HAGE:让 Agent 的记忆图自己学会该走哪条边
论文:HAGE: Harnessing Agentic Memory via RL-Driven Weighted Graph Evolution 作者:Dongming Jiang, Yi Li, Guanpeng Li, Qiannan Li, Bingzhe Li 机构:UT Dallas / University of Florida / UC Davis 链接:https://arxiv.org/abs/2605.09942 代码:https://github.com/FredJiang0324/HAGE_MVPReview
一句话判断
把 Agent 记忆从"向量库 + 静态图"升级成"加权多关系图 + RL 学出来的路由策略"。在 LoCoMo 上从最强 baseline 的 0.700 涨到 0.739,HotpotQA 上 F1 从 0.640 涨到 0.678。思路不算颠覆,但它把"图边权可训"和"路由网络可训"这两件事真的放进同一个 REINFORCE 目标里联合优化,这一步是有意思的。
一个真实的痛点
做过长程 Agent 的人都遇到过这种情况。
跟 Agent 聊了几十轮,它的记忆系统在干一件事:把对话切片、算 embedding、扔进向量库,需要回忆的时候 cosine 取 top-K。能跑,但不太对劲。
你问它:"上个月那次出差,我为什么改签的航班?"
向量库做的事是:拿这句 query 去匹配最像的片段。它大概率会找到"出差"、"航班"、"改签"这些关键词附近的对话。但真正的原因可能是三周前的某次闲聊里随口提了一句"客户那边把会议挪到周四了"。这条因果链,纯语义相似度永远连不起来。
更糟的是,就算你认真搭了知识图谱,把记忆做成节点和边——那些边的权重通常是 1(连了)或 0(没连)。或者是个人工拍的分数。它不知道:
对于"为什么"这种问题,因果边比时间边重要得多。 对于"什么时候"这种问题,时间边才是主路。 对于"和谁一起"这种问题,实体共指边权重应该被拉满。
而现有图记忆系统在所有 query 上用同一套边权遍历。这就像不管你问什么,地图都按"距离最近"给你导航——可你要的是不堵车的路。
HAGE 想解决的就是这个:让边权变成可学的、让走哪条边的策略变成 query 相关的、让下游任务的对错能反过来更新这张图。
这篇论文具体在做什么
先看一张总览图,建立直觉。
图1:记忆增强生成的高层架构。Agent 每一步要做的事是:从记忆里检索证据、生成回答、再把新的事件写回记忆。重点是这个写回是持续的,记忆状态 M 会随时间一直变。
这张图本身没什么新东西,它只是在交代背景:长程 Agent 的记忆不是静态文档库,而是一个在不断更新的状态。
真正的核心在 Figure 2。
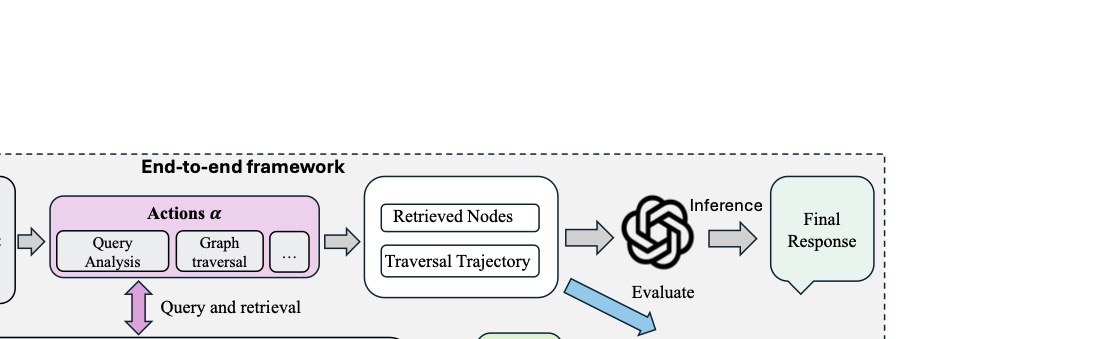
图2:HAGE 的两个核心组件。左边是加权多关系记忆图,每条边带一个可训练的特征向量,编码时间、语义、因果、实体四种关系信号。右边是 RL 训练框架,把图遍历建成 MDP,REINFORCE 同时更新路由网络的权重和边的特征向量。
把这张图拆开看,HAGE 干的事情可以分成三层。
第一层:图怎么建。 记忆被组织成有向多重图 \(\mathcal{G}_t = (\mathcal{N}_t, \mathcal{E}_t)\)。边集拆成四种关系类型:
时间、语义、因果、实体共指。每个节点是个 Event-Node,存事件内容、时间戳、稠密向量、结构化元数据。这部分跟其他图记忆方案区别不大。
关键差异在每条边带什么。 在 HAGE 里,边 \((i,j)\) 关联一个可训练的关系特征向量 \(\mathbf{e}_{ij} \in \mathbb{R}^4\),维度对应四种关系信号。冷启动的时候,这个向量初始化为 LLM 给四种关系打的分:
如果没有 LLM 打分,就用 one-hot 表示主关系。然后这个向量进入训练,被 RL 更新。
第二层:检索怎么走。 给定 query \(q\),先做四步:query 分析、锚点识别、加权遍历、上下文合成。
最有意思的是加权遍历。LLM 分类器先识别 query 的关系意图 \(T_q\)(这是个"时间问题"还是"因果问题"),拿到对应的稠密 embedding \(\mathbf{v}_{T_q}\)。然后对每条边把静态特征和运行时特征拼起来:
丢进一个轻量 MLP(QueryRouter),输出一个正的结构权重 \(w_{ij}(q)\)。最终的转移分是语义相似度和结构权重的加性组合:
这个加性而不是乘性的形式很有讲究。它的意思是:一条边即使指向的节点跟 query 在语义上不像,只要结构权重够高,照样可以被选中。这正是图遍历需要的——很多关键证据要通过"桥节点"才能到达,桥节点本身可能跟 query 八竿子打不着。
