把 Agent 的"技能"从文本提示升级成可执行护栏:HASP 框架到底解决了什么
arXiv: 2605.17734 | Harnessing LLM Agents with Skill Programs
写在前面
做过 Agent 的朋友大概都遇到过这种问题:你给模型一段精心设计的 system prompt,里面苦口婆心地写"在确认证据之前不要给出最终答案"、"避免重复搜索"、"复杂多跳问题要先拆解"——然后模型读完,点头表示理解,转头继续犯同样的错。
我之前调一个多跳问答 Agent,prompt 里"verify before finalize"那条加粗加重写了三遍,结果跑 MuSiQue 的时候,模型还是搜了一轮就 confidently 输出"FINAL: xxx",连 read 都懒得读。这种"我说了你不听"的感觉,做过 Agent 工程的人应该都很熟悉。
问题出在哪?说到底,文本指令只是建议。它告诉模型"应该这样做",但既不规定什么时候应该这样做,也不强制怎么改下一步动作。模型自己决定理不理你,多数时候它就是不理。
这篇论文的切入点很直接:既然文本管不住,那就把技能改成可执行的程序,让它在 Agent 的 reasoning loop 里直接拦下错误动作并改写。HASP 这个名字也很实在——Harnessing,套上缰绳。
核心摘要
痛点:现有 Agent 系统把"经验技能"塞进 prompt(Reflexion、Skill 系列工作都是这套路),但文本提示本质是 advisory,缺乏触发条件和介入机制。论文统计了 recovered case,37–43% 的可恢复失败属于实体混淆,29–33% 是探索不足——这些都是结构化、可复用的失败模式,被一句文本提示挡不住。
方案:把每个技能写成一个 Program Function(PF),强制包含两个接口:should_activate() 决定何时触发,intervene() 决定如何修改下一步动作或注入纠错上下文。Agent 在 ReAct loop 的每一步都先让基础策略提议动作,再把这个 (state, action) 喂给 PF 库做触发判定,命中就改写动作、注入提示。这套 harness 在三个维度都能用:推理时直接介入、后训练时提供结构化监督信号、自我演化时把残余失败提炼成新 PF 入库。
效果:在 Qwen2.5-7B-Instruct 上,纯推理时 PF 介入把 web-search 平均准确率从 ReAct 的 31.2% 拉到 51.0%;加教师选择再到 56.2%;后训练 + 闭环演化(HASP-Evolve + RS)拉到 60.3%,math 到 45.4%,coding pass@1 到 69.9%。相对 Search-R1 在 web-search 上有 30.4 个点的绝对提升。
我的判断:思路漂亮,工程可落地。最有价值的不是"又一个 7B 刷榜方案",而是它把 skill 这个概念从"prompt 工程的一种花式"硬生生拉回到了"可审计、可复用、可演化的策略外挂"——这件事本身比具体数字更值钱。但论文里有一些细节让我皱眉,下面具体聊。
论文信息
- 标题:Harnessing LLM Agents with Skill Programs
- 作者:Hongjun Liu、Yifei Ming、Shafiq Joty、Chen Zhao
- arXiv:2605.17734
- 时间:2026 年 5 月 18 日
- 篇幅:40 页,7 张图,目标 NeurIPS 2026
一、为什么文本技能撑不住
先聊一下 skill memory 这条线最近的演进。
最早是 Reflexion:让 Agent 失败之后写一段反思塞回 prompt,下次再来一遍。后来 ExpeL、Skill-0 这些工作把"反思"做成了一个外部库,按 query 去检索相关经验。本质都是用自然语言描述失败模式 + 修复建议,然后期待模型读完之后自觉改正。
