EnvFactory:85 个环境如何打掉 500+ 的工具调用 RL 数据工厂
核心摘要
最近这一年做工具调用 Agent 的 RL,最让人头疼的不是算法,而是没数据。准确点说——是没有"既能跑、又像真人在用、还能给出可验证奖励"的训练环境。
EnvFactory 这篇直接把这事儿当成一个工程问题来解:用一套全自动 pipeline,让 LLM 智能体自己上网搜索 → 自己沉淀环境元数据 → 自己写代码 → 自己测试 → 自己改 bug,最终生成 85 个跨 7 个领域、含 842 个工具的有状态可执行 MCP 环境。光有环境还不够,它还配了一个拓扑感知的工具图采样器和一个校准式查询精炼模块,专门用来把"机械的指令链"改造成"带省略、带歧义、带隐式意图"的真人请求。
最后用 Qwen3 系列做底座,在 BFCLv3 多轮上从 33.5 涨到 48.5(4B 模型,涨了 15 个点),MCP-Atlas 通过率 拉高 8.6 个点,τ²-Bench / VitaBench 这种对话型基准也能 涨 6 个点 左右。
最关键的数字其实不在分数上——在数据规模上:85 个环境、2575 条轨迹,对比 EnvScaler 的 191 环境 / 11572 任务、AWM 的 526 环境 / 3315 任务。换句话说,这是一篇"用 1/5 的数据、刷出更高的分"的论文。这种"反规模"路线值不值得跟,是这篇文章最值得聊的地方。
论文信息
| 项目 | 内容 |
|---|---|
| 标题 | EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL |
| arXiv | 2605.18703(v1, 2026-05-18) |
| 作者 | Minrui Xu、Zilin Wang、Mengyi Deng、Zhiwei Li、Zhicheng Yang、Xiao Zhu、Yinhong Liu、Boyu Zhu、Baiyu Huang、Chao Chen、Heyuan Deng、Fei Mi、Lifeng Shang、Xingshan Zeng、Zhijiang Guo(共 15 人) |
| 链接 | https://arxiv.org/abs/2605.18703 |
注:原页面没明确写机构。从作者名单(Fei Mi / Lifeng Shang / Xingshan Zeng 等)和工作风格看,大概率是华为诺亚方舟实验室的工作,但论文页面没显式标注。
一、为什么需要这篇论文:工具调用 RL 的两个老大难
你有没有这种经历——想训一个会用工具的 Agent,理论很简单:找一堆工具,跑 GRPO 就完事了。但真上手会卡在两个地方。
第一个是环境。工具调用 RL 想 work,得有真实可执行的环境。市面上三条路,每条都有坑:
- 走真实 API(ToolLLM、StableToolBench 这类):贵、慢、限流。RL 一跑起来动辄几万次 rollout,OpenWeather API 给你限到怀疑人生。更要命的是 RL 训练对延迟敏感,公网 API 抖一下整批 batch 就废了。
- 走 LLM 模拟器(让 GPT-4 假装是工具):便宜、快,但幻觉。模拟器今天告诉你"航班 CA1234 已订",明天告诉你"航班不存在",奖励信号就成了噪声。
- 走合成沙箱环境(AutoForge、AgentScaler 这类):理论上最理想——本地代码、可控、零延迟。但有两个常见瑕疵:要么是无状态的(一次性查询,不能模拟"先查酒店列表,再用 hotel_id 订房"这种链式逻辑),要么严重依赖预先收集的 API 文档(覆盖范围被卡死)。
第二个是数据。退一步说,环境搞定了,轨迹怎么造?
现在主流合成方法的通病是过度规约(over-specified)。你看一条典型的合成 query 长这样:
"请先调用 search_destinations 查找东京附近的目的地,然后调用 get_hotels 查询酒店列表,再用 get_hotel_details 查询第一个酒店的详细信息,最后调用 book_hotel 完成预订。"
——这哪是用户说话啊,这是写好的脚本。真实用户会怎么说?
