工业质检领域的 MLLM 卡在哪了?这篇论文给了一个把工具调用塞进 RL 的解法
核心摘要
工业异常检测(IAD)这事儿本来挺尴尬的——传统方法靠"正常样本建模 + 测试时找异常",每换一种产品就要重训一遍;后来有人想用多模态大模型搞零样本,但模型一上工业场景就开始胡说八道:要么把光斑当成裂纹,要么对一颗微小的焊点视而不见。
IndusAgent 这篇 2026 年 5 月新出的工作,给了一个相对完整的答案:别让 MLLM 只看一眼就回答,让它像质检员一样"先看全局、有疑就放大、不确定就查手册",把这一整套行为塑造成一个工具调用智能体,再用 RL 训出"什么时候该用工具"的判断力。
具体做法:构建 3000 条带 CoT 推理轨迹的 Indus-CoT 数据集做 SFT 冷启动;定义 4 个工具(Crop/Prior/Enhance/Measure)让 Agent 主动调度;最后用一套带"准确率门控"的分层 RL 奖励,避免模型为了刷工具调用奖励而胡乱调工具。结果是:基于 Qwen3-VL-8B,在 5 个工业基准(MVTec-AD、VisA、MPDD、DTD、SDD)上全面刷新 SOTA,平均分 83.4 个点,比 7B 的 Anomaly-OV 高出近 4 个点,比 GPT-4.1 高了快 6 个点。
我读完最大的感受是:这不是一篇靠堆参数刷榜的论文,它给"MLLM 该怎么用工具"这个问题提了一种相对工程化的解法——尤其是 Accuracy-Gated 的奖励设计,挺值得借鉴的。
论文信息
- 标题:IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
- arXiv:2605.20682
- 提交日期:2026 年 5 月 20 日
- 作者团队:Rongbin Tan、Fangfang Lin、Zhenlong Yuan(项目负责人)等 13 人,主要来自中科院计算所、LongCat 团队、纽约大学、斯坦福、南洋理工等多机构合作
- 基础模型:Qwen3-VL-Instruct-8B
一、为什么 MLLM 在工业场景"不太行"
先聊聊这个问题为什么难。
工业异常检测要解决的事情,说到底是一个长尾、细粒度、强领域知识的视觉判别任务。一颗 PCB 上的焊点是不是冷焊?一块布料上那道线是织造纹理还是断纱?一个胶囊上那个点是印刷标识还是污染物?人类质检员要看很久、还要对照规范才敢下结论,而 MLLM 在这种任务上的表现,老实说挺糟糕。