走下一步的策略是 softmax:
训练时按概率采样做探索,推理时贪心或 beam search。跳数上限到了,或者证据找全了,就停。
第三层:怎么训。 把图遍历建模成 MDP。
状态是 当前节点 + query embedding + 已访问 mask。动作是按 \(\pi_\theta\) 选下一个邻居。奖励长这样:
走到目标证据节点给正奖励 \(r_t^{hit}\),每多走一步扣一点 \(r_t^{step}\),超过跳数预算再罚一次 \(r_t^{timeout}\)。多跳问题里,每找到一个新的目标证据都加一次 hit。
训练用最朴素的 REINFORCE 加 EMA baseline 降方差:
可训参数 \(\theta\) 里同时包含 QueryRouter 的权重和图上每条边的特征向量。这是 HAGE 的关键设计。路由网络学怎么用边特征,边特征学该编码什么信号,两者在同一个 reward 信号下一起演化。
但联合优化有个隐藏问题。边特征是从 Phase 1(LLM 打分)热启动的,如果没约束,REINFORCE 会把它推到很远的地方。问题是:训练时用的图边特征是飘过的,推理时换一个新对话样本,边特征又是从 Phase 1 重新打分的——分布对不上,泛化就崩了。
作者的解法是加 L2 anchor 正则:
把训练中的边特征锚定在初始值附近,允许微调但不允许漂走。这一步看起来朴素,但其实是让方法能泛化到没见过的图的关键。
再加一个小技巧:非对称学习率。路由网络用 \(\eta_{router} = 10^{-3}\),边特征用 \(\eta_{edge} = 10^{-4}\)。让 router 快速适配,边特征慢慢演化。
实验:到底涨了多少
直接看主表。LoCoMo 是一个长对话记忆 benchmark,平均一段对话 9K token,分五类查询:多跳、时序、开放域、单跳、对抗。
LoCoMo 主表(LLM-as-a-Judge 评分)
gpt-4o-mini 作为 backbone:
| 方法 | Multi-Hop | Temporal | Open-Domain | Single-Hop | Adversarial | Overall |
|---|---|---|---|---|---|---|
| Full Context | 0.468 | 0.562 | 0.486 | 0.630 | 0.205 | 0.481 |
| A-MEM | 0.495 | 0.474 | 0.385 | 0.653 | 0.616 | 0.580 |
| MemoryOS | 0.552 | 0.422 | 0.504 | 0.674 | 0.428 | 0.553 |
| Nemori | 0.569 | 0.649 | 0.485 | 0.764 | 0.325 | 0.590 |
| MAGMA | 0.528 | 0.650 | 0.517 | 0.776 | 0.742 | 0.700 |
| MemSkill | 0.480 | 0.453 | 0.498 | 0.614 | 0.317 | 0.501 |
| HAGE | 0.547 | 0.667 | 0.497 | 0.797 | 0.839 | 0.739 |
Qwen2.5-3B 作为 backbone:
| 方法 | Multi-Hop | Temporal | Open-Domain | Single-Hop | Adversarial | Overall |
|---|---|---|---|---|---|---|
| Full Context | 0.229 | 0.095 | 0.335 | 0.227 | 0.244 | 0.215 |
| A-MEM | 0.258 | 0.203 | 0.219 | 0.416 | 0.684 | 0.410 |
| MemoryOS | 0.285 | 0.212 | 0.194 | 0.341 | 0.229 | 0.280 |
| Nemori | 0.317 | 0.450 | 0.379 | 0.641 | 0.036 | 0.412 |
| MAGMA | 0.301 | 0.402 | 0.334 | 0.576 | 0.589 | 0.499 |
| MemSkill | 0.149 | 0.079 | 0.158 | 0.187 | 0.266 | 0.179 |
| HAGE | 0.315 | 0.457 | 0.335 | 0.657 | 0.603 | 0.548 |
几个数得拎出来看。