"我打算 5 月 18-20 号去 Kyoto 出差,帮我看看那边有啥酒店,重点看 Sakura Garden Hotel,再帮我把行程发给 WhatsApp 上的同事。"
差别在哪?真人话里省略了 ID 这种内部状态(hotel_id 哪个用户记得住)、省略了显式的工具调用序列(用户不关心你调几个工具)、带了点歧义("那边有啥酒店"是指 Kyoto 还是出差期间的住所)、带了二级目标(顺手发给同事)。
如果你拿"过度规约"的合成数据训 RL,模型学到的是"按部就班执行指令",一上线碰到真人请求就懵——这就是合成数据训出来的 Agent 在真实场景翻车的根因。
EnvFactory 想同时解决这两件事。说实话,这两个问题之前的工作都各做各的——做环境的不太关心 query 真实度,做 query 合成的又把环境当成黑盒。把两者打通,是这篇论文最值钱的工程贡献。
二、EnvFactory 全景:两个模块、三条飞轮
整个 pipeline 分成两大块:EnvGen(环境合成)和 QueryGen(轨迹合成)。我们先看 EnvGen。
2.1 EnvGen:让多个 Agent 联手把环境造出来

图 1:左半部分是 EnvGen 的多 Agent 工作流——Search Agent 从可信网络资源拉信息、Code Agent 写实现、Test Agent 跑单测,三方在 Environment Generation Loop 里循环 N 次直到通过验证。右半部分是 EnvFactory 最终产出的 85 个环境的领域分布——Office(24%)、Lifestyle(24%)、Commerce(16%)、Academic(12%)、Utilities(11%)、Travel(9%)、Finance(4%)。每个扇区里还能看到具体环境名,比如 Office 下有 Notion、GoogleDocs、Calendar、ExcelServer 等,Commerce 下有 AmazonProducts、Retail、EbayServers 等。
这个图把整个故事讲得很清楚。三个 Agent 分工:
Search Agent:负责"开题"。它会先扫描已有环境池,识别覆盖盲区(比如发现金融领域只有 4%,差太多),然后去网上找权威资料(API 文档、技术博客、官方使用示例)来给新环境打底。这步的关键是不依赖预收集文档——它直接基于"我现在缺什么"自己去网上挖,所以理论上覆盖范围可以无限扩。Search Agent 输出的是结构化元数据 \(m\),包括环境描述、工具定义、参数 schema。
Code Agent:拿到元数据后干两件事。先建数据库 schema \(\mathcal{D}\)——这里他们用的是 Pydantic,把工具参数、中间状态、持久化记录都建模成 Pydantic schema,配标准化的序列化接口。这点设计很实用,因为 RL rollout 之间需要干净的 session 隔离(每条 rollout 是一个独立的"游戏存档"),用 Pydantic 序列化能保证可复现。然后是写工具实现 \(\pi\),每个工具是一段可执行 Python,最后包成 MCP 接口。
Test Agent:最关键的把关人。它会自动生成单测,从四个维度验证:(1) 工具接口是否和 metadata 一致;(2) 工具能不能正常 import 和执行;(3) 执行结果是否符合预期;(4) 执行后数据库状态有没有正确变化。任何一项不过,Test Agent 会生成结构化错误报告——它会指出错在哪个环节(实现逻辑?schema 定义?接口包装?),然后甩回 Code Agent 让它改。
整个流程是个 revision loop,循环到全部测试通过或者达到 budget 上限。最终产物是一个完整的、有状态的、可重复的环境元组:\(e = (m, \mathcal{D}, \pi, \mathcal{V}_e)\)。
我看到这块的第一反应是——这套多 Agent 协作的范式其实挺常见,OpenHands、SWE-Agent 都干过类似的事。EnvFactory 真正讲究的地方在于Test Agent 的四维校验和结构化错误回报——很多人做 self-debugging Agent 都会卡在"它知道错了,但不知道错在哪",这里把错误归因做得相对扎实,所以收敛得比较稳。
2.2 QueryGen:让查询像真人在说话
环境造好了,接下来要造轨迹。这部分才是真正的功夫活。