论文一开始用了一张图把这个问题讲得很清楚。
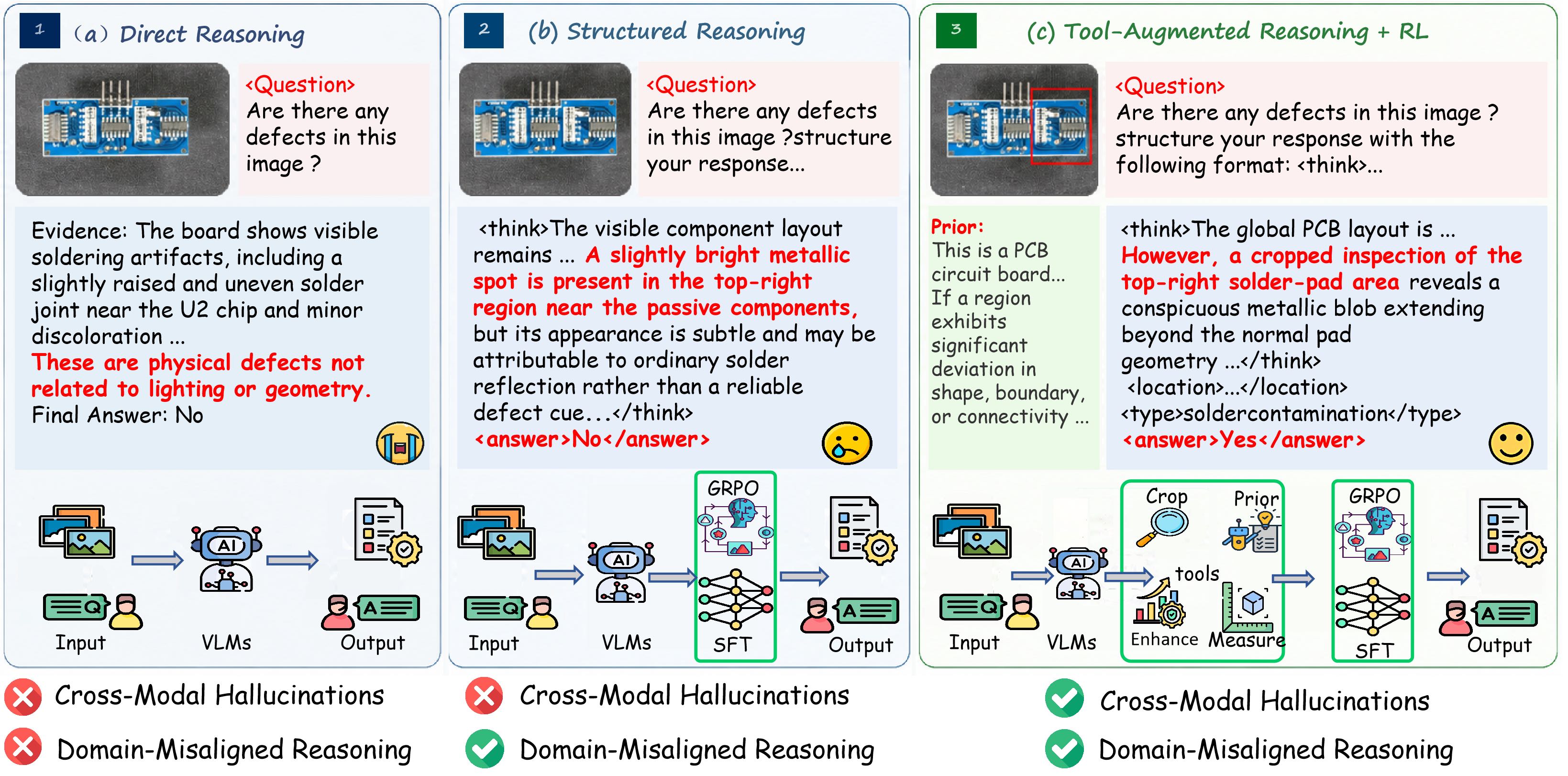
图 1:作者用一个 PCB 板的检测案例对比了三种范式。(a) 直接推理:模型看一眼就回答,结果把"右上角焊点处明显凸起的金属球"判定为"光照或几何因素",最终回答 No——典型的领域错位幻觉。(b) 结构化推理(带 SFT):模型识别到了"右上角的金属反光斑点",但因为只看全局图,仍然把它归因为"焊接反光"而不是缺陷,回答 No。(c) 工具增强推理 + RL:模型先调用 Prior 工具检索"PCB 通常应该有什么样的形态",再调用 Crop 工具把右上角焊盘区域放大查看,看清楚后才给出"是的,存在焊料污染"的诊断,并定位到具体区域。
这张图其实把整篇论文要讲的故事压缩在一起了——模型不是不能推理,是缺乏"主动获取证据"的能力。
作者在引言里把 MLLM 用于 IAD 的硬伤拆成了三块:
1. 领域错位推理(Domain-Misaligned Reasoning) 通用 MLLM 训练目标是"开放对话"——给一个问题,生成流畅、合理、安全的回答。但工业诊断要的是"严格协议":遵循检测规范、输出结构化结论、能回溯证据。一个被对齐成"乐于助人"的模型,看到模糊证据时倾向于给一个"圆滑的回答",这在工业场景下就是漏检。
2. 感知稀释(Perceptual Dilution) ViT 把图像切成 patch、再做全局池化,对全图理解很有用,但对亚像素级缺陷是灾难。一颗 1024×1024 的图里,缺陷可能就占 32×32 的区域,全局编码完之后,缺陷信号几乎被稀释成了零。这也是为什么传统 IAD 方法都要做 patch-level 特征匹配。
3. 开放词汇泛化失效 更尴尬的是,零样本场景下你压根没见过"目标缺陷长什么样"。新产品、新缺陷类型、模糊指令——MLLM 就会开始编。
说实话第二点是我之前在做相关项目时最头疼的——你给模型一张高分辨率瑕疵图,它能描述得头头是道,但就是说不出"哪里有问题"。背后的原因就是 patch-level 信息在 attention 里被均化掉了。
二、IndusAgent 的核心思路:把质检员的工作流写成一个 Agent
回到这篇论文,作者的核心洞察其实很朴素:人类质检员是怎么干活的?