这套思路有三个绕不开的硬伤,论文 Figure 1 左边把这三点画得挺清楚:
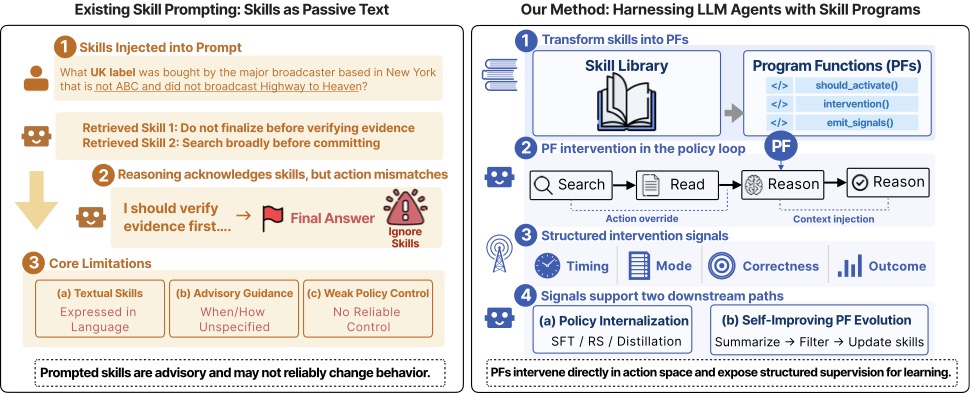
图1:左侧展示典型失败——技能被注入 prompt,模型嘴上承认"我应该先验证证据",转头照样输出 Final Answer,技能被忽略;右侧是 HASP 的方案,技能被编译成带 should_activate / intervention / emit_signals 三个接口的 PF,在 policy loop 内直接干预动作或注入上下文。
看完这张图我的第一反应是:问题诊断得很准。
Textual Skills 的三个问题——"语言表达"、"何时启动不明"、"无可靠策略控制"——任何一条单拎出来都够命。我自己印象最深的是第二条:你 prompt 里写"对于多跳问题先拆解",可是模型自己根本判断不准这道题是不是多跳。MuSiQue 里有些题表面看像单跳,实际要绕三道弯,模型一个不留神就直接 Final 了。
HASP 的破法是把判定权从模型手里收回来。should_activate() 是一个明确的函数,它可以是规则("action_type == Search and len(query.split()) > 15 → 触发 retrieval_failure"),也可以是更复杂的判定。一旦触发,intervene() 直接改写动作或注入上下文,模型没有不听的选项,因为下一步执行的根本就不是它原来提议的那个 action。
这里有一句话我觉得是这篇论文的精神内核:把 skill 从"被动建议"升级成"可执行护栏"(executable guardrails)。 Guardrails 这个词用得很贴切——你不要求模型理解、不期待模型自觉,你直接在它和环境之间夹一层硬控制。
二、HASP 框架长什么样
整个框架的全貌在 Figure 2,看着信息量大,其实拆开就三件事:
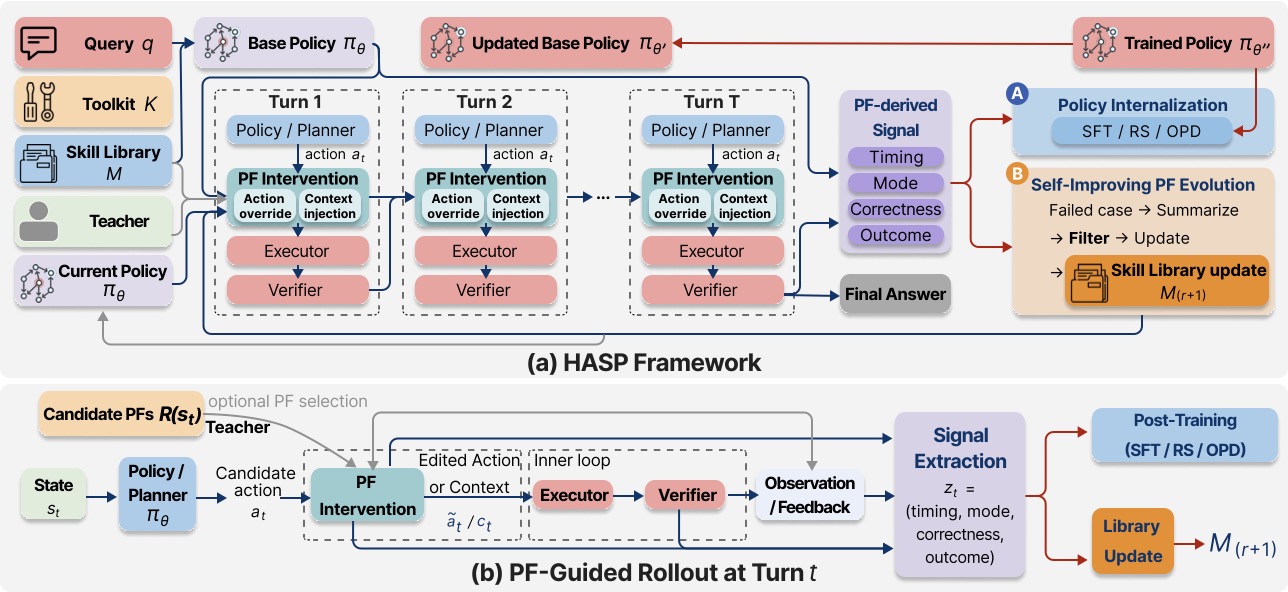
图2:(a) HASP 框架全景。Query / Toolkit / Skill Library / Teacher 共同输入到一个多轮 ReAct loop,每一轮里 Policy 先提议 action,PF Intervention 模块决定是否做 Action override 或 Context injection,Executor 执行后由 Verifier 验证。每一步都向外吐出 PF-derived Signal(Timing / Mode / Correctness / Outcome)。这些信号一路喂给 Policy Internalization(A:SFT/RS/OPD)做后训练,另一路喂给 Self-Improving PF Evolution(B:把 failed case 总结、过滤、入库)。(b) 单步细节:State \(s_t\) → Policy 提议 \(a_t\) → 候选 PF 集合 \(\mathcal{R}(s_t)\)(可选教师选择)→ PF Intervention 给出 \((\tilde a_t, c_t)\) → 执行 → 提取信号。
形式化一下。基础策略 \(\pi_\theta\) 给定状态 \(s_t\) 提议动作 \(a_t^{\mathrm{orig}}\),harness 拿着 skill 库 \(\mathcal{M}\) 检索出候选 PF 集合 \(\mathcal{R}(s_t) \subseteq \mathcal{M}\),每个 PF 跑一遍 should_activate(s_t, a_t),命中的 PF 通过介入算子 \(\Gamma\) 输出最终动作:
其中 \(\tilde a_t\) 是改写后的动作,\(c_t\) 是注入的纠错上下文,\(\kappa_t\) 是元数据(哪些 PF 触发了、用什么模式)。如果没有 PF 触发,\(\tilde a_t = a_t^{\mathrm{orig}}\)。
