EvolveMem:让 Agent 的记忆系统自己改自己的检索配置
一段开场白
做过 LLM Agent 长期记忆的人,多少都被这件事刺过一下:
刚部署的时候挺顺。记忆库里几十条东西,top-k=5、BM25 + 余弦做混合检索,问什么基本都能命中。然后用着用着,记忆涨到几百上千条,里头既有事实、又有偏好、还夹着一堆程序性的小步骤——同一套检索参数开始崩了。问"上周三我们决定用什么版本",它给你翻出三个月前的会议纪要;问"我喜欢什么口味",它跑去扯一段对话上下文。
问题不在记忆里存了什么,问题在记忆怎么被检索出来。
但几乎所有现有的记忆系统——MemGPT、Mem0、A-MEM、SimpleMem——都默认了一件事:存的内容会演化,但取的策略一辈子不变。fusion 权重、top-k、context budget、答案生成风格,部署那天怎么定的就怎么用下去。这就像把一个只熟悉 50 平米房间的人扔进 500 平米仓库,他还在用同一套找东西的习惯。
EvolveMem 这篇 paper 的切入点就在这。它问的问题特别朴素:能不能让检索这套基础设施本身,跟着记忆内容一起进化?而且全自动,不需要人去调?
更妙的是它的解决思路——不是 RL,不是贝叶斯优化,而是让 LLM 读自己的失败日志、自己写诊断、自己改配置。作者把这个范式叫 AutoResearch:系统对自身的检索架构做一遍"观察—假设—实验—验证"的科研循环。
一段话摘要:EvolveMem 把检索配置(fusion 模式、top-k、视图权重、回答风格、按问题类别的子配置等)整体暴露成一个结构化动作空间,让一个 LLM 诊断模块每轮读全量 QA 的失败日志,提出针对性修改;一个带"回滚 + 探索"双护栏的元分析器决定要不要采纳。从最简陋的 BM25-only baseline 起步,7 轮全自动演化,LoCoMo 的 F1 从 30.5% 涨到 54.3%(相对 +78%),相对最强基线 SimpleMem 提升 25.7%;MemBench 上相对最强基线 +18.9%。最让我觉得有意思的是,进化出来的配置可以正向迁移到另一个基准,说明学到的不是过拟合的"应试技巧",而是更通用的检索原则。
论文信息
- 标题:EvolveMem: Self-Evolving Memory Architecture via AutoResearch for LLM Agents
- 作者:Jiaqi Liu, Xinyu Ye, Peng Xia, Zeyu Zheng, Cihang Xie, Mingyu Ding, Huaxiu Yao
- arXiv:2605.13941(v1, 2026-05-13 提交)
- 代码:github.com/aiming-lab/SimpleMem
为什么"检索配置冻结"是个真问题
我先把这件事的工程感觉讲清楚,因为如果你只看 paper 的 motivation,会觉得有点抽象。
不同类型的问题,根本上就需要不同的检索策略:
- 事实查找("她男朋友叫什么")——要的是精确的关键词匹配,BM25 才是最稳的
- 时序推理("最近一次见面是什么时候")——要带 recency 加权,按时间过滤
- 多跳推理("她男朋友喜欢的运动是什么")——要把问题拆成几个子查询分别检索再合并
- 对抗性问题(人名替换攻击)——要做 entity-swap,把名字摘掉再去匹配,否则就被人名绑架