- 先扫一眼整体(全局观察)
- 看到可疑区域就凑近放大(局部检查)
- 不确定就查规范手册(先验知识)
- 拿不准的还会用尺子量一量(几何测量)
- 最后给一个结构化的诊断结论
这套工作流恰好就是多轮工具调用。把 MLLM 训成会调用这套工具的 Agent,问题就解了一大半。
整体框架长这样:
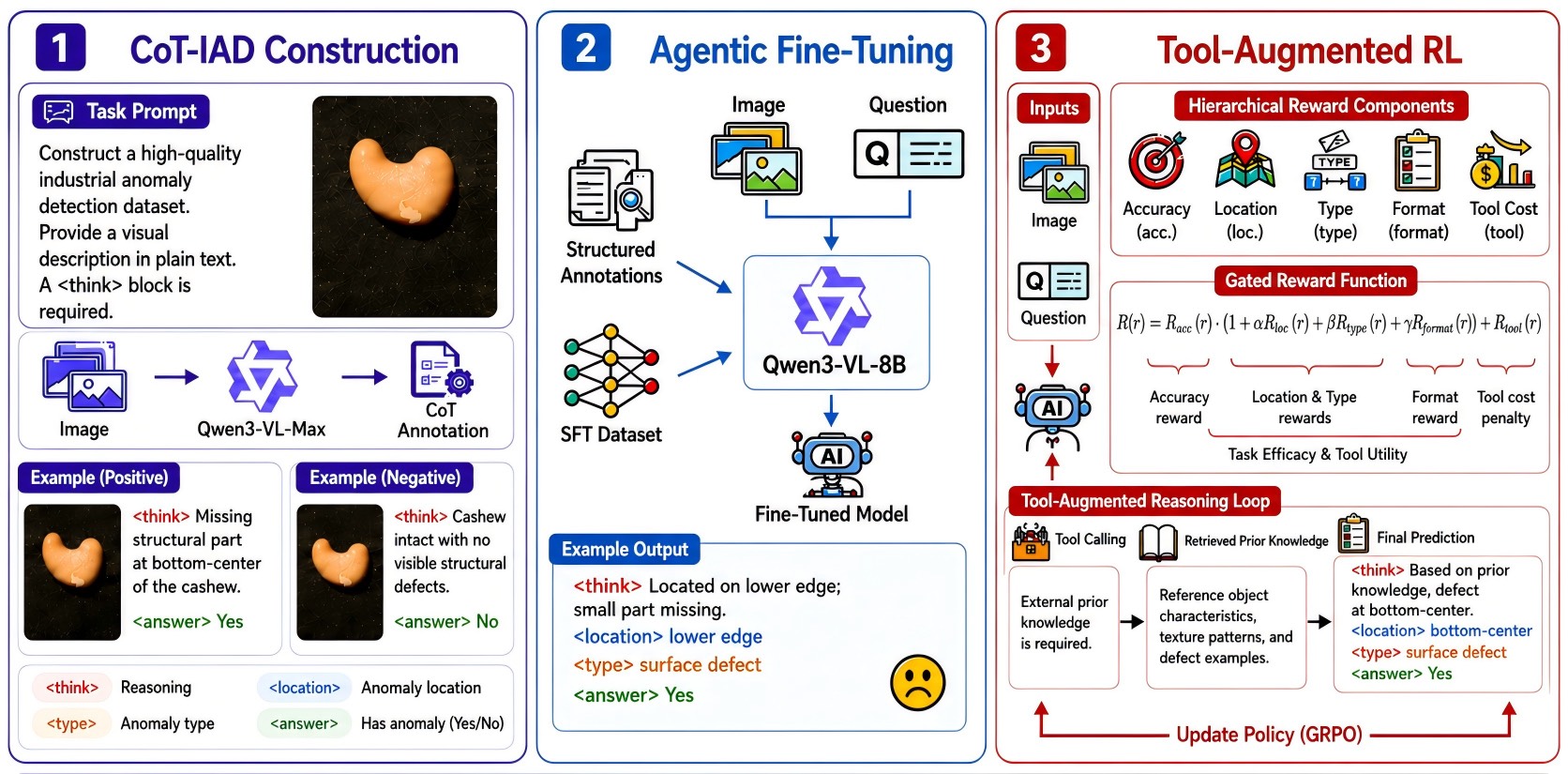
图 2:IndusAgent 整体训练流程分三阶段。第一阶段 CoT-IAD Construction:用 Qwen3-VL-Max 作为强教师模型,针对正常和异常样本,分别生成带 \<think>/\<location>/\<type>/\<answer> 四段式的结构化推理轨迹,构成 SFT 数据集。第二阶段 Agentic Fine-Tuning:用结构化标注 + 图像 + 问题,把 Qwen3-VL-8B 微调成能输出工业诊断协议的"基础 Agent"。第三阶段 Tool-Augmented RL:在 SFT 模型基础上引入分层奖励函数(Accuracy/Location/Type/Format/Tool Cost)和门控乘性奖励,通过 GRPO 更新策略,让 Agent 学会"什么时候该调工具、调哪个工具"。
后面的章节我们一个一个拆开讲,看这套设计的每个螺丝是怎么拧的。
三、四件工具:Agent 手里能用的"武器"
工具空间定义如下:
每件工具的设计动机都对应着前面提到的某一种 MLLM 失败模式:
| 工具 | 解决什么问题 | 怎么实现 |
|---|---|---|
| T_crop | 感知稀释——细微缺陷被全局编码淹没 | 从 Agent 给出的可疑区域裁出高分辨率块,作为下一轮观察的额外输入 |
