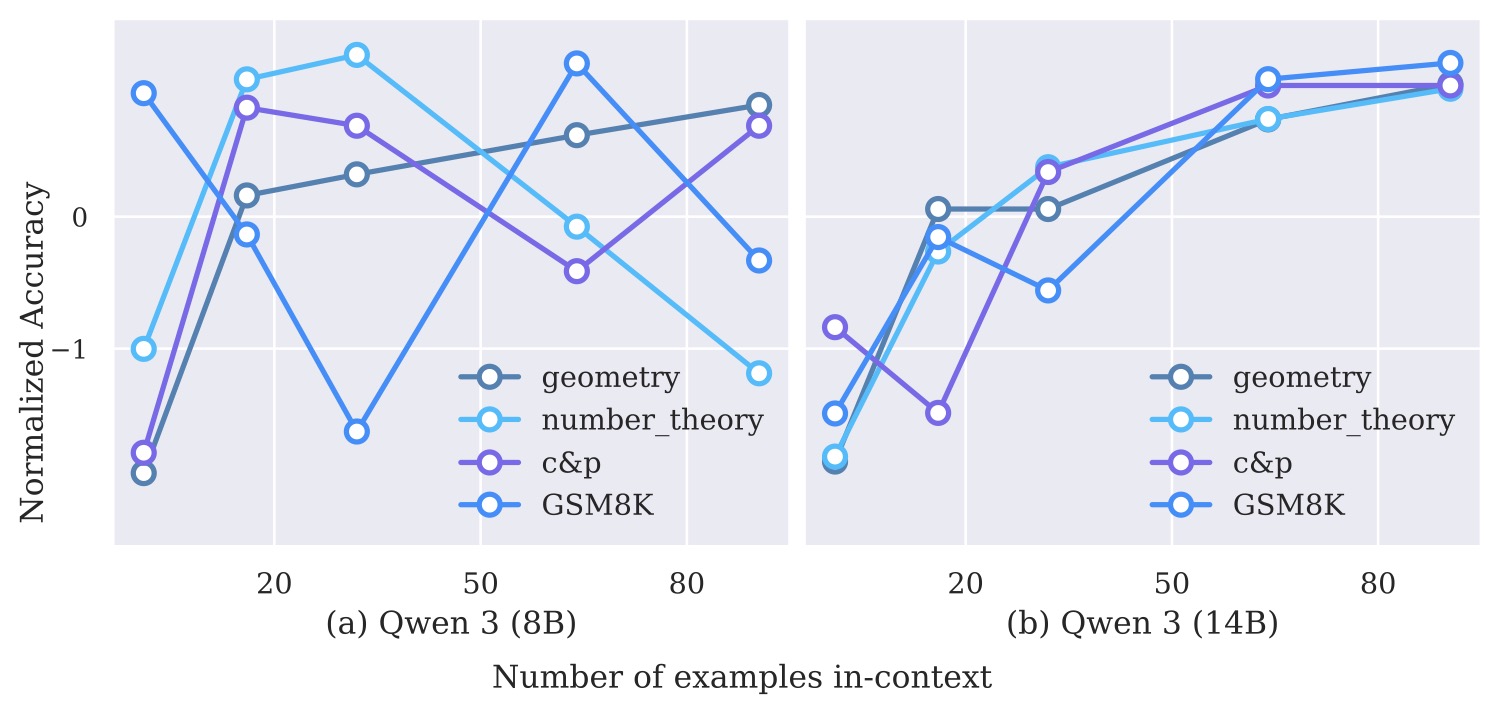
图 3:Qwen3 家族的 scaling 曲线。14B 模型在 geometry、number_theory、c&p、GSM8K 四个任务上几乎都是单调上升。8B 因为模型容量更小,在某些任务上有显著震荡,但整体仍然往上走。
这里有个细节非常值得抠:作者在表 1 里专门做了 thinking on/off 的对照。Qwen3-14B 开思考模式时几何能到 73.07,关掉就掉到 65.76;并且开思考模式时,把 shot 数从 16 拉到 128,准确率从 66.18 涨到 73.07,同时 think 段内生成的 token 数还减少了 24.02 个百分点。
这个数我看到的时候真愣了一下。它的言外之意是:CoT-ICL 没有让模型在 query 时多想,反而让它少想——长上下文里的示例已经帮模型把任务程序内化好了,思考阶段只需要复用,不需要重新推导。这件事如果坐实,那 many-shot CoT-ICL 就有点像在做隐式的"测试时蒸馏"。
发现二:相似度检索在推理任务上翻车
这一节大概是整篇论文我最喜欢的部分。
过去做 ICL 示例选择的主流玩法就一条:embedding 算相似度,挑跟 test query 最像的几个 demo 拼进 prompt。这套做法在 RAG 里也是常态。作者把这条规则在 BANKING77、DetectiveQA、几何、数论四个任务上重新跑了一遍,得到的曲线相当戏剧性:
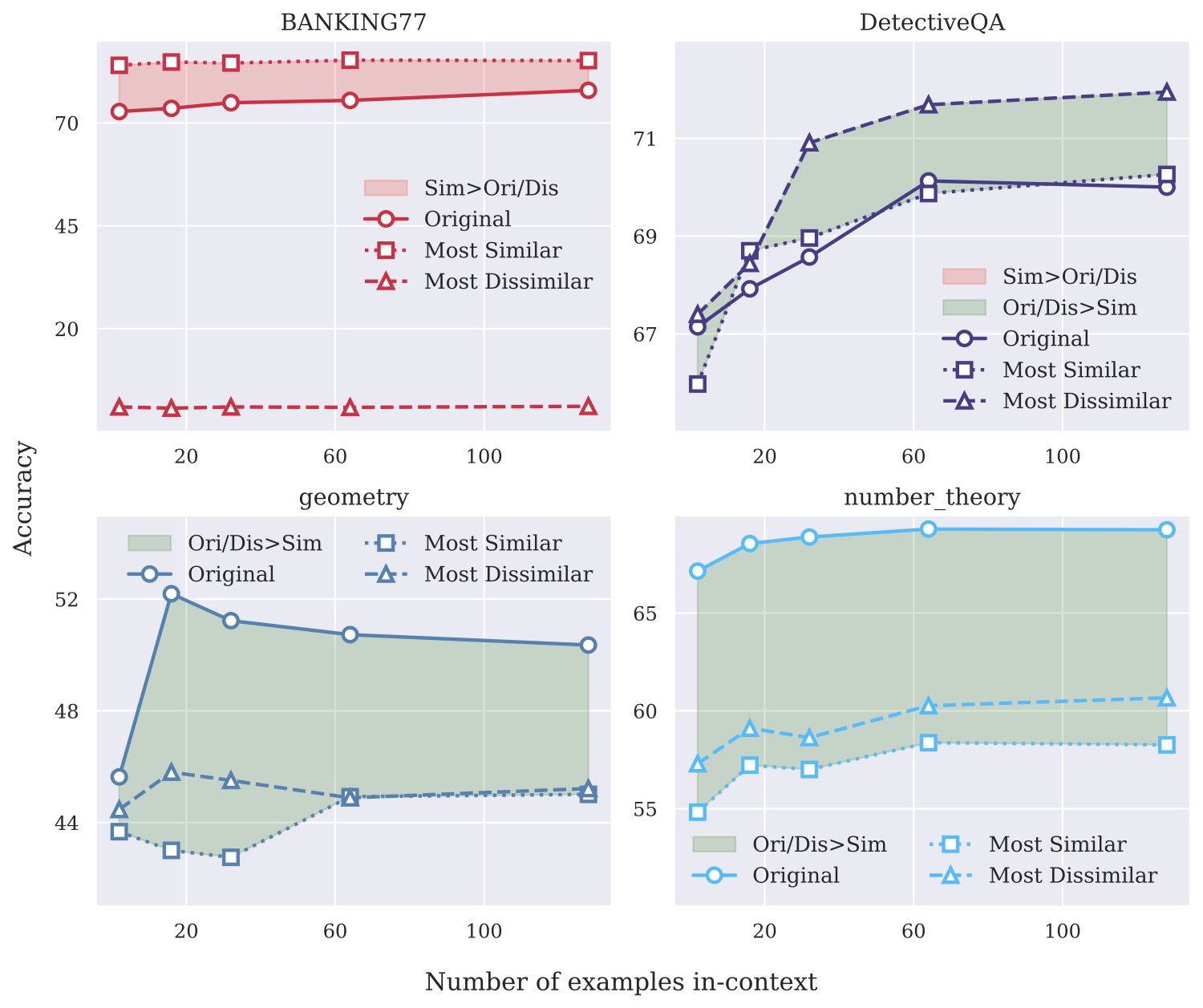
图 4:四个任务上"最相似 vs 最不相似"两组示例的对比。BANKING77 上最相似的红色集合一骑绝尘,符合过去的认知。但右上的 DetectiveQA 和下方两个数学任务上,最相似集合(虚线方块)反而稳定垫底——绿色填充区域就是这个反转的视觉化。
数论任务上差距尤其夸张。原始随机排序的曲线(实心圆)稳定在 67-68,最相似集合(虚线方块)压在 55-58 之间,差了将近 10 个点。
作者的解释挺有洞察力——semantic similarity 对应的是问题层面的相似,但 CoT 任务需要的是程序层面的相似。两道题的问法可能高度雷同,解法却完全不同。我看附录里给了个具体例子,挺生动:
测试题是 30-60-90 直角三角形里求高线分段长度,正确解法用的是"面积法 + 勾股"。检索回来最相似的 demo 是另一道直角三角形题目,但那道题用的是 30-60-90 比例直接套,根本没出现高线。模型被这个 demo 误导,照搬比例法,结果就翻车了。