- 开放式问题("她最近过得怎么样")——要更长的 context budget,宽一点收一些上下文
一套 fix 死的检索配置不可能同时把这几种都做好。你要么偏 BM25 牺牲语义,要么偏语义牺牲精确性。这就是论文里说的 "frozen retrieval cannot optimally serve all needs simultaneously"。
更难受的是记忆库规模本身在变。同一个 top-k=5,记忆库 50 条时召回率 90%,到了 1000 条时可能跌到 40%。你需要不断重新校准。可没人有这个时间一直手动调。
EvolveMem 解决的就是这个:把检索基础设施变成一个能持续被自动调整的对象。
整体架构:四层加一个闭环
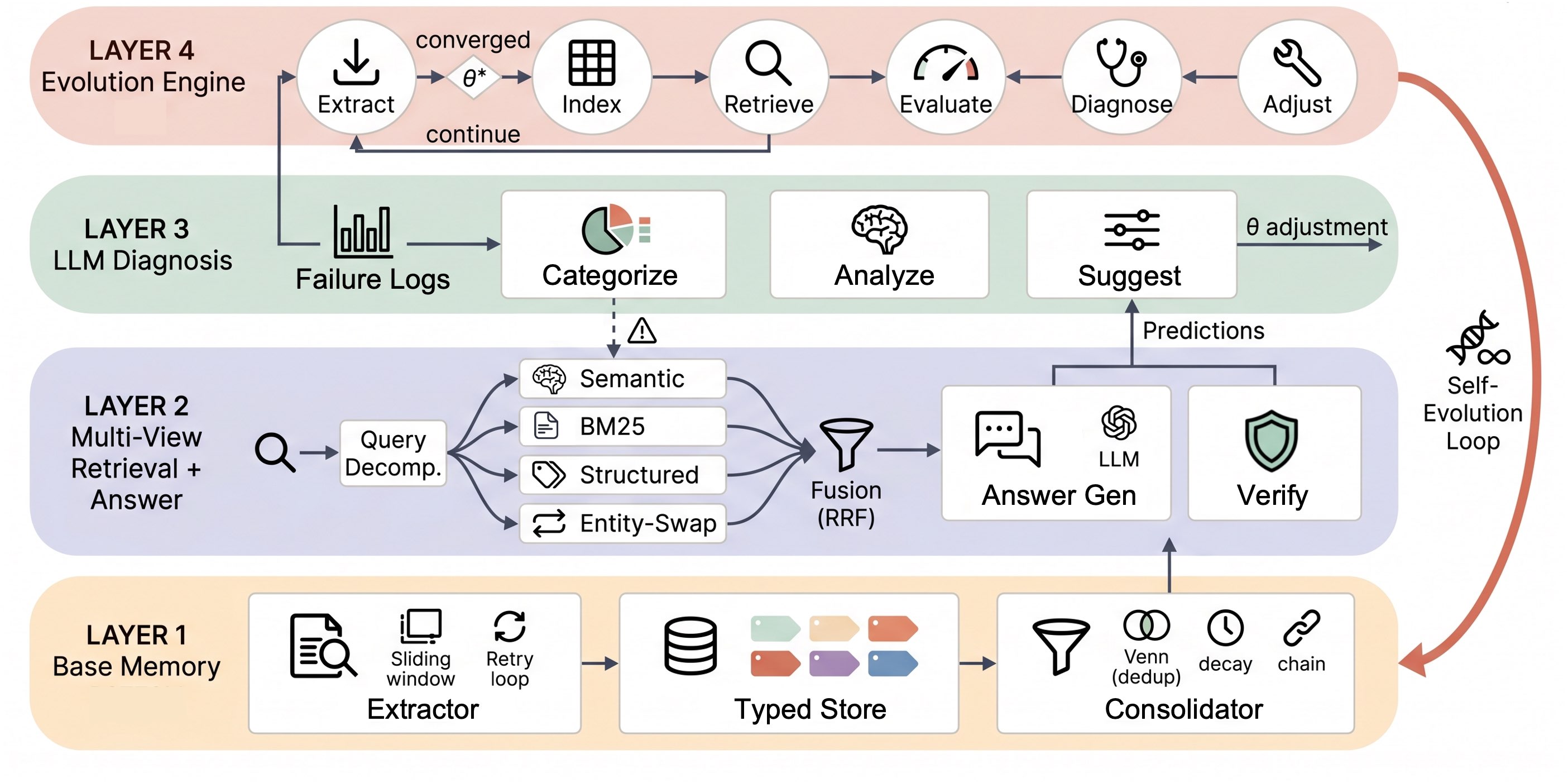
图1:EvolveMem 四层架构。LAYER 1 是基础记忆层(抽取+类型化存储+整合);LAYER 2 是多视图检索(语义/BM25/结构化/Entity-Swap + Fusion + 答案生成 + 验证);LAYER 3 是 LLM 诊断(按问题类别分析失败日志,提出 θ 调整);LAYER 4 是演化引擎(Extract→Index→Retrieve→Evaluate→Diagnose→Adjust 循环)。右侧那条 Self-Evolution Loop 把一切串起来。
这张图把整个系统看得很清楚。三个核心模块,加一个把它们连起来的演化引擎:
| 层 | 角色 | 一句话理解 |
|---|---|---|
| Memory Store | 把对话变成结构化记忆 | "记忆是什么" |
| Retrieval | 多视图检索 + 答案生成 | "怎么把记忆找出来" |
| Diagnosis | 读失败日志、提配置修改 | "哪里有问题" |
| Evolution Engine | 决定要不要采纳,带护栏 | "改不改、怎么改" |
下面挨个聊。
LAYER 1:结构化记忆——别小看抽取的质量
每条记忆是一个四元组 \(m = (c, \mu, e, \eta)\):
- \(c\):自然语言内容
- \(\mu\):6 类记忆类型(情景、语义、偏好、项目状态、工作摘要、程序性知识)
- \(e\):768 维 dense embedding(BAAI/bge-base-en-v1.5)
- \(\eta\):元数据——重要性、置信度、实体强化分数、时间戳等
抽取走滑动窗口 + LLM,带三重容错:失败重试、超长分块、覆盖率校验。
为什么抽取这块要单独拎出来讲?因为后面消融实验会告诉你——整个系统里最不能动的就是抽取质量,去掉这三重保护,F1 直接从 54.3% 掉到 31.1%,砍掉了一半。检索层做得再花哨,记忆库里没存进去该存的东西,一切归零。这是地基。
整合阶段还有三个机制:
- 去重合并:Jaccard 超阈值的合并
- 重要性衰减:线性衰减 + 下限兜底,防止有用的记忆被衰减没了
- 实体强化:被反复引用的实体加分
LAYER 2:检索作为可演化的动作空间
这是全文最关键的设计决定。
传统记忆系统里,检索是一段固定代码——比如先 BM25 取 10 条、再 cosine 取 10 条、相加排序、取 top-5。EvolveMem 把这整段过程参数化:
里头每一项都可以被改:
- 三种检索视图各自的 top-k
- context budget(一次塞多少内容给 LLM)