| T_prior | 领域知识缺失——不知道"正常应该长啥样" | 检索缺陷无关的几何/纹理/结构正常先验,比如"PCB 应当具有规整焊盘"等文本描述 |
| T_enhance | 低对比度缺陷难以察觉 | CLAHE 对比度增强、边缘提取等轻量图像处理 |
| T_measure | 几何关系判断——位置/角度/比例是否符合规范 | 计算距离、角度、相对位置等几何量 |
值得说一下 T_crop 的实现方式——作者用的是无监督前景提取:背景估计 + 图像差分 + Otsu 阈值 + 形态学操作,最后用中心裁剪兜底。这是典型的"老派 CV + 新派 LLM"组合,不依赖任何额外的检测器或分割模型,工程上很省事。
整个 Agent 的统一推理形式可以写成:
其中 F 是来自工具的视觉反馈(裁剪图、增强图等),E 是文本反馈(先验描述、几何量等)。每一轮推理之后,Agent 决定继续调工具还是输出最终诊断。
四、Indus-CoT 数据集:3000 条精修的"工业 CoT"
光有架构没用,得让模型先学会怎么"按工业协议思考"。这就是 Indus-CoT 数据集的作用。
关键事实:从 Real-IAD 数据集采样,约 3000 条推理轨迹,正常和异常样本大致平衡。
3000 条这个数量其实蛮少的。这点很值得说说——SFT 数据量小但质量高,是这两年 R1-Zero 之后大家逐渐认可的范式。不是数据越多越好,是"对齐协议的数据"越干净越好。
数据生成是三阶段的:
Phase 1:全局感知与工具路由 教师模型(Qwen3-VL-Max)先看全图,识别"哪里可疑",输出路由指令:要不要调 Prior?要不要 Crop 哪个区域?