介入只有两种基本模式:
- Action Override:直接改下一步动作。最典型的例子是把过长的 query 重写——
retrieval_failure检测到 query 词数 > 15 就触发,把 16 词的搜索串改写成 9 词的精简版。 - Context Injection:往 reasoning 流里塞一段提示。比如
decompose_complex_question触发后注入"[DECOMPOSITION HINT] This is a multi-hop question. Search for each piece of information separately."
论文统计在 web-search 任务上 65.1% 的触发是 action-level,34.9% 是 context-level——改动作比补提示更频繁。这点跟我直觉一致:动作错了改动作最直接,光加段文字祈祷模型领悟,效率太低。
Skill 库怎么来的
初始 PF 库不是手写的,是从训练池里挖出来的。流程是:
- 用 base agent 跑训练池,收集失败 trajectory;
- 用 LLM(应该是 GPT-4o,论文没明说但实验用的就是它当 teacher)把失败聚类成可恢复模式(premature finalization、entity confusion、insufficient exploration 等);
- 每个模式生成一个候选 PF,必须明确写
should_activate和intervene两段代码; - 候选 PF 过三道关:syntax 检查、interface 验证、mock execution,全过才入库。
这个验证流程其实是关键。后面的消融会看到,没有过滤的演化基本会把库搞烂——加几轮就崩,准确率掉到 36.3%。
三、三个使用场景:推理 / 后训练 / 自我演化
HASP 的模块化体现在同一个 PF 接口可以被三种方式消费。
场景 1:推理时直接介入(最便宜)
这个最简单:你的模型不动,挂个 harness 在 ReAct loop 外面就行。每步 PF 检查一下,命中就改。完全不需要训练。
PF-only 的设定甚至不要 teacher,PF 自己根据 should_activate 触发。加上 teacher 做 PF 选择(多个 PF 同时命中时挑一个)能再涨几个点。
场景 2:后训练把 PF 内化(更彻底)
每次 PF 触发都会留下一条结构化记录:
包含触发状态、原动作、修复后动作、注入上下文、元数据、下游反馈。这些记录被打 4 个分(Timing / Mode / Correctness / Outcome):
权重 \((\lambda_t, \lambda_m, \lambda_q, \lambda_o) = (0.15, 0.10, 0.25, 0.50)\)——Outcome 占一半,Correctness 占四分之一,触发时机和模式权重最低。这个权重设计挺有意思,下游效果还是主导。
四个信号怎么用?三种训练方式:
| 训练方式 | 损失 | 直觉 |
|---|---|---|
| SFT | \(\mathcal{L}_{\mathrm{SFT}}=-\sum_t w_t \log\pi_\theta(\tilde a_t \mid s_t)\) | 直接学 PF 修正后的局部动作,权重由 \(A_t\) 决定 |
| RS(拒绝采样) | 按 \(\mathrm{Score}(\tau)=\beta_1 \mathrm{TaskSuccess} + \beta_2 A(\tau)\) 选 top trajectory,再 SFT | 选最终对 + PF 中间评分高的轨迹喂给学生 |