图 2:QueryGen 完整工作流。Part 1 是拓扑感知采样——从工具图里抽出一条非线性的工具链(注意左下那个分支结构,不是简单的 1→2→3→4 直线,而是 1→2→4,2→3,2→5 的树状)。Part 2-7 是 query 合成——规划场景、生成数据库初始状态、生成 query、精炼 query、沙箱解题、过滤选最优。中间那个例子很说明问题:先生成机械版"Help me plan a team trip to Kyoto from May 18 to May 20. Find the Kyoto destination, get hotels for those dates, check Sakura Garden Hotel details...",再精炼成"I'm planning a team trip to Kyoto from May 18 to May 20. Could you help me compare where we could stay. Look into Sakura Garden Hotel in more detail, and find my teammates on WhatsApp so I can share the option with them?"——后者明显更像真人在说话。
QueryGen 的核心创新有两块:拓扑感知采样和校准式精炼。
2.2.1 拓扑感知采样:先把工具关系图建对
很多人造 query 的做法是:随机选几个工具,让 LLM 串成一句话。这种方式有个致命问题——采到的工具链未必有合理的逻辑依赖。
举个例子:你随机采到 [book_hotel, get_weather],让 LLM 写 query。LLM 大概率会写"帮我订 hotel_id=123 的酒店并查天气"——但 hotel_id 这个内部状态用户怎么会知道?真实场景一定是先 search → 拿到 hotel_id → 再 book。
EnvFactory 的解法是先建一个工具依赖图 \(G=(\mathcal{V}, E)\):
- Step 1(语义参数匹配):用 BAAI/bge-m3 embedding,把每个工具的输入/输出参数都编码。对任意两个工具 \((v_i, v_j)\),如果 \(v_i\) 的某个输出参数和 \(v_j\) 的某个输入参数语义相似度超过阈值,就连一条有向边 \(v_i \rightarrow v_j\)。
- Step 2(逻辑依赖修正):用 LLM 二次过一遍,补上漏掉的边(比如
delete_all_notes这种没有输入也没有输出的工具,光靠语义匹配会被孤立),同时剪掉伪边。
图建好之后,采样就要有原则——核心约束是:采样链中每个工具的必需输入参数,必须要么由用户外部提供,要么由前序工具的输出内部满足。
具体怎么落地?他们先用 LLM 把每个输入参数标记为 external 还是 internal:
- external:像
city、name、date这种用户能自然说出口的参数。 - internal:像
hotel_id、order_id这种内部状态,用户根本不会知道。
采样时遇到一个工具 \(v\),对它的每个输入参数 \(p_i\) 检查:
- Optional:有默认值或可省略 → ✅ 独立。
- Externally providable:是 external 类参数 → ✅ 独立(用户会说)。
- Internally satisfiable:是 internal 但前序工具能产出 → ✅ 独立。
- 其他情况 → ❌ 必须递归地往回采前序工具来满足这个 internal 参数。
这个递归过程保证了所有依赖在 \(v\) 加入链之前都被解决。然后,处理完依赖之后,从 \(v\) 的出边里随机选 1 到 \(k\) 个邻居继续展开——这个分支机制就是图 2 里那个非线性树状结构的来源。
我觉得这个设计是真的扎实。我之前在做类似事的时候踩过坑:random walk 出来的工具链跑训练时会经常出现"用户说不清楚的参数"这种逻辑漏洞,模型只能瞎猜或者反复 clarification,奖励信号变得很噪。EnvFactory 这套显式的 internal/external 划分 + 递归依赖求解,等于给训练数据上了一道逻辑可满足性的硬约束。这步搞对了,下游所有合成才有意义。
2.2.2 校准式精炼:把指令链扭成真人话
工具链采好之后,QueryGen 还要做四步精炼,把"过度规约"的初稿改造成自然请求:
- Implicit reference(隐式引用):把显式 ID 换成上下文引用,省略可推导参数。比如把
book hotel with hotel_id=hotel_42改成book the first one。 - Action compression(动作压缩):把可推理的中间步骤压缩。比如"先查列表再选第一个"可以简化为"帮我订一个"。
- Ambiguity introduction(歧义引入):故意加一些合理的指代歧义。
- Goal expansion(目标扩展):补一些和主题相关的次要目标,让对话更像真人那种"顺嘴一提"的风格。