Phase 2:工具执行与上下文观察 - T_prior:从一个预构建的"工业知识库"里检索文本先验 - T_measure:算几何量 - T_enhance:跑 CLAHE 等滤波 - T_crop:用上面那套无监督前景提取
Phase 3:最终诊断验证 基于全局观察 + 工具反馈,交叉验证,输出 \<think>...\</think>\<location>...\</location>\<type>...\</type>\<answer>Yes/No\</answer>。
还有一个细节我觉得做得比较扎实——类别去重。作者明确剔除了与评测基准(DTD、MPDD、MVTec-AD、SDD、VisA)重叠的类别,比如 toothbrush、zipper、pcb、transistor1 等。这意味着训练集和测试集的物体类别完全不相交,是货真价实的零样本评估。
这点对我来说是一个加分项——很多号称"零样本"的工作,仔细看就会发现训练数据其实包含了测试类别,不算严格意义上的开放词汇。
五、训练流程:SFT 冷启动 + Tool-Augmented RL
5.1 为什么必须先 SFT?
直接上 RL 行不行?作者的回答是:不行,会有 reward hacking 和 format collapse。
我之前调过类似的方案,确实是这样——R1-Zero 类训练在简单数学/代码任务上 work,是因为奖励信号特别干净(答案对就是对)。但 IAD 这种任务,奖励信号本身就模糊("位置接近"、"类型相似"都是连续值),如果模型一开始连基本的输出格式都不会,RL 就会陷入混乱。
SFT 阶段的 loss 是标准的语言建模损失,但只对推理过程的 token 计算损失:
这个细节也挺关键——只算"agent 自己生成的部分"的损失,不算"工具反馈"的损失,避免模型去学"复读"工具的输出。
5.2 GRPO + Accuracy-Gated 奖励:核心创新点
这是整篇论文我觉得最有意思的部分。
先说 GRPO——DeepSeek 在 R1 里推广的一个 RL 算法,不需要独立的 value network,通过组内相对比较来估计优势:
简单说就是"同一个 prompt 采 G 条轨迹,谁的奖励高谁就被强化"。算力省、实现简单,是目前 LLM RL 训练的事实标准之一。
关键创新在奖励设计:
注意看这个公式——它不是简单的奖励加权和,而是 R_acc 作为乘性门控。
我第一次看到这个设计的时候愣了一下,因为它解决了一个我之前在 Agent RL 里很头疼的问题:奖励解耦带来的局部最优。
举个例子:如果你简单地把奖励写成 R_acc + α·R_tool,会发生什么?模型很快会发现"我多调几次工具,R_tool 就能涨",于是疯狂调工具,但最终诊断错得离谱。这就是 reward hacking。
而 Accuracy-Gated 的写法是:只有最终诊断对了,工具调用、定位、类型预测的奖励才计入。R_acc ∈ {0,1},如果分类错了,整个乘子项归零,剩下的只有 R_format。这个设计逼着 Agent 必须把"调对工具"和"答对问题"绑定起来,不能投机。
五个奖励组件分别是:
- R_acc ∈ {0,1}:异常分类二元正确性,作为门控
- R_loc:用 IoU 衡量定位质量
- R_type:异常类型预测的语义距离
- R_tool = λ·𝕀[Δ_conf > 0] - η|C|,其中 λ=0.3, η=0.1
- R_format:输出格式合规性
特别说说 R_tool 的设计——它是一个净收益项:
- 正项 λ·𝕀[Δ_conf > 0]:调工具如果让模型置信度提升了,给奖励
- 负项 -η|C|:每次调工具有固定成本
这是一个典型的"鼓励有用调用,惩罚无效调用"的设计。说实话比单纯的"调工具就给奖励"或"调工具就扣分"都要细致——后者要么会鼓励刷工具,要么会让模型干脆不调工具。