这个失败模式在工程上其实很常见。我之前在做数学 RAG 的时候也遇到过——retriever 召回的题目长得像,但解法路径是另一套,模型就跟着 demo 跑偏。当时我们的临时方案是给检索结果加一个"解法签名"做二次过滤,但说到底这是个绕过去的工程 hack,没回答"为什么 similarity 在推理任务上失效"这个更根本的问题。这篇论文给出的答案——question similarity 是 procedural compatibility 的弱代理——比我之前想的要清晰。
发现三:示例数越多,顺序方差越大
第三个反常识结论是关于顺序敏感性的。
按照过去几年的主流说法,shot 数变多之后,模型对示例顺序就不敏感了——这也是 many-shot ICL 的一个卖点。作者用五次随机置换的标准差作为度量,把这件事在两类任务上对比了一下:
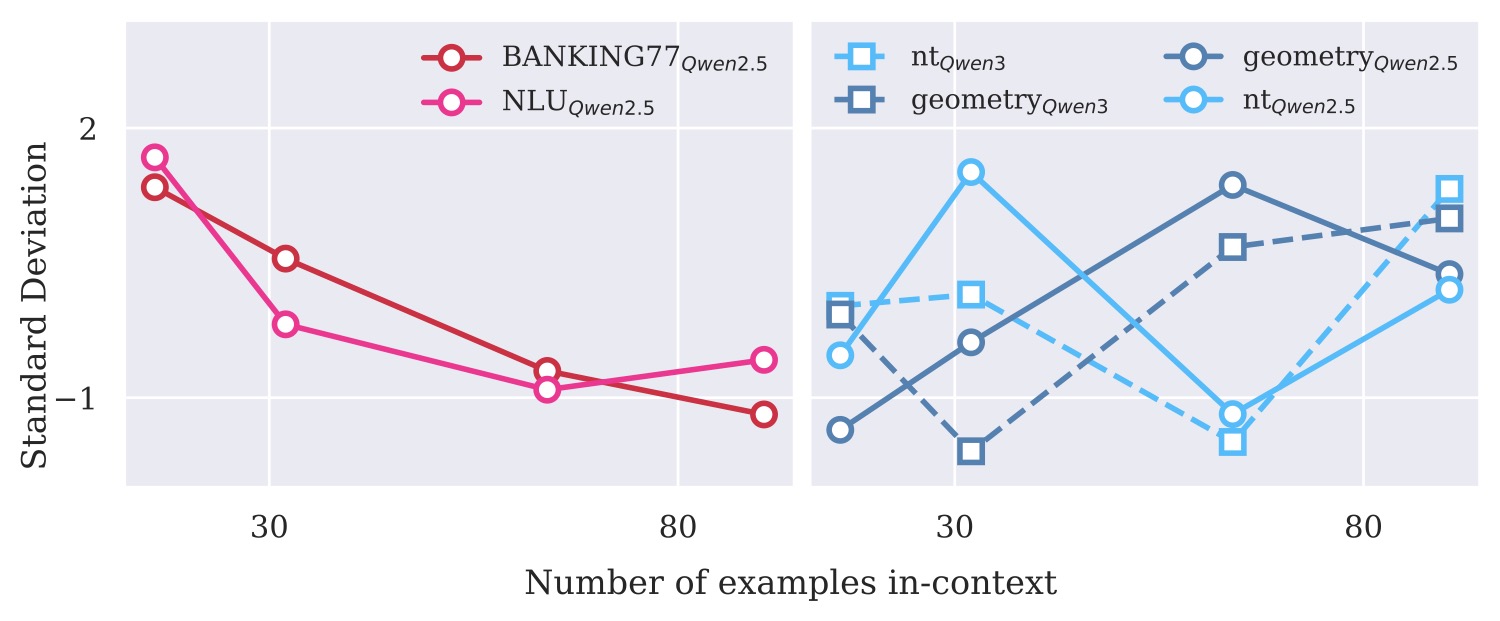
图 5:两类任务的顺序方差曲线完全相反。左侧分类任务上 shot 数增加方差下降;右侧推理任务上 shot 数增加方差反而扩大。这就是论文里所谓的 order-scaling effect。
这个 order-scaling effect 是整篇论文逻辑链条上最关键的一环。如果 many-shot CoT-ICL 只是在做模式匹配,那它应该和分类任务一样,shot 越多越稳。但实际观察到的是相反趋势,这就把"放大版模式匹配"这个假设彻底打掉了。
那为什么顺序在 CoT-ICL 里这么关键?作者的解释是——demo 之间的转折决定了模型走的推理轨迹。两个连续的 demo 如果概念跳跃太大,模型在内部状态上就会出现强烈的扰动,把前面好不容易"内化"的程序冲掉。这就为后面的曲率方法埋了伏笔。
重新定义 CoT-ICL:上下文里的测试时学习
聊到这儿,作者抛出了整篇论文的核心论点:many-shot CoT-ICL 不是检索 + 模式匹配,而是上下文里的测试时学习。prompt 不是一个静态的参考库,而是一段"在前向传播里完成的训练数据"。
这个 framing 听起来有点玄,但作者用了一个相当干净的对照实验来证明它。在几何任务上设置两组 prompt:
- Valid:标准 \((x_i, C_i, y_i)\),每个题目配自己的推理链。
- Corrupted:把所有题目的推理链都替换成第一个 demo 的那条 \(C_0\),题目和答案保持不变。
在 \(n=16\) 时,两组结果几乎一样(Qwen3-8B 都是 57.62,Qwen3-14B 一组 66.17 一组 67.01)。但到了 \(n=128\),差距出来了——Qwen3-8B 从 67.01 跌到 65.76,Qwen3-14B 从 73.07 跌到 70.56。
这个对照设计得很聪明。它控制了三件事:prompt 格式、上下文长度、\(x \to y\) 映射。唯一变化的是"推理链是否和题目对齐"。在小 shot 数下没差别,说明模型本来就靠不上 CoT;而 shot 数变大之后,掉点变明显,说明此时模型真的在读这些推理过程并提炼出可复用的程序。