Adversarial 这一列在 gpt-4o-mini 上从 0.742 干到 0.839,涨了将近 10 个点。Adversarial 是 LoCoMo 里专门刁难的查询类型——问的事情其实没在对话里出现过,正确答案是"我不知道"。能在这一列拉这么大差距,说明 HAGE 的遍历策略学会了一件事:找不到证据的时候,敢承认。这背后的机制大概是 REINFORCE 训练让模型学到"瞎遍历到无关节点会被扣分",所以不如直接停下来。
Temporal 从 0.650 到 0.667,看着不多但很有意思。时序问题最依赖图边的语义——你得知道哪条边是"在之前"、"在之后"。如果边权全是 1,路由器就只能靠 query 和节点的语义相似度判断走哪条边。HAGE 把时序关系编码进 \(\mathbf{e}_{ij}\) 的一个维度,路由器一眼能看出来。
但也得说几句不那么漂亮的地方:
- Multi-Hop 上 HAGE 没赢,反而是 Nemori 拿了最高分(0.569 vs 0.547)。理论上多跳推理是图记忆应该最擅长的场景,结果反而被对手压一头,这有点意外。作者文中没解释这件事。
- Open-Domain 上也不是第一,输给 MAGMA。
- 在 Qwen2.5-3B 上的 Adversarial(0.603)输给 A-MEM 的 0.684 一大截。
整体看 HAGE 是 Overall 第一,但单看具体类别,它的优势主要集中在 Temporal、Single-Hop、Adversarial 这三类,多跳和开放域并不强。
HotpotQA 的泛化测试
| 方法 | GPT-4o-mini F1 | GPT-4o-mini LLM Score | Qwen2.5-3B F1 | Qwen2.5-3B LLM Score |
|---|---|---|---|---|
| A-MEM | 0.433 | 0.547 | 0.186 | 0.416 |
| MemoryOS | 0.477 | 0.592 | 0.350 | 0.459 |
| Nemori | 0.131 | 0.624 | 0.091 | 0.332 |
| MAGMA | 0.640 | 0.807 | 0.337 | 0.424 |
| MemSkill | 0.579 | 0.779 | 0.179 | 0.247 |
| HAGE | 0.678 | 0.824 | 0.429 | 0.527 |
HotpotQA 是非对话场景的多跳 QA,作为泛化测试。HAGE 在两个 backbone 上都是第一,F1 比 MAGMA 高了 3.8 个点。这说明 HAGE 学到的不是"对话记忆专用"的某种特化,而是更通用的图遍历策略。
效率代价
| 方法 | Avg Score | Tokens/Query K | Latency s |
|---|---|---|---|
| A-MEM | 0.580 | 2.62 | 2.26 |
| MemoryOS | 0.553 | 4.76 | 32.68 |
| Nemori | 0.590 | 3.46 | 2.59 |
| MAGMA | 0.700 | 3.37 | 1.72 |
| MemSkill | 0.501 | 0.92 | 1.46 |
| HAGE | 0.739 | 3.82 | 2.17 |
HAGE 不是最快的,每个 query 3.82K token、2.17 秒延迟。比 MAGMA 慢一点、贵一点,但精度涨了 5.6 个百分点。MemSkill 跑得最快但精度最差。这是个典型的精度-效率权衡,HAGE 落在右上角的位置。
值得提一句:MemoryOS 那个 32.68 秒的延迟有点离谱,应该是它的层次化记忆操作系统涉及频繁的 LLM 调用。
消融实验:到底是哪个组件在起作用
| HAGE 变体 | Judge | F1 |
|---|---|---|
| Static Edge(边权固定,无路由) | 0.698 | 0.462 |
| LLM Scorer Edges(用 LLM 打分初始化,不训练) | 0.712 | 0.500 |
| Trainable Edge(只训边特征,不训路由) | 0.724 | 0.514 |
| Trainable Router(只训路由,边特征固定) | 0.713 | 0.502 |
| HAGE 完整版 | 0.739 | 0.548 |
这张消融表是论文最有信息量的部分之一。
从 0.698 到 0.712 是 14 个千分点,说明 LLM 给关系打分比纯结构边强一点,但有限。
从 0.712 到 0.724 是 12 个千分点,说明把边特征变成可训练的,提升不大但有。
只训路由不训边是 0.713,跟 LLM 打分初始化差不多——这说明光有路由网络去解读固定的边特征,提升有上限。