- fusion 模式(sum / weighted-sum / RRF)
- 三个视图各自的权重
- 时间衰减系数
- 按问题类别 c 的子配置 \(\theta_c\)——这条特别重要,意味着对单跳问题和多跳问题可以用完全不同的检索策略
最终排序公式:
理解到这一层,你才会明白后面 AutoResearch 在搜索什么——它在搜索的是 \(\theta\) 的最优值,而且这个 \(\theta\) 的维度本身在演化过程中还会被新增(后面会讲)。
LAYER 3:LLM 诊断——用读日志代替调参
这是这篇论文最反直觉、也最让我觉得"对,应该这么做"的地方。
传统超参搜索(grid search、贝叶斯优化)在这里其实不太好使。原因有两个:动作空间既有连续参数也有离散选择;每次评估都得跑全量 QA + LLM,成本极高。所以暴力搜索行不通,必须带方向地搜。
EvolveMem 的做法:让 LLM 当"研究员"。
每轮演化,LLM 拿到的是整轮 QA 的逐题原始日志——问题、模型预测、ground truth、F1 分数、检索来源都摆上来。LLM 按结构化评判标准做归因:
- 错误实体?(说明视图权重、entity-swap 没做好)
- 上下文不足?(context budget 太小)
- 时间混淆?(缺 recency 加权)
- 多跳召回不全?(需要 query decomposition)
然后输出一个修改提案 \(\Delta\theta\)。注意,这个 \(\Delta\theta\) 可以包含原始动作空间里没有的新维度——比如它发现对抗性问题老是检索错人名,会"发明"一个 entity-swap 机制;发现多跳问题召回不全,会"发明"查询分解。这些不是预先编进去的。
LAYER 4:演化引擎——三分支的 meta 更新规则
提案不能直接采纳,否则一个糟糕的 \(\Delta\theta\) 就把系统搞崩了。元分析器走三分支决策:
读起来其实很直白:
- 回归触发回滚:如果性能掉得太狠(超过 \(\tau_{\text{rev}}\)),直接回退到历史最优 \(\theta^*\)
- 停滞触发探索:连续两轮几乎没变化(变化幅度 \lt \(\epsilon\)),就给当前配置加一个随机扰动 \(\eta_{\text{exp}}\),逼系统离开局部最优
- 其他正常情况:把提案 \(\Delta\theta\) 应用上,clamp 到合法参数范围
这三件事放在一起,等于给一个完全没人监督的演化过程上了三道保险。后面实验里会看到,R2 那一轮有个 MMR 多样性的提案让 F1 掉了,回滚保护立马生效——这套护栏不是写在 paper 上好看,是真的在跑。
演化轨迹:7 轮,从 30.5% 到 54.3%
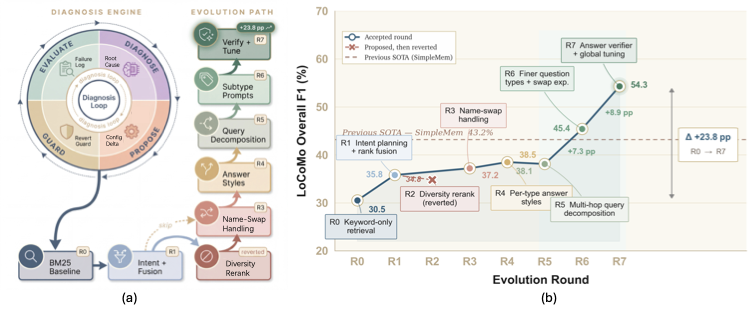
图2:(a) 演化路径:从 R0 BM25 baseline 起步,依次激活 Intent+Fusion、Diversity Rerank(被回滚)、Name-Swap Handling、Answer Styles、Query Decomposition、Subtype Prompts、Verify+Tune;右侧 Diagnosis Engine 的循环也很清楚——Evaluate→Diagnose→Propose→Guard。(b) F1 轨迹:30.5% → 35.8 → 34.8(回滚)→ 37.2 → 38.5 → 38.1 → 45.4 → 54.3,相对前 SOTA SimpleMem(43.2%)总共 +23.8 个百分点。