这就给"测试时学习"这个 framing 找到了直接证据:模型不是在背答案,是在背"怎么算"。
两条设计原则
有了这个新视角,作者推出两条原则。
原则一:示例要对模型"易理解"
这个原则借了教育心理学里的"最近发展区"概念。简单讲,示例不在于多正宗、多权威,而在于落在模型能解读的范围内。
实验设计是这样的:同一道题,让目标模型自己用 temperature=1.0 采样 10 次,生成 10 条 CoT;然后构造三个集合——只用答对的(cr)、只用答错的(wr)、第一条不管对错(first)。再和数据集自带的 ground-truth CoT(origin)做对比。
结果很有意思:自生成的 CoT 几乎在所有设置下都比 ground-truth 更好用,哪怕里面有答错的。Qwen3-8B 用自己生成的 first 集合在数论上 91.08,原版 88.04,gap 三个点。更夸张的是 Llama-3.1-8B 用 wrong 集合(全是答错的 CoT),居然比原版还高——35.91 vs 22.21。
这个结果其实在挑战一个很深的直觉:示例的"质量"到底是什么?传统直觉里,正确性 = 质量。但这里说,分布对齐 > 答案正确。一个写得跟模型自己风格一致的错误推理,比一份完美但风格不熟的标准答案更有用。
作者还测了一个跨模型迁移:用 Qwen3-14B 生成的 CoT 去 prompt Qwen3-8B。结果是这套"更强老师"的演示在小 shot 数上勉强能用,到 64-shot 和 128-shot 就被自生成方案反超。这事在工程上挺有指导意义——别人家训练得很好的 CoT,对你的目标模型不一定是最优监督。
原则二:示例之间的过渡要平滑
第二条原则就更几何化了。把整条 prompt 看成嵌入空间里的一条折线,相邻 demo 之间的转折角度就是局部曲率。整段 prompt 的总曲率越小,过渡就越平滑。
公式上,每个位置 \(i\) 的局部曲率是连续两段位移向量的夹角:
整体曲率是所有夹角之和。作者在三个数学任务上跑了一遍曲率和准确率的相关性,得到了 Pearson 相关系数 \(r = -0.547\)(几何 -0.545、数论 -0.468、计数概率 -0.628)。
这三个数其实蛮硬的。-0.5 量级的相关系数说明曲率不是随便扯进来的指标,它确实和性能挂钩。而且这件事在工程上给前面的 order-scaling effect 提供了机制解释——shot 数越多,随机排列里出现"剧烈概念跳跃"的概率就越大,方差自然就放大了。
CDS:把这件事变成算法
到这里,整个故事就被收成一个明确的优化目标:找到一个示例顺序,让总曲率最小。
直接解组合优化不现实,128 个示例的 128! 排列空间没办法穷举。作者退而求其次,把这个问题转写成了一个 TSP(旅行商)变种:
欧氏距离项保证相邻示例不会跨越太大的语义空间,曲率项压低相邻转折的角度。两个项加起来作为图上的边权,跑一个 nearest-neighbor + 2-opt 的启发式 TSP,128 个节点 1 分钟内就能解完。
为什么要把欧氏距离和曲率项合起来?作者的解释是——只用曲率会得到"几何上很直但跨度很大"的轨迹,相邻 demo 可能离得很远,模型连续读两个会跳得很远,过渡仍然不平滑。这个细节挺工程化的,能看出来作者真的跑过实验。
主实验:CDS 在四种 shot 配置上的表现
CDS 在三个推理任务(几何、数论、DetectiveQA)上的结果如下表。注意作者还用 bge-m3 换了一遍 embedding 模型(CDS\(_{bge}\)),证明这套方法不依赖某个特定 embedder。
| 任务 | 模型 | 方法 | 16 | 32 | 64 | 124 |
|---|---|---|---|---|---|---|
| number_theory | gpt-5.2 | origin | 89.63 | 91.11 | 88.56 | 91.48 |
| CDS | 89.26 | 92.59 | 92.04 | 91.85 | ||
| CDS_bge | 88.15 | 91.48 | 88.70 | 91.30 | ||
| Qwen3 | origin | 86.67 | 87.96 | 86.30 | 90.93 | |
| CDS | 85.56 | 87.85 | 87.78 | 90.74 | ||
| geometry | gpt-5.2 | origin | 75.99 | 74.74 | 75.37 | 75.78 |
| CDS | 81.21 | 78.08 | 80.79 | 75.99 | ||
| Qwen3 | origin | 66.18 | 65.76 | 65.14 | 73.07 | |
| CDS | 65.55 | 68.27 | 68.89 | 73.90 | ||
| CDS_bge | 66.60 | 67.85 | 70.36 | 74.32 | ||
| DetectiveQA | gpt-5.2 | origin | 80.52 | 82.47 | 83.77 | 85.71 |
| CDS | 80.52 | 83.12 | 85.06 | 88.31 | ||
| Qwen3 | origin | 75.97 | 74.03 | 70.78 | 72.73 | |
| CDS | 76.62 | 75.32 | 73.38 | 75.32 |
最亮眼的几个点:
- 几何上 gpt-5.2 在 16-shot 拉了 5.22 个点(75.99 → 81.21),64-shot 拉了 5.42 个点(75.37 → 80.79)。这就是摘要里那个 5.42 的来源。