完整版 0.739 比单独训边或单独训路由都高出一截。这是共同演化真正起作用的证据:边特征学到的关系信号要被路由网络消化,路由网络学到的偏好要被反向传到边特征上。两个模块互为彼此的训练信号。
几个值得想想的点
第一,HAGE 跟 MAGMA 的关系。
MAGMA 在 baseline 里是仅次于 HAGE 的方法。论文里说 MAGMA 是"multi-relational memory with static edge weights and heuristic traversal"。也就是说,MAGMA 的结构跟 HAGE 几乎一样——多关系图、多种边类型——区别只在 HAGE 把边权和遍历策略变成可训练的。
这意味着 HAGE 的 5.6 个百分点提升,主要来自"训"这件事,而不是"图结构怎么设计"。这反过来也说明:图结构本身可能已经接近设计极限了,真正能榨出性能的地方在于让结构里的参数可学。
第二,REINFORCE 居然 work,这件事本身值得想想。
REINFORCE 是最古老最朴素的 policy gradient 方法,方差大、收敛慢。HAGE 用 REINFORCE 加 EMA baseline 就能稳定训练,而且只用 node-level 监督(知道哪些节点是目标证据),不用 path-level 监督(不需要知道完整路径)。
这件事的工程意义其实挺大的。你只需要标"这个问题的正确证据是哪几个事件",不用标"该怎么走过去"。后者在长对话场景下基本不可能标。
第三,L2 anchor 正则是真正的工程关键。
论文里这一段没用太多笔墨,但我觉得很重要。如果没有 anchor,训练时的边特征会自由漂移,但推理时换一个新对话样本,边特征又得从 LLM 打分重新初始化——分布完全对不上。
加了 anchor 之后,可以理解成一种约束策略学习:让 RL 在初始化的语义结构附近做小步探索,不允许跑远。这跟 RLHF 里的 KL 约束是同一个思想。
第四,跨样本的泛化是怎么做到的。
5-fold 交叉验证是按对话样本分的——同一段对话的所有 query 要么全部在训练集要么全部在测试集。这意味着模型在推理时面对的是完全没见过的图。
边特征是图的边的属性,没见过的图就没有训过的边特征。这时候模型怎么用?答案是:边特征的初始化来自 LLM 打分,路由网络才是真正学到泛化策略的那个组件。L2 anchor 保证了训练时的边特征不会偏离初始化太远,所以训练时学到的"路由网络该怎么解读这些边特征"的策略,可以迁移到新图。
这是个有点 elegant 的设计。如果你直接把边特征当成完全自由的参数,它就成了图的"专属参数",没法跨图迁移。HAGE 通过 anchor 把它压回 LLM 打分的语义空间里,于是路由网络学到的就是一种"通用的解读策略"。
我的判断
这篇论文不属于颠覆性工作,但属于"做得干净"的那类。
它解决的问题是真实的:现有图记忆系统的边权和遍历策略大多是手工设计的,没办法被下游任务反馈训练。HAGE 把这件事真的做成了端到端可训的,并且 anchor 正则解决了泛化问题。
技术上的创新点其实不大——多关系图早就有人做(GraphRAG、AriGraph 等),RL 训检索也有先例(AgeMem、RouterRAG 等)。HAGE 的贡献在于把这两条线串起来:多关系图 + 边特征可训 + 路由可训 + 联合优化 + anchor 正则。每一块都不新,但拼起来产生了能涨 5 到 6 个百分点的方案。
值得想的工程方向:
-
L2 anchor 正则的思路可以迁移到很多 RL 微调场景。任何在初始化附近做约束探索的需求,都可以试试。
-
node-level 监督的 RL 训练是有可行性的。不用标完整轨迹,只标终点状态,这在大量真实场景下能落地。
-
路由器 + 可训边特征的联合演化框架值得做更深入的探索。当前 HAGE 只用了 REINFORCE,换 PPO 或 GRPO 大概率还能涨。
几个不太满意的地方:
- 多跳推理上没能赢过 Nemori,作者没分析原因。理论上多跳应该是图记忆的核心战场。
- 边特征向量只有 4 维。如果扩展到更高维(每个维度编码更细的关系子类型),是不是能进一步涨?论文没尝试。
- HotpotQA 上的提升幅度比 LoCoMo 上要小一些,说明 HAGE 对对话记忆这个场景有一定的过拟合倾向。
但整体来说,这是一篇值得长程 Agent 工程师认真看的论文。如果你正在做带记忆的 Agent,特别是需要长期对话或多跳推理的场景,HAGE 提供的这套"可训边权 + RL 路由 + anchor 正则"的组合是个值得 fork 来试的 baseline。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我