把 7B 视觉语言模型从 32K 拉到 128K,他们只花了 50 亿 token——还顺便外推到了 512K
一段话说清这是什么
视觉语言模型现在卷得很厉害,能力上的下一个分水岭就是长上下文:能不能一次塞进整本财报、整场长视频、整段 Agent 工具调用历史。问题是,闭源那几家从来不告诉你"长文档数据到底该怎么配"。这篇论文做的就是把这件事掰开了讲清楚:他们把 Qwen2.5-VL-7B 的上下文窗口从 32K 推到 128K,只花了 5B token 预算,最后得到的 MMProLong 在长文档 VQA 上比 base 提升了 7.11 个点,更离谱的是——训练只到 128K,但在 256K 和 512K 上比基线高出 20 多个点。能不能复制不是重点,重点是他们把每一个数据配方决策都做了消融,让别人能直接抄作业。
我看完最大的感受是:长上下文这件事,"训练数据多长"远不如"训练数据怎么分布"重要。
论文信息
- 标题:Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
- 作者:Zhaowei Wang, Lishu Luo, Haodong Duan, Weiwei Liu, Sijin Wu, Ji Luo, Shen Yan, Shuai Peng, Sihang Yuan, Chaoyi Huang, Yi Lin, Yangqiu Song
- 机构:HKUST + ByteDance Seed
- arXiv:2605.13831(2026 年 5 月,work in progress)
先说清楚痛点:长上下文 LVLM 训练,外人根本不知道怎么搞
你去翻 Qwen3-VL、GLM-4.5V、Gemini 3.1 这些最新模型的报告,长上下文部分基本都是一笔带过:用了哪些数据、按什么比例混的、序列长度分布长什么样——一概没有。开源世界拿到的,只是一个号称支持 128K 的 checkpoint。
我自己之前做长上下文相关项目的时候就被这事坑过。直觉上你会想:既然要训 128K,那训练数据就尽量都做成接近 128K 的不就好了?结果发现训出来的模型在中长度(比如 60K~80K)上性能反而崩了。这种"训练长度和评估长度不一致就翻车"的现象很常见,但没人系统讲过该怎么办。
这篇论文的切入点就是这里:实证地、消融地、一项一项把长上下文持续预训练(Long-Context Continued Pre-training, LongPT)的关键决策跑一遍。具体而言他们想回答四个问题:
- 长文档数据应该做成什么任务形式?OCR 转录还是 VQA?
- 训练样本的长度分布应该怎么选?聚焦目标长度还是覆盖宽分布?
- 多种长上下文任务怎么混?以检索为主还是以推理为主?
- 长数据训练会不会把短上下文能力训没了?需不需要专门补短数据?
每个问题都对应实打实的消融实验,下面一个个聊。
数据合成:长文档 VQA 完胜 OCR 转录
五种候选任务
他们从超过 150 万份 PDF 文档里抽出 32 到 50 页的样本(这个范围在 Qwen2.5-VL 的 token 化下正好落在 32K~128K),然后基于这些文档构造五种训练任务:
长文档 VQA 类(带指令格式的 QA 对): - extract-single:从单页提取事实信息 - extract-multi:跨多页聚合事实 - reasoning:在提取出的信息上做数值或逻辑推理(加和、比较、计数等)
OCR 转录类(让模型把图像里的文字抄出来): - OCR-full:转录整篇文档所有页的文字 - OCR-needle:只挑 1~3 页转录,其他页当干扰项,相当于"检索风格"的 OCR
长文档 VQA 的数据合成流水线挺巧妙。下面这张图把整个过程画得很清楚:
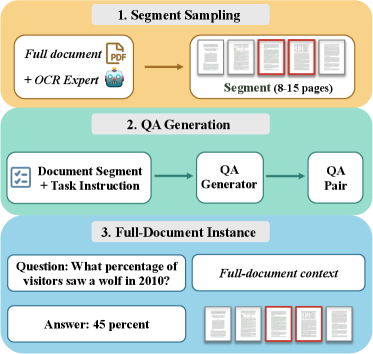
图1:三步走的合成流水线。第一步用 OCR 专家解析整个 PDF,按章节边界采样一段 8~15 页的连贯片段;第二步把这段片段喂给 Seed 2.0,让它针对这一段生成一组 QA 对;第三步把生成的 QA 对放回原始整本文档里,让答案虽然存在于一个局部短片段中,但模型在训练时必须在完整长文档里检索定位。
这个设计有个聪明的地方:QA 生成器只看 8~15 页,不需要它具备 128K 的长上下文能力。强短上下文模型就够用。生成成本因此降得很低。