| OPD(on-policy distillation) | 让 student 自己 rollout,PF 在易错点介入,学生学纠正后行为 | 训练分布对齐 inference 分布,但更不稳定 |
主推荐路线是 HASP-Evolve + RS,因为 RS 在演化的 skill 库下最稳。
场景 3:闭环演化(最贪)
每隔固定训练轮次,HASP 用当前 checkpoint 重跑训练池,收集仍然失败的 case,提炼新候选 PF,过两道质量门:
- \(Q_{\mathrm{exec}}(c) \ge \eta_{\mathrm{exec}}\):可执行性(语法、接口、mock 执行、返回类型)
- \(Q_{\mathrm{teach}}(c) \ge \eta_{\mathrm{teach}}\):教师审核(是否捕捉了可复用模式、是否在合理条件下触发、修复是否有用)
两道门都过的才进库。这个双重过滤后面被消融实验证明是命脉——掉任何一个,库都要烂。
四、实验数据:这个方法到底有多能打
来看主表。Qwen2.5-7B-Instruct 当 backbone,web-search 三个 benchmark + math 三个 benchmark:
Web-search reasoning(HotpotQA / 2Wiki / MuSiQue)
| 方法 | Avg | 备注 |
|---|---|---|
| GPT-4o (~200B) | 42.5 | 大模型 closed-source 参考 |
| Qwen2.5-7B-Instruct(裸) | 16.7 | 7B 起点 |
| RA-Agent(multi-loop) | 31.2 | 多轮 ReAct baseline |
| Prompt-Only Skills | 20.5 | 文本技能注入 prompt |
| AutoGen | 36.6 | 工程化 Agent 框架 |
| Search-R1(训练) | 29.9 | 检索增强 RL |
| ZeroSearch | 29.3 | RL 训练 |
| AgentFlow + Flow-GRPO | 53.2 | 当前最强 baseline |
| HASP-Intervention(PF-only) | 51.0 | 不训练,挂个 harness 就涨 19.8 点 |
| HASP-Intervention(w. Teacher) | 56.2 | 加教师选 PF |
| HASP-Evolve + RS | 60.3 | 训练 + 演化,最强变体 |
几个数让我愣了一下。
51.0% vs 31.2%——纯推理时介入涨了 19.8 个点。这个幅度在 web-search 上算炸裂级别。Prompt-Only Skills 同样的技能内容只涨到 20.5%(更差,因为塞 prompt 反而稀释了上下文),可见问题真的不在"有没有 skill"这件事,而在"skill 能不能落地"这件事。
56.2% 比 GPT-4o 的 42.5% 还高。一个 7B + harness 把 200B 级别的 closed model 打了 14 个点。当然,这里 harness 调用了 teacher(GPT-4o 本身),所以严格说不是纯 7B vs 200B 的对比。但 PF-only 不带 teacher 的 51.0% 也已经远超 GPT-4o 的 42.5%——架构红利是真实存在的。
60.3% 把 AgentFlow 的 53.2% 拉开 7.1 个点。AgentFlow 是当前 search Agent 的强 baseline,HASP-Evolve + RS 在不依赖 RL 的情况下把它甩开,说明结构化的 PF 监督信号比纯 outcome reward 更高效。
但要客观一点:
- HotpotQA 上 HASP(69.0)比 AgentFlow(57.0)涨 12 个点,但 2Wiki 上 AgentFlow 是 77.2,HASP-Evolve 是 74.0——AgentFlow 在 2Wiki 上更强。