这四步看起来零碎,但综合起来效果其实挺有意思。我们在消融实验里能看到:去掉 refinement 阶段,在 Miss-Func / Miss-Param 这种考歧义处理的子集上掉得最厉害——这恰好印证了 refinement 不只是让 query "好看",而是真的在训练模型处理隐式意图的能力。
2.2.3 沙箱交互 + 过滤:把奖励基础打牢
光有 query 还不够,RL 训练需要 ground-truth trajectory。QueryGen 的做法是:
- 部署沙箱环境,让 Agent 和模拟用户对话。Agent 调工具或者反问用户,模拟用户照 instruction 回答或主动结束会话。
- 每个 query 跑 \(k\) 次拿到 \(k\) 条候选轨迹。
- 评估每条轨迹和数据库状态变化,挑最优的留作 ground-truth。
- 过滤掉冗余调用、不必要的用户交互,并对那些"值不影响正确性的参数"打 mask(这点对 RL 奖励特别重要,避免因为参数细节差异给假阳性奖励)。
2.3 RL 训练:一个简洁但讲究的复合奖励
整个数据合成管道下游接的是 SFT + RL 的两阶段后训练。RL 部分用的是 GRPO(DeepSeekMath 那套),框架是 VeRL。
奖励设计是这样的:
三个组件各管一摊:
- \(R_{\text{traj}}\):轨迹匹配奖励,看预测的工具调用序列和 ground-truth 的匹配度。
- \(R_{\text{state}}\):状态等价奖励,看执行完后数据库的最终状态是否等价。
- \(P_{\text{length}}\):长度惩罚,防止模型为了多调几次工具骗奖励。
为什么不能光看 trajectory 或者光看 state?作者讲得很清楚:有效解通常不唯一。两个独立的只读工具调用换换顺序也都是对的;search 工具的 limit=10 还是 limit=20 都行。光看 trajectory match 会过严,光看 state match 又过松(因为有些工具是只读的,不改变状态)。所以两个都要看,权重 \(\alpha\) 调到合适才稳。
这块设计我个人觉得挺漂亮的。Tool-use RL 的奖励设计是个老问题——精确匹配一定的 trajectory 会给学习路径打太死,纯 outcome reward 又稀疏到学不动。EnvFactory 这套 trajectory + state + length penalty 的复合设计是个相对务实的折中。
三、实验:拿 1/5 的数据怎么跑赢
实验设计很直接:在 Qwen3-1.7B/4B/8B 三个尺寸的底座上,对比 base 模型、AWM(526 环境 / 3315 任务)、EnvScaler(191 环境 / 11572 任务),评估在 BFCL v3、τ²-Bench、VitaBench、MCP-Atlas 四个基准上的表现。
3.1 主表:4B 模型从 24.09 涨到 30.77
| 模型 | Env | Tasks | BFCL ST | BFCL MT | MCP Pass | MCP Cov | τ²-Bench Avg | VitaBench Avg | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-1.7B | |||||||||
| Base | -- | -- | 79.48 | 16.75 | 1.03 | 6.25 | 14.61 | 1.33 | 16.27 |
| EnvScaler | 191 | 11572 | 60.41 | 30.13 | 2.75 | 9.40 | 13.65 | 4.36 | 16.51 |
| Ours (SFT) | 85 | 1622 | 78.30 | 23.25 | 1.72 | 10.05 | 15.57 | 6.33 | 18.60 |
| Ours (full) | 85 | 2575 | 78.44 | 28.38 | 3.09 | 9.64 | 15.11 | 7.33 | 19.74 |
| Qwen3-4B | |||||||||
| Base | -- | -- | 85.15 | 33.50 | 4.12 | 12.86 | 25.25 | 7.67 | 24.09 |
| AWM | 526 | 3315 | 85.97 | 40.75 | 4.47 | 12.33 | 22.37 | 11.67 | 25.47 |
| EnvScaler | 191 | 11572 | 83.64 | 45.00 | 9.97 | 22.27 | 29.25 | 14.69 | 29.56 |