| 轮次 | 类型 | 自动化变更 | F1 (%) |
|---|---|---|---|
| R0 | weak baseline | BM25-only, k=5, \(B_{\text{ctx}}{=}8\) | 30.5 |
| R1 | auto | intent planning + RRF fusion | 35.8 |
| R2 | revert | MMR diversity(被回滚) | 34.8 |
| R3 | auto | 对抗类 entity-swap(Cat.5) | 37.2 |
| R4 | auto | 按类别设回答风格 | 38.5 |
| R5 | auto | 多跳查询分解(Cat.1/4) | 38.1 |
| R6 | auto | Cat.3 推理子类型 + entity-swap 扩展 | 45.4 |
| R7 | auto | 答案验证 + 超参扫描 + ctx-budget 调优 | 54.3 |
逐轮拆开看:
R1——LLM 看到 baseline 下时序类问题大量错答,提议加 intent planning 和 RRF 融合。RRF 这个选择挺聪明的,因为它对不同视图的分数尺度差异天然鲁棒,避免了 weighted-sum 那种调权重的痛苦。+5.3 个点。
R2——这一轮提议在多跳类引入 MMR(最大边际相关度)做多样化重排,结果 F1 反而掉了 1 个点。回滚护栏立刻把配置退回到 R1。这是论文最有意思的负证据——它告诉你这套机制是真的会自我纠错,不是 cherry-pick 出来好看的轨迹。
R3-R5——LLM 进入"发明新维度"阶段。它发现:
- 对抗类问题(人名 swap)老是被人名误导 → 发明 entity-swap
- 多跳问题召回不全 → 发明 query decomposition
- 不同问题类别需要不同回答风格 → 提出 per-category answer style flags
这三个东西,原始动作空间里都没有。它们是 LLM 在读失败日志时凭经验"造"出来的。这点比单纯的超参搜索强一个量级。
R6-R7——精细化阶段,处理推理子类型、加答案验证(second-pass LLM 校对低置信度回答)、扫一遍超参、调 ctx-budget。最后一跳从 45.4% 直接拉到 54.3%。
整轮 7 步全自动,没有人工介入。+78% 相对提升。
主实验:LoCoMo 上的全面碾压
LoCoMo 是长期对话记忆的标准 benchmark:10 段多轮对话,每段 19-32 个 session、369-689 turns,共 1986 个 QA 对,5 类问题。
GPT-4o backbone
| 方法 | MultiHop F1 | SingleHop F1 | Temporal F1 | OpenDomain F1 | Adversarial F1 | Overall F1 |
|---|---|---|---|---|---|---|
| MemVerse | 0.260 | 0.157 | 0.196 | 0.192 | 0.944 | 0.365 |