- MuSiQue 上 HASP 大幅领先(38.0 vs 25.3),印证了论文里说"难度越高 PF 触发越频繁"的观察。
- 这不是全面碾压,是特定难度上的优势。论文这点写得很坦诚,没有夸大。
Mathematical reasoning(AIME24 / AMC23 / GameOf24)
| 方法 | Avg |
|---|---|
| RA-Agent | 34.2 |
| Prompt-Only Skills | 32.8 |
| AgentFlow + Flow-GRPO | 51.5 |
| HASP-Intervention (Infer.) | 38.8 |
| HASP-Evolve + RS | 45.4 |
数学这边 HASP 不是最强,AgentFlow 比它高 6.1 个点。论文也直接承认了"remains competitive with stronger reasoning-specialized methods on math"。
我的解读:数学推理的失败模式更难抽象成 PF。web-search 里"query 太长就重写"、"过早 Final 就再搜一轮"这种模式很明确,PF 容易写。但数学题的失败是连续的推导链断裂,很难定位到一个明确的 trigger state,所以 PF 介入的边际收益就小了。
Coding(HumanEval / MBPP / BigCodeBench)
平均 pass@1:
- Vanilla SFT:57.5
- HASP-Intervention (PF-only):63.4
- HASP-Intervention (w. Teacher):68.7
- HASP-Evolve + RS:69.9
- GRPO(强 baseline):69.5
- KodCode-RL:70.1
Coding 上 HASP-Evolve + RS 跟 GRPO、KodCode-RL 基本平手。这块我觉得 HASP 的优势没那么大——coding 任务比 search 更"自包含",PF 介入的空间也更小。
五、消融:哪些设计真的不能删
这里是论文最干货的部分,也是我最想让大家细看的地方。
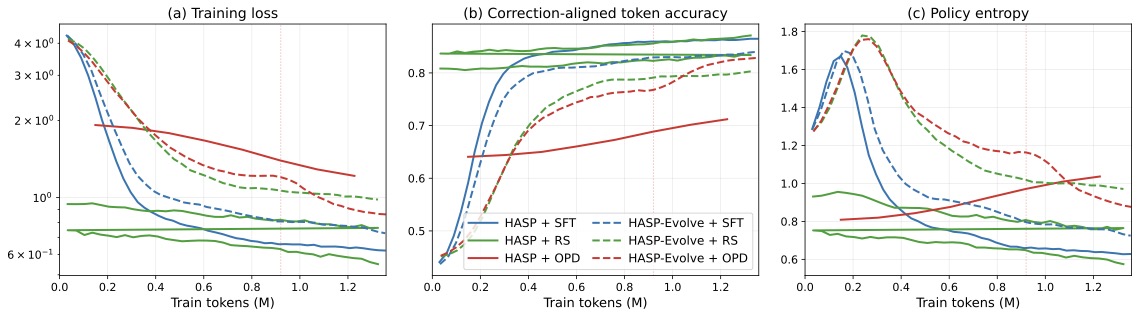
图3:(a) Training loss 曲线显示 SFT 下降最快最稳,OPD 最慢且 Evolve + OPD 出现波动;(b) Correction-aligned token accuracy 上 SFT/RS 都能爬到 0.85+,OPD 较慢且 Evolve + OPD 后期反而下降,跟它在 web-search 上掉到 56.7% 的现象一致;(c) Policy entropy 上 RS 维持低熵(说明在选确定性高的轨迹),OPD 早期熵冲到 1.7+ 表明策略大幅波动。
消融 1:信号缺哪个最致命
主信号四件套 Timing / Mode / Correctness / Outcome 都在 HASP-Evolve + RS(60.3)的基础上去掉一个,看掉多少:
| 去掉信号 | Avg | \(\Delta\) |
|---|---|---|
| 全保留 | 60.3 | -- |
| w/o Timing | 52.5 | -7.8 |
| w/o Mode | 44.8 | 掉 15.5 个点 |
| w/o Correctness | 48.2 | -12.1 |
| w/o Outcome | 47.5 | -12.8 |
最关键的居然是 Mode(PF 介入是 action-override 还是 context-injection),不是 Outcome。掉一个 Mode 比掉 Outcome 还狠 2.7 个点。
这个发现挺反直觉的。我本来以为 Outcome(最终对没对)会是最重要的信号,毕竟权重 \(\lambda_o = 0.5\)。但消融告诉你:知道"这一步 PF 是改动作还是补提示"对学生模型最重要。