- DetectiveQA 上 Qwen3 几乎所有 shot 数都有 1-4 个点的稳定提升。
- 数论上提升较小——但作者解释了,数论 baseline 已经很高了,留给排序的空间不大。这个解释我倾向于接受,因为 91 分以上要再涨确实需要别的手段。
因果消融:高曲率对照
我看到表格的时候有个担心——CDS 的提升会不会其实是欧氏距离项带来的?毕竟它在邻域聚类上也做了优化。作者很警觉地补了一个"高曲率"对照实验:保留欧氏邻域约束不变,但反转曲率目标,强迫连续示例之间转折角度最大。
| 任务 | 模型 | 方法 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|
| number_theory | Qwen3-14B | CDS | 85.37 | 87.78 | 87.22 | 91.30 |
| high curv | 79.26 | 84.44 | 84.26 | 90.37 | ||
| geometry | Qwen3-14B | CDS | 66.60 | 67.85 | 70.36 | 74.32 |
| high curv | 66.38 | 66.81 | 66.60 | 71.80 |
数论 16-shot 上 CDS 比高曲率高了 6.11 个点,几何上也有持续优势。这就把"曲率本身是因果因素"这个论点坐实了。
我的几点判断
聊到这儿,我想说几句自己的看法。
这篇论文最有价值的地方不是 CDS 算法本身,而是它把 many-shot CoT-ICL 从"模式匹配"的视角拉到了"测试时学习"。前者只能解释为什么 shot 多了会涨,解释不了为什么会反向 scaling、为什么相似度检索失效、为什么顺序方差会放大。后者一次性把这三件事都收进来了,框架的解释力比单点提升要更重要。
思考模式 + 长 CoT 上下文那段表格特别让我在意。Qwen3-14B 把 shot 数从 16 拉到 128 时,思考阶段 token 数反而减少 24.02%。这事如果能复现,那 CoT-ICL 就不只是 prompt 工程,而是某种隐式蒸馏——长上下文示例把任务程序"装进"了模型的注意力,思考阶段就不用再重推一遍。如果这个机制坐实了,未来 reasoning 模型的部署可能会有新的 trick:用 CoT-ICL 把任务程序灌进去,再把模型从冗长 thinking 模式切到精简模式,省一大笔推理 token。
但这套方法也有几个明显的边界。
第一,CDS 严重依赖好的 embedding。论文用了 Qwen3-Embedding-4B 和 bge-m3 两种,效果差不多。但如果换个对推理结构不敏感的 embedding(比如纯语义模型),曲率信号可能就失真了。曲率只是 embedding 空间里的几何量,embedding 本身的语义能力是天花板。