六、实验结果:到底打不打得过同期工作
6.1 主实验:5 个基准全部 SOTA
先看一张总览雷达图:

图 3:雷达图直观对比 IndusAgent(红)、Anomaly-OV(绿)、Qwen3-VL-8B 基线(蓝)。红色区域在 6 个维度(5 个基准 + 平均分)上全面覆盖前两者,说明 IndusAgent 的提升不是某一个数据集的偶然,而是全方位的。
下面看具体数字(核心数据,论文 Table 1):
| 类型 | 模型 | 参数量 | MVTec | MPDD | VisA | DTD | SDD | 平均 |
|---|---|---|---|---|---|---|---|---|
| 商用 | GPT-4o | / | 69.6 | 60.3 | 63.5 | 69.9 | 65.7 | 65.8 |
| 商用 | GPT-4.1 | / | 81.9 | 66.7 | 69.1 | 90.1 | 79.9 | 77.5 |
| 商用 | Claude-Sonnet-4 | / | 67.6 | 65.9 | 63.5 | 88.4 | 81.7 | 73.4 |
| 开源 | Qwen3-VL-Instruct | 8B | 67.0 | 50.0 | 46.8 | 70.2 | 50.0 | 56.8 |
| 开源 | AnomalyR1 | 3B | 69.4 | 56.0 | 59.8 | 61.0 | 57.6 | 60.7 |
| 开源 | Anomaly-OV | 7B | 74.3 | 70.3 | 74.3 | 90.7 | 88.7 | 79.6 |
| 开源 | Qwen2.5-VL-Instruct | 72B | 77.4 | 64.7 | 68.2 | 81.9 | 69.0 | 72.2 |
| 本文 | IndusAgent | 8B | 83.6 | 72.7 | 76.8 | 95.6 | 88.9 | 83.4 |
几个值得注意的点:
第一,相对基线 Qwen3-VL-8B 的提升是惊人的——从 56.8 涨到 83.4,平均提升 26.6 个百分点。这个幅度其实非常能打,因为基础模型完全一样(都是 Qwen3-VL-8B),区别只在于训练流程。
第二,超过了 72B 的 Qwen2.5-VL-Instruct——以 1/9 的参数量,多打了 11.2 个点。这个对比说明在 IAD 这种垂直领域,"领域适配 + 工具调用"比"扩参数"更划算。
第三,超过了 GPT-4.1——8B 开源模型超过商用闭源旗舰,平均高 5.9 个点。这点要稍微保留——GPT-4.1 是通用模型,没做工业领域微调,单纯比 zero-shot 能力对比有点不公平。但反过来,这也说明通用大模型在垂直工业场景下并没有想象中那么强,这跟我之前在客户现场看到的情况是吻合的。
我对这张表唯一不太满意的地方是:没给传统 IAD 方法(如 PatchCore、PaDiM、SimpleNet)的对比。这些方法在 MVTec-AD 上的 Image-AUROC 通常能到 99% 以上,虽然它们不是开放词汇的,但作为基准放在那儿对读者更有参考价值。
⚠️ 一个细节:原表中"最佳"高亮在某些数据集上(如 MPDD/VisA/DTD/SDD)标在 Anomaly-OV 7B 行,IndusAgent 行被标成"次佳"颜色。但仔细看数值,IndusAgent 在所有 5 个数据集上都比 Anomaly-OV 高。这看起来是论文表格高亮颜色映射有点小错误,按数值 IndusAgent 是全胜的。
6.2 异常召回率:更能反映真实价值
主实验的"综合分"其实是分类正确率为主的指标,而工业场景里,异常召回率(Recall)才是命门——漏检一个缺陷比误报一个正常品成本高得多。