| Ours (SFT) | 85 | 1622 | 85.10 | 44.25 | 7.90 | 19.66 | 25.25 | 11.33 | 27.29 |
| Ours (full) | 85 | 2575 | 85.46 | 48.50 | 9.97 | 21.89 | 30.13 | 16.00 | 30.77 |
| Qwen3-8B | |||||||||
| Base | -- | -- | 84.31 | 41.25 | 5.15 | 14.86 | 32.30 | 16.70 | 29.23 |
| AWM | 526 | 3315 | 84.80 | 42.25 | 6.19 | 16.60 | 28.42 | 16.48 | 28.65 |
| EnvScaler | 191 | 11572 | 84.74 | 51.88 | 9.62 | 22.63 | 34.30 | 18.67 | 32.72 |
| Ours (SFT) | 85 | 1622 | 84.83 | 46.50 | 8.25 | 22.86 | 32.71 | 16.67 | 30.82 |
| Ours (full) | 85 | 2575 | 86.02 | 49.00 | 13.75 | 25.98 | 33.67 | 18.67 | 33.40 |
几个值得拎出来说的点:
4B 上的提升最为干净。BFCL 多轮从 33.5 涨到 48.5(涨了 15 个点),VitaBench 从 7.67 涨到 16.00(翻倍以上),整体从 24.09 拉到 30.77。比起 EnvScaler 的 11572 任务,EnvFactory 只用 2575 任务就拿到了更高的 Overall 分(30.77 vs 29.56),训练效率差距相当明显。
MCP-Atlas 上的优势更打眼。这是个真实 MCP 环境的基准,4B 上 EnvFactory 拿到 9.97 Pass / 21.89 Coverage,跟 EnvScaler 持平甚至略有优势;8B 上更夸张,13.75 Pass / 25.98 Coverage 直接是全场最优。MCP-Atlas 是离线评测里最接近"真实部署效果"的,这个数能打就说明 EnvFactory 的环境建得"够真"。
1.7B 上 EnvScaler 的 BFCL 多轮反而更高。这点其实暴露了一个细节——EnvScaler 在 1.7B 上 BFCL 单轮反而崩到 60.41(base 79.48),多轮分高很可能是用单轮能力做了交换。EnvFactory 1.7B 单轮稳在 78.44,没出现这种"刷一项掉一项"的现象,整体均衡度更好。
对话型基准(τ²-Bench、VitaBench)的优势特别清楚。这俩基准对"隐式意图"和"多轮歧义处理"考得最严,正是 QueryGen 精炼阶段对症下药的地方。VitaBench 上 4B 从 7.67 涨到 16.00、8B 涨到 18.67,配 8B 和 EnvScaler 持平——考虑到只用了 1/5 的数据,这个性价比是真高。
说实话,看到这张表的时候我有几秒钟在怀疑——是不是数据太少导致评测不稳定?但是看到三个尺寸的曲线都能保持一致的提升,而且不是只在某一个 benchmark 上偏科,这种"全面但适度"的提升其实是高质量数据的典型信号。
3.2 环境数量的 scaling 与效率

图 3:(a) BFCL v3 多轮平均分随环境数量(0/50/75/85)变化的曲线。三个尺寸都呈现 diminishing return——4B 从 0 环境 33.5 → 50 环境 41.4 → 75 环境 47.38 → 85 环境 48.25,前 50 个涨幅最大,后面 35 个加速放缓。(b) 资源效率散点图:横轴是环境数、纵轴是训练任务数、点上的标注是 BFCL 多轮分。EnvFactory(左下绿点,85 env / 2575 task / 48.5 分)显著优于 EnvScaler(中上蓝点,191 env / 11572 task / 45.00 分)和 AWM(右下紫点,526 env / 3315 task / 40.75 分)。
这张图的右半部分特别值得反复看。EnvScaler 用了 4 倍多的训练任务(11572 vs 2575)只拿到 45.00,AWM 用 6 倍多的环境(526 vs 85)只拿到 40.75,而 EnvFactory 在左下角的"少环境少任务"区位拿到 48.50。
但同时图 3(a) 也透露出一个不该忽略的信号——diminishing return 已经显现。从 75 个环境涨到 85 个的边际收益(4B 上 47.38 → 48.25 只涨 0.87 个点)远小于 50 → 75 的跨度(41.4 → 47.38 涨 5.98 个点)。这意思是说,如果继续往上叠环境,收益曲线会越来越平。这其实是把"质量 vs 数量"的天花板讲清楚了——数量到了一个临界点(差不多 75-100 之间),增量必须靠质量分化。