还有一个细节我觉得值得拎出来说。因为 QA 是从局部片段生成的,放回完整文档后可能出现歧义——"报表里写的营收是多少"这种问题,在不同章节可能有不同答案。他们的处理方式是强制 QA 生成器在问题里加 anchor,比如"在第 20 到 25 页提到的"、"在 Introduction 章节里",把指代锁定。这种细节其实就是工程里最容易翻车的地方。
实验结果:一边倒
5B token 预算下,跑了一遍 MMLongBench(包含 MMLongBench-Doc、LongDocURL、SlideVQA 三个长文档 VQA 数据集),结果非常直观:
| 训练数据 | 64K AVG | 128K AVG | 总均值 | 相对 base 变化 |
|---|---|---|---|---|
| Qwen2.5-VL-7B(base) | 52.24 | 48.94 | 50.59 | — |
| extract-single | 56.86 | 54.53 | 55.69 | 涨 5.1 个点 |
| extract-multi | 58.02 | 55.77 | 56.90 | 涨 6.3 个点 |
| reasoning | 57.33 | 55.62 | 56.47 | 涨 5.9 个点 |
| OCR-full | 31.24 | 35.11 | 33.17 | 跌 17.4 个点 |
| OCR-needle | 45.61 | 42.00 | 43.80 | 跌 6.8 个点 |
| OCR-full + 5B SFT | 56.09 | 51.59 | 53.84 | 涨 3.2 个点 |
| OCR-needle + 5B SFT | 54.06 | 50.83 | 52.44 | 涨 1.9 个点 |
几个让我皱眉的地方:
第一,OCR-full 直接把模型干跌了 17 个点。这个降幅很恐怖。原因不难理解——OCR 转录是"把图里的字抄出来"的任务,跟"按指令回答问题"完全是两种格式,长时间在这种数据上训会破坏模型的指令跟随能力。
第二,就算给 OCR 模型加 5B token 的 SFT 矫正一下,最好也才涨 3.2 个点。而 VQA 单独训不需要任何 SFT 就能涨 6.3 个点。换算下来 VQA 的"token 效率"是 OCR + SFT 的两倍多。
第三,三种 VQA 任务之间差距不大,extract-multi 最好。这其实暗示了一个判断:长文档 VQA 这个任务族最大的价值是"指令格式 + 任务多样性",至于具体是单页提取还是多页提取,没那么关键。
到这里第一个核心结论就出来了:长文档 VQA 是 LongPT 的主力数据形式,OCR 转录不值得搞。
反直觉的发现一:长样本越多反而越差
确定 VQA 是主力之后,接下来的问题就是——训练样本的长度分布应该怎么调?
直觉上你会觉得:既然要训 128K,那训练样本就尽量靠近 128K 不就好了?这篇论文把这个直觉给打碎了。
他们造了两套数据: - pool-native:自然采样,文档页数在 32~50 页范围里均匀采样,最终大约只有 23.6% 的样本超过 100K - long-biased:人为偏向长样本,把 83.9% 的样本拉到 100K 以上
跑出来的结果是这样:
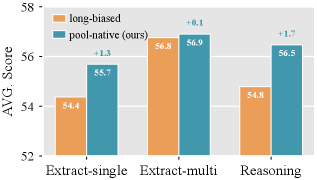
图2:橙色是 long-biased(偏长),绿色是 pool-native(自然分布)。三种任务上 pool-native 都赢,extract-single 上涨 1.3 个点,extract-multi 涨 0.1 个点,reasoning 涨 1.7 个点。
也就是说,让模型只见 128K 附近的样本,反而不如让它见从 32K 到 128K 各种长度都有的样本。
为什么会这样?我自己的理解是这样的:长上下文能力说到底不是"记住到 128K 这个位置还能 attend"这种离散技能,而是"在任意位置都能精准检索关键信息"这种连续能力。如果你的训练样本全集中在 128K,模型见到的"信息位置"分布就高度集中在文档尾部和长距离处;中等距离(比如 50K 处的关键信息)模型见得反而少,自然就训不好。
这个发现对工程很有指导意义——与其想办法把训练样本都做长,不如保持自然的长度多样性。这意味着你不需要专门去合成"超长样本",省事很多。
反直觉的发现二:检索是瓶颈,不是推理
第二个消融是任务混合比例。三种 VQA 任务,extract-single 和 extract-multi 都属于"信息抽取",reasoning 属于"推理"。两类之间应该按什么比例混?