| Mem0 | 0.309 | 0.156 | 0.217 | 0.295 | 0.857 | 0.397 |
| Claude-Mem | 0.294 | 0.153 | 0.167 | 0.243 | 0.915 | 0.383 |
| A-MEM | 0.295 | 0.174 | 0.200 | 0.266 | 0.898 | 0.394 |
| MemGPT | 0.305 | 0.188 | 0.246 | 0.305 | 0.843 | 0.404 |
| SimpleMem | 0.318 | 0.195 | 0.235 | 0.402 | 0.802 | 0.432 |
| EvolveMem | 0.316 | 0.329 | 0.384 | 0.496 | 0.936 | 0.543 |
EvolveMem 整体 F1 0.543,相对 SimpleMem(0.432)提升了 25.7 个点(相对)。最大增量在两类:
- Single-hop:+68.7%(语义检索被激活后的贡献)
- Temporal:+63.4%(recency-weighted fusion)
唯一稍逊的是 MultiHop(0.316 vs SimpleMem 的 0.318,差距小到无意义)和 Adversarial(0.936 vs MemVerse 的 0.944,差 0.008)。但这两类对手用的都是非常专门的策略(MemVerse 的 adversarial 几乎是过拟合到了对抗集),EvolveMem 在没有针对性优化的情况下也咬得很紧。
GPT-5.1 backbone
换更强的 backbone,EvolveMem 优势更大:整体相对 SimpleMem +36.8%,时序类相对提升 98.9 个百分点。这说明它的演化是 backbone-agnostic 的——不是绑定 GPT-4o 的某种 prompt 风格。
MemBench 上同样领先
| 方法 (GPT-4o) | Recall | Reasoning | Robustness | Overall |
|---|---|---|---|---|
| RecentMem | 62.5 | 50.0 | 62.5 | 57.1 |
| MemGPT | 62.5 | 50.0 | 62.5 | 57.1 |
| MemBank | 37.5 | 33.3 | 75.0 | 46.4 |
| SCMem | 62.5 | 25.0 | 37.5 | 39.3 |
| EvolveMem | 87.5 | 66.7 | 50.0 | 67.9 |
Recall +40%、Reasoning +33.4%。
但 Robustness 维度是弱项——50.0% 比 MemBank 的 75.0% 差不少。作者很坦诚地说:失败日志显示 robustness 类的失败基本都集中在 post_processing 子类,这一类的问题是相关记忆压根没存进库里,是 coverage 问题不是 retrieval 问题。检索层面再优化也救不了。
这种坦诚我挺欣赏的。很多 paper 会把弱项藏起来或者用花哨的归因绕过去,EvolveMem 直接告诉你:这是我们方法的能力边界,演化只能优化"如何取",没法优化"有没有"。
跨基准迁移:进化的不是应试技巧
这是我个人最看重的一组实验,因为它直接关系到一个根本问题:EvolveMem 学到的是通用原则还是过拟合?