我在这里有点反向的怀疑:如果是 200 个环境呢?500 个呢?论文展示的是 0-85 的范围,但 EnvScaler 用 191 个的成绩 45.00 还是低于 EnvFactory 的 85 个 48.5。这里的对比有可能不是"85 个就够了",而是"EnvFactory 这套环境的质量比 EnvScaler 高"。换句话说,质量论 vs 数量论在这个对比下其实是混在一起的,不能完全归因。但即便如此,"少而精"的 EnvFactory 确实在 RL 训练资源消耗上占了大便宜,这个工程价值是实在的。
3.3 Reward 权重消融:α=0.5 是甜点
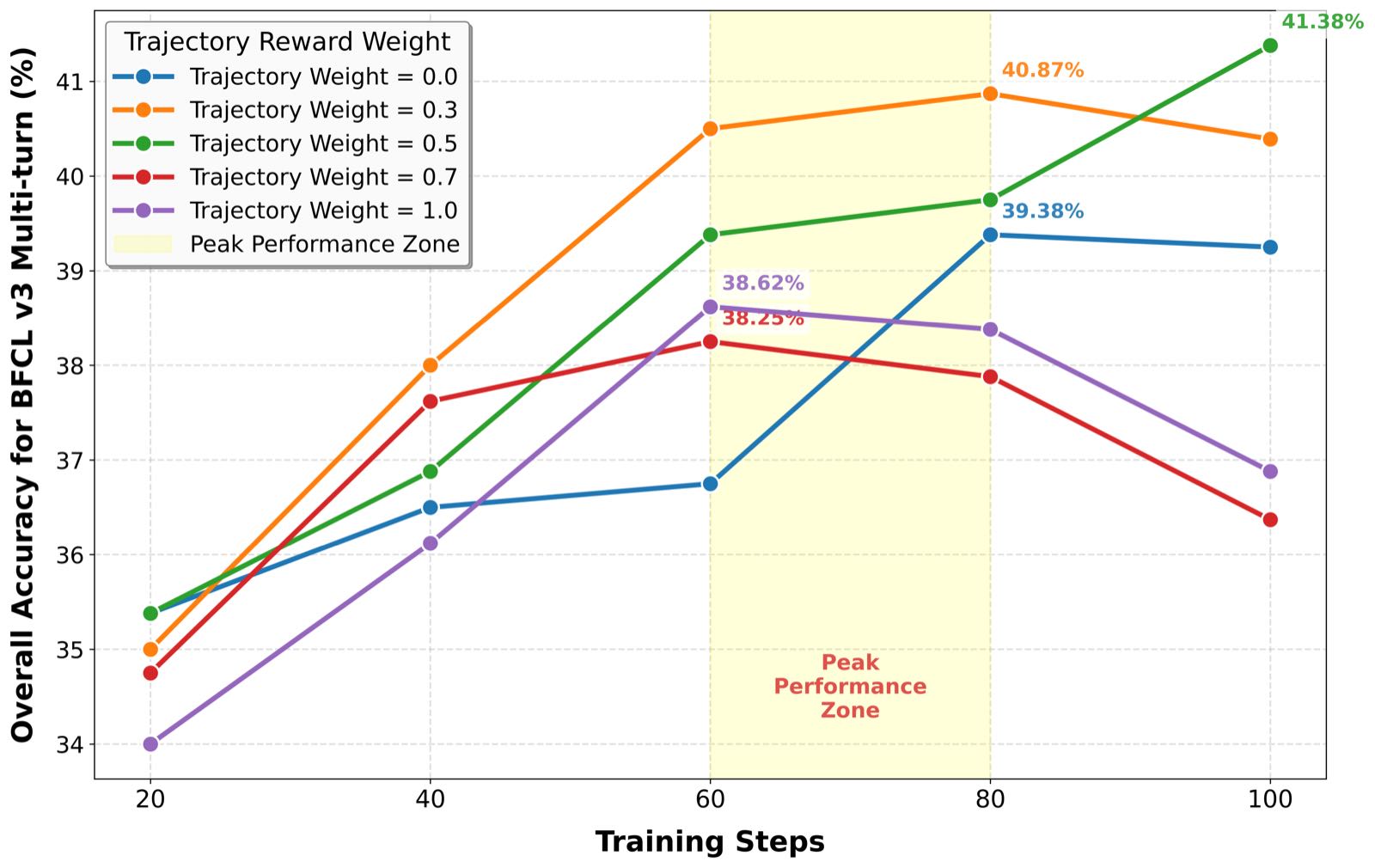
图 4:在 BFCL v3 多轮上,Trajectory reward weight α 取 {0, 0.3, 0.5, 0.7, 1.0} 时的训练曲线。α=0.5(绿色)最终拿到 41.38% 的 peak,α=0.3(橙色)次之 40.87%,纯 trajectory(α=1.0,紫色)和纯 state(α=0,蓝色)都明显更差。Peak Performance Zone 集中在 60-80 步训练区间。
这张图是对前面奖励设计的最强证据。\(\alpha = 0\)(纯 state reward)和 \(\alpha = 1.0\)(纯 trajectory match)都明显跑不过混合权重。这个曲线告诉你两件事:
- trajectory 和 state 是互补信号。光看一个会要么过严要么过松。
- balanced weight 不是越平均越好——α=0.5 比 α=0.3 略好但差距不大,α=0.7 反而退化。这说明 trajectory match 的权重要稍微给得轻一点,让 state 等价性参与训练,因为 state-based reward 能宽容地容纳"等价路径"。
我看到这个图的时候,第一反应是想起 RL 里"奖励组合"的老问题。多个奖励信号合成时,权重选错很容易导致训练发散或者退化到某个 dominant signal。EnvFactory 这里 α=0.5 是个工程上比较安全的默认值,但能不能动态自适应?比如训练前期偏 trajectory(学格式),后期偏 state(学正确性)?这个论文没探讨,是个有意思的扩展方向。
3.4 数据分布画像

图 5:左图 (a) 每 turn 的 step 数分布——平均 3.18 步,中位数 2 步。中图 (b) 每对话的 turn 数——平均 4.99 turn,中位数 5。右图 (c) 每 turn 中工具调用数(橙色)和用户交互数(紫色)的对比——平均 2.38 次工具调用、0.80 次用户交互。
这组分布很有信息量。一条对话平均跑 5 turn,每 turn 3 步左右,全部加起来一条 trajectory 平均 15 个动作(工具调用 + 用户交互)。这个长度对小模型(1.7B / 4B)已经有相当的 long-horizon 挑战了。
这里有个细节挺有意思——用户交互占比(0.80 / turn)意味着平均每 turn 模型会主动反问用户一次。这恰恰是 QueryGen 的 ambiguity introduction + implicit reference 的产物:用户给的信息不全,模型必须学会"主动澄清"。这种数据分布跟 τ²-Bench / VitaBench 这种考"主动澄清"能力的基准是直接对齐的——这也解释了为什么对话型基准上提升比 BFCL 还要明显。
3.5 直接 RL vs SFT+RL 消融
| 模型 | BFCL ST | BFCL MT | τ²-Bench | VitaBench |
|---|---|---|---|---|
| Qwen3-1.7B (base) | 79.48 | 16.75 | 14.67 | 1.33 |
| Ours-1.7B (RL only) | 79.53 | 18.33 | 18.28 | 1.67 |
| Qwen3-4B (base) | 85.15 | 33.50 | 25.33 | 7.67 |
| Ours-4B (RL only) | 85.26 | 41.38 | 24.83 | 12.74 |
| Qwen3-8B (base) | 84.31 | 41.25 | 32.33 | 16.70 |
| Ours-8B (RL only) | 84.42 | 44.35 | 29.08 | 17.00 |
这张表是想回答一个问题:SFT 冷启动是必需的吗?