他们做了一个 6 档网格搜索(抽取:推理 从 0:10 到 10:0),结果如下:
| 抽取:推理 | 64K AVG | 128K AVG | 总均值 |
|---|---|---|---|
| 0:10(纯推理) | 57.33 | 55.62 | 56.47 |
| 2:8 | 58.02 | 54.24 | 56.13 |
| 4:6 | 56.35 | 55.11 | 55.73 |
| 6:4 | 58.79 | 55.75 | 57.27 |
| 8:2 | 59.56 | 55.84 | 57.70 |
| 10:0(纯抽取) | 57.49 | 56.40 | 56.94 |
最佳点是 8:2 偏抽取。这个结果不算特别意外,但有意思的是它比单独任何一种任务都好——说明任务多样性本身是有收益的。
更值得琢磨的是这个最佳比例的方向:检索/抽取占大头,推理只占两成。这个发现挺反 LLM 主流叙事的。现在 LLM 圈大家在卷 reasoning,所有人都觉得推理是稀缺的、推理是天花板。但在长上下文场景下——真正的瓶颈不是推理,而是"我能不能从一百多页里准确找到那个关键 chunk"这件事。
这个判断我是认同的。我自己看过太多长上下文翻车的 case,绝大多数都是检索失败:要么 attend 错了位置,要么把对的位置 attend 上了但 weight 太分散。等检索做对了,剩下的小段推理对 7B 模型来说真不算难事。
反直觉的发现三:纯长数据训练,几乎不掉短上下文能力
第三个问题是大家做长上下文都担心的:长数据训多了,模型在普通短上下文任务上会不会退化?
LLM 圈的经验是会退化得很惨,所以像 ProLong 这种工作都要专门混很高比例的短数据来对冲。这篇论文做的实验是从 0% 短数据加到 80%,看看长短两边的曲线怎么走。
短上下文那一侧的结果(MMBench / RWQA / MMMU / MMMU-Pro / MathVista / OCRBench 六项平均):
| 短数据比例 | 短上下文 AVG |
|---|---|
| Qwen2.5-VL-7B(base) | 66.47 |
| 0%(纯长) | 65.48 |
| 20% | 66.53 |
| 40% | 66.14 |
| 60% | 66.05 |
| 80% | 66.17 |
注意看 0% 这一行——纯长数据训练下来,短上下文能力从 66.47 只掉到 65.48,损失不到 1 个点。这跟 LLM 圈的经验差别太大了。
而长文档 VQA 那一侧的结果:
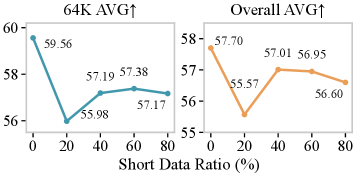
图3:随着短数据比例从 0% 升到 80%,长上下文性能整体下滑。0% 短数据时长文档 AVG 达到 57.70 的峰值。
合在一起,作者最终的取舍是 0% 短数据。如果你确实更看重短上下文保留,40% 是个折中选项(长 57.01 / 短 66.14)。
为什么会跟 LLM 不一样?作者给了一个挺有说服力的解释:LLM 长上下文预训练用的是 books、code repo 这种纯文本流,跟下游"指令跟随"任务的格式差异很大;而长文档 VQA 本身就是 QA 格式,跟短上下文 benchmark 的格式天然一致。也就是说,"长"只是变了 input 长度,"任务形态"没变,所以短能力不掉。
这个观察其实给了一个挺实用的工程启发:如果你的长上下文训练数据本身就是 instruction-style 的,那短数据混合可以省了,省下的预算全砸到长数据上。
把上面这些拼起来:MMProLong 的最终配方
把消融的所有结论组合起来,最终配方就是:
- 基础模型:Qwen2.5-VL-7B
- 数据形式:长文档 VQA(不要 OCR 转录)
- 长度分布:pool-native,自然分布,不要人为偏长
- 任务比例:抽取(extract-single + extract-multi)和推理 = 8:2
- 短数据比例:0%
- mRoPE 基频:从 1e6 提到 4e6(按 Dynamic-NTK 启发式)
- 预算:5B token,最大序列长度 131072,全局 batch 4M token