设计上很干净:
- \(\mathcal{C}_L\):只在 LoCoMo 上演化 7 轮
- \(\mathcal{C}_{LM}\):从 \(\mathcal{C}_L\) 出发再到 MemBench 上继续演化
- \(\mathcal{C}_M\):直接在 MemBench 上从 baseline 演化
| 配置 | LoCoMo | MemBench |
|---|---|---|
| Baseline | 0.305 | / |
| \(\mathcal{C}_L\)(只在 LoCoMo) | 0.543 | 0.543 |
| \(\mathcal{C}_{LM}\)(LoCoMo→MemBench) | 0.593 | 0.792 |
| \(\mathcal{C}_M\)(只在 MemBench) | / | 0.679 |
三个发现:
发现一:零样本迁移有效——\(\mathcal{C}_L\) 直接搬到 MemBench,零调参拿到 54.3%。已经超过所有原 baseline。这等于说在 LoCoMo 上学到的东西在 MemBench 上仍然有效——检索原则是有共性的。
发现二:先演化后微调比从零开始好得多——\(\mathcal{C}_{LM}\) 在 MemBench 上拿到 79.2%,比从零开始的 \(\mathcal{C}_M\)(67.9%)高了 16.6% 相对。这是个挺有意思的现象:LoCoMo 的演化轨迹给 MemBench 提供了一个更好的起点。
发现三:帕累托改进——\(\mathcal{C}_{LM}\) 不仅在 MemBench 上更好,回到 LoCoMo 还从 0.543 涨到 0.593,两个基准同时变好。换句话说,演化没有"灾难性遗忘"——它学的是通用的检索原则,不是某个数据集的偏方。
如果这个结论成立,EvolveMem 的工程意义就比一个"在 LoCoMo 上 SOTA"要大得多——它意味着演化可以累积。把它部署到一个新场景,先借用之前演化好的 \(\theta^*\) 做 warm start,再针对新场景继续演化几轮,效果会比从零开始好。
消融实验:每个组件值多少分
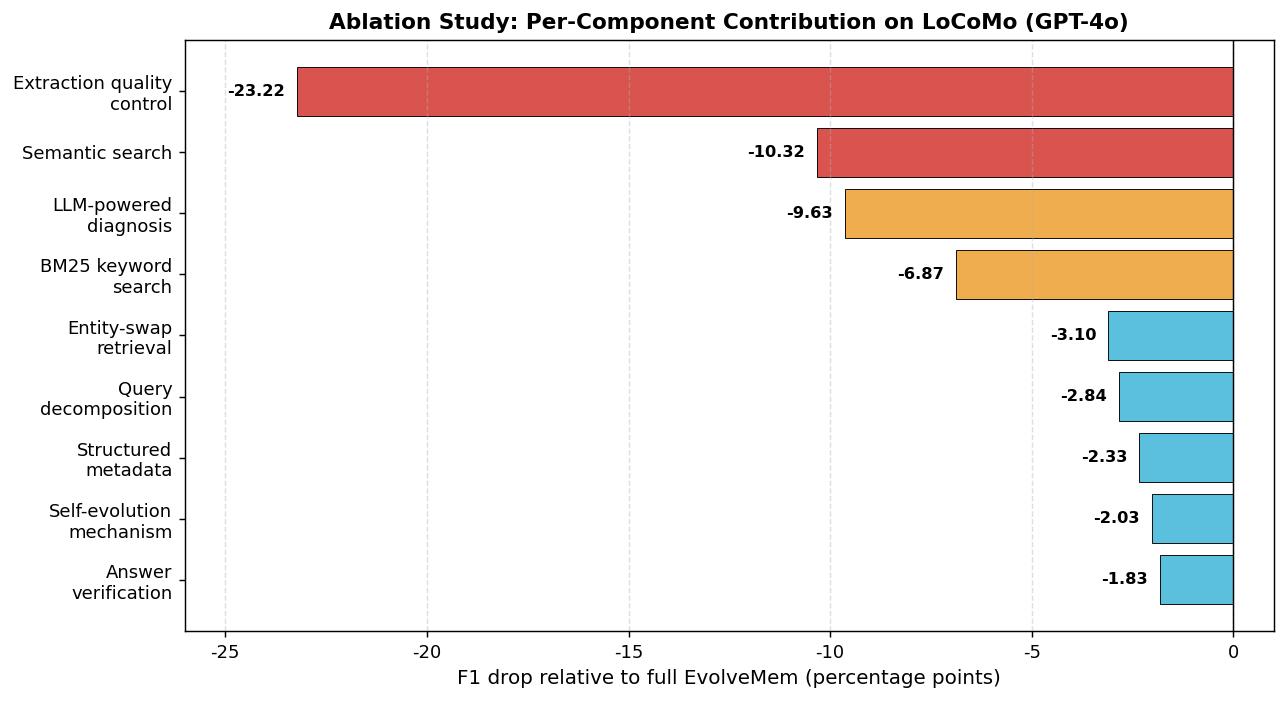
图3:把 EvolveMem 各组件单独移除后 LoCoMo F1 的下降幅度(基于 GPT-4o)。红色 \gt 10 点为关键组件,橙色 5-10 点为重要组件,蓝色 \lt 5 点为辅助组件。
| 移除的组件 | F1 (%) | \(\Delta\) |
|---|---|---|
| EvolveMem 全功能 | 54.3 | -- |
| − 抽取质量控制 | 31.08 | −23.22 |
| − 语义检索 | 43.98 | −10.32 |
| − LLM 诊断模块 | 44.67 | −9.63 |
| − BM25 关键词检索 | 47.43 | −6.87 |
| − Entity-swap | 51.20 | −3.10 |
| − 查询分解 | 51.46 | −2.84 |