答案是:有 SFT 冷启动稳定得多。直接 RL 在 BFCL 多轮上 4B 能从 33.5 涨到 41.38(+7.88 个点),但相比 SFT+RL 的 48.5(+15 个点),还是差一截。更要命的是 τ²-Bench 在 4B 和 8B 上居然退化了(25.33→24.83,32.33→29.08)。
这其实是 RL 训练的常识——直接从 base 模型起 RL,很容易因为初始策略太烂、reward 信号稀疏导致对话风格上的 mode collapse。SFT 的作用不只是教格式,更是把"回答方式"先固定到一个合理基线,再让 RL 在这个基线上做优化。所以表里看到 BFCL(纯工具调用)上 RL 能直接学,但 τ²-Bench(带对话)上必须 SFT 兜底,这跟两个基准对"对话稳定性"的要求差异是吻合的。
3.6 Refinement 阶段的细分增益
| 模型 | Base | Miss-Func | Miss-Param | Long-Context | Overall |
|---|---|---|---|---|---|
| Unrefine-1.7B | 30.0 | 21.5 | 19.5 | 14.0 | 21.25 |
| Refine-1.7B | 30.5 | 22.5 | 21.0 | 14.5 | 22.12 |
| Unrefine-4B | 52.0 | 47.0 | 30.5 | 34.0 | 40.88 |
| Refine-4B | 49.5 | 47.5 | 32.0 | 36.0 | 41.25 |
| Unrefine-8B | 51.5 | 47.0 | 38.5 | 35.0 | 43.00 |
| Refine-8B | 55.0 | 47.0 | 39.0 | 35.0 | 44.00 |
这张表是 refinement 阶段的精细消融。Miss-Func(缺工具)和 Miss-Param(缺参数)这两列上,refined 数据训出来的模型几乎全胜——这正是"歧义处理"和"主动澄清"能力的直接体现。
但是 4B 在 Base 子集上反而是 unrefined 略高(52.0 vs 49.5)。这点其实暴露了 refinement 的双刃剑性质:refined 数据让模型学会了在简单场景下也"过度谨慎"地反问,反而丢了一点直接执行的效率。这个 trade-off 论文没展开讨论,但工程上是个值得注意的点——如果你的产品场景大部分是简单任务,盲目做 ambiguity 注入未必是好事。
四、几个我觉得值得单独拎出来聊的设计
4.1 为什么 internal/external 参数划分是个聪明的工程抽象
我前面特意花篇幅讲了这点,因为这其实是整套数据合成里信息密度最高的设计。
业内做工具调用的同行应该都体会过——为什么有些合成数据训出来的模型上线后老是"幻觉参数"?因为合成数据里 hotel_id=42 这种内部 ID 出现得太多,模型学会了"反正就乱编一个 ID"。
EnvFactory 的 internal/external 划分等于在数据源头显式区分了哪些参数是"用户能给的"、哪些是"工具链得自己产出来的"这件事。前者训练时直接放在 query 里、后者必须靠工具组合自动满足。这种分离让 RL 训练的奖励信号变得格外干净——模型学到的不是"猜参数",而是"该 search 就 search、该 take from previous 就 take"。
这种思路其实在很多论文里都隐含地存在,但 EnvFactory 把它做成了显式的、可计算的、嵌入采样过程里的硬约束,工程上是真的扎实。
4.2 拓扑感知采样跟工业界的常见做法的对比
我顺便比了一下同期的几个工业方案:
- AgentScaler / AutoForge:基于预收集的 API 文档展开,工具关系通过 LLM 一次性推断,缺乏显式图结构。
- EnvScaler:环境数量大(191),但工具间依赖建模相对粗糙,靠大数量盖住质量。
- AWM(Agent Workflow Memory):偏向从历史 trajectory 复用模式,对新工具组合的覆盖偏弱。
EnvFactory 的差异在于把工具关系建成一张有向图,且做了 internal/external 分层——这种处理让"用户能怎么自然地表达"和"工具链怎么自动满足依赖"被打通了。这是它能"用少数据打多数据"的方法论根源。
4.3 真实 API vs 合成沙箱:这条路线赌的是什么
EnvFactory 这套方案说到底还是"合成沙箱"路线——不直接对接真实 API,而是让 LLM 写代码模拟出有状态、可执行的本地环境。这条路线的赌注是:
- 赌训练效率高于环境真实度损失。沙箱环境再像真的,跟生产 API 还是有差距。但如果训练能跑得稳、能 scale,最后在真实 MCP(MCP-Atlas)上的迁移效果不差,这笔账就划算。
- 赌 Search Agent 找的源能足够全。如果 Search Agent 漏掉了某些重要 API 模式,整个环境池会有系统性盲区。