我的猜测:Mode 信号实际上把每个 PF 的"工作方式"暴露给了训练,学生不仅学纠正后的动作,还学到了"在这种 state 下应该走 action 还是 context"——这是一种更结构化的归纳偏置。
消融 2:演化过滤——这个数让我皱眉了
| 演化策略 | Avg | \(\Delta\) |
|---|---|---|
| 全过滤(Exec + Teacher) | 60.3 | -- |
| 不演化(fixed library) | 59.3 | -1.0 |
| 演化 + 不过滤 | 36.3 | 掉 24.0 个点 |
| 演化 + 仅 Exec 过滤 | 48.8 | -11.5 |
| 演化 + 仅 Teacher 过滤 | 47.2 | -13.1 |
看到 36.3 这个数我愣了三秒。演化但不过滤,比 fixed-library 都低 23 个点。
这件事的工程意义太大了。它说明:所谓"自动从失败中演化技能"这个听起来很酷的能力,如果没有强过滤,就是反向优化这件事。系统会把奇奇怪怪的边缘 case 提炼成 PF 入库,污染检索,把好的 PF 也连累。
这也回应了过去几年 self-improving Agent 那一波研究的根本性怀疑:self-improvement 不是真的"自动",它需要外部 quality control 才能工作。HASP 的双重过滤其实就是把这个隐藏成本显式化:你要演化,就要付出 teacher review 的代价。
消融 3:技能内化哪些更容易
论文做了一个很细的分析:训练后哪些 PF 不再触发了?这反映了哪些技能被模型真正内化。
multi_hop_reasoning_failure和retrieval_failure:训练后 100% 不再触发——完全内化insufficient_exploration:30–37% 不再触发——部分内化decompose_complex_question:3–12% 不再触发——几乎没内化
这个分布告诉你一个很 fundamental 的东西:纠正"模型自己的坏习惯"的 PF 容易内化(query 太长、读得太少这种),纠正"任务结构"的 PF 难内化(多跳拆解这种)。后者依赖输入结构,模型不可能光靠后训练学会。
也就是说,永远会有一类 PF 必须留在外部 harness 里在线提供。这是个稳态结论。
六、Case study:一个真实的失败如何被救回来
光看数字没感觉,看一个具体例子最直观。
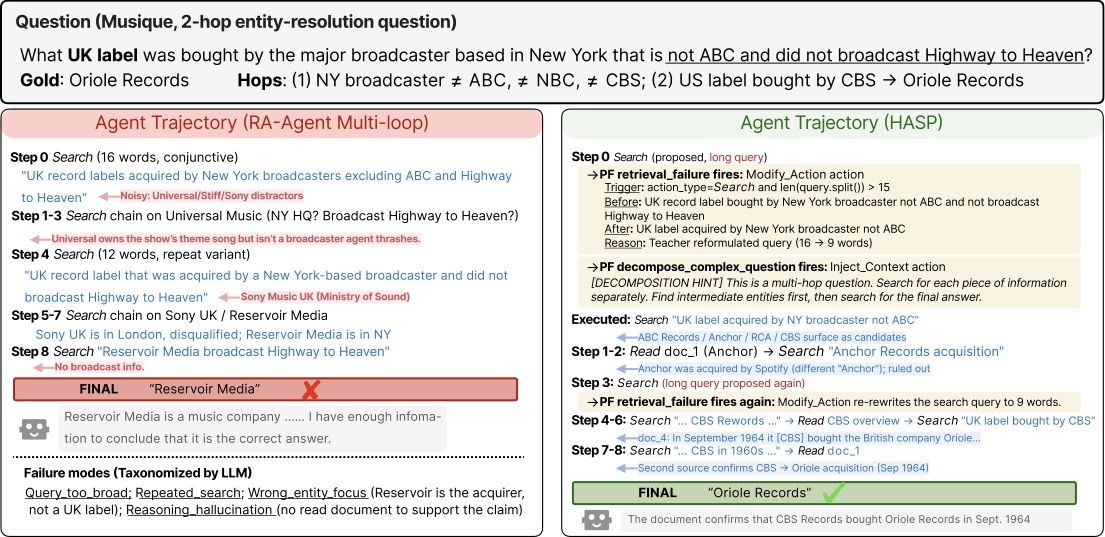
图4:题目"What UK label was bought by the major broadcaster based in New York that is not ABC and did not broadcast Highway to Heaven?" Gold answer 是 Oriole Records。左侧 RA-Agent baseline:第 0 步用了 16 词的复杂联合查询,被 Universal/Stiff/Sony 等噪声 distractor 带偏;1–3 步在 Universal Music 死磕;4 步换变体仍然 12 词;5–7 步又跑到 Sony UK / Reservoir Media;最后 Final "Reservoir Media" 错。失败模式被标记为 query_too_broad / repeated_search / wrong_entity_focus / reasoning_hallucination。右侧 HASP:第 0 步同样提议了 16 词长 query,但 retrieval_failure 立刻触发(trigger: action_type=Search and len(query.split()) > 15),把 query 改写成 9 词;同时 decompose_complex_question 注入分解提示;接着模型按"先找 NY broadcaster ≠ ABC → 再找该 broadcaster 收购的 UK label"的两跳结构搜,第 4–6 步定位到 CBS,第 7–8 步找到 CBS 1964 年收购 Oriole Records,Final 答对。