| − 结构化元数据检索 | 51.97 | −2.33 |
| − 自演化机制 | 52.27 | −2.03 |
| − 答案验证 | 52.47 | −1.83 |
| Baseline(全部禁用) | 30.50 | −23.80 |
几个我觉得重要的观察:
抽取质量是真正的地基(−23.22):去掉抽取的三重容错,F1 砍掉一半。这跟整体 baseline(30.5)差不多。意味着如果你记忆库都没建好,再花哨的检索都救不回来。
多视图检索贡献分配很合理(语义 −10.32、BM25 −6.87、结构化 −2.33):语义贡献最大,说明很多查询是"概念匹配"而不是"字面匹配";BM25 仍然不可替代,对精确实体非常关键;结构化元数据是辅助,但也有它的位置。
LLM 诊断 vs 随机扰动(−9.63):这一项特别值钱,因为它直接回答了"用 LLM 读日志值不值"这个问题。把诊断模块换成对同样动作空间做随机扰动,F1 掉 9.63 个点。说明 LLM 读日志确实带来了有方向性的搜索信号,不是凭运气。这是对 AutoResearch 范式的一次定量验证。
被"发明"出来的三个维度合计 −7.77:entity-swap、query decomposition、answer verification 加起来贡献近 8 个点。这三个原始动作空间里都没有,是 LLM 在演化过程中自己搞出来的。这部分的贡献证明了"动作空间扩展"不是噱头。
自演化机制本身 −2.03:单独这个数看起来不大,但要注意——它说的是保留所有组件、但不让它们之间联动演化。也就是说,组件本身的功能在,演化带来的协同优化没了,掉 2 个点。综合所有体现"演化"的组件(self-evolution + diagnosis + 三个 discovered dimensions),合计大概 −19.6 个点,这才是"演化"这件事真正的价值。
一些值得讨论的问题
我大致信这篇 paper,但也不打算无脑吹。几个我觉得作者没有讲清楚或者还存疑的地方。
1. 演化代价是个黑盒
7 轮演化,每轮要跑完整的 1986 个 QA 评估 + LLM 诊断,再算上抽取阶段的 LLM 调用——这个总 token 消耗很可观。论文里没给具体的 cost 数据,这对工程落地的人来说是个明显的缺失。如果一次完整演化要烧 $1000,那它和"花两周时间手动调参"的性价比对比就不那么明显了。
2. 离线演化 vs 在线演化
当前的演化是 offline 的——需要一批带 ground truth 的 QA 对来做评分。真实部署里,用户提问没有 ground truth,怎么持续演化?论文没回答。这是一个开放问题。可能的方向是用 LLM-as-judge 做代理评分,但那又是另一篇 paper 了。
3. MemBench 样本量偏小
28 个样本(7 类 × 2 话题 × 2 样本),统计显著性需要打个问号。LoCoMo 的 1986 对足够,但 MemBench 上的"+18.9% 相对提升"我会保守看待。
4. 跟 RL-based 路线缺乏正面对比