- 赌 Test Agent 的校验足够严。如果 unit test 不全,错误的工具实现会带毒进训练。
从 MCP-Atlas 上的最优表现看,这三个赌注目前都站住了。但我的判断是:这条路线的天花板取决于 Search Agent 的覆盖能力。当一个领域的工具生态频繁更新(比如新的 SaaS 产品、新版本 API),EnvFactory 需要重新跑一遍 EnvGen 来追上,否则训练数据会慢慢和真实生态脱节。这是合成沙箱路线绕不开的天然劣势。
4.4 "85 个环境就够"的话术要带保留
整篇论文反复强调"only 85 environments",这是它最 catchy 的卖点。但坦率说——
- 85 这个数已经覆盖了 7 个领域,842 个工具,平均每个环境约 10 个工具。这其实不算少了,跟很多 toolbench 的规模差不多。
- "5 倍少"是对比 EnvScaler 的 191 environment(其实只有 2.25 倍多)和 AWM 的 526 environment(这个是 6 倍多)。比起更早期的 ToolBench-16k 这种环境量,85 当然是少很多。
也就是说,"85 vs 500+"的对比是合理的,但不要被"85 个环境就够训世界级 Agent"这种话给迷惑了。这套方法在更复杂的、更长尾的工具调用场景(比如你要做个能控制 200+ 个内部企业系统的 Agent)下,环境量大概率还是要扩。
4.5 缺失的对照:纯靠 trajectory 数据增强而不增加环境会怎样?
论文展示了 0 / 50 / 75 / 85 个环境的 scaling,但没有展示固定环境数、不断增加 trajectory 数据的曲线。也就是说:"85 environments + 5000 trajectories" vs "85 environments + 2575 trajectories" 谁强?
如果是前者反而更强,那说明 trajectory 数据规模本身仍是瓶颈,"85 envs 够用"的论点就要打折。如果是后者饱和,那才能说"85 envs + 2575 trajectories 是个甜点"。论文这块缺失对照让"少数据更好"的论点不够完整。
五、我的判断:值不值得跟、能怎么用
亮点很扎实:
- 环境合成的多 Agent 协作 + Test Agent 四维校验:这套范式可复用,工程价值高。如果你团队也在做 self-debugging 的代码生成 Agent,Test Agent 的结构化错误归因模式值得抄。
- 拓扑感知采样 + internal/external 划分:是这篇论文方法论上的硬骨头,把"用户能怎么说话"形式化进采样过程,是真的解决了过度规约问题。
- 复合奖励设计(trajectory + state + length penalty):tool-use RL 上一个相对务实的稳健配方,工程上可以直接借鉴。
- 数据效率:在 Qwen3-4B / 8B 上拿到的 BFCL 多轮 / MCP-Atlas 数字是真能打的。如果你做 Agent RL 又被环境数据卡住,这套思路值得仿制。
值得保留的批判:
- 关于所谓"85 个环境就够"这套话术,其实有点过度营销。MCP-Atlas 这种真实场景上,环境覆盖度是个长期命题,不可能一劳永逸。
- 质量 vs 数量的对照不完整。论文没做"同样 85 个环境扩 trajectory 到 5000+"的实验,所以"少而精"的论断只能算部分成立。
- Search Agent 覆盖盲区的风险没充分讨论。这套方法对长尾、闭源、新兴的工具生态适配能力存疑。
- Refinement 在简单任务上的过度谨慎副作用没有在文中点破——4B Base 子集上 unrefined 反而更高,这个 trade-off 实际部署里要权衡。
- 直接 RL 在对话型基准上退化这点其实暴露了 RL 单独跑的脆弱性,对工业落地是个真问题。
对工程实践的几条启发:
- 如果你在做工具调用 Agent 的 RL 训练,先把环境的有状态可执行做扎实比急着上算法重要得多。EnvFactory 的 EnvGen 流程可以直接拿来当模板。
- Internal/External 参数划分这个抽象,在你做任何工具调用相关的数据合成时都值得引入——不只在 RL 里,SFT 也一样适用。
- 复合奖励配方(trajectory + state)是个稳健选择,比单一 reward 鲁棒得多。如果你不知道权重怎么调,从 α=0.5 起是个安全默认值。
- 不要直接 RL 跳过 SFT——尤其是涉及对话风格的任务,τ²-Bench 上的退化是个明确的警告。
整体看下来,EnvFactory 是一篇工程性极强、方法论扎实、但话术稍微夸大的好工作。不是颠覆性突破,但确实给"工具调用 RL 数据合成"这个方向树了一个相对完整的 pipeline 模板。如果你正在这条赛道上挣扎,值得花时间细读、把它的几个核心组件拆出来在自己的栈里复现。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我