第二,CDS 默认你已经有一组高质量 demo。它解决的是"怎么排序",不是"怎么选"。当 demo 池本身质量一般时,CDS 帮不了你太多。原则一(自生成 CoT 优于权威 CoT)已经回答了一部分选择问题,但论文没有把"选择 + 排序"合成一套统一方法。
第三,所有曲率提升基本在 32-shot 到 64-shot 区间最显著。在 128-shot 上,gpt-5.2 在几何上的提升收窄到 0.21(75.78 → 75.99)。看起来当 shot 数足够大时,模型对单条转折的鲁棒性其实会变好,CDS 的边际收益反而下降。这个 trade-off 在工程选型时要考虑。
第四,论文里所有"推理 LLM" 都来自 Qwen3 / QwQ / DeepSeek 系列,方法学结论会不会泛化到 OpenAI o-系列或 Anthropic 的扩展思考模型,作者没测。gpt-5.2 的实验是后补进来的辅助证据,但 gpt-5.2 不是论文重点对比对象。
工程上能怎么用
如果你也在做长上下文 CoT 任务,这篇论文有几条可以直接落地的建议。
第一,别再无脑相似度检索 CoT 示例。如果你的任务是推理(数学、代码、agent planning 这种),similarity retrieval 大概率帮倒忙。可以测一下随机排序作为对照,很多时候不检索反而比检索好。
第二,自己的模型生成自己的 CoT。要训目标模型就让它自采样,哪怕一半答案是错的,对齐到自身分布带来的收益比借用更强模型的 CoT 大得多。这条对小模型部署尤其重要——拿 GPT-4 蒸馏出来的 CoT 给 7B 模型当 demo,效果可能反而不如让 7B 自己生成。
第三,示例顺序值得花时间调。CDS 跑一遍 TSP 在 CPU 上不到一分钟,没什么部署成本。如果你的生产 pipeline 里 demo 是固定的,那 CDS 排序甚至可以离线算好缓存起来,推理阶段零开销。
第四,关注 thinking token 的变化。如果你在用 Qwen3、DeepSeek-R1 这种推理模型,CoT-ICL 可能让 thinking 段变短。这其实是好事——既能涨准确率又能省推理成本,但需要你的部署框架支持 thinking 段长度统计。
一个还没解决的问题
最后留一个我自己没想明白的事。
CDS 假设的是:嵌入空间里的曲率 = 推理过程中的概念跳跃。但 embedding 空间和模型实际的 attention pattern 是两套东西。一个用 Qwen3-Embedding-4B 算出来的"平滑过渡",在 Qwen3-14B 的内部表征里真的是平滑的吗?这中间隔了多少?
如果哪天有人能直接从模型自身的隐状态里抽出曲率信号,再去做排序,效果可能比借用外部 embedding 更好。但那就是另一篇论文了。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我。