这张图我看了两遍,第二遍才注意到一个细节:HASP 第 3 步的时候模型自己又写了一个 long query,retrieval_failure 又触发了一次,再次重写。这就是可执行护栏的精髓——不是"提醒一次模型就改",而是每一步都强制检查,错了就改。文本 prompt 做不到这件事,因为 prompt 是一次性的,护栏是状态触发的。
另外左边 baseline 的失败被作者打上了 4 个 tag(query_too_broad / repeated_search / wrong_entity_focus / reasoning_hallucination),这本身就是 HASP 整个 pipeline 的起点:所有 PF 都是从这种失败 taxonomy 里蒸馏出来的。整个系统是个闭环。
七、几个让我皱眉的地方
不能光夸,这篇论文也有几个让我有点不舒服的点:
1. Teacher 用的就是 GPT-4o
PF-only setting 不依赖 teacher 是干净的。但一旦切到 with-teacher、HASP-Evolve、OPD(teacher trajectory),都在用 GPT-4o。这意味着 56.2%、60.3% 这些数字背后是GPT-4o 在做隐性蒸馏。论文也没回避这点,但读者要清楚:HASP 的部分增益来自"7B 在结构化框架下使用 GPT-4o 信号的效率",不是纯 7B 的能力。
2. 初始 skill 库是怎么生成的,论文写得不够细
"从训练池里收集 recovered failure case,summarize 成 PF" 这一步在主文里就一两句话带过,附录我没细看,但这个步骤应该是 cost 大头。如果初始库的 PF 写得不好,整个系统就垮了。这块的可复现性可能比想象中难。
3. Math 上的优势确实弱
45.4% 跟 AgentFlow 的 51.5% 差 6 个点,论文里轻描淡写过了。我觉得应该承认得更明确:HASP 的设计偏好"动作空间离散、失败模式可定位"的任务。Web-search 是它的 sweet spot,math 不是。
4. PF 数量没说
文中只提到几个 PF 名字(decompose_complex_question、retrieval_failure、insufficient_exploration 等),但 web-search 上具体用了多少个 PF?10 个?50 个?这个数字直接影响检索开销和工程可行性。我在主文里没找到(可能在附录),是个不大不小的遗憾。
5. Inference 开销没量化
每一步都要检索 PF + 跑 should_activate + intervene,这个 overhead 多大?延迟翻几倍?论文几乎没讲。对于工程团队这是关键问题。
八、它跟同期工作处于什么位置
skill memory 这条线最近一年的代表工作:
- Reflexion(2023):经典文本反思
- ExpeL(2024):经验池 + 检索
- Skill-0(2026):in-context agentic RL with skills
- AgentFlow + Flow-GRPO(2026):当前 search agent SOTA
- Search-R1 / VerlTool / ReSearch:检索增强 RL
HASP 跟前几个的核心差别是把 skill 从语言移到了代码空间。这件事其他工作并不是没人想过——should_activate 这种判定函数在传统软件工程里就是 contract programming——但把它塞进 LLM Agent 的 ReAct loop 并配套 4 信号训练 + 双过滤演化,这套完整体系是新的。