然后把它跟一长串 baseline 比,重点看 15B 以下开源小模型:
| 模型 | 64K AVG | 128K AVG | 总均值 |
|---|---|---|---|
| MMProLong(7B) | 59.56 | 55.84 | 57.70 |
| Qwen2.5-VL-7B | 52.24 | 48.94 | 50.59 |
| InternVL3-8B | 50.19 | 44.11 | 47.15 |
| InternVL3-14B | 50.67 | 44.27 | 47.47 |
| InternVL3.5-8B | 38.40 | 16.72 | 27.56 |
| Gemma3-12B | 48.03 | 47.49 | 47.76 |
| Gemma4-E4B | 37.07 | 37.09 | 37.08 |
7B 这个体量下,MMProLong 是同档最强。比自己的 base 涨了 7.11 个点,跟 14B 量级的 InternVL3-14B 拉开了 10 个点。
要客观一些说:跟 Qwen2.5-VL-32B(58.31)和 72B(60.83)比,MMProLong 7B 已经接近 32B 的水平。但它确实打不过 Gemma4-31B(67.10),更打不过闭源那一档(Gemini-3.1-Pro 83.66,GPT-5.5 那个 90.77 的数我看着觉得有点离谱,估计是闭源模型在 MMLongBench 这种公开 benchmark 上的污染问题)。
这里我想停下来吐槽一句:论文里 GPT-5.5 在 64K MMLB-D 上拿到 93.10 分这个数据,我个人是比较怀疑的。MMLongBench 已经发布很久了,这种新一代闭源模型大概率训练数据里见过原题或同源材料。这个数应该谨慎看,不要直接拿来当"长上下文能力天花板"。
真正让我兴奋的部分:训练只到 128K,外推到 512K
通常你训练到 128K,模型在 200K 以上就直接崩。但 MMProLong 没崩,而且非常稳:
| 模型 | 256K AVG | 512K AVG | 总均值 |
|---|---|---|---|
| MMProLong | 55.09 | 52.52 | 53.80 |
| Qwen2.5-VL-7B | 38.12 | 19.49 | 28.80 |
| Gemma3-4B | 32.52 | 15.51 | 24.02 |
| Gemma3-12B | 47.37 | 23.51 | 35.44 |
看 Qwen2.5-VL-7B 这一行——从 256K 的 38.12 直接掉到 512K 的 19.49,腰斩。MMProLong 从 55.09 只掉到 52.52,几乎线性外推。
为什么会这样?我倾向于把这个外推能力归因到前面的第一个发现——pool-native 长度分布让模型学到的是泛化的相对位置检索能力,而不是只针对 128K 这一个长度上的检索套路。一旦学到的是泛化的能力,外推就成立。
这是这篇论文我最看重的一个发现。如果你的工程目标是"训一个能扛超长上下文的模型,但又不想为 512K 单独训",pool-native + VQA 这套配方真的是个实用解。
泛化到完全没训过的任务
最后他们还测了三类完全没在训练时见过的长上下文任务:
MM-NIAH(多模态大海捞针):在长网页里塞针,让模型找。
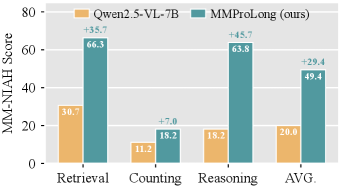
图4:MMProLong 在 MM-NIAH 上全面碾压 base。检索任务从 30.7 涨到 66.3(提升 35.7 个点),推理从 18.2 涨到 63.8(提升 45.7 个点),整体均值从 20.0 涨到 49.4。
Retrieval 涨 35.7 个点,Reasoning 涨 45.7 个点——这种幅度的提升在零样本迁移上是相当夸张的。它说明 LongPT 学到的"在长上下文里定位 + 利用关键信息"的能力,可以从文档场景直接迁移到网页场景。
长视频理解:Video-MME、MLVU、LongVideoBench 这三个长视频 benchmark,注意训练里没有任何视频数据,纯靠长文档 VQA 训出来的能力外推。