最近一年另一条路线在做 Memory-R1、Agentic Memory 这类用 RL 优化记忆操作的工作(GRPO、PPO)。EvolveMem 走的是 LLM 诊断这条路,从效率上看更轻、不需要 reward model,但它没跟 RL 路线做正面比较。这两条路谁的天花板更高,目前还看不到答案。
5. "discovered dimensions" 的可复现性
LLM 诊断每次提出的新维度(entity-swap、query decomposition)确实能涨点。但换一个 LLM、换一份失败日志,会不会得到完全不同的"发明"?多次运行的稳定性如何?论文里只展示了一条演化轨迹,缺少多 seed 的统计。
这篇论文好在哪、能用在哪
撇开上面这些 nitpick,我觉得这是一篇少见的工程感 \gt 包装感的工作。它的核心贡献其实可以讲得很短:
把检索基础设施变成一等优化对象,用 LLM 读失败日志驱动演化,加双护栏防崩。
就这一件事,但做得扎实——动作空间设计合理、护栏机制有效、迁移实验干净、消融拆得清楚。
对工程的启发我觉得有这么几条:
a) 不只是记忆,所有"基础设施类"配置都可以这么改
EvolveMem 把"检索配置"当一等优化对象,等于把基础设施从硬编码升级成可观测可改写的对象。这套思路用到 RAG 的 chunking 策略、prompt 路由、tool selection 上都成立。任何"部署即冻结"的配置都值得问一句:能不能像这样让 LLM 读日志改自己?
b) 双护栏比 fancy 算法更值钱
回滚 + 探索两条规则就解决了"演化跑飞"的核心风险。比花式贝叶斯优化要实用得多。落地系统第一要务是别崩,然后才是性能——这套设计哲学非常对路。
c) "发明新维度" 的能力是 LLM 诊断的真正价值
如果只是在固定动作空间里搜参数,传统超参优化就够了,没必要叫 AutoResearch。EvolveMem 真正打动我的是 entity-swap、query decomposition 这些预先没写在动作空间里的维度,靠 LLM 读日志"造"出来。这才是 LLM-driven research loop 的天花板。
收尾
读完之后我自己最大的感受是:LLM Agent 这一波工作,正从堆功能逐渐转向让系统自己优化自己。EvolveMem 是这个方向上一个挺干净的样本——它没有引入新的训练范式、没有依赖更大的模型,就是把"配置"这件事做活了。
如果你也在做长期记忆、RAG 或者任何"配置越来越复杂、人工调不动"的系统,这篇 paper 的思路是真的值得抄一抄。
具体抄哪一段?我会优先抄它的护栏机制——回滚阈值 + 停滞探索这套规则,几乎是任何自演化系统的最低安全线。然后是结构化失败日志 + LLM 诊断——把每一次失败都变成可读的、可被 LLM 推理的输入,这件事本身就比 reward signal 更可控、更可解释。
至于"自己发明新维度"这件事——目前看是 EvolveMem 最闪光的部分,但也是最不稳定的部分。我会先抄稳的两块,再看看能不能在自己的场景里复现"发明"。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我