| 模型 | DTD | MPDD | MVTec | SDD | VisA | 平均 |
|---|---|---|---|---|---|---|
| Qwen3-VL-8B | 75.1 | 62.3 | 68.9 | 64.2 | 58.7 | 65.8 |
| Claude-Sonnet-4 | 80.2 | 70.5 | 75.3 | 71.1 | 65.4 | 72.5 |
| IAD-R1 | 83.7 | 78.0 | 81.7 | 79.6 | 72.3 | 79.1 |
| IndusAgent | 94.1 | 95.4 | 85.5 | 83.3 | 73.4 | 86.3 |
(表中数值单位为 %,召回率)
MPDD 上从 IAD-R1 的 78.0% 涨到 95.4%,提了 17.4 个点。这个数字如果稳定,落到产线上是真的能省钱的。
但 VisA 上提升只有 1.1 个点(72.3 → 73.4),相对偏弱。我猜测原因是 VisA 包含很多电子元件类的细微缺陷,依赖更精密的视觉细节,而仅靠 8B 视觉编码器加 Crop 工具可能还是力有未逮——这块作者没展开分析,是个可以挖的方向。
6.3 消融实验:每个模块都不能少
表 3:核心模块消融
| 方法 | MVTec | VisA | DTD |
|---|---|---|---|
| (a) Qwen3-VL-8B 基线 | 67.0 | 46.8 | 70.2 |
| (b) IndusAgent 完整版 | 83.6 | 76.8 | 95.6 |
| (c) w/o RL(仅 SFT) | 72.3 | 57.6 | 74.1 |
| (d) w/o SFT | 69.5 | 55.5 | 72.8 |
| (e) w/o TOL(无工具增强) | 78.1 | 67.5 | 87.9 |
几个观察:
- w/o SFT 效果比 w/o RL 还糟(VisA:55.5 vs 57.6):印证了"先 SFT 冷启动再 RL"的必要性,单跑 RL 收敛不好
- 去掉工具增强(w/o TOL)后下降明显(VisA 76.8 → 67.5,降 9.3 个点):证明工具调用确实在贡献价值,不是装饰
- 完整版相对仅 SFT 提升 19.2 个点(VisA):RL 阶段的奖励塑造确实在做实事
表 4:分层门控奖励消融
| RL 奖励配置 | MVTec | VisA | DTD |
|---|---|---|---|
| (f) w/. Base(标准 RL,无门控) | 76.0 | 64.9 | 79.1 |
| (g) w/o Tool 奖励 | 81.9 | 71.5 | 92.8 |
| (h) w/o Loc 奖励 | 79.5 | 68.8 | 89.6 |
| (i) w/o Type 奖励 | 78.5 | 72.8 | 90.6 |
| (j) w/o Format 奖励 | 76.6 | 65.7 | 82.5 |
| 完整版 | 83.6 | 76.8 | 95.6 |
最值得说的是 (j) 行——移除 Format 奖励之后退化最明显(VisA 从 76.8 降到 65.7,降 11.1 个点)。这说明在 Agent 训练里,让模型保持稳定的输出协议比想象的更重要。Format 奖励看起来不起眼,但它实际上是在防止"模型推理着推理着就跑偏"——这跟我之前调 Agent 的经验完全一致。
(f) 行是最关键的对照——标准 RL(不用乘性门控)反而比仅 SFT 好不了多少(VisA 64.9 vs 57.6,仅+7.3 点)。而完整版的乘性门控带来的提升是 +19.2 点。门控设计才是 RL 阶段真正的发动机。
七、案例分析:Agent 真的"会用工具"吗?