图5:MMProLong 在三个长视频 benchmark 上都比 Qwen2.5-VL-7B 强。Video-MME、MLVU、LongVideoBench 全面提升,注意训练数据里完全没有视频。
视频上能涨,说明模型学到的不是"对文档结构的过拟合",而是更底层的"长序列中跨模态对齐 + 长距离检索"的能力。
VTCBench(长上下文视觉-文本压缩):从 48.23 涨到 52.73。
这三类外推结果合起来,作者的判断是:这套 LongPT 配方学到的是一种通用的长上下文多模态能力,不是对 document VQA 格式的过拟合。我倾向于认同这个判断。
我的几个判断
优点:
第一,这篇论文最大的价值不是 MMProLong 这个模型本身,而是它把"长上下文 LVLM 训练的每一项决策"做成了独立可复用的消融。这种 ablation-first 的工作在开源社区是稀缺的——大家都知道闭源那几家肯定做了很多内部消融,但从来不公开。这篇论文相当于把字节内部的 LongPT 配方实证细节交出来了。
第二,三个反直觉发现都站得住脚:长样本越多反而越差、检索是瓶颈不是推理、纯长训练几乎不掉短能力。这些发现里至少有两个跟 LLM 圈的主流经验是反着的,这种"打破既有认知"的论文我特别愿意推荐人去读。
第三,5B token 预算 + 128K 训练 → 外推 512K 这个 ROI 非常打。在 H100 还是稀缺资源的当下,能用小预算抠出长上下文能力,对很多团队都很实用。
问题或保留:
第一,论文里只在 Qwen2.5-VL-7B 上做了完整消融,附录里在 Qwen3-VL-8B 上做了验证但不算完整。如果换到更大的 base 上(比如 72B 量级),8:2 这个比例还成立吗?短数据 0% 这个结论还成立吗?我不确定。
第二,所有评测都集中在 MMLongBench 这一个长文档 benchmark 系列上。MMLongBench 已经发布一年多,模型在上面刷分是不是有训练数据污染风险?尤其闭源那一栏的数据,我会更谨慎看待。如果能在更新发布的 long-context benchmark 上再验证一遍会更有说服力。
第三,"长样本越多反而越差"这个结论在他们的设定下确实成立,但 pool-native vs long-biased 只是两个端点,中间还有很多分布形态没试。比如"对数均匀分布"或者"两端高、中间低的 U 型分布"会不会更好?这块还有空间。
对你/我的实际启发:
如果你也在做长上下文相关的训练,几条直接能抄的:
- 长上下文 SFT/CT 数据不要做成 OCR 转录这种没指令的形态,做成 QA 格式,跟下游评测对齐
- 训练样本长度分布让它自然,不要为了"匹配评估长度"专门偏长合成
- 抽取类任务占大头,少量推理点缀,比例 8:2 是个不错的起点
- instruction-format 长数据可以省掉短数据混合,预算砸更划算
- 用 Dynamic-NTK 把 RoPE 基频调一下,外推到 4 倍训练长度可期
收尾
长上下文这件事,过去一年大家都在卷"窗口大小",从 32K 到 128K 到 1M。但 token 数本身只是一个上界,真正决定模型在长上下文里好不好用的,是训练时见过的信息分布形态。
这篇论文说的核心其实就这一句话:你得让模型学会"在任意位置、任意距离上检索关键信息"这种泛化能力,而不是过拟合到某个目标长度上的特定模式。配方上的每一个决策——VQA 而不是 OCR、pool-native 而不是 long-biased、抽取偏重而不是推理偏重、纯长不混短——都是在朝这个方向调。
我会把这篇放进我自己长上下文相关工作的 reading list 里,也建议你认真读一遍。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我
参考
- Wang, Z. et al. Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context. arXiv:2605.13831, 2026.
- 论文链接:https://arxiv.org/abs/2605.13831