跟 AgentFlow 比,AgentFlow 走的是 "训练一个 flow controller" 的路子,HASP 走的是 "外挂一组确定性 guardrails"。两者其实可以叠加,论文没做这个实验,我猜如果 AgentFlow + HASP-Intervention 一起用,应该还能再涨。
跟 Search-R1 比,HASP 在 web-search 上把它甩开 30 个点,但 Search-R1 是 base 模型 RL,不依赖 teacher。所以严格说不是公平对比,但 HASP 的工程性显然更强——你不需要 RL infra 就能在推理时拿到 51% 的提升。
九、对工程的启发
如果你也在做 Agent,这篇论文里最值得抄的几个点:
1. 别把所有逻辑都塞 prompt
如果你的 Agent 老在重复同样的错误,与其加大 prompt,不如把判定写成代码挂在 loop 外。if action.is_search and len(query.split()) > 15: rewrite_query() 这种规则,比 "请使用简洁的搜索查询" 这种 prompt 强一万倍。
2. 介入要 audit-able
每次 PF 触发都留一条记录(state、原动作、改写后动作、原因),这件事即使不做训练也很有价值——它是你的 Agent 调试日志。HASP 的四信号 (timing, mode, correctness, outcome) 也是一个不错的日志 schema,可以直接抄。
3. self-improvement 必须有质量门
如果你想做"Agent 自动从失败中学习",请记住:没有 strict filtering 的演化是反向优化。要么有 teacher review,要么有可执行验证,最好两个都有。无脑演化 = 库污染。
4. 区分行为型 PF 和任务型 PF
行为型(retrieval_failure、multi_hop_reasoning_failure)可以通过后训练内化。任务型(decompose_complex_question)训练学不会,必须留在外部。做 Agent 系统设计时就要把这两类技能分开管理——一类是"训练目标",另一类是"永久外挂"。
十、收尾
这篇论文我读完最大的感受是:有些 idea 不需要花哨的算法创新,需要的是把一个被忽视的工程问题用一种合适的抽象解决。
skill 这个概念被滥用太久了。"给 prompt 加几条 best practice" 也敢叫 skill memory,"让 GPT-4 写一段反思"也叫 self-improvement。HASP 没创造新概念,它做的是给"skill"这个词重新画了一条更高的及格线——能可执行、能精确触发、能被 audit、能被结构化训练、能被过滤演化。达不到这五条的,可能都不该叫 skill。
这种工作我向来很喜欢。它不是黑魔法、也不是"在某 benchmark 涨了几个点"那种增量灌水,它是对一个领域基本词汇的重新定义。后续我猜 skill memory 这条线如果还要往前走,至少都得过 HASP 这道坎——你的 skill 总得能执行吧?总得能审计吧?
至于 60.3% 这个数能撑多久,不重要。重要的是这套抽象会留下来。
我打算下周在自己的 search Agent 上试一下 PF-only 的简化版。不做训练,就把 4 个最常见的失败模式(query 太长、过早 finalize、漏读、重复搜索)写成 4 个 PF 挂在 ReAct loop 外面,看看在自己的 case 上能不能复现 19 点的提升。如果能复现,这套思路就值得作为基础设施沉淀下来。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我