光看数字不够带感,再看一个具体案例。

图 4:测试图是一根电缆截面,绿色绝缘层有破损暴露铜芯。Qwen3-VL-8B 直接给出"无明显缺陷"的回答,把破损归因为"切割工艺或反光"。IndusAgent(图中标 OVIAD-X)则在 Round 1 主动识别"绿色绝缘体存在局部断裂、铜丝外露,且与相邻蓝/棕导体的完整绝缘不一致",调用工具放大确认后,在 Round 2 给出结构化诊断:location=green-insulated conductor,type=insulation break,answer=Yes。
这个案例其实把"主动检查者范式"的价值讲清楚了——关键不是模型一次就能看对,而是模型会复盘自己的不确定,主动找证据。Qwen3-VL-8B 也观察到了"边缘不平整",但它选择了一个保守解释(切割工艺);IndusAgent 在多轮里把这个不确定挑出来,去核实,最终改变了结论。
这种行为模式是 RL 训出来的——SFT 只能让模型模仿"会查工具的样子",RL 才能让模型真的形成"不确定时去查工具"的策略。
八、几点真实的判断
聊到这里,说说我的看法。
这篇论文做对了什么:
-
奖励门控的设计是真的优雅。R_acc 作为乘性门控这一招,把"工具调用"和"最终正确性"绑定起来,避免了 Agent RL 里最常见的 reward hacking 问题。这个 trick 我觉得可以迁移到很多其他 Agent 任务上——比如代码 Agent 里把"测试通过"作为门控、检索 Agent 里把"答案准确"作为门控。
-
数据质量优于数据规模的实践。3000 条 CoT 数据,配合严格的类别去重,做到了真正的开放词汇评估。这跟 R1-Distill 的精神是一致的——少而精,远比多而粗有用。
-
工具集设计贴合人类质检员的真实工作流。Crop / Prior / Enhance / Measure 这四件,每一件都对应着人类质检员的一个动作,工程上也都好实现(不依赖任何额外大模型)。
这篇论文我有疑虑的地方:
-
没和传统 IAD 方法对比。PatchCore、CFA、SimpleNet 这些方法在 MVTec 上 Image-AUROC 已经能到 99%+。当然它们是 closed-set 的,但作为天花板基准,应该放上来。
-
VisA 上召回率提升只有 1.1 个点。论文没分析为什么。我猜是 VisA 上的小尺寸缺陷(如 PCB 上的引脚弯曲)依赖比 Crop 更精细的视觉机制,光放大可能也看不清——这是个真问题,下一步该往这里挖。
-
工具调用次数的成本没充分讨论。RL 期间一个 sample 平均调几次工具?训练一轮多少 GPU 时?工具调用引入的额外推理延迟是多少?这些工程数字论文给得太少,对想复现/落地的人不够友好。
-
OVIAD-X 这个名字在案例图里出现。我推测论文初稿里方法叫 OVIAD-X,后来改名成 IndusAgent,但有的图没替换干净。这种小细节看出论文打磨还没到位。
对工程同行的启发:
- 如果你也在做垂直领域的 Agent,Accuracy-Gated 奖励是一个值得直接抄的设计。你的"工具调用收益项"如果不和"最终任务正确性"绑定,模型就会刷工具调用次数。
- SFT 数据的去重很重要。很多人做 SFT 不去管和测试集的类别重叠,结果泛化能力被高估。
- Format 奖励别忽略。从消融实验看,它的贡献几乎和 RL 主奖励一样重要。Agent 输出协议保持稳定,是后续所有奖励能起作用的前提。
九、收尾
工业异常检测这个领域,过去十年大致是"PatchCore 时代"——封闭集、特征匹配、单产品训一个模型。MLLM 兴起后,大家都想做开放词汇,但一直没找到特别好的方案。
IndusAgent 这套"工业 CoT 数据 + 工具调用 Agent + 门控 RL"的组合拳,我觉得是目前我看到的相对完整的解。它不是革命,但它把每个工程环节都做扎实了——SFT 有冷启动协议、工具集贴合实际工作流、奖励设计避免了 reward hacking、评估做了严格的类别去重。
如果你现在在做相关项目,这篇论文我建议至少把第 4-5 节(Indus-CoT 构建 + RL 奖励设计)和消融实验仔细啃一遍。代码暂时没看到开源,等开源后值得复现一把。
更宏观一点说,我觉得这类"把垂直领域专家工作流写成工具调用 Agent + 用 RL 训调度策略"的范式,可能会成为 2026 年很多领域应用 LLM 的标配——不只是 IAD,医疗影像、代码审查、法律合规、设备故障诊断,哪个不是这套套路?
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我